
云计算中基于群体智能算法的大数据聚类挖掘*
2022-10-14 13:51刘现芳
科技创新与生产力 2022年9期
龚 静,刘现芳
(湖南环境生物职业技术学院,湖南 衡阳 421005)
云计算背景下,信息技术获取的数据信息呈现出海量爆发状态,人们所生产和运用的数据增多,类型也越来越复杂,采用数据挖掘技术从海量数据信息中挖掘出有价值的数据,成为人们在数据方面的研究热点。聚类分析是大数据挖掘技术中的重要组成内容,将各类相同特征的数据进行分类,是大数据挖掘算法中的核心内容之一。但是,在传统的聚类分析中,模糊均值算法和K 均值算法都需要采用多次数据迭代的方式进行数据挖掘,该种数据运行方式不仅使数据挖掘效率受到限制,数据挖掘的质量也因此受到负面影响。云计算背景下,人们设计出群智能算法,并以该算法为前提展开数据聚类挖掘。当今时代,网络数据庞大,人们需要有选择的处理数据信息,云计算的方式可以将多项数据协调在一起,打破用户在空间和时间方面的数据应用限制,获取无限数据资源,使用的大数据挖掘技术也更加灵活。
1 聚类分析概述
作为信息挖掘的一项主要研究方向,聚类分析日益受到人们的关注。聚类的输入通常是一个没有分类标识的数据,人们事先可能知道这种数据聚成几个簇,也可能不知道聚成几个簇。通过分析这种数据,可以按照相应的聚类规则,合理分配记录集,从而使相同的记录被分配到一个簇中,不同的数据分配到不同的簇中[1]。
聚类分析算法问题一直是研究人类活动的一项非常重要的内容。人们早在远古时代就形成了对事物做出分类识别的思想,“物以类聚,人以群分”就是对这一思想的形象表述。一个人早在孩童时代,就利用不断完善潜意识中的分类模型,来学习辨别不同的物种。随着人们对自然界和社会认识地不断深入,要处理的数据也出现了如下发展趋势:人类规模愈来愈大,彼此关联愈来愈复杂,分类也愈来愈精细,对提出的问题需求也愈来愈高[2]。这时单纯依靠定性分析法,是无法满足要求的。为克服这种困难,人类首先引进了数理教育这种得力的教学工具,并在此基础上进一步发展产生了数据分类学(Numerical Taxonomy),对分类对象进行定性的研究。而经过定性的研究后,在分类的过程中不再只是凭借经验和知识,还得借助于对数据本身的分析方法对数据对象加以分类。数据分类方法不但能够运用于分类领域,还能够用于聚类领域,也因此产生了基于数值分析的聚类分析[3]。
电脑的广泛应用已深入到人们生活的方方面面,存储商业贸易记录、管理企业工作、监视生产操作、提供娱乐工具和消息交换等。由于互联网的出现,人们也步入网络信息社区,大量的数据信息被存储下来,但如果人们对数据信息聚类处理的方法还是通过人工,则无法实现。这也导致利用计算机进行数据信息聚类分析的新技术的诞生与发展。
聚类分析算法尽管已被应用在很多领域中,但是都存在着这样或是那样的缺点。这种不足总体来说主要有如下4 个方面。
一是对初始化参数敏感,最后结论往往强烈地取决于初始化工作参量。在这种算法的初始化输入中,不仅要求聚类的数据,还需要为用户输入一些相应的工作参数,而这种参量所确定的高低也影响着聚类结论的高低。对于普通用户来讲,参数的选取具有一定的难度[4]。
二是难以得到最佳聚类。一组含有n 个数据群的数据集合,如果假设将其聚成k 个群,就具有k"种可能,但目前还缺乏一项能从k" 种聚类中找到最佳聚类的计算。因为现在的计算通常是利用某个引导算子,完成某种在全部空间上的不完整查找,而且利用这种引导算子常常会陷入局部最优解。
三是聚类的效率问题。为了用好无导师学习方法,如果并不了解大数据分析或集中信息的分布状况,就会产生聚类分析法结论的有效性问题,即在所得出的聚类分析法结论中类别的数量是不是合理?在众多的聚类算法中哪一种得出的结论更合理?又或者在一个聚类算法中,哪个参数所得出的聚类分析法结论更合理?这都是无从判断的[5]。
四是对噪声信息的高敏感性。现在许多聚类算法都对噪声数据非常灵敏,而噪声数据的出现也影响着这种计算的应用范围。
2 模糊C-均值聚类算法概述
模糊C-均值聚类算法所遵从的算法思想为硬聚类思想,数据集利用来表示,而表示第j 个数据样本的s 个特征向量,x 表示第j 个数据样本在维度k上的特征值。将数据集X 进行分组,形成C 个子集,可利用Y={X1,X2,…,Xc},C∈[2,n]。如果Y 符合式(1)的要求,那么,Y 可以被视为硬C 分组。
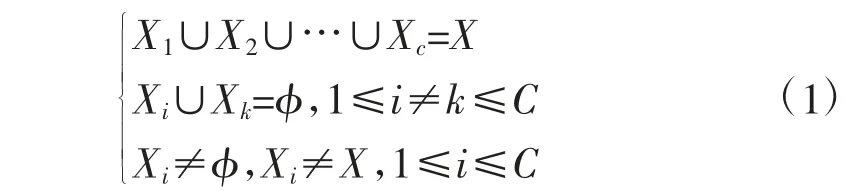
假设样本xj属于子集xi的隶属度为uij,那么可以用隶属矩阵U=[uij]C×n来表示硬C 分组,其中uij∉{0,1}。因此,数据集X 的硬C 分组可以用公式(2)来表示。
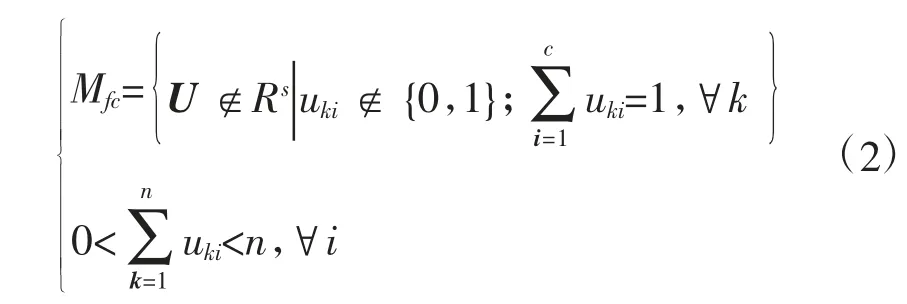
因此,模糊C 分组可以用式(3)来表示。
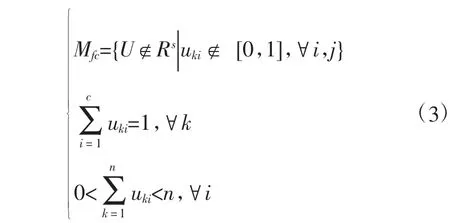
对于数据集X={x1,x2,…,xk,…,xn}⊂Rs来说,n是数据集X 中元素的数量,s 是样本x 中属性值的个数。c 个聚类中心组成1 个矩阵V=[v1v2… vi… vc]s×c,其中vi={vi1,vi2,…,vis}为第i 个聚类中心的元素,c 为聚类的类别数,则模数C-均值聚类算法的目标函数公式为
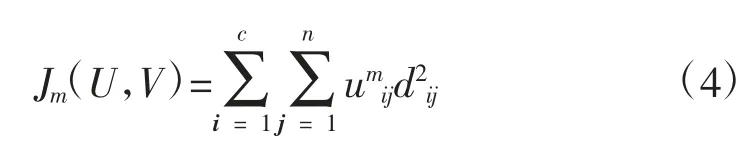
3 混合蛙跳算法概述
混合蛙跳算法针对蛙在岩石上觅食时的种群分布变化所给出的计算。算法于2003 年提出,时间虽然不短,但相关的论文不多,仍有较大的研究和改进空间。
混合蛙跳算法中,每一只青蛙的定位都代表着一种可能解。如果青蛙们所在的水池上有数块石头,在一代,青蛙们都将被分配在石头上。在这一代中,只有石头上位置比较糟糕的青蛙能跳跃。这些青蛙首先是向着在同一个石头上的最优预测方位的青蛙方向跳跃,若新的方位仍比原方位差则向其全局最优方位跳跃,若新的仍比原方位差则在解空间里随机跳跃一次[6]。可以看出每只跳动青蛙在每代中至少跳动1 次,至多跳动3 次,但由于每次跳动的青蛙数量等于石块数,故当石块数、青蛙数/3时,每代总跳动次数小于青蛙总数。
4 群体智能算法的融合
如上所述,模糊C-均值聚类计算可以通过将目标函数进一步优化到最小的方式来解决。不过,这种方式容易使最后解落入局部极小值点附近,且收敛速度慢。身为一个群体智能算法,混和蛙跳具备着较强的全局搜索特征。为此,将混合蛙跳算法与模糊的C-均值聚类算法加以组合,来改善聚集效率并进一步优化精度[7]。混合蛙跳的模糊C-均值聚类计算过程包括以下5 个步骤。
步骤1:初始化。初始化青蛙类型的总量N,聚类中心个数c,并建立随机的归属度原始矩阵,进行初步的系统聚类分析,统计各种类型的聚类中心,以用作初始混合蛙跳算法中的青蛙映射代码。
步骤2:行为选择。方法中模拟了青蛙群体在行为时所获得的每只青蛙的适应力指数值,并对青蛙按降序进行了排名和分类。
步骤3:从每个子群中开始局部搜寻并更换子种群中的最差个体,直至获得局部搜寻的最高迭代数量[8]。
步骤4:将子群体混合,并及时更新种群的最优值。
步骤5:反复步骤2~步骤4,直至得到最大值给定迭代频率,此时的全局最优解便是初始聚类中心。使用模糊C-均值聚类方法,可以得到结果的聚类矩阵分组。最后利用最大隶属度法则,在对手护具集中已有的数据加以属类型标记[9]。
融合算法流程见图1。
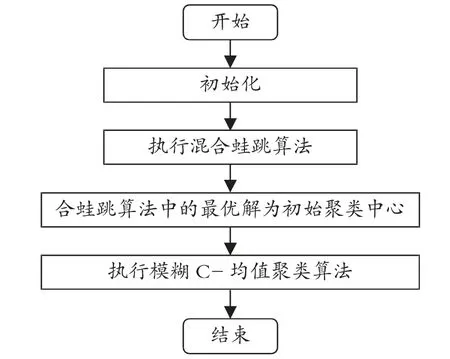
图1 融合算法流程
5 仿真实验分析
5.1 实验数据
前文阐述了群体智能算法的融合思路,为了判断融合算法是否有效,和传统大数据聚类挖掘算法相比是否更先进,此次选取典型Iris 数据集以及另外3 组人工数据集合展开仿真实验,实验过程中将4 组实验数据分别代入到传统模糊C-均值聚类算法、POS-FCM 算法、混合蛙跳算法以及此次所形成的融合算法当中。4 组实验数据见表1。
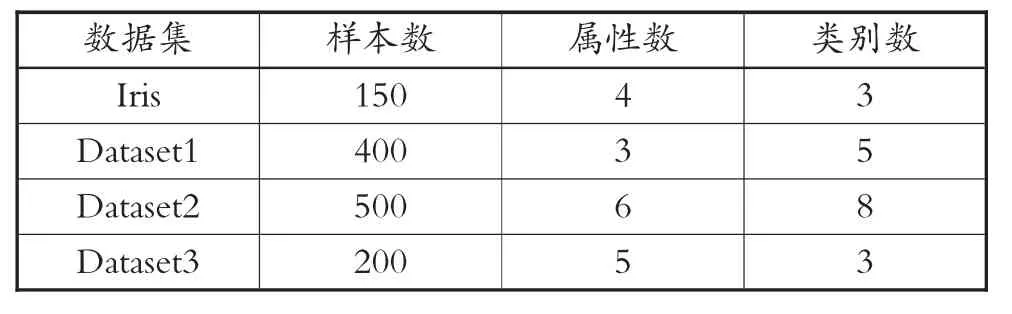
表1 4 组实验数据
5.2 聚类分析结果
根据表1 中的数据可以了解到,仿真实验中数据最大迭代次数在人工数据集2 中,迭代次数为500 次。将4 组数据在4 种算法中均执行40 次,并且计算每个经过迭代的数据指标平均值,此时4 组数据集在不同算法中的实验结果如表2 到表5 所示。此时可以借助分类正确率的相关计算公式来判断此次聚类结果的有效性情况。计算分类正确率的公式为

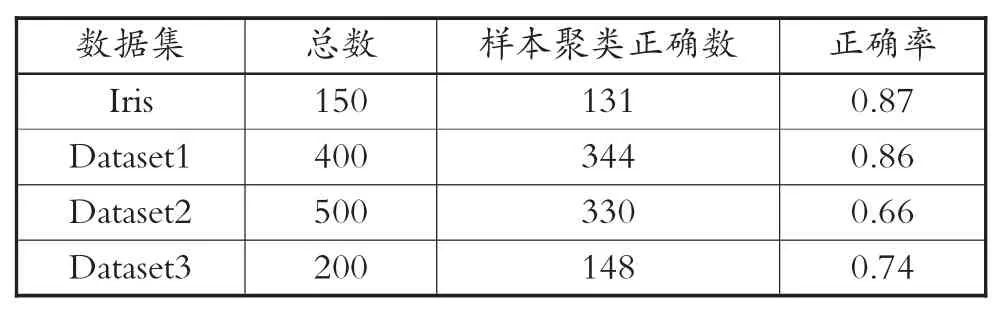
表2 模糊C-均值聚类算法实验结果
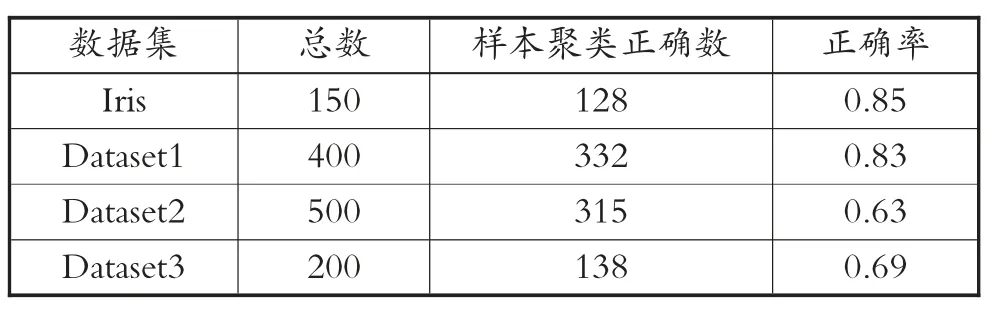
表3 混合蛙跳算法实验结果
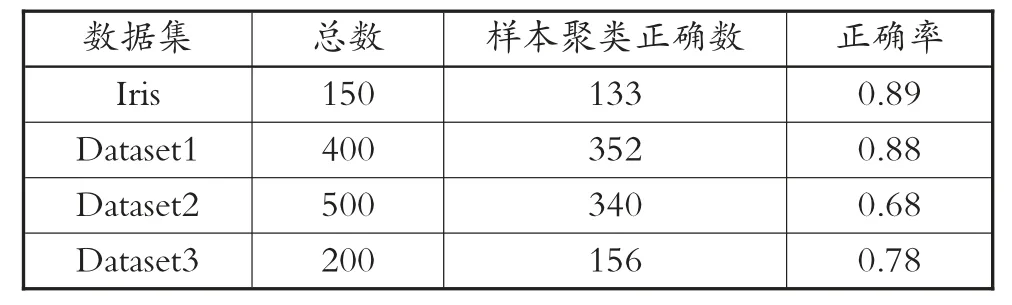
表4 PSO-FCM 算法实验结果
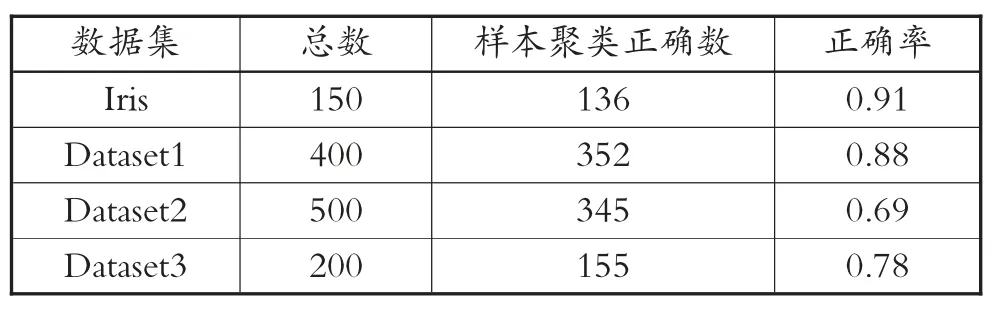
表5 融合算法实验结果
从表2 到表5 中的数据可以了解到,因为算法中对于数据集的初始数值具有较高的敏感度,因此,模糊C-均值聚类算法所呈现出的聚类效果是4 种算法中最差的。而在混合蛙跳算法中的结果可以了解到,该算法具有较好的数据收敛速度以及鲁棒性,该种特性克服了部分数据的极值问题,但是在对大数据进行聚类划分时,划分精确度明显低于其他算法。从PSO-FCM 算法实验结果来看,该算法结合了模糊C-均值聚类算法以及粒子群优化算法两种算法,呈现出群智优化算法的特征,具备局部数据搜索能力,让聚类效果增强,以此来提升算法的准确性[10]。从本文提出的融合算法思路仿真实验结果来看,借助混合蛙跳算法对模糊C-均值聚类算法进行调整,优化聚类中心值,使算法在获取数据时,选择更加适合的函数,不仅具备全局搜索数据的能力,且大幅度提升搜索精准度,呈现出的聚类效果更好。
综上所述,本文所提出的融合算法思路更具备群体智能算法的特征,且该种大数据挖掘算法综合了混合蛙跳算法以及模糊C-均值聚类算法的优点,能够对算法中的数据进行参数调整,使算法具备全局数据搜索能力。此次研究结果表明,和其他算法相比,融合算法下的数据聚类挖掘有效解决了数据迭代过程中的局部陷阱问题,呈现出的聚类效果更好,数据挖掘的准确度提升。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国现代医生(2022年21期)2022-08-22
消费电子(2022年5期)2022-08-15
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
发明与创新·中学生(2017年5期)2017-05-12
电子技术与软件工程(2016年24期)2017-02-23
