
基于Skyline的建筑设计数据挖掘方法
2022-11-24 02:29:16李晓飞
长春工业大学学报 2022年3期
李晓飞
(吉林建筑科技学院 计算机科学与工程学院, 吉林 长春 130114)
0 引 言
建筑设计案例对建筑师具有非同寻常的重要价值。数据信息的迅速传播,建筑网站的数量以及建筑设计案例的数量急剧增长,积累了海量的数据。大数据时代的到来,对于建筑设计师从互联网中挖掘建筑案例,并获取有价值的信息造成了一定障碍。如何准确快速地从海量建筑案例中找出建筑师需求的有价值的案例并实现设计创新,将会很大程度缓解建筑设计师数据挖掘困难的问题。
提高数据挖掘性能的关键技术之一是对检索进行优化。因此,对于数据挖掘问题来说,找到一个最优挖掘计划,成为数据挖掘研究中一个重要内容[1-2]。
构建一个多连接检索树是对一个数据库进行最优检索成本最低的。为了解决对大型数据库的检索进行优化的问题,国内外学者提出了很多检索优化算法[3-6]。传统的检索优化算法使用全搜索算法,该类算法只适用于数据库中对象的连接关系数量较少时,当数量较大时,检索速度和效率很低。而大数据环境下,数据库中的检索连接量都很大。为了解决此问题,相关学者提出了动态规划算法进行优化,但查询效率依旧较低[7-8]。Chen Z等[9]提出R-Tree索引结构,该结构解决空间最近邻问题,索引结构利用MBR对空间进行了分割,使空间利用率达到50%。此后,Qusdtree索引[10]、R-Tree倒排索引[11-12]被陆续提出,对存在的问题进行优化。
基于上述问题以及建筑设计案例的特点,提出一种基于Skyline算法的建筑设计数据挖掘方法,针对数据库查询特点进行了索引结构的构建,并优化了Skyline算法。实验结果表明,该方法提升了建筑设计数据挖掘的执行效率。
1 索引结构构建
针对建筑设计数据挖掘中多关键词匹配效率低的问题,文中构建了一种关键词索引结构KeyTree,如图1所示。
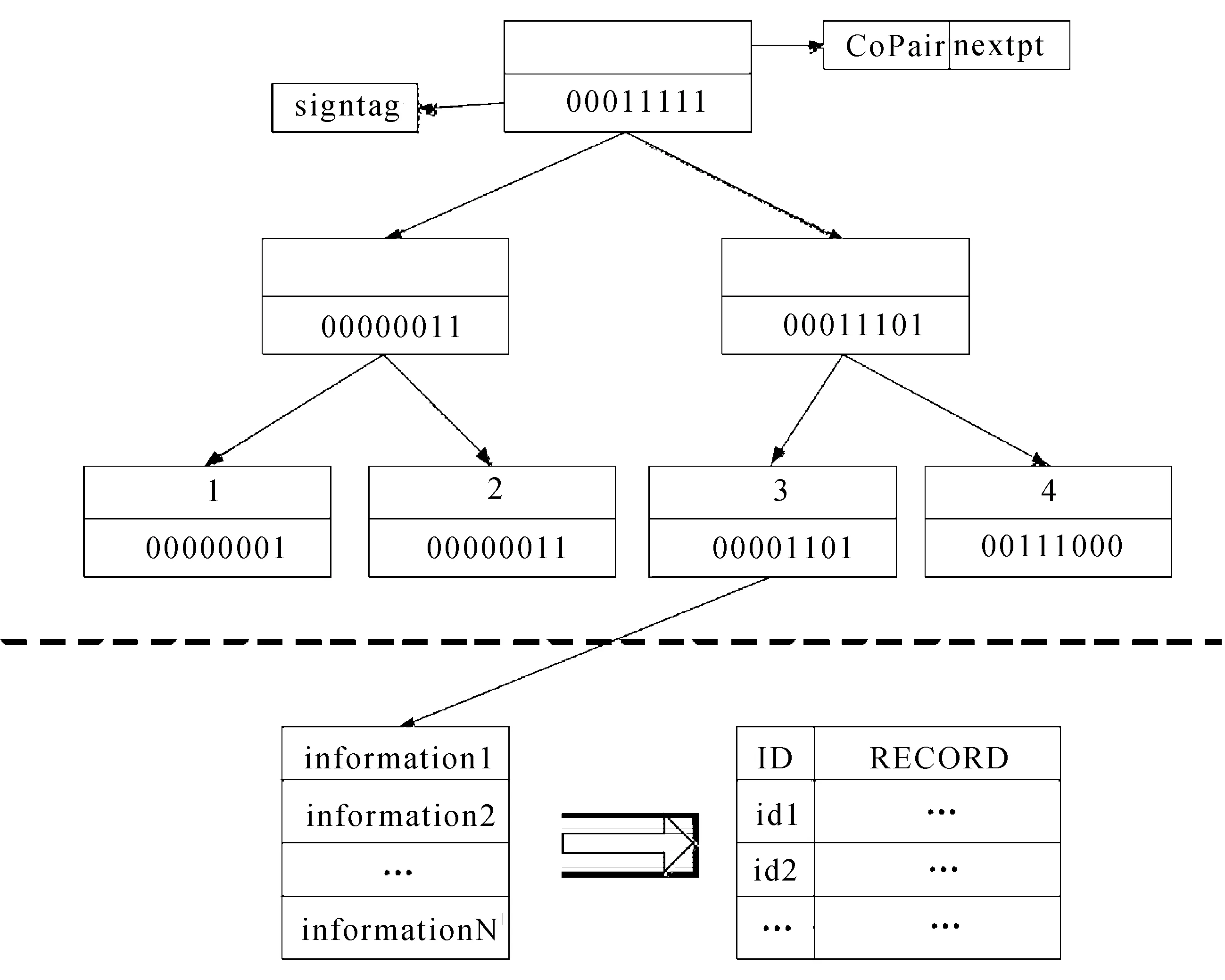
图1 KeyTree索引结构图
KeyTree分为两层:
1)上层索引:在R-Tree索引结构的基础上,对关键词进行了签名设置,将签名信息加入到节点中,从而找到关键词信息与挖掘对象的空间区域关系;
2)下层索引:构建了倒排表的结构,能够反映关键词和挖掘对象信息的映射关系。
上层索引中,
该索引结构关键词签名信息的构建降低了检索过冲中的位冲突概率,此外还可以通过签名信息过滤与关键词无关的检索区域,将无关的信息点进行剪枝。采用倒排索引结构相比于传统倒排结构,很大程度上降低了大数据环境下索引的空间存储容量依赖性。
2 Skyline建筑设计数据挖掘方法
在构建KeyTree索引结构的基础上,提出了基于Skyline算法的建筑设计数据挖掘方法,包括Skyline数据挖掘算法、过滤策略和关键词挖掘判定算法。
2.1 Skyline数据挖掘算法
为了解决多关键词Skyline检索效率问题,基于KeyTree索引结构,提出了Skyline数据挖掘算法----KTSL算法。
KTSL算法在对KeyTree索引遍历的过程中,上层索引通过比较关键词位置信息与查询关键词信息,算法对数据信息文本集合进行过滤。
在下层索引中,对叶子节点进行遍历,通过位之间的快速运算获取满足检索关键词的数据,从而获得相关区域的候选集。基于KeyTree索引的Skyline数据挖掘算法如下:
KTSL算法:
输入:检索点p,检索关键词p.k,检索范围W,数据信息集S,KeyTree索
输出:结果集OT
过程:
1. TempS←{ };TS←{ };
2. While !Node.isEmpty() do
3. NS←Node.pop( )
4. if NS.isInRange(p.k,W) then
//检索关键词p.k与检索范围W匹配
5. if NS.isLeaf() then
6. TS←getSet(p.k)
//获得满足检索关键词的集合TS
7. for ts in TS
8. TempS←CSkyline(TempS,TS,p.k,W)
9. else
10. Node.push(NS.getChild());
KTSL算法中,首先以栈的形式维护KeyTree上层索引节点中未被访问的节点,然后判断检索区域,当检索到叶子节点时,则采用倒排索引计算符合检索条件的集合TS;最后,循环调用CSkyline(TempS,TS,p.k,W)方法,支配判定关键词,生成新的中间结果集TempS。
2.2 过滤策略
由于中间结果集TempS和候选集合TS之间的关键词支配判定的计算,导致CSkyline(TempS,TS,p.k,W)方法比较耗时且操作频繁。为此,文中进行了空间优化,通过过滤策略提高挖掘效率。
通过验证发现:
①s1,s2为区域关键词对象,对∀s1,s2∈TS,若s1,s2之间不能构成支配关系,则s1,s2必定不构成区域关键词信息支配。
②如果某个区域关键词对象存在关系,si∈TS,并且关键词对象的加权距离小于中间结果集TempS中距离检索点最近的关键词对象点,则si一定属于TempS。
基于上述定义,采用如下过滤策略:
1)Min过滤法。设置一个小顶堆结构,堆顶对象tp为中间结果集TempS中距离检索点p加权距离最近的对象点。然后判断候选对象点ts的加权距离,如果小于tp,根据②,则ts∈TempS。根据此规律,在后续计算中只需要判定关键词支配关系,并且直接对中间结果集中未被ts支配的点删除即可。
2)Sum过滤法。根据数值型对象的属性,过滤的判定依据为关键词的数值和。设s为关键词对象点,∀s在N维属性上的过滤公式为
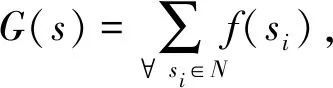
(1)
式中:G(s)----过滤值。
该方法的时间复杂度为O(1),在算法开始执行时,采用Sum过滤法对支配关系进行判定。对于∀s1,∀s2,若G(s1)G(s2),则表明s2在N维属性上不可能支配对象s1。因此,如果对象点s1与s2无关键词支配关系,根据①可以得到s1和s2不存在支配关系,就不需要在循环中继续进行计算,对其进行直接剪枝操作,算法的执行效率得到有效提高。
2.3 关键词挖掘判定算法
通过上述优化,得到的关键词挖掘判定算法CSkyline算法如下:
输入:中间结果集TempS,候选对象ts,检索关键词p.k,检索范围W
输出:中间结果集TempS
过程:
1.TempS←getHeapTop(TempS);
2.if dt(ts,s) < dt(tp,s) then
3. KeyDetele(TempS, ts); //删除TempS中所有被ts支配的点
4. insert ts into TempS;
5.else
6. for tp in TempS from the Stack do
7. if G(ts)≤G(tp) then
8. if ts∉Zhiper(TempS) then
9. continue;
10. else if dt(ts,s) 11. delele tp from TempS; //删除SP中被c支配的点sp 12. else 13. if tp∉Zhipei(ts) then//不构成文本支配 14. continue; 15. else if dt(tp,s) 16. break; 17. if tp=NULL then //指向堆末,表明遍历完所有对象 18. insert ts into TempS; 在CSkyline算法中,前4行采用Min过滤法对集合对象进行剪枝,6~9行采用Sum过滤法判定关键词对象的支配关系;10~11行主要对中间结果集中被支配对象进行删除操作。 为验证该算法的可行性,主要从数据集大小、数据集维度、关键词数量三个方面对算法性能影响进行了实验验证。 为了评估所提出方法的性能,数据集同时使用了合成数据集和真实数据集进行验证。合成数据集是用标准数据生成工具,生成完整数据集,然后随机生成不完整的数据集功能。真实数据集采用中外建筑案例形成的数据库,主要包括公建和住宅两大类建筑案例数据信息,每一条数据包括23个属性,其中17个属性是可比的,数据库中共包含1 627个元组。 文中采用两个指标评估算法的性能,响应时间和结果集的大小。在建筑设计案例数据库中设计了一个实验,与INKS算法[13]和STD算法[14]进行比较,为建筑案例信息数据的每个维度设置了不同的权重,以获得不同的Skyline算法结果。 实验主要分析了执行时间随数据集大小的变化。数据集大小对算法性能的影响如图2所示。 从图2可以看出,随着数据集中元组的增加,CSkyline算法的执行时间近似呈指数增长,而INKS 算法和STD算法的执行时间约占CSkyline算法的10%。STD算法的初始执行时间与INKS算法相近,STD随着数据集大小的增加,算法的执行时间逐渐低于INKS算法的执行时间。 图2 数据集大小对算法性能的影响 结果集的大小随数据集大小的变化,实验结果如图3所示。 图3 数据集大小对结果集的影响 CSkyline算法产生的结果集中元组数量较少,可以减少额外元组的数量。 为了验证关键词数量对算法性能的影响,实验对建筑设计案例数据库进行部分抽取,数据维度为4。在检索点q区域坐标一致的情况下,关键词数量由1增加到10的算法执行时间的变化如图4所示。 图4 关键词数量对算法性能的影响 可以看出,文中CSkyline算法在关键词较高的时候,明显优于其他两种算法,多关键词匹配上采用签名信息,并利用hash函数进行映射,有效提高了多关键词时的挖掘速度。 数据集维度对算法性能的影响验证采用独立的数据集,数量为200 K,维度为2~8维,查询关键词数量为4,检索区域坐标随机产生。 数据集维度对算法性能的影响如图5所示。 图5 数据集维度对算法性能的影响 从图5可以看出,STD算法和INKS算法随着维度逐渐升高,算法的检索时间逐渐变长,算法性能逐渐下降。CSkyline算法由于进行了剪枝操作,前期减少了无效对象点之间的匹配计算时间,所以随着维度的逐渐增加,计算开销没有明显增大。维度为8时,计算开销约为STD算法的1/3。 针对大数据时代下建筑设计师从互联网中挖掘建筑案例,并获取有价值的信息效率低的问题,提出一种基于Skyline算法的建筑设计数据挖掘方法,针对数据库查询特点构建了索引结构KeyTree,加入了签名信息,降低了检索过冲中的位冲突概率,过滤了与关键词无关的检索区域,将无关的信息点进行剪枝。在索引结构KeyTree的基础上,提出了多关键词挖掘算法CSkyline算法。实验结果表明,该方法有效提升了建筑设计数据挖掘的执行效率,并能够有效解决建筑设计案例中多关键词Skyline检索问题。3 实验结果及分析
3.1 数据集
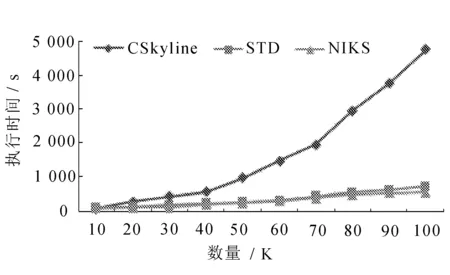
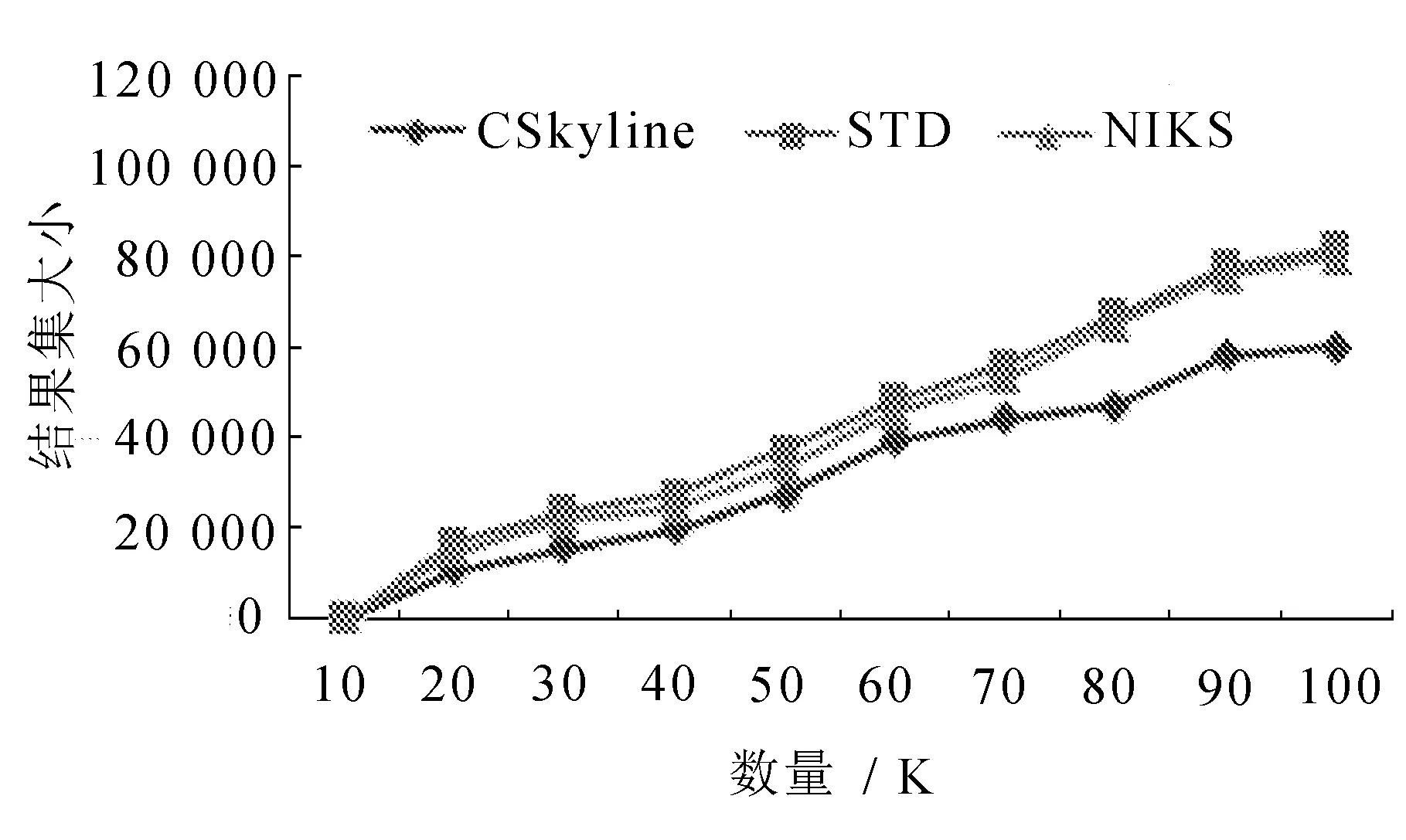
3.2 数据集大小对算法性能的影响
3.3 关键词数量对算法性能的影响
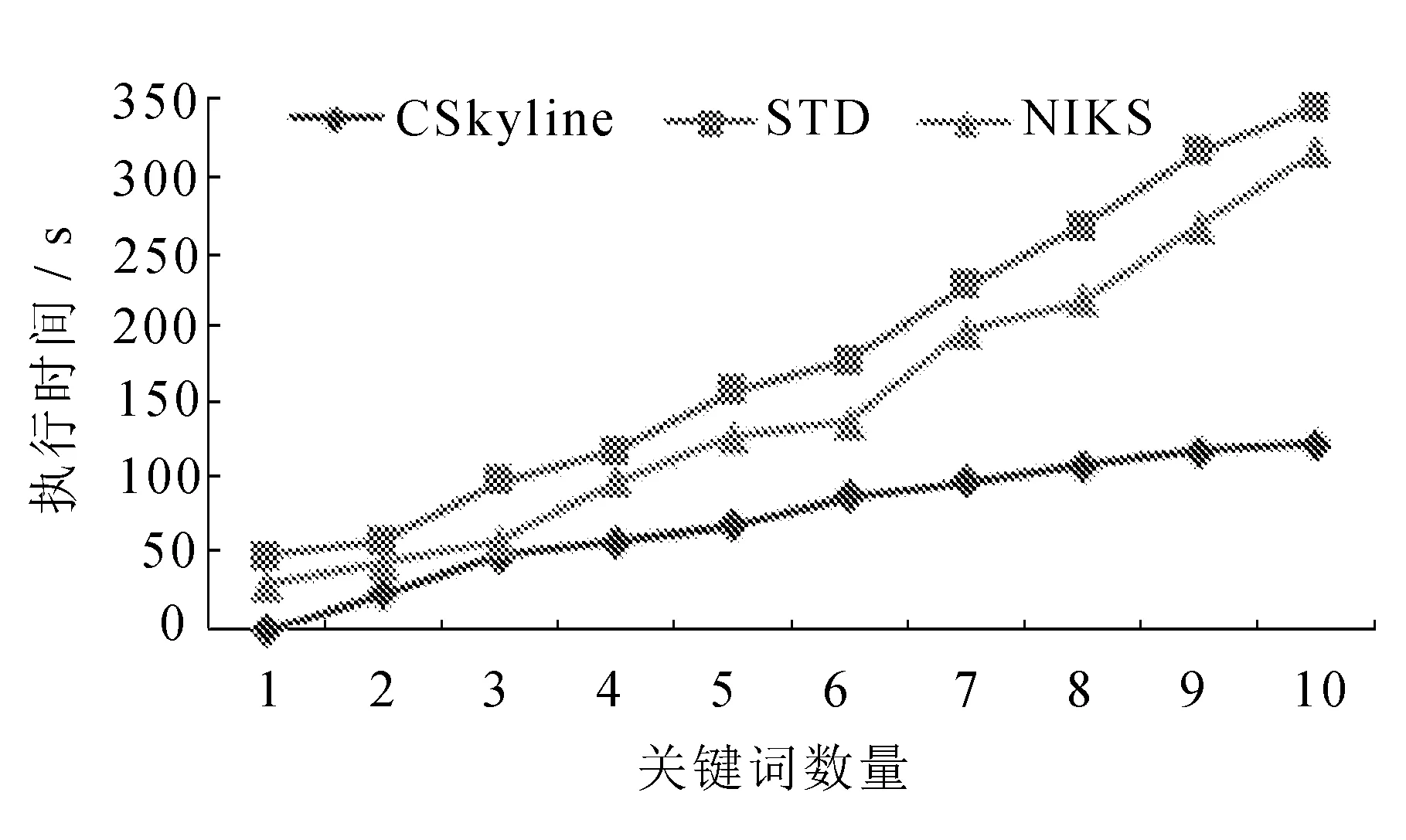
3.4 数据集维度对算法性能的影响
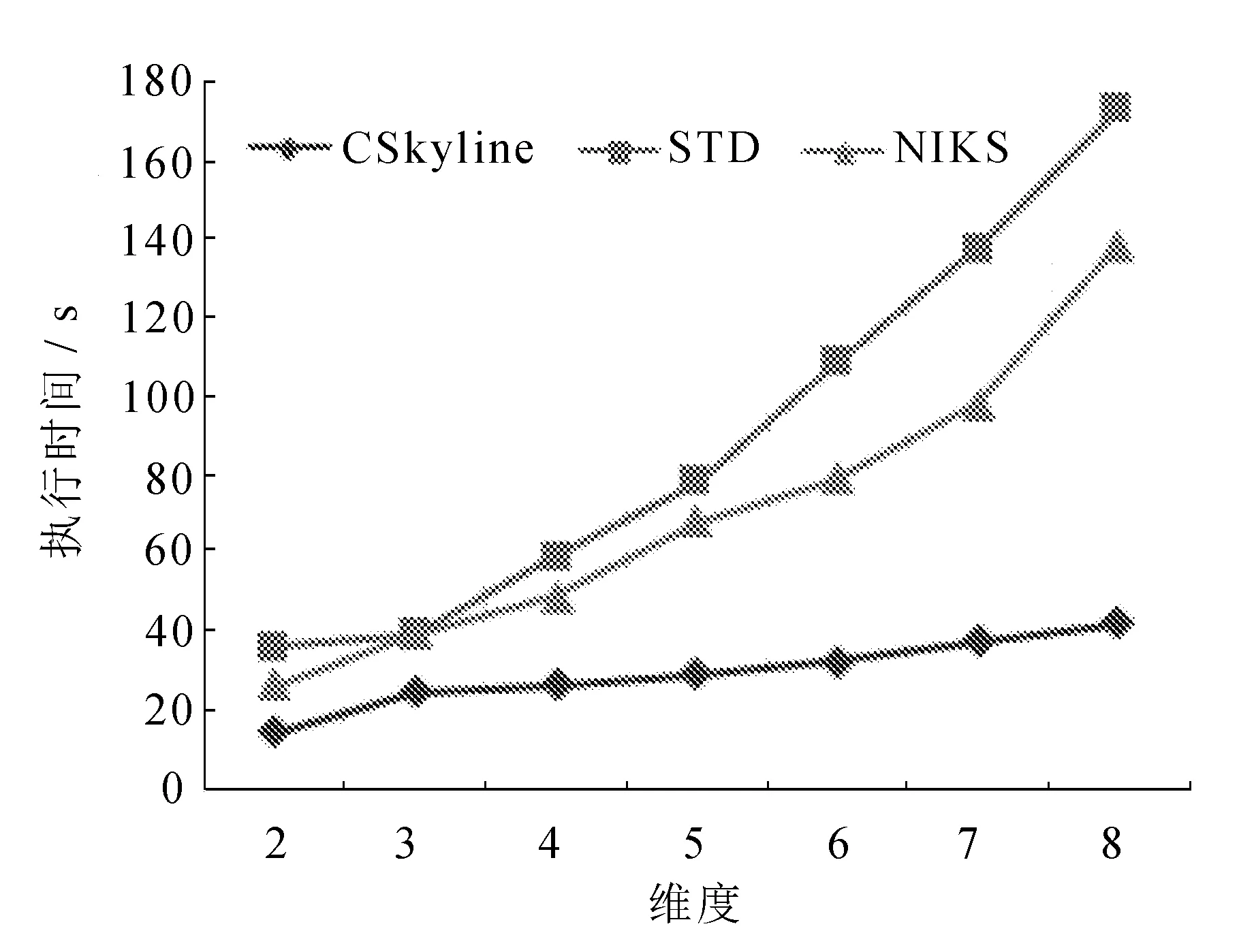
4 结 语
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26建材发展导向(2019年10期)2019-08-24 06:25:04意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46现代装饰(2017年9期)2017-05-25 01:59:43电力与能源(2017年6期)2017-05-14 06:19:37专利代理(2016年1期)2016-05-17 06:14:36中国房地产业(2016年2期)2016-03-01 01:25:34信息通信技术(2015年6期)2015-12-26 01:16:46河南科技(2014年11期)2014-02-27 14:10:05电子设计工程(2014年18期)2014-02-27 12:00:13
