
基于最短欧氏距离替换码元的VoIP隐写算法
2022-07-13 01:51孙鑫昊王开西
计算机工程与应用 2022年13期
孙鑫昊,王开西
青岛大学 计算机科学技术学院,山东 青岛 266071
加密系统、隐私系统和信息隐藏系统是信息安全领域[1]的三大基本安全系统。由于加密和隐私系统在公共信道中建立信道,信道易被定位,攻击者可以对其进行阻断、拦截或篡改、窃听或破坏。与加密系统和隐私系统不同,信息隐藏系统将秘密消息传输信道隐藏到不易被怀疑的公共信道中,攻击者无法准确有效地定位秘密通信信道。
随着现代技术的发展,数字媒体已经成为信息隐藏系统的主要载体类型,包括文本、图像、音频和网络流等[2]。随着网络的普及和多媒体技术的发展,基于IP的语音传输(voice over internet protocol,VoIP)技术逐渐成熟,它不仅可以被部署在传统电信运营商运营的IP多媒体子系统(IP multimedia subsystem,IMS)中,而且还能被融合到互联网上的许多社交应用中,如微信、Skype等。VoIP 的广泛应用、低冗余度和实时性等特点,使其成为信息隐藏的主要载体之一,基于VoIP 的隐写已成为当今的研究热点。
VoIP 具有低冗余性、实时性等特性,使得其作为隐写载体进行隐写更加困难,但是同样检测难度也更大,所以基于VoIP 的隐写研究具有重要意义。Xiao 等人[3]提出了互补邻节点(complementary neighbor vertex,CNV)算法,该算法通过将线性预测编码(linear predictive coding,LPC)码本中的码元根据图论构建成多个子图,根据子图中相邻位置属于不同码本的原则,将原始码本分为两个子码本。发送方可根据秘密消息和音频选择子码本及其中的码元,从而嵌入秘密消息。Tian 等人[4]在CNV 的基础上提出了Sec-QIM 方法,通过秘钥与矩阵编码方式进一步提升了隐写的安全性与嵌入效率。
虽然基于VoIP 的隐写术已经较为成熟,但是随着隐写检测技术的发展,隐写术还需更进一步提升。本文根据对载体的改动越少,越不容易被检测的基本原则,提出了最短欧氏距离替换码元的方法。提出的方法以VoIP 中压缩音频的LPC 特征参数作为操作对象,将其划分成不同的原子隐写单元,每个原子隐写单元进一步划分为数据域和索引域。在数据域中,对比秘密消息与数据域LPC值的欧式距离,使用秘密消息替换最小距离的LPC值,在索引域中将数据域中被替换的位置进行记录。在实验分析方面,本文分别从语音质量、隐写容量、隐写效率以及KL 散度(Kullback-Leibler divergence)等方面进行了实验分析和对比。结果表明,相比已有方法,本方法具有较高的隐写效率,较低的隐写修改率,具有很好的安全性,而且极大地改善了语音质量。
1 相关工作
目前,基于VoIP 的隐写算法按照修改区域的不同主要分为三类:基于协议域的隐写术、基于载荷域的隐写术和两者混合使用的隐写术[2]。其中,基于载荷域的隐写术通过修改特征参数值或者调整在音频压缩过程中的某些操作进行秘密消息的隐藏。例如,在线性预测编码中的矢量量化(vector quantization,VQ)操作中,使用量化索引调制(quantized index modulation,QIM)[3-4]或者最低有效位(least significant bit,LSB)[2]实现隐藏秘密消息。或者在基音预测编码中进行修改实现隐写。例如,Yan 等人[5]发现在基音编码过程中产生的第二个参数适合进行隐写,引入了三层嵌入矩阵进行隐写;而刘程浩等人[6]则通过控制基音搜索自适应码本的取值范围来实现隐写。
VoIP 的实时性和高压缩性使压缩后的音频都具有极低的冗余。对于隐写术来说,分析和利用这些冗余是隐写的主要工作。VoIP中使用G.723.1和G.729等低速率编码标准进行数据压缩,不同编码器的冗余分布特性不同。文献[7-8]采用不同的方法对G.729 压缩标准的冗余度进行分析,得出LPC特征参数(特别是LPC的第二个特征参数)比其他参数具有更大的冗余度,Su[7]和Liu 等人[8]基于G.729 的LPC 特征参数的固定码本进行了信息隐藏研究,其方法都具有很好的隐蔽性。G.723.1标准支持5.3 Kb/s和6.3 Kb/s两种速率,文献[9]和[10]分别对这两种速率下的编码标准进行了验证和分析,同样得出了LPC 特征参数比其他参数冗余度更大的相同结论,由此可以得出,LPC 特征参数适合用于基于修改操作的隐写。综上,本文选择使用LPC特征参数作为隐写操作对象。
现有以LPC 特征参数作为操作对象的信息隐藏技术主要分为两类:基于QIM 的隐写和基于LSB 的隐写。基于LSB 的隐写通过修改载体中的最不敏感位置(修改后产生的失真最小的位置)的参数来使隐写后的音频损失尽可能的少。Tian 等人[11]提出了一种利用m序列技术的隐写模型,考虑了连续帧之间的相关性,获得了良好的秘密传输安全性。
QIM 方法是由Chen 等人[12]在2001 年提出,此方法应用于音频、图像、视频等含有能够划分码本的压缩过程中。在音频编码中,一个含有已训练好码元的码本将会被分成了两个(或更多)个子码本,发送方根据秘密消息选择对应的子码本,并根据待编码的音频从子码本中找到一个最优码元从而完成秘密消息的隐藏。例如定义其原始码本为CB,CB按某种分类标准被分为两个子码本,分别被命名为CB0和CB1。CB和CB0、CB1必须满足公式(1)和公式(2):

如果当前秘密消息是比特“0”,则根据当前音频帧在CB0码本中找到最优码元,若秘密消息为“1”,则在CB1码本中找到最优码元。
陈铭等人[3]基于QIM思想,提出了基于离散余弦变换(discrete cosine transform,DCT)域QIM 的音频信息隐写算法,该算法针对信息提取的误码,采用改进的QIM 方案隐写。通过对在嵌入端与提取端进行容错处理同时提取误码,根据量化区间与信息比特的映射关系提取秘密消息。周围等人[14]提出了一种基于听觉掩蔽效应的自适应量化索引调制音频信息隐藏算法,针对听觉感知特性划分临界带,提高了算法的不可见性和安全性,同时使用QIM提高算法的隐写容量。
对于QIM 方法,如何有效地将原始码本划分成子码本从而减少音频失真是关键问题。Xiao等人[3]提出的CNV算法,将码本中的码元看作图中的节点,根据欧式距离计算其邻居节点(距离当前节点最近的节点),并连接邻居节点从而构成多个子图。在每个子图中,两个相邻的码元被分配给不同的子码本,使原码本被划分为两个子码本。该方法有效地减少了QIM方法因为码本分割造成的失真损失,对基于统计特性的隐写分析具有较强的抵抗力。而Tian等人[4]在CNV的基础上,利用互补邻居顶点算法中码本分割子码本的特点,设计了一种基于密钥和矩阵编码的码本分割策略,该策略遵循Kerckhoffs原则,具有更高的安全性。
2 向量量化(VQ)
VoIP会话通信过程中,音频经模数转换器转换为数字信号后,通过压缩编码经由IP网络传输至接收器。接收器端接收到IP包并对其进行解压缩和数模转换,获得传输音频。本文提出的方法的操作对象在压缩编码过程中的LPC的VQ中计算,本章将对LPC码本结构以及VQ的基本原理做基本介绍。
不同编码标准的LPC 码本是不同的,且每个码本可能有不同数量的元素。每一个元素是一个键值对,表示为x↔
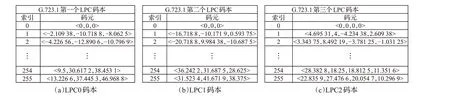
图1 G.723.1码本Fig.1 Codebook of G.723.1
VQ 操作是将多个输入参数量化为一个参数,以便压缩数据,降低失真[2],在高压缩率的同时产生较小的失真[15]。VQ从原始音频中提取到的参数向量与码本中已经训练好的码元向量进行对比,选择码本中与原始音频系数向量失真最小的一个码元,输出其索引值作为一个LPC 值。接收方可根据该索引调用码本中的码元向量作为输出,其值近似于原始音频的系数向量[16]。
在图2所示的VQ 操作中,输入系数向量A与每个预先训练的码元基于特定失真标准进行计算,选择失真最小的码元的索引值输出。解码器接收索引值并在码本中找到码元向量A′作为输出。

图2 向量量化(VQ)过程Fig.2 Vector quantization process
3 最短欧氏距离替换码元隐写算法
本文提出了一种基于最短欧氏距离的最优替换码元方法(SED-CR)。首先给出如下定义、约束和符号说明。
(1)隐写单元(steganography unit,SU):音频经压缩编码后得到M帧LPC值(每帧中含有N个LPC值),定义为隐写单元SU。SU根据需求分成多个含有NUM个LPC 值的子隐写单元(sub-SU,下文称为原子隐写单元)。使用矩阵CW表示隐写单元SU:

SU根据公式(4)划分原子隐写单元,隐写过程中将以原子隐写单元作为隐写操作对象。如图3 演示了在G.723.1编码标准下的一种原子隐写单元划分方式。对于含有11帧,每帧含有3个特征参数的CW矩阵,定义前3行作为索引域:L1、L2、L3,其余8帧数据按列划分成3组数据域,定义为D1、D2、D3。索引域和数据域一一对应,即
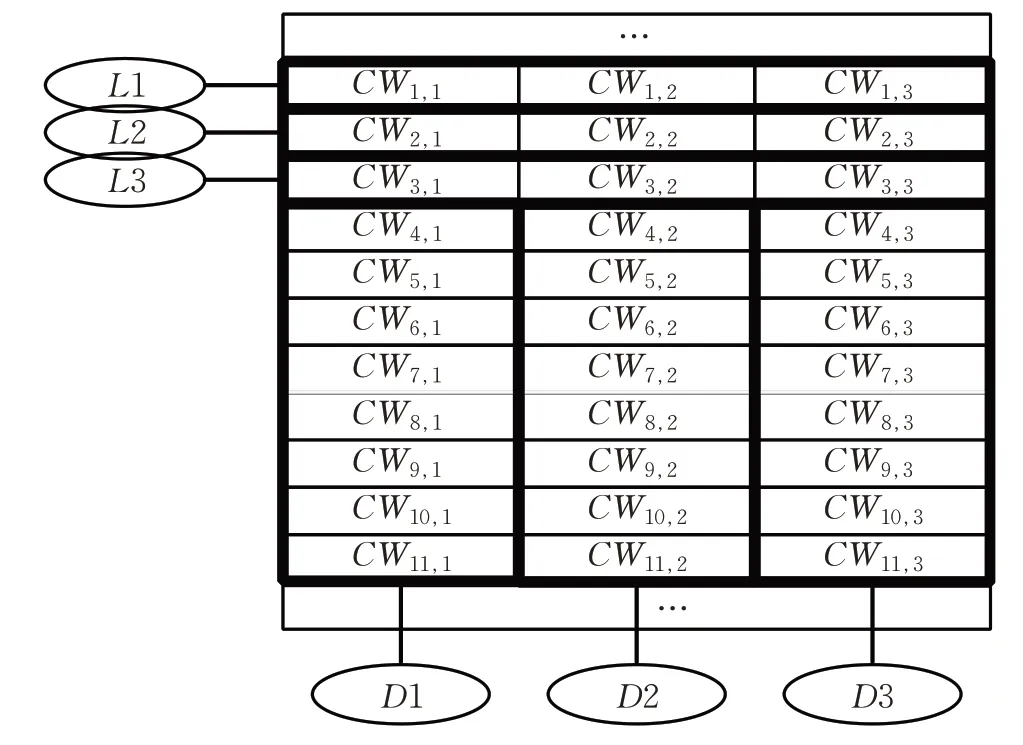
图3 G.723.1隐写单元划分样例Fig.3 Example of steganographic unit for G.723.1
(4)定义所有LPC 特征参数的码本的集合为CB={CB1,…,CBn,…,CBN}。对于任意CWm,n,CWm,n∈CBn,m∈[1,M],n∈[1,N],即同一列的码元来自同一个码本。
基于上述定义、约束和符号说明,本文提出的最短欧氏距离替换码元隐写算法隐写过程如图4 所示。在隐写过程中,首先提取sub-SU 中所有LPC 值。其次在sub-SU 的数据域,根据码本集CB确定每个LPC 值和SS对应的码元向量,计算SS码元向量与数据域中每个LPC 值的码元向量之间的欧氏距离,确定与SS具有最小欧氏距离的LPC 特征参数的位置。最后使用SS替换此LPC值,并在sub-SU的索引域使用CNV方法隐藏被替换参数的位置。
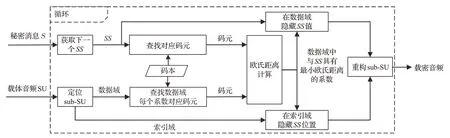
图4 隐写单元整体嵌入流程Fig.4 Overall embedding procedure of SU
CNV方法采用的策略是计算每个码元与其他码元的欧氏距离,以确定当前码元的邻居节点并构成多个子图。然后根据处于同一子图的相邻节点属于不同码本的原则进行子码本划分,其核心是通过相邻节点分布在不同码本的划分减少失真。本文提出的方法采用的策略是计算秘密消息与数据域的LPC值的欧氏距离,确定距离秘密消息最近的LPC值进行替换,关键在于操作过程中大幅度降低修改的参数数量,以此达到减少失真的目标。
最短欧氏距离替换码元隐写算法数据域隐写详细过程如下:

步骤4 确定CW_DATA中距离SS有最小距离的LPC值,并用SS将其替换,完成当前原子隐写单元数据域秘密消息嵌入操作。
以下举例说明上述数据域隐写过程。假设SS=128,选择G.723.1中第一个LPC特征参数的码本作为所有特征参数的码本,其替换过程如图5所示。对于秘密消息片段SS,从码本中获得其码元向量为。sub-SU中数据域的LPC 值分别是254、10、156、81、88、88、90、120,从码本中获得码元向量后分别与SS的码元向量进行欧氏距离计算得到最小欧氏距离的LPC值为120,使用128替换120,数据域隐写操作完成。
数据域替换隐写过程完成后,为了定位被替换的位置,在索引域中使用CNV 方法将其位置进行嵌入。例如在图5 示例中,128 替换的位置为7(从0 开始计数,7的二进制表示为111),则可以用CNV 方法将7 隐写到sub-SU的索引域中。

图5 秘密消息SS 替换过程示例Fig.5 Demonstration of index replacement process by SS
4 实验与分析
在本章中,提出的SED-CR与CNV方法和Sec-QIM方法分别在音频质量、隐写容量、修改比特率、KL 散度以及隐写效率方面进行了实验和分析。实验中使用的数据集来自于文献[17],该数据集包含41 h 的中文和72 h 的英文VoIP 通话音频。本文实验数据从上述数据集中随机截取了2 000 个长度20 s 的音频片段,并将其分为4 组:英文男声(ESM)、英文女声(ESW)、中文男声(CSM)和中文女声(CSW),每个分组音频数量为500个。
4.1 语音质量
本文使用PESQ 客观语音质量测评工具(PESQ 把在信号传输通过设备时提取的输出信号与参照信号进行比较计算出差异值。一般情况下,输出信号和参照信号的差异性越大,计算出的值就越低,PESQ 值范围为[−0.5,4.5])分别对CNV、Sec-QIM 和SED-CR 进行隐写后音频质量评估,结果如表1所示。
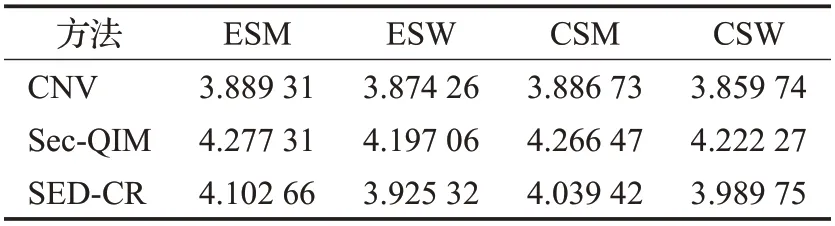
表1 隐写语音质量Table 1 Steganography audio quality
根据表1,本文提出的方法在语音质量语音质量上明显高于CNV方法。相比CNV方法,本文方法替换的LPC 特征参数可能不是最优的,因为这取决于SS与LPC 值的匹配程度,可分为下列两种情况:一是被替换的LPC 值与SS相同,即二者的欧式距离为零,此时无需替换,失真为零,是优于CNV方法的;二是SS与LPC值不匹配的情况,此时替换值造成的失真比CNV 方法差。本文根据实验统计发现,在G.723.1中,第一种情况出现的概率为15.92%,第二种为84.08%。虽然第二种情况出现的概率大,但是因为在隐写过程中改动的数量更少,最终导致了语音质量上升幅度,这都说明所提方法低修改率的优势,虽然提出的方法在语音质量不及Sec-QIM 方法,但其对应的语音质量能满足通信的要求。
4.2 隐写容量
本文定义作为载体的音频含有M帧数据帧,每帧中有N个LPC 值。CNV 方法的隐写容量可以达到:CCNV=M×N。而对于Sec-QIM方法来说,每帧能隐藏lb(N+1)个比特秘密消息,载体隐藏总量为CSec=M×lb(N+1) ,在使用的Sec-QIM 方法中,采用N=3 的策略,即每帧可隐藏的秘密消息数量为2 bit,则隐写容量为CNV方法的66%。本文提出的方法的隐写容量计算如公式(6)所示:

实验结果表明,在不考虑其他条件下,提出的方法的隐写容量可以达到CNV方法的267%,但在实际应用中,需要根据实际情况进行参数调整,因此其可能达不到此理想比率。当秘密消息通信过程中对隐蔽性要求较高时,ND和NI的值需要增大
4.3 比特修改率(MBR)和隐写效率
本文定义比特修改率(MBR)为隐写后修改的数量(MB)与所有可被修改的数量(AB)之比,如公式(8)所示:

在本节实验中,选择使用满嵌入率和72%嵌入率的CNV 方法(与提出的方法的隐写容量保持一致)、Sec-QIM方法和本文提出的方法进行MBR统计计算。相同音频长度下,Sec-QIM 的隐写容量是满嵌入率下CNV的66%,而本文提出的方法(图3分组)是CNV的72%。
实验结果如表2所示。SED-CR方法相较于其他方法在修改率上具有显著的降低,对于相同容量的CNV方法能降低11.3个百分点。与Sec-QIM方法相比,其值虽然下降幅度不大只有2.2 个百分点,但是提出的方法的隐写容量比Sec-QIM方法多了6.73个百分点,在修改比特率方面也是优于Sec-QIM 方法。虽然Sec-QIM 采用矩阵编码减少修改数量,但是其会增加更多的冗余数据,而本文方法虽然也会增加冗余,但是相对比Sec-QIM 方法,根据隐写容量和MBR 实验分析,提出的方法能在增加较少的冗余前提下隐藏更多的秘密消息。
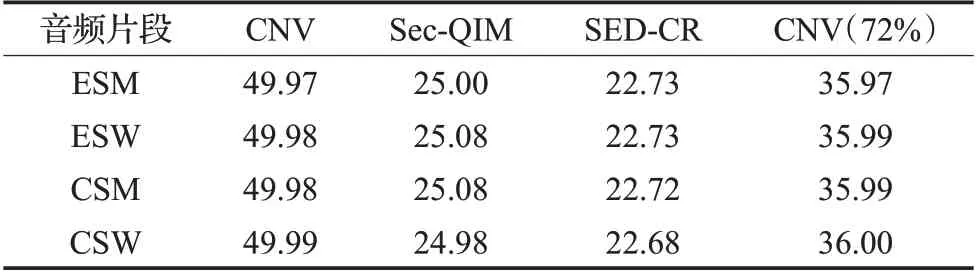
表2 不同方法下的MBR比较Table 2 Comparison of MBR by different methods%
文献[4]提出了隐写效率的概念,其表示如公式(9)所示,表示修改1单位下能隐藏的秘密消息单位数。

其中,SB 表示秘密消息数量,MB 表示修改的数量。根据每个方法的不同特点,每个方法的隐写效率如表3所示。可以发现,SED-CR方法在隐写效率方面效果显著。

表3 不同方法下的隐写效率δTable 3 Steganography efficiency δ under different methods
4.4 安全性分析
为提高安全性,一个信息隐藏系统应当使隐写后的特征参数的统计分布PS尽可能地接近原始前的统计分布PC。KL 散度[18]被用来量化PS与PC的差异。其定义如公式(10)所示:
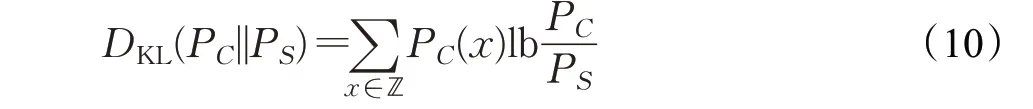
其中ℤ 为特征参数的所有可能值组成的一个集合空间。当时,意味着这个隐写系统是绝对安全的。本文对CNV、Sec-QIM和SED-CR方法的音频的统计分布与未隐写音频的统计分布进行KL散度分析。实验结果如表4所示。
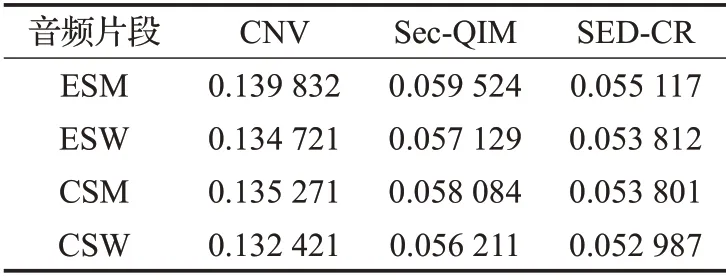
表4 KL散度Table 4 KL divergence
由表4 可以看出,本文提出方法的KL 散度相比较CNV 与Sec-QIM 方法的数值都要低,证明提出的方法在安全性上具有明显的提升。提出的方法与Sec-QIM方法的KL 散度虽然差距不是很明显,但是由于本文方法的隐写容量相较于Sec-QIM 方法提升了6.73 个百分点,实现了在隐写容量增加的前提下安全性也得到了提升。
5 结束语
本文提出了一种基于最佳替换码元的隐写方法,通过降低修改率提高隐写的隐蔽性和隐写效率。通过对比秘密消息与数据域中LPC 特征参数进行欧氏距离计算,选择最短距离特征参数进行替换,在索引域中记录被替换的特征参数的位置完成隐写。本文方法对音频质量有一定的改善。在相同隐写容量的情况下,改进后的比特率比CNV 方法低约13 个百分点,隐写效率可达3.2。
猜你喜欢
数学年刊A辑(中文版)(2022年3期)2023-01-05
电讯技术(2022年3期)2022-03-27
通信技术(2021年12期)2022-01-25
导航定位与授时(2021年2期)2021-04-16
河北北方学院学报(自然科学版)(2021年1期)2021-02-25
空间科学学报(2020年1期)2021-01-14
雷达与对抗(2020年2期)2020-12-25
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
四川大学学报(自然科学版)(2020年1期)2020-01-10
中国交通信息化(2019年12期)2019-08-13
