
面向语文辞书编纂的神经网络语料库检索研究*
2023-02-07 03:11胡钦谙
辞书研究 2023年1期
胡钦谙
一、 引 言
在语文辞书编纂工作中,语料库正发挥着日益重要的作用。目前,汉语辞书编纂者普遍采用北京语言大学BCC现代汉语语料库(荀恩东,饶高琦等 2016),北京大学中国语言学研究中心CCL语料库(詹卫东,郭锐等 2019)等通用或特定领域语料库,或者使用通用搜索引擎(如百度)等作为检索工具。用户输入关键字、词或短语等作为检索 词,[1]由检索系统返回排序后的句子列表,然后由人工进行筛选。
然而,随着语料库规模不断扩大,返回结果的数目动辄逾万。人的精力有限,往往只能聚焦于返回结果列表的头部。有时要在语料库中找到一个恰当的例句,仿若大海捞针。海量检索结果与用户趋于饱和的语料消化能力之间的矛盾已成为辞书编纂过程中的痛点之一。
本研究观察到,辞书编纂人员在检索语料库时,实际上更为关注的是检索词出现的语境(或称上下文)。语境具有相对稳定的语言学规律,语料库中往往存在着大量符合同一语言规律的语境。这种同质的语境对辞书编纂提供的价值相对有限。此时,单纯依靠增加语料数量对辞书编纂的贡献已呈现出边际效益递减的现象。
因此,本研究尝试以海量检索结果中的同质语境为突破口,通过人工智能方法,以可视化及可交互的形式为辞书编纂人员展现检索结果分布的概貌,批量处理同质的语境,以提升辞书编纂的效率。
二、 语料库检索与语境量化
语料库检索系统不同于通用搜索引擎。通用搜索引擎通常会赋予来自权威网站、高点击率的网页更高的权重,并考虑个性化等因素;而语料库检索系统则需要更多地聚焦于检索词出现的语境。然而,刻画语境所涉及的语言现象相当复杂。
首先,语境的范围具有模糊性,常随检索词的不同而灵活多变。
其次,现代汉语语法信息词典(在2017年由俞士汶、朱学锋研制)从词语语法属性的角度对语境进行了抽象概括。具体地,该词典按形、音、词类、词项、义项等维度对同形词及其语境进行区分。然而词项、义项等信息都隐含在语境中,对于语料库检索系统来说缺乏显式的说明。
最后,虽然共现为刻画语境提供了显式特征,但是语料库中存在着大量语境难以利用共现进行区分。如例(1)、例(2)中的“松”,属于“常绿乔木”义项;例(3)、例(4)中的“松”,属于“放开,使松散”义项。然而,下面四个句子的语境之间并没有任何交集,因此无法利用共现判断出“松”分别在例(1)、例(2)和例(3)、例(4)的语境下语义相近。
(1) 大松树没有回答。
(2) 过了几天,松鼠再也受不了啦。
(3) 现在给你松绑。
(4) 千万不能松手!
类似地,语料库中亦存在大量难以通过分词、词性标注甚至句法分析等手段区分的语境。例如,从句法的角度来看,例(5)与例(6)中的“服”都与其右侧的字构成并列复合词,语境中都出现了“需要”,并且都以名词作为宾语;但是从语义的角度,例(5)中“服”属于“吃(药)”义项,而例(6)与例(7)中的“服”语义相近,属于“顺从” 义项。
(5) 她需要按时服用药物。
(6) 士兵需要服从命令。
(7) 母亲信服地点点头。
义项和释义是对词汇语义的高度抽象,是语文辞书编纂工作的重点和难点。吴云芳、俞士汶(2006)指出,语境是计算机区分词汇语义的最终凭借。因此,在为语文辞书编纂服务的语料库检索系统中,语境的量化须围绕着检索词的语义,对检索词在不同语境下的语义具备基本的辨别能力。
三、 语境相关的词汇语义量化
本文将词汇在特定语境下的语义称为语境相关的词汇语义。
在向量空间模型中,词汇的语义可以表征为向量空间中的点,词汇之间的语义距离可以表征为点间的距离。首先,向量空间模型可以为理解语境相关的词汇语义提供一种全局视角。检索词的基本义及其引申义、比喻义等新义、不同义项以及同一义项的不同属性等均可以表示为同一语义空间中的点。一般来说,同一义项属性之间的语义距离较近,而不同义项之间的语义距离较远。如图1所示,“苹果”的基本义、品牌义项、苹果树义项、果实义项及其价格属性均可以表示为向量空间中的点。其中,“苹果”的价格属性也是“苹果”本身所蕴含的语义的一部分。

图1 向量空间模型中语境相关的词汇语义
其次,向量空间模型可以为理解语境相关的词汇语义提供一种动态视角。当检索词出现在不同语境中时,在形、音、义、词法、句法及共现等各维度表现出的差异,可以认为是检索词与语境互动的结果。语境对检索词的影响可以体现在检索词的语义上。一方面,与检索词存在照应关系的语境的语义将深刻地影响检索词的语义;另一方面,不存在照应关系的语境对检索词语义的影响则微乎其微。在这里,照应泛指依存、指代等各种具有语言学意义的关系。
上述观点在语义空间中就体现为词汇的语义位置不是固定的,而是会随语境而发生位移。位移的原点代表基本义,终点代表发生位移后的某个义项、属性、引申义或比喻义等新义。不同的语境带给检索词语义的影响不同,造成最终检索词在语义空间中的位置也各不相同。如图1所示,例(8)中的“手机”以及例(9)中的“吃”将“苹果”从基本义拉向了两个相反的方向。
(8) 他买了苹果手机。
(9) 我喜欢吃苹果。
鉴于语境对检索词语义的影响可以体现在检索词在语义空间中的位移上,那么语境的量化问题就可以转化为语境相关的词汇语义量化问题来解决。(详见图2)

图2 将语境量化问题转化为词汇语义量化问题
四、 神经网络相关技术
神经网络中的注意力机制、上下文相关词向量以及预训练语言模型等技术为语境相关的词汇语义提供了量化方案。
注意力机制刻画了语境内词与词之间的各种照应关系(Vaswani,Shazeer,Parmar,et al.2017)。它可以突破语境被限定在预定义宽度的窗口范围内的限制,处理长距离依赖关系时依然有效。照应关系的强度通过注意力权重反映出来。
在神经网络中,词的语义以词向量(或称词嵌入)的形式表示。(Mikolov,Sutskever,Chen,et al.2013)词向量由低维、稠密的实值组成。词向量使得语义匹配可以不再依赖共现等显式特征,可以进行模糊匹配。上下文相关词向量是指向量数值会随语境不同而发生变化的词向量,其数值的变化可以由注意力机制等引发。
预训练语言模型是使用海量语料训练的参数量巨大的神经网络模型(Devlin,Chang,Lee,et al.2018)。词向量的初始值以及词与词之间的注意力权重等均保存在预训练语言模型中。图3展示的是汉语预训练语言模型Chinese-BERT-wwm-ext[3](Cui,Che,Liu,et al.2021)在输入例(10)后得到的注意力权重。(Vig 2019)注意力权重越高,连线颜色越深。其中,左图“她”和“女”“娲”、中图“这”和“作”“品”之间的照应关系是指代,右图“对于”和“感到”之间的照应关系是依存。

图3 注意力机制中的指代及依存关系[2]
(10) 女娲对她这优美的作品,感到很满意。
检索词的上下文相关词向量可以用于对语境相关的词汇语义进行量化表征。在神经网络的输入层,词向量的初始值代表词汇的基本义。在输入层之后的各层,与检索词照应关系强的语境中的词向量的数值将被更多地累加到检索词的词向量上,而照应关系弱的语境中的词向量则对检索词的词向量的影响较小。随着神经网络层数不断加深,各种存在照应关系的语境的词向量就被逐层累加到检索词的词向量上。体现在语义空间中,检索词的语义位置就从词向量的初始值,随着存在照应关系的语境的语义被逐层累加到检索词的语义上,不断发生位移。
例如,图4中的注意力权重显示“女”与“娲”之间存在着强烈的照应关系。值得注意的是,这种照应关系是单向的。这是因为“娲”的语义比较单一,比“女”更接近“女娲”的语义。这种单向照应关系使得“女”的语义需要做出重大调整才能得以靠近“女娲”的语义。具体地,如图5所示,“女”的语义受“娲”的语境影响出现了较大位移,向“娲”靠近;而反之则不然,“女”作为“娲”的语境,对“娲”语义则影响不大。

图4 注意力机制中的构词关系

图5 语境“娲”对“女”语义的影响
五、 实 验 结 果
(一) 使用检索词的上下文相关词向量对语料库检索结果中的语境进行量化及可视化
实验语料选取自人民教育出版社、语文出版社、北京师范大学出版社和江苏教育出版社出版的中小学语文教材,句子长度不超过128个字,合计3万句。
实验使用经典的汉语预训练语言模型Chinese-BERT-wwm-ext(Cui,Che,Liu,et al.2021)计算上下文相关词向量。图6是模型输入的示例。输入时按照BERT的输入格式,句子前后填充[CLS]、[SEP]。为了消除BERT中位置嵌入(position embeddings)对检索词向量的影响,检索词统一放在输入序列正中间的位置,左右两侧的语境长度相同,前后空位填充[PAD]。输出值取输入层词向量初始值以及BERT内部12层隐状态的均值,作为检索词上下文相关词向量。对输出的向量采用tensorflow embedding projector[4]及UMAP(Uniform Manifold Approximation and Projection)[5](McInnes,Healy,Melville 2018)降维至三维空间进行可视化。

图6 检索字居中输入
图7—图9是为辞书编纂人员展现的可视化界面。图中的三维空间表示检索词的语义空间,圆点表示检索词在一条检索结果语境下的语义,圆点的位置由检索词上下文相关词向量决定。用户可以点击圆点查看该圆点对应的检索结果原文,也可以对检索结果进行拖拽旋转、缩放、选择、查找、重置等操作。
以“打”字为例,在语料中检索“打”字时共返回480条检索结果。图7将“打”字在所有这些检索结果中的语义展现在同一界面中,其语义分布自然呈现出聚集的状态。这有助于辞书编纂人员掌握检索结果分布的概貌,识别同质的语境。

图7 “打”的检索结果
图8显示出拖拽一个圆点至前景放大后的局部结果,拖拽时与该圆点语义相近的圆点也会被一同置于前景。可以看出,这些语义相近的“打”对应的检索结果其右侧语境都是“算”,说明这些语境中的“算”对“打”的语义产生了显著影响。这些语义还可以进一步细分。图中上部“打算”承接的是宾语从句,出现在疑问句中的“打算”在图下部,出现在否定词后的“打算”在图左侧,图右侧“打算”是名词性用法,说明这四种不同的语境对“打”的语义各自产生了不同的影响。

图8 “打”字右侧为“算”的检索结果
当用户点击选择一个圆点时,界面右侧将列出与在该语境下检索词语义相似的检索结果,左侧将标示出相似检索结果在语义空间中的位置。例如,图9列出与例(11)中的“打”语义相似的检索结果。

图9 与例(11)中的“打”语义相似的检索结果
(11) 他态度粗暴严厉,常常打学生。
(二)对比观察检索结果展现形式对语文辞书编纂中义项分立效能及效率的影响
16名辞书编辑被随机分为两组,为给定的字头编写义项条目。两组的不同在于检索结果的展现形式。基于神经网络的语料库检索系统使用Tensorflow的可视化界面进行操作。对照组使用AntConc[6]concordance,检索结果列表按检索词右侧及左侧各一个字进行排序,图10显示的是“点”字检索结果。

图10 使用AntConc concordance对检索结果列表排序
实验选取了《新华字典》第12版中义项最多的“干、生、开、点、下、子、起、对”8个字。实验要求辞书编辑在不使用互联网、手机或查字典的情况下,仅根据前述教材语料库的检索结果及自身语感为给定的字头归纳义项,给出义项释义及例词,但无需推敲释义的措辞。
实验结果详见表1。表中对标义项数是指以《新华字典》第12版中的义项为标准,与辞书编辑给出的义项进行比对时,相同的义项数。[7]两组对标义项数分别是6.38、6.88,说明检索结果的两种展现形式在义项分立任务上的效能大致相同。
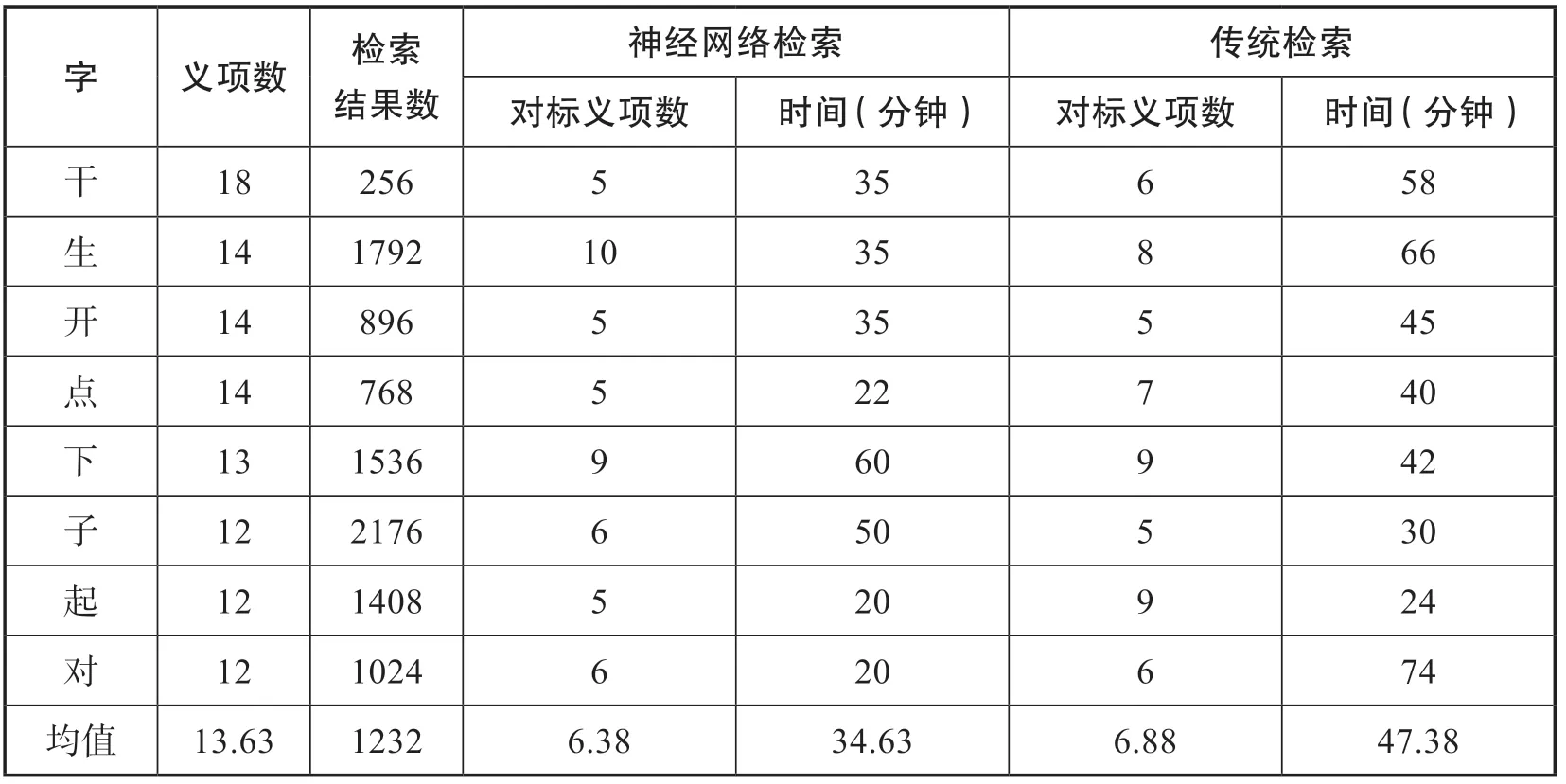
表1 字头及编纂时间、对标义项数
基于神经网络的语料库检索的优势主要体现在效率方面。两组分别平均用时34.63及47.38分钟,前者比对照组节省了26.92%的时间。
六、 结 语
本文以海量检索结果中的同质语境为突破口,探讨了基于神经网络的语料库检索系统的构建。本文将语境的量化问题转化为语境相关的词汇语义量化问题,使用上下文相关词向量使得检索结果的分布呈现出聚集的状态,为语料库检索提供了可视化及交互功能。
义项分立的实验表明,基于神经网络的语料库检索系统有助于辞书编纂人员对检索结果去芜存菁,提升辞书编纂效率。
在后续研究中,我们将持续改进可视化的展现形式,把检索词从字扩展至词及短语,并为词语辨析、例句甄选等更多的语文辞书编纂应用场景提供量化依据。
附 注
[1] 本文中检索词泛指用户输入的关键字、词、短语等。
[2] 图中Layer i表示神经网络第i层,Head i表示第i个注意力头,[CLS]和[SEP]是标志位,前者置于句首,后者置于句尾。
[3] https://github.com/ymcui/Chinese-BERT-wwm。
[4] https://projector.tensorflow.org/。
[5] UMAP算法学习的是高维空间中的流形结构及其低维表示。
[6] https://www.laurenceanthony.net/software。
[7] 计数以义项为单位计算,而非以子义项为单位计算。例如,“下”义项②由高处到低处有 6个子义项,包括1.进2. 离开3. 往……去4.投送,颁布5.向下面6.降落等,计数时按一个义项计算。
猜你喜欢
汉字汉语研究(2021年1期)2021-06-11
天津外国语大学学报(2020年1期)2020-03-25
语言与翻译(2015年4期)2015-07-18
阅江学刊(2015年5期)2015-06-22
知识窗(2015年1期)2015-05-14
东北亚外语研究(2010年9期)2010-04-24
当代外语研究(2010年3期)2010-03-20
