
基于深度学习的计算机视觉技术在交通场景中的应用
2022-11-24 02:38王雪涵高俊平王赢庆尹栋程
长春工业大学学报 2022年3期
潘 超, 王雪涵, 高俊平, 王赢庆,尹栋程, 李 佳, 肖 巍*
(1.长春工业大学 计算机科学与工程学院, 吉林 长春 130102;2.长春市十一高中北湖学校, 吉林 长春 130102)
0 引 言
中国汽车工业协会公布的数据显示,2019年国内汽车销量2 576.9万辆,2020年国内汽车销量2 531.1万辆。从数据上可以看出,每年都有众多的汽车源源不断地融入到交通系统,给交通系统带来了巨大的压力,可以说交通系统的管理能力决定了社会生活的方方面面。交通问题的解决离不开计算机技术大加持,而人工智能技术的不断革新突破可以进一步提升交通系统的工作效率。因此对交通场景智能识别系统(Traffic Scene Intelligent Recognition System)的需求越来越高。
高效准确地完成交通场景的智能识别依赖于计算机视觉的目标检测技术。目标检测是区分视频或图像中感兴趣的区域与其他区域,判断目标存在与否,确定目标的位置并识别其种类的计算机视觉任务。近年来,随着深度学习理论的日趋成熟以及硬件性能的飞速提升,目标检测任务也从基于计算机视觉与手工特征提取的传统算法转向基于深度神经网络的检测方法[1],基于深度学习的视觉处理方法以各种卷积神经网络结构模型为代表,合并特征提取、选择和分类过程,通过端对端训练来自动提取特征,达到分类效果,这类方法精度较高[2]。一般常用的深度学习方法包括: R-CNN、Fast/Faster R-CNN、SSD、YOLO系列等。
计算机目标检测算法的发展历程见表1。

表1 计算机目标检测算法的发展历程
2001年,维奥拉-琼斯通过滑动窗口的检测方法首次实现了人脸的实时检测,使用传统的目标检测算法进行检测。2005年,N Dalal等[4]对尺度不变特征变换和性状上下文作出改进,提出HOG。2008年,传统目标检测算法发展达到顶点,P Felzenszwalb等[5]提出DPM算法,经过多人改进,使用“边界框回归”技术提高了检测精度。
2012年,随着GPU技术的不断发展,进入基于深度学习的目标检测算法时期。Hinton教授团队利用卷积神经网络设计了AlexNet, 在ImageNet数据集上打败所有传统方法的团队,使得CNN成为计算机视觉领域中最为重要的工具[14]。
2014-2017年间,涌现出R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、YOLO、SSD、Retina-Net、Pyramid Networks等深度学习算法,可分为One-stage和Two-stage两类。
Two-stage 识别错误率较低[15]。R-CNN 首次将深度学习应用到目标检测上,SPPNet 输入具有灵活性,能在输入尺寸任意的情况下产生固定大小的输出,Fast R-CNN主网络是VGG16,比R-CNN 和SPPNet 快数倍,Faster R-CNN相较于Fast R-CNN改为多参考检测,Pyramid Networks融入特征融合,使得基于深度学习的目标检测算法逐渐成熟。
One-stage 检测速度较快[16],YOLO 将物体检测作为回归问题求解,检测网络pipeline简单,SSD引入多分辨检测和难分类样本挖掘的思想,Retina-Net在分类损失上进行改动,加上权重因子,加大难分类样本的相对权重。
不少学者将这些算法应用到交通路口智能识别产品中,而目前比较传统的交通路口智能识别产品在固定角度、固定距离的条件下虽具有较好的识别效果,但在不同角度条件下识别效果较差。在这些算法中,YOLO V3版本算法主要在损失函数上做了改进,在开放目标检测数据集上的检测效果和性能都很出色。文中利用YOLO V3检测算法适应性强的特点,从实际问题的特性出发,尝试使用YOLO V3实现交通场景的分析。
1 关键技术的研究
1.1 YOLO V3检测算法
YOLO系列算法是基于卷积神经网络的目标检测算法[17],以YOLO V3算法为基础进行车辆检测研究。
对物体进行识别时,网络通过特征提取的方式对目标进行识别。识别时将目标图像分为若干个小块,根据待识别物体的大小可以分为13×13,26×26,52×52的小格,在实际使用中,如果待识别的物体更小(如小昆虫、小零件等),还可以将图像分割的更小(如104×104)。当物体的中心坐标被分入某个格中,就由这个格子预测物体。物体有固定数量的外框(bounding box),YOLO V3 使用逻辑回归确定用来预测物体的回归框。原理如图1和图2所示。
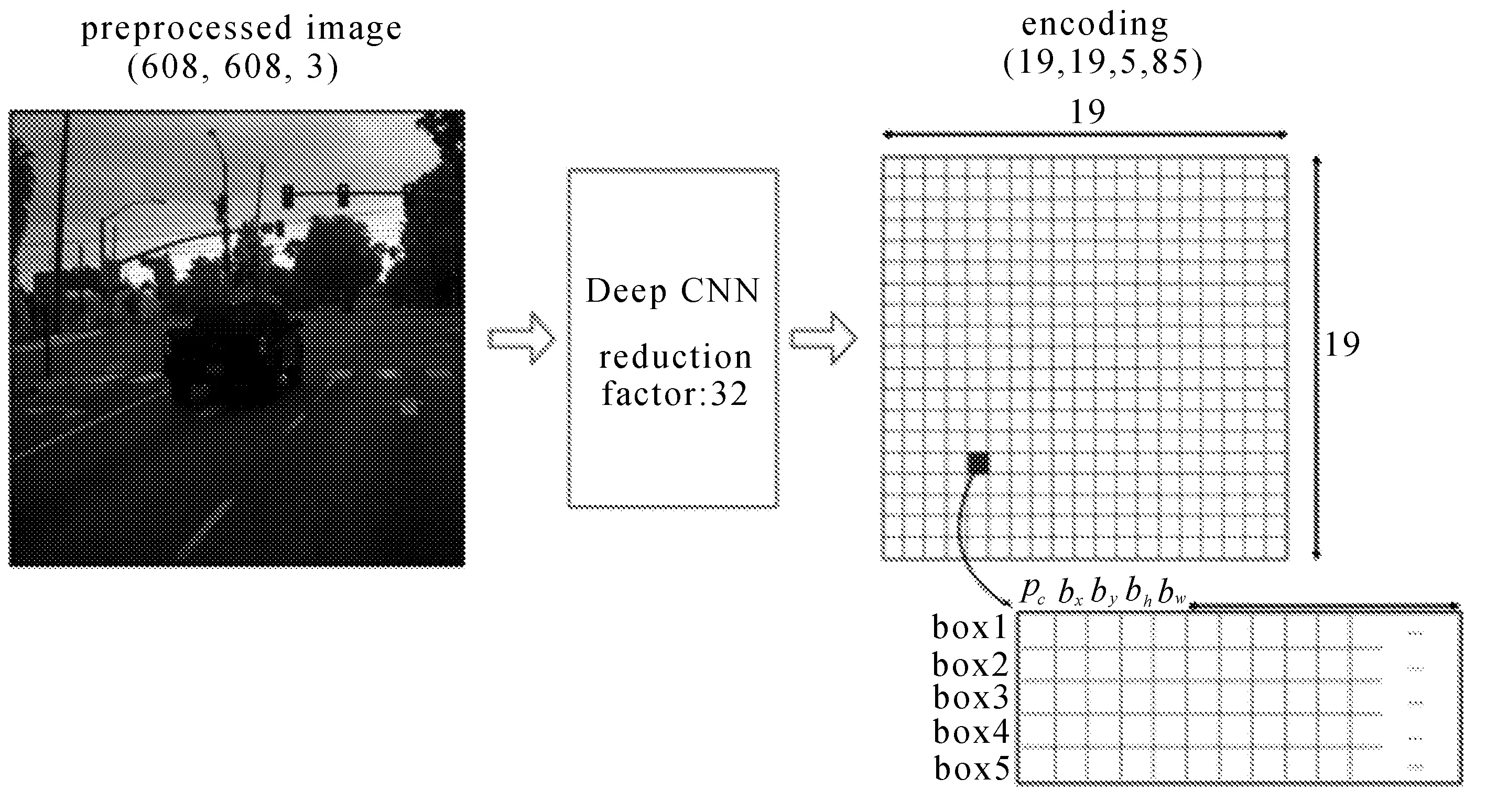
图1 YOLO实现原理1

图2 YOLO实现原理2
总体上讲,YOLO V3网络结构包括输入部分、基础网络部分、特征融合层。输入部分要求输入数据为 416×416像素,如果数据过大,需要对输入数据进行Resize操作,使之变为合适的尺寸。虽然YOLO V3本身使用的是全卷积层,输入数据和特征图尺寸的修改都是通过卷积层来实现。但是输入图片过大仍然可能影响识别效果的完整性。
基础网络部分中YOLO V3采用Darknet-53网络。该网络综合考虑了Darknet-19和ResNet的Residual残差结构。既增加了网络的深度,提升了拟合能力,又减小了训练难度。
Darknet-53 模型结构如图3所示。

图3 Darknet-53 模型结构
Darknet-53由BDL组件和5个RES(残差块)联合构成。由于YOLO V3是全卷积网络,所以DBL由卷积网络、归一化组件BN(Batch Normalize)、激活函数(LeakyRelu)构建而成[18]。YOLO V3的总网络一共有75个卷积层,采用深度学习中常用的LeakyReLu作为激活函数,并使用batch normalization对数据进行正则化,加速收敛速度,提高了模型的拟合能力,但是模型结构冗长也有产生梯度消失问题的风险。为解决此问题,模型引入了残差模块,每个残差块中包含若干个残差单元,残差块中包含具体残差单元的数量由残差块res的n值确定。由于网络主体是由许多残差模块组成,这种结构减小了梯度爆炸风险,很好地加强了网络的学习能力[19]。
算法允许在速度和准确率之间做出选择,根据需要可以选择侧重于速度而牺牲一些准确率或侧重准确率而牺牲一些算法效率。从V2版本中使用的darknet-19到V3版本中使用的darknet-53,YOLO版本表现的提升很大程度上取决于backbone网络性能的提升。
Joseph Redmon实验表明,在分类准确度与效率平衡上,Darknet-53模型比ResNet-101、 ResNet-152和Darknet-19表现得更好[20]。YOLO V3并没有那么追求速度,而是在保证实时性(fps>60)的基础上追求performance。同时,V3提供了可以替换的backbone-tiny darknet。对于注重性能的准确性场景可以使用darknet53,对于注重效率的场景可以选用tiny darknet。 YOLO V3的这种特性使其具有非常好的适应性,适合应用于实际的工程场景[21]。
1.2 物体重识别算法设计
YOLO检测算法可以对每一帧进行分析,找到画面中的各个目标,但在实际交通场景中,大部分监控场景都是一个复杂连续的过程。识别出每个画面中的物体只是第一步,还要提取物体的静态特征,对每个物体进行追踪,以判断是否存在违反交通规则的情况。
算法: 物体重识别算法
输入: 每帧画面中物体中心点坐标(xi,yi),特定距离阈值m
输出: 是否为同一物体
1.计算前后两帧画面物体中心点的欧氏距离di;
2.比较di与m,
2.1.若di≤m,则将两个物体视作前后两帧画面中的同一对象。
2.2.否则,
2.2.1.若(xi-1,yi-1)不存在,而(xi,yi)存在,则对于本帧新出现的点记作新的物体;
2.2.2.若(xi-1,yi-1)存在,而(xi,yi)不存在,则对于本帧画面未能配对的点予以注销。
在进行物体重识别设计时,主要依据欧氏距离进行检测,上一帧和本帧画面中物体中心点之间的欧氏距离为
di=(xi-1-xi)2+(yi-1-yi)2,
在画面分析结束后,获取YOLO的分析结构,将YOLO识别出的物体中心点作为检测依据,分别比较上一帧画面和本帧画面中物体中心点的变化情况:若先后两个点之间欧氏距离小于特定值,则将两个物体视作前后两帧画面中的同一对象;对于新出现的点记作新的物体;对于上一帧画面中存在,而本帧画面未能配对的点予以注销,算法示意图如图4所示。
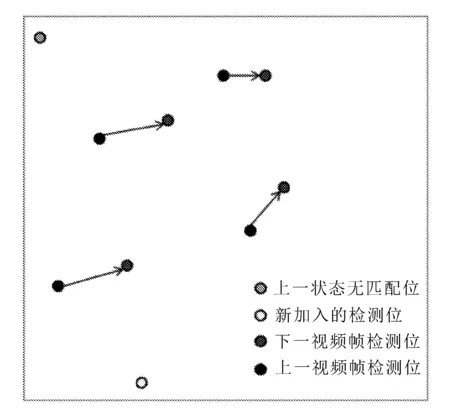
图4 物体重识别算法示意图
1.3 距离判断
在交通管理的场景中,距离检测运用最为广泛,通过距离检测判断识别车辆与车道线的距离、车辆与行人的距离、车辆与人行道的距离。通过车辆与车道线的距离,可以判断车辆是否红灯越线,以及是否有闯红灯等行为;在车辆与行人的距离判定中,可以判断车辆的车速,以及车辆是否礼让行人;根据车辆与人行道的距离,判断车辆是否进入或者通过人行道,用车辆与中心线之间的距离来统计车流量。
在判定车辆是否闯红灯时,首先采用距离算法来判断车辆具体在哪个车道上,从而得到车道导向,并通过信号灯的识别获取对应的红绿灯信息,判断车辆所在导向是否为红灯。当为红灯时,判断车辆所在位置是否在对面车道线和当前车道线之间,如果是,则判定该车辆闯红灯。
算法:判定车辆是否闯红灯
输入:车道对应的红绿灯信息
输出:车辆是否闯红灯
1.判断车辆所在导向是否为红灯,若为红灯;
1.1判断车辆所在位置是否在对面车道线和当前车道线之间,若是,输出车辆闯红灯;
2.否则,输出车辆未闯红灯。
车速计算示意图如图5所示。
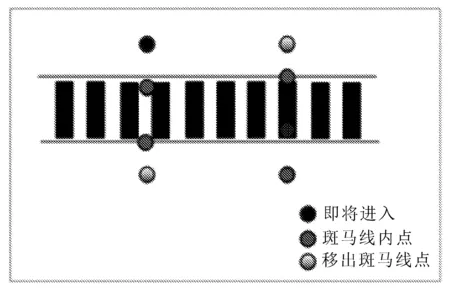
图5 车速计算示意图
测量车速时,利用人行横道作为参照物,只要利用车辆经过人行横道的时间就可以粗略测量出车辆速度,那么关键就集中于如何判断车辆经过人行横道的时间。车辆未到达人行横道时,车辆入点与人行横道下沿之差为正数,在某视频帧下,此差变为负数时,则代表车辆经过人行横道下沿,记录时间点;接下来就是车辆入点与人行横道上沿进行作差,过程与人行横道下沿相同,然后记录时间点;前后两个时间点作差,就可以得到车辆通过人行横道的时间,从而可以判断车辆是否超速。
算法:车辆超速判断算法
输入:人行横道宽度s,人行横道上沿纵坐标y上,人行横道下沿纵坐标y下,每帧车辆入点纵坐标yi,限速v限
输出:车辆是否超速
记录yi-y下由正变负的时间点t1和yi-y上由负变正变化时的时间点t2;
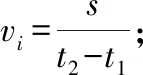
比较vi与v限,
若vi≤v限,输出车辆未超速
否则,输出车辆超速
判断礼让行人示意图如图6所示。
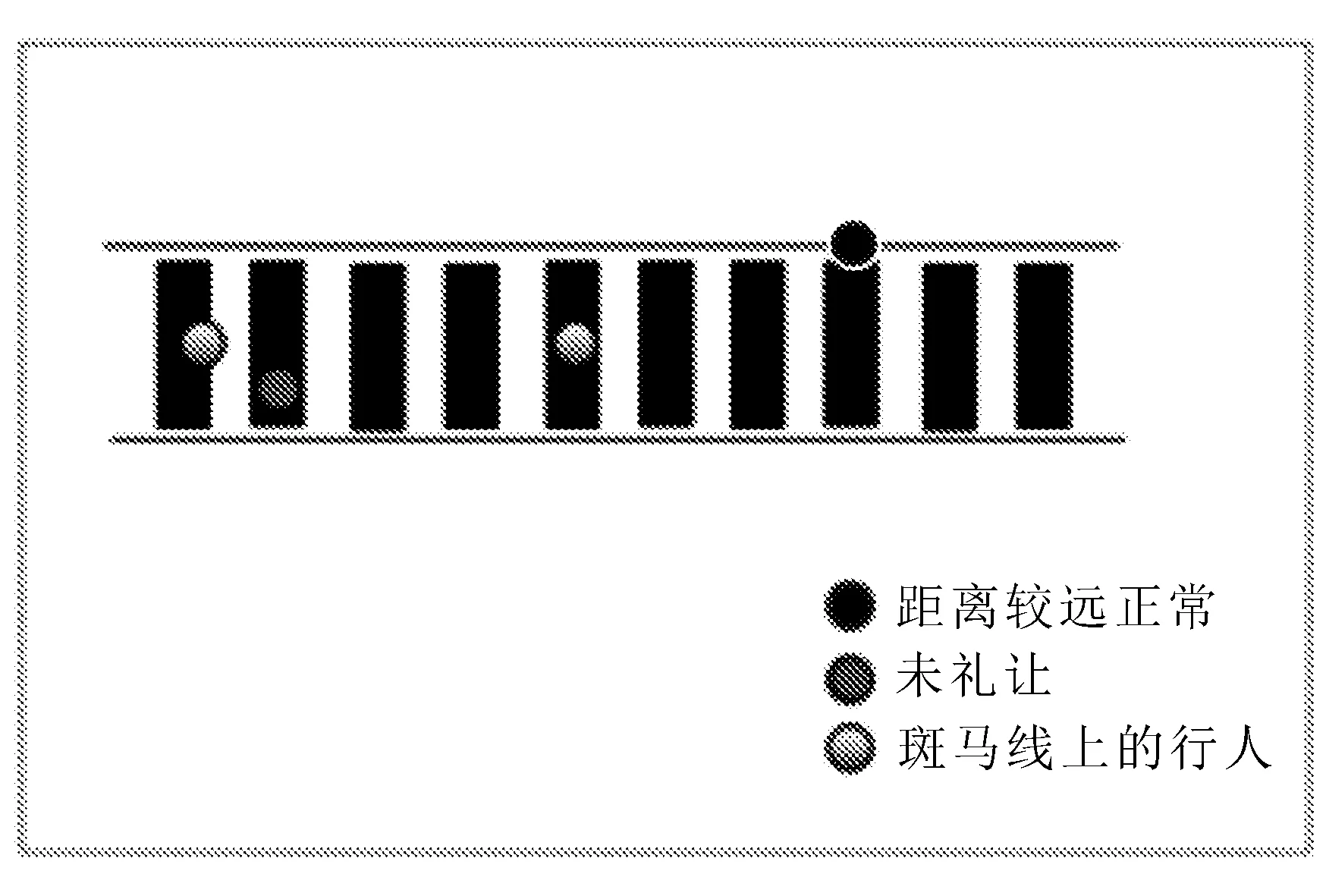
图6 判断礼让行人示意图
车辆是否礼让行人与距离密切相关,通过计算车辆与行人之间的距离判断行人在人行道上,还是在人行横道的区域内。人行道的行人无须判断,而对于在人行横道上的行人,如果车辆与行人的距离过近,则触发车辆未礼让行人的事件。
车流量计数示意图如图7所示。

图7 车流量计数示意图
车流量计数是通过判断车辆点与中心线之间的关系实现的。车辆通过中心线则记录,无论哪个方向驶来的车辆都会加入车流量计数的行列。算法方面则是通过判断当前点是否比中心线纵坐标大或者小来判断车辆是否通行。如果有小到大或者大到小的变化,则可将车辆加入计数中。
2 实验结果
为了配合YOLO以及其他功能的实现,系统整体使用Python语言实现。前台使用PYQT绘制界面并提供交互,使用OpenCV读取视频文件,VideoCapture获取视频帧用于分析。系统产生的信息用json格式进行存储,便于日后的读取和进一步分析。
系统对路口视频进行测试的结果如图8所示。

图8 视频分析结果
系统可以正确识别车辆、行人、非机动车、信号灯,模型mAP均值见表2。

表2 各模型mAP均值
绘制车道线后可以识别出车辆压线、未礼让行人等违反交通规则的行为,并将违反交通规则的瞬间进行取证保存以备查看。
系统将数据输出到主面板的视频显示窗口,以及主面板的速度显示窗口、车速检测窗口、车流量统计窗口、红绿灯显示,违章显示窗口显示YOLO前端检测的车辆、车牌、红绿灯等信息的数据结果,为用户提供最为直观的数据。
3 结 语
交通场景智能识别是现代智能交通系统重要组成部分。首先对摄像机拍摄的车辆图像或者视频图像进行处理分析,得到每辆车的车牌号码,从而完成识别过程。文中实现结合基于深度学习的智能交通, 从车辆压线检测、距离判断等方向进行研究, 并根据实际应用环境进行具体的分析工作, 对检测算法与物体重识别算法进行了论述。研究成果能够帮助管理者实时掌握交通整体运行态势,有效地维护道路交通秩序, 特别是交通违规行为识别,对于实现智慧交通可视化管理具有较强的实用价值。将计算机视觉技术应用于实际工程场景,对于维护交通安全和城市治安,防止交通堵塞,提升道路通行效率有现实意义。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
新传奇(2021年32期)2021-09-22
意林(2021年5期)2021-04-18
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
扬子江(2019年1期)2019-03-08
中国人民公安大学学报(自然科学版)(2018年2期)2018-01-14
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
小天使·四年级语数英综合(2015年4期)2015-04-20
