
基于残差收缩网络的关系抽取算法
2022-11-08 12:42袁泉薛书鑫
计算机应用 2022年10期
袁泉,薛书鑫*
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.重庆邮电大学 通信新技术应用研究中心,重庆 400065)
0 引言
在信息爆炸的时代,海量的数据在给人类带来便捷的同时也让大家困惑于如何快速有效地从中找到自己想要的信息。信息抽取技术应运而生,关系抽取是信息抽取中重要的任务之一。其为下游任务(如构建知识图谱和问答系统)提供了技术基础,也在文本摘要、语言翻译、情感分析等自然语言处理任务中有深远的意义。
关系抽取的目的是从非结构化、无序的句子中抽取出两个实体之间的关系。如在句子“苏炳添出生自广东省”中,选取“苏炳添”和“广东省”作为实体,可以在抽取结束后得到两者为“出生地”关系,并构成(苏炳添,出生地,广东省)的三元组,如图1 所示。
因此解析句子的结构特征,明了词语的语义特征是任务的关键。人们早期依赖自然语言工具,构建人工选择的特征工程。尽管研究者采取了很多有效的构建人工特征方法(如基于核函数和基于模式识别的方法),但是这些方法并不能保证所需特征的完整性并且会耗费大量时间。因此研究者目前普遍使用Mintz等[1]提出的远程监督的方法自动学习特征,但该方法同样也被大量的噪声问题困扰,主要为以下两种:
1)句子之间因错误标记产生的噪声。远程监督的关系抽取根据实体对在知识库(Knowledge Base,KB)存在的某种关系将所有含有相同实体对的句子看作一个关系结果,然而事实上具有相同实体对的不同句子并不一定有相同的关系。如在句子“马云创建了阿里巴巴公司”和句子“马云在讲阿里巴巴的故事”中,同样选“马云”和“阿里巴巴”作为实体对,关系却不相同,当把其中一个句子的关系当作正确结果,则另一个句子将成为噪声。当选取的句子在KB 中没有关系时,即KB 容量不足时,也会产生噪声。如句子“母亲对儿子非常地包容”,应该得到(母亲,亲人关系,儿子)这样的关系结果,但若KB 中不存在亲人关系,则该句子的抽取结果将被错误地标记为NA(其他结果)。
2)句子内部词语的噪声。对于一个较长的句子,句子中的两个实体是句子的核心,句子中的其他字词有时可以看作辅助判断两个实体关系的信息,但有时也可以看作影响判断的噪声,在包含信息比较多的句子或者是存在语义转折的句子中影响更为明显。如“小明的邻居是镇子上有名的裁缝”,选取“小明”和“邻居”作为实体本应该得到“邻里”的关系,但是可能会受到“裁缝”这个词语的干扰得到“工作职业”的关系。又如句子“秦始皇虽然覆灭了其他六国,但创立了秦王朝”,应得(秦始皇,创建,秦王朝),但是“覆灭”这个词与“创建”的意思完全相反,会对模型的关系判断造成干扰。
大量诸如上述的句子严重影响关系分类的性能,因此噪声问题亟待解决。Hoffmann等[2]利用多实例学习(Multiple Instance Learning,MIL)方法对噪声去强调。以包为一个整体,每个包里存在一组有相同实体对且未标记的句子,对整个包预测关系结果。Zeng等[3]将深度学习的方法和MIL 相结合,利用分段卷积的网络框架预测包中实体对的类别,但是并没有使用包中全部的句子作为训练样本,而仅仅采用包中标签概率最高的句子,显然不能获得全面的样本分析。Lin等[4]将注意力(attention,att)机制应用于关系抽取模型中,给包内不同的句子分配不同的权重,注意力机制的应用大幅度抑制了噪声对训练的影响。在此基础上不断有人根据不同的场景和模型添加适合的注意力机制。如Zhang等[5]将注意力机制加入网文关系分类模型中;Bai等[6]将其加入药物分类领域;谌予恒等[7]将注意力机制和残差网络相结合,探索出了更加有效的关系抽取模型。但随着数据集的不断扩大、噪声数量和种类的增多,研究者尝试选择更复杂的算法解决问题。Feng等[8]和Qin等[9]通过强化学习的方法生成标签,并与句子预测标签比对,由此来决定是删除还是保留句子。Chen等[10]从句子被标记的多个关系中选择最可靠的标签后再进行训练。Yi等[11]通过训练样本提取器删除噪声,挑选出有用的句子加入训练。
上述方法都取得了很好的降噪效果,但仍存在两点弊端:第一,它们丢弃了大量被训练认定为噪声的句子,然而这些被认定的“噪声”可能存在有用的信息;第二,它们仅仅考虑了包内句子间错误标注带来的噪声,而忽视了句子内部的噪声。事实上,大部分研究者对句子内部噪声处理都是强调已有的重要信息或是增加额外的有用信息,如Zeng等[12]给句子中的每个词都加入位置向量,谢腾等[13]给输入的句子加入关键词信息。这些模型可以在一定程度上通过提高重要信息比重的方式降低句子内部的噪声的比重,但是这种方式不能剔除噪声且会受到句子多样性的影响。
为了解决句子内部的噪声问题,本文引用了Zhao等[14]在2020 年提出的残差收缩网络结构,该网络创新性地将软阈值化加入深度学习中来解决故障诊断中信号噪声的问题。本文以此特性为基础,提出使用残差收缩网络解决关系抽取中句子内部噪声问题的算法。而对于包内句子间标注错误的噪声,本文则采用注意力机制处理。实验结果表明基于残差收缩的网络模型可以取得更高的预测精度,从而有效地解决远程监督带来的噪声问题。
1 残差收缩模块
残差收缩(Residual Shrinkage,RS)模块由普通的残差网络上、软阈值化和阈值训练子模块组成,如图2 所示。残差收缩网络[14]本质是一种改进的残差网络。在残差路径(shortcut 路径)连接主体之前加入核心是软阈值化的子模块。该模块会在训练中自动生成阈值给不同的特征通道分配权重。它由两个卷积层构成,其中第二个卷积层选用Sigmoid 作为激活函数,保证了阈值是个不会太大的正数。卷积层的输出与原特征的绝对值乘积得到当前特征的阈值。软阈值化使用上述阈值对当前通道的特征收缩,包含无用信息的通道特征将会被缩小或者删除。由于这种算法可以根据不同的输入自主生成适合当前输入的阈值降噪,针对不同类别的输入语料都能得到不同的阈值,所以非常适合用于解决句子内部的噪声问题。上述的降噪原理类似于Hu等[15]提出的基于通道注意力机制的网络模型,通过处理通道间特征实现降噪。不同在于RS 模块不再使用通道注意力机制中的加权函数,而是改用软阈值化。通道注意力机制注重权重的分配,而RS 模块则注重无用信息和边缘信息的处理,更加契合降噪的目的。本章将会从软阈值模块和阈值训练子模块两个方面介绍。
1.1 软阈值模块
软阈值化在降低信号噪声的处理中非常常见。首先将信号转换到一个域中,该域接近0 的信号为噪声信号,然后通过软阈值化处理这个域中信号。作用原理如式(1)所示,其中y为输出,x为信号大小,τ为阈值。当信号的绝对值低于阈值时,该较低的部分将会被置零(式(1)中-τ≤x≤τ所示,噪声置零),而其他的部分也将向零的方向减小(式(1)中x>τ和x<-τ所示,影响较小的信号减小)。
显然软阈值化存在两点困难:1)软阈值模块需要在其工作的过程中默认噪声存在于零附近,所以信号降噪前经常要使用小波变换或其他方法预处理信号,使得操作更加复杂;2)软阈值化需要根据信号收缩的阈值选择不同的滤波器,这种滤波器的选择需要专业的人才,即便如此,当多种信号轮流输入时滤波器的选择将会异常复杂。
如果将软阈值操作移植到深度学习中以上的两个困难都可以迎刃而解。首先,深度学习的特征值大小可以决定输入特征的关键程度,不需要对特征进行复杂的处理。类比于卷积网络中最大池化选择最有效的特征值作为代表特征,在软阈值中可以将较小的特征值,即接近零的特征值当成是噪声或是没意义的特征消除,保证了软阈值化后的模型将会保留主要的信息。不同于线性整流函数(Rectified Linear Unit,ReLU)那样将负的特征置零,软阈值化可以将负的、有用的特征保留下来。其次,深度学习是一个通过训练学习的算法,在选择滤波器时,只需要额外增加一个阈值训练子模块便能根据不同的输入特征学习不同的阈值,避免了滤波器选择困难的问题。
考虑到软阈值化和深度学习的兼容性,软阈值化的导函数由式(2)给出,其中y′为输出特征导数。可以看出式(2)结果都是值为0 或1 的整数,说明软阈值化深度学习的反向传播过程中不会引起梯度爆炸或者梯度消失的问题,这一点也契合深度学习的训练过程。
1.2 阈值训练子模块
阈值训练子模块需要根据软阈值化的特点设计。模型对于阈值至少有两点要求:第一,阈值必须是正数,若阈值为负,代入式(1)将会产生错误;第二,阈值不能过大,如果阈值即式(1)中τ很大,根据式(1)可以看出大量的信息x将会被置零,此时用于训练的特征将被大幅压缩,若是阈值大到超越了信号量,即式(1)中τ<x时,所有的特征都等于0,模型将无法训练。
根据以上要求设计的阈值训练子模块如图2 的右半部分所示,它由绝对值层、全局池化层和两个全连接层组成。绝对值层将特征取为正数,全局平均池化将特征转化成一维向量,接着通过两个全连接层进行学习。需要注意的是第二个全连接层必须使用Sigmoid 作为激活函数,Sigmoid 函数可以把输出结果归一化到0 和1 之间,由此可以防止阈值(阈值=全连接输出结果×求绝对值后的特征)过大的问题。
由于上述所有过程都是在单独的特征通道内完成,所以每个特征通道都会根据当前通道阈值减少无关信息的干扰,从而完成了句子内部降噪的功能。
2 基于残差收缩网络的关系抽取模型
本文使用的基于残差收缩网络的模型结构如图3 所示。模型主要由嵌入层(词嵌入+位置嵌入)、卷积层、分段池化层、注意力层、全连接层和Softmax 组成。嵌入层负责模型的输入,卷积层负责特征的提取(用于降低单个句子内部噪声的RS 模块就包含在此层中),注意力层负责处理包内句子之间的噪声问题,最后全连接层和Softmax 则根据前面提取的特征输出每种关系的预测概率。
2.1 模型结构
2.1.1 嵌入层
为了让深度学习模型能够识别输入用于训练的句子,嵌入层将输入句子编码成嵌入矩阵。嵌入矩阵中的每一条向量都是由词嵌入和位置嵌入构成,词嵌入包含句子语义信息,位置嵌入则包含相对位置信息。
词嵌入是一种对单词的分布式表示。通俗来说就是将低维的单词表示成高维的实值向量。由于词嵌入从大量文本中预训练得到,由此捕获了原单词的部分语义信息。本文使用Word2vec 作为实验预训练模型。
在关系抽取过程中,相同的实体因在句中位置的不同可能导致不同关系结果,因此仅有语义信息并不能完整地反映输入特征。位置嵌入提供了原句子中的每个单词和两个实体相对位置信息。如在句子“Alibaba was founded by Jack Ma in Hangzhou”中,“by”在“Alibaba”后第三个单词位置,“Jack Ma”前一个单词位置,所以它的位置映射可以用“3”和“-1”表示。这些位置映射通过随机化初始向量的方法变为位置向量。
设输入句子为s={W1,W2,…,Wi},其中Wi表示句子第i个单词。设词向量维度为dw,位置嵌入维度为dp,则输入通过嵌入层后将得到特征向量qi(qi∈Rd),其中d为输入向量的维度,d=dw+2 ×dp。
2.1.2 卷积层
卷积运算借助卷积核在输入矩阵上滑动点积的方式获得句子多个局部特征。计算过程如式(3)所示:
其中:b为偏置,f为激活函数,qi为通过嵌入层后的特征。
实际卷积过程中,为了更好地捕捉语句特征,通常使用多个大小不同的卷积核,每个卷积核计算后都会得到一个特征通道。本文的软阈值化便是在特征通道内部进行。如式(4)所示:
其中:W为待训练矩阵。经过一层卷积后的特征将被送入多个残差收缩模块继续训练。这些特征一方面将会被更高层网络继续细化学习,另一方面也会在各自的特征通道中学习阈值并利用软阈值化删除不重要的部分进而减少句子内部噪声。上述过程可以用式(5)表示:
其中:ci为卷积层后的输出,FRS为残差收缩模块运算。
2.1.3 分段池化层
为了获取更全面的结构信息,实验依照实体1 和实体2的位置将句子分成三段:句子开始到实体1 为第一段,实体1到实体2 为第二段,实体2 到句子结束为第三段。设实体1的位置为a,实体2 的位置为b,则三段句子经过卷积层后的特征 表示为={c1,c2,…,ca},ci2={ca+1,ca+2,…,cb},={cb+1,cb+2,…,cb+n}。
由拼接池化后的三个向量x1、x2、x3得句子的最终特征表示X,如式(9)所示:
2.1.4 注意力层
注意力层主要解决包内句子间噪声问题。由于远程监督的关系抽取会将所有拥有相同实体对的句子放在一个包中并以包为单位得到这两个实体的关系,所以训练时需要通过分配权重的方式减少包中句子因错误标注带来的噪声干扰。
根据包中每个句子S={s1,s2,…,sn}的权重计算出整个包的加权和u,如式(10)所示:
其中:M为包中句子数量;ai为权重;Xi为包中第i个句子特征。
此处采用双线性模型为每种关系和当前句子的相关程度打分,如式(11)所示:
其中:r为和关系种类相关的查询矩阵;W为待训练矩阵。由此权重ai可以用式(12)表示:
其中:N为关系数量。
2.1.5 Softmax层
得到包的加权和u后,先通过全连接层调整维度,维度的大小是最终分类的关系数量,再利用Softmax 预测每种关系存在的可能性,在输入句子Si下预测关系rj的条件概率为:
2.2 损失函数
本文采用交叉熵作为损失函数。设包的加权和u通过Softmax 后条件概率为p(r|S)。损失函数将根据包中句子S={s1,s2,…,sn}和其对应的标签关系r={r1,r2,…,rn}给出如式(14)所示:
其中:|B|为包的数量;S为输入句子;θ为模型的所有参数。
3 实验与结果分析
3.1 实验数据集
实验使用来自于Riedel等[16]的NYT(New York Times)公开数据集。该数据集共有522 611 个训练用例,17 448 个测试用例,具体数据参数如表1 所示。

表1 数据集参数Tab.1 Dataset parameters
3.2 评价指标
本文通过精确率P(Precision)、召回率R(Recall)计算得到的F1 值与PR(Precision-Recall)曲线来评估网络的优劣性,如式(15)~(17)所示:
其中:TP(True Positive)为真正例(预测为正且真实为正);FP(False Positive)为假正例(预测为正且真实为反);FN(False Negative)为假反例(预测为反且真实为正);TN(True Negative)为真反例(预测为反且真实为反)。
每结束一次循环记录F1值,如果当前指标值比记录的高,则将记录的指标更新。
3.3 参数设置
设使用Word2vec 的预训练模型词嵌入维度为100,随机化初始的位置嵌入维度为10。利用暖启动加上多项式递减学习率,初始学习率设为1E-6,学习率逐渐增加到1E-3,再使用多项式衰减,结束学习率又回到1E-6。使用3、4、5 的卷积窗口每个窗口的卷积核为128(Feature maps),共384 个卷积核,如表2 所示。

表2 实验参数设置Tab.2 Experimental parameter setting
3.4 残差收缩模块数量的影响
在模型训练过程中,可以使用一个残差收缩模块,也可以增加网络的深度,堆叠多个残差收缩模块。为了探究多少个残差模块性能最好,分别使用了1、3、5、7、9 个残差收缩模块(RS-1、RS-3、RS-5、RS-7 和RS-9),实验结果如表3 所示。
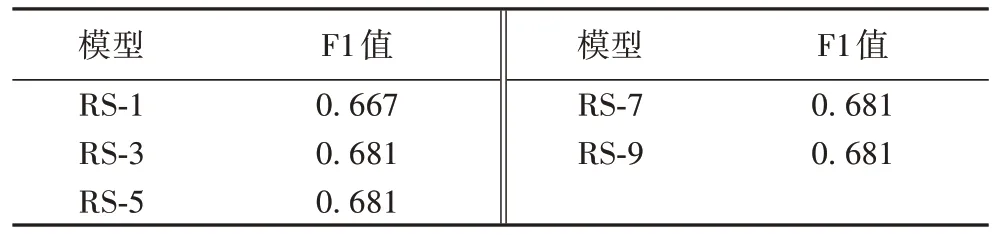
表3 残差收缩模块数量对性能的影响Tab.3 Influence of number of residual shrinkage modules on performance
从表3 可以看出,使用1 个残差模块时的模型F1 值为0.667,使用3 个和5 个残差模块模型F1 值为0.681,模型性能提升了约1.40 个百分点;但当残差模块更多时,F1 值的变化微乎其微。由此可以表明,在当前数据集下,3 个残差模块便可使模型达到稳定。
3.5 实验结果和分析
为了评估基于残差收缩网络构建的模型,本文选择分段卷积神经网络(Piecewise Convolutional Neural Network,PCNN)、双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络以及残差网络(Residual Network,ResNet)模型作为基线模型。实验所得的PR 曲线如图4所示。
在PR 曲线中,曲线下方的面积越大则模型的性能越好。通过观察图4 看出,本文模型明显优于其他3 个基线模型,原因是由多个残差收缩模块构建的模型通过给不同特征通道软阈值的方式减少了各个通道中干扰信息对特征提取的影响,进而减小了句子内部的噪声影响,大幅提高了关系抽取模型的准确性。
3.6 由残差收缩模块构成的模型与注意力机制关系实验
本文使用的残差收缩模块用于解决句子内部的噪声问题,注意力机制用于解决包内句子的噪声问题。为了验证两种降噪的方式能否并行,将基线模型+注意力机制、残差收缩网络、残差收缩网络+注意力机制3 组对照又进行了实验,结果如表4 所示(其中att 表示注意力机制)。
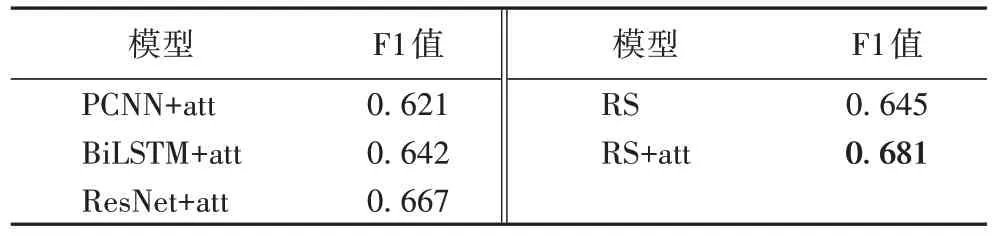
表4 不同模型结合注意力机制的F1值对比Tab.4 Comparison of F1 scores of different models combined with attention mechanism
在实验过程中F1 值稳定后会围绕某数值产生轻微上下波动。将每个模型选择实验过程中能达到的最大F1 值作为数据。通过分析结果得到以下几点结论:
1)对比PCNN+att、BiLSTM+att、ResNet+att 这3 个模型可看出,ResNet+att 模型的F1 值比PCNN+att 高4.60 个百分点,比BiLSTM+att 高2.50 个百分点,由此可以看出深层次的网络模型在大数据集上有较好的效果。
2)对比PCNN+att、BiLSTM+att、ResNet+att 和RS+att 模型可看出,RS+att 模型比其他3 个模型的F1 值分别提高了6.00、3.90 和1.40 个百分点,说明了残差收缩模块中的软阈值化有效地减少了句子内部的噪声,从而获得了F1 值的提升。
3)对比ResNet+att、RS、RS+att 这3 个模型可以看出,残差收缩模型和注意力机制是可以共同作用的,在只使用残差收缩的模型时,F1 值为0.645;在只使用注意力机制时,F1 值为0.667;当模型同时使用两者时,F1 值高达0.681。两种降噪方式共同作用取得了最高的F1 值。因为残差收缩模型处理的是句子内部干扰两个实体的噪声,而注意力机制处理的是包中标签错误带来的噪声问题,两者并不矛盾,共同使用时可以更全面地去除噪声从而获得更好的抽取性能。
4 结语
本文针对关系抽取中句子内部单词干扰产生的噪声问题,提出了一种基于软阈值模块的残差收缩网络模型。所提模型从两方面解决噪声问题:一方面利用残差收缩模块降低句子内部的噪声;另一方面利用注意力机制减少包中错误标注的噪声。实验结果证明残差收缩网络的关系抽取模型效果优于基线模型。未来的工作有两点展望:1)考虑到本文主要针对英文抽取,未来可能会将工作放到中文或者其他小语种的抽取上;2)尝试在模型中加入更多特征,如同义词向量表,提高模型鲁棒性。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
临床骨科杂志(2020年1期)2020-12-12
北京航空航天大学学报(2020年10期)2020-11-14
智能计算机与应用(2020年4期)2020-08-31
北京航空航天大学学报(2019年9期)2019-10-26
