
基于时空序列的Conv-LSTM 航班延误预测模型
2022-11-08 12:43屈景怡杨柳陈旭阳王茜
计算机应用 2022年10期
屈景怡,杨柳,陈旭阳,王茜
(1.天津市智能信号与图像处理重点实验室(中国民航大学),天津 300300;2.中国民用航空华北地区空中交通管理局 天津分局,天津 300300)
0 引言
近年来,随着国内航空业发展迅速,客流量逐渐趋于饱和,航班延误问题也因此面临着巨大挑战。造成航班延误的因素有很多种,而任何程度的航班延误都会给航空公司、机场和旅客造成一定的损失。精确的航班延误预测可以为大面积航班延误响应机制提供参考,使民航相关部门提前做好应对机制,以降低延误带来的损失,因此航班延误预测具有重要的应用价值。随着航班数据的不断积累,基于大数据的航班延误预测方法也应运而生。
航班延误预测的目标是对于某一特定机场,在相对较短的时间内预测其未来一段时间的延误水平,因此涉及时间和空间两个维度。在时间维度上,当发生大面积航班延误时,此时前一架航班的延误会导致一段时间内的后续航班延误,造成机场内的航班积压。针对时间维度上的航班延误预测问题,已有国内外学者进行了大量研究,多采用循环神经网络的一系列算法,文献[1-6]中分别采用了经典的长短时记忆(Long Short-Term Memory,LSTM)网络和改进后的双向长短时记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络对航班延误进行分类或回归预测。其中文献[3]中通过多步预测和时空相关性的联合挖掘,引入时间注意力机制和辅助特征构建预测模型。文献[5]中在Bi-LSTM 网络的基础上加入注意力机制来预测未来的航班延误状况。
但是,上述算法仅聚焦于航班延误在时序上的影响,均未能有效提取航班数据中包含的空间信息,而航班数据中的空间信息对预测算法也十分重要。
卷积神经网络(Convolutional Neural Network,CNN)是有效提取空间信息的算法之一,因此许多研究成果也基于空间维度展开。文献[7-13]中分别提出了几种基于不同卷积神经网络的延误预测模型:文献[10]中在航班数据中结合机场天气数据,扩充了数据集的特征数,然后通过区域残差结构提取数据空间特征;文献[10]中通过卷积提取空间特征来预测地铁站的拥堵情况;文献[12]中采用通道和空间注意力机制来加强网络结构深层信息的传递。鉴于卷积神经网络的模型在提取空间特征上具有优势,气象数据的加入也为卷积的实现提供了可能。
虽然已有同时考虑时空两方面特性的预测方法,但目前已有预测方法多为两种或多种算法的结合,存在算法间的融合问题。因此本文提出了一种基于时空序列的卷积长短时记忆(Convolutional LSTM,Conv-LSTM)网络航班延误预测模型,在提取数据中时序性的基础上,加入气象数据扩充特征列,通过卷积操作同步提取数据的空间信息,以此充分利用样本内隐含的空间特征和样本间的时序特征来进行算法的迭代学习。然后,针对国内4 个机场的航班数据对所提模型的有效性进行了验证,并讨论了气象因素和序列长度对延误状态的影响。
在获得模型预测结果之后,本文设计了一个航班延误分析可视化系统。目前国内外构建可视化主要有两种方式:客户端/服务器(Client/Server,C/S)和浏览器/服务器(Browser/Server,B/S),其中B/S 架构具有丰富的可视化模块,本文将基于此架构选择Java 语言和Web 技术进行航班延误预测系统的开发。该系统利用航班信息和气象数据,根据模型预测的结果并提供历史航班数据统计和可视化功能。
1 航班延误预测模型
航班延误预测模型一共由三部分组成,分别是:输入模型时的数据预处理、网络的训练以及输出模型时的分类和预测。其中网络训练部分将在第2 章中做详细描述。
模型整体结构如图1 所示。其中预处理模块主要融合航班与气象数据,对融合后的数据进行编码并转换维度,以适应网络的输入;模型训练模块负责进行网络的搭建,学习训练网络参数并保存模型;分类和预测模块输出各个延误等级的概率值并返回最终的预测结果。
1.1 模型输入
在深度学习算法中,输入模型的数据集是至关重要的一部分,高质量的数据集可以使模型性能大幅提升。
在原始数据输入神经网络进行训练之前,首先需要数据预处理,预处理过程由数据清洗、数据融合、数据编码和序列化四个部分组成。经过数据处理后,所有变量将转变为数值型变量并统一做归一化处理,然后对其通过滑窗划分时序,使得数据同时具有时序性特征,整个数据预处理流程如图2所示。
1.1.1 数据集介绍
本文使用的数据集为华北空中交通管理局提供的4 个国内机场的航班与气象数据,分别是北京首都机场、北京大兴机场、天津滨海机场和石家庄正定机场,样本量分别为305 万、79 万、107 万和59 万条,数据记录时间为2019 年9 月至2020 年10 月。
航班数据包含“航班号”“飞机型号”“起降时间”“起降机场”“高度”和“速度”等23 个特征。
气象数据每分钟记录一次,包含“跑道视程”“降雨量”“温度”和“风速”等49 个特征。
为了更好地描述航班延误在时间维度上的影响,图3 展示了一段天津机场2019 年10 月1 日10∶00~14∶00 航班延误时间统计情况。图3 记录了这段时间内27 架航班的延误时长,从图3 中可以看出,当第一架航班发生延误时,会对短时间内后几架航班的延误造成较大影响,但随着时间的推移,后续航班的延误时间在逐渐减小,这说明航班延误的影响只存在于与之相邻的几架航班之中,而延误影响的航班数量就涉及网络模型中时序这一参数的选择。
1.1.2 数据预处理过程
1)数据清洗和标注。
当数据中缺失关键特征时,本文采用的方法是删除整条航班或气象数据;当数据含有异常值时,用特征的平均值来进行填充。由于本文选择的神经网络为有监督的算法,因此清洗数据后,需要对训练集数据进行标注。
2)数据融合。
将数据的特征完整、多样化地放入模型中,有助于神经网络更充分地提取特征之间的信息。本文将航班数据和气象数据做融合,扩充数据集特征列,丰富了样本的多样性。此外,融合气象数据会大幅增加样本量,起到数据增强的作用,使得数据集更匹配网络模型。在融合之前,需要提取关联主键,以此作为融合的依据。首先提取航班数据的计划起飞时间,然后提取天气的记录时间,将两个时间同时作为键值进行融合,即当两个时间相同时,将这两条航班和气象数据合并为一条。这样就得到了在航班计划起飞的时刻下,带有此时气象信息的一条航班数据。
3)数据编码。
为了消除不同特征列维度之间的影响,输入神经网络的数据往往需要将数据集编码到同一量纲下,做归一化处理,使得神经网络更好地学习数据之间的关联。由于融合后的数据中包含数值型特征和离散型特征,本文对这两种特征分别采用了不同的编码方式,数值型特征采用MinMax 归一化编码,离散型特征采用Catboost 编码[14]。
4)序列化。
由于航班延误数据之间存在短期的时间相关性,因此本文将输入数据构造为一个时间序列,序列化过程如图4 所示。首先将数据集E按记录时间排序,得到数据集Et,然后使用序列长度为L的滑动窗口进行滑动分割,每次向下滑动1 个数据,得到一个新的长度为L的时间序列数据Enew。使用序列数据中最后一次飞行数据的标签作为网络模型的输出。
构建出时序样本之后,需要对样本做数据集的划分,按照一般经验,本文训练集和验证集的样本量划分比重为8∶2。
1.2 模型输出
经过数据预处理后,将模型的输入转化为张量以适应Conv-LSTM 网络的输入维度。表1 列出了Conv-LSTM 网络输入输出的参数结构,初始输入维度为(15,72),即经过序列化后得到的15 条数据作为1 个样本,每个样本包含72 列特征,经过维度转换后得到(15,8,9,1)的四维数组,其中最后一个维度为滤波器个数。
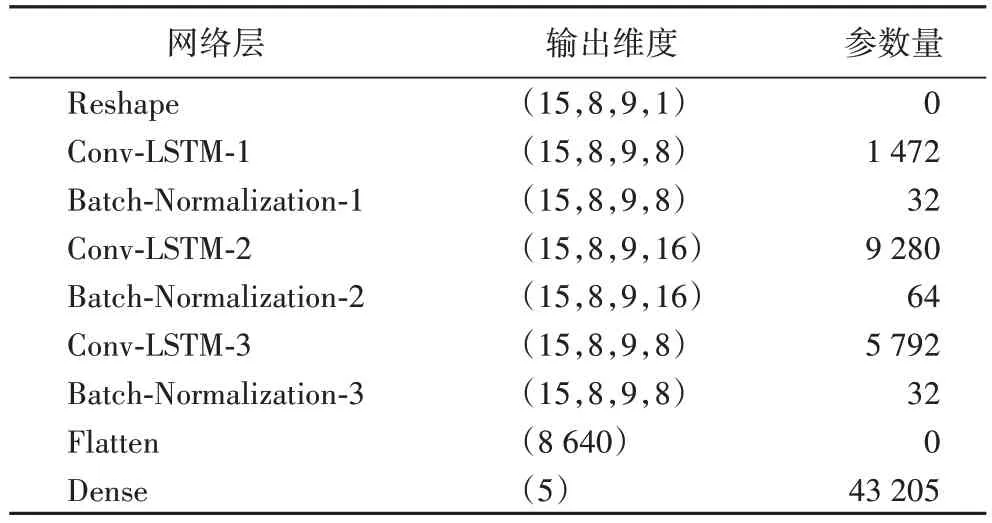
表1 网络结构组成和参数量Tab.1 Composition of network structure and number of parameters
对于模型输出维度的划分,本文参照中国民用航空局规定的15 min 内为不延误的标准,将航班延误状态按时间分为不延误(小于15 min)、轻度延误(15~60 min)、中度延误(60~120 min)、高度延误(120~240 min)、重度延误(240 min以上)5 个等级。
在神经网络模型充分学习数据的特征后,将通过全连接层的Softmax 激活函数对输出结果进行分类预测,损失值通过交叉熵函数Categorical_Crossentropy 计算,其计算公式如式(1)所示,其中“I”在本文中的取值为5。
为了评价Bi-LSTM 和Conv-LSTM 网络模型在航班延误预测问题中的准确率,本文采用的评价标准为:
其中:N是验证集中的数据量;acc代表模型预测的延误等级与实际延误等级相同的数量;precision是整个模型的准确率。在预测阶段,本文将使用未经过网络训练的测试数据集,调用训练集保存的编码参数以及保存的模型对测试集进行编码以及预测,预测后返回各个等级的概率值,并将其中最大概率输出为最终的预测结果等级。
2 Conv-LSTM网络
2.1 网络描述
LSTM网络[15]是循环神经网 络(Recurrent Neural Network,RNN)的一种改进算法,广泛应用于时间序列问题。由于航班延误的短期时序性,通过LSTM 网络对航班延误数据进行迭代学习,可以有效利用航班序列中前序延误对当前航班延误的影响。Bi-LSTM[16]衍生自LSTM 网络,在LSTM 网络改善循环神经网络中梯度消失的基础上,Bi-LSTM 可以进一步考虑序列前后每个时间的延误信息,而不仅仅是当前时间之前的延误信息。
图5(a)为LSTM 单元结构示意图。从图5(a)中可以看出,LSTM 网络增加了多个门控结构,在每个序列索引位置t都含有一个遗忘门、输入门和输出门,此外还增加了一个隐藏状态C作为备选的更新状态。
LSTM 的记忆功能主要依赖于结构单元的中间状态。中间状态ht的更新由两部分组成:第一部分是输出门;第二部分由隐藏状态Ct和tanh 激活函数组成。
Bi-LSTM 的结构如图5(b)所示,以虚线框处的时刻t为例,将输入xt和前一时刻的中间状态ht同时输入正向LSTM层和反向LSTM层,得到中间层的输出:正向和反向,然后对这两个输出按权重相乘得到网络最终的输出yt。计算公式如式(3)~(5)所示:
其中:w1~w6是每个输入xt和中间层ht的权重参数。
Conv-LSTM 网络[17]在Bi-LSTM 的基础上,对输入层和隐藏层加入卷积操作来提取空间特征。对于航班数据这类结构化数据,首先需要进行维度转换,本文将2D 的数据格式根据特征总数转化为一个尽可能方正的3D 数据,然后将转换后的数据和权重参数进行卷积,以此作为网络结构中三个门控结构以及隐藏状态的输入。
Bi-LSTM 的每一层输入都来自上一层的输出,层与层之间采用全连接的方式;除此之外,每一层的结构中,前后时刻的样本将同时输入进隐藏层和下一层网络。Bi-LSTM 的网络结构如图6(a),Conv-LSTM 输入输出的结构[17]如图6(b)所示。
Conv-LSTM 的核心和Bi-LSTM 一样,将上一层网络的输出作为下一层网络的输入。不同的是Conv-LSTM 加入卷积运算后,不仅可以提取时序特征,还可以通过卷积操作提取空间特征。此外,网络状态之间的转换也变成卷积操作,其单元结构公式如下:
其中:wf、wi、wo和wC分别代表网络中输入门、遗忘门、输出门和中间状态的权重参数矩阵;bf、bi、bo和bC分别是三个门控结构和中间状态的偏置项;“*”表示卷积运算;“◦”表示Hadamard 矩阵乘积。
2.2 网络反向传播
搭建好网络结构之后,将进行模型的训练和验证,模型的训练过程一般使用损失值作为目标函数,其代表的物理意义是在有监督的算法中,预测值与真实值之间的误差大小。随着训练迭代次数的增加,如果误差越来越小,则代表训练效果越好,因此损失值将随着训练过程的进行而不断降低。
在1.2 节的介绍中,本文使用的目标函数为交叉熵损失函数,由于模型的最终输出是5 类航班延误预测等级,属于分类问题,而交叉熵函数正适用于深度学习中的分类问题。该目标函数的计算公式如下:
其中:I表示航班延误的分类个数,本文中I的值为5表示网络预测值;y表示网络标签值。五分类激活函数采用Softmax 激活函数,其公式如下所示:
其中:zj表示经过Softmax 前的输出的5 个分类神经元之一。
模型的反向传播过程是通过对前向传播得到的损失函数对z进行链式求导,如式(13)~(16)所示。由此不断更新每一层的参数w和b,最终得到一个趋于收敛的损失值,此时模型达到最优。
整个前向传播和反向传播的流程如图7 所示。
此外,由于深度学习一般将数据集划分为训练集和验证集,每一轮训练都将通过上述前向传播输出整个数据集的平均损失值,将训练和验证的损失值是否同步减小作为标准,再经过反向传播对网络模型中的参数不断调整,最终得到适合该网络结构的一套参数。
3 实验与结果分析
本章将介绍实验环境和基本参数,并通过不同维度对比验证模型的性能。
3.1 实验环境
实验环境处理器为Intel Xeon E5Mu1620,GPU 内存为11.92 GB,操作系统为Ubuntu16.04(64 位),深度学习开发环境为Tensorflow 1.10.0,实验环境所需参数如表2 所示。

表2 实验环境参数Tab.2 Parameters of experimental environment
3.2 气象数据对准确率的影响
气象数据可以扩充数据特征,增加样本的多样性,为卷积的实现提供可能。表3 列出了石家庄正定机场融合与不融合气象数据的准确率对比。
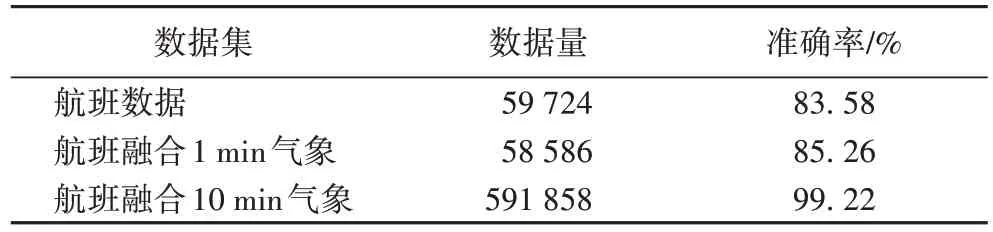
表3 气象数据对准确率的影响Tab.3 Influence of meteorological data on accuracy
在1.1.2 节介绍的数据融合中,本实验采用了两种融合方法:一种是按照时间精度为1 min 融合航班和气象数据;另一种按精度为10 min 融合。实验结果表明,在航班数据中添加1 min 的天气数据后准确率略有提高,而融合10 min 天气数据准确率有较大幅度提高。分析原因如下:
一方面,以1 min 为时间精度融合气象的数据集只增加了特征列,以实现卷积操作,但是以10 min 精度融合气象不仅增加了特征列,还大大增加了数据量。与一条航班信息对应融合一条气象数据相比,该方法一条航班融合了10 条气象数据,使数据集扩大了近10 倍。在增加样本多样性的同时,也解决了数据集小但模型复杂导致的过拟合问题。
另一方面,融合10 min 的气象后,每条航班相当于加入了前后10 min 之内的10 条气象数据,因此网络可以学习更多数据之间的相关性,使得预测的分类结果更加准确。
3.3 序列长度对准确率的影响
序列长度是循环神经网络系列中的一个重要参数。由于航班延误与时间相关,本节将讨论序列化过程中序列长度对网络结果的影响。本文测试了9 个不同的步长参数,使用的数据集为石家庄正定机场的航班和气象数据,最终得到的准确率如表4 所示。
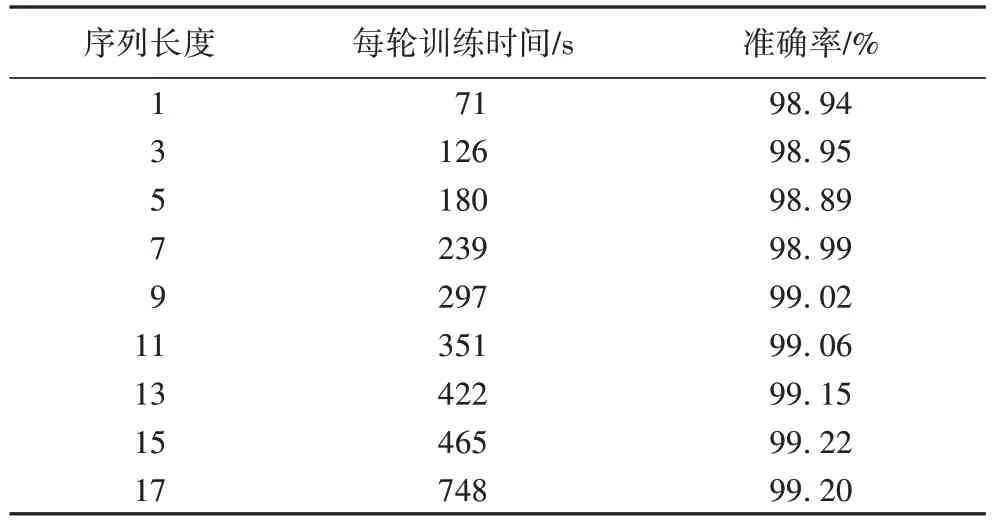
表4 序列长度对准确率和训练时间的影响Tab.4 Influence of sequence length on accuracy and training time
表4 列出了随着序列长度的增加准确率的变化,对比发现,并不是序列越长,准确率越高,当步长为15时,准确率达到最高值。在步长较短时,准确率呈上升趋势,而步长为17时不但准确率略有下降,训练时间也大幅增长。
随着步长的增加,过长时间后的航班状态对当前时刻的航班是否延误的影响已经较小或是消失,因此网络会学习到无关信息,造成数据冗余,导致准确率降低;此外,更长的时间序列会消耗更多的训练时间。从表4 中几组数据的对比可以看出,15 是较为合适的时序长度取值,因此,本文将序列长度取值为15 作为后续实验的基本参数。
3.4 不同模型的准确率比较
本节将通过3 种不同网络模型的训练准确率,对比讨论本文算法相较于单独的时序网络和卷积网络的优势,以及时序信息和空间信息分别在神经网络学习中所起的作用。
使用4 个国内不同机场融合10 min 的气象后的航班数据作为数据集,列出了3 种不同网络,以及同一种网络3 种不同层数下,网络模型的验证集准确率对比,其中包括二维卷积(Convolutional-2 Dimention,Conv-2D)网络模型,1~3 层的LSTM 网络模型以及1~3 层Conv-LSTM 网络模型。实验结果如表5 所示。

表5 不同数据集上各模型准确率对比 单位:%Tab.5 Accuracy comparison of different models on different datasets unit:%
表5中,ZBAA、ZBAD、ZBTJ 和ZBSJ 分别为北京首都机场、北京大兴机场、天津滨海机场和石家庄正定机场的地名代码。各机场融合气象后的数据总量分别为305 万、79 万、107 万和59 万条。从表5 中可以看出,在不同机场的数据集中,Conv-LSTM 网络的准确率都比单独使用时间序列网络LSTM 或卷积网络Conv-2D 更高。与LSTM-3 相比,Conv-LSTM-3 增加了卷积部分,准确率平均提高了0.65 个百分点。与Conv-2D 相比,Conv-LSTM-3 增加了时序部分,准确率平均提高了2.36 个百分点。
图8 展示了石家庄正定机场数据集下3 种网络模型的准确率曲线。从图8 和表5 中都可以看出,由于Conv-LSTM 网络中包含时序信息的保留以及卷积特征的提取,相较于单独使用时序网络或者卷积网络,模型收敛时的准确率都更高。
在Conv-LSTM 网络中,本文通过实验尝试了3 个不同数量的网络层数。对于含有LSTM 结构这样的复杂网络,3 层网络层已经是一个非常庞大的网络结构模型,从表5 可以看出,3 层Conv-LSTM 网络的准确率最高。
3.5 不同模型的损失值比较
损失值是评估神经网络模型是否拟合良好的重要参数,和准确率相对应。当准确率升高,损失值降低,相反则损失值上升。图9 展示了3 种不同网络及同一网络不同层数训练时的损失值下降趋势。
图9 中所展示的曲线为验证集的损失值下降趋势图,本文中训练集与验证集曲线拟合良好,在每个网络参数调整至最优的情况下,将不同模型的验证集损失值曲线进行了对比。
本节同样展示了石家庄正定机场融合10 min 气象后的航班数据,训练集样本量为80%,验证集样本量为20%,模型训练轮数为100 轮。
通常情况下,损失值越小,准确率越高,表示训练效果越好。从图9 可以看出,每个网络模型中,训练集和验证集的损失值下降平缓,且拟合良好,符合一般深度学习模型的下降规律,其中Conv-LSTM3 层网络的损失值最低,达到了0.028 7。
4 航班延误预测系统
该系统是为空中交通管制部门开发,将安装在中国民用航空局华北空中交通管理局,空中交通管制中心的流量管理室,其系统架构如图10 所示。
4.1 预测系统介绍
本文航班延误预测系统包含5 个模块。
1)获取航班信息。系统数据的导入采用离线导入方式,前端提供数据的导入接口,并通过数据库管理数据。
2)深度学习(Deep Learning,DL)算法模块。基于深度学习模型的航班延误预测算法,主要完成气象和航班信息的融合,实现模型的训练和航班延误预测。
3)数据库管理系统(Data Management System,DMS)。建立基于MySQL 的数据库,负责航班信息和气象信息的查询,并管理其他终端的数据访问操作。
4)航班延误信息处理(Flight Delay Information Processing,FDIP)。负责接收航班和气象信息,对航班延误信息进行查询和统计分析,调用航班延误预测算法获取预测结果,并将结果转发到航班延误服务终端进行可视化显示。
5)航班延误服务终端(Flight Delay Service Terminal,FDST)。完成对历史航班延误数据的查询和统计分析,展示航班延误预测的结果,并将预测结果按延误程度进行排序。
4.2 航班延误界面
对深度学习算法进行封装后,使用Socket 调用训练好的航班延误预测模型,系统后端为客户端,算法为服务端。
系统启动后,算法端监听可视化系统后端发送的请求,前端获取用户上传的航班调度信息,由后端解析航班数据上传至算法服务器,然后将航班数据发送到航班延误预测模块进行数据处理和预测,最终得到预测的每条航班的延误等级。预测结果通过Socket 返回到系统后端,再到前端接口,最后存储到数据库中。
5 结语
本文基于国内航班与气象数据提出了一种同时考虑了时空序列,基于Conv-LSTM 网络的航班延误预测模型,Conv-LSTM 算法可以充分提取数据中的时间序列和空间信息,有利于神经网络的深度学习。本文的主要结论如下:
1)航班延误预测问题是一个时空预测问题,只有在某一特定空间中,其延误状态才具有时序相关性,因此本文中将考虑的空间限定为某一单个机场,在这一特定空间下,引入时序的网络模型对延误状态进行预测,并通过卷积操作提取数据中隐含的空间信息。Conv-LSTM 与经典的时序LSTM 网络以及卷积CNN 相比,能够同时提取数据中的时间序列特征和空间特征,因此可以在训练时获得更高的准确率。
2)航班延误状态具有短期的时间相关性,因此时间序列的长度是Conv-LSTM 网络中的一个重要参数,当输入序列过长则延误影响会降低,造成数据冗余,序列长度过短会导致输入数据中包含的信息量和神经网络结构不匹配,模型无法正常拟合。对于本文中选用的四个国内机场数据集,当序列长度为15时,模型的性能最好。
3)气象因素是造成航班延误的重要影响因素之一,因此气象数据也是航班飞行数据中的重要组成部分,它包含的特征列中含有许多关于航班状态的有效信息。加入气象数据之后,整个数据集的特征变多,卷积网络可以发挥更大的作用,准确率也会相应提高。
后续研究将围绕特征工程展开,如何通过提升数据集的质量来提高模型准确率,并研究实现回归模型预测具体的延误时间。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
金桥(2021年10期)2021-11-05
金桥(2021年9期)2021-11-02
金桥(2021年8期)2021-08-23
金桥(2021年7期)2021-07-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
