
面向嵌入式平台的安全帽实时检测方法
2022-05-15 06:35农元君王俊杰徐晓东赵雪冰
计算机工程与应用 2022年9期
农元君,王俊杰,徐晓东,赵雪冰
中国海洋大学 工程学院,山东 青岛266100
建筑业因劳动密集及施工作业环境复杂导致安全事故多发。据住房和城乡建设部统计,2019年全国共发生房屋市政工程生产安全事故773起、死亡904人,给社会和家庭带来了巨大的损失[1]。安全帽作为保障现场作业人员生命安全的基本装置,很大程度上能减轻安全事故对作业人员的伤害。但由于施工现场安全管理疏忽、佩戴安全帽引起不适以及施工作业人员安全防护意识薄弱等原因,一些因未佩戴安全帽而引发的工程安全事故频发。因此,实现建筑施工现场工人的安全帽佩戴识别和检测具有重要的现实意义。
传统的安全帽检测方法主要包括施工管理人员现场巡检以及查看监控视频等,存在耗时费力、人工成本高、容易出现漏检等缺陷。随着计算机视觉技术的快速发展,目标检测技术掀起新的研究热潮,为安全帽的智能化检测提供了新的研究视角。目前,应用广泛的目标检测方法主要分为两类:一类是以Fast R-CNN[2]和Faster R-CNN[3]等为代表的基于区域建议的目标检测算法;另一类是以SSD[4]和YOLO[5-7]等为代表的基于回归的目标检测算法。前者检测精度高但速度慢,难以实现实时检测,后者检测速度快但精度较低。目前已有学者将目标检测技术应用到安全帽的佩戴检测中。方明[8]、林俊[9]、施辉[10]、王兵[11]采用基于YOLO的方法对安全帽进行自动识别和检测;Wu[12]采用基于SSD 的方法对施工现场工人的安全帽佩戴进行检测;张明媛[13]、徐守坤[14]采用基于Faster R-CNN的方法自动识别和检测安全帽。
尽管采用目标检测方法可实现对安全帽的自动检测,且准确率较高,但已有研究均采用GPU工作站作为实验平台,缺乏在嵌入端对安全帽进行检测的考虑。相比而言,基于嵌入端的安全帽检测方法将原有在服务器端的检测任务迁移到数据源附近,具有实时数据处理、低延迟、部署成本低、可扩展性强等优势,可实现对工人安全帽佩戴的快速检测。
基于此,本文提出一种适用于嵌入式平台的轻量化安全帽实时检测方法MT-YOLO。该方法通过优化网络结构、引入空间金字塔池化模块、改进初始化锚框对Tiny-YOLOv3[7]进行改进优化。实验结果表明,所提方法具有较高的检测精度,同时在嵌入式平台NVIDIA Jetson Nano 上可达到实时的检测速度,满足了在嵌入端对安全帽佩戴进行实时高精度检测的需求。
1 Tiny-YOLOv3算法
Tiny-YOLOv3 作为YOLOv3[7]的轻量化版本,是一种端到端的基于回归的目标检测方法。如图1 所示,Tiny-YOLOv3 将目标识别作为回归问题进行求解,直接在整幅图上回归得到目标边框的位置和类别,提高了识别的速度。Tiny-YOLOv3 网络结构如图2 所示。以416×416 尺寸的输入图像为例,Tiny-YOLOv3 采用由7层卷积层和6 层池化层组成的特征提取网络对输入图像进行特征提取,特征提取完成后借鉴特征金字塔网络[15]的思想,在13×13和26×26两个尺度上进行检测。
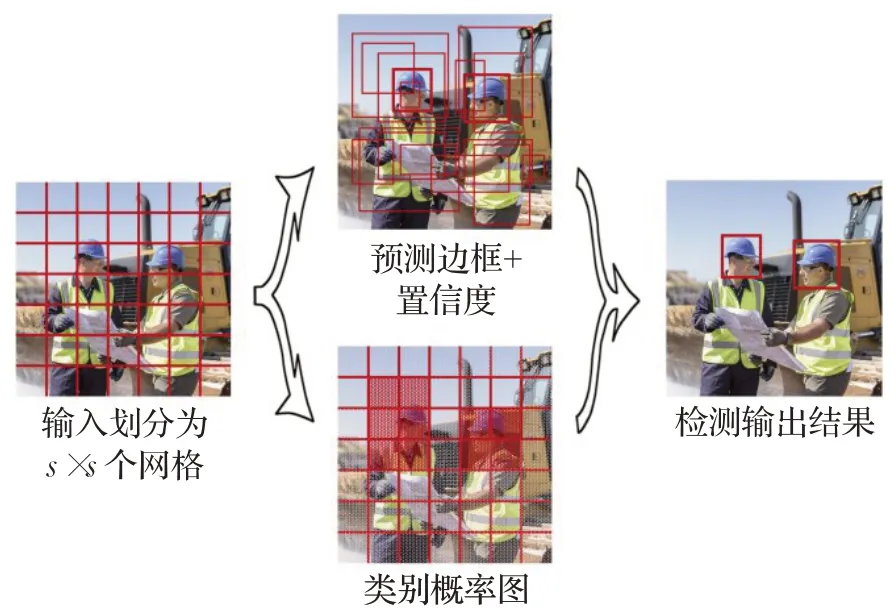
图1 Tiny-YOLOv3检测原理Fig.1 Detection principle of Tiny-YOLOv3
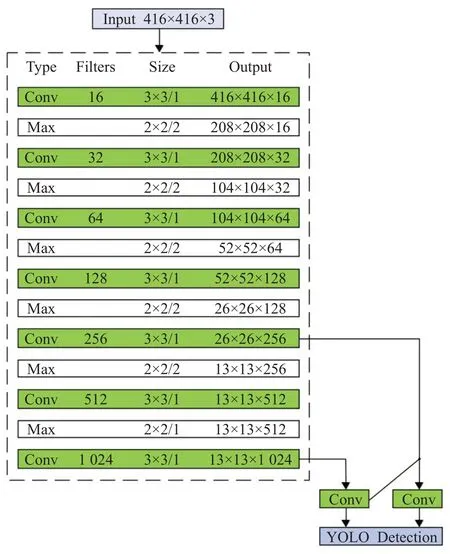
图2 Tiny-YOLOv3的网络结构Fig.2 Tiny-YOLOv3 network structure
2 改进Tiny-YOLOv3
Tiny-YOLOv3因结构轻巧及计算量小等特点,可在嵌入式设备上实现实时检测,但对安全帽的检测精度较低,无法满足实际需求。基于上述考虑,对Tiny-YOLOv3进行如下优化:(1)通过改进特征提取网络和多尺度预测优化网络结构;(2)引入空间金字塔池化模块;(3)采用K-means聚类算法改进初始化锚框;(4)引入CIoU边界框回归损失函数。
2.1 优化网络结构
Tiny-YOLOv3 的特征提取网络采用最大池化操作对特征图进行下采样以降低特征图的大小。最大池化操作在一定程度上可提高网络的泛化能力,但只保留池化窗口中安全帽特征信息的最大值,会造成部分语义特征信息的丢失,进而影响模型检测性能。施工现场背景环境复杂,会对安全帽检测产生干扰,因此安全帽的特征信息对网络模型的训练学习至关重要。相较于最大池化操作,卷积操作对卷积窗口中的安全帽信息进行相乘求和,考虑了卷积窗口中所有的安全帽信息,可降低安全帽特征信息的丢失。因此,将步长为2的最大池化层替换为步长为2的卷积层对特征图进行下采样,提高网络的特征提取能力。
Tiny-YOLOv3特征提取网络中卷积核数量为1 024的第13层卷积层在416×416的输入尺寸下消耗15.95亿次浮点运算,对计算资源有限的嵌入式平台来说过于冗余,不利于网络对安全帽的实时检测。因此,移除特征提取网络中第13 层卷积层以及第12 层最大池化层,降低Tiny-YOLOv3 的冗余度,提高其在嵌入式设备上的检测速度。同时将第11 层的卷积核数量从512 减少到256以进一步精简网络。
Tiny-YOLOv3对输入图像进行特征提取后,在13×13、26×26 两个尺度的特征图上进行预测,未能充分利用浅层的特征信息。如图3 所示,与26×26 尺度的深层特征相比,52×52尺度的浅层特征包含丰富的安全帽细节信息和位置信息,对目标定位较准确,同时浅层特征感受野包含的背景噪声小,对安全帽小目标有更好的表征能力。在建筑施工现场安全帽检测任务中,因检测距离的远近会产生大小不同的安全帽目标,存在小目标。为了提高Tiny-YOLOv3 对安全帽小目标的检测效果,优化多尺度预测结构,增加一个52×52 的预测尺度,在13×13、26×26、52×52三个尺度的特征图上进行预测。

图3 浅层特征与深层特征Fig.3 Shallow features and deep features
2.2 引入空间金字塔池化模块
在施工现场的安全帽检测中,因检测距离的不同存在大中小不同尺度的安全帽目标,导致输入网络的安全帽特征信息尺度不一致。为了解决该问题,引入空间金字塔池化[16](spatial pyramid pooling,SPP)模块。该模块借鉴了空间金字塔的思想,通过池化操作将局部特征映射到不同维度空间并将其进行融合,丰富特征图的多尺度信息。如图4 所示,13×13×256 的安全帽特征图输入SPP模块后,在5×5、9×9、13×13三个大中小不同尺度的池化层上进行池化操作,生成三个13×13×256的局部特征图,最后将生成的三个局部特征图与原始输入的特征图利用通道融合在一起,得到13×13×1 024的特征图,丰富了安全帽特征图的多尺度信息。引入SPP 模块可将大中小不同尺度的安全帽特征进行融合,有助于消除因不同大小目标造成特征信息尺度不一致的影响,提高检测准确率。
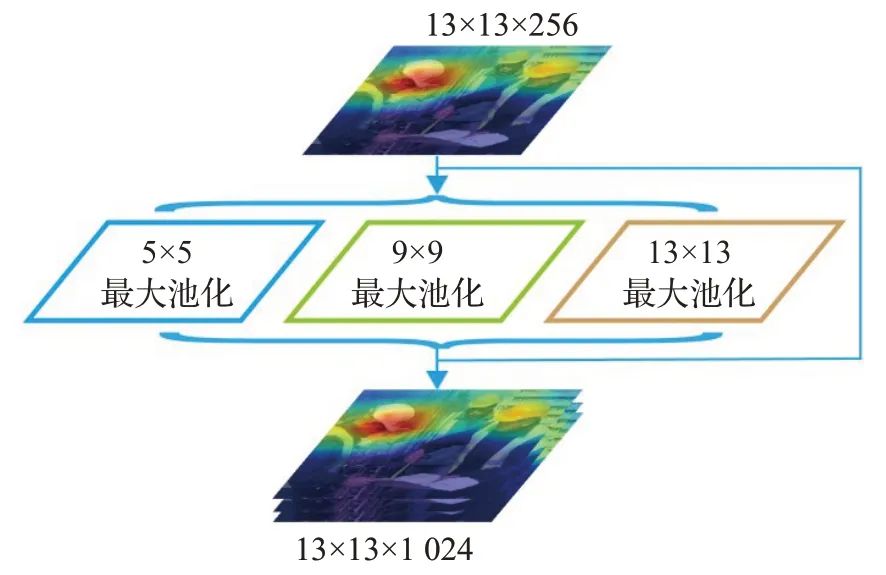
图4 空间金字塔池化模块Fig.4 Spatial pyramid pooling module
将改进后的模型命名为MT-YOLO,其结构如图5 所示。与Tiny-YOLOv3 相较,MT-YOLO 优化了网络结构,并引入了空间金字塔池化模块。
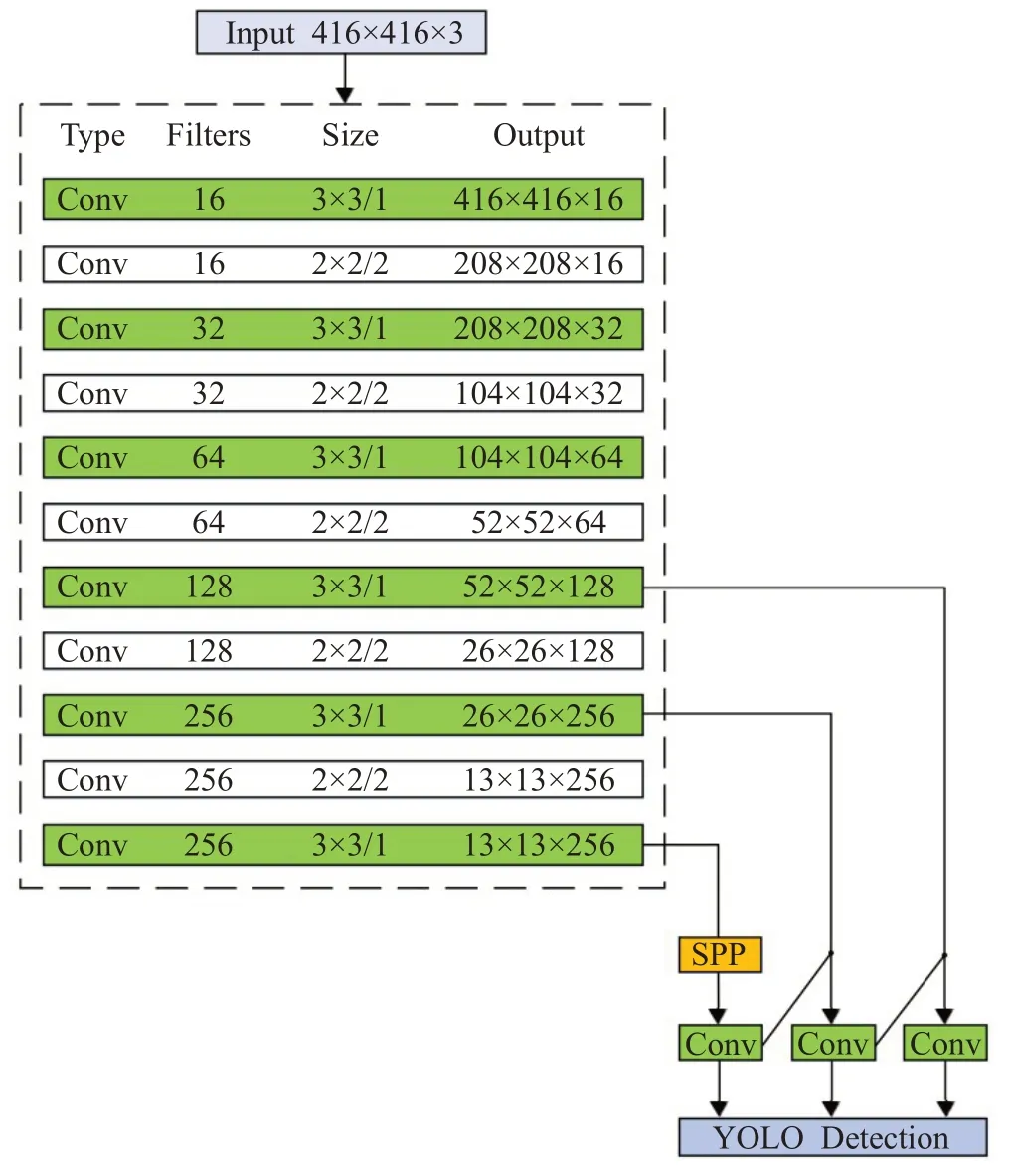
图5 MT-YOLO的网络结构Fig.5 MT-YOLO network structure
2.3 改进初始化锚框
Tiny-YOLOv3 的初始化锚框由K-means 聚类算法在公共数据集上聚类生成,用于预测边界框的坐标。由于公共数据集基于自然场景采集,目标类别丰富,所生成的锚框具有普遍性,不适合本文的安全帽检测场景,使用原始锚框将难以得到准确的目标框信息。因此,需要采用K-means聚类算法在安全帽数据集上重新聚类,确定适合安全帽检测场景的锚框。Tiny-YOLOv3 采用6 个锚框并按面积从小到大均分到2 个尺度的特征图上,由于提出的MT-YOLO 增加了一个预测尺度,在三个尺度上进行预测,因此将框数量增加至9 个,采用K-means聚类算法在安全帽数据集上进行维度重聚类,目标框聚类及锚框分布如图6 所示,得到的9 个锚框分别为(5,9)、(11,19)、(17,30)、(24,44)、(34,60)、(46,85)、(70,111)、(90,167)、(149,245),将其面积按从小到大排列均分到52×52、26×26、13×13 三个不同尺度的特征图上。

图6 目标框聚类及锚框分布图Fig.6 Target clustering and anchor distribution
2.4 引入CIoU边界框回归损失函数
IoU(intersection over union)是目标检测中重要的一个指标,其通过计算真实框和预测框之间的交并比来衡量边界框的优劣。IoU的计算式如式(1)所示:

式中,A为目标的预测框,B为目标的真实框。
Tiny-YOLOv3 采用IoU 作为损失函数,如式(2)所示。该损失函数具有尺度不变性的优点,但存在一个缺陷:当检测框与真实框没有重合部分时,梯度不存在,无法进行梯度下降优化。

为了弥补IoU损失函数存在的不足,本文采用CIoU边界框回归损失函数[17],如式(3)所示。该损失函数考虑了检测框的重叠面积以及检测框中心点的距离,有效解决了当检测框与真实框没有重合部分时所导致的IoU损失函数为零的问题,同时还增加检测框和真实框的长宽比相似性的衡量参数,使模型更倾向于往重叠区域密集的方向优化。
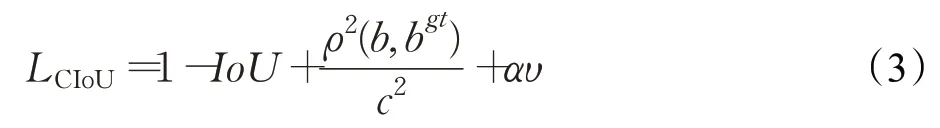
式中,b、bgt分别表示预测框和真实框的中心点,ρ表示预测框和真实框两个中心点之间的欧式距离,c表示能够同时包含预测框和真实框的最小闭包区域的对角线距离,υ为衡量检测框和真实框的长宽比相似性的参数,α为权重参数。
3 实验
3.1 实验数据集
在公开的安全帽数据集GDUT-HWD[12]上对提出的方法进行验证。该数据集涵盖了不同背景条件、不同光照条件以及存在遮挡的图像数据,共有3 174张图像和5个类别目标,其中1 587张图像用作训练集,剩余的1 587张图像用作测试集。5类目标分别是佩戴红色、黄色、白色、蓝色安全帽的目标,以及未佩戴安全帽的目标,对应的类别标签为red、yellow、white、blue和none。
3.2 实验平台及配置
目标检测方法的训练和验证对硬件环境要求较高,因此选择在GPU 型号为GeForce RTX 2060 并采用CUDA10.1、CUDNN7.6 加速的工作站上对提出的模型进行训练和验证,再将训练完的模型移植到GPU型号为ARMv8 Processor rev1 并采用CUDA10.2、CUDNN8.0加速的嵌入式平台NVIDIA Jetson Nano 上进行部署。实验基于Darknet 深度学习框架进行,训练时批处理大小设置为64,分组设置16,动量设置0.9,权重衰减设置0.000 5,初始学习率设置10-3,同时引入Mixup[18]数据增强方法以提高模型的泛化性能。
3.3 评价指标
为了定量评价实验结果,采用平均准确率均值(mean average precision,mAP)、召回率(recall)、F1 值作为衡量模型精度的指标,计算公式如式(5)、式(6)、式(8)所示。同时还采用模型体积(volume)、浮点运算量(billion float operations,BFLOPs)和每秒帧率(frame per second,FPS)作为衡量模型大小、计算量、及运行速度的指标。模型性能检测及评价在416×416、512×512、608×608三个不同的输入尺寸下进行。

式中,TP表示真正例,FN表示伪负例,FP表示伪正例,n表示类别总数。
3.4 训练过程可视化
采用安全帽训练集对提出的模型进行训练,训练过程的损失变化如图7所示。网络前5 000次迭代期间的损失值较大,随着迭代次数的增加损失值不断减小,当迭代到15 000 次后损失值基本稳定在0.5 左右,表示模型收敛。
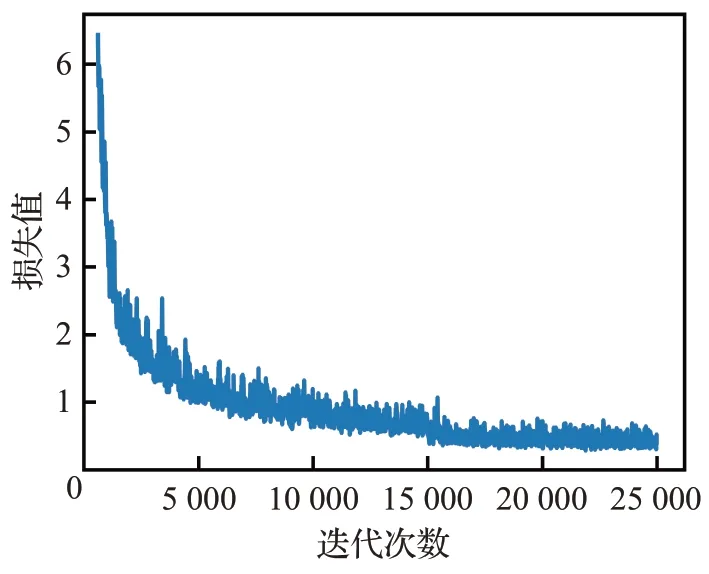
图7 训练过程损失曲线Fig.7 Loss curve in training process
4 实验结果
4.1 测试结果
表1对比了所提出的MT-YOLO与其他方法的检测性能。由表1 可知,MT-YOLO 在精度、计算量、模型体积上具有较大优势。在检测精度方面,MT-YOLO 在608×608的输入尺寸下实现了87.50%的mAP、84%的召回率、83%的F1值,较Tiny-YOLOv3相关指标分别高出11.27、11和7个百分点,与高精度版本YOLOv3相接近。尤为重要的是相较于Tiny-YOLOv3,提出的MT-YOLO方法在较低的输入尺寸416×416 下仍能保持较高的检测精度,表明其具有较强的鲁棒性。在计算量和模型体积方面,MT-YOLO 方法的计算量和体积均小于Tiny-YOLOv3和YOLOv3方法,有利于缓解嵌入式设备的计算压力,释放存储空间。实验结果表明,相较于Tiny-YOLOv3,所提方法在减少计算量和模型体积的同时,有效提高了安全帽检测精度。
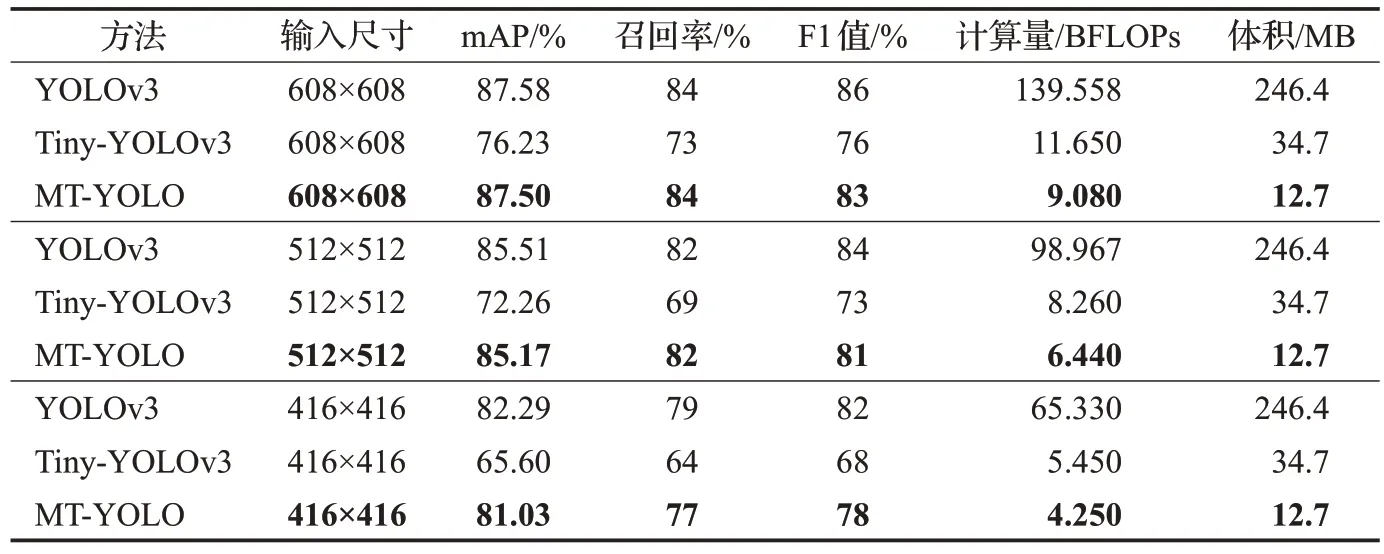
表1 不同模型的检测性能Table 1 Detection results of different models
图8为不同模型在五个类别目标上的PR(precisonrecall)曲线,曲线下的面积即为相应模型在该类目标下实现的平均准确率(average precision,AP)。从图8可看出,所提出的MT-YOLO在五个类别目标上的平均准确率均高于Tiny-YOLOv3,与高精度版本YOLOv3相接近。
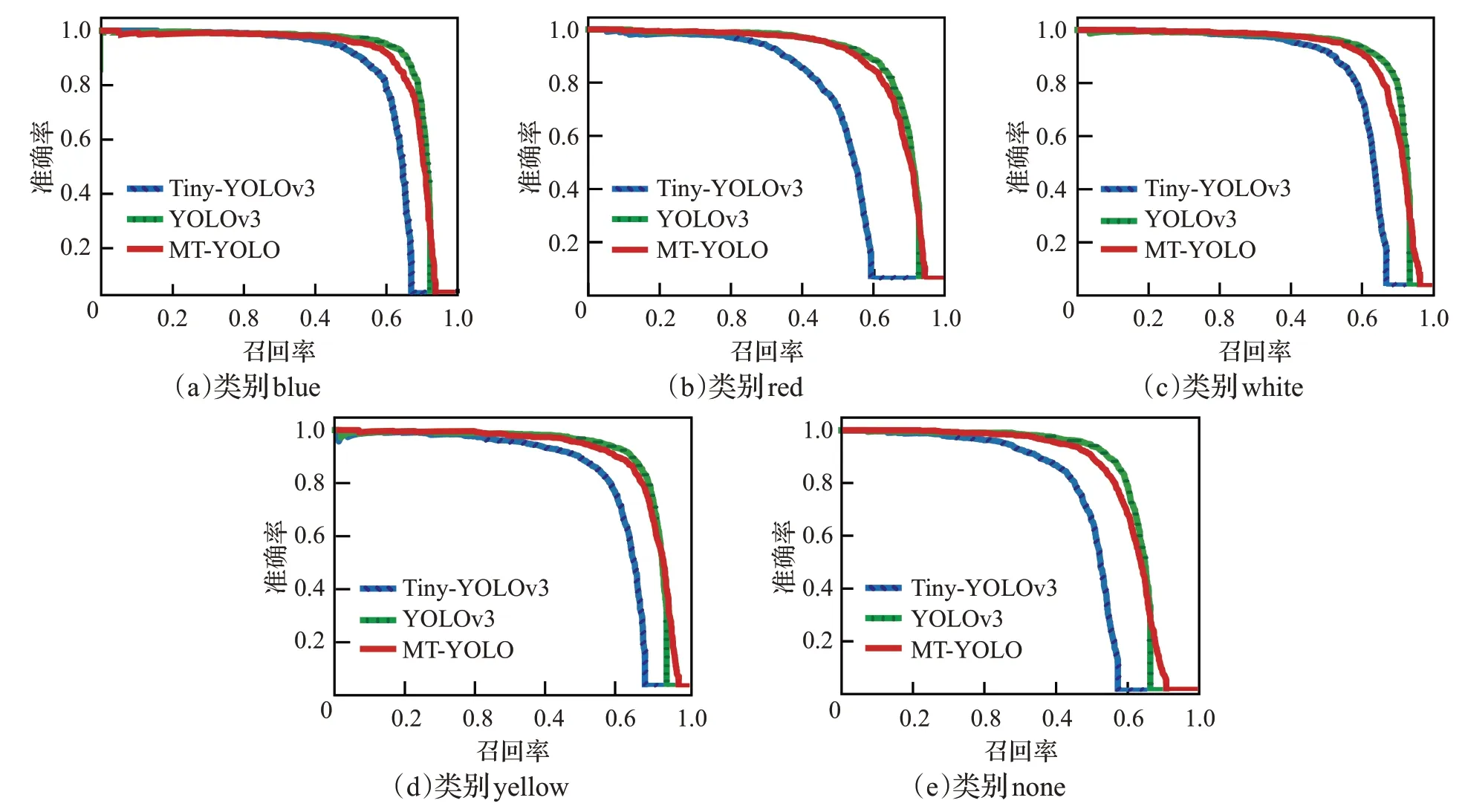
图8 不同模型在五个类别目标上的PR曲线Fig.8 PR curves of different models on five categories of targets
4.2 检测结果可视化
图9展示了所提出的MT-YOLO在安全帽测试集中不同环境场景下的检测结果。由图9可知,在检测角度不佳、目标存在遮挡、目标密集、小目标等复杂环境场景下,MT-YOLO具有良好的检测性能,均精准地检测出工人是否佩戴安全帽。

图9 MT-YOLO在不同环境场景下的检测结果可视化Fig.9 Detection results visualization of MT-YOLO under different environments
4.3 泛化性检验实验
为了进一步检验所提出模型的泛化性,除了在公开的安全帽测试集上检验MT-YOLO的效果之外,还运用从施工现场收集的图像数据直接检验模型的检测效果。图10展示了不同模型在光线不佳、小目标、目标密集等实际施工现场环境下的检测效果。由图10 可见,Tiny-YOLOv3 存在较多的漏检(图中相应实线椭圆处)和误检现象(图中相应虚线椭圆处),YOLOv3在密集目标场景中也存在漏检现象,但MT-YOLO依然保持了良好的检测性能,均精准地检测出了安全帽目标,表明该方法具有良好的泛化性。
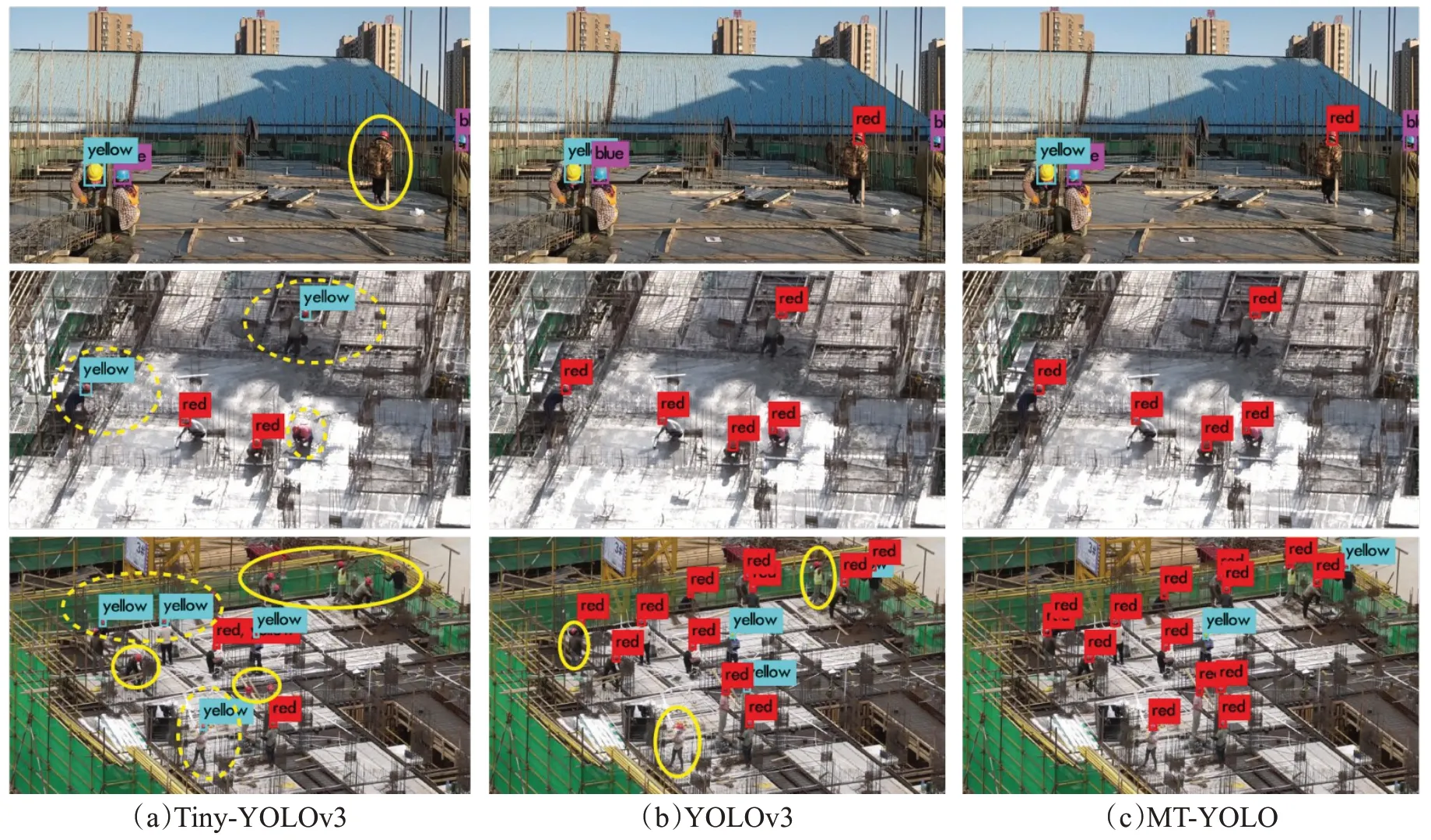
图10 MT-YOLO与其他模型的泛化性检测结果Fig.10 Generalization test results of MT-YOLO and other models
4.4 嵌入式平台实验
如图11所示,为检验提出的模型在嵌入式平台上的检测速度,将训练好的模型加载到TensorRT加速引擎中进行加速推理后,部署到嵌入式平台NVIDIA Jetson Nano上,并与其他模型的检测速度相比较,结果如表2所示。

图11 在嵌入式平台Jetson Nano上进行实验Fig.11 Experiment on embedded platform of Jetson Nano
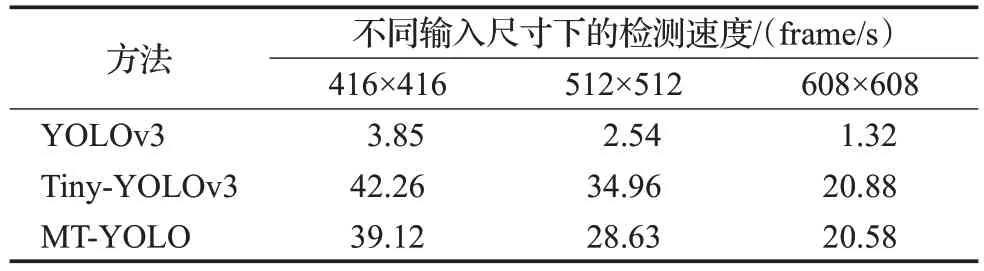
表2 不同方法在Jetson Nano上的检测速度Table 2 Detection speed of different models on Jetson Nano
由表2 可知,受嵌入式平台计算能力的限制,检测精度较高的YOLOv3 在Jetson Nano 上只达到了最高3.85 frame/s的检测速度,无法实现实时检测。而提出的MT-YOLO在三种输入尺寸下分别实现了20.58、28.63、39.12 frame/s 的实时检测速度,可满足在嵌入端对安全帽进行实时检测的需求。为了提高检测精度,本文对原始的Tiny-YOLOv3网络结构进行了优化并引入空间金字塔池化模块,增加了模型的复杂度,使得MT-YOLO的检测速度稍逊色于Tiny-YOLOv3,但依然满足安全帽实时检测的需求。实验结果表明,本文提出的MT-YOLO在嵌入端满足实时检测的情况下,检测精度较Tiny-YOLOv3有较大幅度的提升,更适合在嵌入端进行安全帽检测。
5 结论
为了实现在嵌入端对工人佩戴安全帽进行检测,以Tiny-YOLOv3 检测方法为基础,通过优化原始网络结构、引入空间金字塔池化、维度重聚类确定适合安全帽检测的锚框、引入CIoU边界框回归损失函数,提出一种适用于嵌入式平台的轻量化安全帽检测方法。实验结果表明,所提方法检测精度高、计算量少、模型体积小、实时性好、泛化性和鲁棒性强,在608×608 的输入尺寸下,平均准确率均值和召回率分别达到了87.50%和84%,较Tiny-YOLOv3 提升了11.27 和11 个百分点,计算量和模型体积较Tiny-YOLOv3 方法减少了22.06和63.40个百分点,且在嵌入式平台NVIDIA Jetson Nano上可达到20.58 frame/s的实时检测速度,随着输入尺寸的减小,其在嵌入式平台上的检测速度可以进一步提升。本文提出的方法在精度上稍逊色于Tiny-YOLOv3方法的高精度版本YOLOv3,下一步将引入注意力等机制,在保持实时检测速度的情况下进一步提升模型的检测精度。
猜你喜欢
计算机与生活(2022年11期)2022-11-15
计算机应用(2022年9期)2022-09-25
机电安全(2022年4期)2022-08-27
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
软件导刊(2022年3期)2022-03-25
计算机系统应用(2020年3期)2020-03-18
课外生活·趣知识(2019年4期)2019-09-10
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
