
面向电商的多模态商品检索引擎设计
2022-07-15 09:54:08林榆森施自凯林世翔
智能计算机与应用 2022年7期
潘 巍,林榆森,施自凯,林世翔
(哈尔滨华德学院 数据科学与人工智能学院,哈尔滨 150025)
0 引 言
近年来,随着互联网技术的发展以及人们对生活便利的需求,网购电商平台得到了飞速的发展,网上消费和选购心仪商品成为大多数人的首选。当前,随着网购模式的快速普及,虽然电商平台已经储备了海量的用户商品购买行为数据,但人们在网上购物时,若想在电商平台中有效检索出符合自身偏好的商品却越来越难,该问题的存在使得电商平台的现有检索系统面临着巨大挑战。此外,经常使用电商购物平台(如淘宝,京东和亚马逊)的用户还会发现,这些平台仅支持语音搜索、文本搜索、图片搜索等单模态检索方式,不能满足用户精准定位的商品需求。
1 多模态商品检索引擎需求分析
商品搜索引擎以多模态商品检索条件数据作为输入,并将这些数据和数据库里的用户行为信息一起提取特征,进行多模态融合得到融合后的特征向量,并把特征向量,构建出一种全新的多模态个性化商品检索引擎,主要应用于电商的多模态商品检索、商品个性化推荐和商品问答机器人。目的是为了提高检索的准确度,提高用户购物体验的满意度。可以说检索引擎为用户带来了线上购物的极大便利,对相关的电商平台带来了巨大的盈利效益。
多模态的商品检索引擎需要处理多种数据类型的数据,如图片,音频和文本信息。如何将多模态数据进行特征表达和融合是其要解决的关键性问题。此外,在现有的电商商品交易系统中存在海量的多模态数据,若能从中自动提取出商品特征,有效的检索出用户偏好的商品集合也是其有待解决的重要问题。相比传统的机器学习方法,深度学习可通过多个隐含层的仿射变换来自动提取多种类型数据的特征,并且对于海量数据处理任务表现出极好的学习泛化能力。从而利用深度学习来构建多模态的商品检索引擎是最好的选择。
2 基于深度学习的特征表示和提取技术
在多模态的商品检索引擎中,主要提取文字、图像和声音数据的特征,并有效的将其融合。其特征提取可依赖于深度学习技术来完成。
2.1 基于深度学习模型的图像处理技术
近年来,基于深度学习的卷积神经网络,在图像识别方面获得了巨大的成功,其可以通过多层卷积操作来获得图像特征的深度表达,如ResNet、LeNet5、AlexNet、Inception Net等。Vision Transformer的提出,相较于卷积神经网络来说,使用了一种自注意力机制,该模型的学习能力超越了前面所提到的基于深度学习的神经网络模型。2021年3月,微软公布了Swin Transformer模型,该模型使用移动窗口来计算多尺度的图像特征,并减少了模型的计算复杂度。同年,美团和阿德莱德大学提出了Twins Transformer(Twins-PCPVT),其设计出空间自注意力机制,使其在图像分类、目标检测和语义分割任务上超越了Swin Transformer模型。Twins-PCPVT通过将PVT中的位置编码替换为CPVT中提出的条件位置编码CPE,使其在分类和下游任务上直接获得大幅度的性能提升。尤其是在稠密任务上,由于条件编码CPE支持输入可变长度,使得对于图像的处理上,可以灵活处理来自不同空间尺度的特征。
2.2 基于深度学习模型的音频处理技术
众所周知,早期的语音识别系统通常由两部分组成:一是利用输入的waveform,人为提取MFCC特征;二是通过分类模型来对声音进行识别。随着深度神经网络技术的发展,可以通过CNN、DNN、LSTM等深度神经网络结构来自动化提取特征,相对于非端对端模型,减少了工程的复杂度,并广泛的应用到语音识别中获得了良好的效果。
2006年以来,虽然基于深度学习的CTC模型(如LSTM-CTC、RNN-CTC等)在语音识别声学建模上获得了巨大的成功,但该模型也存在如下问题:一是缺乏语言模型建模能力,不能整合语言模型进行联合优化;二是不能构造模型输出之间的依赖关系。针对CTC的不足,Alex Graves提出了RNN-T模型。RNN-T模型巧妙的将语言模型与声学模型整合在一起,同时进行联合优化。2020年2月,谷歌团队提出了Transformer Transducer。其是一款在RNN-T模型基础上,把LSTM encoding替换为transformer encoders的模型,利用有限宽度的上下文时序信息,在基本不损失精度的条件下,可以满足流式语音识别的要求,获得了巨大成功。
2.3 基于深度学习模型的文本处理技术
近年来,NLP自然语言处理在文本识别方面获得了巨大的成功,可以通过文本嵌入技术来获得文本特征的深度表达。例如Skip-Gram、Word2vec和GloVe等等。基于深度学习的文本处理任务存在很多模型,如ABCNN、IndRNN和TextCNN模型等。在此基础上,2017年谷歌公司提出了基于多头注意力机制的Transformer的模型,该模型并没有沿用典型的循环神经网络结构,而是通过多头注意力来学习文本的语义,并在性能方面超越了其它模型。
2.4 多模态特征融合技术
众所周知,对于多模态任务,如VQA、视觉定位等,都需要融合两个模态的特征。近年来,多模态融合最常用的方法是拼接(concatenation)、按位乘(element-wise product)、按位加(element-wise sum)。而多模态紧凑双线性池(MCB)的作者认为,这些简单的操作融合效果不如外积,不足以建模两个模态间的复杂关系。MCB将外积的结果映射到低维空间中,使其计算更为方便。双线性池化首先对特征提取,得到特征映射每个位置的特征向量进行向量外积计算,然后对所有位置外积计算的结果进行平均池化得到特征向量;最后经过L2范数标准化得到最后的特征。
3 基于深度学习的多模态的商品检索引擎
根据深度学习的特点,本文设计了一种全新的基于深度学习的多模态商品检索引擎。其整体结构框架如图1所示。该引擎的工作流程如下:首先采用深度学习模型对用户偏好信息中的文本和图片信息进行特征提取,即对商品数据库中的文本和图片进行特征提取;然后对用户输入的检索条件(如文本、音频和图片)信息进行特征提取;计算两种商品特征的相似度,选取相似度超过一定阈值的商品,组成用户偏好商品集合;之后求得商品数据库内的商品信息和用户检索查询之间的商品特征向量相似度,选取相似度超过一定阈值的商品组成用户检索查询的商品集合。如果上述两个集合有交集,在交集中根据商品特征相似度,选取前个商品作为多模态商品检索的结果;否则,就将用户检索查询的商品集合中根据商品特征相似度选取前个商品作为多模态商品检索的结果。

图1 多模态的商品检索引擎结构图Fig.1 Structure diagram of multimodal commodity retrieval engine
多模态特征融合信息主要分为两类:一类是对于用户检索的条件包含了音频、文本和图像的特征融合;还有一类是对于商品数据库信息和用户偏好信息的融合(如文本和图像特征融合)。
关于音频、文本和图像的特征提取以及融合如图2所示。首先采用LCMV算法对音频进行增强,然后将音频分成Refiner段,再把Refiner段带入Transformer Transducer模型得到文本转换信息;然后把这些文本信息和用户检索查询的文本进行串联拼接,再对拼接后的文本进行Skip-Gram嵌入分词得到Tokenization,将其带入Transformer模型得到文本的特征向量;之后图像的处理也是如此,先将图像进行分割成Patch Projection,再将其带入Twins-PCPVT模型进行特征提取,得到图像的特征向量;最后再将文本的特征向量和图像的特征向量采用多头注意力机制和全连接层的处理,得到了处理后的商品信息的文本和图像的特征向量,再将这两个特征向量带入MCB模型进行融合。
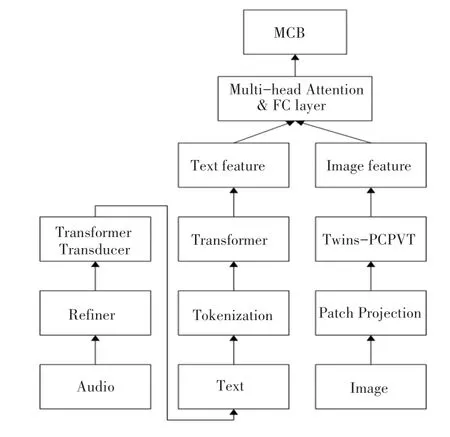
图2 多模态特征融合的结构图Fig.2 Structure diagram of multi-modal feature fusion
4 实验及分析
本文选用KDD Cup 2020挑战赛中的多模态商品数据集,该数据集中包含用户文本检索数据和图像检索数据,从中选取10万条数据作为实验数据集,在此基础上添加了用户的偏好信息,并为数据集中50%的样本添加了商品语音检索信息,构造出实验所需的多模态商品数据集(MCDB)。实验环境为Ubuntu13.04操作系统,Intel i9 109000x处理器,内存32G,GPU RTX3090 32G,硬板1T。实验中使用Python3.6和Pytorch1.10深度学习框架编写程序来实现模型并对上述模型进行训练。
为了验证本文模型的有效性,选取具有代表性的文本检索模型LSTM-DSSM和图像检索模型DELF与本文提出的多模态商品检索模型MCFRNet模型进行运行时间效率对比实验,实验结果见表1。

表1 单模态与多模态商品检索模型的时间效率Tab.1 Time efficiency of unimodal and multimodal commodity retrieval models s
表1中,MCFR-Net-1表示利用图像和文本进行商品检索的模型,MCFR-Net-2表示利用声音和文本进行商品检索的模型,MCFR-Net-3表示利用图像、文本和声音进行商品检索的模型。在模型训练阶段,随机选取MCDB数据集上的80%样本进行训练,其余的作为测试样本。通过表1可以看出,本文提出的MCFR-Net模型相比LSTM-DSSM和DELF模型需要更多的训练时间才能使模型收敛,但对于测试样本的平均测试时间不存在明显差异。
根据检索召回率对比LSTM-DSSM、DELF和MCFR-Net的性能,实验结果见表2。

表2 单模态与多模态商品检索模型的召回率Tab.2 Recall rate of unimodal and multimodal commodity retrieval models %
通过表2可以看出,随着检索排序结果数量的增加,各模型的检索召回率都有明显提升。DELF模型的性能要高于LSTM-DSSM模型,而本文提出的MCFR-Net系列模型的召回率明显高于DELF和LSTM-DSSM,并且MCFR-Net-3模型的性能最好。
5 结束语
综上所述,本文设计了一种全新的多模态商品检索引擎,采用深度学习和特征融合技术实现了多模态数据同时应用在一次搜索行为中。实验证明,面对多种多样的信息来源(如语音,图像和文本)时,可以使用多模态检索引擎模型来提升搜索的准确性,解决了单模态检索模型特征表示能力有限和准确性较低的问题。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
专利代理(2016年1期)2016-05-17 06:14:36
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
质量与标准化(2010年5期)2010-05-03 04:15:40
