
结合LDA与Word2vec的文本语义增强方法
2022-07-13 01:51唐焕玲卫红敏王育林窦全胜
计算机工程与应用 2022年13期
唐焕玲,卫红敏,王育林,朱 辉,窦全胜
1.山东工商学院 计算机科学与技术学院,山东 烟台 264005
2.山东省高等学校协同创新中心:未来智能计算,山东 烟台 264005
3.山东省高校智能信息处理重点实验室(山东工商学院),山东 烟台 264005
4.山东工商学院 信息与电子工程学院,山东 烟台 264005
5.上海绘话智能科技有限公司,上海 200120
文本表示在自然语言处理领域占据重要的地位,对自然语言处理领域中的文本摘要[1-2]、信息抽取[3-4]、自动翻译[5-6]等任务产生重要的影响。由于自然语言具有复杂性、多样性等特点,使得目前文本表示的研究存在“维数灾难”“向量高度稀疏”“浅层语义”等诸多问题[7-11],导致文本向量不能充分表达文本信息,文本语义表示仍然是目前研究的重点和难点[12]。
文本表示方法常用的是词袋模型(bag of word,BOW)[13]和基于BOW 的向量空间模型(vector space model,VSM)[14],两者将文本表示成实数值分量所构成的向量,在文本分类任务上取得不错的效果,但是都存在向量高度稀疏、无法处理“一义多词”和“一词多义”的问题。
Blei等人[15]提出了LDA(latent Dirichlet allocation)主题模型,将主题看作是词的概率分布,将文本表示从高维词空间变换到低维主题空间。LDA主题模型属于无监督学习,SLDA(supervised LDA)[16]模型将文档类别标记作为观测值加入LDA主题模型,能识别主题-类别之间的语义关系,提高了文本分类的性能。
Word2vec(word to vector)[17]模型成功用于情感分类、句法依存关系等领域,可以在大规模无监督文本语料上快速训练得到词向量,但是Word2vec 模型没有区别上下文单词与中心词的语义关系,语义相对缺失,对后续任务的效果提升有限。
近年来,文本表示方法的研究有了新的进展。Glove(global vectors for word representation)模型[18]是基于全局词频统计的词嵌入工具,将单词之间的语义关系转化为嵌入空间的向量偏移量,可以有效地计算单词间的语义相似度。GPT(generative pre-training)系列模型[19-21]采用单向transformer叠加完成训练,但其采取的语言模型是单向的,未考虑下文语义信息,语义相对缺失,且参数巨大。BERT(bidirectional encoder representations from transformers)[22]在transformer 中引入了注意力机制,能够准确地训练出词向量,广泛应用于许多领域,但其需要庞大的语料库,计算量巨大且成本高,难以应用于实际生活中。
鉴于此,本文提出一种将LDA主题模型与Word2vec模型相融合的文本语义增强方法Sem2vec(semantic to vector)模型,利用该模型对文本语义进行增强,进一步提高后续自然语言处理任务的性能。Sem2vec 模型从预训练的LDA主题模型中获得单词与主题之间的先验知识,并通过主题嵌入向量,将该先验知识融入语义词向量的训练之中。本文的主要贡献如下:(1)利用LDA主题模型识别单词主题分布,计算中心词与上下文词的主题相似度,从而得到上下文单词的主题权重嵌入词向量,作为Sem2vec模型的输入。(2)根据最大化对数似然目标函数,训练Sem2vec 模型获得最优参数,根据最优参数计算单词的语义词向量表示。(3)根据单词的语义词向量进一步获得文本语义向量表示。由此,利用LDA主题模型将全局语义信息融入到了词向量的训练之中。通过在不同数据集上的语义相似度计算和文本分类实验,验证了Sem2vec 模型的有效性,该模型在增强文本语义的同时,有效提高了模型的训练速度。
1 LDA主题模型和Word2vec模型
1.1 LDA主题模型
LDA主题模型是三层贝叶斯概率生成模型,是一种无监督模型,该模型认为文档是主题的概率分布,而主题是词汇的概率分布,LDA概率图模型如图1所示[15]。

图1 LDA概率图模型Fig.1 LDA probability graph model
LDA主题模型采用Gibbs采样算法,对第m篇文档的第i个单词t的隐含主题采样,计算方法如式(1)所示:

1.2 Word2vec模型
Word2vec 模型是目前主流的词分布式表示模型,Word2vec模型包含两种模型,分别是CBOW(continuous bag of words model)模型与Skip-Gram(continuous skip-gram model)模型,模型结构如图2所示[17]。CBOW的核心思想是通过上下文词预测中心词,Skip-Gram 则是通过中心词预测上下文词。与Skip-Gram模型相比,CBOW模型适合文本数量较大的运算,具有较高的计算精度,本文采用CBOW模型。
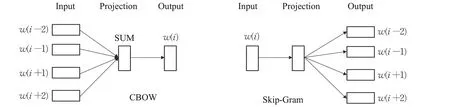
图2 Word2vec模型结构Fig.2 Word2vec model structure
CBOW 模型本质上是采用三层神经网络来训练词向量,模型输入是某个特定词上下文相关的词,模型输出是该特定词的词向量。在CBOW模型中训练目标是使对数似然函数L最大化。

2 Sem2vec模型
结合LDA 主题模型和Word2vec 模型,本文提出了一种将主题语义信息与词向量相融合的文本语义表示方法,该方法从主题层面和词层面来增强文本的语义。
2.1 Sem2vec模型框架
在Word2vec 模型中,没有区别上下文单词与中心词的语义关系,然而不同上下文单词与中心词在语义上是有差别的。为此,本文结合LDA主题模型,获得单词主题分布,识别单词的主题语义信息,通过单词主题嵌入向量,将该先验知识用于Sem2vec模型语义词向量的训练之中,以增强文本的语义表示。Sem2vec模型结构如图3所示。
如图3 所示,Sem2vec 模型包括主题嵌入层、输入层、隐藏层和输出层。在主题嵌入层,由预先训练生成的LDA主题模型,获得主题-词分布φ和文档-主题分布θ。给定中心词wi,根据主题-词分布φ,计算中心词与其上下文词的主题相似度γi。然后,融合γi与Wi计算得到主题权重嵌入词向量Ψi。Ψi作为Sem2vec 模型的输入层的输入,经过隐藏层函数计算后得到模型的输出yi。在最大化对数似然目标函数约束下,通过反向传播优化ϑ和ϑ′,经过多次迭代训练得到最优ϑ*和ϑ′*。
2.2 主题嵌入层
不同于Word2vec模型,Sem2vec模型的输入层前面增加了主题嵌入层,如图3所示。
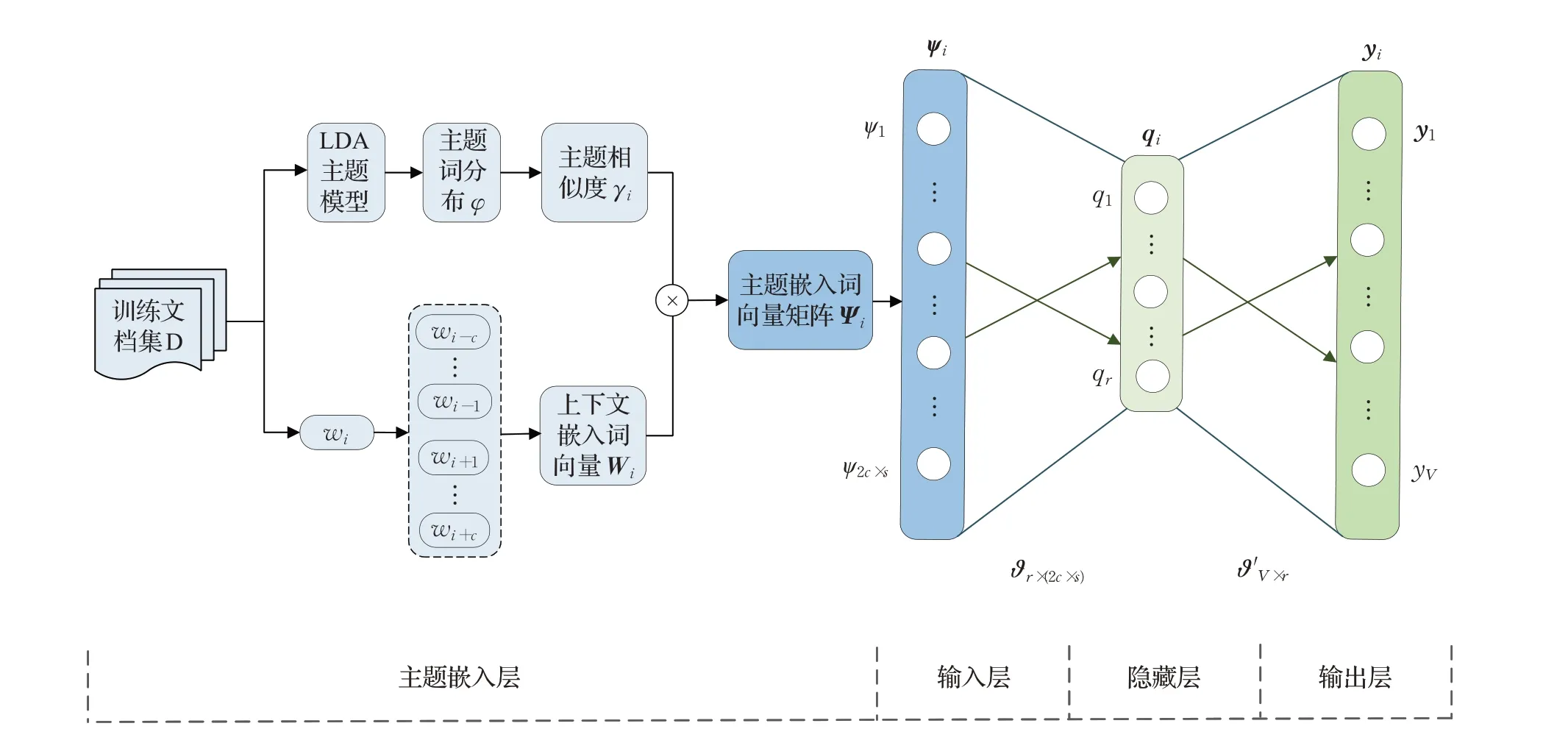
图3 Sem2vec模型结构Fig.3 Sem2vec model structure
给定中心词wi,首先进行上下文词嵌入,假设上下文窗口大小为c,词向量的维度为s,则其上下文词嵌入向量为:
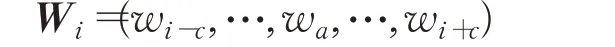


2.3 Sem2vec模型的训练与测试



如算法1 所示,由预先训练生成的LDA 主题模型,获得主题-词分布φ和文档-主题分布θ。在每轮迭代训练中,首先计算得到中心词wi的主题相似度权重向量γi,然后对上下文词向量进行主题加权,经过式(7)计算后得到单词wi的主题权重嵌入矩阵Ψi,Ψi作为Sem2vec模型的输入,经过隐藏层函数计算后得到输出向量yi。而后通过梯度下降算法使得式(10)目标函数的对数似然概率最大化,反向优化ϑ和ϑ′,得到最优参数ϑ*和ϑ′*。其中超参数c、s和r的值在实验中经验选取。
对任意一篇新文档中的每个单词经过主题嵌入层计算得到主题权重嵌入列向量ψ̂,输入到Sem2vec 模型,根据最优参数ϑ*按照式(14)计算,最终得到单词的语义词向量v。
2.4 文本语义向量表示
Sem2vec 模型将主题语义信息融入到词向量的训练中,在训练生成Sem2vec 模型之后,得到Sem2vec 模型的最优参数ϑ*和ϑ′*。任意单词输入到Sem2vec 模型,可以根据式(14)计算输出其语义词向量。在此基础上,进一步计算文本的语义向量。
给定文本xm={w1,w2,…,wNm}为数据集D中的第m篇文档,Nm为文档单词总数。对文本中的每个单词wi,按照式(7)计算得到单词wi的主题权重嵌入向量:

其中,xm∈ℝNm∗r。由此,在Sem2vec模型的基础上,根据单词的语义词向量,可以获得任意文本的语义向量表示。
3 实验分析
3.1 实验环境和参数设置
本文在下述环境下进行实验:64 位Windows10 系统,Intel®CoreTMi5-5200U CPU @ 2.20 GHz 处理器,8 GB 内存,使用的编程语言为Python,深度学习框架Pytorch。影响算法性能的主要参数及其影响的描述如表1所示。
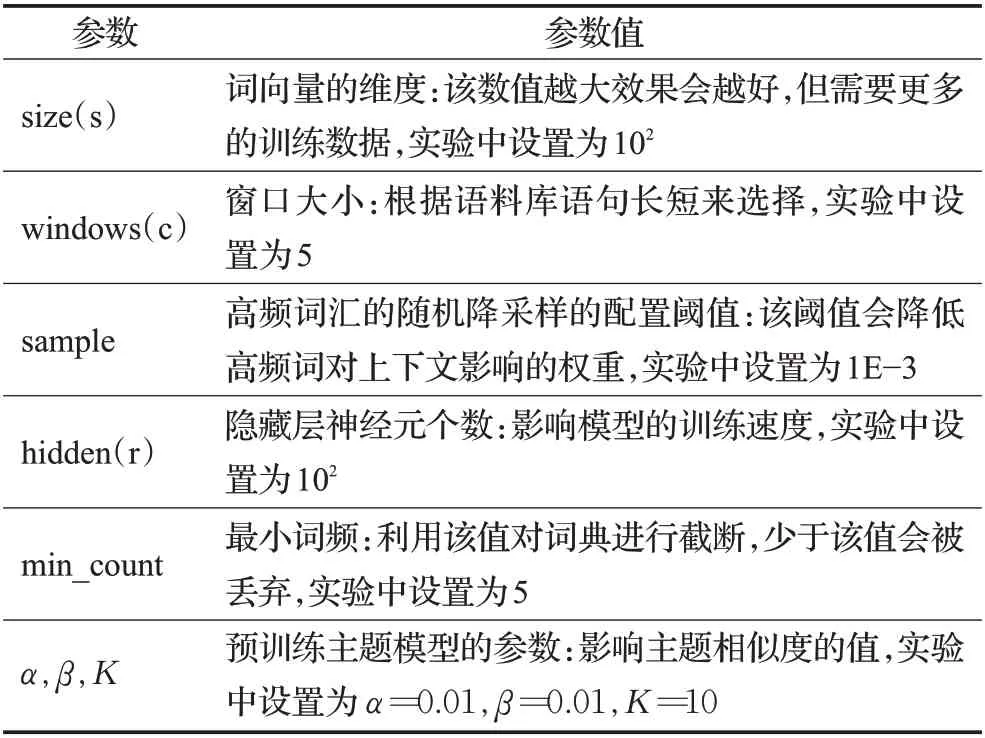
表1 参数描述Table 1 Parameter description
3.2 数据集和对比方法描述
实验选取搜狗(Sogou)、清华(THUCNews)和20 新闻组(20newsgroup)这3个公开数据集,随机抽取部分文档和类别构建实验数据集,描述如表2 所示。其中,20newsgroup 中选取20 类文档,Sogou 中文数据集中选择了包括类别为IT、军事、教育、旅游和财经的5 类文档,THUCNews 数据集中选择了包括财经、彩票、房产、股票和家居的5类文档。实验中按照8∶2构建训练集和测试集。

表2 数据集描述Table 2 Datasets description
为了验证Sem2vec 模型的有效性,在表2 所示的中英文数据集上,从单词的语义相似度和文本分类两个角度,与Word2vec 和Glove 模型进行了对比实验,具体的实验对比方法描述如下所示。
(1)Sem2vec(cos):按式(5)余弦夹角计算单词的主题相似度的Sem2vec 模型,记作Sem2vec(cos),训练语义词向量。
(2)Sem2vec(JS):按式(6)JS 散度计算单词的主题相似度的Sem2vec模型,记作Sem2vec(JS),训练语义词向量。
(3)Word2vec:按照Word2vec模型训练词向量方法。
(4)Glove:按照Glove模型训练词向量方法。
实验中,根据经验设置超参数c=5,r=102,s=102。单词的语义相似度的评价采用余弦相似度,分类结果的评价采用Accuracy、Macro-precision、Macro-recall 和Macro-F1。
3.3 实验结果及分析
3.3.1 语义相似度比较
利用单词的语义相似度任务,验证Sem2vec模型的有效性。首先基于Sem2vec 模型、Word2vec 模型和Glove模型,分别生成单词的词向量,计算并比较词向量之间的语义相似度,相似度计算采用余弦夹角公式。在Sogou数据集上的对比实验结果如表3所示。
如表3所示,第2列是一个类别的代表词,第3~7列表示与对应的代表词语义最相近的前5 个词及语义相似度。从表3 中的数据可以直观看出,与Word2vec 和Glove 模型相比,Sem2vec 模型在计算词之间的语义相似度方面更准确一些。例如,选取“联想”为“IT”类中的代表词,在Sem2vec(JS)模型中,得到的与“联想”的最相似是“电脑”,Sem2vec(cos)得到的最相似是“价格”,而Word2vec 模型得到的最相似词是“系列”,与Word2vec模型相比,Sem2vec模型词与词之间的相关性更大。选取“考研”为“教育”类中的代表词,在Glove 模型和Sem2vec(cos)模型中,与“考研”语义最相近的词都是“专业”,其中Sem2vec(cos)的语义相似度为90.7%,Glove 的语义相似度为89.6%。这是因为Sem2vec 模型将单词的主题分布信息融入到了语义词向量的训练学习中,因此可以更准确地捕获单词的语义信息,从而提高语义相似度计算的准确性。
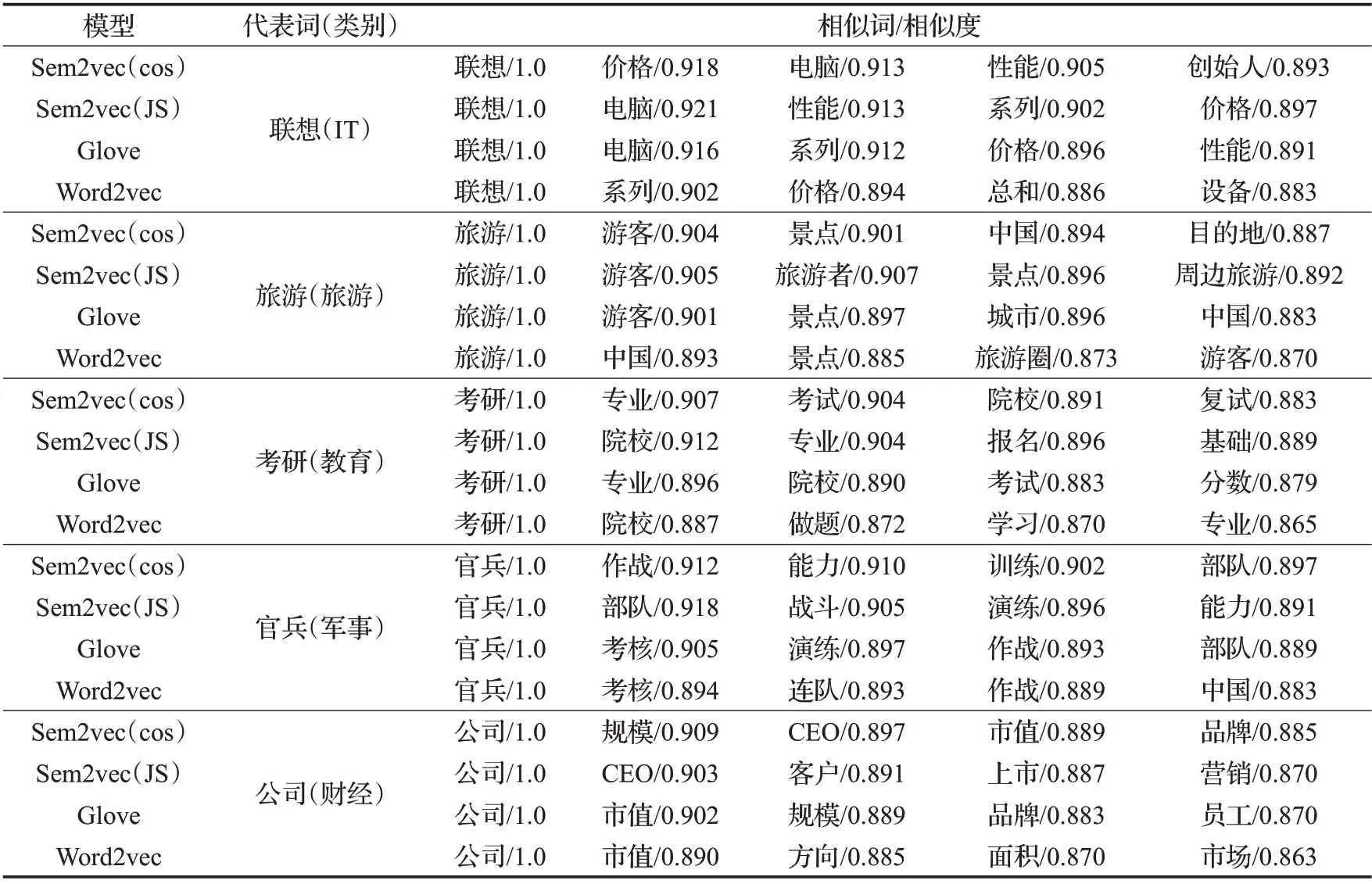
表3 语义相似度比较Table 3 Comparison of semantic similarity
3.3.2 分类结果比较
这里利用文本分类任务,来验证Sem2vec模型在文本语义表示方面的有效性。基于Sem2vec、Glove 与Word2vec模型,在多种分类任务上进行了实验比较,其中分类算法包括textcnn、BiLSTM 和Transformer,分类评估指标采用Accuracy、Macro-precision、Macro-recall和Macro-F1。在20newsgroup、Sogou 和THUCNews 数据集上的实验比较结果如表4~6所示。
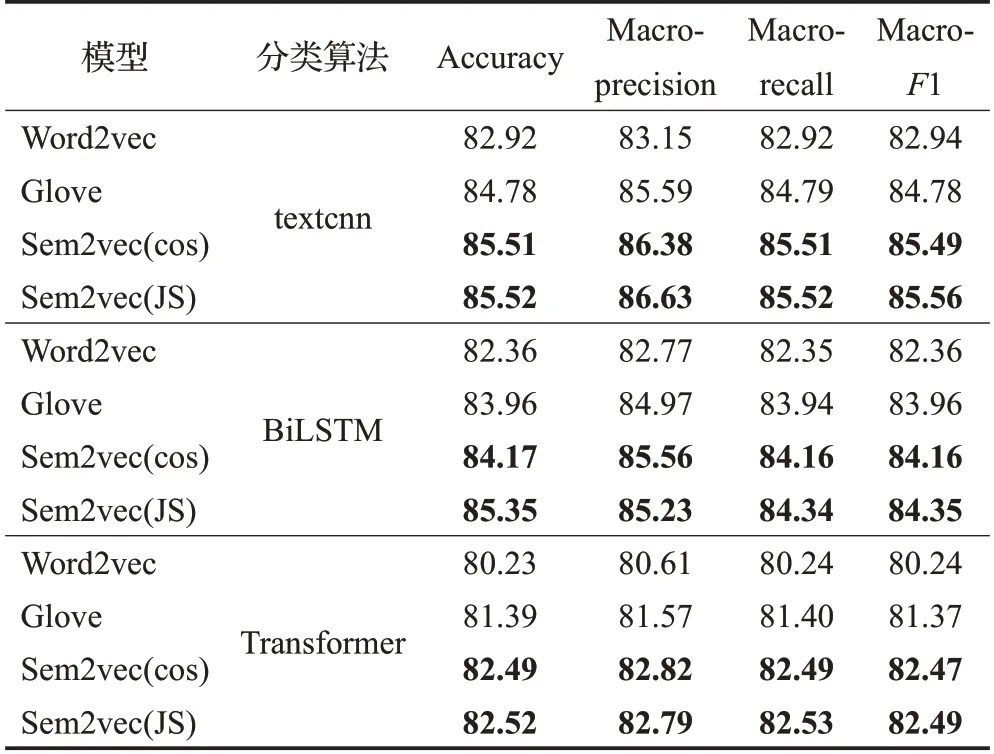
表4 20newsgroup上分类算法结果比较Table 4 Comparison results of various classification algorithms on 20newsgroup %
如表4所示,在20newsgroup数据集上,分类算法为textcnn时,对比Word2vec,Sem2vec(JS)的4种指标分别提高了2.60、3.48、2.58、2.62个百分点,对比Glove,指标分别提高了0.74、1.04、0.73、0.78 个百分点。当分类算法为BiLSTM 和Transformer 时,Sem2vec 模型的4 种分类指标也均高于Word2vec和Glove模型。
从表5 和表6 中的数据可以看出,在Sogou 和THUCNews数据集上,基于Sem2vec模型的各种文本分类算法的分类结果也均高于Word2vec 和Glove 模型。这是因为,基于Sem2vec模型的文本语义向量融入了单词的主题分布信息,因此可以更准确地捕获单词的语义信息,从而提高文本分类的准确性。
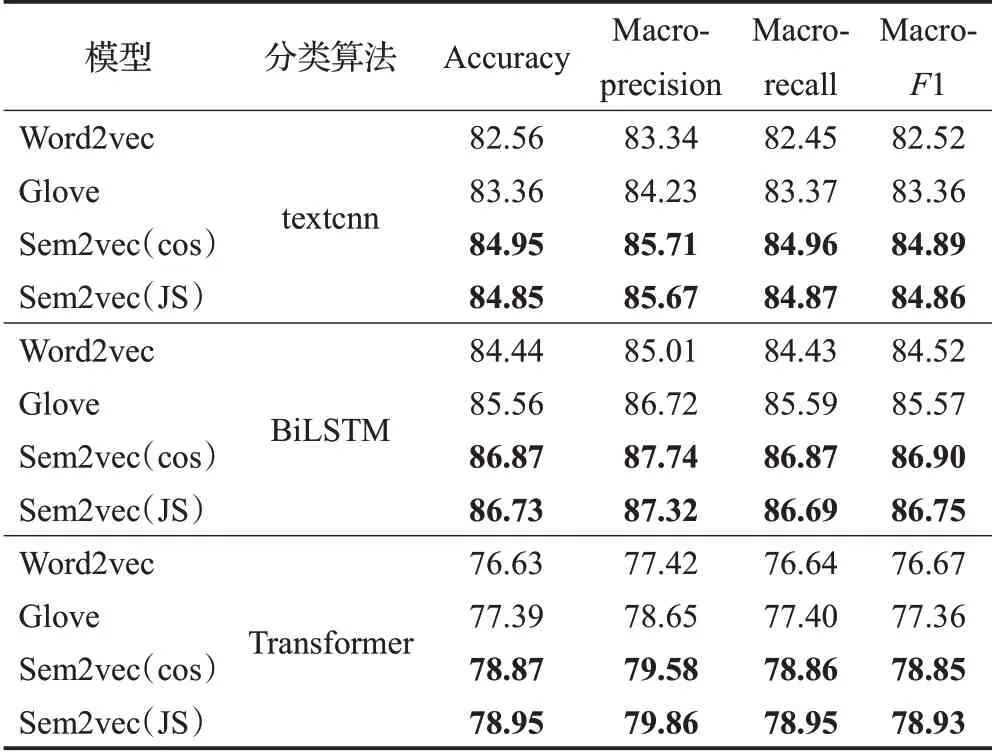
表5 Sogou上分类算法结果比较Table 5 Comparison results of various classification algorithms on Sogou %
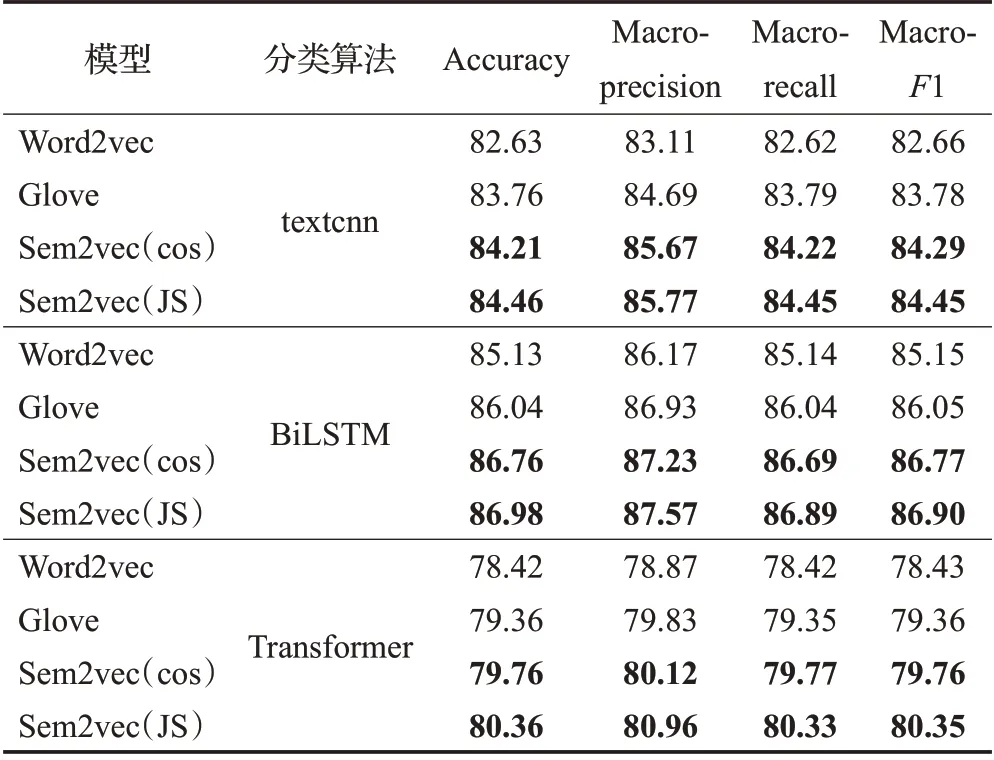
表6 THUCNews上分类算法结果比较Table 6 Comparison results of various classification algorithms on THUCNews%
Sem2vec、Word2vec 与Glove 模 型 在20newsgroup和THUCNews数据集上的时间性能比较如表7所示。
从表7中可以看出,在两个数据集上,Sem2vec模型的分类准确率均高于Word2vec和Glove模型,且Sem2vec模型的训练时间比Word2vec 模型要快9%~14%,比Glove 模型快7%~9%。如在20newsgroup 数据集上,当分类算法为textcnn 时,Sem2vec 模型的训练时间比Word2vec 模型快14%,比Glove 模型快8%,且Sem2vec模型的分类准确率比Word2vec 高2.6 个百分点,比Glove 模型高0.74 个百分点,在其他分类算法上也是类似的。同样的,在THUCNews 数据集上,Sem2vec 模型的训练时间比Word2vec模型要快9%~14%,比Glove模型快7%~9%,且Sem2vec 模型的3 种分类准确度优于Word2vec 模 型1.59~1.71 个 百 分 点,优 于Glove 模 型0.58~0.68个百分点。原因在于,Sem2vec模型增加了主题嵌入层,相当于从预训练的LDA 主题模型中获得单词与主题之间的先验知识,该先验知识通过主题嵌入向量来指导语义词向量的训练,从而加快了训练速度。若词典的大小为V,则Sem2vec 模型的时间复杂度为O(V)。
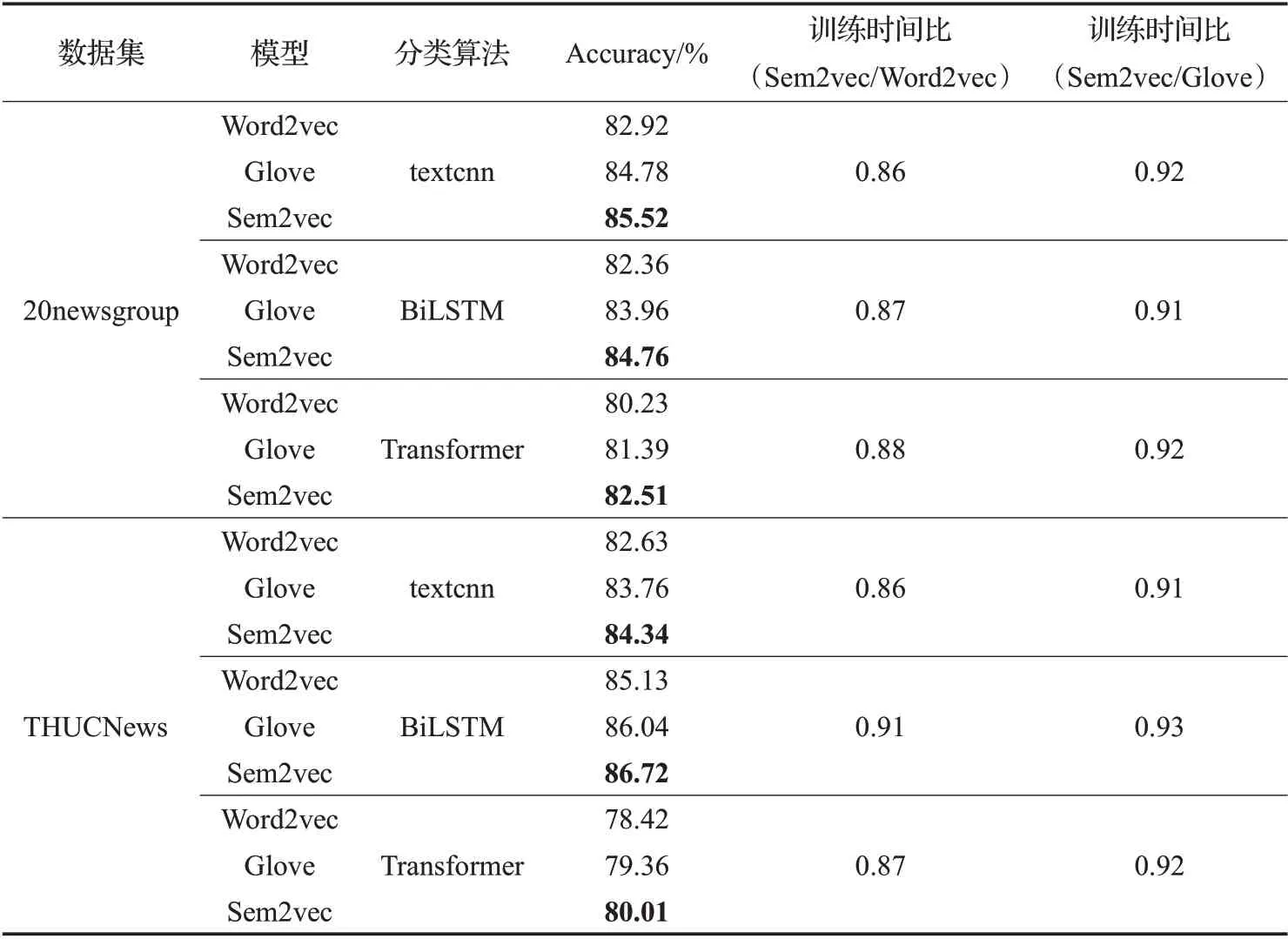
表7 Word2vec、Sem2vec与Glove时间性能比较Table 7 Time performance comparison of Word2vec,Sem2vec and Glove
在Sogou和THUCNews数据集上,对比分析Sem2vec、Word2vec 与Glove 模型在不同epoch 下,各种分类算法的Macro-precision、Macro-recall 和Macro-F1。实验结果如图4~9所示。
基于Sem2vec、Word2vec 和Glove 模型的各种分类方法的结果比较如图4~9所示,其中横坐标表示训练次数epoch,纵坐标表示Macro-precision、Macro-recall 和Macro-F1。可以看出,采用Sem2vec模型的各种分类结果优于对比模型。
如图4~6所示,在Sogou数据集上,3种分类算法随着epoch 的不断变大,基于3 种模型的各种分类结果均逐渐提高,并收敛于一定的上限,并且可以从图中看出,基于Sem2vec 的各种分类结果与对比模型相比更好。如图4(a)所示,采用textcnn分类算法,当epoch=100时,对比Word2vec 的Macro-precision 值83.34%,Sem2vec(cos)的为85.71%,Sem2vec(JS)的为85.67%,分别提高了2.37个百分点和2.33个百分点。如图5(b)所示,采用BiLSTM 分类算法,当epoch=100 时,对比Glove 的Macro-recall 值85.59%,Sem2vec(cos)的为86.87%,Sem2vec(JS)的为86.69%,分别提高了1.28个百分点和1.10 个百分点。在transformer 分类的算法上也是类似的,基于Sem2vec模型的各种分类结果均高于Word2vec和Glove模型。
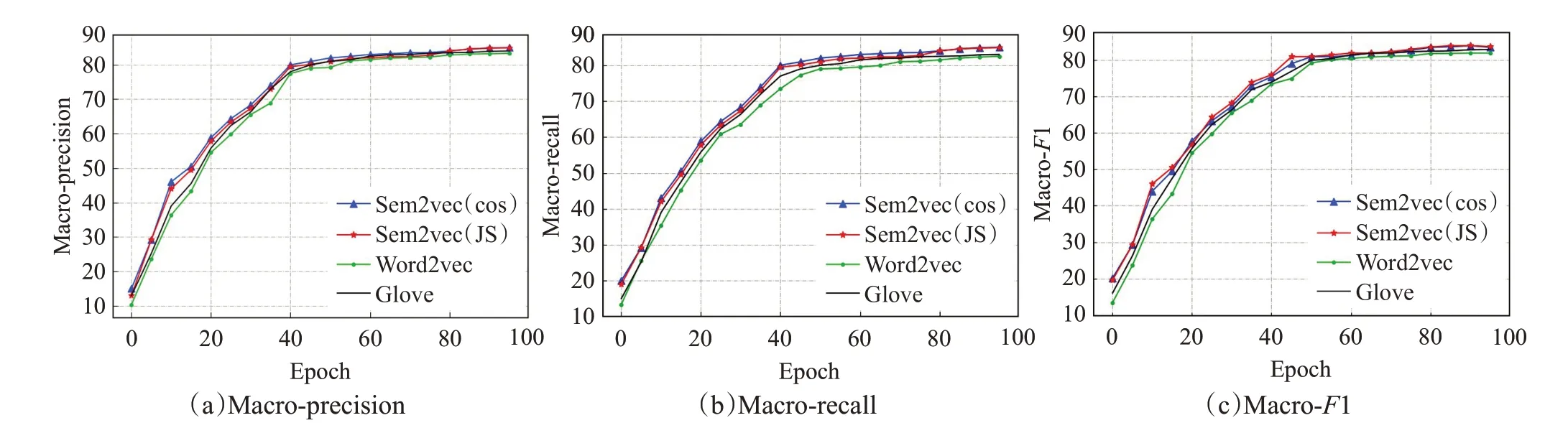
图4 Word2vec、Sem2vec和Glove的textcnn分类结果比较(Sogou)Fig.4 Comparison of textcnn classification results of Word2vec,Sem2vec and Glove(Sogou)
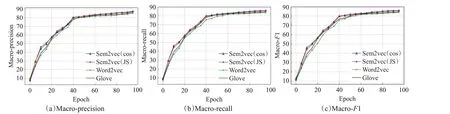
图5 Word2vec、Sem2vec和Glove的BiLSTM分类结果比较(Sogou)Fig.5 Comparison of BiLSTM classification results of Word2vec,Sem2vec and Glove(Sogou)

图6 Word2vec、Sem2vec和Glove的Transformer分类结果比较(Sogou)Fig.6 Comparison of Transformer classification results of Word2vec,Sem2vec and Glove(Sogou)
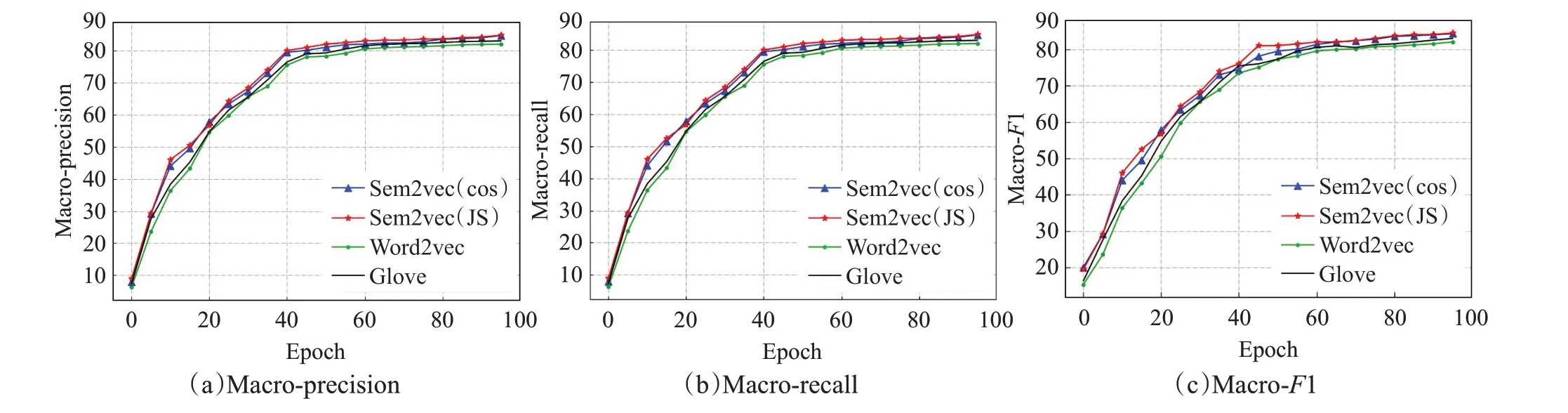
图7 Word2vec、Sem2vec和Glove的textcnn分类结果比较(THUCNews)Fig.7 Comparison of textcnn classification results of Word2vec,Sem2vec and Glove(THUCNews)
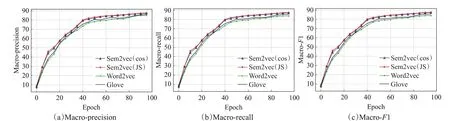
图8 Word2vec、Sem2vec和Glove的BiLSTM分类结果比较(THUCNews)Fig.8 Comparison of BiLSTM classification results of Word2vec,Sem2vec and Glove(THUCNews)
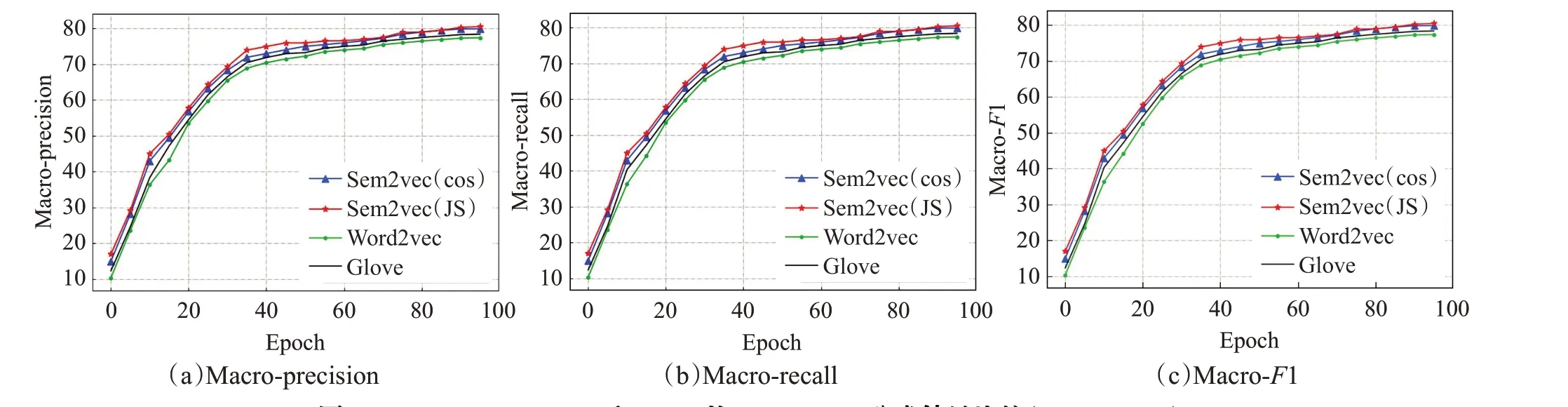
图9 Word2vec、Sem2vec和Glove的Transformer分类结果比较(THUCNews)Fig.9 Comparison of Transformer classification results of Word2vec,Sem2vec and Glove(THUCNews)
同样,如图7~9所示,在THUCNews数据集上,基于Sem2vec 的各种分类方法的结果均高于对比模型。如图7(a)所示,采用textcnn分类算法,当epoch=100时,对比Word2vec 的Macro-precision 值83.11%,Sem2vec(cos)的为85.67%,Sem2vec(JS)的为85.77%,分别提高了2.56个百分点和2.66个百分点。在BiLSTM和transformer 分类方法上也是类似的,相比于Word2vec 和Glove模型,Sem2vec模型增强了文本的语义表示,因此能够提升文本分类的精度。
综上所述,Sem2vec模型将单词的主题分布信息融入了语义词向量的训练学习过程中,可以更准确地捕获单词的语义信息,因此能够得到语义增强的词向量表示,进而增强文本的语义表示。
4 结论
本文提出了一种文本语义增强方法Sem2vec模型,该模型将主题语义信息融入到词向量的训练中,进而对文本语义进行增强。在多个数据集上,利用单词语义相似度计算和文本分类两个任务,对比分析了Sem2vec模型的有效性。实验结果表明,与Word2vec和Glove模型相比,Sem2vec 模型在语义相似度计算方面更为准确。另外,根据Sem2vec 模型得到的文本语义向量,在多种文本分类算法上的分类结果,较对比模型可以提升0.58%~3.5%,同时也提升了时间性能。后续,将结合BTM(Biterm topic model)模型,对文本的语义增强表示展开进一步研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
四川大学学报(自然科学版)(2021年6期)2021-12-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用(2020年12期)2020-12-31
开放教育研究(2020年2期)2020-03-31
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
文苑(2015年9期)2015-09-10
