
融合知识图谱邻居双端的在线学习资源推荐算法
2022-11-08 12:42樊海玮张锐驰安毅生秦佳杰
计算机应用 2022年10期
樊海玮,张锐驰,安毅生,秦佳杰
(长安大学 信息工程学院,西安 710064)
0 引言
在线教育蓬勃发展,数字化学习资源呈现出资源海量的特征。学习者在有了诸多选择的同时,也不可避免地面对严重的知识过载和学习迷航问题。为解决此问题,需要依靠个性化学习和适应性推荐为学习者导航。
适应性推荐是个性化学习过程中的核心任务,经典的推荐算法依据群体的历史行为信息与相似性关系发掘学习者的潜在兴趣偏好[1]。此类算法仅将学习者与资源的交互信息作为输入,数据的稀疏性使推荐存在一定的缺陷。综上,传统推荐算法存在以下缺陷:1)交互数据的稀疏性会影响推荐性能并且存在冷启动问题;2)在推荐过程中无法针对学习者不同的学习目标作出适应性推荐。
为了解决上述问题,研究者通过引入不同的辅助信息来提高推荐性能。知识图谱包含了实体间丰富的语义关联关系并具有信息多样且适用性强的特点,可以为推荐系统提供丰富的辅助信息[2]。其特有的结构信息可以刻画学习者与学习资源在知识层面上的联系,在推荐过程中不仅能考虑到学习者的兴趣偏好,也可以将资源间的关联作为推荐依据。故将知识图谱引入推荐算法,旨在:1)知识图谱中包含了项目之间的语义相关性,可用于发现项目之间的隐含关系,提高推荐的准确率;2)利用连接图谱实体的不同的关系类型可以合理扩展用户兴趣偏好以及特征,增加推荐结果的多样性;3)知识图谱连接了用户的交互项目与被推荐项目,这使推荐算法具有可解释性。本文基于知识图谱,利用学习者特征在知识图谱上的传播以及学习资源在知识图谱中的邻居信息,提出一种融合知识图谱邻居双端的学习资源推荐算法KNDP(Knowledge Neighbor Double Polymerization),并在公开数据集MOOPer 上通过对比实验分析,验证了该算法的有效性。
1 相关研究
1.1 学习资源推荐算法
推荐算法的目标是从海量数据中提取用户所感兴趣的信息,是解决“信息过载”问题的有效工具之一[3]。王根生等[4]将用户的学习行为转化成用户对资源的评分并改进用户的相似度计算来解决推荐系统中潜在的数据稀疏和冷启动问题;Zhuhadar等[5]利用学习材料构建基于领域本体的E-learning 资源知识库,将基于内容和基于规则的方法相结合,为用户提供混合推荐;赵继春等[6]构建了一种基于领域本体与学习者属性信息的特征模型,以学习特征模型为基础设计一种融合相似度的协同过滤推荐方法;聂黎生[7]提出了基于行为分析的学习资源推荐算法,挖掘学习者行为数据并将其格式化融入协同过滤推荐中。在上述文献中,为了克服传统推荐算法所存在的缺陷,研究者引入了不同类型的辅助信息以提高推荐性能。然而,这些辅助信息仅包含用户或项目的孤立特征。事实上,无论是用户与项目间,还是项目与项目间均存在丰富的关联。为推荐算法引入知识图谱可以通过实体间丰富的关系获得用户与项目之间的细粒度关系,从而提升推荐的性能。
1.2 基于知识图谱的推荐
基于知识图谱的推荐主要分为两类:基于嵌入方法和基于路径方法的推荐[8]。基于嵌入方法将知识图谱中的节点与边映射为低纬度的稠密向量,以丰富用户与物品的表示信息。例如,吴玺煜等[9]使用知识图谱表示学习方法,将语义数据嵌入到低维空间,并将物品语义信息融入协同过滤推荐;陈平华等[10]使用知识图谱表示学习把项目实体嵌入低维向量空间,向矩阵分解模型中加入实体信息,计算实体之间的语义相似性,来提升推荐性能。上述基于嵌入方法的推荐方式首先需要利用表示学习将知识图谱中的节点和边转化为向量,其中经典的表示学习方法有TransE(Translating Embeddings)[11]与TransR(Translation in the corresponding Relation space)[12]等。此类嵌入方法侧重于建立严格的语义相关性,故更适用于连接预测或知识补全等图内应用而不是推荐算法。
基于路径方法的推荐的主要思想是挖掘基于图谱用户、项目之间多种连接关系,例如,Hu等[13]通过卷积神经网络针对不同的元路径采样得到路径的嵌入表示后构造基于元路径的用户偏好特征,最后结合神经矩阵分解(Neural Matrix Factorization,NeuMF)模型[14]构建推荐系统;Sun等[15]采用元图的方式替代元路径对知识图谱进行特征提取,相较于元路径更能描述复杂的特征信息。然而此类算法需要先从数据中抽取和构建大量的元路径(元图),当图谱或者推荐场景发生变化时需要对其重新构造,并且元路径或元图主要依靠手工抽取,在实际场景中难以实现最优。
上述方法通过引入知识图谱提升推荐算法的性能,却未充分利用知识图谱的信息。RippleNet[16]在给定与用户交互过的项目后,通过将此项目的向量同用户周围的n跳项目进行交互计算最终得到用户的嵌入表示。知识图谱卷积网络(Knowledge Graph Convolutional Network,KGCN)[17]能够更好地捕捉项目的邻域信息,针对特定用户与图谱中的特定关系给出邻居节点与该节点聚合的权重,用加权结果表示邻居节点,完成项目向量的计算。这两种模型均提供了端到端的推荐方法,使用户(项目)以及知识图谱实体与关系的嵌入表示成为可学习向量。但上述两种模型仅从用户或项目一端出发,没有同时考虑两端的信息,而且RippleNet 在传播用户偏好时其传播方向是随机的,故并不能充分表示学习者特征。
综上所述,本文提出的KNDP,以学习者为用户端,以学习资源为项目端,将学习者的特征在知识图谱上有选择性地传播并控制每一跳传播的权重,以获得学习者的嵌入表示;在聚合学习资源的一阶或高阶邻居节点时,通过用户端的学习者嵌入表示来为其分配聚合权重,来扩充其嵌入表示;最后通过得到的学习者和学习资源嵌入表示计算两者的交互概率。
2 KNDP模型构建
2.1 问题定义
在为学习者推荐学习资源时,学习者和学习资源的集合分别设置为S={s1,s2,…,sn}和L={l1,l2,…,lm},两者的交互矩阵定义为M=(msl),其中s∈S,l∈L。当学习者s与学习资源l之间存在交互行为且实践结果通过时msl=1,否则msl=0;如没有发生过交互msl=-1。知识图谱由三元组{(h,r,t)|h∈E,r∈R,t∈E}构成,其中(h,r,t)表示从头实体h通过关系r连接到尾实体t,E和R分别表示知识图谱中的实体集合与关系集合。对于学习者s∈S,选取在交互矩阵中msl=1 的所有资源集合Ls作为种子集。另外K表示从集合Ls出发到达学习目标(例如msl=0 的资源)的中间实体集合。给定交互矩阵M和知识图谱G计算=F(s,l,M,G,Θ),其中是学习者与学习资源之间交互概率,Θ表示预测函数F的参数。
KNDP 模型在学习者角度,利用知识图谱G中实体间的关系找到msl=1 的节点与msl=0 的节点之间的实体集合K,聚合该集合中的实体及其邻居信息,其特征便通过知识图谱传播到了目标节点,据此得到学习者的表示。在学习资源角度,在邻居实体集合N(l)中以固定大小采样作为此节点的接受域,并以一定的权重与l聚合得到学习资源的嵌入表示,最终通过全连接层得到两者的交互概率。本文模型的总体框架如图1 所示。
2.2 学习者表征计算
从用户端出发,在计算学习者嵌入表示的过程中,通过在知识图谱上将学习者已有的知识特征向目标节点传播,并在此过程中更新学习者向量以提高用户端表示信息的质量,过程如图2 所示。
2.2.1 计算实体的融合权重
给定交互矩阵与知识图谱G,对于学习者s,获得交互矩阵中msl=1 的学习资源lb与msl=0 的学习资源lg。每一个lb都可以被表示为向量形式lb∈Rd,其中d表示向量的维度。在为其初始化时,可以采用独热编码[18]或词袋模型[19]。在知识图谱G中得到以学习资源lb为起点,以学习资源lg为终点构成的学习资源集合Ks={lb,lb+1,…,lg-1,lg}。将l∈Ks的q阶邻居节点定义为:
其中:q=1,2,…,n。对于实体l找到其在知识图谱G上与其一阶邻居所形成的三元组集合Ul:
给定l∈Rd与Ul计算(hi,ri,ti)∈Ul这个三元组实体嵌入过程中的融合权重pi:
其中:hi∈Rd,Ri∈Rd×d,l∈Rd分别是头实体hi、关系ri和学习资源l的嵌入表示。融合权重pi可理解为头实体hi与学习资源l在关系空间ri下的相似度。
2.2.2 传播向量的计算
为丰富集合Ks中各个实体的嵌入表示,将实体lj∈Ks的一阶邻居与lj融合。首先利用式(3)计算实体融合的权重pi,之后将Uli中的尾实体乘以相应的融合权重并求和得到ojs:
将lj∈Ks的向量表示lj替换为。
以lj为例,在融合其一阶邻居节点时,lj+1也是其邻居节点之一,所以在融合lj+1的一阶邻居信息时,将式(3)中的l替换为可将学习者的知识特征从lj传播到lj+1。依次计算l∈Ks中的每一个实体得到os。
经过上述计算,得到集合Os=对于,随着i的不断增大,距离学习者已掌握的知识实体越来越远,其中包含的噪声信息越多。故采用文献[20]中提出的累加方式如式(5)所示,得到最终的学习者嵌入表示s:
其中:γ为控制Ks中实体每一步传播输出的权重,此操作可区分传播结果的重要性。
2.3 学习资源表征计算
从项目端出发,利用KGCN[17]将邻居节点信息聚合到当前实体节点,使之捕获到局部的近似结构及特征,扩充学习资源的特征表示,基本框架如图3 所示。
给定一个资源实体l∈L与知识图谱G,将在G中与l直接相连的实体表示为N(l)。对于每个学习者,由于其知识体系与偏好不同,故在聚合邻居实体过程中,需考虑到学习者s∈S在不同关系r∈R下聚合的权重:
其中:s∈Rd,r∈Rd,g为降维操作。通过N(l)中实体的加权和表示学习资源l的拓扑结构信息:
其中:e为实体e∈N(l)的嵌入表示;为标准化后的学习者—关系权重;rl,e表示实体l与e之间的关系,其公式如下:
考虑到N(l)集合中的实体规模问题,选择随机采样固定数量的邻居来降低计算的复杂度。
其中:Q表示采样的数量。聚合其采样后一阶邻居拓扑信息与自身信息l得到嵌入表示:
如图3 所示,此时已将H=1 的实体信息聚合到了中间实体。若要进行二阶邻居聚合,先将该实体二阶邻居信息聚合到一阶邻居,再将融合后的一阶邻居信息与该实体融合即可。KGCN[17]聚合实体的权重计算方式如式(6)、(8)所示。本文将2.2 节计算得到的学习者嵌入s代入式(6)。此外,本文中表征实体间关系的矩阵r∈Rd×d,而KGCN的r∈Rd。因此,需要对进行降维操作,即将其维度从d映射为1。根据式(6)~(10),将实体的邻居节点从高阶邻居向低阶邻居不断聚合,计算得到学习资源的嵌入表示ls。
2.4 概率预测
由2.2 节与2.3 节得到最终的学习者嵌入表示s与学习资源嵌入表示ls,将其输入全连接层来预测交互概率。将s和ls融合后作为全连接层的输入向量x0:
x0通过第一层的输出值表示为:
其中:W1表示为输入层与第一个隐含层之间的权重;b1表示偏置矩阵;f(·)表示激活函数。输出层的计算公式为:
最后根据ŷ为学习者作出推荐并据此对候选项目排序生成待推荐资源列表。
3 实验与结果分析
3.1 实验环境与数据集
本文实验在64 位Windows10 系统上的PyCharm 中开展,基于TensorFlow 1.8 框架和Python 3.6实现,GPU 为GTX1080Ti,使用Anaconda 4.9.2。
实验采用MOOPer(http://openkg.cn/dataset/mooper)数据集。该数据集分为两部分:交互数据与知识图谱。其中交互数据有3种,分别为学习者行为、学习者反馈和系统反馈。学习者行为展示了与学习资源之间的交互过程,学习者反馈则反映了他们的学习状况和学习满意度,系统反馈数据描述了学习者在实践练习过程中的结果反馈。知识图谱由课程、实践、关卡、知识点的属性信息及其之间的相互关系建模形成,整体结构如图4 所示。数据集经过预处理后的统计信息如表1 所示。
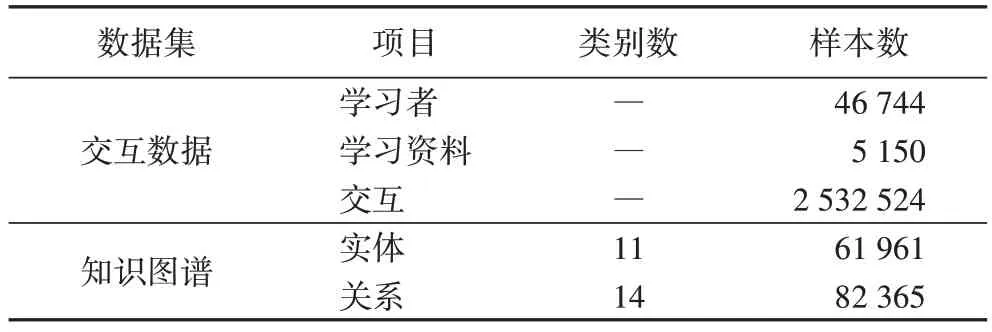
表1 数据集统计信息Tab.1 Dataset statistics
3.2 对比模型
为了验证算法的有效性,将KNDP 与以下对比对象进行比较。对比对象的参数设置与原文献中的设置相同。
1)改进型深度神经网络学习资源推荐算法(UDN-CBR)[21]:将学习者信息和学习资源信息作为输入,通过全连接层得到其特征向量;同时引入Word2vec 获得学习资源的文本特征与学习资源的特征向量进行融合;最后通过多层感知器(Multi-Layer Perceptron,MLP)网络预测评分。
2)RippleNet[16]:将与用户发生过交互的项目作为种子集,在知识图谱上通过实体与实体之间的关系传播用户的偏好并最终得到用户的嵌入表示,最后计算用户与项目的交互概率。
3)KGCN[17]:利用知识图谱中实体的邻域信息,将其邻居节点的信息通过图卷积的方式聚合到该节点中,以丰富项目的表示。
4)基于知识图谱卷积网络的双端(Double End Knowledge Graph Convolutional Network,DEKGCN)推荐算法[22]:在用户端和项目端分别利用图卷积将邻居信息聚合到该节点中,得到用户和项目的嵌入表示,最后计算两者的交互概率。
3.3 实验结果与分析
本文实验以7∶2∶1 的比例将交互数据划分为训练集、验证集与测试集对模型进行训练。将式(6)中的函数g设置为内积函数。将全连接层数设置为4,非最后一层的激活函数为线性整流函数(Rectified Linear Unit,ReLU),最后一层的为tanh,学习率为0.001。对于知识图谱G,将实体嵌入维度设为32,式(9)中的采样大小Q设置为4,邻居跳数在聚合学习者信息时设置为1,在聚合学习资源信息时设置为2。
在交互率预测中,使用训练好的模型对测试集中的每个交互行为进行预测,使用曲线下面积AUC(Area Under Curve)和准确率ACC(Accuracy)指标评估模型性能。针对Top-K推荐任务,为测试集中的学习者推荐前K个学习资源,使用Precision@K和Recall@K指标评估模型性能。AUC 是受试者工作特征曲线(Receiver Operating Characteristic,ROC)下的面积,ACC的计算公式如下:
其中:TP(True Positive)为真阳数、TN(True Negative)为真阴数、FP(False Positive)为假阳数、FN(False Negative)为假阴数。
交互概率预测中AUC与ACC的对比结果如表2 所示,Top-K任务中Precision@K和Recall@K的对比结果如图5~6所示。
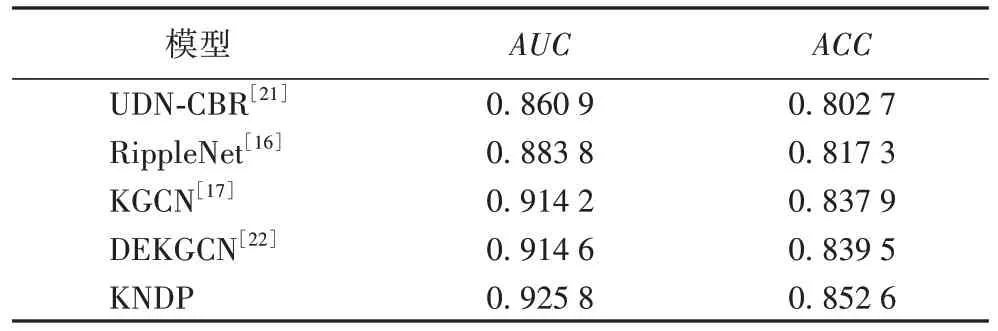
表2 交互概率预测中AUC和ACC的对比结果Tab.2 Comparison results of AUC and ACC in interaction probability prediction
由表2 可知,KNDP在ACC和AUC评估指标上均取得最好的性能,相较于其余基线模型的AUC提高了1.12~6.49 个百分点;ACC提高了1.31~4.99 个百分点。从图5~6 中可以看出,在K=5时,DEKGCN 的Precision@K和Recall@K是表现次好的,与DEKGCN 相比,KDNP 在Precision@K和Recall@K上分别提升了6.49%和13.07%。
通过对比分析实验数据可知,3 种基线模型RippleNet、KGCN 和DEKGCN在AUC、ACC、Precision@K以及Recall@K指标上均优于UDN-CBR 模型,说明在引入知识图谱之后,知识图谱中的实体与关系信息有利于提升推荐性能。其中,RippleNet 从用户端出发,利用学习资源的周围实体传播学习者的偏好信息以计算学习者的向量表示,其不足在于没有利用知识图谱提升项目端的信息质量。与RippeNet 类似,KGCN 着眼于项目端,融合学习资源邻居节点得到其嵌入表示,未利用知识图谱的信息丰富学习者嵌入表示。DEKGCN的优势在于同时考虑到了用户端和项目端,但是在聚合用户端的信息时,选择通过构建用户属性图来聚合用户的人口统计学信息[22]。这使用户端缺失了知识特征信息,故导致学习者嵌入表示的语义丰富度有所不足。本文提出的KNDP在用户端和项目端均充分利用了知识图谱的异构信息并将学习者已交互的项目与学习目标之间的实体与其邻居信息也融合进学习者的向量嵌入表示中,因而产生性能上的明显提升。
4 结语
本文提出融合知识图谱邻居双端(KNDP)推荐算法,从学习者和学习资源出发,通过引入知识图谱对邻居双端的聚合计算,获得学习者与在线资源的嵌入表示,表达学习者的个性化知识获取需求,继而送入MLP 网络模型中做全连接,以交互概率作为隐含学习资源的发现概率,创建在线学习推荐资源。KNDP 推荐算法解决了协同过滤算法存在的数据稀疏以及推荐结果各向同性的问题。实验结果验证了模型在推荐性能提升方面的有效性。由于学习是一个具有时间属性的序列过程,下一步工作将考虑学习活动中对于不同学习资源的交互次序,从而更为精细地表示学习者向量,更准确地捕获学习需求而服务,提高学习资源推荐的靶向性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
