
基于知识增强的NL2SQL方法
2022-07-15 09:52:34王秋月程路易王志军
智能计算机与应用 2022年7期
王秋月,程路易,徐 波,王志军
(东华大学 计算机科学与技术学院,上海 201620)
0 引 言
关系型数据库是信息系统的基础和核心。用户可以用SQL查询来检索数据库中的数据,但这通常对用户的SQL掌握水平有一定要求。而通过自然语言直接与数据库交互可以帮助非技术用户获取到关系型数据库中的信息,提高用户的使用效率和体验。因此,本文研究的任务是将自然语言问句转化为SQL查询(NL2SQL)。目前解决此任务的主流方法是基于草图的模型,其考虑了SQL的句法模式,通过SQL语句中的关键词如“SELECT”、“FROM”、“WHERE”等将原任务拆解为多个子任务。草图框架具体实例如图1所示,以问句“How many number does Fordham school have?”为例,其对应的表包含列名Player(选手)、No.(编号)、Position(位置)、School/Club Team(学校/俱乐部球队)等。按照草图框架,需要完成6个子任务的预测,根据模板进行槽填充构建完整的SQL语句。第一,需要预测SELECT从句中出现的列(SELECT-COLUMN子任务),此例中预测结果“No.”;第二,需要预测SELECT从句中出现的列对应的聚合操作(SELECT-AGGREGATION子任务),此例中预测结果为“COUNT”;第三,需要预测WHERE从句中条件的数量(WHERE-NUMBER子任务),此例中预测结果为1个;第四,需要预测WHERE从句中出现的列(WHERE-COLUMN子任务),此例中预测结果为“School/Club Team”;第五,需要预测WHERE从句中条件列对应的操作(WHERE-OPERATOR子任务),此例中预测结果为“=”;第六,需要预测WHERE从句中条件列对应的条件值(WHEREVALUE子任务),此例中预测结果为“Fordham”。

图1 基于草图的方法Fig.1 Sketch-based approach
虽然目前NL2SQL任务上提出的方法达到了比较好的效果,但仍然不足,这些方法都是对问句进行直接编码,缺乏语义信息,不能充分地理解问句。
针对自然语言问句存在语义缺失的问题,本文考虑利用外部知识图谱来对自然语言问句进行语义增强,使其包括充分的语义信息。基于知识增强的NL2SQL方法主要面临3个挑战:
(1)对问句的哪些部分进行增强;
(2)用外部知识图谱中的哪类知识进行增强;
(3)如何进行增强。
针对第一个挑战,本文提出对问句中出现的命名实体进行增强,并使用现有的实体链接技术,将问句中的命名实体链接到外部知识图谱中;针对第二个挑战,本文将知识图谱中的知识类别分为摘要(Abstract)、类型(Type)、标签(Category)、语义关系(Infobox)4种,并系统调研了各种类型知识的增强效果;针对第三个挑战,本文分别提出了一种基于符号化知识的增强方法和两种基于向量化知识的增强方法。在公开的大规模的NL2SQL数据集WiKiSQL上进行实验,实验结果证明了本文提出的增强方法的有效性。
1 相关工作
NL2SQL的方法主要分为两大类。
第一类是基于Seq2seq模型,采用“编码器-解码器”将此任务转化为从文本到SQL的翻译任务,代表方法是Seq2SQL,将SQL语句划分为SELECT从句和WHERE从句两部分,并分开独立生成,这类方法存在两种缺陷:第一种是WHERE从句中可能包含多个条件三元组,多个条件三元组之间的顺序并不影响最终的执行结果,但会极大地影响以之前的标记预测下一个标记的方式进行预测的Seq2seq模型的性能,Seq2SQL使用强化学习来消除顺序问题,但准确率依然不高;第二种缺陷是Seq2seq模型没有充分利用SQL句法结构来限制输出空间,模型复杂且准确率不高。
第二类方法是基于草图的方法。文献[1]基于此想法提出了SQLNet模型,根据SQL语句的句法结构将SQL查询分解为6个子任务。预定义草图包含各个子任务的依赖关系,每个子任务的预测只基于其所依赖的部分。与Seq2SQL不同,SQLNet采用了顺序到集合的方法和基于列字段的注意力机制,消除了顺序问题,提高了准确率。在此基础上,文献[2]提出执行指导编码(Execution-Guided Decoding),可以理解为一种后验操作,假设生成的SQL查询可以执行,通过执行结果来排除错误的候选SQL查询。随着动态表示学习的发展,更多的方法选择预训练语言模型作为编码器。文献[3]提出的SQLova使用表感知的BERT作为编码器,在编码后提出了3种不同的解码器变体,其中一种变体类似SQLNet,3种解码器之间的精度差也论证了预训练语言模型的有效性;文献[4]提出X-SQL,使用MT-DNN作为编码器,将全局上下文信息融合到表模式中,为下游任务提供更好的表达,显著地提高了性能。不同于连接问句和表中所有列名作为输入的SQLova和X-SQL,文献[5]提出的HydraNet将问句和表中的各个列名单独拼接送入编码器,不需要额外的池化操作或长短期记忆网络来获得一个列的向量表示,可以更好地获得列的表示。
2 方法
2.1 任务定义
基于知识增强的NL2SQL任务定义:给定一个数据库,还有一个外部知识图谱,包括实体的各类知识,如:摘要、类型、标签和语义关系等,如图2所示。其中,摘要是对实体的描述,类型说明了实体的所属类型,标签简要介绍了实体的特征,而语义关系包含了实体的属性及属性值。在不使用表中字段值的前提下,输入一个自然语言问句,输出对应的SQL语句。

图2 实体的相关知识Fig.2 Related knowledge of entity
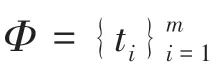
2.2 系统框架
本文工作的核心思想是利用知识来增强问句的语义信息,实现问句到SQL语句的转化。本文提出基于知识增强的NL2SQL模型KESQL,模型结构如图3所示。
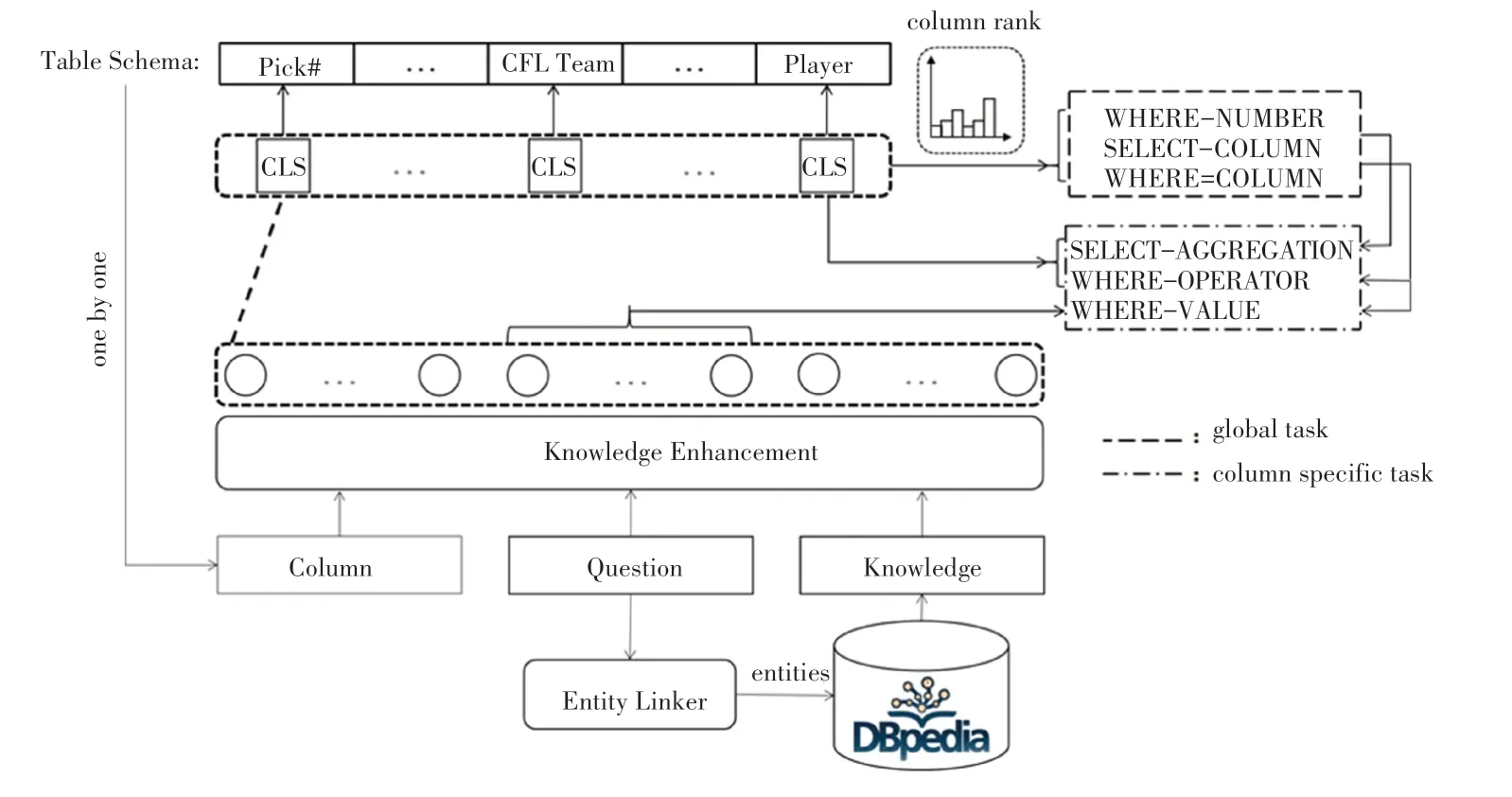
图3 KESQL模型结构图Fig.3 Structure diagram of KESQL model
本文的系统框架主要包含3个部分:首先对问句进行实体链接,找到问句中出现的命名实体,将其链接到知识图谱中,以获得这些命名实体的更多语义信息;其次,在知识增强模块从符号化和向量化两个角度实现增强,将问句与知识融合对齐,使模型更充分的理解问句;最后,利用知识增强后的编码层输出来解码草图结构中的各个子任务。
目前已经有很多成熟的实体链接工具,本文选择了主流的实体链接工具DBpedia Spotlight,将自然语言文本中的命名实体链接到知识图谱DBpedia中。
3 模型
3.1 输入模块
给定一个问句,问句对应的实体的某类知识以及相应的表t,对表中的每个候选列c,考虑其字段类型信息t y pe,组成输入序列((t y p e,c),,)。 其中,(·)表示一个将多个句子连接成一个字符串的函数。
3.2 知识增强模块
本文从符号化和向量化两个角度进行知识增强,包含一种符号化增强方法和两种向量化增强方法。
3.2.1 符号化知识的增强方法
符号化知识的增强是指将实体知识表示为一个字符串,直接与自然语言问句拼接,再进行后续的编码等操作。本文将结构化和非结构化的实体知识统一转化为自然语言作为实体的符号化知识描述,见表1。

表1 实体符号化知识描述的生成Tab.1 The generation of entity symbolic knowledge description
直接拼接问句和实体符号化知识描述,作为编码器的输入,输入序列为[][],[], 其 中,,是列信息(t ype,c)、问句、实体符号化知识分词后的形式,本文将此方法称为符号化知识增强(Knowledge Enhancement with Symbolic Knowledge),如图4所示。
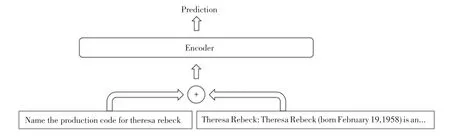
图4 符号化知识增强Fig.4 Knowledge enhancement with symbolic knowledge
3.2.2 向量化知识的增强方法
向量化知识的增强方法是指将实体知识转化为向量化表示,再与问句中所对应的实体指称项(mention)的向量化表示进行融合。具体来说,对于问句中出现的每个实体e,假设其对应的问句中的实体指称项为[p:q],p、q分别表示实体指称项的起始索引和结束索引。首先,通过不同的方法来获得实体e的向量化表示h,然后将其输入到一个线性层中,再与向量化后的实体指称项对齐;其次,通过线性组合实体指称项和实体的向量化表示来获得知识增强的实体指称项的向量化表示,计算方式如公式(1)所示。

其中,为增强后的实体指称项的向量化表示,()为语言模型的嵌入层,在训练过程中从0退火到,∈[0,1]。
本文提出了两种不同的实体向量化方法。第一种方法,即图向量化知识增强(Knowledge Enhancement with Graph Embedding),在给定图结构知识的情况下,包含实体与实体之间的语义关系,来自于全部实体的语义关系,对图结构的实体知识进行编码,获得实体的向量化知识表示。使用知识图谱向量化(Knowledge Graph Embedding,KGE)的方法来获得每个实体的向量化表示。本文使用提出的TransE模型来进行知识图谱向量化,称为图向量化知识增强(Knowledge Enhancement with Graph Embedding),如图5所示。

图5 图向量化知识增强Fig.5 Knowledge enhancement with graph embedding
第二种方法指在缺乏图结构知识的情况下,通过语言模型对文本形式的实体知识进行编码,获得实体的向量化知识表示。因为实体知识总是以被描述的实体开头,如“Theresa Rebeck:Theresa Rebeck(born February 19,1958)is an American playwright,television writer,and novelist.”,所以采用实体知识描述的第一个标记的词向量作为实体知识的向量化表示,此方法称为文本向量化知识增强(Knowledge Enhancement with Textual Embedding),如图6所示。

图6 文本向量化知识增强Fig.6 Knowledge enhancement with textual embedding
在问句和知识融合后,再对增强后的问句进行编码,为下游子任务提供更好的表示。
3.3 解码模块
此模型采用HydraNet模型的解码方式,采用草图框架,将SQL查询划分为6个子任务,根据各个子任务是否依赖具体的列,将其划分为全局任务和局部任务两类。
全局任务主要包含3个子任务SELECTCOLUMN、WHERE-NUMBER、WHERE-COLUMN。SELECT-COLUMN子任务的目标是预测SELECT从句中出现的列,本研究SELECT从句中出现的列固定为1个。所以,对所有候选列计算其出现在SELECT从句的分数,选择分数最高的列,式(2):


WHERE-NUMBER子任务的目标是预测WHERE从句中条件列的数量。本文任务中WHERE从句中条件列可以为空,至多出现4个条件列,将问题转化为五分类任务。问句对应的SQL中的WHERE从句包含多少条件列,主要取决于问句,但是本模型中的问句和表中每个列单独交互,得到的多个全局表示都可以预测出WHERENUMBER,需要根据每个列的相关度来对预测结果加权,式(3)~式(5):
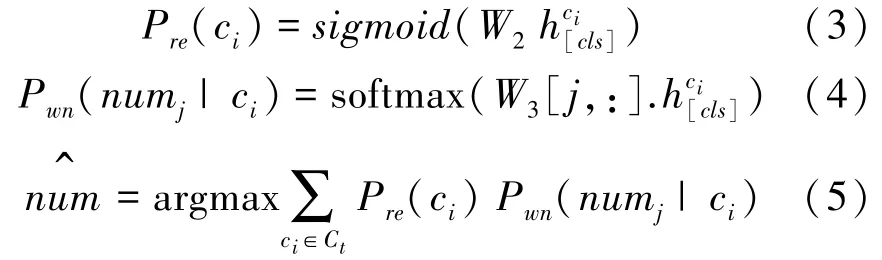
其中,P(c)为第列出现在SQL中的分数,P(num|c)为第列与问句交互后得到的全局表示预测WHERE从句中列数量为的概率,将P(c)和P(num|c)加权求和,取概率最高的数为WHERE-NUMBER。
WHERE-COLUMN子任务的目标是预测WHERE从句中出现的列,对所有候选列计算其出现在WHERE从句的分数,选择分数最高的前WHERE-NUMBER个列,式(6)。


局部任务依赖从句中的列的预测结果,包括SELECT-AGGREGATION、WHERE-OPERATOR、WHERE-VALUE。SELECT-AGGREGATION子任务的目标是预测SELECT从句中的列对应的聚合操作,从A=[′′,′MAX′,′MIN′,′COUNT′,′SUM′,′AVG′]中选择概率最大的聚合操作,式(7)。

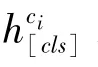
WHERE-OPERATOR子任务的目标是预测WHERE从句中的条件列对应的操作符,从[′=′,′>′,′<′]中选择概率最大的操作符,式(8)。

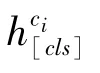
WHERE-VALUE子任务的目标是预测WHERE从句中条件列对应的条件值,可以被理解为从问句中抽取一段文本,预测条件值在自然语言问句中的起始位置,式(9)和式(10):


4 实验
4.1 实验准备
实验使用的WikiSQL数据集是大型NL2SQL数据集之一,基于维基百科文章构造自然语言问句和对应的SQL查询。训练集、验证集、测试集基于不同的表,分别包含56 355,8 421,15 878个问句-SQL查询对。本文选用RoBERTa-base作为基础编码器,AdamW为优化器。
执行指导编码(Execution-Guided Decoding),简称EG,利用SQL查询的执行结果来指导编码过程。如果预测的SQL执行结果出错或返回空结果,EG将认为此条SQL预测错误,会将其排除选择概率次高的SQL。在模型预测结束后,运用EG,进一步提升模型的效果。
4.2 评估指标
使用目前主流的两种评估指标,即逻辑形式准确率()和执行结果准确率(),来评估模型的效果。逻辑形式准确率是指预测生成的SQL与真实标注的SQL匹配的比例(这里匹配指SQL语句完全一致);执行结果准确率是指执行预测生成的SQL的结果与执行真实标注的SQL的结果匹配的比例。
4.3 基线
本文以当前最优模型HydraNet作为基础模型,将问句与相应表中的所有列名分别交互,得到编码层输出,再根据草图框架,利用列排序等方法对各个子任务进行解码预测。
本文以RoBERTa-base作为基础编码器复现了HydraNet模型,将其作为实验的基线。统一运用EG,对得到的实验结果做进一步的比较。
4.4 结果
本文模型的逻辑形式准确率和执行结果准确率均优于基线,在摘要、类型、标签、语义关系上分别运用符号化知识增强(SK)、文本向量化知识增强(TE)、图向量化知识增强(GE)得到逻辑形式准确率和执行结果准确率见表2、表3。

表2 测试集上逻辑形式准确率Tab.2 Logical form accuracy(%)on WikiSQL test set of various methods

表3 测试集上执行结果准确率Tab.3 Execution accuracy(%)on WikiSQL test set of various methods
通过表2和表3,可以观察到:
(1)类型和语义关系可以更充分地补全NL2SQL任务中缺失的语义,对效果的提升最明显。因为类型信息仅是几个具体类型的拼接,语义关系包含的是关键的键值对,相对来说带来的干扰更小;而摘要的第一句话虽然非常重要,但太过精练反而可能会漏掉一些信息;
(2)向量化知识增强的方法都比符号化知识增强的方法好,因为符号化知识增强的方法过于简单直接,融入外部知识反而带来一定的噪声干扰。
5 结束语
本文针对自然语言问句存在语义缺失的问题,使用了外部知识图谱来对自然语言问句进行语义增强,使其包括充分的语义信息。本文提出对问句中出现的命名实体进行增强,使用现有的实体链接技术来将问句中的命名实体链接到外部知识图谱中,并提出了一种基于符号化知识的增强方法和两种向量化知识的增强方法。同时,系统调研了摘要(Abstract)、类型(Type)、标签(Category)、语义关系(Infobox)等4种类型知识的增强效果,最终发现使用类型和语义关系两种类型的知识来进行文本向量化知识增强的效果最好。
猜你喜欢
数学教学通讯·小学版(2022年4期)2022-05-29 00:11:44
开放教育研究(2020年2期)2020-03-31 01:54:14
中国外汇(2019年18期)2019-11-25 01:41:54
新校园·上旬刊(2017年10期)2017-12-08 10:58:10
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
纺织科技进展(2016年3期)2016-11-29 01:27:00
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
