
人脸微表情分析方法综述
2023-02-20 09:38于明钟元想王岩
计算机工程 2023年2期
于明,钟元想,王岩
(1.河北工业大学 人工智能与数据科学学院,天津 300401;2.天津商业大学 信息工程学院,天津 300134)
0 概述
面部表情、肢体语言、语音等能够反映人类的真实情感,其中,面部表情是人类情感的重要表达方式之一。很多学者利用计算机视觉技术对面部表情进行分析,进而将其应用到医疗服务[1]、学生课堂质量检测[2]、测谎[3]等人机交互系统中。
面部表情分为宏表情和微表情。宏表情是主动发生的,可以伪造,有着较大的运动幅度。微表情持续时间较短,运动幅度较小,是下意识发生的,表示一个人在尝试抑制真实情感时的一种情感泄露,其可以揭示人类的真实情感,因此,分析微表情能够发现潜在的心理活动。
2003年,EKMAN 开发了微表情培训工具(Micro-Expression Training Tool,METT),利用该工具可以进行微表情识别[4]。然而,这种方式耗费时间过长,且只能取得50%左右的准确率。因此,众多学者尝试开发基于计算机视觉技术的微表情自动分析系统。在研究初期,主要采用结合机器学习的多阶段训练方式,先提取具有判别性的微表情运动特征,再训练一个可靠的分类器。芬兰奥卢大学的赵国英研究团队[5-7]采用局部二值模式(Local Binary Pattern,LBP)以及扩展算法捕捉面部纹理信息。中国科学院心理所的王甦菁团队提出主方向平均光流(Main Directional Mean Optical-flow,MDMO)[8]、张量独立的颜色空间[9]等方法;山东大学的贲睍烨团队针对高维张量数据不易提取判别信息的问题,研发基于张量的最大边缘投影用于微表情识别[10]。
随着卷积神经网络(Convolutional Neural Networks,CNN)在各个领域的广泛应用,许多研究人员将CNN与长短期记忆(Long Short-Term Memory,LSTM)网络相结合,研发端到端的微表情分析系统。KHOR等[11]将CNN 与LSTM 相结合提取微表情时空特征,但是该方法先提取空间特征再提取时序特征。LO 等[12]采用3DCNN 网络表达空间信息与时间信息之间的关系。近年来,Transformer 因其能够发现图像全局依赖关系而在相关领域取得了良好表现,ZHOU等[13]尝试利用Transformer 的这一优势,挖掘微表情面部全局运动关联。
微表情分析包括检测和识别两个部分。微表情检测是在微表情视频中判断是否存在微表情并定位时间位置。微表情识别是对存在微表情的图像或视频进行分类。本文分析微表情数据集和面部图像序列预处理方法,总结近年来微表情检测和微表情识别方面的研究成果。首先分析基于传统机器学习和基于深度学习的微表情检测方法,其中,将机器学习方法细分为基于时间特征和基于特征变化的方法;然后比较基于纹理特征、基于光流特征和基于深度学习的微表情识别方法,在深度学习微表情识别方法中,从面部区域运动、关键帧、样本量等角度进行区分;最后通过多个实验指标比较各类方法的特点,并对该领域未来的发展方向进行展望。
1 微表情数据集
微表情分析技术的发展依赖于完善的数据集,现有微表情数据集可分为两类:一类是非自发的微表情数据集,包括美国南佛罗里达大学创建的 USFHD[14]、日本筑波大学创建的 Polikovsky 数据集[15];另一类是自发的微表情数据集,包括芬兰奥卢大学创建的SMIC[16],中国科学院创建的 CASME[17]、CASMEII[18]、CAS(ME)2[19]、CAS(ME)3[20],英国曼彻斯特城市大学创建的SAMM[21],山东大学创建的MMEW[22],加拿大PORTER 团队创建的York DDT[23]。表1 对上述数据集进行分析与归纳,其中,FACS(Facial Action Coding System)表示面部动作编码系统。

表1 微表情数据集 Table 1 Micro-expression datasets
在上述数据集中,USF-HD、Polikovsky 和York DDT 并未公开。USF-HD 中的受试者被要求同时表现宏表情和微表情,主要用于区分宏表情和微表情。Polikovsky 中的受试者被要求模拟微表情动作,主要用于分析微表情所处阶段。York DDT 由自发微表情组成,主要用于测谎。
经典的自发微表情数据集有SMIC、CASME、CASMEII、SAMM、CAS(ME)2和MMEW。SMIC 有HS、VIS 和NIR 这3 个子集,分别用不同类型的摄像机捕捉微表情,受试者由8 个高加索人和8 个亚洲人组成,一共有164 个微表情片段,包含3 个微表情类别。CASME、CASMEII 和CAS(ME)2采用相同的实验方案。CASMEII 是CASME 的扩展版本,分别有247 和195 个样本:CASMEII 的分辨率为280×340 像素,有5 类微表情;CASME的分辨率为150×190 像素,有8 类微表情。CAS(ME)2收集宏表情和微表情的数据,微表情分为4类,判定该数据集中表情持续时间小于0.5 s 的是微表情,否则为宏表情。SAMM包含159 个样本,这些样本由高速摄像机进行记录,分辨率为2 040×1 088 像素,有7 个微表情类别。MMEW 包含300 个样本,有7 个微表情类别,该数据集中每个样本都由专家标定起始帧、顶点帧和终止帧,同时提供AU 标注,分辨率为1 920×1 080 像素,相比于其他数据集具有更详细的情感分类。
考虑到深度信息对视觉感知的影响,CAS(ME)3对深度信息进行采集,可以更加敏锐地捕捉人脸信息的变化,该数据集包含7个微表情类别,分为Part A、Part B、Part C 三部分,Part A 和Part B 采用观看视频时保持中性表情的方式诱导微表情,Part A 中包含943 个有标签微表情样本,Part B 中包含1 508 个无标签样本,Part C中包含166 个样本,其采用模拟犯罪的诱发范式诱导微表情,得到了高生态效度的数据集,为在真实环境中进行微表情分析提供了基础。
数据集中的评估方式包括单一数据集验证方法和跨数据集验证方法。在单一数据集验证方法中,采用留一法、留一视频法和k 折交叉验证法将微表情数据集划分为训练集和测试集。在跨数据集验证方法中,采用复合数据集验证法和保留数据集验证法,其中,复合数据集验证法将多个数据集进行合并再利用留一法划分训练集和测试集,保留数据集验证法将一个数据集作为训练集,另外一个数据集作为测试集。
通常采用的实验指标包括准确率、精确率、未加权F1 分数、加权F1 分数、未加权平均召回率和加权平均召回率。
2 面部图像序列预处理
原始图像序列是在一定的环境背景下拍摄而成的,不可避免地存在噪声,对图像序列进行预处理,消除无关信息,保留面部关键信息,有利于特征提取和微表情分类。预处理的关键技术主要包括人脸检测、人脸裁剪和对齐、帧归一化、面部图像分块。
人脸检测方法有基于方向梯度直方图(Histogram of Oriented Gridients,HOG)特征的人脸检测法[24]、基于特征金字塔网络的方法[25]等;人脸裁剪和对齐方法有活动形状模型(Active Shape Models,ASM)[26]、约束局部模型(Constraint Local Model,CLM)[27]等;帧归一化方法有时域插值模型等;面部图像分块方法有象限分割、网格分割、德劳奈三角测量、基于FACS 的分割等[28]。
3 微表情检测
微表情检测的目标是判断视频中是否存在微表情,若存在,则对微表情进行定位,找到微表情起始点、顶点、终止点。起始点是微表情运动的开始,顶点是微表情肌肉运动幅度达到最大值的时间点,终止点是微表情结束的时间点。微表情序列检测方法可以分为基于传统机器学习特征的检测方法和基于深度特征的检测方法两类。表2和表3分别对两种检测方法进行总结。

表2 基于传统机器学习特征的微表情检测方法 Table 2 Micro-expression detection methods based on traditional machine learning features

表3 基于深度特征的微表情检测方法 Table 3 Micro-expression detection methods based on depth features
3.1 基于传统机器学习特征的检测方法
在基于传统机器学习特征的检测方法中,一类方法在时间维度上检测微表情,另一类方法通过计算特征变化来检测微表情。
3.1.1 基于时间特征的微表情检测方法
SHREVE等[14,29]利用中心差分法计算下巴、嘴、脸颊、前额这些区域的光流场,得到面部产生的运动强度,以此来检测微表情。该方法可以判断视频序列中是否存在微表情,但是需要通过人工设定阈值,在训练数据较少的情况下,无法保证所选择阈值的可靠性。对应区域点的运动向量可以用u=[u,v]T表示,有限应变张量ε可以用式(1)表示:

其中:u、v表示每个点的运动向量;εxx和εyy表示法向应变分量;εxy和εyx表示切向应变分量。
PATEL等[30]利用运动特征获取方向连续性进行微表情检测,先将判别响应图拟合模型[17]结合FACS定位人脸关键点,并将关键点分为多个区域,再计算每个区域的平均运动,最后通过累加每个区域的运动幅值找到相应区域的运动顶点。通过计算平均运动并设定阈值,减少头部运动、眨眼等动作对微表情检测的影响。然而,不同区域之间存在隐藏关联,该方法仅依靠单一区域检测微表情,无法充分体现微表情的区域运动关联。
MA等[31]统计运动单元发生的区域,接着根据运动出现的频率选择感兴趣区域(Regions of Interest,ROI),最后提取光流场,计算定向光流直方图(Histogram of Oriented Optical Flow,HOOF),自动识别顶点帧。该方法可以有效提高顶点帧检测的准确性,但其忽视了角度信息。GUO等[32]提出结合幅值与角度的光流特征提取方法,选择眼睑、眉毛、嘴角鼻子两侧这4 个ROI 提取光流向量,获取可靠的运动信息,每一帧的光流幅值Ai计算如式(2)所示,光流角度信息θi使用反三角函数进行计算,如式(3)所示:

其中:i表示当前帧数;pi表示水平分量;ri表示垂直分量。
WANG[33]使用光流在主方向最大差异(Main Directional Maximal Difference,MDMD)进行微表情定位,获得了更加可靠的运动特征。在输入的视频序列中,设定当前帧为Fi,Fi的前k帧为Fi-k,Fi的后k帧为Fi+k。将面部分为不同的区域,计算Fi-k帧与Fi帧、Fi-k帧与Fi+k帧的鲁棒局部光流,将光流矢量个数最多的方向定义为主方向,并根据主方向计算所有区域中的差值并进行降序排列,选择前1/3作为Fi帧的特征,最后根据运动方向检测微表情,检测过程如图1 所示。MDMD 虽然在检测长视频中的微表情时能够取得很好的效果,但是不易选择合适的k值,k值过大,对光流的计算会有影响,k值过小,则主方向上的差异也会很小,另外,该方法只能检测单一帧的面部运动。在MDMD 方法的基础上,HE 等[34]增加一个后处理步骤,将原先输出帧的相邻帧都视为微表情,形成一个间隔,但是该方法同样需要手动设置参数。为了消除头部摆动造成的影响,ZHANG等[35]从鼻子区域提取平均光流和局部运动矢量检测微表情,此外还采用多尺度滤波器提高微表情检测性能。HE等[36]选取14 个ROI 捕获细微面部运动,引入密集光流来估计ROI 的局部运动,结合时域变化曲线的峰值检测方法精确定位运动间隔。

图1 MDMD 方法检测流程Fig.1 Detection procedure of MDMD method
3.1.2 基于特征变化的微表情检测方法
POLIKOVSKY等[15,37]将人脸图像划分为12 个ROI 区域,计算区域中的HOG 特征,通过k-means 算法判断面部肌肉运动幅度的变化区间。该方法设计简洁,但是不适用于自发的微表情。DAVISON等[38]使用HOG 特征关注人脸运动,但是没有充分利用角度信息。
MOILANEN等[5]将人脸图像分割为36 个区域,计算每个区域的LBP 直方图特征,观察相同的区域中序列帧的特征变化情况。此外,为了观察当前帧在图像序列中的变化强度,计算与当前帧间隔k帧的前后两帧的特征平均值,最后得到当前帧与平均值的卡方距离。XIA[39]基于ASM 和尺度不变特征变换描述符提取人脸关键点,接着使用Procrustes 分析方法将关键点进行对齐,消除头部运动和光照变化对微表情的影响。此外,采用随机漫步模型计算帧间的变形相关性,获取转移概率。最后,设定阈值进行微表情检测。LI等[40]利用Kanade-Lucas-Tomasi算法跟踪图像序列中的3 个点,分别为2 个内眼角和1 个鼻脊点,根据3 个点对图像序列进行校正,接着将人脸图像分为36 个图像区域,计算每个区域中的LBP 特征和HOOF 特征,以此计算每帧的特征差分值,最后根据设定的阈值检测微表情的起始点、顶点、终止点。虽然文献[5,39-40]方法均能取得较好的实验结果,但是不易确定可靠的阈值或参数,在实际应用中有很多不确定性。
YAN等[41]、LIONG等[42]和HAN等[43]分别提出定位微表情顶点的方法。文献[41]方法使用CLM 定位人脸关键点,计算图像序列与第一帧的相关性,最后根据峰值定位顶点帧。文献[42]方法根据运动单元和人脸关键点对人脸区域进行划分,然后采用LBP、CLM、光学应变(Optical Strain,OS)提取特征,最后根据二叉搜索策略定位顶点帧。上述两种方法不需要人工设定阈值,但是只能定位顶点帧。文献[43]提出协同特征差异算法,利用LBP特征和MDMO特征作为互补特征,将人脸划分为ROI 区域,并给不同的区域分配不同的权重,从而突出关键区域,最后计算区域的特征差以定位顶点帧。
基于机器学习的微表情检测方法能够有效提取更多的面部运动变化细节信息,基于特征变化的方法大多依赖于设定的最佳上下限阈值,上限阈值能够区分宏微表情,下限阈值能够定义微表情的最小运动振幅,但是阈值的设定具有不可靠性,面部眨眼等噪声动作也会对阈值判定造成影响。基于时间特征的方法计算复杂度高,无法满足实时检测的需求。
3.2 基于深度特征的微表情检测方法
ZHANG等[44]首次将深度学习方法用于微表情检测,利用顶点帧的相邻帧扩充数据集,然后使用SMEConvNet 网络提取特征,最后使用滑动窗口对特征矩阵进行处理,从而定位顶点帧。相较传统机器学习方法,其检测效果得到提升,但是只能检测顶点帧。TRAN等[45]提出基于深度序列模型的微表情检测方法,采用机器学习方法提取视频序列中每个位置的时空特征,接着使用LSTM 网络预测顶点帧,其改善了由帧间距离导致的网络鲁棒性差问题。DING等[46]利用滑动窗口将微表情长视频片段分割成几个短视频,将光流与LSTM 相结合,通过改进的低复杂度的光流算法提取特征曲线,接着使用LSTM 预测微表情的发生,从而达到实时检测微表情的目的,但是该方法在划分短视频时采用固定大小的滑动窗口,不能很好地反映滑动窗口生成的候选片段属于微表情的程度,导致起始帧和终止帧出现定位不准确的情况。
为了解决低强度微表情对微表情定位的影响,PAN等[47]提出一种局部双线性卷积神经网络,将微表情定位问题转变为细粒度图像分类问题,使用MDMD 获取面部局部区域,分别为左眉毛、右眉毛、鼻子和嘴,再将人脸图像和这4 个区域输入到网络中,分别获取全局特征和局部特征,最后融合全局特征和局部特征进行微表情检测。该方法可以捕捉微表情细微的运动,但是只能检测单帧图片。同样地,LIONG等[48]提出的多流浅层网络也只能检测单帧微表情。WANG等[49]提出微表情定位网络(Micro-Expression Spotting Network,MESNet),用于在长视频中定位微表情序列,其网络结构如图2 所示。首先使用二维卷积网络提取空间特征,接着使用一维卷积提取时间特征,根据剪辑建议网络找出微表情序列的时间位置,最后通过分类网络判定剪辑的视频是否属于微表情。该方法具有较好的检测效果,但是模型包含了时空卷积网络模块、剪辑模块和分类回归模块,庞大的参数量导致网络效率较低,无法达到实时检测的效果。

图2 MESNet 网络结构Fig.2 MESNet network structure
与文献 [48]方法和文献 [49]方法不同,XUE等[50]提出两阶段的微表情定位网络,将顶点帧定位和微表情间隔相结合,将光流的水平分量、垂直分量以及光学应变输入到第一阶段的三流注意力网络中,提取时空特征,定位顶点帧。TAKALKAR等[51]将双重注意力网络与二维卷积网络相结合,提出一种基于双重注意网络结构,使用局部注意力模块关注特定区域,同时构建全局注意力模块关注全局面部运动信息,模型在具有较高检测效率的同时取得了较好的鲁棒性。为了降低眨眼和光照的影响,GUPTA[52]将改进的特征编码与多尺度滤波器卷积网络相结合,增加眉毛区域时间变形的可信度,同时也更好地探索序列之间的时序关联,提高了网络效率。但是,该方法依赖精准的预处理方法对眉毛和嘴巴进行对齐和定位,需要更多的预处理时间。ZHOU等[13]提出一种基于双向Transformer 的微表情检测网络,首先利用候选片段生成模块生成候选段,接着由时空特征提取模块将候选段划分为更小的时隙,最后通过分组模块合并片段,定位微表情的起始帧和顶点帧。该方法很好地利用了时序信息,关注了帧间的相关性。
基于深度学习的微表情检测方法相较于机器学习方法,具有更高的检测效率,但是存在耗时、不稳定等问题。由于微表情检测模型需要提供判别模型以及剪辑模型,存在庞大的计算量,计算复杂度随之上升,在部分小型网络中,通常采用滤波器过滤峰值曲线,但是滤波器的不稳定性会给检测结果造成影响。
4 微表情识别方法
微表情识别是指对检测到的微表情进行识别并分类,根据特征提取的方式可以将微表情识别方法分为基于手工机器学习特征的识别方法和基于深度学习特征的识别方法。
4.1 基于手工机器学习特征的识别方法
基于手工机器学习特征的识别方法又可以分为基于纹理特征和基于光流特征的识别方法。
4.1.1 基于纹理特征的识别方法
微表情包含大量有效的时序信息,PFISTER等[53]为了发现微表情中的运动时空关系,利用三维正交平面的局部二值模式(Local Binary Pattern from Three Orthogonal Planes,LBP-TOP)提取特征,其微表情识别流程如图3 所示。

图3 LBP-TOP 微表情识别流程Fig.3 Micro-expression recognition procedure of LBP-TOP
LBP-TOP在XY、XT、YT这3个正交平面上提取LBP特征,并将得到的结果进行拼接作为最终的LBP-TOP特征,该方法能够有效捕捉时域信息,但是需要计算3个平面的特征,其特征维度高,只考虑2 个像素之间的特征差异,未考虑其他有用信息。为了解决该问题,WANG等[54]使用中心点上3条相交线的六交点减少冗余信息,提出六交点局部二值模式(Local Binary Pattern with Six Intersection Points,LBP-SIP)算法,该算法可以减少很多冗余信息,且计算速度快,但是其存在鲁棒性差的问题。HUANG等[6]为了能够捕捉水平和垂直积分投影的外观和运动变化,提出积分投影时空局部二值模式(Spatio-Temporal Local Binary Pattern with Integral Projection,STLBP-IP)算法,该算法能够有效保留人脸图像的形状特征,所采用的积分投影能够更好地发现同类情绪的统计分布,但是其只关注类内信息的相似性,忽视了样本间的判别信息。之后,HUANG等[7]提出时空完全局部量化模式(Spatio-Temporal Completed Local Quantized Patterns,STCLQP)算法,该算法利用3 种有用的信息,包括基于符号、基于大小和基于方向的像素差,同时设计一种时空域的码本,在码本的基础上提取时空特征,这使得局部模式更具判别性。
融合纹理和形状信息进行识别的效果优于仅使用外观信息进行识别,为此,HUANG等[55]提出判别性时空局部二值模式算子(Discriminative Spatio-Temporal Local Binary Pattern with Revisited Integral Projection,DISTLBP-RIP)方法,以用于微表情识别,该方法将形状属性与动态纹理信息相结合,获得更具判别性的特征。当微表情发生时,面部肌肉在斜方向上会发生偏移,但LBP-TOP 只能捕捉水平和垂直方向上的信息,因此,WEI 等[56]提出五相交局部二值模式(Local Binary Pattern from Five Intersecting Planes,LBP-FIP)方法,先提取在偏离X或Y方向45°的斜方向上8 个顶点的LBP特征,获得八顶点局部二值模式特征(Eight Vertices Local Binary Pattern features,EVLBP),然后与LBPTOP 提取的水平和垂直方向上的特征进行级联。
HOG 特征可以表示图像的纹理信息,LI等[40]利用HOG 及其扩展算法作为特征描述符,提取面部结构信息,引入图像梯度直方图(Histograms of Image Gradient Orientation,HIGO),改变投票策略,降低光照对微表情识别的影响。相较LBP 相关方法,该算法更加适合在彩色视频中进行微表情识别。WEI等[57]提出单方向梯度直方图(Histogram of Single Direction Gradient,HSDG)算法,该算法在某一运动方向上提取梯度值,简化HOG,最后将HSDG 与LBP-TOP 特征进行级联,得到具有外观纹理和运动信息的LBP-SDG(LBP with Single Direction Gradient)特征,其捕捉到了最有利于微表情识别的运动特征,但是选取18 个方向进行测试,计算复杂度过高。
4.1.2 基于光流特征的识别方法
光流特征可以有效提取微表情的时间信息。LIU等[8]提出MDMO 特征用于微表情识别,将人脸划分为36 个感兴趣区域,减少了与表情无关的冗余信息。在各个区域中计算HOOF 直方图,将直方图特征的最大值索引作为主方向,最后计算主方向上向量特征的均值从而进行微表情识别,其识别流程如图4 所示。

图4 MDMO 微表情识别流程Fig.4 Micro-expression recognition procedure of MDMO
MDMO 考虑到了各个区域的运动信息和空间位置,易于实现且特征维数小,但是容易丢失特征空间中固有的底层流形结构,采用预定义的AU关系进行建模,导致模型泛化能力较差。LIU 等[58]在MDMO 的基础上提出Sparse MDMO,能够有效揭示底层流形结构,比MDMO 特征具有更强的判别能力。
为降低小强度噪声光流的影响,LIONG[59]提出双加权定向光流(Bi-Weighted Oriented Optical Flow,Bi-WOOF),首先估计顶点帧和起始帧之间的水平和垂直光流分量,然后根据这两个分量计算每个像素点的方向、幅值和光学应变,最后通过局部加权的幅值和全局加权的光学应变获得基于方向的Bi-WOOF 直方图。然而,利用光流直方图作为分类器的特征向量时,光流直方图的轻微偏移会增大图像之间的欧氏距离,放大两个图像之间的差异,从而影响识别效果。HAPPY等[60]提出光流方向的模糊直方图(Fuzzy Histogram of Optical Flow Orientations,FHOFO),其能忽略无关运动,对表情强度和光照的变化不敏感。WANG[61]认为基于运动强度的权值容易受到图像噪声的影响,因此,提出一种新的基于光流时间累积的加权特征提取方法MINOF(Motion Intensities of Neighboring Optical Flows):首先计 算微表情视频中的光流时间累积,以降低图像噪声的影响;接着根据光流累积大小计算各区域的运动强度,获取每个区域的权重;最后将局部特征和权重相乘生成全局特征,有效去除噪声运动的权重,提高权值的有效性。
基于手工机器学习特征的微表情识别方法关注像素点的变化情况,可以保留更多的信息,对不同的面部表情具有很好的灵活性,能够忽略光照强度的影响,但是其特征维度高,计算复杂度高,需要结合特征选择算法过滤无效信息,以降低计算复杂度。MDMO、Bi-WOOF 等方法依赖于面部对齐效果,无法实现良好的微表情识别效果。上述方法的实验指标对比如表4 所示,其中,ACC(Accuracy)表示准确率,F1表示F1分数。从表4 可以看出:LBP-TOP、STCLQP、Sparse MDMO 在SMIC 数据集上分别取得了0.542、0.640、0.705 的准确率,这是因为SMIC 数据集只有3 个情绪类别,同时采集微表情所用的近红外摄像机也减少了光照对微表情的影响;LBP-TOP、STCLQP、Sparse MDMO在CASMEII数据集上分别取得了0.464、0.584、0.670 的准确率,这是由于CASMEII 数据集情绪类别较完备,样本分布更加均衡。

表4 基于手工机器学习特征的微表情识别方法 Table 4 Micro-expression recognition methods based on manual machine learning features
4.2 基于深度学习的识别方法
本节从AU、关键帧、迁移学习三方面对基于深度学习的微表情识别方法展开讨论。
4.2.1 基于AU 的识别方法
在微表情运动中,分析AU 能够发现潜在面部运动和情绪之间的关系。FACS 对面部行为进行编码,每个编码表示一个AU,如AU1 代表内部眉毛抬起、AU6 代表脸颊抬起等。不同AU 组合所表示的情绪如表5 所示。基于图的学习算法可以在非欧氏数据中发现每个对象节点之间的关系,AU 通常与图卷积(Graph Convolutional Network,GCN)相结合。基于AU 的微表情识别方法实验指标对比如表6 所示,其中,CASMEII 和SAMM 默认为五分类。

表5 情绪与AU 的关系 Table 5 The relationship between emotion and AU

表6 基于AU 的微表情识别方法性能对比 Table 6 Performance comparison of micro-expression recognition methods based on AU
WANG 等[9]基于AU定义16 个ROI,提取每个ROI 的特征,但预定义的AU 规则会导致泛化能力有限。LO 等[12]利用GCN 发现AU 之间的依赖关系,提出MER-GCN 网络用于微表情识别,这是第一个基于GCN 的端到端微表情识别网络,其结构如图5所示。

图5 MER-GCN 网络结构Fig.5 MER-GCN network structure
MER-GCN 将每对AU 的共现作为相关关系构建邻接矩阵,然后通过GCN 获取不同AU 之间的隐藏关系,最后将其与3DCNN 残差模块提取的特征进行融合,以完成微表情识别。该方法关注了局部动作变化,但是3DCNN 具有较大的参数量,同时AU关联矩阵依靠共现作为相互关系,极易受到噪声动作的影响。LEI 等[62]设计双流图时序卷积网络(Graph-TCN),通过获取微表情局部肌肉的运动特征进行微表情识别。首先选择眉毛和嘴巴区域的28 个人脸关键点,提取这些关键点7×7 的特征矩阵,并压缩成长度为49 的特征向量,以此为基础构建图结构并输入到双通道网络中,最后将提取的节点特征和边缘特征进行融合以完成微表情识别。Graph-TCN 能够更好地分析微表情的局部运动信息,具有较好的判别性,但其利用固定的扩张因子学习边缘特征,只能学习到固定区域的关联变化。LEI 等[63]提出双流网络Graph-GCN,包括图学习流和AU 学习流。AU 学习模型选择与眉毛和嘴巴相关的9 个AU,利用AU 的共现关系构建邻接矩阵,采用单词嵌入的方法构建节点矩阵,将这两个矩阵输入到双层GCN 中提取特征,最后融合图学习流的特征进行分类。ZHAO 等[64]提出时空AU 图卷积网络(Spatio-Temporal AU Graph Convolutional Network,STAGCN),先利用3DCNN 提取AU 相关区域的时空运动信息,再通过GCN 捕捉AU 的依赖关系,最后与全脸特征相乘得到激活特征进行微表情识别。SUN等[65]提出一个双分支融合的微表情识别框架(Dual Expression Fusion micro-expression recognition framework,DEF-Net),使用OpenFace 模型分析AU 的发生,将深度网络提取的人脸特征与AU 进行级联,捕获细微面部运动以完成微表情识别。WANG等[66]将AU 与人脸关键点相结合,构建眼睛、鼻子、脸颊和嘴巴等4 个感兴趣区域,接着将相应区域进行加权,最后结合所提出的MER-AMRE(MER framework with Attention Mechanism and Region Enhancement)网络提取特征,提高了网络提取局部运动信息的能力。CEN等[67]为了挖掘面部表情与AU 之间的关联,将微表情视频分割为多个相邻视频片段,揭示三维邻域的时空特征变化情况,最后结合所提出的多任务面部活动模式学习框架(Multi-task Facial Activity Patterns Learning Framework,MFAPLF),促进同类微表 情聚合。
4.2.2 基于关键帧的识别方法
文献[59,68]使用单一顶点帧进行微表情识别,大幅减少了输入帧的冗余信息,降低了特征的计算复杂度。LI等[69]基于VGG-16 CNN 架构提出一个基于局部和全局信息的学习模型(LGCcon),分别提取全局和局部特征。先利用欧拉运动放大方法将顶点帧的细微运动进行放大,再采用全局信息流提取整个面部图像的上下文信息,利用局部信息流将面部图像划分为子区域,寻找贡献最大的局部区域并提取特征,最后将局部和全局特征进行融合以完成微表情识别。实验结果表明,与完整的序列相比,单一顶点帧也能获得较好的性能,但是参数量相比于单分支结构更大,模型能够获取关联特征,但需要对全局和局部定义多重约束条件,同时需要引入多个损失函数来区分类内和类间特征,模型复杂度过高。
起始帧和顶点帧之间的运动变化在微表情识别中具有较强的判别性,文献[70-72]方法使用起始帧和顶点帧的光流提取面部的运动特征。LEI等[63]抽取起始帧和顶点帧作为输入,设计Graph-GCN 网络,先利用MagNet[73]对顶点帧进行放大,接着将图学习模型和AUs 学习模型提取的特征进行融合以完成微表情识别,其网络结构如图6 所示。
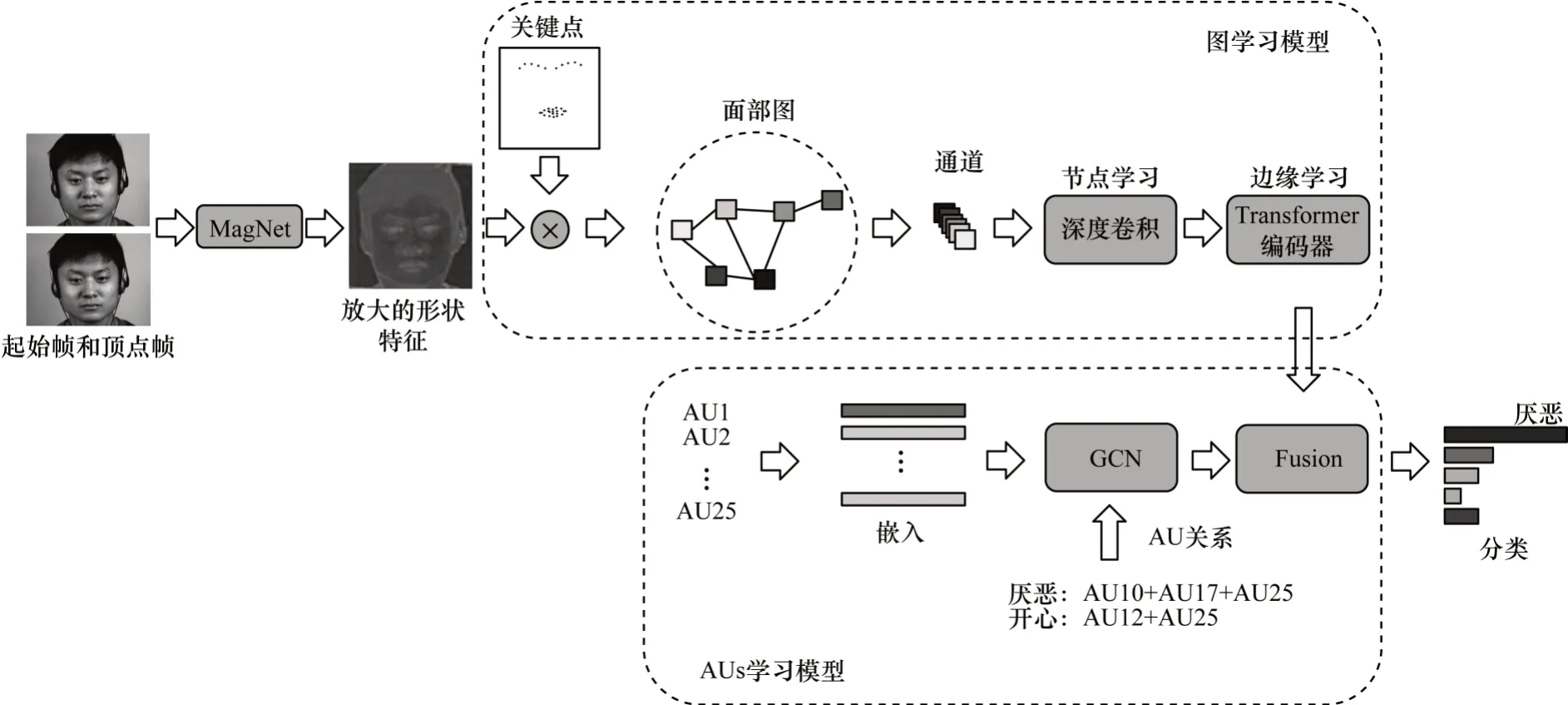
图6 Graph-GCN 网络结构Fig.6 Graph-GCN network structure
Graph-GCN 网络可以学习到节点间的信息关联,但采用预定义的AU 信息,限制了模型的学习能力。其次,Transformer层数缩减为原始模型的一半,但依然存在较大的参数量。最后,双分支融合模块仅采用简单的串联操作,增加了冗余信息。ZHAO等[71]采用基于L1 的总变差光流算法计算起始帧与顶点帧之间的运动信息,并将得到的光流特征反馈给后续的深度网络。GAN等[74]提出基于顶点帧的光流特征网络(Optical Flow Features from Apex frame Network,OFF-ApexNet),采用起始帧和顶点帧来提取两个方向的光流,表示微表情的运动细节,输入到深度网络中进行特征增强,从而获得更具判别性的特征以完成微表情识别。文献[75]和文献[76]也采用类似的方法,将起始帧和顶点帧的光流作为网络输入,在降低模型输入复杂性的同时又能保持较好的识别效果。CHEN 等[77]提出分块卷积网络(Block Division Convolutional Network,BDCNN),计算起始帧和顶点帧4 个光流特征,接着将这4 个光流图进行分块,并对这些小块进行卷积和池化操作,最后将4 个光流提取的特征向量进行特征级联,以完成微表情识别。
基于关键帧的微表情识别方法能够在降低特征维度的同时保持良好的识别效果,但是会丢失较多的时序信息。各方法的实验指标对比如表7所示,其中,UAR(Unweighted Average Recall)表示未加权平均召回率,标有“*”代表三分类,SMIC 为三分类。

表7 基于关键帧的微表情识别方法性能对比 Table 7 Performance comparison of micro-expression recognition methods based on key frame
4.2.3 基于迁移学习的识别方法
迁移学习方法通常将知识从具有大样本容量的源域迁移到目标域中。现有的微表情数据集较小,而宏表情数据集包含大量的训练样本。考虑到宏表情与微表情存在相关性,通常会结合宏表情数据集进行训练来提高微表情的识别性能。
文献[68,78]方法利用迁移学习的思想,结合宏表情数据集提高微表情识别性能。文献[79]方法使用3 种有效的二值面部描述子提取特征,将这些特征输入到源域和目标域共享的公共子空间中进行学习。文献[80]方法引入表情身份分离网络(Expression-Identity Disentangle Network,EIDNet)作为特征提取器,分别用宏表情和微表情数据集对两个EIDNet进行训练,分别命名为MacroNet 和MicroNet,固定MacroNet 并对MicroNet 进行微调,MicroNet 可以从宏表情样本中学习共享知识,并采用不等式正则化损失使MicroNet 的输出收敛于MacroNet 的输出。EIDNet 利用从宏表情样本学习到的知识指导微表情网络的调整,提高了微表情的识别性能,但整个网络模型包含多个模块,模型设计较为复杂,且训练过程较为繁琐,很难满足实时性的需求。
文献[81]方法在CK+、Oulu-CASIA NIR&VIS、Jaffe和 MUGFE 这4 个宏表情数据集[82]上进行训练,接着利用微表情数据集对网络进行微调,然而该网络仅在注意力方面做出了改进,且在经过宏表情预训练后再对微表情进行训练,不能很好地突出宏微表情之间的关联。TANG等[83]首次将迁移学习和GCN相结合应用于微表情识别领域,提出迁移双流随机图卷积网络(Transferring Dual Stochastic Graph Convolutional Network,TDSGCN),利用宏表情数据集对源网络进行训练,然后用微表情数据集对网络进行微调,最后完成微表情识别。ZHANG等[84]提出的运动放大多特征关系网络利用迁移的ResNet50来提取全局特征,在一定程度上避免了过拟合问题。
基于迁移学习的微表情识别方法性能对比如表8所示。

表8 基于迁移学习的微表情识别方法性能对比 Table 8 Performance comparison of micro-expression recognition methods based on transfer learning
基于深度学习的微表情识别方法由多段训练发展到如今的端到端训练,可以提取微表情更深层次的信息,同时也避免了复杂的手工特征描述,但深度网络需要依靠一个更大更真实的微表情数据集才能获得较好的性能。Graph-TCN、LGCcon、Graph-GCN 等方法关注局部区域运动信息以挖掘微表情信息,这一点与手工特征方法中依赖面部网格分块突出局部信息的思想一致。在深度学习方法中,Graph-TCN、Graph-GCN、OFF-ApexNet在CASMEII 数据集上分别取得了0.740、0.743、0.883 的准确率,这是因为CASMEII 数据集中有AU 标注,能够突出运动区域;Graph-TCN、Graph-GCN、OFF-ApexNet 在SAMM 数据集上分别取得了0.750、0.743、0.681 的准确率,这是由于SAMM 具有较为完备的情绪分类,同时也有较高的帧率。但是,这一类方法依然受限于现有微表情数据集的数据量,在现实环境中泛化能力较差。
5 总结与展望
微表情检测和识别对人机交互的发展具有重大意义,拥有广阔的应用前景,未来会有更多的研究人员从各个角度对微表情展开研究。但是,目前微表情检测和识别中还有一些亟待解决的问题,针对这些问题,本文总结了该领域未来可能的发展方向,具体如下:
1)生成高质量微表情数据。为了弥补微表情数据量有限和部分微表情图像质量过低的问题,已有方法开始尝试采用生成对抗网络生成微表情数据,但是在该过程中存在两个问题:一是生成的微表情图像对网络性能提升效果有限,说明生成的AU 关系不够准确,同时在生成新的图像时会引入噪声,从而对分类器造成影响,在未来的工作中,利用GAN 生成高质量的微表情图像也是一个值得研究的问题;二是在FACS 中定义了微表情与面部动作的关联,已有工作利用这一关联作为先验知识解决微表情分析问题,事实上,这一关联也直观解释了微表情的发生机理,但现有方法采用的GAN 并没有与之相结合,因此,如何判定生成的图像是否符合微表情的发生机理,还没有一个规范的评价标准,这也是未来的一个工作方向。
2)多模态微表情分析。目前微表情分析算法仅依靠单一面部表情进行分析,但在实际生活中,微表情的发生常伴随着肢体语言以及语音等状态的变化。在未来的研究中,需要充分利用肢体语言等相关信息,充分体现微表情的发生机理,揭示多模态数据的内在关联。
3)采用其他学习策略。已有方法都是采用有监督的方式训练网络,对数据量有一定的依赖性。在今后的研究中,可以考虑采用自监督的方式,减少网络对数据量的依赖,提升所学习到特征的适应性。另外,现有的微表情数据库存在类别不平衡的情况,这包括数量不平衡和识别难度不平衡,今后除了关注样本数量外,还需要结合样本的识别难度来动态调整学习过程。
6 结束语
与人工分析微表情相比,基于计算机视觉的微表情分析方法具有较大优势,本文对基于传统机器学习和基于深度学习的微表情检测与识别方法进行分析和总结。通过对这些方法的分析比较发现,基于机器学习的方法关注像素点的变化情况,能够保留更多的有效信息,鲁棒性较高,并且可以满足实时性的需求,但是该类方法在预处理阶段将面部图像划分为固定网格,难以体现面部运动的发生机理,存在精度低、过程繁杂等问题。相较机器学习方法,深度学习方法具有精度高、易于捕捉上下文信息的优点,但是存在容易过拟合、耗时、依赖数据量等缺点。在未来,微表情分析会有更多的应用需求,对性能也会有更高的要求,下一步将对基于深度特征的微表情分析方法进行深入探究,以开发具有高性能、高精度和强鲁棒性的系统。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
导航定位学报(2022年5期)2022-10-13
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中北大学学报(自然科学版)(2014年3期)2014-11-22
中国铁道科学(2014年6期)2014-06-21
郑州大学学报(理学版)(2013年3期)2013-03-11
中学生数理化·高一版(2009年6期)2009-08-31
