
结合卷积神经网络和三支决策的入侵检测算法
2022-07-13 01:51吴启睿黄树成
计算机工程与应用 2022年13期
吴启睿,黄树成
江苏科技大学 计算机学院,江苏 镇江 212003
互联网时代,计算机的网络安全引起了越来越多的关注,如何识别网络攻击是其中非常关键的问题之一[1]。作为识别网络攻击的重要技术,入侵检测技术一直为国内外学者广泛研究。
传统的基于机器学习的入侵检测技术已经在入侵检测中得到了大量的应用[2]。常见的传统机器学习算法有支持向量机算法(support vector machines,SVM)[3]、K近邻算法(k-nearest neighbors,KNN)[4]以及随机森林算法(random forest,RF)[5]。上述方法在一定程度上提高了入侵检测的性能。然而,传统的基于机器学习的算法不能自主地学习特征,不能很好地反映原始网络数据,并且检测模型稳定性不高,面对海量的网络数据时,并不能取得一个很好的识别效果。
随着深度学习在众多领域取得了巨大的成功,越来越多的深度学习技术也被应用到了入侵检测当中,常用的深度学习技术有深度信念网络[6]、自编码器[7]、循环神经网络[8]等。作为深度学习的有效算法,卷积神经网络是一种基于局部感受野和权值共享的特殊结构的深度学习模型,这样的结构使得卷积神经网络的模型所需参数更少,复杂度更低,从而能够很好地提取数据的深层特征。文献[9]在经典的卷积神经网络模型基础上先通过神经元映射得到新的特征矩阵,然后使用深度卷积神经网络进行特征提取,提升了系统性能。文献[10]将卷积神经网络提取的空间特征和循环神经网络提取的时间特征相融合并引入注意力机制,特征提取能力更强。文献[11]采用多尺度卷积核进行特征提取,并在卷积层中加入BN 方法进行优化,提高了准确率降低了误检率。文献[12]结合跨层聚合设计理念,改进了传统的基于卷积神经网络的入侵检测模型,取得了不错的效果。
在入侵检测算法中,相较于其他深度学习方法,卷积神经网络特征提取能力强,网络模型所需参数少、复杂度低。因此,卷积神经网络被广泛的用作特征提取。此外,现有的分类方法通常是传统的二分类法。当面对网络行为时,二分类法只取两种可能性,即仅将网络行为划分为正常和入侵两种状态。这样的划分策略使得当面对正常或入侵状态模糊的网络行为时,二分类法会出现误分类的风险。三支决策是在二支决策的基础上发展而来,它是人类处理不确定问题普遍采用的有效方法。相较于二支决策,三支决策是在二支决策的基础上引入边界域的思想,即将网络行为划分为正常、入侵和待定三种状态。对于处在边界域上不确定的网络行为,三支决策会采取延迟决策的方法,等待再次进行特征提取,从而补充更多决策信息后,重新进行判断,直至可以将其划分到正常或是入侵的网络行为。正是通过引入边界域的思想,三支决策减少了盲目决策的风险,提高了分类的准确率。
针对上述情况,本文将卷积神经网络与三支决策理论相结合,建立了基于卷积神经网络和三支决策的入侵检测模型,该模型继承了卷积神经网络特征提取能力强的优点,同时将卷积神经网络提取后的特征进行三支决策,对处于论域中信息不足的网络行为进行延时决策,获取到更多信息之后,再进行判断,并得到最终的决策结果。采用延时决策的决策方式相比于二支决策更加合理[13],最后得到的分类结果置信度更高。并且减少了分类过程中所耗费的时间。
1 相关理论
1.1 卷积神经网络
卷积神经网络的构建灵感来源于生物的视知觉。近年来,卷积神经网络以其强大的特征提取能力,引起了广泛的重视[14]。卷积神经网络通常由卷积层和池化层的堆叠组合来构建,这样的结构也使CNN 具有层特性和很强的映射能力,能够充分地学习数据特征。卷积层是网络最基本也是最重要的结构,卷积层输出的结果是由滤波器通过遍历特征图而来的。在卷积神经网络进行卷积操作时,滤波器每滑动一个位置,就会得到相应的映射,当滤波器遍历完整个特征矩阵,再加上网络参数、经过激活函数,便形成了新的特征矩阵。当所有的滤波器完成对特征图的映射时,将其堆叠组合就形成了该卷积层的特征图。目前,在激活函数中,ReLU函数使用较多,它相较于其他激活函数性能较优。卷积层的表达式可以整体表示为:

池化层一般处于两个连续的卷积层之间,池化层也可以称为采样层。当卷积层输出的特征图经过池化层的操作,数据的维度和复杂度将会进一步降低。这样的操作有效的避免了过拟合的问题,加强了网络的鲁棒性。从本质上来说,池化层是对卷积输出的特征图进行统计计算,用概率统计的数据特征代替全部特征。在对特征进行降维的同时,还能将特征数据中最有效的信息保留。常用的池化方式有两种,分别是计算平均值以及选择最大值,它们之间的区别是计算方式不同。常用的池化方式为平均值池化。
在卷积神经网络中,网络的训练包括前向传播和反向传播。当完成一次前向传播,可以获得原始数据的特征输出值。通过比较前向传播得到输出值与实际值之间的误差,再经过反向传播来更新网络参数,通常使用梯度下降法来获得损失函数的最优解。输出值与实际值之间的误差,通常使用预测值和实际值的平方差的一半即:

1.2 三支决策理论
三支决策来源于粗糙集,在二支决策的基础上引入了延时决策。当现有的特征不足以充分做出判断时,为了避免将正常的流量错当成攻击流量的可能,延迟决策的出现是一种可靠的选择。当数据信息得到足够的补充,再进行决策,这样的判断方法避免了信息不足而盲目决策的风险[15]。
误分类通常会伴随着一定的损失成本,在研究中,如果把一个正域的样本错误地归为负域的样本可能会造成一些麻烦,但是如果把负域的样本错误地分类成正域的样本就有可能造成灾难性的后果。
对于一个二分类问题,真实的分类标签可以表示为P(正),N(负)即接受和拒绝,可以用一个状态集Ω={X,¬X}来表示,即用某个数据属于X与某个数据不属于X来表示一个数据的归属问题。三支决策的决策集可以表示为D={DP,DB,DN},分别表示正向决策、边界决策以及负向决策。所有决策的代价损失函数如表1所示。记λPP、λBP、λNP分别表示当前数据属于X的时候,采取行动DP、DB以及DN时的损失,λPN、λBN、λNN分别表示当前数据不属于X的时候,采取行动DP、DB以及DN时的损失。
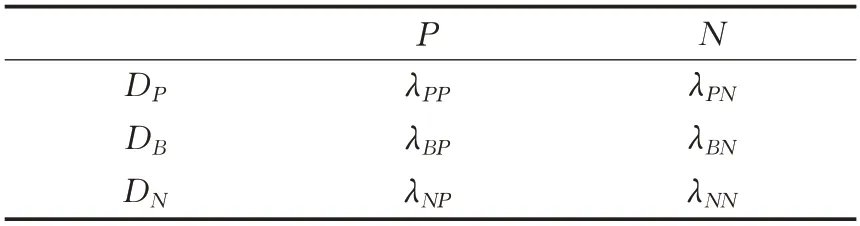
表1 决策的代价损失函数Table 1 Cost loss function of decision making

2 基于卷积神经网络和三支决策的入侵检测方法
2.1 入侵检测算法的整体流程
如图1所示,基于卷积神经网络和三支决策的入侵检测模型包括三个部分,它们分别是数据预处理、特征提取以及三支决策。
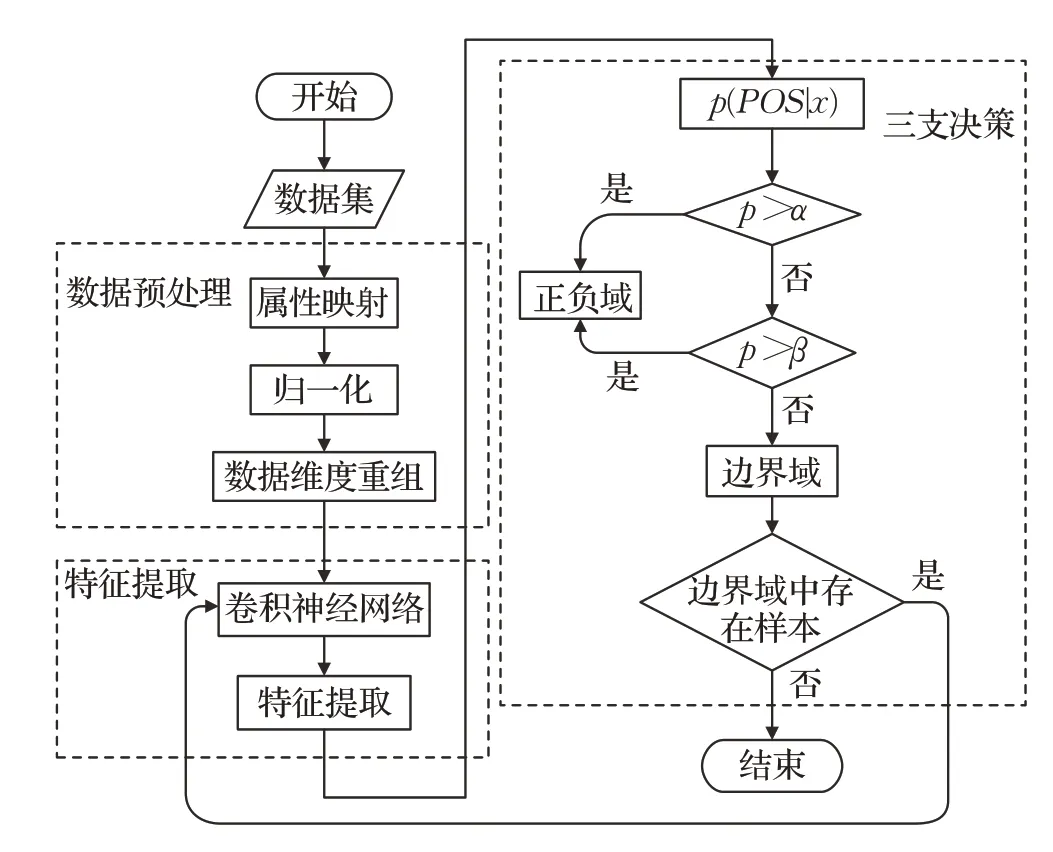
图1 基于CNN和三支决策的入侵检测算法流程图Fig.1 Intrusion detection algorithm flow chart based on CNN and three-way decisions
第一部分是数据预处理,首先对原数据集进行字符型特征数值化,接着对特征归一化处理,使其具有相同量级。最后将归一化后的特征进行维度重组,使其能够放入卷积神经网络进行训练。
第二部分是使用卷积神经网络对预处理后的数据进行特征提取,卷积神经网络具有局部感知和参数共享的特点,模型所需参数少、复杂度低,特征提取能力强。具体的提取步骤在2.2节中详细介绍。
第三部分为三支决策模块,通过引入边界域,三支决策对信息不足的数据采取延迟决策的策略,对不确定的数据再次进行特征提取,重新决策,规避了盲目决策的风险。
整体流程通过卷积神经网络与三支决策理论的结合实现对预处理后数据的分类。数据首先经过卷积神经网络完成特征提取,再交由三支决策进行判断。三支决策模块先获得每条数据属于正域的概率,如果满足大于α或者小于β的条件,则直接划分正负域。若不满足则归入边界域,放入特征提取模块,交由卷积神经网络再次特征提取并重新决策。在卷积神经网络中,边界域样本的每一次特征提取都会在前一次的特征提取的基础上提取到不同的特征,这就为分类器提供了不同的数据信息,从而支撑分类器对边界域中的样本做出决策。流程中当边界域存在样本数据时,过程将一直持续下去。
2.2 基于卷积神经网络的特征提取
使用卷积神经网络进行特征提取时,对网络的卷积层和池化层进行无监督训练,建立BP 神经网络。通过将反向传播将神经网络的输出值与实际样本值之间的误差逐层传到网络中,实现对神经网络的参数迭代更新。具体算法步骤如下:
输入:数据集X(X1,,X2,…,Xi);权重W,偏置b
输出:数据集X的低维表示X′
步骤:
1. 通过前向传播,计算预期值ŷ。
2. 根据公式(2)计算卷积神经网络的实际输出与实际样本之间的误差。
3. 将误差逐层传到神经网络中,根据公式(4),使用梯度下降法来更新网络参数。
4. 更新所有训练样本,选择损失函数总代价最低的网络参数。
5. 根据上步骤求得的网络参数,输出测试数据的低维表示,即提取的数据特征。
2.3 基于三支理论进行分类
根据限制条件,三支决策理论把整个论域分为三个区域,即正域、负域和边界域[16]。在整个决策过程中,都要确定是否对当前的对象做出最终的决策,即确定该对象是属于正域或负域,或是将不确定的对象归为边界域。
假设样本集为X={x1,x2,…,xn},样本xi属于正域的概率p(POS|xi)需要被求解出,其中i=1,2,…,n。将p值与阈值α,β进行比较:若p<β,则将其分入负域,若p>α,则将其分入正域,否则,则分入边界域。
通过卷积神经网络处理得到维度较低的数据,然后利用三支决策对数据进行分类,并根据阈值得到分类结果。对于边界域中的数据,在获得额外的信息,重新进行粒度提取后,将被重新评估。在边界域内不再有样本存在之前,这个决策过程将一直持续下去。具体算法步骤如下:


2.3.1 算法时间复杂度分析
纵观整个入侵检测算法,模型分为特征提取模块和三支决策模块,算法主要的时间复杂度分析也集中两个模块当中。首先是特征提取模块,由于特征提取方式G(卷积神经网络)是深度学习模型,而随着计算机算力的增强以及分布式计算的发展,通常并不计算深度学习模型的时间复杂度,因此并不能确定给出整个算法的时间复杂度,假设这两部分的时间复杂度为O(M)。而三支决策模块的时间复杂度主要集中在对测试集的迭代检查上,假设算法的迭代次数为T,其中第一次迭代时,数据集为测试集的全部数据,随着迭代的进行,测试集越来越小,直至测试数据集为空,停止迭代。由此可得,该部分的时间复杂度为O(T×N),其中,N为测试集中数据个数。于是本模型的时间复杂度为O(M)+O(T×N)。
2.3.2 三支决策阈值的设置
在基于三支决策理论进行分类时,通过损失函数得到阈值对α、β的值,并依此划分正域、负域和边界域。理论上,如果两个阈值的选择过于严格,例如0.95、0.05,这样的选择会导致测试数据集的迭代次数增加,不够友好。如果两个阈值选择过于宽泛,例如0.7、0.4,则会导致三支分类结果精度差。所以选取两个合适的阈值,从而将程序迭代次数控制在一个合理的范围,并兼顾到数据的分类效果是两个阈值选择的重点。通常情况,阈值的设定,在没有相关领域的研究前提下是不可行的,对于损失函数,根据所分析问题以及实际情况的不同,本算法根据专家经验以及先验知识进行设定。各损失函数如表2所示。
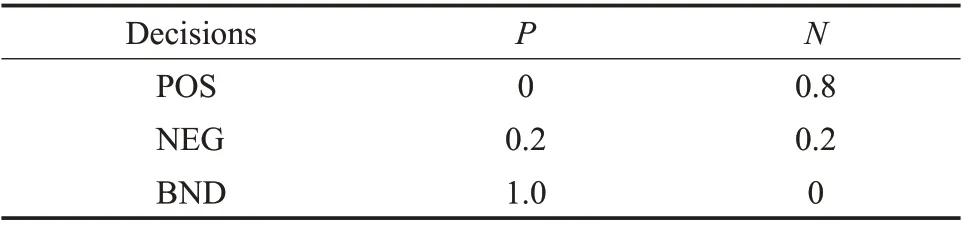
表2 三支决策损失函数的经验值设定Table 2 Empirical setting of three decision loss functions
通过设定的经验值,根据式(5)和(6)即可得到相应阈值。
3 实验仿真
3.1 数据集介绍
公开的网络入侵检测数据并不多,本文采用的是NSL-KDD入侵检测数据集和CIC-IDS2017入侵检测数据集。
3.1.1 NSL-KDD数据集
NSL-KDD 是KDD CUP99 优化后的数据集,虽然该数据集不能完美的代表目前真实网络环境下的入侵数据,但用来检测模型的能力依然具有一定的说服力。NSL-KDD数据集的类型分布如表3所示。

表3 数据集分布Table 3 Distribution of datasets
3.1.2 CIC-IDS2017数据集
CIC-IDS2017 数据集包含良性和最新的常见攻击,类似真实世界数据(PCAPs),补充了NSL-KDD 数据集缺少的各种已知的攻击,比如暴力FTP、暴力SSH、渗透、僵尸网络等等。
CIC-IDS2017 数据集中每条数据由79 个特征属性和1个类属性组成,数据集分布类型如表4所示。
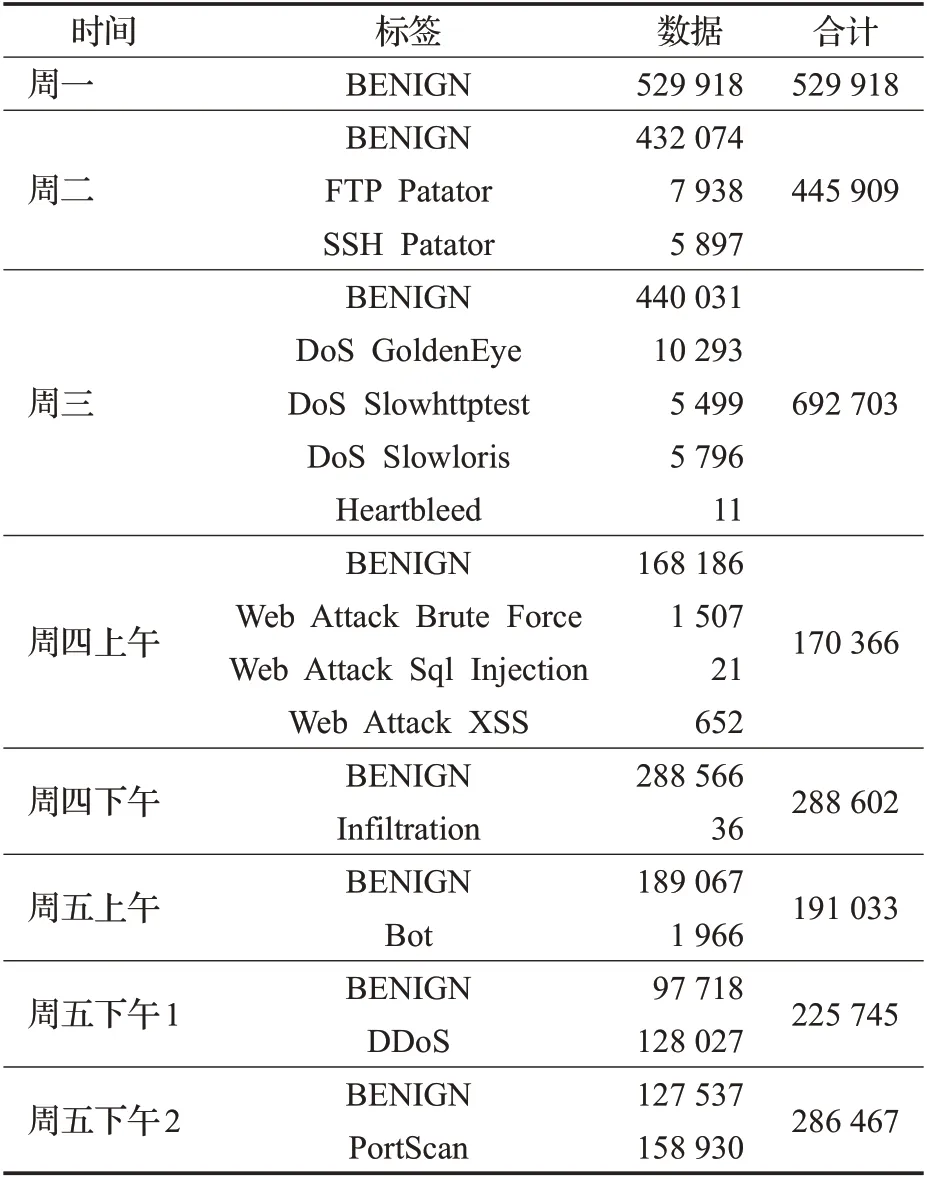
表4 CIC-IDS2017数据集分布Table 4 Distribution of CIC-IDS2017 dataset
由表4可知,该数据集存在着明显的长尾现象,即数据不平稳问题,数据处理部分需针对该问题进行优化。
3.2 数据预处理
数据预处理部分是对原始数据集进行处理,本文涉及两个数据集:NSL-KDD和CIC-IDS2017。相较于NSLKDD 数据集,CIC-IDS2017 数据集中存在属性列重复、个别属性列存在缺省值以及数据集存在明显的长尾现象,所以预处理部分增加了对重复列、缺省值以及数据不平衡的处理。不同数据集原始数据形式存在不同,但总体数据处理流程大体相同。首先读取数据集原始数据,使用Numpy模块装载数据,并根据需求对属性列进行去重等操作。接着对全体数据进行归一化,使得每个属性列所占比重相同。最后,将数据维度重组成一个二维矩阵向量,使其作为卷积神经网络的输入。
3.2.1 NSL-KDD数据预处理
(1)字符型特征数值化
由于离散型的数据无法运用到机器学习中,一般采用One-hot 进行编码。本实验中将数据集由41 个特征属性和1个类属性扩展成为拥有121个特征属性和1个类属性的数据集。
(2)Min-Max归一化
将特征进行Min-Max 归一化处理,使其具有相同量级:

在归一化处理的公式中,x*是归一化后的特征,x是原始特征值,xmin是该特征的最小值,xmax是该特征的最大值。在使用所提模型进行分类的过程,可以进行五分类的操作,也可以把五分类转化成五个二分类进行操作,即当Normal为正类的时候,其余的样本全部归为负类。本文选取后一种分类操作。
(3)数据维度重组
在卷积神经网络中,输入的数据应该是二维矩阵格式,因此需要将处理后的N维数据重组成一个二维矩阵。在进行维度重组时,如果出现维度和矩阵元素相冲突,一般有两种解决办法:一是在矩阵的末位进行相应的补0操作;另一种方法是减少特征维数,去掉在分类上不起作用的特征。本文实验中,采用减少特征维度的方法,将一个分类无关特征去掉,将其维度重组成一个二维矩阵向量。
3.2.2 CIC-IDS2017数据预处理
(1)处理重复列:统计中发现数据集中含有重复的两个属性,属性名均为“Fwd Header Length”,任意一个样本的这两个属性值均相等,所以删除其中一个属性。
(2)处理缺省值:统计发现缺省值存在于“Flow Bytes/s”和“Flow Packets/s”两个属性中,缺省的形式是“infinity”“NaN”或“?”,由于含有缺省值的样本非常少,所以直接删除含有缺省值的样本。
(3)数据不平衡处理:将“Web Attack Brute Force”“Web Attack Sql Injection”“Web Attack XSS”3 种入侵类型样本中,将这3 种类型合并成一种大的类型,即“Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv”“Tuesday-WorkingHours.pcap_ISCX.csv”“Friday-WorkingHours-Morning.pcap_ISCX.csv”3 个 文件合并成一个文件,类别标签为“Web Attack”。将3 种样本数较少的攻击类型合并成一种类型,可以一定程度上解决数据不平衡带来的问题。
(4)Min-Max归一化。
(5)数据维度重组。
3.3 实验性能评价标准
由于数据集存在分布不均衡的现象,因此单纯凭借准确性判断算法的优劣并不合适。在入侵检测领域,有两个评判指标比较重要,一个是误报率,一个是漏报率,而漏报率=1−检出率;精确率反映了被预测为异常的网络行为中有多少是真正的异常行为;F1 分数综合考虑了模型查准率和查全率的计算结果,是反应算法好坏的一个重要指标。
因此本文选用准确率ACC、检出率DR、精确率PR、误报率FPR以及F1得分作为系统性能的评判指标。评价指标的计算公式如下:

其中,TP代表功击记录;TN代表正常记录被正确分类;FP代表误认为是攻击的正常记录;FN代表误分类为正常记录的攻击记录。
3.4 样本选取和参数设置
(1)NSL-KDD样本选取
随机抽取5 个样本子集用作对比,取5 次实验的平均值作结果来用作分析。由于U2R类型的攻击偏少,所以在每个训练集中至少保留40 条U2R 类型的攻击数据。同样的,在每个测试集中将保留最少10 条U2R 类型的攻击数据。各数据集的类型分布如表5所示,表中Tr表示训练数据集,Te表示测试数据集。
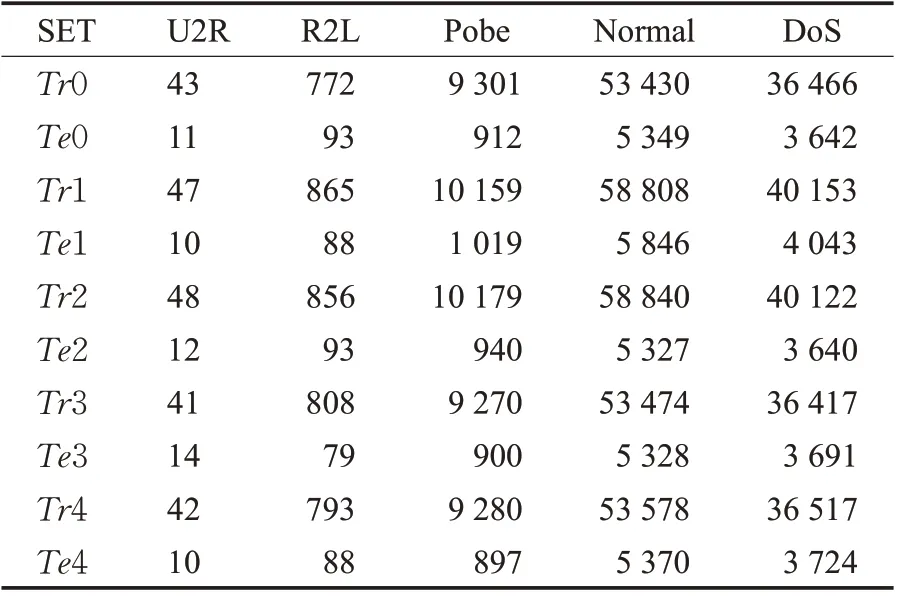
表5 5个数据样本子集数据分布Table 5 Data distribution of five data sample subsets
(2)CIC-IDS2017样本选取
选取的样本数据子集约占总数据集的三分之一,样本类型分布如表6所示。
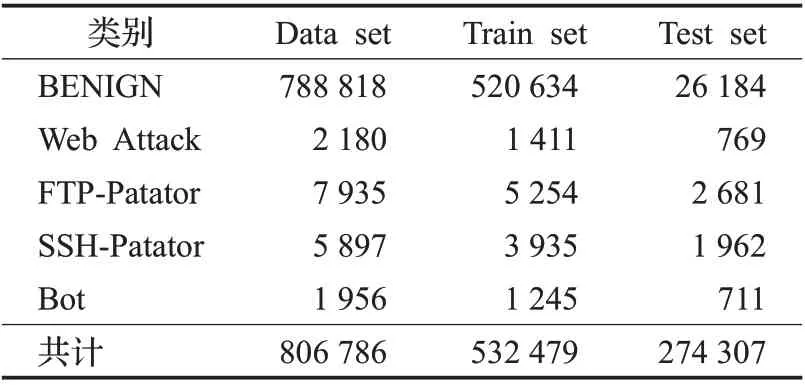
表6 样本集数据分布Table 6 Data distribution of sample sets
3.5 实验及结果分析
本文在处理边界域的时候考虑的主要是CNN网络提取到的信息会随着训练时间的增加而增加,而用数字表达就是重构数据与原始数据的均方误差会随着训练时间的增加而减少。如图2 为本文所使用的CNN 网络在特征提取的过程中,重构数据与原始数据之间的均方误差,从图中的曲线的走势可以看出,均方误差随着训练时间的增加而减少,表明由CNN 得到的低维的特征数据在呈现原始数据的表现上越来越好,即随着训练时间的增多,低维数据能够更好地挖掘出原始数据所包含的信息。
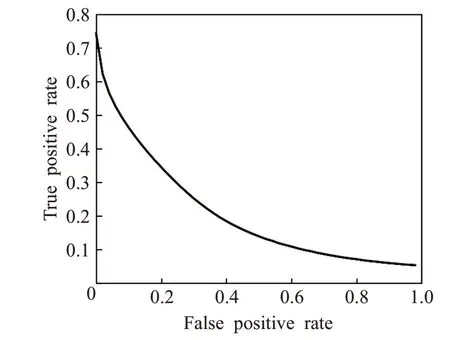
图2 重构数据与原始数据之间的均方误差Fig.2 MSE between reconstructed data and original data
在与其他算法对比性能的表现时,本文考虑卷积神经网络与三支决策两个方面的性能表现,主要进行以下4 个实验:实验1 在保证同样使用三支决策进行分类的同时,对比卷积神经网络与不同的特征提取方法在特征提取方面的表现。实验2 在保证使用同样的卷积神经网络进行特征提取的前提下,对比基于三支决策理论进行分类的表现与基于二支决策进行分类的表现。实验3主要对比本文所提算法与其他研究人员在入侵检测领域所进行的算法研究之间的表现。实验4是在实验3的基础上,将NSL-KDD 数据集替换成CIC-IDS2017 数据集,在保持实验环境不变的情况下,比较本文算法与其他入侵检测算法的效果。
参数设置:
本文选择主成分分析(principal component analysis,PCA)[17]、深度神经网络(deep neural network,DNN)[18]和因子分析(factor analysis,FA)作为CNN 的比较方法。设置PCA的超参数为:最大数迭代次数1 000,最大允许误差le−4,线性函数logcosh,成分数量为30;设置DNN 的超参数为:激活函数使用ReLU,使用L2 正则化,最大迭代次数为2 000,学习率为le−3;设置FA的超参数为:最大数迭代次数1 000,最大允许误差le−2,幂方法的迭代次数3,成分数量为35;设置CNN 的超参数为:使用2个卷积层和2个池化层堆叠,卷积核大小设置为3×3、2×2,采用平均池化方法,使用ReLU函数为激活函数,使用L2 正则化方法,最大迭代次数为2 000,学习率为le−3。
实验1 本文选择主成分分析(PCA)、深度神经网络(DNN)和因子分析FA 验证三支决策分类算法下CNN特征提取的可取性。在NSL-KDD 数据集上进行实验,不同的结果如表7所示。
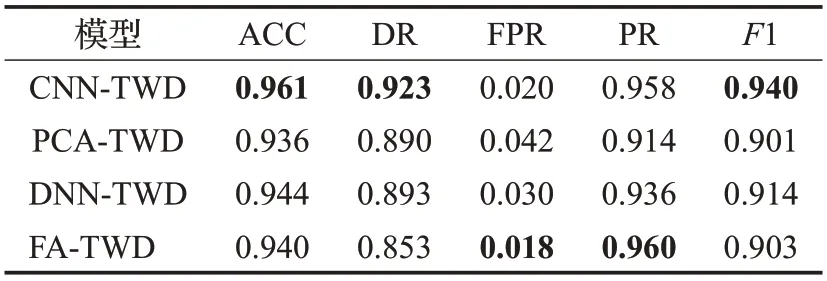
表7 不同特征提取模型的实验结果对比Table 7 Comparison of experimental results of different feature extraction models
从表7 的结果可以看出,本文所提算法CNN-TWD具有更高的准确率(ACC)、检出率(DR)、F1评分,综合性能明显优于其他方法。结果表明,通过CNN 得到的低维特征数据对原始数据的映射效果较好。
如图3是不同方法的ROC曲线对比图,ROC曲线也被称为感受性曲线,是检验准确度的综合代表,曲线面积可用于评价诊断准确性。由图可知,CNN-TWD模型的AUC面积最大,证明CNN-TWD模型的综合表现更好。
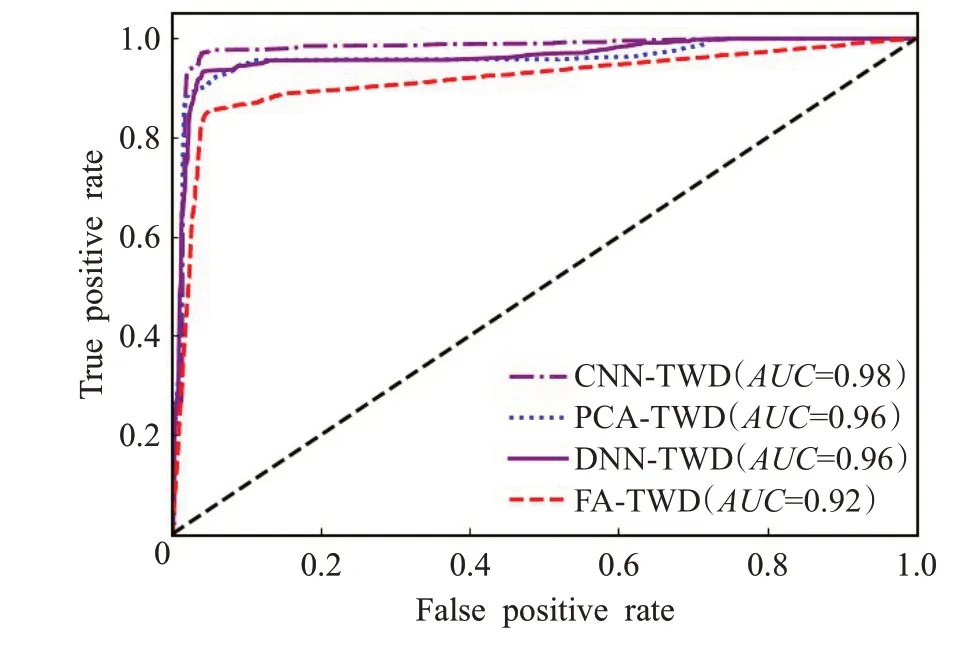
图3 不同特征提取方法的ROC曲线对比图Fig.3 ROC curve comparison of different feature extraction methods
实验2 本文选择支持向量机(SVM)、k-近邻(KNN)、随机森林(RF)和贝叶斯模型(BYS)作为基于三支决策的分类方法的对比模型,此时CNN 是用于特征提取的方法。在数据集上进行实验,不同结果如表8所示。
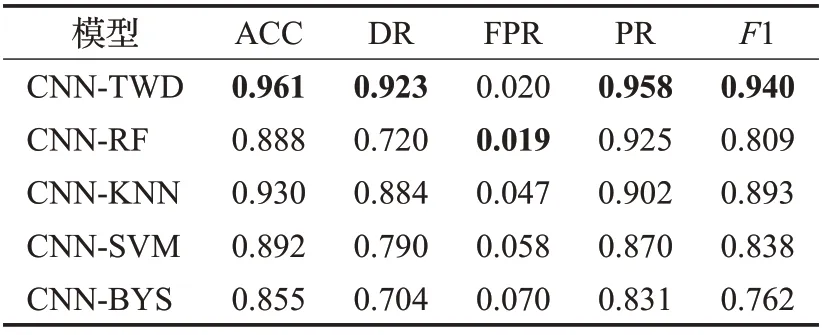
表8 不同分类模型的实验结果对比Table 8 Comparison of experimental results of different classification models
从表8 中的结果可以看出,基于TWD 的分类模型在准确率(ACC)、检出率(DR)、精度(PR)、F1分数(F1)4个指标上要优于其他的分类模型得到的结果,尤其是准确率和检出率明显高于其他几种对比模型,这表明通过本文提出的基于三支决策的分类算法在综合性能上优于其他分类算法。在引入边界域后,避免了一些不确定数据被误分类的风险,大大提高了入侵检测的准确性,把三支决策理论应用在入侵检测上产生了积极的影响,优于传统的基于二支决策的方法。
如图4 是不同方法的ROC 曲线对比图,由图可知,CNN-TWD 模型的AUC 面积最大,证明CNN-TWD 模型的综合表现更好。
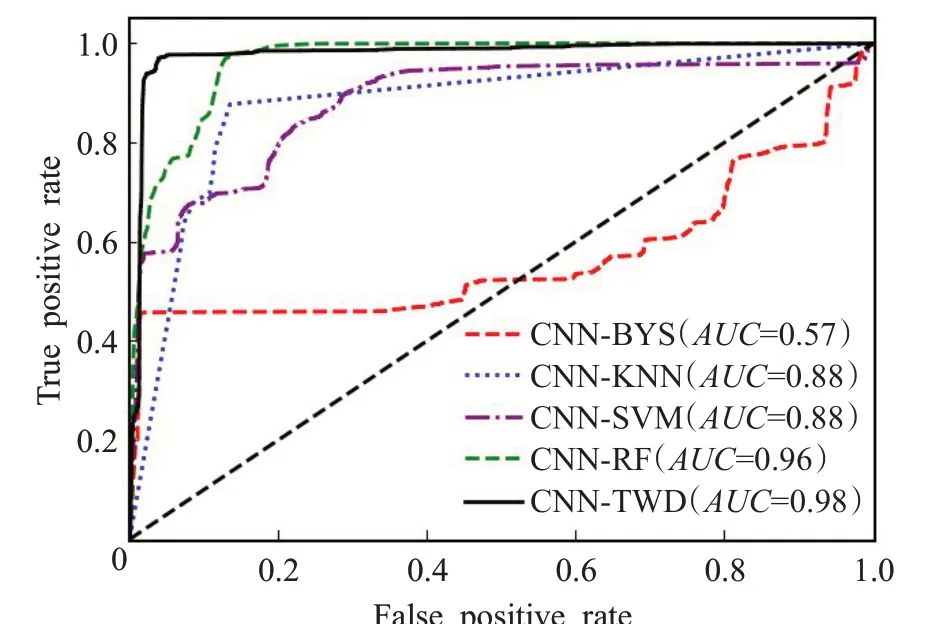
图4 不同分类方法的ROC曲线对比图Fig.4 ROC curve comparison of different classification methods
实验3 本次实验选择的对比模型包括一个基于LDA 和极限学习机的入侵检测模型(LDA-ELM)[19],一个基于半监督学习的入侵检测模型(SSL)[20],一种基于层叠非对称深度自编码器的入侵检测方法(SNADE)[21]和一个基于时空特征的分层入侵检测系统(HAST-IDS)[22]。选取NSL-KDD 数据集作为实验数据集,表9 给出了在保持实验环境不变的情况下,本文算法与其他算法的入侵检测对比结果。从表9 中的结果可以看出,基于CNN-TWD 的入侵检测模型在准确率(ACC)、检出率(DR)、误报率(FPR)、F1 分数(F1)4 个指标上要优于其他的特征提取算法得到的结果,但是在精度(PR)上表现略低于SSL算法。综上表明,通过本文提出的基于三支决策的分类算法在综合性能上优于其他入侵对比算法。

表9 不同算法的实验结果对比Table 9 Comparison of experimental results of different algorithms
如图5是不同算法的ROC曲线对比图。由图可知,CNN-TWD 算法的AUC 面积最大,证明CNN-TWD 算法的综合表现更好。

图5 不同算法的ROC曲线对比图Fig.5 ROC curve comparison of different algorithms
从ROC曲线图上可以看出CNN-TWD算法得到的曲线相对于其他算法得到的曲线更接近左上角,且CNN-TWD 得到的AUC 面积要大于其他算法得到的AUC面积。以上结果表明本文所提算法的表现要略优于本文所引用的另外4篇文献提出的算法。
实验4 实验4 是在实验3 的基础上,将NSL-KDD数据集替换成CIC-IDS2017数据集,表10给出了在保持实验环境不变的情况下,本文算法与其他算法的入侵检测对比结果。
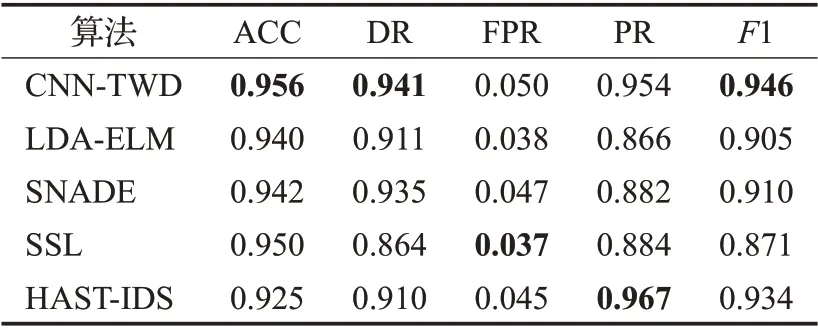
表10 不同算法的实验结果对比Table 10 Comparison of experimental results of different algorithms
从表10 结果可以看出,基于CNN-TWD 的入侵检测算法模型在准确率(ACC)、检出率(DR)、精度(PR)、F1 分数指标上要优于其他的特征提取算法得到的结果,尤其是在指标F1分数上比其他最好结果要高出1.2个百分点,综上表明,在综合性能上,本文提出的入侵检测模型要优于其他对比模型
如图6是不同算法的ROC曲线对比图。由图可知,CNN-TWD 算法的AUC 面积最大,证明CNN-TWD 算法的综合表现更好。
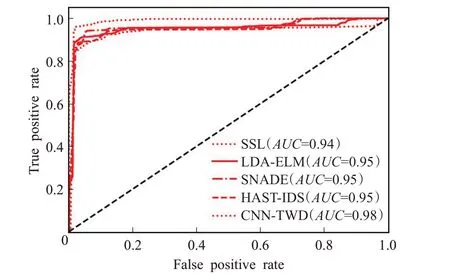
图6 不同算法的ROC曲线对比图Fig.6 ROC curve comparison of different algorithms
实验4 表明本文提出模型在含有新型攻击类型的入侵检测数据集中仍然具有一定的优越性,说明本文提出模型具有适用性。
4 结论
本文提出了一种基于卷积神经网络和三支决策的入侵检测方法,使用卷积神经网络从样本中提取特征,构建多粒度特征空间,利用三支决策理论,对网络行为进行分类。在NSL-KDD、CIC-IDS2017 数据集上的结果表明,本文提出的算法模型具有更好特征提取能力和更精确的分类能力。后续工作,将在更多数据集中检验模型的适用性,并对CNN的网络结构进一步改进,从而优化特征提取能力;同时,一个更有效的三支决策损失函数、阈值的确定方法也是未来模型改进的重点。
猜你喜欢
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
电子制作(2018年19期)2018-11-14
