
基于SSD算法的轻量化仪器表盘检测算法*
2022-08-20 01:39:22张建伟周亚同史宝军
计算机工程与科学 2022年8期
张建伟,周亚同,史宝军,何 昊,王 文
(1.河北工业大学电子信息工程学院,天津 300401;2.河北工业大学机械工程学院,天津 300401)
1 引言
目前,数字仪器表被广泛地应用在各行各业的测量系统中。但是,由于某些仪器表只是通过LED数码管显示数值,没有提供数据传输接口,很难实现数据的自动采集以及保证数据的实时性和准确性。随着科学技术的不断进步,测量系统的数据读取由人工监管方式逐渐向自动管理方式转变。
传统的字符识别方法[1 - 3]一般首先采取图像预处理技术,如去噪、增强和矫正倾斜等,提升图像质量,减少噪声对后续识别的影响;然后采用图像分割技术,如颜色聚类、二值化等,提取出目标前景;再采用先验知识对字符进行分割,如基于轮廓的分割方法[4]和基于细化的分割方法[5,6]等,将单个字符从采集图像中分离出来,减少粘连性,便于后续识别;最后采用模式匹配[7]、支持向量机SVM(Support Vector Machine)[8]等分类方法对单个字符进行识别。基于深度学习的字符识别方法首先利用目标检测技术提取出目标前景,然后使用光学字符识别技术对文本区域进行识别。相比于传统方法,基于深度学习的方法处理流程简单,检测效率高,泛化性强,更能满足自动化作业的需求。图1是字符识别方法流程图,其中,图1a是传统方法,图1b是基于深度学习的方法。
近年来,随着AlexNet[9]在2012年的Image- Net图像分类比赛中的成功,深度学习技术便引发了广泛关注,尤其是卷积神经网络CNN(Convolutional Neural Network)凭借其强大的非线性处理能力和共享参数的优势,在目标检测领域得到了广泛的应用。Girshick等人[10]率先将CNN用于目标检测,提出了R-CNN算法,提供了二阶段检测算法的示例,使用选择性搜索SS(Selective Search)[11]算法生成稀疏的候选目标区域,利用深度卷积网络对其进行特征提取,然后将特征送到SVM分类器中,完成候选区域中目标的分类。He等人[12]在R-CNN算法基础上提出了SPP-Net,使用空间金字塔池化层SPP(Spatial Pyramid Pooling)替代候选区域的裁剪和逐区域特征提取,提升了检测效率。Fast R-CNN[13]将特征提取,候选区域回归与分类放进统一的卷积神经网络中,完成端到端的训练。Faster R-CNN[14]解决了SS算法生成候选区域耗时长的问题,使用区域提议网络RPN(Region Proposal Network)回归锚框(Anchor Box)生成候选区域,至此,二阶段检测算法步入全卷积网络FCN(Fully Convolutional Network)[15]时代。万吉林等人[16]使用Faster R-CNN算法成功检测到变电站指针式仪表的表盘,为后续的读数识别提供了目标区域。
Howard等人[26]提出的轻量化网络MobileNetv1使用深度可分离卷积(Depthwise Separable Convolution)代替标准卷积,大大提升了计算效率和轻量化性能。MobileNetv2[27]网络提出线性瓶颈模块(Linear Bottleneck Module)和倒残差模块(Inverted Residuals Module),在减少网络运算量的同时提升了特征表达能力。Zhang等人[28]提出了ShuffleNet网络,使用逐点分组卷积(Pointwise Group Convolution)降低逐点卷积(Pointwise Convolution)操作运算量,随后紧跟通道混洗(Channel Shuffle)操作加强组间信息交流。ShuffleNet V2[29]网络使用分支并行操作替代分组卷积,进一步提升了运算效率。
本文工作主要包括以下2个方面:
(1)提出了一种基于真实框分布构建锚框的流程,设计能量化表达锚框匹配程度的指标——匹配率,促进构建更匹配且锚框数量更少的锚框方案,在减少内存的同时提升了检测精度。
(2)使用深度可分离卷积替代标准卷积重新构建特征提取网络,大幅减少了网络参数量,加快了检测速度,并提高了检测精度。
2 SSD算法原理
SSD算法是基于前馈卷积神经网络的检测算法,其网络结构分为特征提取网络和回归与分类子网络。SSD算法使用VGG16(Visual Geometry Group with 16 weight layers)[30]作为特征提取网络,在此基础上添加额外的卷积层和池化层等结构,以获得更富有语义信息的特征,然后回归与分类子网络利用提取的特征对锚框进行回归与分类。SSD算法框架如图2所示。Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2作为用于预测的特征图,它们具有不同的分辨率和感受野,其分辨率分别是38*38,19*19,10*10,5*5,3*3和1*1。其中,高分辨率的浅层特征保留了丰富的细节信息,主要用于检测小目标,而低分辨率的深层特征具有语义性较强的抽象信息,主要用于检测中等及大目标。SSD算法生成一组特定数量的预测框和框中存在类别的得分,其数量与检测类别数(Classes)相关,然后进行非极大值抑制NMS(Non-Maximum Suppression)操作,得到最终的检测结果。
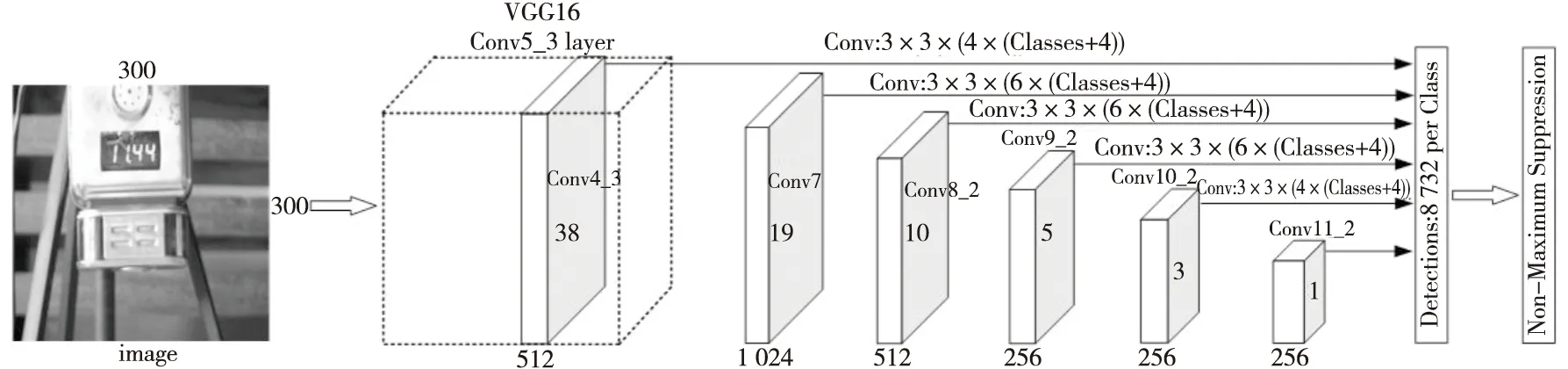
Figure 2 Framework of SSD 图2 SSD算法框架图
锚框是预先设定的一组多长宽比的边界框,规则地排列在特征图组的每一层上,小尺度锚框排列在浅层特征图上,大尺度锚框排列在深层特征图上。在每个特征点上,预测结果为相对于锚框的坐标偏移量和类别得分。
图3为锚框的匹配示例,其中图3a为含有真实框的输入图像,图3b~图3d分别对应Conv7层、Conv8_2层和Conv9_2层特征图匹配示例。在进行预测时,特征图上的每个点都需要产生k个不同长宽比的锚框,3*3的卷积核应用在特征图的每个点上,为每一个锚框生成坐标偏移量和预测p个类别的得分,分别用loc(·)和conf(·)表示。
本研究以鲁迅小说《离婚》的五个英译本为研究素材。《离婚》是鲁迅以现实生活为题材所写的最后一篇小说。它运用对话的形式展开故事情节,介绍人物。这种文学创作形式在当时的文坛是一种创新。也许正是因为其独特的创作手法吸引了译者们对该小说翻译的兴趣。
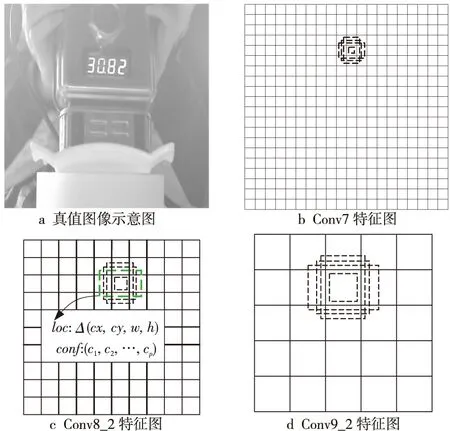
Figure 3 Anchor box for matching of SSD图3 SSD算法锚框匹配示例
SSD算法的损失函数是由定位损失和分类损失的加权和组成,具体计算如式(1)所示:
(1)
式中,Nm为与真实框匹配的锚框个数,Lconf为分类损失函数,Lloc为定位损失函数,α为两者的权重因子,x为输入图像,c为目标类别,l为预测框,g为真实框。
3 轻量化的仪器表盘检测算法
SSD算法是基于锚框驱动的检测算法,通过设计合理的锚框分布以预测真实框。锚框设计具有开放性,需要针对不同的任务场景来制定。本文提出了一种锚框方案的设计流程,并提出能量化表达锚框匹配程度的指标——匹配率,促进构建更匹配且锚框更少的锚框方案。虽然直接回归与分类锚框的做法有着很高的检测效率,但原始特征提取网络VGG16前馈速度慢,参数量大。本文设计新颖的轻量化特征提取网络替代VGG16,提升了特征表达能力,同时减少了时间消耗和参数量,能够在CPU环境下满足实时性需求。
3.1 优化锚框设计
本文提出一种根据真实框分布设计锚框的流程,首先需要分析特定任务场景下真实框的尺度分布,了解待检测目标的形状和大小范围;然后根据真实框分布拟设计锚框方案;最后使用匹配率量化检验该锚框方案是否适合此项检测任务。
图4是真实框的尺度分布,其中图4a和图4b分别是真实框的长宽比和大小的分布统计。仪器表盘中的文本区域长宽比集中在1.0~3.0,大小集中在30~120像素,所以本文将锚框的长宽比设定为1.0,2.0和3.0共3种比例,大小设定为45,75和105共3种尺寸。
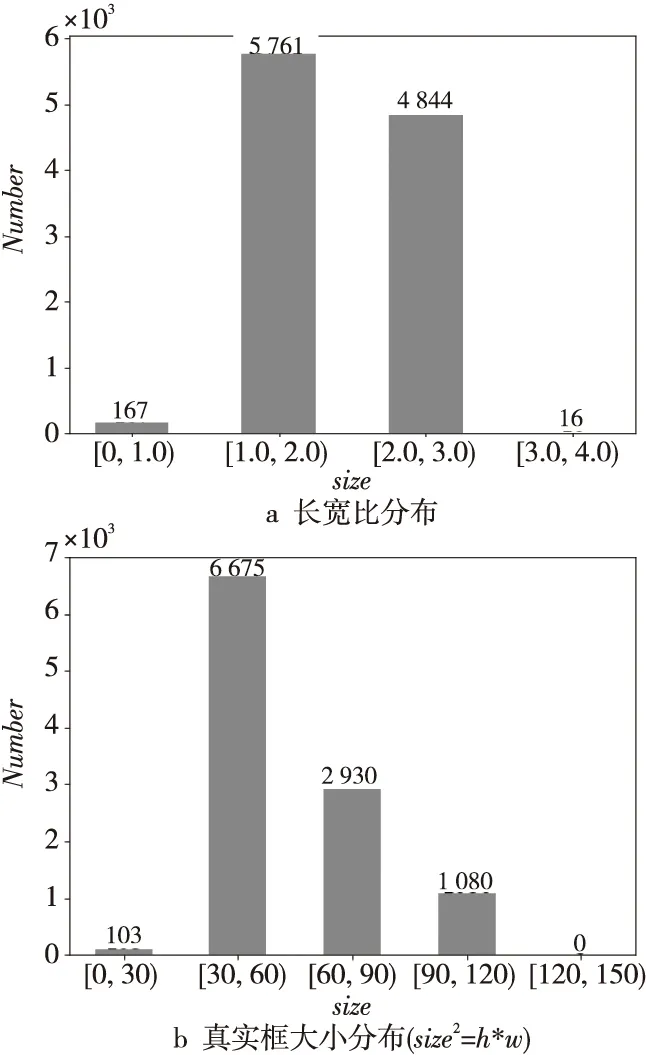
Figure 4 Ground truth box scale distribution(300*300)图4 真实框尺度分布(图像分辨率为300*300)
在锚框分配过程中,SSD算法计算真实框和每一个锚框的交并比IoU(Intersection over Union)。当IoU大于某一阈值时(默认是0.5),该锚框被视为正样本,负责预测该真实框,参与到分类损失和定位损失的计算中。算法是通过正样本来学习前景特征的,所以希望构建合理的锚框分布以匹配每一个真实框。本文设计了一个能量化表达锚框匹配程度的指标——匹配率,首先计算数据样本中,真实框与每一个锚框的交并比,判断该真实框能否匹配高质量的锚框(IoU≥0.5),然后统计被匹配的真实框所占的比例。该指标在一定程度上刻画了锚框分布与真实框分布的相近程度,可量化表达锚框的匹配程度。图5是匹配率计算示例,其中图5a和图5b分别表示真实框被匹配和未被匹配的示例。在图5a中,真实框附近区域存在着与真实框尺度相近的锚框,这些锚框被视为正样本,负责预测该真实框,并参与到分类损失和定位损失的计算中;而图5b中真实框未能匹配高质量的锚框,则会影响算法对前景特征的学习,进而降低了检测性能。
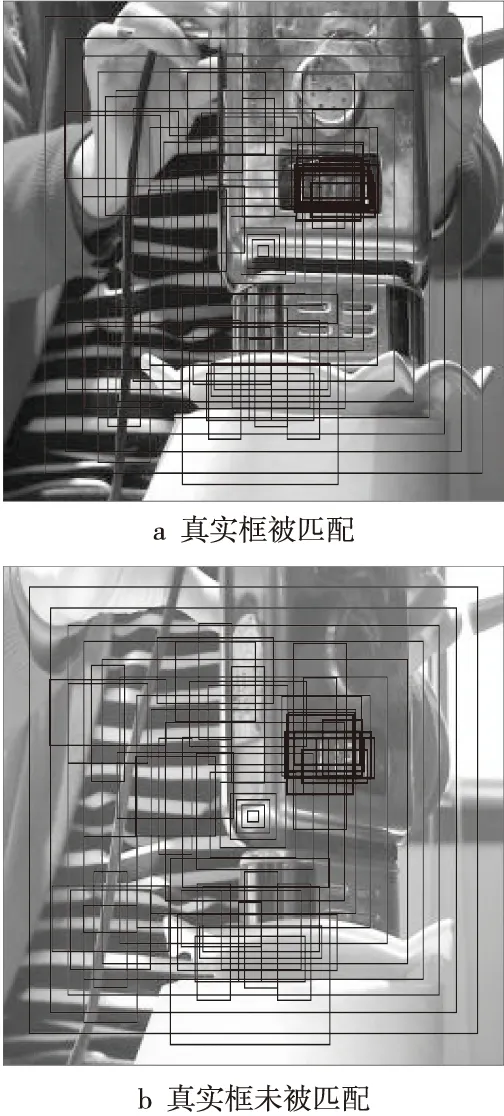
Figure 5 Examples of matching rate calculation图5 匹配率计算示例
3.2 轻量化的特征提取网络

Figure 6 Depth-wise conv module图6 深度可分离卷积模块

Figure 7 Lightweight feature extraction network图7 轻量化特征提取网络
深度可分离卷积有着不逊于普通卷积的特征提取能力,并且计算速度快,参数量少,目前被广泛应用在轻量化网络中。图6是深度可分离卷积的计算示意图。深度可分离卷积首先将输入特征图按照通道数分为m片,对每一片单独进行卷积运算,然后紧跟逐点卷积操作,加强通道间信息交流,其与普通卷积的计算量之比为1/n+1/d2,式中n是输出特征图通道数,d是卷积核大小。本文以深度可分离卷积模块为核心构建了轻量化的特征提取网络,其结构如图7所示。该网络采用类似VGG16的模块化设计,除第2个模块使用4个深度可分离卷积外,其余模块均使用3个深度可分离卷积。在每个模块中,首先使用步幅为2(S2)的深度可分离卷积对特征图进行下采样,同时将通道数加倍,学习更加抽象的语义表达;然后堆叠多个步幅为1(S1)的深度可分离卷积,学习更多的非线性关系。该网络与VGG16相比,结构设计简单,前馈速度快,且参数量远远小于后者,可轻松部署在CPU端实现实时处理。
4 实验与结果分析
4.1 实验数据
本文实验开展在实际工业项目上,实验数据在实际的工作场景中采集得到,采集工作分别在正常光、强光和暗光3种光照条件下进行,并辅以动态采集,从动态视频中抽取单帧图像,获取较大姿态的目标。数据分布如表1所示,共计11 157幅图像,原始图像分辨率为640*480,按照4∶1的比例划分出训练集和测试集。
Table 1 Data distribution表1 实验数据分布
使用标注软件LabelImg对采集的图像进行矩形框区域标注,该软件记录矩形框的左上角坐标和宽高信息,并将标注信息保存为xml文件。标注框范围要紧贴文本区域,范围不能过大,以防留有过多的背景信息,更不能过小,以避免损失文本信息。图8是实验数据集的样本示例,其中图8a~图8c分别对应正常光、强光和暗光3种光照条件下的图像,图8d为标注示例。

Figure 8 Images under different lighting conditions and marked sample图8 不同光照条件下的图像和标注样本
4.2 性能指标
本文研究面向实际应用,除了采用目前广泛使用的目标检测性能评估指标平均预测率AP(Average Precision)[31]和每秒处理帧数FPS(Frames Per Second)外,还增加了2个衡量算法轻量化性能的指标:参数量和浮点运算次数FLOPs。
AP表示预测率p(precision)和召回率r(recall)曲线与横坐标轴围成的曲线面积,其计算如式(2)所示:

(2)
其中,预测率和召回率的定义分别如式(3)和式(4)所示:
(3)
(4)
其中,TP为真正例,FP为假正例,FN为假反例。
FPS表示每秒检测的图像数量,反映了算法的检测速度;参数量表示算法含有的参数数量,反映了算法的空间复杂度,FLOPs为浮点运算量。
4.3 实验步骤
本文实验的硬件环境为Intel(R)Xeon(R)CPU E5-2640 v4@ 2.40 GHz,GPU为一块显存为11 GB的NVIDIA GTX 1080Ti。软件环境为Ubuntu16.04,PyTorch1.5.1,OpenCV4.3.0,CUDA10.2,CUDnn7.6.5。使用随机梯度下降(minibatch-SGD)对网络进行训练,迭代的批次大小为120,初始学习率为7.5e-2,动量因子为0.9,权重衰减系数为5e-4。共训练100个轮次,分别在第50,70和90个轮次衰减0.1倍。
4.4 实验设计与结果对比
锚框分布除了锚框尺度外,还与映射在哪一层的特征图有关,因为特征图的下采样倍数决定了锚框排列的密度,并且特征图需要为锚框提供丰富的有效感受野[32]。将3.1节中确定的锚框方案(大小:45,75,105;长宽比比例:1.0,2.0,3.0)分别映射到不同的特征图上,计算不同方案下的匹配率,确定最适合的锚框分布;为了比较不同的特征提取网络对检测算法性能的影响,将本文所提轻量化特征提取网络与公开的网络进行比较,验证本文所提轻量化特征提取网络的有效性。
表2中,Pi指将锚框映射在下采样倍数为2i的特征图上。锚框方案Ⅰ将最小尺寸的锚框映射在下采样倍数为4的特征图上,虽然有着较高的匹配程度,但是特征图提供的感受野不足以支撑锚框尺度(P2层感受野为41,而锚框尺寸为45),大幅度损害了检测性能。锚框方案Ⅱ将最小尺寸的锚框映射在下采样倍数为8的特征图上,获得了最高的匹配率和检测精度。相比方案Ⅰ,其锚框分布较为稀疏,却能获得相同的匹配率,减少内存消耗的同时加快了检测速率。方案Ⅲ将最小尺寸的锚框映射在下采样倍数为16的特征图上,生成的锚框太过稀疏,不能覆盖到所有的真实框,有10.6%的真实框不能匹配到高质量的锚框,进而损害了检测性能。本文提出的匹配率只计算了被匹配的真实框所占的比例,没有对与真实框匹配的锚框数量和质量做进一步探讨。
为了更好地评估本文所设计特征提取网络的性能,本文还训练了多种经典网络并与之对比,结果如表3所示。本文提出的检测算法需要精确地定位到文本区域上,故将匹配阈值设为0.9。从检测精度上看,基于本文设计网络的检测算法的检测精度达到了90.2%,与基于VGG16[30]的检测算法相比只落后0.3%,与基于MobileNet V2[27]的检测算法相比提高了10.1%,与基于ShuffleNet V2[29]的检测算法相比提高了2.3%;从检测速度上看,本文所设计网络受益于深度可分离卷积模块和直通式设计,检测速度在CPU平台上FPS达到了27.8,是基于VGG16检测算法的5倍,与基于MobileNetv2[27]和ShuffleNet V2[29]的检测算法相比FPS分别提高了6.5和6.7;在轻量化上看,本文所设计的网络参数量只有0.39×106,远远少于其他网络的参数量。
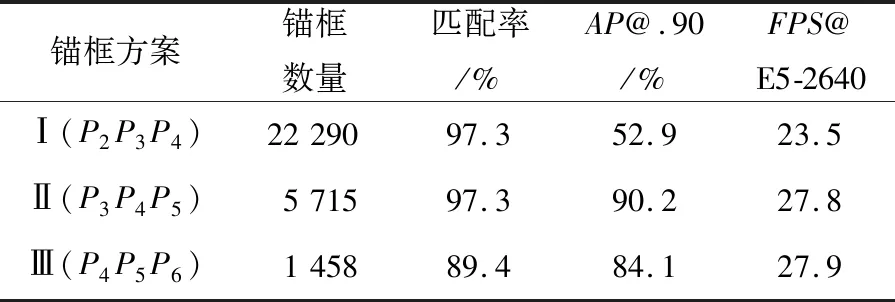
Table 2 Comparison of experimental results under different anchor schemes表2 不同锚框方案下的实验结果对比
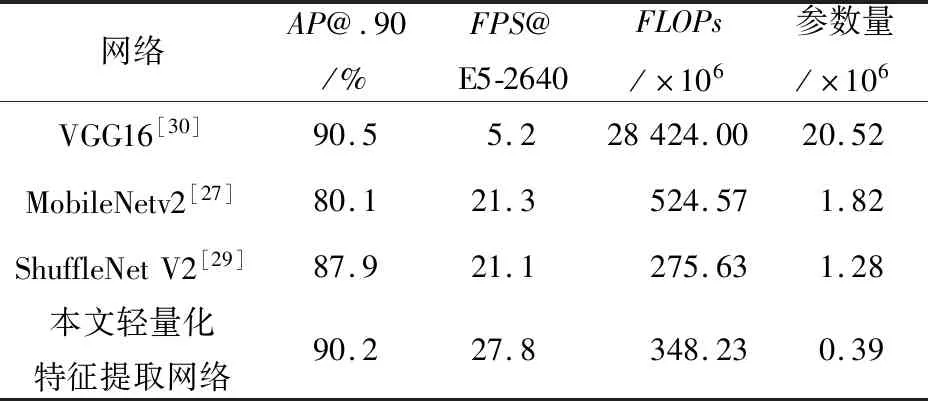
Table 3 Comparison of experimental results under different backbones表3 不同特征提取网络的实验结果对比
4.5 检测结果对比
从4.4节可知,本文所提算法对数字仪器表盘的检测精度优于其他算法的,本节展示了不同特征提取网络下SSD算法的检测效果,检测对比结果如图9所示。从图9中可见,基于VGG16[30]检测算法的检测框较为紧凑,第4幅图像略微丢失了文本信息;基于MobileNetv2[27]的检测算法对第3幅图像存在检测出多个重复框的现象,并且对第4幅图像定位不够精准,丢失了文本信息,而本文所提的算法没有出现误检和丢失文本信息的情况;基于ShuffleNet V2[29]的检测算法普遍存在预测框不精准,留有过多背景信息的现象;而本文所提算法能准确检测文本区域,说明本文所提轻量化网络在数字仪器表盘检测任务上能收获与深度网络VGG16[30]相同的精度,同时优于其他对比轻量化网络。

Figure 9 Comparison of detection results图9 检测结果对比
5 结束语
本文提出了一种轻量化的数字仪器表盘检测算法。该算法设计了轻量化的特征提取网络,与经典的网络相比,在精度和轻量化性能上均有较大提升;提出了一种基于真实框分布构建锚框方案的流程,同时引入了可量化锚框方案好坏的指标——匹配率,以促进构建分布合理且锚框量更少的锚框方案。对比实验分析结果表明:(1)基于真实框分布可快速拟建立锚框方案,随后使用匹配率量化表达锚框分布与真实框分布的匹配程度,有助于选择最合适的锚框方案;(2)本文所提轻量化网络结构设计简单,参数量少,前馈速度快,可在CPU环境下满足实时检测需求,且与经典网络相比,有着更高的检测精度和效率,当匹配阈值为0.9时,本文所提轻量化特征提取网络收获了与VGG16[30]相同的精度,速度却提升了5倍,与MobileNetv2[27]和ShuffleNet V2[29]相比,检测精度分别提高了10.1%和2.3%,速度FPS最高提升6.7;(3)从检测效果上看,本文所提轻量化特征提取网络相比其他网络,对表盘中的文本区域检测效果更好,没有误检和损失文本信息的情况。
猜你喜欢
雷达学报(2023年5期)2023-11-06 08:58:16
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
精密成形工程(2022年2期)2022-02-22 05:44:14
智富时代(2019年2期)2019-04-18 07:44:42
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
专用汽车(2016年1期)2016-03-01 04:13:19
专用汽车(2015年4期)2015-03-01 04:09:07
