
基于文本挖掘技术的信贷欺诈研究
2022-07-15 09:52刘娟娟梁龙跃蔡铉烨
智能计算机与应用 2022年7期
刘娟娟, 梁龙跃,蔡铉烨
(1贵州大学 经济学院,贵阳 550025;2中央财经大学 统计与数学学院,北京 102206)
0 引 言
信贷欺诈识别不仅是国家有关部门关注的重点,亦是对金融市场日常交易中的严峻挑战。中国金融市场发展起步较晚,金融体系尚不完善,有效识别信贷欺诈问题,有利于互联网金融的创新发展和传统金融业的数字化转型升级。然而,仅靠年龄、学历、房产状况等“硬信息”识别欺诈行为具有一定局限性。大数据背景下,文本数据是经济学中应用较多的非结构化数据,其中蕴含着丰富的信息,被广泛应用于度量经济政策的不确定性、股价预测、波动率等,以及将文本数据运用于违约预测。
借贷申请人所提供的文本数据承载了申请人的意愿、倾向,该类文本数据是指其在申请贷款时所填写的贷款用途、贷款原因等文本,因此具有独特的价值意义。了解客户的资信状况是授信过程中十分关键的环节,是决定是否授予贷款的前提和基础,为此相关平台人员必须综合客户的有关信息(资信状况、还款意愿等),识别客户真伪信息。文本数据的引入拓宽了了解客户信息的渠道,为全面评估客户、减少损失提供了保障。
在信贷欺诈识别模型中,机器学习算法是主流算法之一,与统计、计量分析方法(如:Logit模型)相比,具有更高的识别效率和准确率。利用机器学习进行欺诈数据检测主要分为3条路径:
(1)根据不平衡样本集,使用机器学习模型预测。如:文献[5]中构建决策树与布尔逻辑函数的融合模型,对金融消费行为进行分析,并在此基础上使用聚类方式区分正常交易与非正常交易,以此判断持卡人交易是否符合规范。文献[6]基于数据挖掘技术,设计信用卡欺诈检测系统,该系统使用贝叶斯分类器对客户数据进行识别,判断客户是否存在欺诈行为。文献[7]提出模糊二范数二次曲面支持向量机模型,用于信贷违约预测。实证结果表明,相比二次曲面支持向量机模型、二次核的加权二范数支持向量机模型等4个支持向量机变体模型而言,该模型评估效果得到显著提升。
(2)使用神经网络模型进行预测。文献[8]在BP神经网络基础上,融合遗传算法(GA)评估德国信用卡消费行为风险。该研究结果表明,混合模型效果优于单一的BP神经网络模型。
(3)平衡样本数据之后进行预测。由于欺诈数据往往具有样本分类不平衡的问题,SMOTE算法平衡数据被广泛应用于欺诈检测。文献[9-11]研究结果表明:样本平衡后能有效提升模型预测性能。
虽然贷款申请人所提供的文本数据蕴含丰富信息,但如何从该类文本数据中获取有效信息仍存在一些需要解决的问题。为此,相关人员做了大量的研究工作。文献[12]中指出,在传统的词频统计、词典法等方法中,由于选词及词典本身的限制,往往会存在信息遗漏问题。为了能够充分获取文本信息,自然语言处理技术已广泛应用于文本挖掘。如CNN、LSTM、RNN、注意力机制等深度学习模型被广泛用于文本信息提取。文献[13]使用了几种典型的CNN模型,用于文本分类中的特征提取,获取文本信息的向量。随着人工智能技术的发展,文献[14]中提出了一种完全基于Attention机制的Transformer模型,打破了人们使用RNN与CNN做自然语言处理的局限。文献[15]使用多种方式提取文本特征作为新特征变量,用于构建信用违约模型(如:LDA、CNN、Transformer等)。研究对比发现:加入Transformer模型提取的文本特征对模型性能提升效果高于其它文本提取方式。此外,使用深度学习模型所提取的文本信息存在高维问题,一般降维方式为PCA、LASSO、核PCA等方法,但由于经由模型提取后的数据为非线性高维数据,一般降维方法不能有效解决非线性问题,为保证降维效果,需选取合适的降维方法。
本文致力于解决信贷文本信息的提取及降维,并将其运用于信贷欺诈识别。考虑到英文单词具有大小写之分,为降低其重复性,使用Snowball对英文进行词干还原,并在此基础上使用Transformer提取文本信息,有效获取了文本信息。其次,使用自动编码器(AE)对提取的文本信息进行非线性降维,成功获取文本信息测度指标。最后,利用多个机器学习模型(如:随机森林、XGBoost、GBDT等)与数据均衡算法(SMOTE、TomekLinks欠采样等)相结合,作为信贷欺诈识别基准模型。在其基础上引入文本信息测度作为新的预测变量,根据模型预测性能及特征重要性分析,研究贷款申请人所提供的文本数据对信贷欺诈识别的判断能力。
1 信贷文本信息提取建模
1.1 文本特征模型理论
1.1.1 自动编码器(AE)
自动编码器(AE)是一种基于神经网络的数据降维方法,主要包括编码(Encoder)和解码(Decoder)两部分,其网络结构如图1所示。当网络输入确定后,利用输出等于输入来训练自动编码器网络,使得输出尽可能地逼近输入。其中,隐层单元数量的选取要小于输入数据的维度。在数据降维中,AE只需使用Encoder部分的编码操作,将高维度的输入数据映射到低维度的特征编码,达到降低数据维度的目的,且该方法相比于主成分分析(PCA)方法能以非线性方式解决多重共线性问题。

图1 自编码结构Fig.1 Autoencoder structure
1.1.2 Transformer
Transformer由Vaswani等,在2017年提出,其开创性的放弃了基于RNN、LSTM、GRU等循环神经网络结构,取而代之使用了Attention层和全连接层构建网络,解决了语义长期依赖问题。位置编码器的引入解决了词语顺序的问题,并且由于没有了循环神经网络的递归结构,网络求解过程可以并行完成,大大提高了效率。该模型由一个完整的Encoder-Decoder框架构成,如图2所示。其中,Encoder部分功能比较单一,仅用于从原始句子中提取特征,而Decoder则功能相对较多,除特征提取功能还包含语言模型功能。

图2 Transformer结构Fig.2 Transformer structure
1.2 信贷文本信息获取及处理
1.2.1 信贷文本信息获取
本文所使用的数据集,来源于美国大型信贷平台Lending Club所提供的2007~2018年贷款申请人信息,数据集中贷款申请人提供的“贷款描述”即是本文所使用的“文本信息”。该文本主要表现为贷款申请人的贷款目的、贷款理由自述及贷款类别。由于原始数据中并非所有样本均含有贷款描述,经数据预处理后总共获取有效文本信息51 820条,其中文本长度90%以上少于50个单词,表明文本数据均为短文本。
1.2.2 信贷文本信息处理
由于原始文本较短且英文单词无需进行分词,故本文在对原始文本进行去除无意义字符、词干还原及转化词向量后,基于Python软件构建Transformer+AE的融合模型对文本特征进行提取。由于该模型所提取的文本特征维度高达68维,为降低维度及便于后期衡量文本信息对模型贡献度,本文使用AE将文本信息降维至1维,获取最终的文本信息测度(文本特征)。实现流程如图3所示。

图3 文本特征获取流程Fig.3 Text feature acquisition process
文本信息测度提取的主要步骤为:
使用“正则表达式”,剔除无意义字符(如:日期、特殊符号等)。
使用Snowball词干还原,获得原始单词后,通过词袋法对单词出现次数进行排序,选取出现次数排列前38 000的词,获得文本向量。
将文本向量输入Transformer模型,训练并使用编码层获取文本特征(其中包括:位置编码层、Transformer层以及全连接层),由此可得到多维度的文本特征。
使用AE对高维文本特征进行非线性降维,最终获得一维文本信息测度。
2 变量选取与模型构建
2.1 信贷欺诈数据收集及选取
与信用风险客户相比,欺诈风险客户主要表现之一为没有还款意愿,其目的是找到风控系统的漏洞或通过伪造信息等欺诈方式获得利益,是一种主观上的恶意欺诈、拖欠等行为。从定义出发确定欺诈样本,将好样本标签以数字1表示,坏样本以数字0表示,便于后期模型拟合使用。
本文选取的原始数据集中共有150个特征变量,为了客观、全面判断借款人是否有欺诈意图,通过数据特征工程,选取以下18个指标构建反欺诈评估体系,各指标含义见表1。

表1 部分特征介绍Tab.1 Introduction to part of features
2.2 数据描述性统计
经数据预处理及特征工程后,最终剩余51 820个样本,样本集描述性统计结果见表2。

表2 定量指标描述性统计Tab.2 Descriptive statistics of quantitative indicators
根据数据描述性统计结果,数据集方差差异显著。为提高模型拟合结果,需对数据进行归一化处理,针对分类变量home_ownership、addr_state进行One-Hot编码。归一化处理公式为:
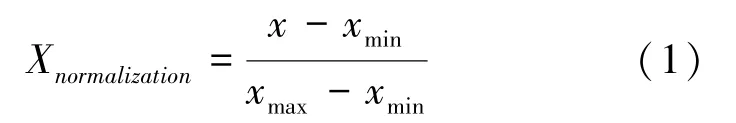
2.3 基准模型介绍
2.3.1 随机森林模型
随机森林(Random Forest,RF)算法是一种经典的装袋法(Bagging)模型,其基本原理是先在原始数据集中随机抽样,构成个不同的样本数据集,然后根据这些数据集搭建个不同的决策树模型,最后根据这些决策树模型的投票情况获取最终结果。随机森林具有拟合速度快,方便处理大规模数据、易于实现、可以避免过拟合等优点。
2.3.2 GBDT模型
GBDT(Gradient Boosting Decision Tree)属于提升(Boosting)集成算法中的一种。Boosting集成算法的构建过程,是不断加强之前弱学习器判别错误的样本权重,保证之后的弱学习器在错误样本上判别正确。GBDT算法将损失函数的负梯度作为残差的近似值,不断使用残差迭代和拟合树,使残差沿着最大梯度的方向下降,最终生成强学习器。
2.3.3 XGBoost模型
XGBoost(eXtreme Gradient Boosting)是在GBDT的基础上,引入正则化损失函数来实现弱学习器的生成。加入了正则化的损失函数,不仅可以降低过拟合的风险,且XGBoost模型利用损失函数的一阶导数和二阶导数值进行搜索,通过预排序、加权分位数、稀疏矩阵识别及缓存识别等技术,大大提高了XGBoost模型性能。XGBoost通过最小化下面的正则化目标函数来实现:

其中,是损失函数;是模型复杂程度的惩罚项;、分别是的正则化系数。
2.3.4 LightGBM模型
LightGBM算法在原理上与GBDT和XGBoost算法类似,都采用损失函数负梯度作为当前决策树的残差近似值,去拟合新的决策树。只是对框架进行了优化(重点对模型训练速度的优化)。其二叉树的分裂增益公式为:
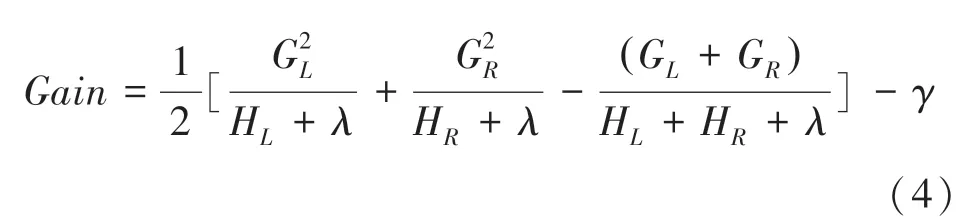


其中,G为该叶子节点上样本集合中数据点在误差函数上的一阶导数和二阶导数。
2.3.5 Extra-Trees模型
极端随机树(Extra-Trees,ET)算法与随机森林算法十分相似,都是由许多决策树构成。ET算法在节点划分时,选择的特征及对应的特征值不是搜索比较所得,而是随机抽取一个特征,再从该特征中随机抽取一个特征值,作为该节点划分的依据。当子模型的准确率大于50%,并且集成的子模型数量足够多时,整个集成系统的准确率达到合格。这样做的优点是:提供额外的随机性、抑制过拟合,并且具有更快的训练速度,缺点是增大了偏差(bias)。
2.3.6 ANN模型
人工神经网络(ANN)是由大量神经元模型组成的信息响应网络拓扑结构,其可以分为几个“层”,如:输入层、隐藏层和输出层。其中,输入层和输出层功能较为单一,隐藏层功能较多。隐藏层可以由多层神经网络层构成,其主要作用是对输入层输入的数据进行计算转换,并将得到的结果传递给输出层。整个神经网络中,每层内部的神经元没有连接,连接只设置在层与层之间。此外,每个连接都具有一个权重值。
3 实证分析
本文使用Python软件展开实证分析,构建欺诈检测模型,将51 820个样本按9:1的比例划分训练集和测试集。由于数据样本的不均衡性,会对模型拟合效果评价产生较大影响,本文选取不同的欠采样、过采样方式对数据集进行均衡采样,探索不同采样方式下模型性能的表现。同时,多元化采样方式有助于增强模型结果稳健性。实证结果表明,在不同采样方式下,加入文本特征后模型性能均有一定提升。实证过程中,将样本集分为两组,一组不加入文本特征指标,另一组加入文本特征指标。
3.1 实验结果评价
3.1.1 评价指标
3.1.1.1 真正例率()和假正例率()
在反欺诈模型中,其目的是为了检测出欺诈样本。由于传统的准确率()指标无法准确评价该模型实际欺诈检测准确率,为此模型评价采用指标,并绘制出模型的ROC曲线。
对于一个二分类任务,可将所有的样例根据其真实所属类别与模型结果组合分为真正例()、假反例()、假正例()、真反例()4种情况,见表3。

表3 混淆矩阵Tab.3 Confusion matrix
根据表3可定义真正率()和假正率()为:
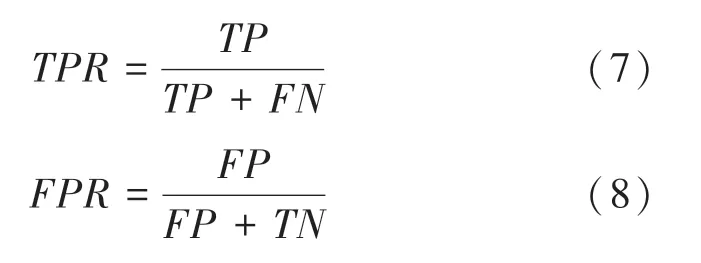
3.1.1.2 ROC曲线和值
受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)以为横轴,为纵轴绘制,当其越靠近左上角,表明模型的性能越好,如图4所示。但当存在多条ROC曲线很难进行比较时,可使用值对模型性能进行评估。是ROC曲线和轴(轴)之间的面积,其值能直接反映出模型拟合结果的优劣。

图4 ROC曲线Fig.4 ROC curve
3.1.2 实验结果评价
本文选用随机森林、GBDT、XGBoost、LightGBM、ET以及全连接神经网络(ANN)共6个机器学习模型,验证在不同模型上文本信息测度对预测结果贡献的稳健性。
对全样本分别进行邻域欠采样、Tomek Links欠采样、随机欠采样、随机过采样以及SMOTE过采样。为了降低模型过拟合及更多的获取数据信息,研究中将训练集数据随机划分为10份进行交叉验证,每次选取其中一份作为校验集,其余部分作为训练集用于模型训练。
3.1.2.1 加入文本数据前预测模型实验结果
根据表4可知,除SMOTE采样下,LGBM模型表现最好以外,其余采样方式下最好模型均为GBDT;在邻域欠采样下,所有模型评价结果明显高于其它采样方式。从总体评价结果来看,GBDT模型拟合结果最佳。
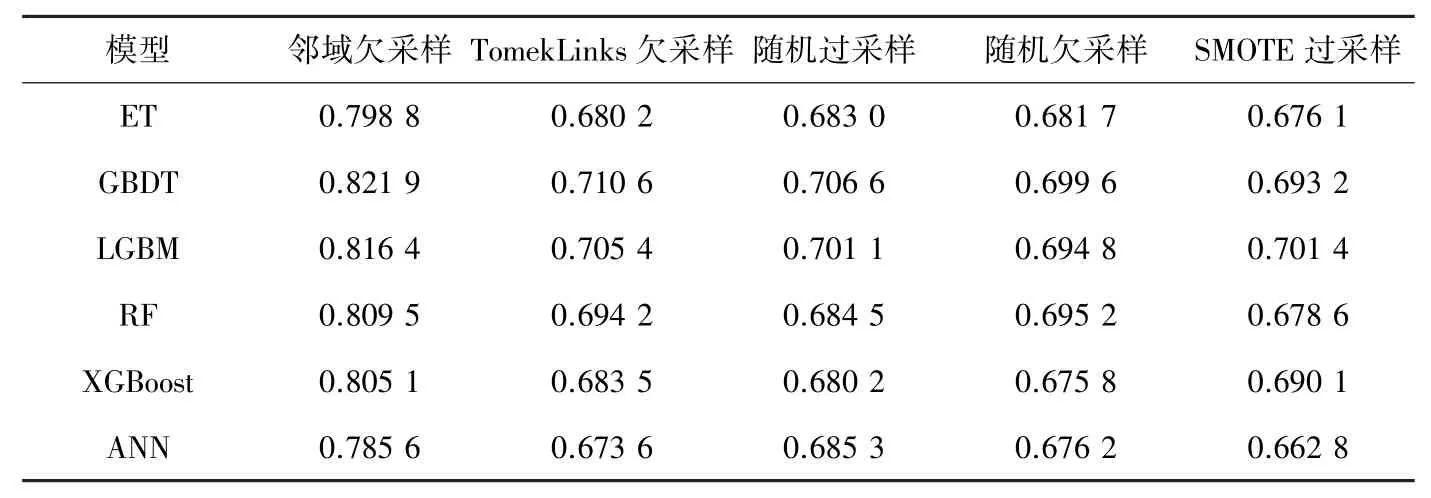
表4 未加文本特征AUC值Tab.4 AUC value without text feature
3.1.2.2 加入文本数据后预测模型实验结果
从采样方式看:邻域欠采样下所有模型评价结果均高于其他采样方式,其中SMOTE过采样方式下除LightGBM模型外,其它模型结果均表现欠佳。由此可知,领域欠采样方式是最优采样方式,对提高模型评价结果具有一定意义。从模型角度看,除SMOTE过采样方式,其余采样方式下最佳拟合模型为GBDT模型,其值高于其它模型。

表5 加入文本特征后AUC值Tab.5 AUC values after adding text features
对比无文本特征模型的值,含文本特征模型值均有显著提升,最高提升效果为1.42%(随机森林模型),最差提升效果为0.68%(ET模型),GBDT模型作为值最高模型,其提升效果为1.01%。因此,加入文本特征对模型性能具有提升效果,该特征对预测结果有贡献作用。
3.2 模型特征重要性分析
特征重要性可以查看特征变量对目标变量的作用,且按作用大小进行排序。本文选取了提升表现较好的4个模型进行特征重要性分析,提取欺诈检测模型中排名前10的特征,并观察文本特征在前10重要特征中的位置,结果如图5所示。
图5(a)表明,在随机森林模型中,最重要的特征变量为“desc”(文本特征)。可以看出加入文本信息特征会对模型预测的结果造成较大影响,证明文本信息特征能有效改变模型预测结果;而在硬特征中,贷款利率(int_rate)占有重要影响地位。
图5(b)显示在GBDT模型中,最重要的特征变量为int_rate,次重要特征为desc,可看出文本特征对模型预测结果的影响程度较为显著。
图5(c)显示文本信息特征“desc”重要性位列第四,展示了加入文本信息特征的作用。除此之外,int_rate及term重要性表现出一致性,且位列第一、第二。
图5(d)的LightGBM模型中,文本(desc)特征重要性排位第一,且重要性显著高于其它特征。除去文本特征外,前4个特征的重要性基本一致。

图5 特征重要性结果图Fig.5 Feature importance results
由特征重要性图示可知,文本特征指标在各模型中均是重要特征,在大部分模型中位列第一和第二,其重要性相比硬特征处于重要位置,对模型的预测结果贡献较大。从而验证了加入文本特征后,反欺诈模型风险识别能力得到提升,文本特征的引入具有一定意义。
4 结束语
本研究中引入文本信息作为新的影响因子,探索了贷款文本信息对欺诈识别的作用,拓宽了非结构化数据在金融交易中的应用。此外,将Transformer与AE相结合,有效降低了文本信息维度,同时也保证了信息的全面性。
研究结果表明,以贷款利率、借款人年收入、最早循环帐户已开立月数及文本特征为主的10个指标与客户欺诈行为相关性最高。在反欺诈预测模型中,文本信息的引入,能够明显提升模型对欺诈客户的识别性能,提升结果介于0.65%-1.42%之间。启示有关金融机构平台,在审核贷款申请人信息时,可要求贷款申请人提供必要的文本“软信息”,获取更丰富的贷款人信息,更为全面评估是否授予贷款,维护双方利益,减少不必要损失。
在未来工作中,除基础自编码器外,还可使用其它编码器进行数据降维,也可尝试使用其他新算法构建反欺诈模型,探索更多欺诈检测方式。文本挖掘技术的发展日新月异,新兴的文本挖掘技术也可用于提取文本特征,亦是今后可以挖掘的方向。由于文本特征的特殊性,其对目标变量的影响机制有待进一步挖掘,未来可探究文本特征可解释性分析。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
现代世界警察(2019年3期)2019-09-10
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
博览群书·教育(2016年9期)2016-12-12
科技视界(2016年16期)2016-06-29
计算技术与自动化(2014年1期)2014-12-12
河北经贸大学学报(2014年6期)2014-10-30
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
银行家(2012年11期)2012-01-17
