
基于矫正理解的中文文本对抗样本生成方法
2023-02-20 09:38王春东孙嘉琪杨文军
计算机工程 2023年2期
王春东,孙嘉琪,杨文军
(1.天津理工大学 计算机科学与工程学院,天津 300384;2.计算机病毒防治技术国家工程实验室,天津 300384)
0 概述
近年来,自然语言处理(Natural Language Processing,NLP)技术在众多领域都取得了快速的发展和进步。然而,现有研究证明NLP 模型容易受到对抗样本的影响[1]。对抗样本是通过对测试数据添加不可察觉的扰动生成的,可以使目标模型以高置信度输出错误的分类结果[2-3]。目前,解决这一问题的有效方法是通过对抗训练提高自然语言处理模型的泛化性和鲁棒性[4],而对抗训练需要大量高质量的对抗样本数据[5]。因此,高质量、大批量地生成对抗样本具有重要意义。
在文本对抗样本的研究中,以英文文本为背景的研究已趋于完善,其中大部分方法通过改动单词中的字母来达到生成对抗样本的目的,例如单词内字母的插入、删除、互换位置及相似字符替换等。由于中文和英文隶属于不同的语系,文字构成最小单元不同(英文以字母为最小单元,中文以汉字为最小单元)[6],这就导致了上述英文文本对抗样本生成方法对于字母的改动无法直接应用在汉字上,直接影响了英文方法的可迁移性。
汉语是世界上使用人数最多的语言,中文自然语言处理系统在现实场景中应用广泛。由于缺乏中文文本对抗样本研究,因此这些系统正面临着巨大风险。中文文本对抗样本研究的缺乏主要有四方面的原因:第一,汉语句子结构不同于印欧语系(英语、德语、荷兰语等),英语的对抗样本生成方法很难直接迁移到汉语上;第二,中文关键词度量函数的通用性较差,这些度量函数将注意力更多地放在具有强烈情感倾向性的句子上;第三,汉字结构复杂,很难给汉字添加扰动,现有的汉字扰动策略,如汉字分割、繁体汉字替换和汉语拼音替换,欺骗性较弱,易于人眼识别;第四,生成的文本对抗样本需要在不影响人类阅读的基础上使NLP 分类错误。[6-7]因此,现有方法在这种条件下效果并不理想。为了解决上述问题,本文提出一种基于中文文本的可探测黑盒对抗样本生成方法WordIllusion,通过触发人类矫正理解,即一种由多个心理学现象共同作用的使人类可以忽略文本中特定错误而理解文本含义的现象,有效生成人类难以察觉的对抗样本。
1 相关工作
在众多文本对抗样本生成的研究中,基于英文文本的研究已经比较完善,PAPERNOT等[3]利用单词语义嵌入空间中距离相近的单词替换原始文本中随机选择的单词,但这些距离相近的单词很可能只是词性相似但表示的含义有很大差异,引入这些词汇将会颠覆原始文本语义,同时对随机选出的词语进行攻击的效率很低。针对攻击效率低下的问题,LIANG等[7]通过单词向量梯度计算方法确定关键词位置,然后利用关键词的错拼词作为替换生成对抗样本。这种方法很大程度上提升了文本对抗样本的攻击效率。在实际应用场景中,攻击者通常无法访问目标模型中白盒攻击方法所用到的参数,所以上述白盒攻击方法很难为真实场景中的对抗样本攻击提供实质性帮助。GAO等[8]和LI等[9]分别提出DeepWordBug 方法和TextBugger 方法,两种方法均设计了基于英文文本的关键词筛选策略和对抗样本生成策略。JIN等[10]提出TextFooler,该方法首先利用余弦相似度选择字典中的n个相近词并将其作为替换候选词,然后利用POS 检测和语义检测对候选词进行评估,最后使用可以成功改变分类结果或者使分类置信度降低最多的词作为最佳替换词。ZHANG等[11]提出Argot 方法,通过设计物种替换策略生成对抗样本。但这两种方法的限制过于严格,无法大规模生成对抗样本。
汉语作为联合国6 种官方语言之一,在文本对抗样本领域拥有着很高的研究价值。汉字具有独特的结构以及造字方法,致使中文在数据处理方面比英文文本更加离散。这也是中文文本对抗样本领域目前取得研究成果较少的主要原因之一。王文琦等[12]提出WordHandling 方法。该方法针对中文文本生成对抗样本,对具有倾向性的词汇设计了关键词度量函数,并使用同音字库作为替换空间。但是,该方法的替换策略较为单一,没有充分利用汉字的特点。NUO等[13]提出WordChange 方法。该方法使用3 种中文关键字修改策略,包括汉字交换(CCE)、字符插入(CI)、汉字拆分和替换(CCSR)。这些策略利用了汉字的独特结构,通过引入与原句语义不相关的汉字进而干扰模型分类。此外,汉字还具有简体字可映射成汉语拼音和繁体字的特性。基于该特性,仝鑫等[14]提出CWordAttack 方法。该方法利用汉语拼音、繁体字以及其他字符替换原句中的关键词,但很大程度上影响了人类的正常阅读理解。同时,上述中文文本对抗样本方法仅将TextCNN 和LSTM 作为靶机模型测试其他方法的效果。随着近些年文本分类模型数量的激增,这些方法对于新兴文本分类模型的有效性不得而知,因此探索具有强泛化性的对抗样本生成方法显得尤为重要,其在评估和提升模型鲁棒性的过程中可起到关键作用。
2 对抗样本生成方法
2.1 矫正理解
在研究人类阅读习惯的过程中发现一个有趣的现象,即将中文文本中一些汉字替换成对应的特定汉字,并不会对人类理解文本含义造成影响。从心理学角度出发,找到了这种现象的心理学解释,它是由多个心理学效应共同作用产生的。人们由于存在确认偏差[15],因此在阅读时产生阅读惯性[16],从而忽略了文中的一些替换字,但仍能获取文本真实含义,即使后来发现了替换字的存在也会由于现状偏见[17]认为自己已经理解了文本含义而不会改变对句意的判断,这种现象被称为矫正理解。汉字作为一种复脑文字[18],字形和字音共同作用向人类传达信息,因此利用同音字和字形相似的字替换原文可使人类获取足够其根据先验信念做出结论的信息,并忽略这些替换字。
2.2 基于中文文本的可探测黑盒对抗样本生成方法
WordIllusion 方法整体架构如图1 所示,包含数据处理与计算、关键词替换两个模块。首先,将数据输入数据处理与计算模块,在删除标点符号后将数据输入深度学习模型得到模型计算出的分类置信度,再将分类置信度输入CKSFM 计算函数,通过计算比较cksf 值选出句子中的关键词。然后,将关键词输入关键词替换模块,在这个模块中利用字形嵌入空间和同音字库中的相似词语替换关键词并构建对抗样本候选序列,再将其重新输入数据处理与计算模块计算cksf值。最后,选择一个cksf 值最高的数据作为最终生成的对抗样本。

图1 WordIllusion 方法整体架构Fig.1 Overall architecture of WordIllusion method
为了便于区分,在图1中,输入模型或方法的数据流用实线表示,输出模型或方法的数据流用虚线表示。基于中文文本的可探测黑盒对抗样本生成方法的具体步骤如下:
步骤1关键词筛选。给定一个句子X={x1,x2,…,xn},其中只有一部分词能影响到文本分类模型的分类结果。因此,本文设计一个评分函数CKSFM,以此衡量单词x∈X对文本分类结果F(x)=Y的影响程度。CKSFM 中cksf 值的计算如式(1)所示:

其中:Yorigin代表原标签的分类置信度;Yother代表其他标签的分类置信度。同理,在向原始文本添加扰动后,Y′origin代表原标签的分类置信度,Y′other代表其他标签的分类置信度。在计算过程中将k设为标签数,选择使分类模型分类置信度变化最大的词作为关键词。当两个关键词对分类置信度的改变量相同时,选择对其他标签的分类置信度的累加改变量影响更大的词作为关键词。输入数据示例的cksf 曲线如图2 所示。

图2 输入数据的cksf 曲线Fig.2 cksf curve of input data
步骤2关键词替换。在步骤1 筛选出关键词后,利用可以触发人类矫正理解的词汇(字形和字音与关键词相似的汉字)对其进行替换。
针对字形相似汉字,借鉴一种新的汉字表征方法[19],利用常用简体字及与其对应的繁体字构建嵌入式空间,并从中选择与关键词相似的汉字。针对字音相似汉字,利用pypinyin(https://pypi.org/project/pypinyin/)库将关键词转换成对应的同音字。原始汉字及其替换汉字示例如图3 所示。

图3 原始汉字及其替换汉字示例Fig.3 Examples of the original Chinese characters and their replacements
具体而言:首先,找到中文字形嵌入空间中最接近关键字的前m个单词,并生成字形替换序列Xgly;然后,在同音字库中找到在读音上与关键字相同的前l个词,并生成同音字替换序列Xhom;最后,将这两个序列组合起来生成候选词序列Xcan。
步骤3最终对抗样本确定。首先,使用步骤2 生成的候选词序列中的词来替换原始句子中的关键字,并生成对抗样本候选序列;然后,再次使用式(1)计算每个句子的cksf值,并将具有最高cksf 值的句子作为最终生成的对抗样本。
算法1WordIllusion 算法
输入 文本数据X={x1,x2,…,xn},对应的正确标签Y,靶机模型F,超参数m和l,中文字形嵌入空间Xgly={xgly1,xgly2,…,xglym},同音字字典Xhom={xhom1,xhom2,…,xhoml}
输出对抗样本Xadv
1)根据式(1)计算X中每个汉字的cksf值。
2)将cksf 值最大的字作为关键字。
3)在中文字形嵌入空间Xgly={xgly1,xgly2,…,xglym}中搜索与关键字字形相似的m个汉字。
4)用搜索到的汉字替换原句中的关键字并生成新的句子,组成字形候选序列。
5)在同音字字典Xhom={xhom1,xhom2,…,xhoml}中搜索与关键字同音的l个汉字。
6)用搜索到的汉字替换原句中的关键字并生成新的句子,组成字音候选序列。
7)将字形候选序列与字音候选序列合并,生成替换候选序列。
8)根据式(1)计算替换候选序列中每条文本的cksf 值并记作rresi。
9)取rresi值最大的数据作为输出的对抗样本。
3 实验评估
3.1 实验设置
实验分为横向实验和纵向实验。横向实验旨在探究数据集特征、目标模型和攻击方法对攻击有效性的影响,分为新闻分类和情感分析2 个任务,每个任务有TextRNN[20]、TextCNN[21]、TextRCNN[22]、DPCNN[23]和Transformer[24]等5 种目标模型,其中前4 种模型相比于Transformer模型提出时间更早,结构更简单,因此将其统称为传统模型。将WordIllusion方法与CWordAttack、WordHandling 这2 种基线攻击方法进行比较,攻击成功率越高意味着攻击方法越有效。
设置纵向实验的目的在于探究不同扰动率对生成的对抗样本的效用影响。选择平均长度为20 个字的2 000 条数据,并将最大修改范围设置为30%。在相同的实验环境中测试了WordHandling、CWordAttack 和WordIllusion 方法,并比较了不同扰动率下的攻击成功率(Attack Success Rate,ASR)。
3.2 数据集和实验环境
选择THUCNews 和Meituan 作为实验数据集。THUCNews 基于新浪新闻历史数据生成,包括金融、房地产、股票、教育、科技、社会、时事、体育、游戏、娱乐等10 个候选类别。Meituan 基于美团外卖的在线评论,包括正面和负面2 个分类。本文基于AMD Ryzen7 5800H 3.20 Hz CPU、16 GB RAM 和RTX 3060 GPU实现WordIllusion方法。
3.3 评价指标
3.3.1 攻击成功率
为了验证本文WordIllusion 方法的有效性,计算实验样本中的攻击成功率并将其作为实验评价指标。随机抽取2 000 个生成的对抗样本,并将它们放回文本分类模型中。对于每个数据,当分类结果与原始标签不同时,记录为攻击成功。将攻击成功次数记录为Ns,攻击总数记录为Nt。攻击成功率为成功次数与攻击总数之比,计算公式如下:

3.3.2 音形码相似度
为了衡量生成的对抗样本的质量,引入音形码相似度(Sound Shape Code Similarity,SSCS)[25]。音形码是1 种对汉字进行编码的方法,将汉字转换为10 个字母数字序列,如图4 所示。该序列包含声母、韵母、声调、结构、四角编码、笔画数等信息,在一定程度上描述了汉字的读音和字形特征。
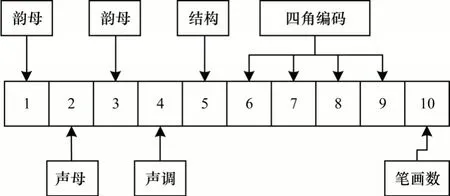
图4 音形码结构Fig.4 Structure of sound shape code
音形码相似度将每个汉字的音形码的前4 位和后6 位数字分开,并在字音和字形2 个维度上计算替换汉字和原始汉字之间的相似度,其中,利用前4 位音码计算汉字之间字音相似度SSoundCodeSimilarity,利用后6 位形码计算汉字之间字形相似度SShapeCodeSimilarity。
相似度越高意味着对抗样本的欺骗性越强,也意味着该对抗样本更可能触发人类的矫正理解。这证明了生成的对抗样本使人类可以忽略文本中特定错误而理解原文的含义。SSCS 的计算公式如下:

4 实验结果与分析
4.1 横向实验
通过横向实验比较在最小扰动攻击下WordIllusion和基线方法的攻击成功率,其中,THUCNews 数据集的平均扰动率为5.33%,Meituan 数据集的平均扰动率为7.08%,最小扰动为每个数据被一个文字替代。表1 和表2 给出了黑盒攻击下5 种模型在2 个文本分类任务中的攻击成功率,其中最优指标值用加粗字体标示。

表1 WordIllusion 和基线方法在THUCNews 数据集上针对不同模型的攻击成功率 Table 1 ASR of the WordIllusion and baseline methods for different models on the THUCNews dataset %

表2 WordIllusion 和基线方法在Meituan 数据集上针对不同模型的攻击成功率 Table 2 ASR of the WordIllusion and baseline methods for different models on the Meituan dataset %
由表1 和表2 可以看出:
1)WordIllusion 方法相比于基线方法对2 个文本分类任务中的5 种模型的攻击成功率均为最高,其中在THUCNews 数据 集的DPCNN 模型上,WordIllusion 方法的攻击成功率相比于CWordAttack 方法最多高出41.73 个百分点,验证了WordIllusion 方法的有效性与通用性。主要原因为:CWordAttack 方法通过引入英语字符和繁体汉字来攻击模型,而这些字符在文本分类模型预先训练的词嵌入空间中并不存在,因此文本分类模型将它们视为“陌生字符”,即模型不会从字符中提取特征,等价于从输入模型序列中删除了关键字;WordIllusion 方法从字形和字音两个维度找到替代词,相比于WordHandling 方法,扩展了替换空间,更容易找到有效关键词,并具有更高的攻击成功率。
2)WordIllusion 方法在情感分析任务中对于传统文本分类模型的平均攻击成功率比新闻分类中高4.68个百分点。主要原因为:Meituan 数据集包含了大量具有情感倾向性的词汇,使模型易于从此类词汇上提取分类特征并做出正确分类,但是它们也很容易被攻击方法锁定,导致目标模型的准确性显著下降。
3)对于在2 个文本分类任务中攻击Transformer模型,WordIllusion 方法在新闻分类任务中表现出了更好的性能,验证了WordIllusion 方法针对Transformer模型的攻击有效性。然而,WordIllusion 方法在情感分类任务中表现不佳,主要原因为Meituan 数据集相比于THUCNews 数据集规模较小,导致Transformer 模型训练不充分,攻击成功率降低。
WordIllusion 方法在THUCNews 数据集上生成的对抗样本与原始文本示例如下所示:
示例1
原始文本(标签:Science):中移动合并铁通后宽带业务将遭受非对称管制。
对抗样本(标签:Stocks):中栘动合并铁通后宽带业务将遭受非对称管制。
示例2
原始文本(标签:Science):美股周三小幅下跌,中国概念股涨跌互现。
对抗样本(标签:Society):美股周三小幅下跌,中国慨念股涨跌互现。
WordIllusion 方法在Meituan 数据集上生成的对抗样本与原始文本示例如下所示:
示例3
原始文本(标签:Negative):送来的辣椒粉都撒了!
对抗样本(标签:Positive):送来的辣椒粉都撤了!
示例4
原始文本(标签:Positive):酸辣粉很好吃,虽然没有给筷子。
对抗样本(标签:Negative):酸辣粉很妤吃,虽然没有给筷子。
4.2 纵向实验
纵向实验的目的在于研究扰动率对于攻击成功率的影响,结果如图5 所示。由图5 可以看出,WordIllusion 方法的性能在多数情况下优于其他方法。当扰动率达到20%时,WordIllusion 方法攻击成功率逐渐趋于平缓,与其他两种基线方法相比可以在更小的扰动空间中有效地攻击目标模型。对于相同的攻击成功率,WordIllusion 与其他两种基线方法相比具有更低的计算开销。但是,由图5(d)可以看出,随着扰动率的增加,CWordAttack 方法的攻击成功率超过了WordIllusion 方法,主要原因为CWordAttack 方法的攻击策略类似于从输入模型序列中删除关键字,扰动率的增加意味着原句保留的可用信息越来越少,使得Transformer 模型无法捕获汉字的相对位置信息[26],失去了解决远距离信息问题的能力,从而更容易受到攻击。
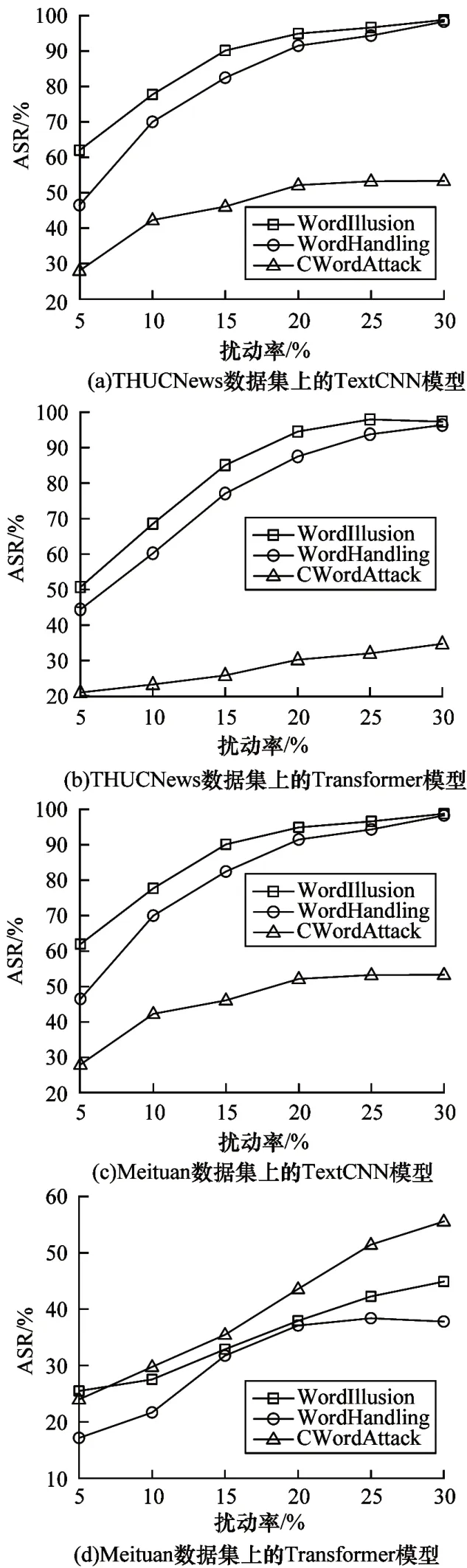
图5 扰动率对TextCNN 和Transformer 文本分类模型的攻击性能影响Fig.5 Impact of perturbation ratio on attack performance of the TextCNN and Transformer text classification models
4.3 效用分析
在SSCS 计算过程中,选择经典模型TextCNN 和较为先进的Transformer 模型,并在THUCNews 数据集上进行测试。实验随机选择50 组原始文本和对抗样本,计算原始汉字和替换汉字之间的SSCS,最后计算50 组原始文本和对抗样本的平均相似度并进行比较,如图6所示。由于CWordAttack 方法不使用汉字替换,无法计算SSCS,因此该实验仅计算WordIllusion 和WordHandling 方法之间的SSCS。由图6可以看出,WordIllusion方法生成的对抗样本与原始文本更相似。这意味着结合字形和字音考虑,WordIllusion 方法生成的对抗样本更有可能触发人类矫正理解,并使人们更容易保持对原始文本的预测。

图6 两种攻击方法在不同数据集上选择的替换汉字和原汉字之间的SSCSFig.6 SSCS between the replacement characters and the original characters selected by two attack methods on different datasets
4.4 消融实验
为了验证基于中文文本的可探测黑盒对抗样本生成过程中关键词筛选步骤的有效性,在该步骤上设计了消融实验,将其从整个过程中删除,并使用随机选择方法确定替换的汉字。应用TextCNN和Transformer作为目标模型,并在THUCNews 数据集上对其进行测试,同时保持关键词替换、最终对抗样本确定步骤和扰动率不变,测试结果如表3所示。由表3可以看出,在删除关键词筛选步骤并使用随机选择方法确定替换的汉字后,在两种测试模型上攻击成功率降低了20个百分点以上。这表明关键词筛选对于整个对抗样本生成过程的攻击成功率至关重要,它可以准确定位句子中对分类结果影响最大的词,选择这些词可以有效地减少冗余的扰动率,并且不降低攻击成功率。

表3 删除关键词筛选步骤前后的模型攻击成功率比较Table 3 Comparison of the ASR for the models before and after deleting keywords filtering step %
4.5 真实场景实验
随着机器学习技术的发展,机器学习模型通常部署在云服务器上,用户可以通过调用API 解决实际问题,然而这些计算服务时刻面临被攻击的风险。选择腾讯云中的文本分类服务作为测试对象,在真实场景中测试WordIllusion 方法的攻击性能。该文本分类服务基于数千亿大规模互联网语料库和深度神经网络模型(如LSTM 和BERT)进行训练,通过不断迭代和更新确保性能的持续改进。实验测试了新闻分类和情感分析功能:新闻分类API 包含14 种分类标签,分别为汽车、科学、健康、体育、旅游、教育、职业、文化、房地产、娱乐、女性、奥运、金融和其他,适用于一般场景;情感分析API 包含积极和消极2 种分类标签。图7 给出了腾讯云中的情感分析API,可以看出情绪分析API 返回积极和消极2 种分类标签,置信度之和等于1,置信度最高的类为输出结果。

图7 腾讯云API:深度学习分类平台实例(黑盒场景)Fig.7 Tencent Cloud API:an example of deep learning classification platform which is a black-box scenario
选择一些原始文本和通过各种方法生成的对抗样本,将它们分别输入腾讯云中的新闻分类API 和情感分析API,并记录分类结果,具体步骤如下:
1)计算不同攻击方法生成的对抗样本的平均攻击成功率,结果如表4所示,可以看出,WordIllusion方法生成的对抗样本的攻击成功率达到70.95%和71.43%,其他两种方法的攻击成功率均低于WordIllusion方法。实验结果验证了WordIllusion方法在真实场景中的有效性。

表4 针对腾讯云API 的3 种对抗样本的攻击成功率 Table 4 ASR of three kinds of adversarial examples for Tencent Cloud API %
2)攻击方法虽然对本文分类模型的分类结果影响较小,但仍可以降低模型分类置信度,因此计算置信度变化并进行统计,如图8 所示。由图8可以看出,不同攻击方法生成的对抗样本对于文本分类模型的总体置信度趋于下降,其中WordIllusion 方法生成的对抗样本使模型分类置信度下降幅度更大,从而验证了WordIllusion 方法的有效性。

图8 3种对抗样本生成方法攻击API时的模型分类置信度变化Fig.8 Change of the model classification confidence of three kinds of adversarial example generation methods against the APIs
5 结束语
本文提出一种基于中文文本的对抗样本生成方法WordIllusion,使用音形码相似度来确保对抗样本与原始样本充分相似,通过对深度学习模型实施黑盒攻击导致模型错误分类。实验结果表明,WordIllusion 方法对深度学习模型的分类准确度有较大影响,但对原始中文文本的修改仅为输入数据长度的5%~7%,从而验证了WordIllusion 方法的强欺骗性和泛化性。后续将确定不同中文文本的最优扰动率,并分析最优扰动率下的对抗样本攻击成功率,进一步提升定向攻击中的攻击成功率。
猜你喜欢
当代水产(2022年6期)2022-06-29
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
中国生殖健康(2020年8期)2021-01-18
中国生殖健康(2018年3期)2018-11-06
计算机应用(2018年5期)2018-07-25
小学阅读指南·低年级版(2017年4期)2017-04-24
小学阅读指南·低年级版(2017年1期)2017-03-13
轴承(2015年2期)2015-07-25
海峡姐妹(2015年5期)2015-02-27
