
事件抽取综述
2022-11-08 12:48马春明李秀红李哲王惠茹杨丹
计算机应用 2022年10期
马春明,李秀红*,李哲,王惠茹,杨丹
(1.新疆大学 信息科学与工程学院,乌鲁木齐 830046;2.香港理工大学 电子及资讯工程学系,香港 999077)
0 引言
事件抽取研究具有重大意义和实用价值,是不同学科发展和融合的需要。在实际生活中,事件抽取研究在信息收集、信息检索、文档合成、信息问答等方面有着广泛应用,促使自然语言处理技术的发展取得了重大突破。事件抽取可以定义为检测特定类型事件并识别有关信息,即事件类别识别和事件元素识别。
将事件句从文本中检测出来,然后根据其特征判断其所属类别,即事件类别识别。在事件句的检测过程中,一般使用基于触发词的方法,在训练时实例化其中的每一个词,可以判定触发词是否存在于机器学习模型中。然而许多反例也被引进来,使正反例严重失衡。为解决上述问题,文献[1]中首先进行事件检测,然后对事件进行分类。这种方法是对部分事件进行特征选择,把特征选择中的正特征和负特征组合在一起,识别的效果较好。在基于触发词的方法中,不仅正反例严重失衡,还产生了数据稀疏性问题。为解决此问题,文献[2]中提出了一种全新的关于自动识别事件类别的算法。在事件句的分类问题中,主要使用了最大熵模型(Maximum Entropy Model,MEM)和支持向量机(Support Vector Machine,SVM)分类器进行分类。在进行候选事件句类别识别时,文献[3-4]中在基于二分类策略中均使用了以上两种分类器。在实际应用中,使用多元分类处理一个事件句属于多个事件类别的情况比使用二元分类更好,而用合适的事件特征来描述事件句以此提高分类的准确性是事件句分类的难点。文献[5]中利用选取词、上下文及其词典信息描述候选事件,在ACE(Automatic Content Extraction)2005 上进行测试,该方法的F 值为61.2%,效果良好。如果在原来的基础上引进依存分析,然后寻找触发词和别的词已有的句法关系,最后根据这个特征让事件句在支持向量机分类器上进行分类,该方法的F 值为69.3%。为提高事件类别的相关识别率,未来研究将会重点放在分类器和事件特征的选取上。
识别出真正关于命名实体、时间表达式和属性值的事件元素,然后对它们进行正确的角色标注,即事件元素识别。事件句一般包含许多实体、时间表达式、属性值等事件信息。为了过滤真实的事件元素,必须首先识别并标注信息,对于信息理解会议(Message Understanding Conference,MUC)来说,这是很重要的研究内容。对于事件元素识别来说,如果事件信息识别及其标注在文本预处理时已经结束,事件元素识别在任务方面会产生和语义角色标签(Semantic Role Labeling,SRL)类似的效果。在一个句子中,动词(谓词)和有关联的不同短语的语句间有着语义关系,根据语义关系把语义角色信息给予这些句子的成分,即语义角色标注。例如施事、受事或者工具等。文献[6]中角色标注了任职事件和会见事件的元素,在条件随机场(Conditional Random Field,CRF)取得了良好的标注效果,这也说明事件元素和语义角色之间存在一定的联系。
文献[7]中在进行事件元素的识别时运用了上述联系。对于底层的模块,如分词以及句法分析等,很依赖这种联系;如果它们不够成熟,可能造成很多级联错误,对事件元素的识别有一定影响。为解决此问题,使用分类问题的思想来进行事件元素的识别,运用了MEM。在对候选元素进行描述时,从四种特征多方面进行:取词法、类别、上下文以及句法结构。为实现事件元素进行自动识别,运用了二元和多元两种分类策略[3]。
在最近的事件抽取研究中,文献[8]中提出了一种基于对比学习的预训练框架CLEVE,让预训练模型更好地从大型无监督数据中学习事件知识和对应的语义结构,从而在有监督和无监督的两种场景下都取得了良好结果。
本文从不同角度对事件抽取的研究现状进行了总结与展望。可大致分为5 个部分:
1)从全局出发总结事件抽取算法以及评价方法,并介绍事件抽取所用的各种数据集以及与之相关的事件表示方法。
2)根据事件抽取的研究方向,详细介绍了元事件抽取和主题事件抽取的抽取方式以及使用不同抽取方式的研究现状。
3)介绍了中英文事件抽取的研究现状以及成果;跨语言事件抽取面临的问题及其解决方法,以及在未来研究中跨语言事件抽取的研究趋势。
4)根据不同研究角度,总结事件抽取相关技术,包括事件表示、元事件抽取、主题事件抽取、跨语言事件抽取的分类及特点。
5)事件抽取研究面临的问题以及未来研究趋势。
1 相关事件抽取算法及评价方法
事件抽取算法可分为四种:基于建立事件、事件句模板或者事件本体的模式匹配法;基于关键词的触发词法;基于领域本体的本体方法;把不同模型利用不同技术联合在一起的前沿联合模型方法。下文将对这四种事件抽取算法以及当前事件抽取主要的评价方法进行介绍。
1.1 基于模式匹配算法
以人工或自动构建的事件句子特征形式表示模板为指导的事件抽取,一般称为模式匹配。语义角色标注法与事件本体法是现有研究中最常用的构建模板的方法。
1.1.1 语义角色标注法
事件元素对应其语义角色,即语义角色标注法。对于实体、中心词词性以及关键词的层次,它们的语义约束在事件元素中完成定义。如果要使事件被匹配到,必要元素与相应的语义角色对应就会出现。首先预处理文本信息,然后在文本信息里进行语义角色标注,语义角色标注的语义信息通过词法分析对应得到;接着通过语义信息建立概念图,如果领域场景能被匹配到,就让规则库中的规则和映射规则一起匹配;最后,通过映射信息点实现抽取[9]。基于语义角色与概念图的抽取流程如图1 所示。
1.1.2 事件本体法
定义实体元素组、事件类别和事件的关系,从中得到特征项构建,再根据得到的特征项对事件和事件间的关系进行挖掘,即事件本体法。文献[10]中提出了一种基于事件本体的文本特征重构方法,该方法表明了事件本体法的实用性。在构建事件的特征项时,包括两个流程:一是基于本体进行特征压缩,这主要指对同义项进行合并;二是基于本体进行扩充,这主要指在事件文本中,添加已经失去的事件元素特征。
在“中奖欺诈”“网络色情”“非法交易”三类语料库上比较了基于事件本体并且支持向量机的方法和只支持向量机的方法的准确性,实验结果如表1 所示,与只支持向量机的方法(平均准确率为85.0%)相比,基于事件本体并且支持向量机的方法(平均准确率为78.7%)更加准确,这也说明了事件本体能让分类变得更准确。

表1 基于支持向量机与基于事件本体+支持向量机的文本分类结果Tab.1 Text classification results based on support vector machine and based on event ontology+support vector machine
1.2 触发词法
触发词法也叫作事件关键词法。在统计处理事件句时,在句子的文本中有一类情况出现的事件句比较多,这种情况基本都是在句子文本中有某一种术语或者词汇,因此可以通过创建事件触发词词典,使得事件抽取出现更好的效果[11]。
创建事件触发词词典的方法有两类:一是在应用中,如果触发词的词量没发生多少变化,就基于领域经验由领域专家手工创建,不过这种方法很依赖领域专家的经验;二是根据词汇在事件句中已经存在的分析统计,把触发词从相应的事件句中提取出来,这类方法比第一类方法在触发词的查重率方面有所提高。在触发词字典中,也有两类方法进行系统应用:一是通过程序自动地读取建立的触发词库,这种方法比较灵活并且容易维护;二是在程序代码中直接写入触发词,这种方法不够灵活,必须通过对程序进行修改才能进行触发词的增减操作[12]。
1.3 基于领域本体的本体方法
领域本体事件基于专业领域的概念、领域概念的属性、方法及其概念之间的关系,但是这些概念可能并不仅仅是事件,甚至有些基本不包含事件。如果把某一领域的事件作为研究的对象,那么该领域概念可以用事件来表示,并且概念间关系对应于事件间关系;但在事件实体里面,元素之间的关系一般不存在[13]。在事件抽取算法中,都会有一个预处理阶段,这个阶段一般包括有分词、词性标注、去噪、特征提取等。通过本体例库里存在的命名实体以及命名实体之间的关系等语义信息,合并有联系的词,删掉无用信息构成领域实体;为了使特征项变少,可以合并同义概念,增加预处理性能。邻域本体通常和触发词、模式匹配、语义分析或者机器学习算法一起使用,即基于本体的事件抽取算法。
1.4 前沿联合模型方法
前沿联合模型方法是利用技术把不同的模型联合在一起。下面介绍三种联合模型。
1.4.1 模式识别和支持向量机联合
文献[14]中在进行模式识别时,使用了基于SVM 的算法。在实验中设计了单分类器和多分类器两种算法,这是根据多元关系的特征进行研究,抽取事件的关系识别及其关系元。对于识别多元关系的全部角色,研究只使用了一种分类器,即单分类器算法;对于不一样语义约束的角色进行识别,研究在多种分类器上进行,即多分类器算法,实验结果表明,后者的算法效果比前者好。
1.4.2 机器学习和词嵌入联合
文献[15]中提出了一种抽取中文事件的方法。这属于商务事件抽取中的一种全新方法。在深度学习中,研究对模式、词嵌入技术以及机器学习模型进行集成。为扩展事件触发词的字典,运用了词嵌入以及事件触发词字典。在机器学习的算法中,引入了触发器特征,这种特征在字典中是存在的,研究使得事件类型识别变得更精细。
1.4.3 深度学习和词嵌入联合
文献[16]中提出了一种表示方法,该方法属于多重分布式表示,可应用在生物医学事件抽取中。在训练模型时,该方法中深度学习模型的输入使用了基于依赖的词嵌入和任务特征的分布式方法;在标记示例候选时使用了Softmax 分类器。实验结果表明了该方法的先进性。
1.5 事件抽取评价方法
主流的事件抽取评价方法有两种:
1)微平均值法。
设P表示正确标注的数量与系统中进行标注的总数之比,即准确率;R表示正确标注的数量与按语料标准进行标注的总数之比,即召回率;F为它们的综合度量值。计算公式如式(1)所示:
2)错误识别代价法。
设L表示丢失率;M表示误报率;Cmiss表示一次丢失代价;Cfa表示一次误报代价;Ltar表示当系统作出肯定判断时的先验概率,一般为常值。错误识别代价C的计算公式如式(2)所示:
在分析不同的算法效果时要运用不同的评价方法。通常单一的事件抽取都使用微平均值法来进行测评,而对于需要作出错误判断的事件比如话题追踪类任务等常用错误识别代价法来进行测评。
2 相关数据集
目前为止,事件抽取技术大多使用ACE2005 数据集,但是它数据规模较小,具有严重的数据稀疏问题,因此后续研究又使用了其他数据集或者借助其他资源来解决数据集问题。
2.1 ACE2005数据集
ACE2005 数据集是一种以阿拉伯文、英文以及中文作为培训数据并由关系、实体以及事件注释构成的不同类型的数据集。
ACE 语料解决了实体、值、关系、时间表达式以及事件这5 个子任务识别的问题,文档中存在的语言数据通过系统处理,这是子任务的要求。此外文档还要输出提到或者讨论子任务的信息。
下面是关于此版本中数据量、注释状态以及数据源缩略语信息:
adj、fp1、fp2、timex2norm 文件夹分别表示不同的标注过程。ACE 语料在所有任务上都是通过两个独立工作的标注器来进行标注。第一轮的标注成为1P,与之独立的双重第一轮标注成为DUAL。对于1P 和DUAL 来说,一个标注器完成文件的所有任务。文件是通过自动标注工作流程系统(Annotation Work-flow System,AWS)来进行分配的,而且文件分配是双盲的。Note:1P 和DUAL 在文件夹里都是以fp1和fp2 来存放的,也就是说1P 和fp1 对应,DUAL 和fp2 对应。每个文件的1P 和DUAL 版本之间的差异由资深标注员或者小组负责人来进行裁决,从而得到一个高质量的gold standard 文件。gold standard 裁决文件被称为ADJ(即ADJ 文件夹)。在裁决之后,TIMEX2 值被标准化处理以后得到NORM。这个语料中的所有数据集都已经被NORM 标注。表2 为英文数据源的注释状态,表3 为中文和阿拉伯文数据源的注释状态。
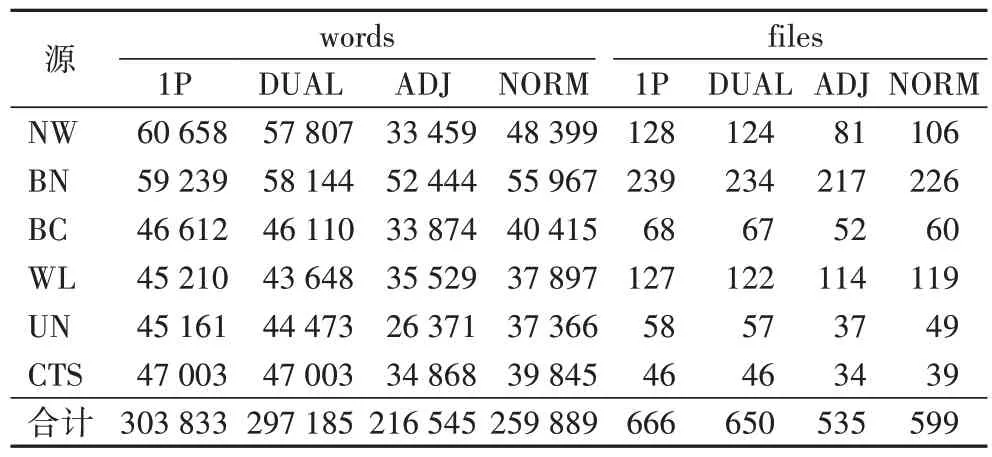
表2 英文数据源的注释状态Tab.2 Annotation status of English data sources

表3 中文和阿拉伯文数据源的注释状态Tab.3 Annotation status of Chinese and Arabic data sources
2.2 第四次信息理解会议数据集
第四次信息理解会议(Fourth Message Understanding Conference,MUC-4)事件抽取数据集包含1 700 篇发生在拉丁美洲恐怖袭击的新闻报道。MUC-4 数据集被切分为了1个dev 集和4 个测试集,其中dev 集包含1 300 篇文档,每个测试集中包含100 篇文档。在使用MUC-4 数据集时,使用了dev 集中的1 300 篇文章进行训练,test1+test2中的200 篇文章作为dev集,test3+test4 中的200 篇文章作为测试集。
MUC-4包含4 种类型的事件模板ARSON、ATTACK、BOMBING、KIDN。事件共用4 种槽位Prepetrator、Instrument、Target 和Victim。Prepetrator 是Prepetrator Invdividual 和Prepetrator Organization 的组合。MUC-4 数据集的标注样例如图2 所示。
2.3 Freebase数据集
Freebase 包含超过1.25×108个tuple 关系元组、超 过4 000 种类别、超过7 000 种属性,支持超大规模的collaborative data creation and maintenance,也就是支持信息之间的丰富关联并且赋予这种关联的使用。
Freebase 里的数据包含非常多话题和类型的知识,如关于人类、媒体、地理位置等信息。同时Freebase 不仅提供一个数据集或数据库,还提供较为便捷的访问方式。它支持面向对象的查询语言(Metaweb Query Language,MQL)与结构化的查询对象;还支持HTTPweb(Hyper Text Transfer Protocol web)端的访问和JSON(JavaScript Object Notation)数据格式的API(Application Program Interface)。
2.4 其他数据集
1)FrameNet(Frame Network)数据集是一个人读和机读的英语词汇数据库。它的基本思想很简单:事件、实体或者关系以及对参与者的描述叫作语义框架,而借助语义框架可以很好地对大部分单词含义进行理解。在ACE2005 数据集中许多类别事件存在着数据稀疏问题;为了解决该问题,引入FrameNet 数据集,在定义的事件类型里,让它与ACE2005数据集匹配,从而建立新的事件识别数据集。
2)TAC KBP(Text Analysis Conference,Knowledge Base Population)数据集2009—2018。TAC KBP 是通过美国国防高级研究计划局进行资助的一种对实体链接的评测,TAC KBP 数据集一般可用于事件抽取中,用手工进行标注,新闻与论坛是数据来源。
3)中文事件语料库(Chinese Emergency Corpus,CEC)属于生语料数据集,生语料来自互联网上5 种突发事件的新闻报道,经过了一系列操作处理,最终把标注结果保存到语料库。该语料库总计332篇,全面标注了事件及其事件的要素。
3 事件表示
把信息通过结构化的形式表示出来,即事件。而把结构化形式的信息表示为计算机能够理解的形式称为事件表示,它促进了人工智能的发展,与事件抽取任务有着密切联系。人们早期基本使用离散的事件表示,后来开始研究以深度学习为基础,用神经网络来进行向量表示的稠密事件表示。
3.1 离散的事件表示
早期研究者们基本都使用由事件元素构成元组的离散事件表示。如文献[17]中使用三元组(Oi,P,t)对事件进行表示,O表示给定对象集合,对象的谓词Oi⊆O;P表示对象与对象的关系或者属性;t表示事件的发生时间。文献[18]中则在事件表示中加入了角色元素,使用了六元组(P,O1,O2,O3,O4,t)进行标记,其中,P为事件发生时的动作或者状态,也即对象与对象的关系或者属性;O1为不同数量事件的实施者;O2为不同数量事件作用的对象;O3为使不同数量事件发生的工具;O4表示一个或者多个地点;t为时间戳,也即事件的发生时间。文献[19]中使用了四元组(O1,P,O2,t),P表示事件动作,也即对象与对象的关系或者属性;O1为实施事件者;O2为受事者,也即不同数量事件作用的对象;t为时间戳。一个事件仅有一个实施事件者和受事者。文献[20]中提出了一种事件表示方法。在脚本事件预测任务里,以时间为顺序将该方法与有关事件合成事件链。而在该方法中,构成以每个事件表示为动作并且动作和角色之间存在依存关系的二元组。由于角色在相同事件链中都是相同的,所以不用在事件表示中加入角色。
在离散的事件表示研究中,研究者们做了大量工作来对事件进行泛化,提出了基于语义的知识库,这很好地解决了离散事件表示所面临的稀疏性问题。例如文献[19]在事件元素中,基于WordNet(Word Network)把单词还原成词干,为得到泛化事件,把事件动作词泛化为一种类别名称,该类别名称存在于VerbNet(Verb Network)里。
3.2 稠密的事件表示
研究者们在深度学习技术不断发展的基础上对文本学习分布式的语义表示进行了探索。把字、词等文本单元嵌入向量空间,对于任意文本单元语义信息,由语义单元所在的向量空间位置确立,即分布式语义。在此基础上产生了稠密的事件表示,它的基础是预训练词向量,对此按照事件的结构进行语义组合。对于低维、稠密的向量,可计算事件的向量表示。稠密的事件表示分为两类:基于词向量参数化加法的事件表示和基于张量神经网络的事件表示。
3.2.1 基于词向量参数化加法的事件表示
对事件元素的词向量进行相加或拼接操作,再根据输入的参数化函数将它映射到事件空间向量,即基于词向量参数化加法的事件表示。文献[21]中提出对事件元素词向量进行操作,求取它的平均值。该方法属于基线方法。文献[22]中提出了一种向量表示方法,该方法拼接了事件元素词向量。文献[23]中提出一种词向量组合方法,组合前拼接了事件元素词向量,在多层全连接神经网络里面进行输入再组合操作。而文献[24]中忽视了组合事件元素的词向量,在文献[25-26]中直接用事件向量进行事件表示。不仅在事件表示中用事件元素向量的和或者平均值来表示,而且在不同的事件元素角色中出现相同词时使用不同词向量来表示。用|V|表示词表的大小,|R|表示角色的数量,H表示词向量的维数,三维张量T∈R|V|×|R|×H由不同角色词向量组成。通过三个矩阵A、B、C来表示三维张量T,并且用F个一阶张量的乘积来表示张量的分解,减少了模型参数数量。如式(3)所示:
设r表示角色独热向量,r和三维张量T的切片相对应。r和T的切片wr如式(4)所示:
最后,对于事件元素对应角色的词向量矩阵,可以在其中寻找其词向量,并且和所有事件元素词向量组合成事件向量。
3.2.2 基于张量神经网络的事件表示
对于基于词向量参数化加法的事件表示,虽然取得了良好效果,使词向量信息被完全利用,但对于建模事件元素来说,很难以实现交互,而且在建模时,事件表面形式的微小差异使之很困难。为了解决其中的问题,基于张量神经网络的事件表示被提出,该方法的事件元素通过双线性张量运算组合得到。
v1,v2∈Rd表示两个事件元素向量,三维张量神经网络T∈Rk×d×d,可得张量计算公式如式(5)所示:
vcomp的结果是k维向量,由向量v1、v2以及矩阵Ti相乘得到k维向量里一个维度i上的元素。为了取得事件论元的交互,在双线性张量运算中,模型作了相乘运算;因此,虽然事件论元只有很小的表面区别,但是对于事件表示来说,语义上会有很大差别。
文献[27]中使用了三元组(O1,P,O2),P表示事件动作或者状态,O1为实施事件者,O2为受事者。研究考虑了它的事件结构,使用了神经张量网络模型,模型结构如图3 所示。若使用O1、P、O2分别表示三种事件元素的词向量,即实施事件者O1的词向量为O1、事件动作或者状态P的词向量为P、受事者O2的词向量为O2,使用E表示组合两个向量的最终事件向量,Wi和bi均为张量参数。由张量运算、线性运算以及激活函数f组合起来,计算公式如式(6)~(8)所示:
文献[21]中同样使用了三元组(s,p,o),考虑了事件结构,其中:s表示主语,p表示谓语,o表示宾语,使用了谓词张量模型以及角色—因式张量模型,模型结构见图4。对谓语p用三维张量T进行建模。分别用s表示主语s的向量、p表示谓语p的向量、o表示宾语o的向量,事件向量e由主语向量s和宾语向量o通过张量T语义组合形成,它的每个元素ei的计算公式如下:
谓词张量(Predicate Tensor)模型通过张量T由谓语词向量p动态计算得出,然后由张量T语义组合主语和宾语。模型参数用W和U来表示,d表示词向量维数,W和U都是d×d×d的三维张量,如式(10)~(11)所示:
角色-因式张量(Role-Factored Tensor)模型单独地对事件的主语及谓语、谓语及宾语进行语义组合,组合后的两个向量通过线性变换后相加得到事件向量,如式(12)~(14)所示:
文献[28]中使用了较小维度的张量值来分解低矢量的张量,使模型参数变少了。低秩张量分解运算的示意图见图5。用T1∈Rk×d×r、T2∈Rk×d×r、t∈Rk×d这三个参数来代替三阶张量参数T,而T的近似值为Tappr,表示每一个切片,如式(15)所示:
在使用低矢量张量的分解时,不仅减少了模型参数,还能取得和以前模型差不多甚至更好的性能效果。
4 元事件抽取技术
元事件抽取方式有三类:基于模式匹配、基于机器学习和基于神经网络的元事件抽取。本章将对这三种类型进行详细介绍。
4.1 基于模式匹配的元事件抽取
模式的作用是在目标信息的上下文指定构成约束环,并且对语言和领域知识进行融合。在模式的指导下对元事件进行识别和抽取,即基于模式匹配的元事件抽取。为了使模式约束的信息得到满足,必须使用多种模式匹配算法进行抽取,构建模式是核心。基于模式匹配的元事件抽取分为两步:模式获取、元事件抽取,它的抽取框架见图6。
在基于模式匹配的元事件抽取中,早期使用手工方法获取模式,这种方法费时间和人力,而且用户要有相当高的技能水平。文献[29]中对句型模板进行填充时建立了抽取规则,该规则是通过手工来确定的。在文本进行处理后,对事件信息进行抽取并填充句型模板。文献[30]中研究了自动获取模式,提出了一种学习方法,该方法基于领域无关概念知识库。在学习模式中,信息抽取(Information Extraction,IE)任务被用户定义,在没有分类和标准语料中,IE 模式能自动被系统学习出来,降低了对用户的劳动力和技能的要求。文献[31]中将军事演习组块的识别和领域词典结合起来了,这是一种基于种子模式的自举方法。实验结果说明了该方法的有效性。
通常,使用模式匹配的方法来进行元事件抽取可以在特定领域内产生更好的结果;但是系统的可移植性不好,从一个领域移到另一个领域时,必须重新创建模式。建模既费时又费力,并且需要该领域的专家指导。尽管引入机器学习方法可以在一定程度上加快模式的获取,但是模式之间的冲突也是一个难题。此外,大多数可用的研究语义级别仍处于句法级别,并且语义级别仍需要改进。
4.2 基于机器学习的元事件抽取
4.2.1 基于机器学习的元事件抽取方法
基于机器学习的元事件抽取有两类方法:管道式抽取方法、联合学习方法。
管道式元事件抽取方法将抽取分为触发词以及论元识别等任务,它被转化为多阶段进行分类的问题。抽取的基础是触发词的识别,后面的抽取依赖触发词识别取得的成果。文献[3]中在抽取元事件时使用了管道式方法,分成触发词检测、论元检测、事件对齐以及事件关系检测四部分,并对它们进行特征选择,模型构建时选择了K近邻以及MEM 算法,针对同一任务对两类算法进行性能对比。
由于在管道式方法中,先进行触发词检测再进行论元检测,论元信息在前者不能被考虑到,这对前者的精度有所影响。针对该问题,研究者们提出了联合学习方法。这种方法对各个任务都建立了一个联合学习的模型,使得在提取触发词与论元信息时,它们之间有相互促进的良好效果。文献[32]中使用了联合预测模型,使用带不精确搜索的结构化感知器来联合提取同一句子中同时发生的触发点和论据。根据当前模型w寻找最佳配置z∈y,f(x,y′)表示特征向量,如式(16)所示:
感知器在线学习模型w,设D=为训练实例集(j索引当前训练实例)。在每次迭代中,x在当前模型下找到最优配置z,如果z不正确,则更新权值,如式(17)所示:
由于技术的挑战,还没有将联合产出结构作为一项单一任务进行预测的工作。而文献[33]中将实体识别和事件抽取作为一个联合任务进行,并用基于转移的神经方法进行建模。为了解决问题,研究使用了基于神经转换的框架建立了第一个模型,在状态转换过程中逐步预测复杂的关节结构,动作预测模型见图7。在该预测模型中,存储历史行为用栈A表示;存储的部分实体用栈e表示;维护未被处理的单词用缓冲区β表示;维护处理过的元素用栈σ表示;维护暂时从σ中出栈的元素;未来还会回栈的用队列δ表示;λ是一个变量,每次只提及一个元素。在标准基准上的结果显示了联合模型的优势,它给出了文献中最好的结果。
文献[34]中设计了一种基于跨度的事件提取器,采用联合学习抽取的方法对所有带注释的事件现象进行抽取。在新冠肺炎的预测任务中,自动提取的症状信息改善了测试结果的预测。该方法还将在事件抽取相关领域继续使用。
总而言之,尽管基于机器学习的元事件抽取方法对语料的内容格式不是很依赖,然而却存在着数据稀疏性问题,必须使用大规模语料。现如今的语料不能满足要求,使用人工标注又比较浪费人力资源;另外,机器学习的结果与特征选取有关。因此机器学习方法研究的重点是解决数据稀疏性问题和选择合适特征。
4.2.2 核心任务及面临问题
事件类别识别、分类和事件元素识别是元事件识别的两种核心任务。当识别元事件利用机器学习的方法时,元事件的分类及其文本分类存在差异,它的主要特点是分类简短,大部分是完整的句子。由于它是事件表述语句,因此语句中包含的信息量很大。
在事件元素的识别任务中,文献[35]中第一次引入MEM,实现了事件抽取。该模型在估计概率时使用了除所施加的约束以外尽可能少的假设原则。这些约束通常来自训练数据,表达特征和结果之间的某种关系。满足上述性质的概率分布是具有MEM 的概率分布,它是唯一的,与最大似然分布一致,并具有指数形式,如式(18)所示:
其中:o表示结果;h表示历史(或上下文);Z(h)是归一化函数。每个特征函数是二元函数。例如,在预测单词是否属于单词类时,o是true 或false,h指的是周围的上下文。如式(19)所示:
文献[36]中在研究语义角色标注时,用了CRF 模型来做实验。这还有利于在TimeML(Time Markup Language)进行事件抽取,使得系统的性能大大提高了。为了使系统识别的能力提升,有时候让机器学习和模型匹配混合使用或者使用多个机器学习算法。如文献[3]中为了完成事件类别识别和元素识别,把MegaM 和TiMBL(Tilburg Memory-Based Learner)这两类机器学习算法联系在一起,并在ACE 语料库上进行了实验,证明了该方法比单一算法好。
以上对于事件的探测,都利用了触发词,但它只占全部词的小部分,致使在训练时许多反例被引进来,正反例严重失衡。并且在判断每个词的时候,增加了额外的计算量。为了解决此问题,文献[37]中在对事件类别进行识别时,采用了将触发词扩展与二元分类结合的方法。在相同特征下,分别测试文献[2]与文献[37]中的方法,实验对比结果如表4所示,表明了文献[2]中的方法更有优势。此外,在训练模型时,文献[2]中的词典收录了触发词并且扩展了同义词,解决了正反例严重失衡的问题,还使数据稀疏得到了缓解,在ACE 数据集上的实验结果显示得了良好的效果。
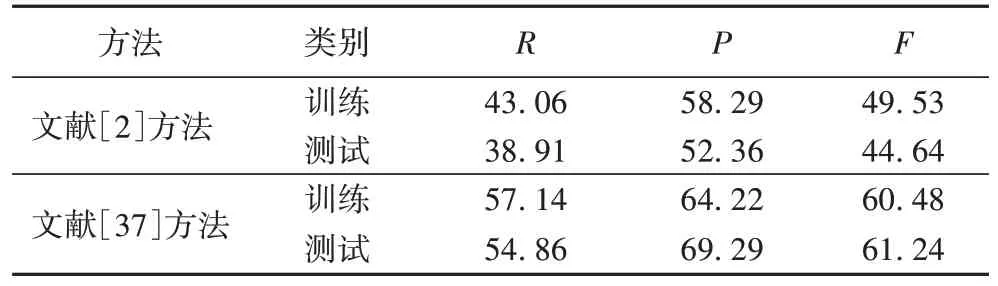
表4 相同特征下不同方法的实验结果对比 单位:%Tab.4 Comparison of experimental results of different methods under same features unit:%
文献[2]和文献[4]在进行事件探测时不使用传统的基于触发词方法,而使用了基于事件实例方法。该方法识别实例为句子而不是词语,解决了正反例严重失衡的问题,数据稀疏也得到了缓解。在文献[2]的实验中,为把非事件句筛选掉,使用了二元分类器,再对取得的候选事件句进行分类,使用了多元分类器。在实验中,分别对8 类事件类别以及33类事件子类别进行测试和训练,实验结果如表5。文献[4]中则将问题转化为聚类问题,以此得到事件句。
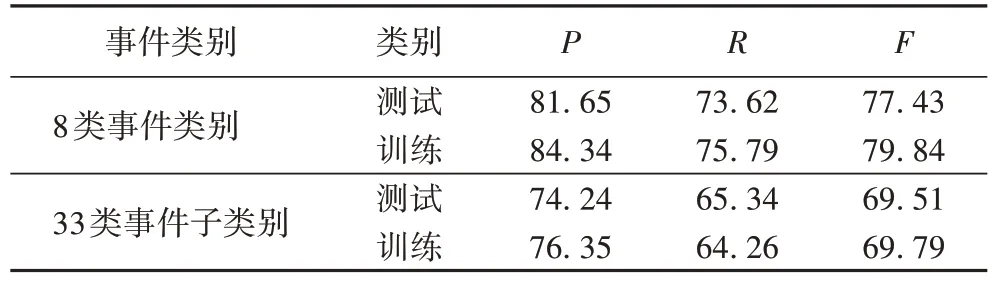
表5 文献[2]方法在不同事件类别上的实验结果 单位:%Tab.5 Experimental results of literature[2] method on different types of events unit:%
此外,文献[38]中提出了一个新的学习范式,将事件抽取转换成为一个机器阅读理解问题。该方法是将事件模式转换成一组自然问题,是一种基于网络的问答过程,以事件抽取的形式检索答案。实验结果显示了该方法在解决数据稀疏性和正反例失衡问题的优越性。
4.3 基于神经网络的抽取方法
在元事件抽取方法中,结合神经网络进行抽取是一种主要方法,该方法属于有监督多元分类,该方法有特征选择以及分类模型两大流程。本文分别从使用特征的范围不同、模型学习方式不同、是否融合外部资源三方面对该方法进行描述。
4.3.1 根据使用特征的范围分类
句子级和篇章级是元事件抽取根据使用特征范围的分类。特征仅由句子内部得到的是句子级事件抽取,它的特征适用于全部事件抽取;特征里面有跨句子、跨文档信息的是篇章级事件抽取,它的特征适用于面向实际任务挖掘。
在句子级基于神经网络的事件抽取中,与传统离散特征的区别是它的特征是连续型向量,并在此基础上学习了更抽象的特征,该特征依托在各种各样神经网络模型上。如文献[5]中在事件抽取和事件识别任务中都使用了同样的方法,即神经网络方法。在传统卷积神经网络(Convolutional Neural Network,CNN)模型中,为使性能方面有所突破,加入了动态多池(dynamic multi-pooling)机制,构成了动态多池CNN(Dynamic Multi-pooling CNN,DMCNN),DMCNN的结构[5]如图8 所示。
对于当前词,输入这个词和它前后的c个词的embedding,通过DMCNN 可以得到特征向量,再通过特征向量进行有监督训练完成抽取和识别。此外,对于事件抽取和识别,在初始表示每个单词时都选择了预训练词向量;在建模研究中,都对单词的语义和语法信息进行了组合。实验结果表明使用神经网络特征对句子级事件进行抽取可以取得良好效果。
在篇章级基于神经网络的事件抽取中,需要跨句子或跨文档信息,以此作为特征来完成任务。如文献[7]中首先研究端到端神经序列模型(带有预先训练的语言模型表示)如何在文档级角色填充提取中执行,以及捕获的上下文长度如何影响模型的性能。为了动态地聚集在不同粒度级别(例如句子级和段落级),提出了一种新的多粒度阅读器。
在多粒度阅读器模型结构嵌入层中,每个token 通过单词嵌入和上下文符号表征拼接表示;词嵌入使用GloVe(Global Vectors for word representation)词向量模型,获得固定长度的预训练词向量。预训练语言模型表征已经被证明了拥有可以超出句子边界建模上下文的能力,并且在一系列自然语言处理任务上表现良好。在MUC-4 事件抽取数据集上评估了该模型,结果表明最佳系统比以前的工作表现更好。多粒度阅读器模型结构如图9 所示。该模型与DMCNN 类似,均是由嵌入层到句子级别,再进行后续抽取和识别;而与DMCNN 分类器提取结果不同的是该模型使用了融合机制再到CRF 的过程。
文献[39]中提出了一种文档级别的神经事件参数抽取模型,通过将任务公式转化为事件模板后的条件生成,还通过创建一个端到端的零触发事件提取框架表明了模型的移植性。
在以前的事件抽取研究中,大多数方法都直接基于触发词的有关特性进行研究,如一些分类的任务被用来辅助论元角色;但在对触发词进行识别的任务里,没有研究论元信息对它的作用。文献[40]中通过结合注意力模型,在事件识别里面成功地输入了论元信息,该注意力模型属于有监督论元。实验结果表明当识别事件触发词时,可以使用论元信息进行辅助。在该论元注意力模型中,在进行触发词的识别时,将论元信息直接与之结合起到辅助作用,这与在联合模型中间接地对触发词和论元信息进行结合然后共同辅助是不一样的。如果把事件检测当成多分类任务,而在句子中,将每一个符号全当成候选触发词,对候选触发词进行分类就是它的目标。
论元注意力模型由上下文表示学习和事件检测器两部分组成。其中,上下文表示学习的主要作用是通过注意机制获取上下文词汇的表示和实体类型信息的表示;事件检测器的作用是基于已经学习到的表示来对每一个候选词进行分类,也就是对事件进行分类。模型结构如图10 所示,该模型与DMCNN 均采用了分部分层次进行事件抽取的操作,最后均由分类器对结果进行输出。
4.3.2 根据模型学习的方式分类
根据模型学习方式分类的元事件抽取有流水线和联合模型。
流水线模型把元事件抽取分为触发词识别和论元识别等任务,依次完成全部任务。其中,在所有元事件抽取流程中,基础是触发词识别,它取得的成果将会对之后的工作产生很大影响。由于文献[3]中没有考虑到论元信息,其触发词的精确度有影响,因此研究者们提出了联合学习方法。
文献[32]中在进行事件识别及其对论元角色进行分类时,采用了联合学习的方法。结构化感知机(structured perceptron)在研究中起到辅助作用,用来在联合学习中完成2 个任务,即实体识别和实体对的关系分类。研究中还使用离散特征进行特征表示。该研究发现了联合学习方法比流水线方法效率更高,这在论元角色进行分类时更为突出。在基于神经网络的元事件抽取中,使用联合神经网络模型还简化了特征工程。文献[41]中在进行事件识别及其对论元角色进行分类时,也采用了联合学习的方法,设计了一种基于循环神经网络(Recurrent Neural Network,RNN)的模型。为进行特征表示,设计了局部和全局特征,其中,文本序列和局部窗口特征属于局部特征。在基于RNN 的模型中传入句子表示,序列特征由此获得;局部窗口特征通过窗口里面的词向量获得。此外,还设计了记忆网络(Memory Network)模型进行建模,由此获取了全局特征,并且2 个任务的性能也有所提升,取得了良好效果。
以前大多采用联合学习方法进行事件识别及其对论元角色进行分类,而文献[42]中首次对联合学习实体进行识别。在文档中抽取事件以及实体,在此环节通过联合推断让信息流贯穿3 个子模块,并且在全局优化中为触发变量t、论元角色变量r及实体变量α赋值,如式(20)所示:
式(20)由三部分组成:第一项是在事件内部结构模块的预估参数上单个事件置信度之和;第二项是事件对模块的预估参数上事件之间关系的置信度之和;第三项是实体识别的置信度之和。实验结果在置信度上取得了良好效果,该研究也在联合学习实体识别任务上取得了重大突破。
此外,文献[43]中提出了一种事件提取的可解释方法,通过为两个目标联合训练来缓解泛化和可解释之间的紧张关系。使用一个编码器-解码器架构,它联合训练一个用于事件提取的分类器以及一个规则解码器,生成解释事件分类器决策的语法-语义规则。在解释事件分类器中,有以下学习以及训练过程,如式(21)~(26)所示:
其中:Wq、WK、Wv为学习矩阵,维数为200×200;HE包含双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)的隐藏状态;Hz是HE中实体z的隐藏状态。将每个上下文向量C与实体向量H连接起来,并使用一个Softmax 函数将连接的向量提供给两个前馈层,使用其输出预测该位置是否有触发器,使用二进制日志损失函数计算分类器的损失。这种方法可以用于半监督学习,并且当在由基于规则的系统生成的自动标记的数据上进行训练时,其性能得到了提高。
文献[44]中提出利用事件中参数的角色信息,设计一个分层策略网络(Hierarchical Policy Network,HPNet)来执行联合事件抽取(Event Extraction,EE)。整个事件处理过程是通过一个两级层次结构来完成的,该结构由两个用于事件检测和参数检测的策略网络组成,实现了子任务之间的深层信息交互,处理多事件问题更加自然。在ACE2005 和TAC2015进行大量实验,分别使用MEM[35]、DMCNN[5]、HPNet[44]的实验结果如表6 所示。从表6 可以看出HPNet 具有最先进的性能,并且对于具有多个事件的句子,优势更明显。

表6 ACE2005和TAC2015数据集上各个模型的结果对比 单位:%Tab.6 Results comparison of different models on ACE2005 and TAC2015 datasets unit:%
4.3.3 根据是否融合外部资源分类
在元事件抽取任务中,大多使用ACE2005 数据集,它含有很稀缺的有标记事件数据,但是标注质量不太好,而且规模很小、事件类型也很稀疏,这对完成事件抽取整体任务有很大影响,所以大量研究都试着使用外部资源来完成抽取。根据是否融合外部资源,可分成基于同源数据和融合外部资源两类。
文献[45]职工为解决事件类型稀疏的问题,使用了FrameNet 数据集来辅助抽取。将ACE2005 的事件类型上加入FrameNet 里面的框架进行匹配,研究设计了全新的基于FrameNet 的数据集,该数据集在事件识别等任务上取得了良好效果。
对从FrameNet 检测到的事件进行间接评估,它基于的直觉是具有更高精度的事件预计会给基本模型带来更多的改进。使用自动检测到的事件扩充ACE 语料,然后分别使用文献[5]方法、文献[40]方法、文献[41]方法、只使用人工神经网络(Artificial Neural Network,ANN)[45]、在ANN 中加入FrameNet 方法[45]共5 种方法进行实验,结果如表7 所示。可知文献[45]中的两个方法在FrameNet 事件检测中的有效性。
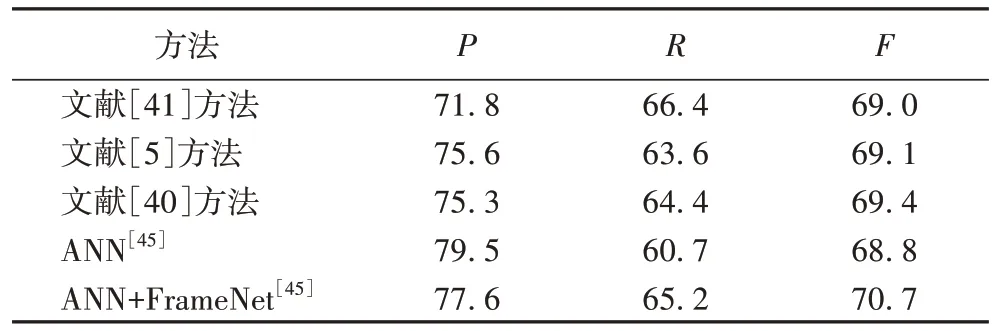
表7 使用自动检测到的事件扩展训练数据的效果 单位:%Tab.7 Effect of expanding training data with events automatically detected unit:%
此外,文献[46]中融合外部资源,研究设计了一个基于维基百科的事件数据集,该数据集使用了Freebase 来辅助设计。在Freebase中,首先使用了统计方法找到在它任一事件类型里面的关键论元集合,然后通过在维基百科里面的每个句子,判断它里面是否存在Freebase 里的任一事件实例的全部关键论元,以此来判断里面有没有存在事件。在存在事件的维基百科句子里使用了统计方法,以此找到每个Freebase事件类型里面的重要触发词。为对触发词进行筛选和对名词性的触发词进行扩展,还借用了FrameNet 来辅助进行,最后得到了数据集。该数据集是从维基百科中得到的有标注的数据集,它被用来和ACE2005 数据集一起训练模型。
为了获取事件抽取所需数据的方法,可用Freebase 和FrameNet 进行自动标注。任一事件类型的关键论元与触发词都可以通过以上方法探测得到,最后利用得到的关键论元与触发词来从文本中标注事件。该方法的体系结构如图11。
文献[47]中使用了外部资源来建立批量事件数据集,该数据集是从维基百科和Freebase 中建立的。为确定事件是否发生,该研究以是否含有关键论元来确定,这和以前在ACE2005 中用触发词的方式来确定有所不同。此外,为获得每个事件类型的关键论元集,该研究也使用了统计方法,从Freebase 里面进行抽取。设计中还含有事件抽取正例,这是从事件实例的关键论元的维基百科句子得来的。此外,为得到质量更高的有标注数据集,该研究还对远距离监督的进程实现了约束。
在以上研究中,事件抽取是直接抽取关键的论元,再加上论元大多是词组,因此将事件抽取转化成一个序列标注问题。目标是标出句子里的标签结构BIO(Beginning,Inside,Outside),从而找到了这一堆实体,再去元数据CVT(Compound Value Types)表里匹配即可。序列标注的模型使用Bi-LSTM+CRF+整数线性规划(Integer Linear Programming,ILP)。Bi-LSTM 可以对于每个单独的词,很好地预测标签BIO;CRF 的目标函数是整个序列的联合概率,可以让相邻的标签之间满足该有的依存规则;ILP 的过程是最大化目标函数,如式(27)所示:
其中:P和A分别是CRF 中的发射分数(emission score)和过渡分数(transition score);Pi,j表示标签i到标签j的概率;Ai,j表示标签i到标签j的过渡分数,是给定的参数。
此外,文献[48]中使用了外部资源来进行事件抽取,通过设计一种面向任务的对话系统,形成了一个由强化学习驱动的框架,实现了利用事件参数关系来进行事件抽取,并在ACE2005 上评估了该方法的优越性。文献[49]中则是将事件抽取范例公式化为一个问答任务,基于问答系统以端到端的方式提取事件参数,实验结果表明了该方法的优越性。
5 主题事件抽取技术
元事件抽取只能在句子层面进行抽取,为了满足对一个及其以上的文档进行抽取,主题事件抽取应运而生,它是由一个以上的动作或者状态构成。为了对相同主题事件中的文档进行描述,需要确定进行描述的文档集合;并且在主题事件的集合里面有许多片段,需要将它们进行合并,这些是主题事件抽取的核心。将主题事件抽取分为基于事件框架和基于本体的主题事件抽取两类。
5.1 基于事件框架的主题事件抽取
对事件框架进行定义,将它结构化、层次化,然后对主题事件抽取进行指导,通过框架来阐述主题事件的各方面以及归纳事件信息,即基于事件框架的主题事件抽取。可以把框架当作一类知识表示的方法,可对有关概念的轮廓框架进行刻画。在人们处在一个新的状态时,会在人脑中进行搜索,从众多情景状态里面找到其中一个,让它来认识新事物。这些众多的情景状态就叫知识框架。对于事件侧面,在语义上能够对它进行分离,因此框架结构属于一种分类体系,把它用来对各种各样的事件侧面进行分隔。对于事件,需要用词语形容它的不同侧面,这样的词语称为“侧面词”。而分类体系可通过“侧面词”进行创建,这就是事件框架。对于框架方法,核心是要出现完全的事件框架体系;对于研究者们,研究的方向是提高构建框架的完整性和自动化程度,这也是研究的重点。
5.2 基于本体的主题事件抽取
在知识工程与人工智能中,本体是很重要的课题,主要用来得到有关的领域知识。关于领域知识,它们之间有共同理解,还能找到其中一起认可的词汇,对于这一系列词汇彼此之间的关系,能从各种各样的层次形式化模式里得到。根据本体的特点,很适合进行主题事件抽取。对于基于本体的主题事件抽取,主要是按照本体描述的信息来进行抽取,该信息包括概念、关系等,抽取的内容是文本里面的有关实体信息和侧面事件。抽取按照3 步进行:建立领域本体,是后续抽取工作的基础;基于领域本体根据文本内容进行自动语义标注;基于语义标注进行抽取。
文献[50]中设计了一类基于本体的事件抽取。在建立本体的过程中,提出了领域层、类别层、事件层、扩展概念层4 层模型。本体中所在领域的名称是领域层,许多个专家定义的类别层构成了它;任一类别都包括一系列事件集合;任一类别包含的事件类由事件层定义;事件和对象的概念以及对任一类事件相关的角色和概念及对应的子事件,这在扩展概念层进行定义。当对新闻事件进行抽取和在自动文摘中,可使用这个构建模型的本体,实验结果表明在中文气象这类新闻事件抽取时能更好地运用这个系统。
文献[51]中构建了一个进化的事件知识本体,以此探索从文本中自动获取事件知识的框架,指出未来研究将用此框架扩展数据,并将进化的事件本体扩展到大规模的事件实例中。
6 跨语言事件抽取
6.1 中文事件抽取
中文事件抽取存在着一系列问题:一方面是方法问题;另外一方面是语言特性问题,其中词句意合特性是首要问题。中文词语之间未曾出现显式间隔,并且分词之间显然存在着错误与误差。
在中文事件抽取中,文献[52]中指出触发词的不一致,并把该问题分为跨语言不一致以及内词语不一致两个类别。为解决上述问题,提出了两种方法:1)在基于词语的触发词标注中,可以对测试集里面分词不一致的触发词进行修正;使用训练集创建一个全局勘误表,该表可以对测试集进行修改。2)在基于字符的触发词标注中,可以对触发词检测进行操作,将它转变为序列标注问题。基于词语和字符的方法之间的性能比较如表8 所示,实验结果表明基于字符的方法比基于词语的方法性能更好。

表8 基于词语和字符的方法之间的性能比较 单位:%Tab.8 Performance comparison between methods based on words and characters unit:%
文献[53]中除了利用基于序列的字符标注法,还运用了Bi-LSTM 以及CRF,利用它们来抽取句子特征。在对上下文语义特征进行抽取时,还使用了CNN,更好地完成了中文事件抽取。另外,中文事件抽取还存在着严重的数据稀疏问题,触发词相当多,而大量未知的触发词将会出现在测试集中。文献[54]中对未知的以及分词错误的触发词进行识别时,使用了中文语言组合语义以及语言一致性,使得系统性能有很大提升。
6.2 英文事件抽取
基于统计以及机器学习的方法是研究英文事件抽取的主要方法。文献[35]中使用了MEM 来进行事件抽取研究,在命名实体等不复杂特征上具有很好成效。
文献[3]中将事件类型与触发词的识别进行等同,基于触发词进行事件抽取。在对事件类别和子类别进行识别时,除了使用触发词识别的二元分类以外,还使用了多元分类器,在ACE2005 上显示了其效果很好。文献[55]中创建了关于跨文档的事件抽取系统,对当前句信息进行操作,在其基础上,把有关的文本背景知识植入进去。文献[56]中使用了文档级别信息,用它提升了系统性能。文献[32]中提出了一个联合学习模型,该模型基于结构化感知机,在实验中对事件触发词与论元进行学习然后抽取,该实验效果良好。
6.3 跨语言事件抽取
基于易得的大规模语料,事件抽取在中英等单语上已经取得足够优秀的成果,而跨语言事件抽取仍然面临着许多问题。
迄今为止,利用跨语言训练来提高性能的工作非常有限。为解决此问题,文献[57]中对众多双语平行语料进行操作,对跨语言谓词集进行抽取,接着使用抽到的谓词集对中英文事件抽取进行操作,以提高其召回率。文献[58]中对特征进行叠加,以此融合双语信息,还在中英文事件中都完成了触发词分类。文献[59]中则是提出了一种全新的跨语言事件抽取方法。这种方法训练了大量的语言,并通过语言特征的依赖性和不依赖性来促使性能提高。该方法不采用高质量的机器翻译或者手动对齐文档,因为给定目标语言是无法满足该需求的。
此外,跨语言还需解决缺乏标注数据给事件检测带来的挑战性问题,通过在不一样的语言之间传递知识,促使性能提升。以前的方法严重依赖并行资源,限制了适用性。为解决此问题,文献[60]中提出了跨语言检测的新方法,实现了并行资源的最小依赖。为了构建不同语言之间的词汇映射,设计了一种上下文依赖的翻译方法;为了解决语序差异问题,提出了一种用于多语言联合训练的共享句法顺序事件检测器。在两个标准数据集上进行了大量实验,实验结果表明该方法在执行不同方向的跨语言迁移和解决注解不足的情况下具有良好的效果。
从资源不足以及注释不足的语料库中进行复杂语义结构的识别(例如事件和实体关系)是很困难的,这已经成为了一个具有挑战性的跨语言事件抽取任务。为解决此问题,文献[61]中通过使用CNN,将所有实体信息片段、事件触发词、事件背景放入一个复杂、结构化多语言公共空间,然后从源语言注释中训练一个事件抽取器,并将它应用于目标语言。文献[62]中引入了一个图形注意力转换编码器(Graph Attention Transformer Encoder,GATE)。由于对句法分析的依赖,GATE 产生了健壮性,有助于跨语言的传输。实验结果表明了该方法在跨语言事件抽取上的良好迁移效果。
基于以前的研究,很多小语种缺少标注语料。由于面临着语义表征等问题,面向小语种的跨语言事件任务成为目前研究的难点。
7 事件抽取技术总结
在事件抽取中,元事件抽取是动作状态级的,动作产生或状态发生变化,一般由动词驱动;而主题事件抽取是事件级别的,指的是核心或者与之有关的事件或者活动。表9 详细总结了事件抽取与之相关的各项技术分类以及特点。
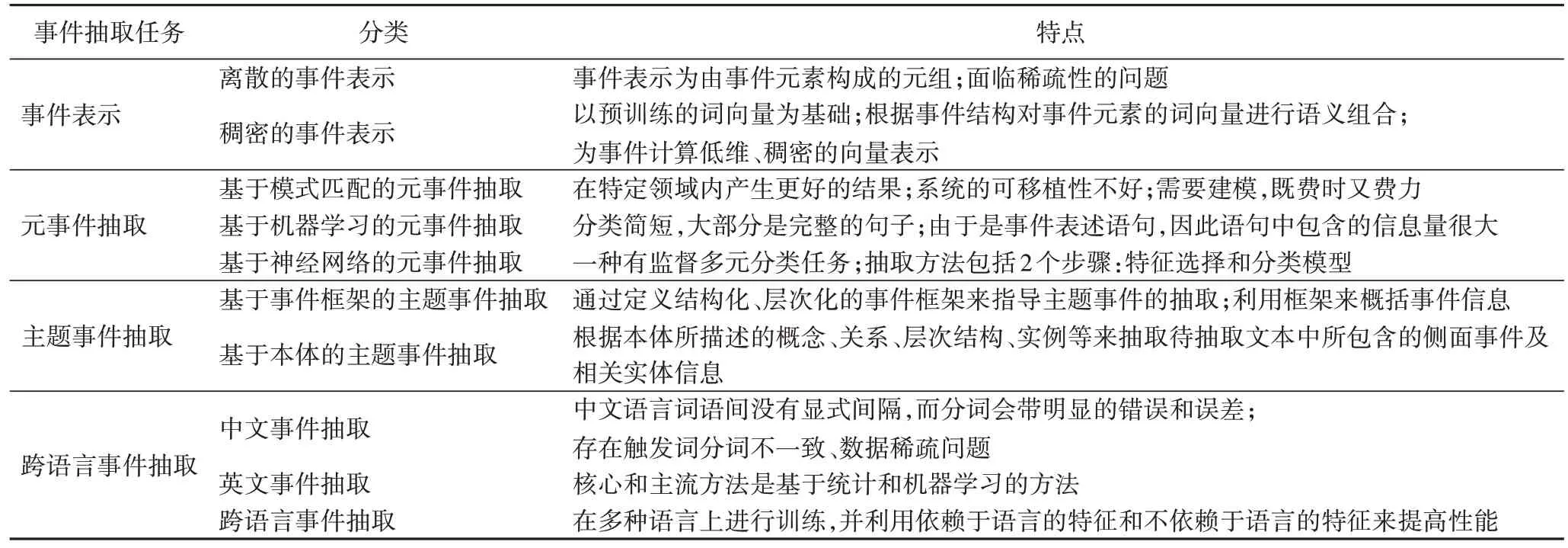
表9 事件抽取技术总结Tab.9 Summary of event extraction technologies
8 事件抽取面临的问题及未来研究趋势
8.1 面临的问题
事件抽取经过长期的发展已经取得了大量的研究成果,尤其在最近几年,随着社会化网络、电子商务应用的快速发展,事件抽取的研究进步更明显。但是从整体来看,还是存在以下问题需要解决:
1)目前研究事件抽取主要用的是ACE 标注语料,但是定义事件类型有限。当前方法仅仅对特定类型事件有用,缺乏可移植性和可扩展性。
2)现阶段的事件框架体系不是通用的。仅通过人工来标注语料数据,费时费力且成本高昂,并且通过这种方式产生的事件语料数据规模小、类型少。
3)事件抽取依赖于子任务结果,为实现多任务联合,怎样设计神经网络模型是一大难点。
4)大量小语种缺少标注语料,面向小语种的跨语言事件抽取面临着语义表征等问题。
8.2 未来研究趋势
在事件抽取技术的研究与发展过程中,尽管面临诸多挑战,也必将受到研究者越来越多的关注,并在未来的研究中呈现出以下趋势:
1)如今对事件抽取进行研究时,都是分开提取短语和依存句法分析信息的特征,怎样对这两种句法分析获取的信息进行全面分析,获得更有效的句法特征需要进一步研究。
2)在事件抽取中,对当前方法的局限性进一步分析;对任一子任务的影响程度进行量化。不仅需要提升句法分析这些基本任务性能,还需要使用新的方法与技术来提升事件抽取中任一子任务的精度。
3)如今对中文事件进行抽取时,大多都是基于现有语料的,实体信息都是已经标注好的语料,在没有标注好的生语料中抽取效果很不好。怎样对没有标注文本的中文事件进行抽取也值得进一步研究。
4)如何解决标注语料的缺失、面临语义表征等问题的面向小语种跨语言事件抽取是进一步研究的重点和难点。
9 结语
从当前研究来看,尽管研究者们对事件抽取技术已经进行了大量研究,在理论以及应用上都取得了许多成果,但依然没有达到实际应用的水平,事件抽取仍然存在大量需要研究的方向,同时还有许多问题需要解决,如如何更好地从无结构纯文本中自动抽取结构化事件知识等。研究者可能最需要关注的是可移植性以及系统性能问题;从作者自身角度上说,如今的事件抽取技术可能大多集中在某一领域进行研究,希望未来研究能渗透到不同领域,让事件抽取技术在多个领域实现创新和发展;诸如小样本和零样本这样的事件抽取研究甚少,希望未来研究能解决某些技术性难题,在这些方面有所贡献;主题事件抽取的研究尚未成熟,还面临着许多困难,能否借鉴神经网络以及外部资源来进行主题事件抽取是作者自身的一个猜想。
此外,事件抽取是自然语言处理的一个分支,它的研究价值已得到广泛重视和认可,不仅需要认识并研究它,还需要对比它和自然语言其他领域的区别和联系,以求创新来引导事件抽取研究的不断发展和进步。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
速读·下旬(2021年11期)2021-10-12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
