
Kubernetes 异构资源细粒度调度策略的设计与实现
2023-02-20 09:38刘志彬黄秋兰胡庆宝程耀东胡誉田浩来
计算机工程 2023年2期
刘志彬,黄秋兰,胡庆宝,程耀东,4,胡誉,田浩来,3
(1.中国科学院高能物理研究所,北京 100049;2.中国科学院大学,北京 100049;3.散裂中子源科学中心,广东 东莞 523803;4.中国科学院高能物理研究所 天府宇宙线研究中心,成都 610041)
0 概述
在复杂的计算环境中,云计算技术可以显著提高计算资源的利用率[1]。随着容器化技术[2]的快速发展,海量的服务正在从虚拟机的单体架构迁移到基于容器的云原生架构[3]。谷歌的开源容器编排工具Kubernetes[4]已经成为在云环境中部署容器化应用的事实标准。因此,需要合理的资源调度技术来提高资源利用率以及服务质量[5-6]。
Kubernetes 的资源调度流程是将用户申请的pod 调度到合适的节点上[7]。调度器通过硬件厂商提供的设备插件掌握拓展的异构资源,并利用拓展资源进行异构资源的调度[8],但是目前Kubernetes 仅支持卡级别的调度,即用户pod 可以申请独占一块或者多块GPU卡[9],而调度器无法判断单个硬件资源是否满足细粒度的需求[10-12]。在CPU 和内存的调度方面,学者们开展了一系列研究工作并取得了一定的成果。文献[13]提出一种基于遗传算法的Kubernetes 资源调度算法,保证了集群的负载均衡。文献[14]结合蚁群算法和粒子群优化算法对调度器进行改进,降低了节点最大负载并使任务分配更加均衡。文献[15]设计一种综合的监控机制,将系统资源利用率和应用指标提交给调度算法以指定更好的调度策略。文献[16]在CPU 和内存的基础上添加了I/O 和网络指标,提高了集群的负载均衡效率。文献[17]提出一种干扰-拓扑感知的深度学习并行化方法,该方法有效提高了GPU 资源利用率。文献[18]考虑了GPU 和CPU 异构资源调度,使用机器学习方法提取pod 任务特征,并且按照任务类型将pod 调度到合适节点。
本文针对交互式计算中pod 异构资源需求依赖于用户申请的情况,提出一种异构计算资源混合调度策略,拓展GPU 资源信息以满足细粒度的资源需求,并且通过优化默认调度器的过滤和打分策略,实现异构资源混合部署情况下的资源调度,以避免资源竞争导致不合理的资源分配,并提高集群资源的利用率。
1 Kubernetes 默认调度策略及其对GPU 的支持
1.1 Kubernetes 调度流程
在Kubernetes 集群中,Kube-scheduler 组件的任务是将pod 调度到集群[19-20]中特定的节点,该组件默认的行为是根据pod 期望的资源(例如CPU、memory等)来过滤节点,然后对可用的节点进行打分,最终选择一个分数最高的节点完成与待调度pod 的绑定。
Kube-scheduler 提供了一个调度框架,可根据多种内置算法进行过滤和打分,并且支持开发者拓展自定义的调度算法。目前,Kube-scheduler framework 调度流程分为两个阶段:过滤阶段和打分阶段。过滤阶段的主要目标是过滤不满足需求的节点,每个节点都会检查自己的空闲资源是否满足pod 的请求,如果满足则将节点加入可用节点列表。默认的过滤节点策略包括PodFitsResources、NoDiskConflict等。打分阶段的主要目标是从可用节点列表中选择一个分数最高的节点与待调度的pod 进行绑定。默认的优选节点策略包括LeastRequestedPriority、ImageLocalityPriority等。
除了基于节点可用资源调度以外,调度器还基于以下方法或特性进行调度:1)NodeSelector,是一种基于标签的调度方法,管理员为某些节点打上特定标签,用户在创建pod 时手动指定NodeSelector 标签;2)节点亲和性,使用逻辑运算符控制节点关联约束的严格程度来调度pod,比NodeSelector 更加灵活;3)pod 亲和性,根据pod 和其他pod 之间的关系来调度,通常相互依赖的pod 运行在同一节点上。
1.2 GPU 支持
在一些高级调度场景中,例如深度学习任务,需要高性能的GPU 来运行训练任务[21-23]。在异构资源混合部署场景中,Kubernetes 集群管理员期望根据约束将pod 正确调度到具有专有计算资源的节点上。
Kubernetes 提供了设备插件机制用于支持GPU[24-25]等异构资源。NVIDIA device plugin具备GPU 加速功能,具体步骤为:1)通过监控节点上的GPU 信息将资源上报到节点上的Extended Resource处;2)当节点部署容器时为容器分配GPU 资源。当用户申请GPU 资源时,在Spec 字段处添加字段"nvidia.com/gpu:2"表示申请两块GPU卡,Kubernetes默认调度器在过滤阶段会检查Extended Resource,完成对GPU 节点的过滤。NVIDIA device plugin 虽然满足了用户使用GPU 的需求,但是也存在以下问题:1)没有提供GPU 调度策略,在异构资源混合部署时容易造成资源竞争;2)资源上报粒度较粗,仅能满足GPU 卡数量的需求,已分配的GPU 在显存大小、核心数量等方面可能无法满足用户计算需求。
2 改进的Kubernetes 异构资源调度策略
本文提出一种细粒度的异构资源调度策略。在集群中,不同类型的应用对计算资源的需求不一样,不同的节点提供的计算资源类型也不同。在异构资源混合部署的情况下,对提供计算资源的节点与申请计算资源的pod 进行类型划分:根据是否提供GPU 将节点划分为CPU 节点和GPU 节点;根据是否申请GPU 将pod 划分为CPU 型pod 和GPU 型pod。
2.1 GPU 资源的拓展
针对GPU 调度资源上报粒度较粗的问题,首先拓展Kubernetes api 对GPU 资源的支持,创建GPU自定义资源,包含GPU 卡数、每张卡的显存大小、每张卡的核心数量等状态信息,将该自定义资源在Kubernetes ETCD 数据库中进行注册并持久化保存,以便调度器从全局视角获取各个节点的GPU 状态信息,然后设计一个控制器定时检查节点上的GPU信息,并上报给apiserver 更新GPU 自定义资源。
用户在申请资源时添加自定义注解进行细粒度资源申请,例如在annotation 中添加字段"oks/gpunumber:2"表示申请两块GPU卡,"oks/gpu-core:2000"表示每块卡有2 000 个核心,"oks/gpu-memory:32000"表示每块卡有32 000 MB 显存。在用户pod调度阶段,自定义调度器通过向apiserver 查询最新的GPU 状态信息,为下一步调度决策提供细粒度资源信息。
2.2 GPU 过滤算法的改进
在调度器过滤阶段,除了原有的CPU、memory等过滤以外,本文算法还会检查自定义注解对GPU细粒度资源的申请,通过对比pod 申请的资源与GPU 拓展中节点当前可用资源进行节点过滤,将满足用户需求的节点加入可调度列表。在GPU/CPU混合部署调度策略下,本文改进的过滤算法流程如图1 所示,具体步骤如下:
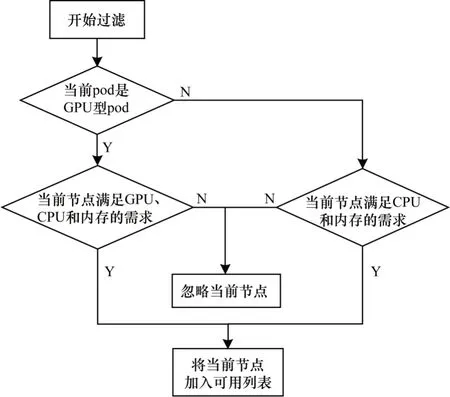
图1 改进的过滤算法流程Fig.1 Procedure of improved filtering algorithm
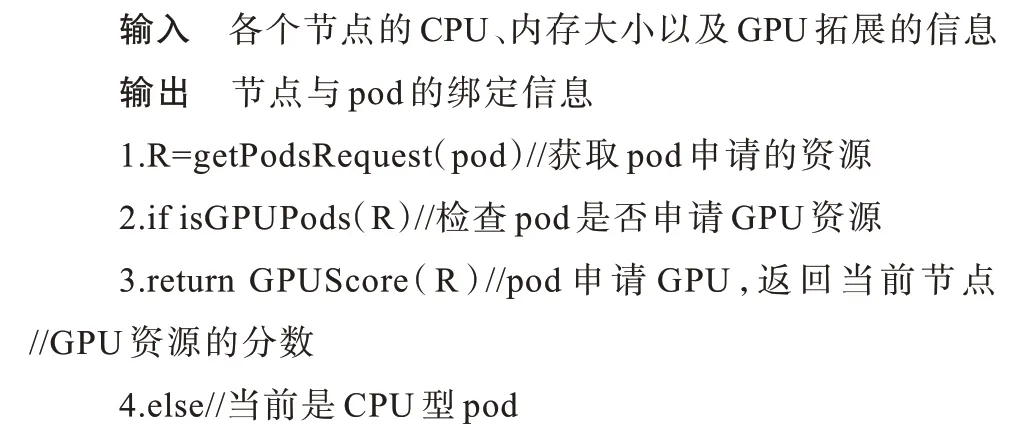
1)根据pod 的自定义注解判断pod 是GPU 型还是CPU型,如果是CPU 型应用则跳转到步骤2,如果是GPU 型pod 则跳转到步骤3。
2)使用默认的过滤策略NodeResourceFit,检查节点的空闲资源是否满足pod 的要求,如果满足则跳转到步骤4。
3)使用改进的过滤策略,在NodeResourceFit 的基础上,根据pod 的注解获取申请的GPU 详细信息,包括GPU 卡数、每块卡的显存大小、每块卡的核心数量等,检查GPU 拓展中节点上空闲GPU 资源是否满足pod GPU 请求,如果满足则跳转到步骤4,如果不满足则跳转到步骤5。
4)节点满足pod 请求,将当前节点添加到可用列表,退出。
5)节点不满足pod 请求,忽略当前节点,退出。
2.3 混合部署下的调度策略设计与实现
为了根据pod 所需的计算资源类型选出最合适的节点,调度器将完成过滤阶段的满足需求的节点进行打分,选择分数最高的节点和pod 进行绑定。由于GPU 资源比较缺乏,因此在混合计算资源部署情况下进行调度,本文打分策略的主要思想是为异构资源的节点设置优先级,优先保证CPU 型pod 调度到CPU 节点:当CPU 节点资源不足时,可以调度到GPU 节点空闲的CPU上,以提高集群资源利用率;当CPU 节点资源充足时,如果CPU 应用调度到GPU 节点,可能会造成GPU 节点因为CPU 不足而无法被调度,从而造成GPU 资源浪费。
针对CPU 节点,使用默认调度器提供的leastRequestedScore,其表示当前节点对于CPU 型pod 的分数,该算法计算公式如式(1)所示:
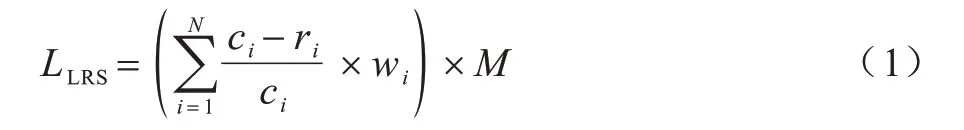
其中:N={1,2}表示CPU 和memory 两种资源;c表示节点上资源最大容量;r表示节点上已请求的资源数量;w表示资源的权重,默认为0.5;M表示节点分数的最大值,节点分数的取值范围为[0,M]。
在调度GPU 应用时,根据GPU 型pod 的需求对GPU 节点进行打分,将GPU 卡的算力、带宽和核心3 个维度的数据综合度量并计算最终得分。定义Scard为节点上GPU 卡的性能分数,计算公式如式(2)所示:
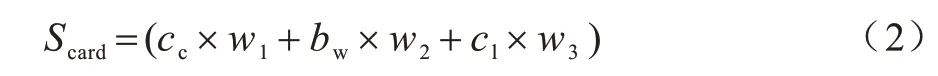
其中:cc代表归一化后的GPU 算力;bw代表归一化后的带宽;cl代表归一化后的时钟;w1、w2、w3默认为1/3。
Scard值越高,代表GPU 卡的性能越好,该值使得当前打分算法偏好性能更好的GPU。
定义Ssimilarity为当前节点空闲资源向量与pod 申请资源向量的相似度。每个节点上空闲的GPU 卡数为CCard_free,每块卡的显存大小为CCard_mem,每块卡的核心数量为CCard_core,空闲CPU 的核心数量为CCPU_free,空闲内存大小为CMem_free,则节点空闲资源向量N可以表示为N=(CCard_free,CCard_mem,CCard_core,CCPU_free,CMem_free)。pod 申请的GPU 卡数为RCard_num,每块卡的显存大小为RCard_mem,每块卡的核心数量为RCard_core,pod 申请CPU 核心数量为RCPU_num,pod 申请内存大小为RMem_num,则pod 申请资源向量R可以表示为R=(RCard_num,RCard_mem,RCard_core,RCPU_num,RMem_num)。相似度计算公式如式(3)所示:

对于过滤阶段得到的候选节点,空闲资源向量均大于pod 申请资源向量,相似度Ssimilarity使得当前打分算法倾向于剩余资源最小的节点,因为GPU 独占使用,所以节点GPU 负载高不会互相影响,并且有利于大需求应用的调度。
GPU 节点打分公式如式(4)所示:

其中:Scard表示GPU 卡自身属性;Ssimilarity代表节点资源与pod 申请资源的需求契合程度。
在调度CPU 应用时,GPU 节点和CPU 节点可能同时满足pod 需求,本文提出一个主导资源优先级的算法PriorityScore,保证CPU 节点资源充足的情况下CPU 节点的优先级大于GPU 节点,即CPU 节点分数一定大于GPU 节点分数。定义SCPU为节点针对CPU 型pod 的分数,计算公式如式(5)所示:
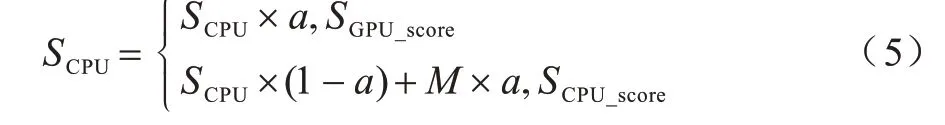
其中:a是GPU 节点数量与集群中节点总数的比值。如果SCPU是CPU 节点,则节点分数取值范围为[100×a,100];如果SCPU是GPU 节点,节点分数取值范围为[0,100×a)。SCPU保证CPU 节点的分数高于GPU 节点的分数,只有在CPU 节点资源不足的情况下,才会将CPU 应用调度到GPU 节点。
算法1混合调度打分算法

3 实验结果与分析
实验采用Kubernetes1.19.5 版本,部署在5 个物理节点上,集群中共有1 个master 节点、4 个worker节点,master 节点不进行应用调度,worker 节点中2 个节点有CPU、2 个节点有GPU。实验环境配置如表1 所示。
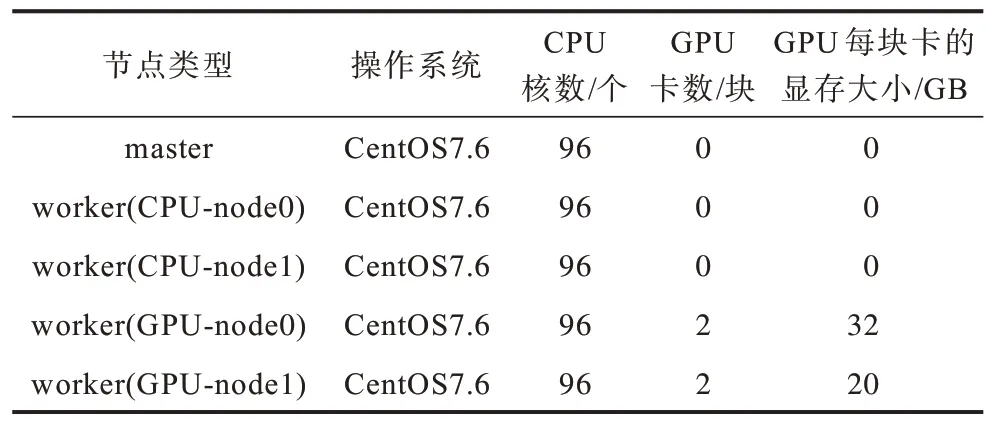
表1 实验环境配置 Table 1 Experimental environment configuration
3.1 混合调度结果
在集群搭建完成后进行混合部署下的实验验证。测试pod 的资源请求量如表2 所示,由于每个节点上都有Kubernetes 代理组件以及监控组件,实际空闲CPU核心数量小于表1 中的数量,因此每个节点最多运行5个pod。然后对集群进行压力测试,创建20个测试pod,其中16 个为CPU 型pod、4 个为GPU 型pod,具体步骤为:1)使用默认调度器创建20 个测试pod;2)删除所有测试pod,使用Kuberentes LabelSelector 将节点按照资源划分为CPU 集群和GPU 集群,使用默认调度器分别调度16 个CPU 型pod 到CPU 集群、4 个GPU 型pod 到GPU 集群;3)删除所有测试pod,使用本文实现的自定义调度器创建与步骤1 相同的20 个pod。

表2 pod 资源请求量 Table 2 pod resource requests
为了对比异构计算资源混合部署下使用默认调度器和自定义调度器的实验结果,实验中只考虑了对调度结果影响最大的CPU 和GPU 两种计算资源。通过统计各个节点pod 的类型和数量,得到节点上pod 的数量如图2 所示。由图2 可以看出,默认调度器均衡地将CPU 应用调度到各个节点。对于4 个GPU 型pod,2 个分别调度到GPU-node0 和GPUnode1节点,剩余2 个因为GPU 节点的CPU 资源不足而处于pending 状态。
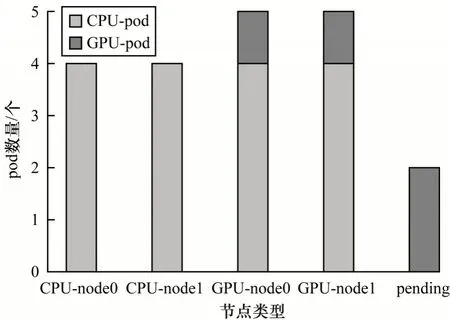
图2 CPU/GPU 混合部署下默认调度器实验结果Fig.2 Default scheduler experimental results under CPU/GPU hybrid deployment
图3 为CPU/GPU 独立部署下默认调度器的实验结果,该部署方式避免了CPU 应用占用GPU 节点的CPU 资源,但是也降低了GPU 节点的利用率。由图3 可以看出,分开调度可以正确调度同一种资源的应用到对应的节点。虽然GPU 应用全部被正确调度,但是GPU 节点的CPU 资源没有被充分利用,因此有部分CPU 型pod 处于pending 状态,从而造成CPU 资源的浪费。
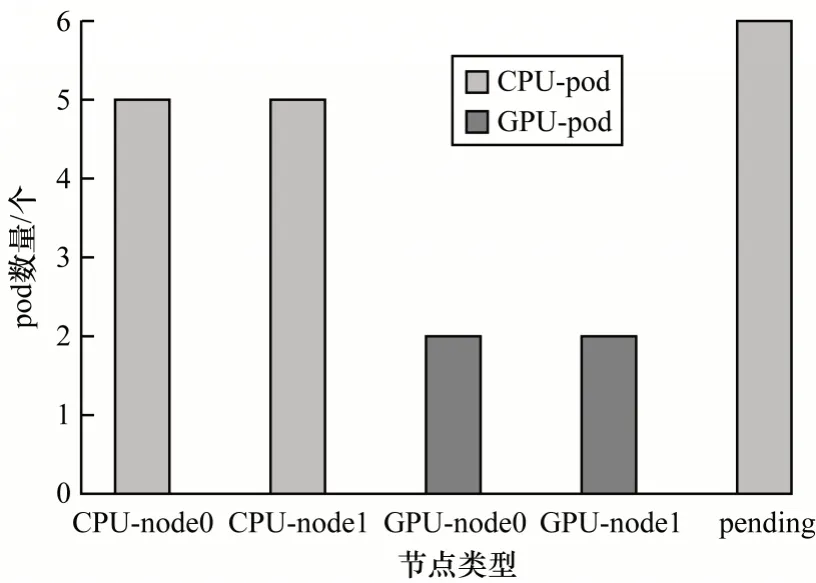
图3 CPU/GPU 独立部署下默认调度器实验结果Fig.3 Default scheduler experimental results under CPU/GPU independent deployment
图4 为CPU/GPU 混合部署下自定义调度器的实验结果,可以看出GPU 应用可以正确调度到GPU节点,而CPU 应用可以在CPU 节点资源不足的情况下被调度到GPU 节点,充分利用GPU 节点空闲的CPU 资源,没有pod 处于pending状态。
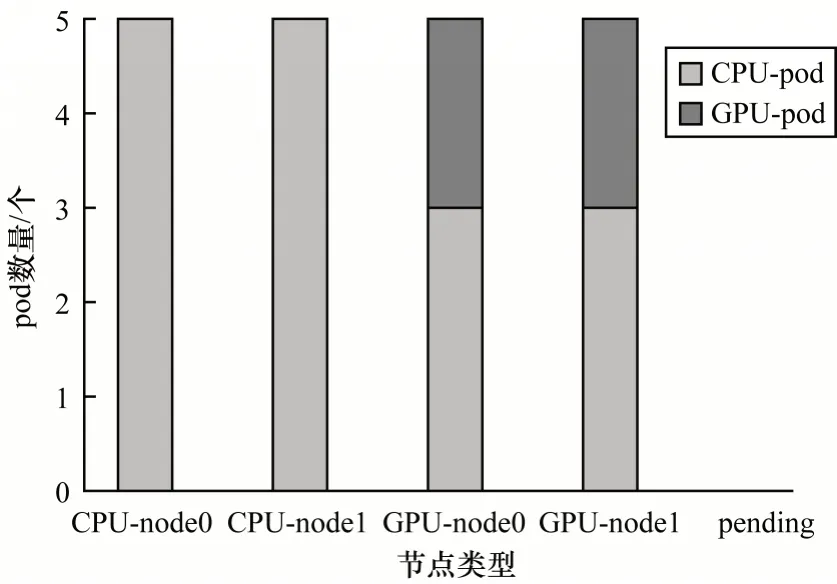
图4 CPU/GPU 混合部署下自定义调度器实验结果Fig.4 Custom scheduler experimental results under CPU/GPU hybrid deployment
在GPU 型pod 调度方面,对比图2 和图4,默认调度器将过多CPU 应用调度到GPU 节点,从而导致部分GPU 应用因为资源不足而处于pending 状态,而本文的自定义调度器可以感知GPU 应用和GPU 节点,从而充分利用GPU 资源,正确调度GPU 应用到合适的节点。在CPU型pod调度方面,对比图3和图4,在CPU和GPU节点分开部署的情况下,虽然GPU 应用得到了正确的调度,但是GPU 节点的CPU 资源没有被充分利用,导致部分的CPU 型pod 处于pending 状态,本文的自定义调度器可以充分利用GPU 节点上的空闲CPU 资源,从而提高集群资源的利用率。
3.2 细粒度调度结果
对于GPU 细粒度调度测试,准备测试应用test1、test2、test3、test4,测试GPU 型pod 的资源请求量如表3 所示,具体步骤为:1)使用默认调度器按顺序创建4 个pod 运行在Kubernetes 集群中;2)删除测试的pod,使用自定义调度器按照同样的顺序启动4 个测试pod,记录各个节点pod 的调度情况。
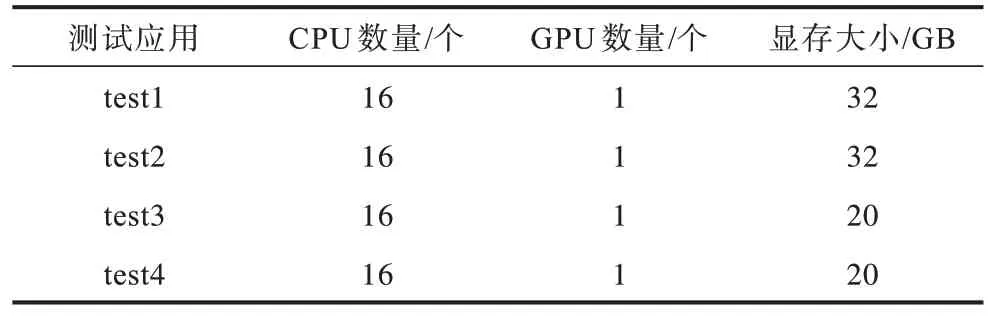
表3 GPU 型pod 资源请求量 Table 3 GPU-type pod resource requests
表4 为默认调度器调度细粒度GPU 型pod 的结果,其中√表示pod 调度到对应的节点。由表4 可以看出,默认调度器由于没有GPU 显存指标,因此无法根据显存大小进行细粒度调度,只能按照空闲卡数调度应用到对应的GPU 节点,导致部分节点GPU需要的显存大小与实际显存大小不匹配,当需要的显存容量大于实际显存容量时可能会出现计算任务失败的情况。
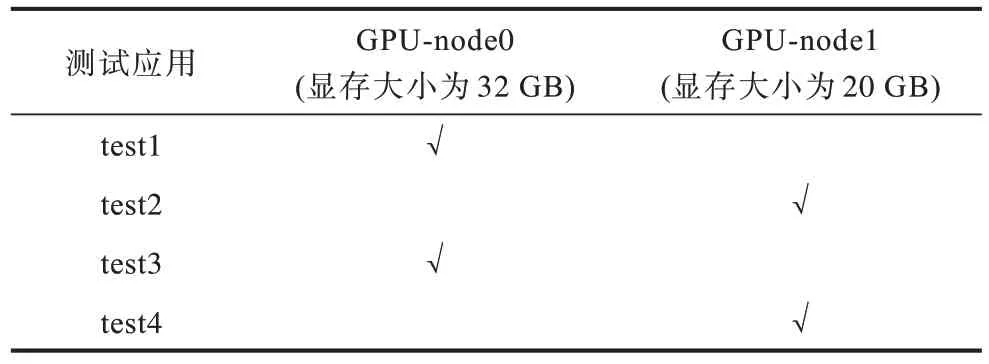
表4 默认调度器GPU 型pod 调度结果 Table 4 GPU-type pod scheduling results through the default scheduler
利用本文的自定义调度器可以综合考虑GPU数量和显存大小进行调度,最终得到调度结果如表5所示,可以看出集群使用了本文改进的自定义调度器后,GPU 应用可以根据显存正确地调度到对应的节点,从而验证了GPU 细粒度调度策略的有效性。
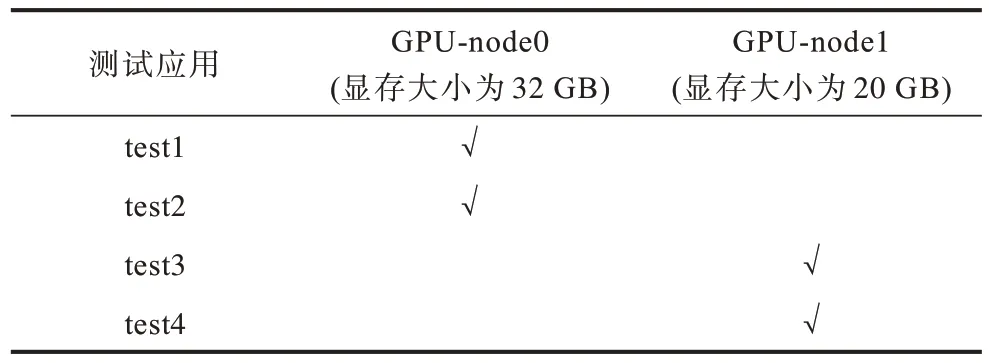
表5 自定义调度器GPU 型pod 调度结果 Table 5 GPU-type pod scheduling results through the custom scheduler
4 结束语
在异构资源混合部署的环境中,针对异构资源利用不均衡导致集群资源利用率降低的问题,本文提出一种基于Kubernetes 的异构资源混合调度策略。利用异构资源调度策略将CPU 型pod 和GPU 型pod 调度到合适的节点,并且在CPU 节点资源不足的情况下能够使用GPU 节点上的CPU 资源,提升集群资源利用率。通过与默认调度算法以及隔离CPU/GPU 集群的方法进行对比,结果表明本文改进的策略可以提升集群CPU 资源利用率,并将GPU 资源调度到合适的节点,满足用户对GPU 细粒度的需求。后续将研究基于用户历史数据的资源分配策略,进一步提升评估节点的实际使用率。
猜你喜欢
红外技术(2022年11期)2022-11-25
小学教学研究(2022年5期)2022-04-28
安阳工学院学报(2020年2期)2020-06-05
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
意林·少年版(2018年1期)2018-02-07
电脑知识与技术(2017年26期)2017-11-20
中国洗涤用品工业(2017年2期)2017-04-16
信息安全研究(2016年3期)2016-12-01
电信科学(2016年11期)2016-11-23
