
基于深度语义融合的代码缺陷静态检测方法
2022-11-08 12:43程靖云王布宏罗鹏
计算机应用 2022年10期
程靖云,王布宏,罗鹏
(空军工程大学 信息与导航学院,西安 710077)
0 引言
随着信息技术的快速发展,各行各业对计算机软件的需求不断增加,软件中存在的大量安全缺陷给计算机系统留下了巨大的安全隐患,黑客可以利用某些安全缺陷入侵目标[1]。由于软件规模和复杂度的增加,仅依靠人工检测或常规的检测工具难以保证代码缺陷检测的效率和准确性。因此,实现代码缺陷的快速和准确定位已经成为安全领域的一个关键问题[2]。
代码缺陷检测技术可以分为静态、动态和混合分析方法。静态分析不执行软件或程序,基于源代码的属性特征检测缺陷,具有更高的执行效率和代码覆盖率,但误报率较高;动态分析利用特定输入执行程序,基于软件或程序的行为特征检测缺陷,具有更高的检测精度,但在分析大量代码时执行效率和覆盖率低,且漏报率高;混合分析同时应用静态和动态分析,但也继承了两者的局限性[3]。据通用漏洞披露(Common Vulnerabilities &Exposures,CVE)报告,截至2021年7月,CVE 中记录的漏洞数量已经超过15 万个[4]。面对已经披露的大量安全缺陷和未知的零日漏洞,综合考虑执行效率、代码覆盖率和检测效果等因素,静态分析技术在效率和有效性之间取得了较好的平衡,并能够在早期发现安全缺陷,被广泛应用于代码分析和缺陷检测。但传统的静态分析方法,比如Flawfinder、RATS(Rough Auditing Tool for Security)和Checkmarx 等静态分析工具基于特定规则检测缺陷,难以发现预定义规则之外的代码缺陷[5];基于代码相似性的方法根据代码的重用特性,能够检测涉及精确、重命名、重组和语义克隆的代码缺陷,但依赖于缺陷代码模板的数量和质量,并且对非克隆代码检测效果较差[6-7]。这些静态分析方法依赖于安全专家的经验以及前期繁重的特征工程等技术,其泛化能力较差。
为了提高代码缺陷检测的性能,机器学习[8]和数据挖掘技术[9]已经被用于代码的静态分析,人工智能的发展使得代码缺陷检测和零日漏洞挖掘更加智能化[10]。基于深度学习的方法能够挖掘源代码间的关系,自动学习脆弱代码的模式,通过匹配源代码的潜在特征来实现快速、准确的代码缺陷检测和定位,但以往的研究主要关注程序、包、组件和文件级别的粗粒度特征,难以精确定位缺陷代码的位置[2]。Russell等[11]提出将源代码进行标记的方法,利用卷积神经网络(Convolutional Neural Network,CNN)检测函数级别的代码缺陷,但同时引入了大量与缺陷无关的代码。Zhou等[12]提出了基于图神经网络(Graph Neural Network,GNN)的代码缺陷检测系统Devign,利用源代码的复合图表示来识别缺陷代码的模式,但只能在方法级别定位代码缺陷,并且计算复杂度较高。许健等[13]提出利用抽象语法树(Abstract Syntax Tree,AST)表示源代码的结构和语义信息,并通过滑动哈希窗口进一步减小了方法体的特征维度,但只对整数溢出类型进行了检测。Li等[14]提出根据应用程序编程接口(Application Programming Interface,API)调用和数据流信息进行程序切片,只提取源代码中与缺陷相关的语句,将检测粒度精细到切片级别,并通过双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络来检测代码缺陷,但涉及的缺陷类别只包括缓冲区错误和资源管理错误。李元诚等[15]提出了一种混合深度学习方法,利用深度卷积神经网络快速处理特征数据,并通过门控循环单元(Gated Recurrent Unit,GRU)保留代码间的调用关系,在检测切片级别缺陷时取得了较好的效果,但涉及的代码样本和覆盖的缺陷类型较少。王晓萌等[16]对代码进行反向数据流分析生成后向切片,并融合两种词向量来表示代码令牌,但没有考虑控制流信息。Li等[17]在文献[14]的基础上引入了控制流信息,提出了一种基于最小中间表示学习(Minimum Intermediate Representation Learning,MIRL)的代码缺陷检测方法,根据系统依赖图(System Dependence Graph,SDG)获取源代码的安全切片,构建了连接式CNN 模型提取代码特征,并利用支持向量机(Support Vector Machine,SVM)对特征进行二次训练,但时间复杂度较高。Jeon等[18]提出了AutoVAS脆弱性分析系统,通过提取易损API 和系统调用处的切片进行代码缺陷检测,并综合分析了不同因素对检测性能的影响,但可能漏报易损API 之外的关键点。
针对上述问题,在数据层面,可以采用合适的切片方法,在提取更细粒度代码片段的同时保留足够的信息;在模型层面,可以采用增强或组合的机制最大限度地学习代码中的特征。同时,由于源码中存在代码复用现象,需要对不同缺陷类型进行测试,以评估模型的泛化能力。因此,本文采用基于过程间有限分布子集(Interprocedural Finite Distributive Subset,IFDS)的切片方法,在源代码关键点上获取包含数据流和控制流信息的双向程序切片;同时,通过文本卷积神经神经网络(Text CNN,TextCNN)的多通道机制提取代码切片中的局部关键特征,采用双向门控循环单元(Bi-directional GRU,BiGRU)捕捉切片序列中的上下文序列特征,融合两部分特征作为代码片段的特征表示,用于代码缺陷检测。最后,对比分析了不同的缺陷类型、切片方法、关键点选取和模型等因素对检测性能的影响,并与类似工作进行了对比实验,验证了本文方法在代码缺陷检测上的有效性。
1 方法设计
1.1 方法总体框架
本文提出了基于程序切片和语义特征融合的代码缺陷静态检测方法,将程序切片技术和语义分析用于程序源代码的处理和分析,本文方法的总体框架如图1 所示。
本文方法主要包含以下几个阶段:
1)数据预处理。对源代码中的关键点进行数据流和控制流分析,通过程序切片获取代码片段,规范化代码片段中的变量名和函数名。
2)预训练阶段。将代码片段令牌化,获得最小中间表示(Minimum Intermediate Representation,MIR)[17],用代码令牌(Token)构建代码片段数据集的语料库,通过词向量法训练生成嵌入矩阵。
3)模型构建。将嵌入矩阵作为模型的嵌入层,通过填充或截断的方式将令牌序列转换为固定长度后输入嵌入层,用构建的网络提取特征来训练代码缺陷检测模型。
1.2 数据预处理
从源代码的角度来看,大多数代码缺陷都源于一个引发安全问题的关键点,例如函数、赋值或控制语句。代码缺陷的产生往往是由多条具有逻辑关系的代码语句导致的,在一定条件下,安全缺陷会在某一关键点处被触发。程序源代码中存在大量的代码语句,其中只有部分语句与代码缺陷的产生联系。为了降低无关语句的影响,在更细粒度上检测代码缺陷,本文利用数据流和控制流分析技术,对代码缺陷产生的关键点进行程序切片,获得由多行与代码缺陷相关的代码语句组成的代码片段。
程序切片技术分为前向切片和后向切片,根据代码中关键点函数或变量的特性,需要采用不同的切片技术[19]。本文采用底层虚拟机(Low Level Virtual Machine,LLVM)对C源代码进行分析,获取程序的前向或后向切片,通过采用基于IFDS 的切片方法,在充分考虑源代码中的数据依赖和控制依赖信息的同时,构建函数内或函数间的代码切片。
以图2 所示的源代码为例,代码第9 行snprintf API 函数处会发生缓冲区溢出。第8 行的malloc 函数为变量buf 分配了一个64 字节的内存,当变量str 的大小超过64 字节时,将会导致缓冲区溢出,因此这里选取<9,snprintf(buf,128,"<%s>",str);/*string copy*/>作为关键点。用数字代表对应行号的代码语句,则该关键点数据依赖于{16,19,20,7,8},控制依赖于{14,17,6},通过反向程序切片获取该缺陷的范围为{14,16,17,19,20,6,7,8,9}。从该示例可以看出,虽然缓冲区溢出只发生在snprintf 函数处,但该缺陷的发生与源代码上下文语义存在长依赖关系,多条代码语句按一定的执行逻辑将会导致这一缺陷。因此,在进行代码缺陷检测时,不仅要关注缺陷可能发生的关键点,还要分析可能会导致这一缺陷的上下文信息。通常在易损API 处更易产生缺陷,但两者之间并无绝对联系,代码中某些不当使用的变量被传递到能够导致程序异常或崩溃的点时,缺陷才会体现出来。针对图2 所示的源代码,若以变量为关键点,采用IFDS切片方法可以获得如表1 所示的静态切片表,其中包含了变量及相关的后向或前向切片代码行。

表1 静态切片表Tab.1 Static slice table
源代码中存在大量与代码缺陷无关的语句和单词,比如注释、用户自定义的函数和变量等,它们不会影响程序的执行逻辑和语义,但大量的无关语句和字符串会造成信息冗余,影响代码缺陷检测的效率和准确性。因此,在进行程序切片后,将用户自定义的函数和变量进行统一替换,函数名用FUNC#表示,变量名用VAR#表示,其中#表示函数或变量在代码片段中出现的序号。最后,利用通配符匹配并规范化代码片段中包含“CWE”“good”“bad”等关键字的令牌。通过统一的符号表示,将代码片段进一步规范化,能够减少人为因素对代码缺陷检测效果的影响,同时可以压缩嵌入层中词汇表的大小,降低运算复杂度。
1.3 预训练阶段
对经过数据预处理的代码片段作分词处理,如图2 所示,可以获得每个数据样本的MIR:{“int”,“main”,“(”,…,“VAR3”,“)”,“;”},从而将代码片段转换为类似自然语言的形式。对于一个长度为n的代码片段T1:n,将其用MIR 表示如下:
其中:Ti为代码中的单个Token;⊕为连接符,在代码片段中用空格表示。
深度学习模型无法直接处理代码片段,因此需要将代码片段转换为向量表示,常用的方法有one-hot 编码、词嵌入等方法,但one-hot 使用0、1 编码代码片段中的令牌,生成的是高维稀疏向量,并且没有考虑上下文的语义关系,因此本文采用Word2vec 中的Skip-gram 模型构建嵌入矩阵[20],模型结构如图3 所示。
Skip-gram 的基本思想是通过中心词来预测上下文,进而生成代码Token 间具有语义关联性的向量表示,该模型的优化目标函数是最大化中心词Ti的上下文单词Ti+j的对数概率之和:
其中:q是中心词上下文窗口的大小;n为代码片段的长度。
在嵌入矩阵中存储了每个Token的d维向量表示,MIR经过嵌入矩阵处理后,其向量表示为:
1.4 深度学习模型构建
考虑到代码缺陷的触发与代码中某些关键区域的语句紧密相关,同时代码缺陷关键点与上下文代码存在较长的数据依赖和控制依赖关系,本文融合了TextCNN 和BiGRU 两种模型的优势,构建了联合检测模型,同时提取代码片段中的局部关键特征和上下文序列特征,将两部分特征融合进行代码缺陷检测。TextCNN 通过一维卷积提取句子中类似于ngram 的局部特征,利用不同尺寸的卷积核能更好地捕捉代码片段中的局部相关性,然后通过一维最大池化,能够从特征图中提取信息最丰富的局部特征[21]。BiGRU 可以更好地捕捉双向语义依赖,建模上下文序列信息,在源代码中可以提取关键点上下文中存在的数据流和控制流信息,保留代码片段中变量和控制语句等对关键点的长依赖关系,同时GRU通过门控机制缓解了循环神经网络(Recurrent Neural Network,RNN)中存在的梯度消失和爆炸问题,能够更好地处理较长的代码片段。
构建的缺陷检测模型的网络结构如图4 所示,采取词嵌入预训练形成的嵌入矩阵作为模型的嵌入层,将固定长度的代码片段输入嵌入层即可获得对应的向量表示。在隐藏层分别使用TextCNN 模型和BiGRU 模型提取代码片段的局部关键特征和上下文序列特征,将两部分特征拼接后形成代码片段的融合特征。
模型的输入是T1∶L,将T1∶L输入嵌入层,得到代码片段的向量表示,如式(4)所示:
其中:Embedding表示嵌入层;L为输入模型的代码片段的统一长度;d为向量维度。
在TextCNN 结构中,对于一个d维代码片段,使用窗长为m的卷积核Conv1D∈Rm×d获取词窗口的特征ci(1 ≤i≤L-m+1),对所有窗口进行卷积操作后可以获得特征图c1∶L-m+1,再通过一维最大池化,获取信息最丰富的局部特征cmax,如式(5)~(6)所示:
其中:w为权重系数;bc∈Rm为偏置向量;f为非线性激活函数ReLU(Rectified Linear Unit)。
在卷积层中,使用K种不同窗口的卷积核,以便从代码片段中提取不同长度的局部特征,并使用N个滤波器从相同的窗口中学习互补特征,对每种窗口卷积后的结果使用一维最大池化,将不同窗口池化后的结果进行拼接,得到K×N个特征向量cTextCNN∈RK×N:
在GRU 网络结构中,设在时间步t处的输入为vt,t-1处的隐藏状态为ht-1,W、U为权重系数,b为偏置向量,则重置门控状态rt和更新门控状态zt为:
然后,将TextCNN 提取的局部特征向量cTextCNN和BiGRU提取的上下文特征向量cBiGRU拼接作为代码片段的特征输入全连接层;为避免过拟合,并提高模型的泛化能力,在全连接层后增加Dropout层,Dropout 比例为0.5;最后,使用Softmax函数,用来预测类别概率。
2 实验与结果分析
2.1 实验环境
本文实验采用Tensorflow 2.4.1 深度学习框架,开发语言为Python 3.8.10。所用的计算机环境为Windows10 操作系统,处理器为AMD R7-5800H,内存16 GB,硬盘512 GB,GPU GeForce RTX 3060,以及Ubuntu 18.04 虚拟机。
2.2 实验数据
实验数据集来自于美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)的软件保证参考数据 集(Software Assurance Reference Dataset,SARD)[22],本文中涉及到的缺陷类型包含CWE134(使用外部控制的格式字符串)、CWE121(堆栈缓冲区溢出)、CWE78(操作系统命令注入)等74 种代码缺陷的切片。如图5 所示,根据缺陷类型将实验数据分为6 大类,采用分层采样将数据集按照6∶2∶2 划分为训练集、验证集和测试集。
2.3 评估指标
混淆矩阵是代码缺陷检测的通用评估指标,该矩阵描述了实际类别与分类模型预测类别之间的混合数目。如表2所示,真阳性TP(True Positive)表示实际为脆弱样本被预测为脆弱样本的数量,真阴性TN(True Negative)表示实际为非脆弱样本被预测为非脆弱样本的数量,假阳性FP(False Positive)表示实际为非脆弱样本被预测为脆弱样本的数量,假阴性FN(False Negative)表示实际为脆弱样本被预测为非脆弱样本的数量。
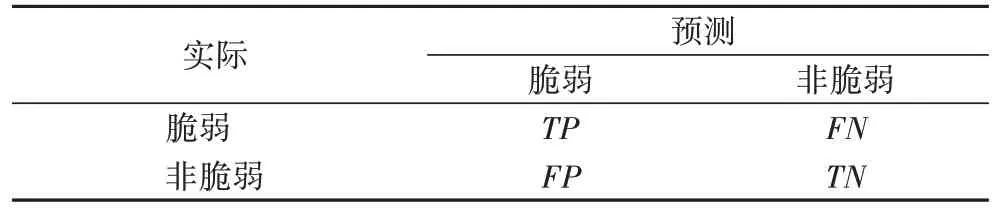
表2 混淆矩阵Tab.2 Confusion matrix
本文采用准确率(Acc)、召回率(Rec)、精确度(Pre)和F1值作为评估指标。计算公式如下:
其中:Acc表示分类正确的样本数与样本总数之比;Rec表示被正确预测的脆弱样本数与脆弱样本总数之比;Pre表示被正确预测的脆弱样本数与预测为脆弱样本的总数之比;F1值表示召回率和精确度的调和平均。
2.4 预训练及参数设置
在构建代码片段的向量表示时,要综合考虑代码长度对检测性能和时间复杂度的影响:如果代码片段长度过短则会丢失部分语义信息,造成检测的准确率下降;过长则会导致运算复杂度增加,甚至导致网络更新慢、梯度消失等问题。为了选择合适的代码片段长度,本文对比了不同代码片段长度对准确率和平均训练时间的影响,在保证准确率的前提下,选择了合适的代码片段长度,减小模型在训练和检测阶段的时间复杂度。
如图6 所示,随着代码片段长度的增加,在验证集上的准确度最终保持在91.80%左右,但是训练时间快速增加,因此在代码片段末尾进行补零或者截断,设置统一长度L=50。通过控制变量法对比不同参数下模型的准确率和时间复杂度,在预训练阶段本文采用的向量表示维度为d=50,滑动窗口大小为5,迭代次数为10。本文中涉及到的主要参数如表3 所示。
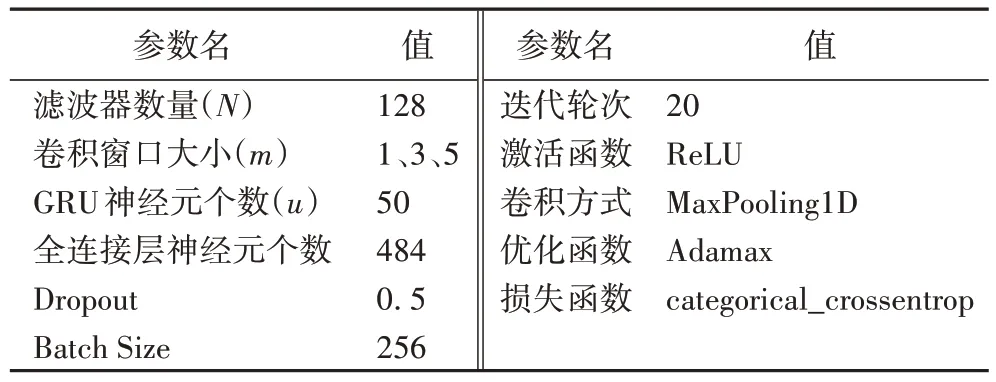
表3 实验参数Tab.3 Experimental parameters
2.5 对比实验分析
2.5.1 不同类型缺陷检测
为了验证本文方法对不同类型缺陷的检测能力,在缓冲区溢出、格式化字符串、内存管理、错误处理不当、命令执行五大类缺陷以及小类别缺陷混合的数据集上分别进行了实验。
图7 是在验证集上检测不同类型缺陷时本文方法的准确率变化曲线。实验结果表明,本文方法在检测命令执行缺陷时的收敛性较好,与缓冲区溢出、格式化字符串、内存管理三大类缺陷在迭代2 次后就基本收敛,而在检测错误处理不当以及混合类型缺陷时收敛性较差,因为这两类缺陷数据量小,缺陷种类较多,需要迭代多次才能达到较好的检测效果。
表4 是在测试集上针对不同类型缺陷的检测效果。实验结果表明,本文方法对缓冲区溢出的检测效果较差,各项指标均在90%以下,这可能是因为缓冲区溢出具有更加复杂的缺陷模式,比如复杂的控制依赖和数据依赖;对其他类型缺陷检测的准确率均在90%以上,召回率均在91%以上;对命令执行以及混合类型缺陷检测效果较好,各项指标均在93%以上,说明这两型缺陷中的脆弱模式相对简单,更容易被识别,检测效果相对较好。综合来看,本文方法能够有效检测代码片段中存在的不同类型缺陷,适应性较好。
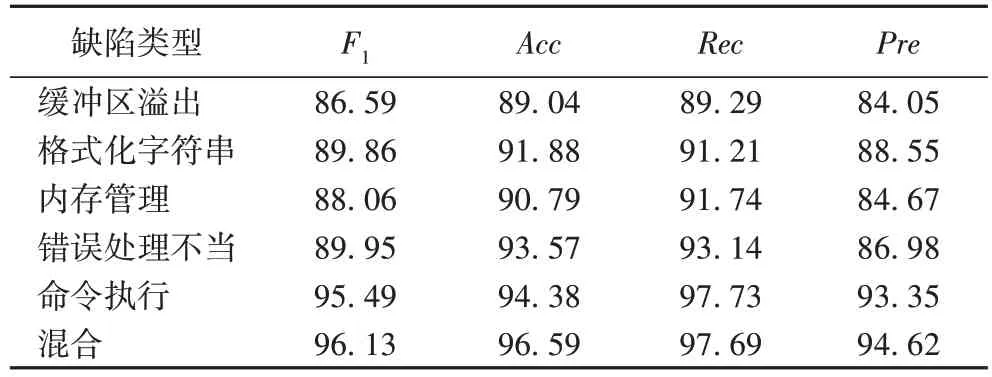
表4 不同缺陷时本文方法的实验结果对比 单位:%Tab.4 Experimental results comparison of the proposed method for different defects unit:%
2.5.2 不同切片方法
现有研究中,程序切片标准和方法的不统一导致生成的代码片段存在一定差异。为了分析程序切片方法对检测性能的影响,在包含所有类型代码缺陷的数据集上进行了5 次实验,结果取平均值。
如表5 所示,本文对比了3 种切片方法:IFDS、SDG 和Weiser,获得7 种不同类型的代码切片。其中:Bo 表示双向切片;Bw 表示后向切片;Fw 表示前向切片。实验结果表明:
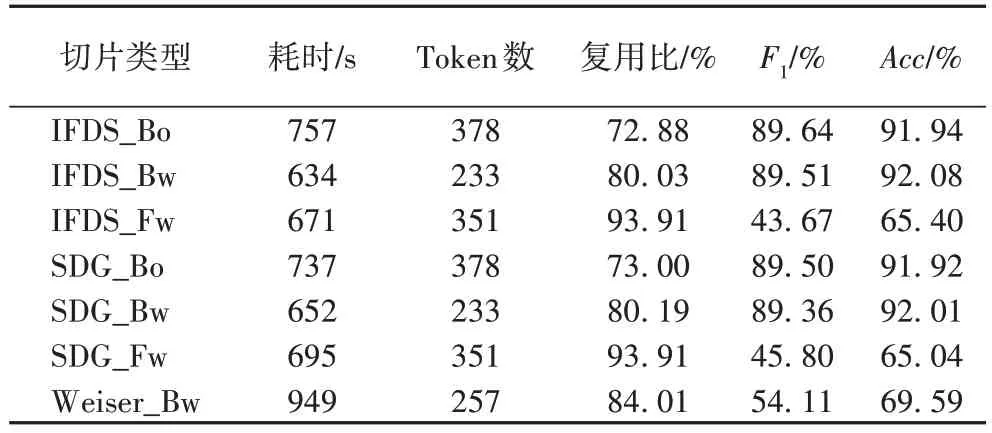
表5 不同切片方法的实验结果对比Tab.5 Experimental results comparison of different slicing methods
1)同一切片方法的时间复杂度与Token 数正相关。Token 数在一定程度上反映了代码语句的复杂度,后向切片的Token 数最少,耗时最短;双向切片的Token 包含后向和前向切片中存在的Token,数量最多,耗时最长。
2)基于IFDS 的切片方法在双向、后向切片上优于基于SDG 和Weiser 的切片方法。对比3 种反向切片,Weiser 切片方法只对代码关键点进行了反向数据流分析,生成的反向切片没有包含控制流信息,因此检测效果最差。
3)双向切片的综合检测性能(F1值)优于反向和前向切片。结合Token 数来看,在反向切片中包含更多的Token,但检测效果最差。通过对比分析生成的代码片段,发现前向切片中包含更多与输出相关的语句,这些语句包含的Token 对缺陷的指示信息较少,且大多与数据流相关,只包含较少的控制流信息,因此检测效果较差。
4)在规范化的切片中普遍存在代码复用现象,在IFDS_Bo 类型中代码复用比最小,能够生成更多独特的切片,并且相较于其他类型切片F1值有不同程度提升。
2.5.3 不同检测方法
为了进一步验证本文方法的有效性,选择了基于专家定义规则的静态检测工具:Flawfinder[23],以及基于深度学习的代码缺陷检测方法[15,17-18],取5 次实验结果的平均值进行对比。实验中统一采用IFDS_Bo 的切片类型,并保持其余实验条件相同。结果如表6 所示。
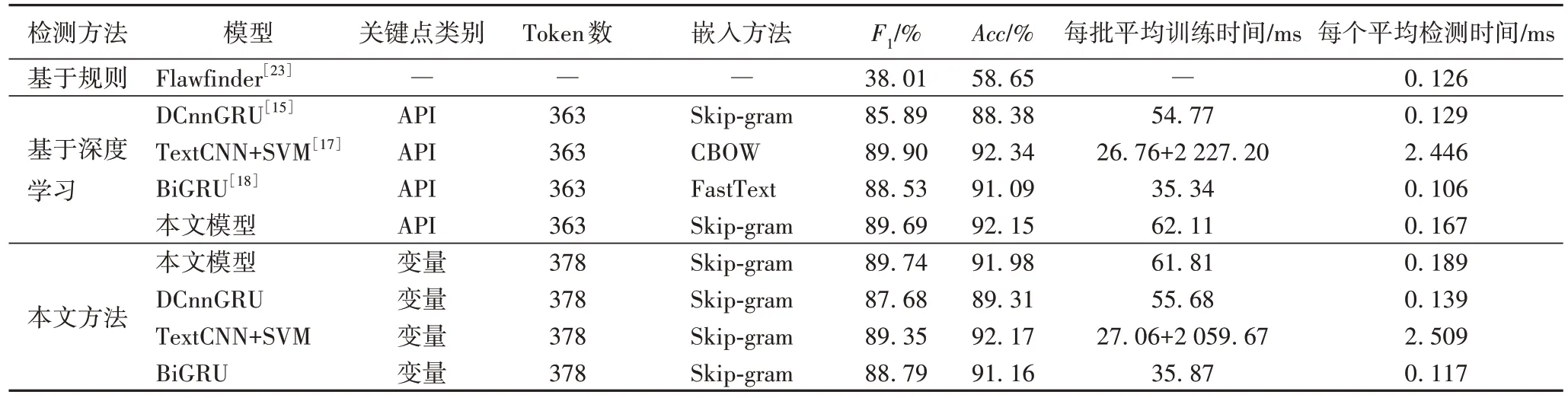
表6 不同方法的实验结果对比Tab.6 Experimental results comparison of different methods
实验结果表明:
1)在检测性能上。基于深度学习的方法[15,17-18]相较于静态分析工具Flawfinder[23]在代码缺陷检测性能上有显著的提升;本文模型在关键点为API 时的F1值比TextCNN+SVM[17]低0.21 个百分点,比DCnnGRU[15]、BiGRU[18]分别高3.80、1.16 个百分点,准确率比TextCNN+SVM[17]低0.19 个百分点,比DCnnGRU[15]、BiGRU[18]分别高3.77、1.06 个百分点;在关键点为变量时,F1值比DCnnGRU[15]、TextCNN+SVM[17]、BiGRU[18]分别高2.06、0.39、0.95 个百分点,准确率比TextCNN+SVM[17]低0.19 个百分点,比DCnnGRU[15]、BiGRU[18]分别高2.67、0.82 个百分点。
2)在时间复杂度上。TextCNN+SVM[17]在TextCNN 提取的特征基础上,引入了SVM 对特征进行二次训练,因此训练和检测时间明显增加,其他方法在一个数量级上,没有显著差异;关键点为API 比变量的时间复杂度相对较小,这可能与Token 数有关系,更多的Token 会增加嵌入层的维度。
3)在模型结构上。DCnnGRU[15]使用了图像处理中的多层卷积结构,破坏了一维代码向量的整体性,同时卷积操作会丢失特征的位置信息;TextCNN+SVM[17]将特征提取模块和分类模块分离,一定程度上提高了模型的泛化能力,但导致时间复杂度显著增加;BiGRU[18]使用自然语言处理中常用的BiGRU 模型,取得了较为均衡的检测效果;本文模型在充分提取局部和全局特征的同时,没有显著增加时间复杂度,并且取得了更好的检测效果。
综合来看,本文方法在不显著增加时间复杂度的同时,取得了更高的准确率和F1值,通过合理的模型设计,能更有效地提取缺陷代码的特征。
3 结语
本文提出了一种基于程序切片和语义特征融合的代码缺陷静态检测方法。首先,为了检测更细粒度的代码缺陷,采用IFDS 切片方法,在关键点处获取包含数据流和控制流信息的程序切片,在保留足够语义特征的前提下,将缺陷范围缩小到关键代码行,提高了检测效率和定位精度;其次,针对代码缺陷与关键点的强相关性以及与上下文存在的长依赖性,利用构建的联合检测模型提取代码片段的深层特征,将局部关键特征和上下文序列特征作为代码片段的特征表示。实验结果表明,本文方法能够有效检测不同类型的代码缺陷,泛化能力较好;对比不同的切片类型,在IFDS 方法提取的双向切片上综合检测性能最优;对比不同的关键点,本文方法在保证检测效率的同时,相较于其他方法有明显提升。深度学习是以数据为驱动,数据决定模型的上限。因此,在下一步工作中,将深入研究源代码更合适的表示形式,比如引入有向图结构来表示切片中的信息流向和语句特征,在保证细粒度的同时,提高缺陷检测的效果。同时,可以通过编译获取代码的不同表示形式,采用多模态学习从不同维度捕获更丰富的代码特征。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
密码学报(2021年4期)2021-09-14
建材发展导向(2021年11期)2021-07-28
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
农家书屋(2016年11期)2016-12-23
世界汽车(2016年9期)2016-09-29
