
基于多视角多监督网络的无人机图像定位方法
2022-11-08 12:43周金坤王先兰穆楠王晨
计算机应用 2022年10期
周金坤,王先兰,穆楠,王晨
(1.武汉邮电科学研究院,武汉 430074;2.四川师范大学 计算机科学学院,成都 610101;3.南京烽火天地通信科技有限公司,南京 210019)
0 引言
无人机(Unmanned Aerial Vehicle,UAV)作为遥感平台之一,相较于卫星和飞机,具有操作性强、便利性高、云层影响度低、数据采集能力强[1-2]等特点,广泛应用于各个领域,如植被细分[3]、车辆监测[4]、建筑提取[5]等。然而,当定位系统(如全球定位系统(Global Positioning System,GPS)、北斗等)不可用时,如何有效地进行无人机定位及导航是一项巨大的挑战。近年来,跨视角地理定位(cross-view geolocalization)在自动驾驶和增强现实的潜在应用,为无人机定位及导航任务提供了新思路。它能够将无地理标记的图像与数据库中有地理标记的图像进行匹配,进而实现无人机的定位和导航任务[6],如图1 所示。图1 中A 表示给定无人机视图,查询对应卫星视图,执行无人机定位任务;B 表示给定卫星视图,查询对应无人机视图,执行无人机导航任务。
作为跨视角地理定位的主要研究方法,跨视角图像匹配(cross-view image matching)是将不同视角(如地面、无人机、卫星视角)的同场景图像进行跨视角匹配的一种方法。其早期研究主要基于地面视图之间的图像匹配[7-9];然而由于地面图像存在遮挡严重、视野有限、覆盖范围小等问题,导致匹配效率过低。相比之下,附带全球地理位置标记的空中视图(包括无人机视图与卫星视图)具有地面视图不可取代的优越性,如无遮挡、变化小、覆盖面广;因此,将地面视图与空中视图进行匹配从而实现地理定位的方式逐渐成为主流[10-13]。此外,由于地面和空中视图之间视点的剧烈变化,导致严重的空间域差(domain gap)问题,使得传统的手工特征方法如尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)[14-15]和加速鲁棒特 征(Speed Up Robust Feature,SURF)[16]很难提取到复杂且具有辨识力的视点不变特征,跨视角图像匹配仍具挑战性。
随着深度学习在计算机视觉任务中取得较大的成功,大多数跨视角图像匹配工作开始采用卷积神经网络(Convolutional Neural Network,CNN)来解决空间域差问题[17-20]。现阶段,实现该任务的CNN 方法大体可以分为两种。
第一种是基于度量学习(Metric Learning)的方法,该方法将跨视角图像匹配视为图像检索领域的子任务,旨在通过网络学习出两幅图像的相似度。Tian等[19]利用建筑物作为地面视图和卫星视图之间的桥梁,进行视点图像匹配,技术上首次提出通过孪生网络来匹配K个最相似的图像,并通过对比损失(Contrastive Loss,CL)来度量图像间的相似度。Hu等[21]基于孪生网络和网络局部聚集描述子向量NetVLAD(Net Vector of Local Aggregated Descriptors)[22]提出CVM-Net(Cross-View Matching Network),他们使用三元组损失(Triplet Loss,TL)进行相似度训练,首次在跨视角地理定位任务实现了稳定的rank1 指标性能。Regmi等[23]基于条件生成对抗网络(Conditional Generative Adversarial Nets,CGANs)[24]提出了一种图像生成方法来减小两个视图之间的视觉差异,此外他们采用加权软边界三元组损失(Weighted Soft Margin triplet loss,WSM)[21]来辅助训练。该方法可以从相应的地面视图图像生成看似合理的空中视图图像,然后进行匹配。Cai等[25]采用注意力机制,将空间和通道注意力嵌入特征图,并使用硬样本重加权三重损失(hard exemplar reweighting triplet loss)来进行训练。该类方法通常使用的数据集(如CVUSA(Cross-View USA)[17]、CVACT[26])在目标位置通常只有一个图像对(每个视图只有一张图像)。当相同目标地点的不同视角图像作为同类来进行跨视角图像匹配任务时,基于度量学习的第一种方法是行不通的。
第二种是将跨视角地理定位任务当作分类问题来看待,旨在将不同视图的特征映射到同一特征空间进行分类匹配,一般使用ID 损失(identification loss)进行训练。Zheng等[6]使用3 个CNN 分支,基于建筑类别标签在其提出的数据集University-1652[6]上实现了卫星视图、无人机视图、地面视图间的匹配,成功验证了无人机定位和导航任务的可行性。Ding等[27]将卫星视图和无人机视图放在同一支网络进行分类任务,专注于无人机和卫星视图的匹配任务。Hu等[28]考虑到相机风格的偏差,采用基于色阶的方法来统一图像风格样式,此外他们还采用网格划分的方式来进行局部特征(Local Features,LF)对齐。
然而以上两种方法将跨视角图像匹配任务割裂地看成了度量学习任务[19,21,23]或分类任务[6,27-29],依然存在着网络参数量过大、图像表征特征单一、训练难以收敛等缺点;并且,现有大多数方法均只对全局特征(Global Feature,GF)进行表征,忽略了局部特征带来的上下文信息。
此外,现有跨视角图像匹配方法主要针对空中视图(包括卫星视图)和地面视图,且目标地点仅具有单个图像对。这些方法并未考虑到卫星视图和无人机视图间的相似性,因此难以应用于卫星视图和无人机视图之间的跨视图图像匹配任务。
为了解决现有方法所存在的度量任务和分类任务割裂、表征特征粒度不均匀、采样不平衡等问题。本文提出了一种新的基于多视角多监督网络(Multi-view and Multisupervision Network,MMNet)的无人机定位方法,来学习跨视角图像匹配中不同视图的全局特征和局部特征,从而实现无人机定位和导航任务。MMNet 采用孪生网络架构,有两个CNN 分支,分别用于学习卫星视图和无人机视图。且每个CNN 具有两个子分支,分别用于提取全局特征和局部特征。为了充分融合度量学习和分类任务的训练特性,并学习到两个视图间的视点不变特征,采取了多监督方式进行训练。具体来说,在对全局特征向量进行分类监督的基础上,进一步对卫星和无人机视图执行非对称相似性度量,该任务采用了新提出的重加权正则化三元组损失(Reweighted Regularization Triplet loss,RRT)。最后,使用加权策略来整合全局特征和局部特征,来表征目标地点的多视角图像,从而实现无人机定位和导航任务。
本文的主要工作为以下5 个方面:
1)提出了MMNet 来解决无人机定位和导航问题,其能够在统一的网络架构中,通过加权的方式将卫星和无人机图像的全局粗粒度信息和局部上下文信息进行多视角聚合,学习到兼具细粒度的视点不变特征,从而更完整地表征目标地点图像。
2)MMNet 在跨视角图像匹配领域首次采用RRT 与ID 损失融合的多监督训练方式来执行相似性度量任务和分类任务,兼具度量学习和分类学习的优点。
3)MMNet 在训练过程中综合考虑了上下文模式,充分利用目标建筑周围的环境,以端到端的方式学习目标场景的上下文信息。
4)提出了多视角平衡采样(Multi-view-based Balanced Mining,MBM)和重加权正则化策略,MMNet 能够有效缓解卫星视图和无人机视图的训练样本失衡问题,在实验中验证了其有效性。
5)MMNet 在最新提出的无人机数据集University-1652 上进行了大量实验验证,MMNet 相较于现有的跨视角图像匹配方法在各项指标中均取得了最优性能。
1 多视角多监督网络
本章主要介绍了所提出的多视角多监督网络MMNet(如图2 所示)。首先阐述MMNet 的网络结构和特征提取方式,然后针对数据集的多视角样本失衡提出RRT,最后通过多监督方式联合ID 损失和RRT 训练出更有区分度的特征,从而实现无人机定位和导航功能。
任务描述为:给定无人机地理定位数据集,x和y分别表示输入图像及对应的类别标签,下标m表示数据源xm的来源平台,其中m∈{1,2},x1表示卫星视图,x2表示无人机视图。标签y∈[1,C],其中C为类别总数。本文实验所用数据集为University-1652,训练集共含有701 栋建筑物,且每栋建筑物包含多张图像。将701 栋建筑分为701 个索引,每个索引代表一个类别,即标签y∈[1,701]。对于跨视角图像匹配,MMNet 通过学习一个映射函数,可以将来自不同平台的图像映射到一个共享的特征空间中,同一索引图像间距离非常近,而不同索引的图像彼此间距离会被拉开。
1.1 多视角网络架构
所提出的MMNet 基于孪生网络架构,包含两个分支(如图2 中C1 和C2 所示),分别用于卫星视角和无人机视角的图像匹配。鉴于每个分支权重共享[6],MMNet 可以使用任何预训练网络架构(如VGG[30]和ResNet[31])作为骨干网。本文采用了经过微调的ResNet-50[31]作为每个分支的骨干网。ResNet-50 包含5 个模块:Conv1、Conv2、Conv3、Conv4、Conv5、一个平均池化层和一个全连接层。具体来说,舍弃了平均池化层及后续网络层,并将Conv5_1 的步长由2 更改为1。
为了训练MMNet,首先将输入图像的尺寸调整为256×256。其中卫星视角和无人机视角分支具有相同的特征提取方式,当图像经过改进的ResNet-50后,可以从多视角网络分支提取到维度为2 048 的中间特征图,用于后续的分类和度量学习。将此层映射记为Fbackbone,多视角特征提取过程可表征为:
其中:fm表示输入图像xm的输出特征图。每个视角在骨干网后分别设置了全局子分支和局部子分支来学习各视角的全局特征和局部特征。
为了提取细粒度特征,本文在全局分支中采用了一种可自学习的广义平均(Generalized-Mean,GeM)池化[32],该池化层融合了最大池化和平均池化的优点,能捕获到特定领域的区分特征。fm在经过GeM 池化后,提取得到全局特征gm∈R1×2048。GeM 池化公式如下:
其中:fk表示特征图,k表示通道方向上的位置序号,k∈{1,2,…,K};Xk表示特征图中各个通道层的激活图,其尺寸为W×H;Pk表示一个可训练超参数,其在全局分支中初始化为6,并通过反向传播不断更新学习。对于上述操作,当Pk→∞时,GeM 池化等价于最大池化;当Pk→1时,GeM 池化等价于平均池化。最终,利用RRT 联合训练卫星视图和无人机视图的全局特征,将多视角映射到同一个特征空间。
在局部分支中,为了充分利用上下文信息,采用方形环切割策略[29]来切割特征图fm。观察到,目标地点通常分布在图像的中心,而上下文信息辐射性地分布在其周围。基于这种语义信息分布的假设,方形环划分的中心可以近似地对准特征图的中心。如图3 所示,根据到图像中心的距离将全局特征fm分为4 个部分,获得了4 块环状的特征图,(n=1,2,3,4)。上标n代表从中心算起的第n部分。同样,局部分支也采用GeM 池化操作,将转换成通道数为2 048 的局部特征,Pk初始化为1。该过程可表征为:
其中:Fslice代表方形环划分;Gempool代表GeM 池化操作。随后,MMNet 采用尺寸为1 × 1 的卷积核对进行降维,得到∈R1×512(i=1,2,3,4)。
至此,MMNet 已经获取了各个分支的局部特征以及全局特征。由于特征是从不同的分支中提取的,可能具有不同的分布,不能直接用于匹配。为了突破这一限制,除了利用RRT 将全局特征映射在一个共享空间外,还建立了一个多视角参数共享的分类模块。该分类模块针对局部特征向量和全局特征向量gm分别建立了5 支参数不共享的分类子模块执行分类任务,来预测各自的标签y。这5 支分类子模块结构相同,由以下层构建:全连接层(Fully Connected layer,FC)、批归一化层(Batch Normalization layer,BN)、弃参层(Dropout layer,Dropout)、分类层(Classification Layer,CL)。此处的CL 也是一个全连接层,后接Softmax 函数可将分类特征向量进行归一化。
在训练过程中,利用反向传播来降低损失,并利用Adam优化器来更新网络参数。通过同时最小化RRT 和多支特征的ID 损失之和来优化MMNet。在对所提出的MMNet 进行训练之后,采用加权策略来聚合全局和局部特征进行目标地点图像表示。
1.2 多视角平衡采样策略
针对数据集University-1652 无人机视角和卫星视角样本量极其不平衡(无人机视图与卫星视图的比例为54∶1)的特点,提出了多视角平衡采样(MBM)策略。多视角样本不平衡表示两个视角之间的样本量不平衡,而每个视角的类别数和每个类别的样本数都是平衡的。如果在训练时,按类别随机采样,各视角采样数相同,则导致样本量多的视角出现欠采样问题,同理,样本量过少的视角易出现过采样问题,因此网络会偏向于出现过采样问题的同视角样本之间的分类任务学习。如果各视角采样比例等同于数据集视角间样本量比例,则会导致网络倾向于样本量多的一方的同视角分类任务学习,从而使网络忽略掉了跨视角视图间的匹配学习。
本文提出的MBM 策略,根据不同视角总样本量的比例,进行一个折中的采样比例设置。根据经验,初始化时将比例γ设为3。即每次批量采样,每个目标地点的卫星视图与无人机视图的采样量之比为1∶3。
1.3 重加权正则化策略
三元组损失(triplet loss)已被广泛应用于各种图像匹配任务,包括人脸识别[33]、行人重识别[34-35]和图像检索[36-37]。三元组损失目标是训练网络将正样本拉近锚点,同时将负样本推开。最简单的三元组损失为最大边界三元组损失(maxmargin triplet loss),公式如下:
文献[21]中为了提高网络训练的收敛速度,提出了加权软边界三元组损失,该损失设置了一个缩放系数α,公式如下:
其中:正样本和负样本有着相同的权重,致使下降梯度的幅度相同。这意味着正、负样本将会以相同的方式和力度被拉近或推开。在实践中,无人机视图相较于卫星视图更易收集,导致数据集University-1652 中无人机视图数量要远高于卫星视图数量。在前文中提出了用MBM 策略来减轻多视角样本不平衡的影响。在该策略下,每一个训练batch 中都会存在比例为γ∶1 的无人机、卫星视图分布,所以在梯度下降的过程当中,应该采取两个优化策略:1)以无人机视图聚类为锚点,将同类别间的卫星视图聚类,相较于将聚类逐个拉向单个卫星图锚点会更容易;2)尽可能拉近同类别间的距离,而不是推开负样本,因为将少数匹配的样本拉到锚点附近比将所有负样本推离锚点更容易。基于上述优化策略,采用重加权的方法,调整正负样本间的不同权重,可以更好地缓解多视角样本不平衡的问题。
此外,上述三种三元组损失均是采用硬样本批量采样策略,即在每个批次中,只选取最远的正样本和最近的负样本组成一个三元组,计算一次三元组损失。该策略仅仅捕获了少量且具有丰富信息的样本,却忽略了大量的常规样本,同时还破坏了原本特征空间样本的分布结构。鉴于此,根据每对样本间的学习难度赋予不同的权重,且不引入任何边界余量。具体来说,即对于距离越远的正样本和距离越近的负样本对,赋予更高的权重。该策略能够保持原样本间的空间结构,降低计算复杂度,更有利于收敛。RRT 函数如下:
其中:(i,j,k)表示每次训练批次中的三元组;对于每张图像i,Pi是与之对应的正样本;Ni是与之相对应的负样本分别表示正负样本对之间的距离分别代表每个正负样本对的正则化权重。如果设置较大的αn,负样本对的梯度随着损失优化会快速下降,意味着只能将负样本对推开小段距离。对于较小的αp,正样本对的梯度则会缓速下降,会迅速将正样本按特征空间距离比例拉向锚点。当正样本数远少于负样本时,例如只有一个卫星正样本的无人机定位任务中,将唯一匹配的正样本拉近锚点比将所有负样本推开更容易,因此本文可通过设置一个远小于αn的αp值来验证此猜想。
1.4 多监督联合学习
为了提高视角特征以及类间特征的可区分度,本文使用ID 损失联合学习类间的全局和局部特征,并提出RRT 联合学习视角间的全局特征。因此,MMNet 不仅能执行分类任务,还能执行相似性度量任务。这种针对性的联合学习策略能够同时有效地学习视角间的显著性特征,提高跨视角图像匹配任务中特征可区分度。
1.4.1 分类学习
近年,许多计算机视觉任务如人脸识别、目标检测、行人重识别等都用到了分类的思想,可将该任务看成一个图像分类任务。本文从分类的角度出发,采用交叉熵(crossentropy)损失联合学习全局和局部特征,将无人机定位任务视为图像分类任务来训练MMNet。两个视角分支的不同特征分别进入一个参数共享的分类模块,将所有特征映射到一个共享的特征空间中。通过结合全局特征和4 个局部特征进行分类共享,能够有效将同地点的输入图像聚类。
具体来说,采用MBM 策略,在一个训练批次中,选择P类ID 的目标建筑图像,每类ID 选择γ幅无人机视图,1 幅卫星视图。因此一个批次中,共有P× (γ+1)幅图像。训练过程中,MMNet 将降维后的局部特征和全局特征gm作为输入,通过分类模块后,输出列向量为和zm,分别表征和gm。然后,利用Softmax 函数将输出列向量进行归一化,并且预测各特征的类别。该过程表征如下:
接下来,将交叉熵损失作为损失函数来计算该批次图像中的局部特征和全局特征的ID 损失:
其中:LPid和LGid分别表示整个批次的局部特征ID 损失和全局特征ID 损失。
1.4.2 度量学习
三元组损失常用于跨视角地理定位任务,用于执行全局特征的相似性度量任务。本文将新提出的RRT 应用在MMNet 中的全局特征度量学习。RRT 的重加权策略以及相对距离权重正则化策略能够有效地将同场景的不同视角图像进行再聚类,提升同类图像的相似度。在MMNet中,RRT可表征为:
为了计算最终损失,本文使用多监督加权策略将分类损失和度量损失进行线性聚合:
其中:η是权重系数,按训练经验设定为0.5。
MMNet 融合了全局和局部特征表示目标地点图像,可以用降维后的局部特征hn(n∈(1,2,3,4))来表示局部特征:
最后,MMNet 使用加权策略融合全局和局部特征进行图像表征:
其中:β是控制局部特征重要性的权重系数。
2 实验与结果分析
本章首先介绍大型无人机定位数据集University-1652[6],然后描述了实验设置细节,最后通过对提出的方法进行消融实验以及整体评估,证明了MBM 策略、RRT、多监督联合学习对于无人机定位任务的有效性,同时提供了MMNet 与University-1652 现有前沿工作的比较。
2.1 实验设置
2.1.1 数据集
University-1652[6]是一个多视图多源数据集,包含卫星视图、无人机视图和地面视图数据,其收集了全世界72 所大学的1 652 栋建筑。训练集包括33 所大学的701 栋建筑,测试集包括其余39 所大学的951 栋建筑。训练和测试集中没有重叠的大学。由于一些建筑物没有足够的地面图像来覆盖这些建筑物的不同方面,因此数据集还提供了一个附加的训练集,该附加数据集中的图像是从谷歌地图中收集的,它们具有与地面图像相似的视图。此外,附加的训练集可以作为地面图像的补充。该数据集主要用作两个新任务的研究,分别为无人机定位(无人机→卫星,如图1 中A 所示)和无人机导航(卫星→无人机,如图1 中B 所示)。训练集含有50 218幅图像,共覆盖了701 栋建筑。在无人机目标定位任务中,Query 集含有37 855 幅无人机视图图像,Gallery 集含有701幅可匹配的卫星视图图像和250 幅干扰卫星视图。在无人机导航任务中,Query 集中有701 幅卫星视图,Gallery 集含有37 855 幅可匹配的无人机视图和13 500 幅干扰无人机视图。
2.1.2 实验细节
MMNet 的骨干网采用了微调的ResNet-50,在ImageNet数据集上对ResNet-50 进行了预处理。本文实验中,无论是训练还是测试,输入图像的尺寸均采用256 × 256。在训练时,使用随机水平翻转、随机裁剪以及随机旋转来增加数据的多样性。本文采用多视角平衡采样策略,训练批次设置为32,γ设置为3,即一个批次中随机选取8 类目标地点图像,每类图像包含3 幅无人机视图和1 幅卫星视图。在反传过程当中,本文采用随机梯度下降法优化参数,momentum设置为0.9,weight_decay为0.000 5。骨干网初始学习率设为0.001,分类模块学习率为0.01,80 个epoch 后衰减为原来的1/10,经过120 个epoch 完成训练。对于RRT 中的超参数,按经验分别设αp=5,αn=20。在测试过程中,利用欧氏距离来度量Query 图像和Gallery 集中候选图像之间的相似性。本文在PyTorch 1.7.1 上实现,所有实验都在一个NVIDIA RTX 2080Ti GPU 上进行。
2.1.3 评价标准
本文实验使用召回率(Recall@K,R@K)和平均精准率(Average Precision,AP)来评估性能。R@K代表在Top-K的Ranking List 中的正确匹配图像的比例,较高的R@K表明网络性能较好。AP 代表了精准率-召回率曲线下的面积。分别在无人机定位和导航任务中使用上述两个指标作为实验评价标准。
2.2 前沿方法对比
在University-1652 数据集上进行了广泛的实验,通过和4 个具有竞争性的前沿方法进行比较,来评估本文所提出方法的性能。如表1 所示,与本文方法作对比的4 个前沿方法分别为:实例损失(Instance Loss,IL)方法[6]、LCM(cross-view Matching based on Location Classification)方法[27]、SFPN(Salient Feature Partition Network)方法[38]、LPN(Local Pattern Network)方法[29]。MMNet 在无人机定位任务中(无人机视图→卫星视图)达到了83.97%的R@1 性能和86.96%的AP 性能,在无人机导航任务中(卫星视图→无人机视图)达到了90.15%的R@1 性能和84.69%的AP 性能。
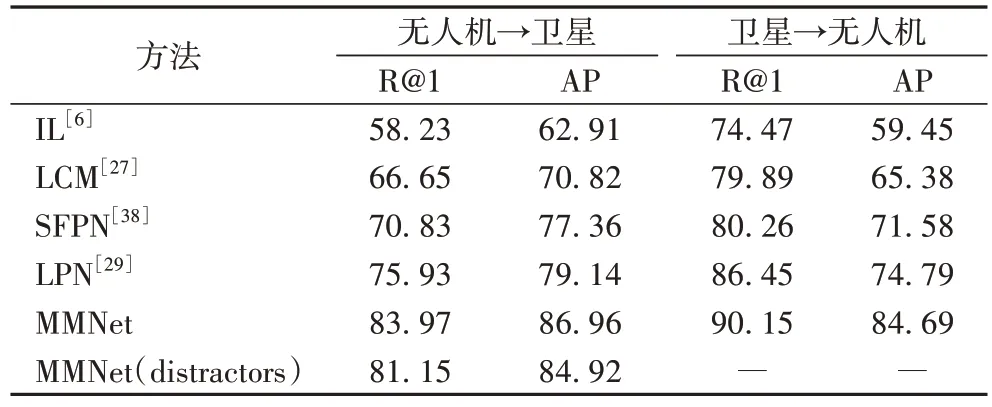
表1 University-1652数据集上本文方法与前沿方法的比较 单位:%Tab.1 Comparison of the proposed method with state-of-the-art methods on University-1652 dataset unit:%
相较于性能次好的LPN 方法,MMNet 在无人机定位任务中的R@1 指标提升了10.59%,在无人机导航任务中AP 指标提升了13.24%,表明MMNet 在University-1652 数据集上的无人机定位和导航任务中都显著优于现有方法。
对于无人机视角地理定位任务,Gallery 中有951 幅卫星视角图像。为了使这项匹配任务更具挑战性,本文从CVUSA 的测试集中收集了8 884 幅卫星图像添加到University-1652 的Gallery 集中作为干扰物(表1 最后一行)。尽管干扰物会降低整体表现,但表1 中R@1 和AP 并没有显著下降,结果仍然具有竞争力。这证明了MMNet 对干扰物的鲁棒性。
此外,在图4 中展示了两个任务的一些检索结果。观察到,无论是在无人机定位还是在无人机导航任务中,MMNet都可以根据内容来检索合理的图像;但图4(a)中第三行展示了一个失败案例,MMNet 并没有成功地匹配R@1 图像。本文发现这项任务仍具挑战性,由于R@1 图像与Query 图像具有非常相似的空间结构特点,两幅图像所含中心建筑的外观尤为相似。
2.3 消融实验
本文在数据集University-1652[6]上评估了MMNet 的各模块性能,各模块均采用MBM 策略进行采样,实验结果如表2所示。在表2中,全局特征(GF)表示仅利用MMNet 的全局分支提取到的特征,即gm来训练网络;局部特征(LF)表示仅利用MMNet 的局部分支提取到的特征,即来训练网络;联合特征(Joint Features,JF)表示联合全局特征和局部特征来训练网络。括号中表示网络训练所使用的损失函数,其中:ID 表示损失函数采用ID 损失中的交叉熵损失,用来学习分类任务;RRT 表示采用本文所提出的RRT,用来学习度量任务。
通过表2 可看出,本文采用的各方法模块如MBM、RRT,多监督联合学习对整个网络的性能提升均有贡献。
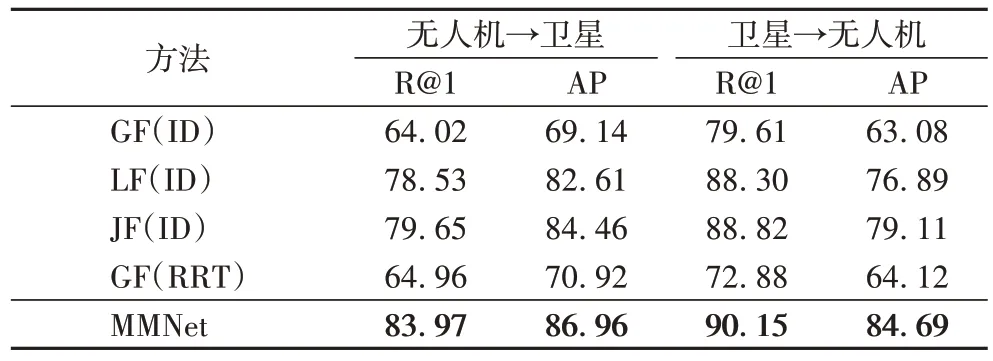
表2 University-1652数据集上MMNet不同模块的比较结果 单位:%Tab.2 Comparison results of different MMNet modules on University-1652 dataset unit:%
2.3.1 多视角平衡采样策略
为了证明所提出的MBM 策略的有效性,在基线上进行了两个对比实验,分别采取文献[6]中的批量挖掘,以及本文提出的MBM。在批量挖掘中,batch_size 设为32,每个batch采样16 个类别的目标地点图像,无人机和卫星视图各一幅图像。由于文献[6]中每类目标地点的无人机视图与卫星视图比例均为54∶1,所以会存在明显无人机视图欠采样问题。此外对于度量任务计算RRT 而言,批量挖掘中每个锚点的正样本均只有一幅,严重影响了损失优化的平衡性。理论上,MBM 可以有效缓解采样中视角图像数量不平衡问题,在特征空间中可以增强无人机聚类,拉近卫星视图与无人机视图的距离。从表3 中数据可以看出,本文提出的MBM 显著提升了MMNet 在University-1652 数据集上的性能。
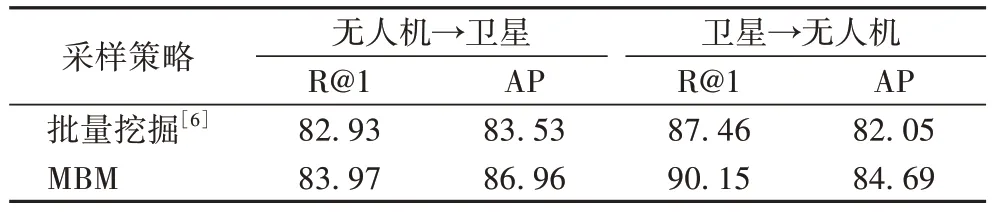
表3 MMNet采用不同采样策略的结果 单位:%Tab.3 Results of different sampling strategies in MMNet unit:%
2.3.2 重加权正则化三元组损失
为了验证RRT 在University-1652 数据集上的有效性。在文献[6]提出的基线上(采用批量挖掘策略)对常用的几种损失如:CL[6]、TL[6]、WSM[21]以及RRT 进行了对比实验,结果如表4 所列。在RRT中,根据经验,设αp=5,αn=20,从而达到了最好的性能,AP 值均得到较大提升。为了能够有效验证重加权策略,在以上RRT 实验的基础上采用MBM 策略,将R@1 和AP 平均提升了2.61 个百分点左右。对于性能提升而言,RRT 采用的重加权策略,以及MBM 策略,均能有效缓解University-1652 数据集的多视角样本不平衡问题,将无人机图像聚类的同时,能够让同地点卫星图像更接近于无人机图像聚类。
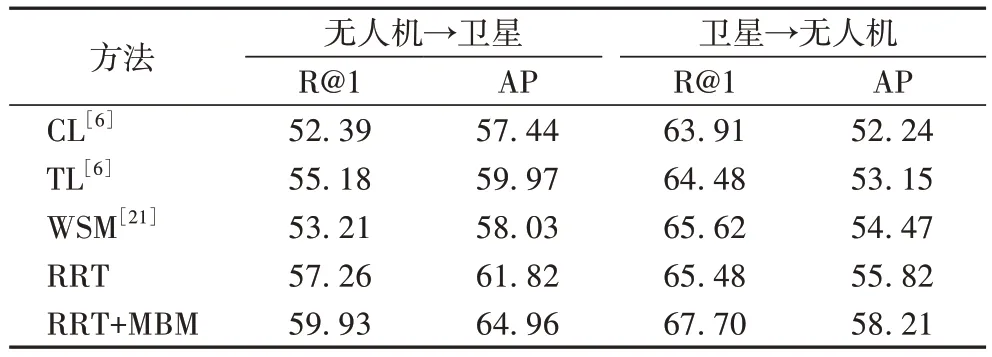
表4 RTT与其他度量损失的比较 单位:%Tab.4 Comparison of RRT with other metric losses unit:%
2.3.3 多监督联合学习
本文所提出的联合学习主要体现在两个方面,分别是全局和局部特征之间的联合学习,以及分类损失和度量损失之间的联合学习。前者能够同时关注全局特征的粗粒度感知信息和局部特征的细粒度上下文信息,做到多粒度信息融合。通过对比表2 中的GF(ID)、LF(ID)和JF(ID)方法可看出,局部特征相较于全局特征能够大幅度提升网络性能。联合全局特征和局部特征的网络能够在局部特征网络基础上兼具粗粒度信息,使网络相较于局部特征训练能够有效地将R@1 和AP 平均提升1.43 个百分点左右。这些数据表明,联合全局和局部特征聚合了多粒度视点不变特征,学习出更丰富的目标地点信息。
在MMNet中,分类任务能够将不同视角的同场景目标地点图像在两个特征空间分别进行聚类,然后通过映射方式实现跨视角图像匹配。相对而言,度量任务则是通过将所有图像映射在一个特征空间,然后拉近不同视角的同场景图像距离,推开异类图像,从而实现跨视角图像匹配任务。简而言之,分类任务专注于同视角间同类场景图像的聚类任务,度量任务专注于不同视角的同场景图像匹配任务。对比表2 中GF(ID)、GF(RRT)、JF(ID)和MMNet 方法的数据,可以看出MMNet 在融合了交叉熵损失和RRT后,显著提升了网络性能,其中在无人机定位任务的R@1 和导航任务的AP指标上分别提高了4.32 和5.58 个百分点。
2.3.4 超参数分析
为了评估β在式(16)中的影响,单独改变β值在MMNet测试中做了单一变量实验,结果如图5 所示,可以看到当β=1时,R@1 和AP 的性能达到最高值。
3 结语
本文基于孪生网络架构提出了一种新的深度学习网络MMNet,用于跨视角图像匹配。MMNet 有效融合了多视角全局和局部特征,学习到兼具粗粒度感知和细粒度上下文的目标地点信息;同时MMNet 联合了分类损失和度量损失进行多监督训练,能够有效互补分类和度量任务中的固有缺陷。对于全局特征,在采用分类损失的基础上,提出了重加权正则化三元组损失,有效缓解了分类损失对于跨视角视图映射较弱的问题。对于局部特征,采用方形环分割策略,将全局特征划分成多个环形部分,从卷积图中学习潜在的上下文信息,并为局部特征执行分类任务。对于University-1652 数据集,本文所提出的多视角平衡采样策略,能够有效缓解该数据集无人机视图和卫星视图样本数量不平衡问题。此外,基于多监督训练方式有效提升了无人机定位和导航任务的跨视角图像匹配性能。在目前流行的无人机数据集上证实了所提出的MMNet 的有效性,相较于现有的前沿方法,显著了提高了无人机定位和导航任务的准确性。
下一步工作将会考虑卫星视图和无人机视图之间的视角转换,让网络自动学习多视角间的视点不变特征的基础上,训练出针对空间域差的自适应视角转换方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
微型电脑应用(2022年3期)2022-04-20
计算机与网络(2020年7期)2020-05-15
现代计算机(2019年19期)2019-08-12
金桥(2018年4期)2018-09-26
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
电脑知识与技术(2016年17期)2016-07-23
