
基于集成学习的冠心病风险预测模型研究
2022-07-15 09:52苏文星张振一郑琰莉宋元涛
智能计算机与应用 2022年7期
苏文星,张振一,郑琰莉,唐 琳,宋元涛
(1中国科学院大学 工程与科学学院,北京 100049;2中国科学院大学 应急管理科学与工程学院,北京 100049;3天津泰达普华医院,天津 300457;4西安理工大学 经济与管理学院,西安 710045)
0 引 言
冠状动脉粥样硬化性心脏病简称“冠心病”(Coronary Heart Disease,CHD),是指冠状动脉血管发生动脉粥样硬化病变而引起血管腔狭窄或阻塞,造成心肌缺血、缺氧或坏死而导致的心脏疾病。随着老龄化进程加快以及居民不良生活方式的影响,心血管疾病的发病率逐年增高。中国患有心血管病的人数约为3.3亿,其中冠心病1 139万人,且农村地区心血管病死亡率持续高于城市水平。目前,临床上对冠心病诊断主要依靠临床症状、实验室检查、影像学检查诊断等,其中冠状动脉造影(Coronary Angiography,CAG)是诊断冠心病的“金标准”,但诊断过程繁琐且费用较为昂贵。如能早期对冠心病给予相应的风险预测,可在降低居民患病风险和就医成本的同时提高疾病筛查的效率,因此,找到快速又经济的冠心病早期预测方法具有重要意义。
近年来,机器学习由于其强大的数据分类与预测能力,在疾病预测及辅助临床治疗决策方面做出一定贡献,集成学习算法的预测效果尤为突出,但机器学习在冠心病风险预测方面并未得到广泛应用。此外,相关研究发现,高血压、高胆固醇、糖尿病以及年龄、性别、身体质量指数(BMI)、是否吸烟等都会影响患冠心病的几率。因此,本文利用Kaggle平台公开的CHD数据集,基于随机森林、XGBoost、LightGBM 3种较为成熟的集成学习(Ensemble learning)算法建立冠心病风险预测模型,利用准确率、召回率、等指标对3种模型的性能进行比较,验证集成学习算法在冠心病风险预测方面的可行性,从而实现对冠心病的早期风险预测。
1 数据处理与特征工程
1.1 数据来源
本文数据源为Kaggle官方大数据平台提供的针对马萨诸塞州弗雷明翰镇居民心血管研究公开数据,其分类目标是预测患者10年间是否罹患冠心病,如果有计作1(阳性),否则计作0(阴性)。数据集共有4 283条记录,涵盖了人口统计学、行为学和医学风险3个维度的15个风险特征指标。具体特征指标变量见表1。

表1 风险特征指标变量详情与解释Tab.1 Detail and explanation for risk characteristic index variables
1.2 数据分析与缺失值处理
采用Pandas对数据源数据对指标变量的值类型、分布以及缺失情况进行分析得出:数据不满足正态分布(0.05),且教育程度(education)、平均每日吸烟量(cigsPerDay)、是否服用降压药(BPMeds)、总胆固醇水平(totChol)、身体质量指数(BMI)、血糖水平(glucose)存在数据的缺失。具体特征指标变量数据情况见表2。

表2 特征指标变量数据情况Tab.2 Data of characteristic index variables
数据的缺失会影响数据分析的质量和建模的准确性,所以需要针对不同特征变量数据分析情况采取恰当方式进行数据处理。教育程度指标变量受患者实际情况影响,数据不可得且缺失数据的比例在5%以下,可以使用删除法对缺失值进行处理;平均每日吸烟量的缺失值,分析发现对应记录均为吸烟者,因此取所有吸烟者且每日吸烟量非空数据的平均数(18.0)对缺失值进行插值;对于是否服用降压药指标变量缺失值,参考美国心脏病协会(American Heart Association,AHA)高血压指南最新诊断标准,在未使用降压药物的情况下,收缩压(systolic blood pressure,SBP)≥130 mmHg和(或)舒张压(Diastolic Blood Pressure,DBP)≥80 mmHg的人群诊断为高血压患者,对收缩压大于130 mmHg或者舒张压大于80 mmHg的数据以1进行插值,否则以0进行插值;对于总胆固醇水平、身体质量指数、心率和血糖水平指标变量的缺失数据,其数据比例均占总数据10%以下,分别求各指标变量数据平均值后对空缺数据进行填补。本文基于Python的pandas工具库对上述数据进行处理,最终得到4 133条样本用于模型构建,其中阴性患者3 505例(84.8%),阳性患者628例(15.2%)。部分样本数据见表3。

表3 部分样本数据Tab.3 Part of sample data
1.3 特征分析与选择
特征选择旨在通过分析特征间的关系筛选出对模型贡献度较高的特征变量,以提高模型的性能。鉴于数据不满足正态分布,本文首先基于Spearman秩相关系数对特征指标变量相关性进行分析,具体相关情况如图1所示。其中年龄(age)、收缩压(sysBP)、是否患有高血压(prevalentHyp)、舒张压(diaBP)、血糖水平(glucose)为重要特征,是否吸烟-平均每日吸烟(currentsmoker-cigsperday)的相关系数为0.93,舒张压-收缩压(diaBP-sysBP)的相关系数为0.78,高血压史-收缩压(prevalentHypsysbp)的相关系数为0.70,高血压史-舒张压(prevalentHyp-diaBP)的相关系数为0.62,值均小于0.05,特征指标变量间存在较高相关性。分析可得特征指标变量与目标值相关性均小于0.6且特征指标数量较少,故保留所有特征指标变量进行模型预测。

图1 特征指标变量相关性Fig.1 Correlation between characteristic index variables
一般来说,不平衡数据集会削弱学习算法预测准确性,本文应用的冠心病数据集中阳性与阴性数据比值约为1∶6,数据类别不平衡明显。人工少数类过采样法(Synthetic Minority Over-Sampling Technique,SMOTE)在解决数据类别不平衡问题上具有良好的效果。本文将采用该方法随机生成新实例以平衡数据。
2 风险预测模型构建
2.1 模型介绍
集成学习通过构建并结合多个学习器来完成学习任务,通过多分类器的预测结果来改善基本学习器的泛化能力和鲁棒性。本文选取随机森林、XGBoost、LightGBM 3种较为成熟的集成学习算法建立冠心病风险预测模型。
(1)随机森林:随机森林具有易于实现、抗噪声能力优、数据集适应能力强且不易陷入过拟合等特点。随机森林(Random Forest,RF)利用集成学习的思想,包含多个决策树的分类器,对于一个输入样本,不同树会有不同的分类结果,随机森林通过随机的方式建立多棵决策树并集成了所有的分类投票结果,选择投票数最多的类别作为最终的输出。
(2)XGBoost:XGBoost(eXtreme Gradient Boosting)是一种改进的梯度提升算法,具有计算复杂度低、灵活性强、运行速度快,精准度高的优点。基于预排序方法并通过对误差函数进行二阶泰勒展开,加入正则化项来优化目标函数,将多个弱分类器进行融合,从而形成强分类器,同时采用收缩(Shinkage)、列特征抽样(Column Subsampling)等方法来防止过拟合。
(3)LightGBM:LightGBM(Light Gradient Boosting Machine)是基于决策树算法的分布式梯度提升框架,采用Histogram算法,使用带有深度限制的按叶子生长(leaf-wise)策略,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率。支持分布式可以快速处理海量数据,训练效果好、不易过拟合。3种集成学习算法在模型设计上存在明显差异,其核心的不同点见表4。

表4 3种集成学习算法对比表Tab.4 Comparison of three ensemble learning algorithms
2.2 模型参数选择
为了确保模型有较好的效果,需要对模型调参,手动调参十分耗时且依赖于个人经验,网格和随机搜索调参需要很长的运行时间。贝叶斯优化法目前广泛应用于解决机器学习中的超参数搜索问题,同时该方法较随机搜索具有省时、性能优的特点。因此,本文基于Python语言使用BayesianOptimization库对3种模型使用贝叶斯优化法进行超参数调优。其中n_estimator代表建立子树的数量,一般来说模型的性能与子树的数量成正比,但是数值过大可能会导致模型过拟合,因此随机森林、XGboost、LightGBM3种集成学习模型基于贝叶斯优化的优化结果分别为383/398/574,其他参数的详细设置情况见表5~表7。

表5 随机森林算法模型参数设置情况Tab.5 Parameter settings of random forest model

表7 LightGBM算法模型参数设置情况Tab.7 Parameter settings of LightGBM model
2.3 模型预测结果
确定好模型参数后,本文基于Python语言并结合sklearn机器学习库,首先将数据集按照7∶3的比例分割为训练数据集和测试数据集,在训练数据集上完成3个模型的训练,并使用训练好的模型在测试数据集上测试,得到相应的预测结果(混淆矩阵),见表8。

表6 XGboost算法模型参数设置情况Tab.6 Parameter settings of XGboost model

表8 3种模型的预测结果(混淆矩阵)Tab.8 Prediction results of three models(confusion matrix)
3 模型性能评价与比较
3.1 模型性能评价指标
本文主要以准确率(,)、精确率(,)、召回率()、值和值评估算法的适用性及效果,同时使用10折交叉验证(10)的方式验证模型的性能。在解释上述评价指标之前需要对混淆矩阵进行释义,首先把预测值与实际值两两匹配,然后显示预测结果为阳性/阴性(Positive/Negative),再根据实际与预测结果对比,得出判断结果为正确/错误(True/False),最终得到混淆矩阵见表9。

表9 混淆矩阵Tab.9 Confusion matrix
准确率是指预测模型预测正确的结果占总样本的百分比,计算公式(1):
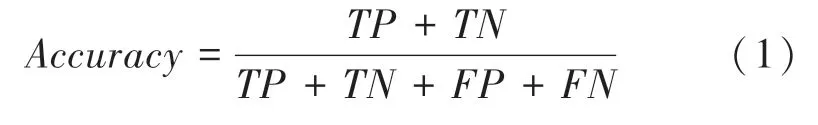
精准率是指在所有被预测为阳性的样本中实际值也为阳性的样本所占百分比,计算公式(2):

召回率是指在所有实际值为阳性的样本中被预测为阳性的样本所占百分比,计算公式(3):

值是为了更好的进行整体评价,在和的基础上,使用两者的加权调和平均进行模型性能效果的评价,计算公式(4):

除此之外,本文还引入(Receiver Operating Characteristic Curve)曲线对模型进行评估,是以假阳性率(False Positive Rate)、真阳性率(True Positive Rate)为轴的曲线,曲线下的面积(Area Under Curve,)可以直观的评价分类器的好坏,范围在0~1之间,值越大代表模型性能越好。
3.2 模型比较结果
利用Python语言metrics库得出3种预测模型的性能度量结果,见表10,可以看出:3种算法的准确率均在90%左右且数值相差不大,预测效果均较为良好;相较于其他模型,LightGBM的精准度最高,为93.94%;由表10和图2可以看出,3种算法的值均在0.9以上且3种算法10折交叉验证的准确率均在85%左右,表明其准确性、稳定性均较好。从值指标上观察,LightGBM模型预测效果略优于其他2个模型。综合上述指标可以看出,在本次选取的3种模型的训练效果均较好,LightGBM性能最为优秀。本文通过与相关研究成果对比发现,本研究选取的3种模型在准确率与值方面较其有明显提升。

表10 3种模型性能度量指标对比Tab.10 Comparison of performance metrics of three models

图2 3种模型的ROC曲线Fig.2 ROC curves of three models
4 结束语
冠心病是最常见的心血管疾病之一,而现阶段的诊疗成本较高,如能早期对冠心病给予相应的风险预测,提高疾病筛查的效率,不仅可降低居民的患病风险,还可降低患者就医成本,因此选择科学有效的方法进行早期冠心病的风险预测是非常有意义的。本文基于Kaggle上公开的冠心病数据集,首先对数据进行分析并对缺失数据按照不同情况处理,并利用SMOTE算法对数据进行平衡处理;采用随机森林、XGboost、LightGBM 3种集成学习算法模型构建了冠心病的风险预测模型,并使用贝叶斯优化算法对模型进行了调优;最后,从准确率、召回率、等指标对3种模型的性能进行比较,发现3种模型均具有良好的性能,验证集成学习算法在冠心病风险预测方面的可行性,从而实现冠心病早期风险预测。此外,基于机器学习建立的风险预测模型不仅可以对冠心病进行风险预测,还可以将其推广到预测其他类型的疾病,以提高疾病的早期筛查效率。
本文也存在一定的局限性。首先,本文采用的数据来源于开放平台,在数据数量、质量以及适用性上存在一定的局限性,未来考虑使用医院的真实大数据进行模型构建与预测;其次,本文使用的算法模型均为集成学习范畴,以后可考虑选取不同类型的机器学习算法进行改进对比,构建更加优秀的风险预测模型。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
健康博览(2020年2期)2020-02-27
中国民族民间医药·下半月(2014年4期)2014-09-26
新高考·高二数学(2014年7期)2014-09-18
金点子生意(2014年4期)2014-04-10
福建中学数学(2011年9期)2011-11-03
中学生英语高效课堂探究(2008年9期)2008-11-17
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
小学教学参考(数学)(2006年7期)2006-12-31
