
深度学习推荐模型中的注意力机制研究综述
2022-05-15 06:34高广尚
计算机工程与应用 2022年9期
高广尚
桂林理工大学 商学院,广西 桂林541004
现实生活中,人类通过快速扫描全局图像,获得需要重点关注的目标区域,得到注意力焦点,然后对这一区域投入更多注意力,以获取更多所需关注目标的细节信息,同时抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,极大地提高了视觉信息处理的效率与准确性。而深度学习中的注意力机制(attention machanism,AM)本质上与人类的选择性视觉注意力机制类似,其目的也是从众多信息中选择出对当前任务目标更关键的信息[1]。具体来说,深度学习中注意力机制的作用就是通过神经网络自主学习出一组权重系数,并以动态加权方式来强化重要信息并同时抑制非重要信息,从而使得模型可以在任务的每个步骤上专注于输入信息的必要部分[2-3]。近年来,注意力机制逐渐成为深度学习中最值得关注和深入了解的核心技术之一[4-8],并在推荐系统社区中获得了极大欢迎[6,9-16]。在深度学习推荐模型中,注意力机制能帮助模型抓住最具信息量的特征,推荐最具代表性的物品。
目前,注意力机制已在点击率预测、多媒体推荐、评分预测和群体与捆绑推荐等经典推荐场景中得到了应用,且被证明在提高推荐性能方面具有诸多优势:(1)一步到位地进行全局关系捕获,并关注数据的局部关系;(2)对长期依赖关系有更强的捕捉能力;(3)具有更高的并行性,能减少模型训练时间;(4)具有更高的可扩展性和鲁棒性;(5)结构比较简单且参数较少;(6)能在一定程度上提高模型的可解释性;(7)可以快速提取稀疏数据的重要特征及其依赖关系[17-19]。鉴于此,本文在GoogleScholar 和CNKI 中分别以关键词“Attention Machanism”和“注意力机制”,并不限定时间范围进行文献检索,通过阅读标题和摘要获取文献研究主题后,筛选得到中文文献26 篇,英文文献61 篇。经过精读并利用追溯法,本文最终对49 篇有代表性的重点文献进行系统梳理,其中英文文献43 篇,中文文献6 篇。通过文献调研,并考虑到注意力机制本身可以不依赖特定框架而能单独处理推荐任务,本文仅从注意力机制及其变种这一角度出发,并基于一些有代表性的推荐场景,对现有研究中深度学习推荐模型如何利用注意力机制及其变种,来对不同的项目(Item)或特征施加不同的权重进行系统梳理、归纳和总结,分析其中的研究成果及存在的问题,并在此基础上提出该领域中需要进一步研究的科学问题,以期为未来融合注意力机制的深度学习推荐模型研究提供一定的理论与实践指导。
1 注意力机制框架
Mnih等[20]最初提出了注意力机制概念,并认为它通过计算输入数据的权重,来突出某个关键输入对输出的影响,如图1所示。图1中,注意力机制网络框架中的输入包含5 个数据(x1,x2,x3,x4和x5),经过端到端的训练后,每个数据将会得到一个适当的权重(注意力得分),权重wi的取值是基于训练阶段在以输出为目标的前提下xi与输出的相关性而决定的,这些权重组合在一起可形成一个概率分布向量。
图1 注意力机制网络框架Fig.1 Network of attention mechanism
注意力机制是一种通用的思想和技术,不依赖于任何模型,即注意力机制可以用于任何模型。根据注意力得分的计算方法不同,现有研究将注意力机制分为标准注意力机制(vanilla attention machanism,业界常说的注意力机制)、协同注意力机制(co-attention mechanism)、自注意力机制(self-attention mechanism)、层级注意力机制(hierarchical attention mechanism)和多头注意力机制(multi-head attention mechanism)等若干变种。值得说明的是,以往研究中涉及到的商品、产品、服务、信息和项目等概念可统称为物品。
2 标准注意力机制
标准注意力机制的基本思想是对每个输入项分配一个权重,通过权重大小来表示模型对该输入项关注程度。本文从点击率预测、多媒体推荐、评分预测和群体与捆绑推荐等经典推荐应用场景方面,来分析其如何利用标准注意力机制来提高推荐性能。
2.1 点击率预测
点击率预测是指根据给定广告或物品、用户和大量的上下文情况等信息,对用户点击偏好进行预测。点击率预测中利用注意力机制旨在解决不同交互特征应具有不同的重要性权重这一问题。为预测用户对物品的兴趣,因子分解机(factorization machines,FM)通过充分考虑用户与物品之间的交互来实现这一目标。具体来说,因子分解机通过在不同的特征向量之间各自做一次乘积操作来进行特征之间的交互(即二个特征同时交互),但它对每个特征赋予相同的权重[21],即仅以线性方式组合特征,并没有考虑特征之间的非线性关系。相较而言,神经因子分解机(neural factorization machines,NFM)充分结合了因子分解机提取的二阶线性特征和神经网络提取的高阶非线性特征,但它对所有交互特征也一视同仁,并没有考虑不同交互特征对结果的影响程度,因而损失了大量有价值的信息[22]。事实上,不同的交互特征对预测结果的影响程度并不相同。例如,在预测一位男性用户是否会购买一款键盘的可能性时,“性别=男&购买历史中包含鼠标”这一交互特征,很可能比“性别=男&用户年龄=30”这一交互特征更为重要。鉴于此,为学习到二阶特征交互的重要性,即学习特征之间的相互作用的权重,Xiao等[9]在神经因子分解机的基础上提出了注意力因子分解机(attention factorization machines,AFM),它通过将注意力机制引入双线性交互池化操作中,进一步提升神经因子分解机的表示能力和可解释性。然而,AFM 对非零特征数量具有较高的平方级复杂度。
2.2 多媒体推荐
多媒体推荐是指视频、图像等方面的推荐。多媒体推荐中利用注意力机制旨在解决隐式反馈信息被忽略、跨站兴趣捕获等问题。Chen 等[1]指出现有大多数协同过滤系统忽略了用户与多媒体内容交互的隐式反馈信息,并认为在用户与多媒体内容的各种交互中,存在着组件级(component-level)、物品级(item-level)隐式反馈信息。其中,组件级隐式反馈是指用户对物品中的不同组件(例如视频中某一帧、图像中某一区域)的偏好是未知的;物品级隐式反馈是指用户对物品(视频、图像等)的偏好是未知的。鉴于此,作者在基于用户的协同过滤(user-based CF)基础上提出了注意力协同过滤模型(attentive collaborative filtering,ACF)以充分利用这些隐式反馈信息。其中,注意力协同过滤模型通过两个注意力模块来区分不同物品在聚合时的重要性权重:(1)组件级注意力模块,用于为每个用户从多媒体内容中捕捉最具信息量的特征,即用于表示每个用户对每个物品的不同的组件的偏好是有区别的,最终得到的物品的内容向量是针对每个用户的个性化内容向量;(2)物品级注意力模块,用于选择最具代表性的物品来描述用户,即最终得到用户特征向量,以用于进行评分预测。简单来说,注意力协同过滤模型通过注意力机制将组件级和物品级隐式反馈信息聚合在一起,得到多媒体内容的表示。通过对组件应用注意力机制,ACF模型能更好地学习多媒体内容上用户的偏好,进而使得推荐更加个性化。尽管ACF模型可以无缝集成到具有隐式反馈的经典CF 模型中,但它未考虑高阶组件级注意力机制。类似地,Yan 等[23]认为现有的网络视频系统根据用户在自己网站上的观看历史向用户推荐视频。然而,由于许多用户在多个网站上观看视频,这种方法无法捕获这些用户在不同网站上的兴趣。为捕获跨站点及特定站点的用户兴趣,作者研究了基于大规模真实数据集的多站点用户浏览行为,并发现用户兴趣由跨站点一致性部分(cross-site consistent part)和具有不同重要性的站点特定部分(site-specific part)组成,继而在此基础上提出了深度注意力概率因式分解模型(deep attentive probabilistic factorization,DeepAPF),以利用深度学习方法来逼近这种复杂的用户视频交互。具体来说,该模型通过注意力网络学习非均匀重要性权重,来准确捕捉跨站点和特定站点的用户兴趣,还能学习复杂的用户-视频交互。然而,该模型需要建模跟平台有关的独特偏好。
2.3 评分预测
评分预测是指根据用户和物品的历史记录来预测用户对物品的评分。评分预测中利用注意力机制旨在准确地捕获用户对不同物品各个方面(aspect)的关注。现实中,用户在写评论的时候,更倾向于在他们关注的特征上去评论,这样可以提取出用户的偏好和产品特征。Cheng等[24]认为不同的用户对不同物品各个方面的关注程度是不一样的,例如,对于苹果手机,用户可能更关注高像素、低耗量等,而对于廉价手机,用户可能更关注通讯质量等,然而现有的方法都没有考虑到这一情形。鉴于此,为学习评论中用户的偏好和物品的特征,作者提出了基于方面级(aspect-level)的自适应注意力评分预测模型(adaptive aspect attention-based neural collaborative filtering model,A3NCF),以准确捕获用户在同一方面对不同物品的偏好的权重。简单来说,A3NCF 模型参考了AFM 模型,并引入注意力机制来捕获用户对目标物品各方面的注意力,即增强区分不同方面的重要程度的能力。然而,该模型并未对比较过程中所采用的物品哪些方面作进一步说明。
2.4 群体与捆绑推荐
群体推荐(group recommendation)主要是指为群体用户推荐物品(例如向同事群推荐一个餐馆),它不仅需要聚合群体成员的偏好,还需要正确理解群体决策过程,因为在群体决策过程中,用户倾向于追随一小部分用户的决策,其中这一小部分用户就是传说中的意见领袖或领域专家。群体推荐中利用注意力机制旨在对群体中的不同成员进行权重分配,权重越高表明用户越重要,因此他们对于群体的最终决策越重要。Vinh等[25]提出使用注意力机制来捕获群体中每个用户的影响权重,然后让模型能基于其成员的加权偏好来向群体推荐物品。值得说明的是,由于注意力机制可以动态调整群体中每个用户的权重,因而它也提供了一个新的灵活的方法来对复杂的群体决策过程进行建模。该方法没有将诸如社交关系、文本信息(例如事件描述)或时间信息等辅助信息纳入上下文中,来学习注意力模型。
捆绑推荐(bundle recommendation)主要是指对用户推荐商品集合。捆绑推荐利用注意机制旨在学习一捆(bundle)的表示。Chen 等[26]认为大多研究主要关注给用户推荐单个物品,然而在很多真实应用场景中,平台需要给用户展示物品集合,例如营销策略中会将多个物品打包在一起销售。为此,作者提出了深度注意力多任务模型(deep attentive multi-task,DAM)以对用户和物品的集合进行建模,该模型具有两个特殊设计:(1)因式分解注意力网络用于对商品的嵌入进行聚合,进而得到捆绑表示;(2)通过多任务处理方式来对用户捆绑交互和用户商品交互联合建模,避免了用户捆绑交互的不足。实验结果表明,其中的注意力机制可以有效地为每个用户学习一个个性化的权重。然而,该方法没有考虑物品共现信息(有些产品是存在互补关系的,如你买网球拍,一般会买个网球)、时间因素(用户的兴趣很容易随时间变化)。
3 协同注意力机制
协同注意力机制的基本思想是同时对多个输入序列进行操作,并共同学习它们的注意力权重,以捕获这些输入之间的交互[27]。它能更好地捕捉不同属性(特征)之间的交互关系。本文从可解释性推荐、知识增强推荐和评论文本推荐等经典推荐应用场景方面,来分析其如何利用协同注意力机制来提高推荐性能。
3.1 可解释性推荐
可解释性推荐中利用协同注意力机制旨在遴选出对推荐与解释生成任务来说都很重要的点评及概念,作为两个任务共有的知识。Chen 等[28]认为在推荐的同时提供文本解释可有效获得用户的信赖,增加推荐系统的说服力与满意度等,而解决这个问题的关键是要对用户与物品之间的深层次交互进行显式、可解释的建模,并将建模结果作为约束直接影响解释生成和推荐结果。鉴于此,受认知科学相关启发,作者提出了一种基于协同注意力机制的多任务学习模型(co-attentive multi-task learning,CAML),其中的层级多指针协同注意力机制选择器(multi-pointer co-attention selector)将仅对重要信息进行保留。具体来说,每个指针(pointer)对应两层协同注意力机制网络,分别选择一个用户或商品概念。以选择用户概念为例,第一层协同注意力机制网络利用点评编码计算用户点评在商品历史点评中的相关程度。在筛选出用户最重要的点评后,点评将被展开到概念(concept)这一层次,接着利用第二层协同注意力机制网络计算每个概念的作用,选择点评中最为重要的概念作为对用户点评信息的补充。值得说明的是,CAML模型没有解决推荐系统的冷启动问题。
3.2 知识增强推荐
知识增强推荐中利用协同注意力机制旨在更好地捕捉不同属性(特征)之间的交互关系。Yang 等[29]认为现有大多数基于注意力机制的推荐模型在生成用户的表示时应用了粗粒度的注意力机制,少数改进的模型尽管在注意力模块中加入了物品的属性(特征)信息,即融入物品的相关知识,但仍然仅在用户表示这一端应用了注意力机制。鉴于此,作者提出了一种在用户表示端与物品表示端协同应用(物品)属性级注意力机制的深度学习推荐模型,称为属性级协同注意力模型(attributelevel co-attention model,ACAM),其主要特征为:(1)物品与用户的初始表示基于知识图谱中物品属性的表示(向量),而非单一的随机初始化向量;(2)内建协同注意力机制模块,通过捕获不同属性之间的关联来增强用户和物品的表示,这是考虑到不同的物品属性(特征)之间可能存在相关性。例如,电影属性中,演员史泰龙与动作题材高度相关,而演员巩俐与导演张艺谋也很相关。因此,利用属性相关性来增强用户或物品表示,能更加精确地揭示目标用户和候选物品之间的潜在关系,从而提升推荐性能。简单来说,ACAM模型首先用细粒度的属性嵌入来表示用户和物品,然后通过属性级的协同注意力模块同时增强用户表示和物品表示。但是,该模型没有考虑用户与物品之间的高阶非线性关系。
3.3 评论文本推荐
评论文本推荐中利用协同注意力机制旨在从用户评论以及与商品相关的评论中抽取出重要的评论信息,以学习用户与商品的表示。Tay等[3]认为在预测用户对商品的评分时,并不是用户写过的所有评论以及商品的所有评论都同等重要,而应通过两者的交互来筛选出最重要的评论,提取最有用的信息,进而帮助更好地进行评分预测和推荐。为找到更加有用的评论,即对评论加上一个重要性权重,作者提出了多指针协同注意力网络(multi-pointer co-attention network,MPCN),该网络能够将用户商品交互的多个视图结合起来。该网络能从用户和商品评论中提取重要的评论,然后逐字逐句地匹配它们,这不仅可以将最有用的评论用于预测,还可以进行更深入的单词级交互。具体来说,该网络通过协同注意力机制在评论级(review-level)和字符级(word-level)上对用户评论和与商品相关的评论进行选择,选择最重要的一条或若干条评论来对用户和当前商品进行表示。然而,该网络仅仅局限在浅层线性特征层面,而且用户特征和商品的高级抽象特征未被充分挖掘。
4 自注意力机制
自注意力机制的基本思想是利用输入项之间相互关系,自行决定分配输入项权重大小,即对于每个输入项所分配的权重大小取决于输入项间的相互作用[30]。本文从可解释性推荐、序列推荐和用户行为推荐等经典推荐应用场景方面,来分析其如何利用自注意力机制来提高推荐性能。
4.1 可解释性推荐
可解释性推荐中利用自注意力机制旨在为用户的交互商品分配注意力权重。Yu 等[31]提出了一个名为NAIRS的神经注意力可解释推荐系统,其中的自注意力机制可以区分不同交互商品对用户概要(user profile)的重要性,即可以根据与用户偏好相关的意图重要性来计算用户概要中历史商品的注意力得分。通过学习到的注意力得分,NAIRS可以根据用户的历史偏好为他们提供高质量的个性化推荐。总结来说,NAIRS具有两方面特征:(1)通过自注意机制来学习用户的表示形式,而不是针对特定商品计算注意力得分;(2)在实践中,可以基于预先计算的用户表示来实时推荐商品。用户的兴趣是短暂的,并且在长时间和短时间内都会发生变化,但NAIRS并没有考虑在用户的交互商品中捕获长期和短期兴趣。
4.2 序列推荐
序列推荐是指给用户推荐在不久的将来可能会发生交互行为的商品。序列推荐中利用自注意力机制旨在从用户历史行为中推断商品之间的关系。Lv 等[32]认为现有的序列推荐中存在两个问题:(1)用户在一个会话(session)中可能存在多个兴趣倾向;(2)用户长期偏好可能无法与当前会话兴趣有效融合。事实上,长期行为多样且复杂,因此与短期行为密切相关的行为应保留融合。鉴于此,作者提出了序列深度匹配模型(sequential deep matching,SDM),它能融合用户的长期与短期行为,在长期行为中挖掘用户对物品属性的偏好(例如类目、品牌、店铺等),在短期行为中结合自注意力机制过滤掉会话内部的一些误点击行为(casual click),并挖掘用户在会话内的多方面兴趣,最后构造出自适应的融合长短期兴趣的用户表示。然而,SDM 模型没有考虑多个交织兴趣的影响,因为用户通常在一个会话中同时具有多个兴趣,并且这些兴趣可能是交织的。类似地,Zhang 等[33]提出了一个序列感知推荐模型AttRec,该模型利用自注意力机制来为用户短期行为模式的依赖关系和重要性建模,同时该模型也使用度量学习(metric learning)保留了用户的长久兴趣。具体来说,通过自注意力机制,模型可以在用户交互历史中评估每个物品的相关性权重,从而更好地学习用户短期兴趣的表示。然而,AttRec 模型没有充分考虑用户交互行为的序列,因为用户在不同时间交互的项目对用户兴趣的反映具有不同的意义。
Zhang等[34]认为现有的序列推荐通常只考虑商品之间的转换模式,而忽略了商品特征之间的转换模式,并指出利用商品层次的序列不能揭示完整序列模式的特性,显式和隐式特征层次的序列有助于提取完整序列的模式。为此,作者提出了特征层次的深层自注意力网络(feature-level deeper self-attention network,FDSA),该网络首先通过标准注意力机制,利用不同权重将多种异质商品特征集成为特征序列,然后基于商品层面序列和特征层面序列,分别利用独立的自注意力模块对商品转换模式和特征转换模式进行建模,接下来,将这两个模块的输出进行集成,得到一个全连接层,然后用于推荐下一个商品。然而,FDSA网络没有考虑如何直接地进行特征间的信息交互。此外,Zhang 等[35-36]在序列推荐中通过自注意力机制来估计用户交互历史中每个商品的权重,进而学习到用户短期兴趣的更准确表示。
4.3 用户行为推荐
用户行为推荐中利用自注意力机制旨在对行为间的互相影响进行建模。Zhou等[37]认为在电商领域中,一个用户可能浏览、购买、收藏商品,领取、使用优惠券、点击广告、搜索关键词、写评论或者观看商家提供的商品介绍视频等,这些不同的行为为人们更全面地理解一个用户提供了不同的视角。然而,面对用户如此异构、多样化的行为,现有推荐模型很难做到更精确的推荐。在这样的背景下,作者提出了一个通用的基于自注意力机制的用户异构行为框架ATRank,以试图将所有类型的行为投射到多个潜在的语义空间中,并通过自注意力机制对行为产生影响。其中,框架利用自注意力机制来对行为间的互相影响进行建模。具体来说,其中的自注意力机制用于将用户的每一个行为从一个客观的表示转换成一个用户记忆中的表示。客观的表示是指,例如用户A、B做了同样一件事,这个行为本身的表示可能是相同的,但这个行为在A、B的记忆中其强度、清晰度可能是完全不一样的,因为A、B 的其他行为不同。然而,ATRank框架仍然需要领域专家的特征工程和架构工程。
5 层级注意力机制
层级注意力机制的基本思想是在具有自然层次化结构的输入序列的不同层次结构上应用注意力机制,使得低层次抽象的特征表示作为高层次抽象的输入[38-39]。本文从长短期序列推荐和评论文本推荐等经典推荐应用场景方面,来分析其如何利用层级注意力机制来提高推荐性能。
5.1 长短期序列推荐
长短期(long and short-term)序列推荐中利用层级注意力机制旨在自动为用户分配商品的不同影响(权重)以捕捉动态特性,并通过层次结构来结合用户的长期和短期偏好。Ying 等[38]认为用户的长期兴趣是随时间而变化的,不同的商品对下一次购买行为的影响是不一样的,且对于不同用户,相同商品对下一次购买也有不同的影响。鉴于此,作者提出了序列层级注意力网络(sequential hierarchical attention network,SHAN)来解决下一个商品推荐问题。其中,作者首先将用户和商品嵌入低维密集空间,然后利用注意力机制计算用户长期集合中商品的不同权值,并用权值对商品向量进行压缩以生成用户长期表示。之后,作者使用另一个注意力机制来耦合用户的序列行为和长期表示,以生成用户的高级混合表示。用户嵌入向量作为两个注意力网络中的上下文信息,以计算不同用户的不同权重。SHAN网络假定每个用户对商品的偏好分布是扁平的,然而,这一假设忽略了用户意图和用户偏好之间的层次差别,导致其在描述特定意图偏好方面能力有限。
5.2 评论文本推荐
评论文本推荐中利用层级注意力机制旨在单词级和语句级上识别评论文本中最重要的部分。Xing 等[40]认为现有研究结合了用户和产品信息来生成评论表示,然而这些方法只考虑了单词级别的评论文本信息,没有考虑语义级别的评论文本信息。鉴于此,作者提出了一种基于用户和产品评论的层级注意力模型(HAUP)以从用户评分和用户评论文本中联合学习用户和物品信息。该模型首先构造一个层级双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU),其中包括单词和句子级别的评论信息。Bi-GRU结构可以处理评论文本中的长期依赖关系。然后,在构建评论文本表示时,在单词和句子级别应用注意力机制以识别最重要的内容。最后,将生成的潜在用户和产品表示合并到相同的向量空间中以估计评分。HAUP 模型没有考虑到评论集合中单条评论的有效性。
6 多头注意力机制
多头注意力机制的基本思想是并行地运行多个注意力层(“多头”),然后将它们的输出拼接起来,再对结果进行线性变换[30]。本文从跨媒体关键词预测和点击率预测等经典推荐应用场景方面,来分析其如何利用多头注意力机制来提高推荐性能。
6.1 跨媒体关键词预测
跨媒体关键词预测中利用多头注意力机制旨在捕获复杂的跨媒体交互信息。Wang等[41]认为当前大多数工作都集中在文本建模上,忽略了相关的图像特征。具体来说,由于社交媒体的非正式风格,跨媒体关键词预测带来了独特的差异,主要体现在两个方面:(1)文本图像关系相当复杂;(2)社交媒体图像通常呈现出更多样化的分布,并且包含光学字符的概率要高得多,因此为有效处理带来了障碍。鉴于此,作者探讨了基于文本和图像联合建模的多媒体关键词预测模型M3H-Att(multimodality multi-head attention)。首先为了对齐社交媒体中的文本和图像特征,作者设计了一个多模态、多头注意力框架去捕获复杂的跨媒体交互信息,接着以字符特征和图像属性的形式来连接图像、文字这两种不同的模态,以弥补它们之间的语义鸿沟。实验结果表明,作者提出的模型优于传统的基于协同注意力机制的技术。M3H-Att模型没有考虑图像中存在大量的无关噪声像素,没有考虑从现有的海量图文数据上学习模态之间的信息转化关系。
6.2 点击率预测
点击率预测中利用多头注意力机制旨在对输入特征的不同顺序的特征组合进行建模。Song 等[42]认为点击率预测非常具有挑战性,主要体现在两个方面:(1)输入特征(如用户id、用户年龄、商品id 和商品类别等)通常是稀疏高维的;(2)有效的预测通常依赖于高阶组合特征(cross features,又称交互特征),由领域专家手工处理非常耗时,很难穷举。因此,致力于寻找稀疏高维原始特征的低维表示及其有意义的组合将是点击率预测的研究重点。鉴于此,作者提出了一种称为AutoInt的模型来自动学习输入特征的高阶特征交互。具体来说,作者将数值和分类特征都映射到相同的低维空间中。然后,提出了带有残差连接的多头注意力机制,以对低维空间中的特征相互作用进行显式建模。最后,利用多头注意力机制的不同层来对输入特征的不同顺序的特征组合进行建模。AutoInt模型未能充分挖掘有意义的高阶交叉特征。其中的组合只是找到了关系相近的特征,而关系相近的特征进行组合并不一定是合适的方式,也就是说多头注意力机制能做到有意义的特征组合,但却不能说明关系不相近的特征的意义就不大。
类似地,Xiao等[10]认为用户在一个时间点的兴趣是多样的,而潜在的主要兴趣是通过行为来表示的,潜在主要兴趣的转变会导致最终的行为变化。因此,建模和跟踪潜在的多重兴趣将是有益的。鉴于此,对于点击率预测任务,作者提出了深度多兴趣网络模型(deep multi-interest network,DMIN)来捕获用户潜在的多兴趣。具体来说,DMIN模型由两部分组成:(1)行为细化层,使用多头注意力机制对用户历史行为进行提炼,即捕捉更好的用户历史商品表示;(2)多兴趣提取层,实现用户多兴趣的抽取。然而,DMIN模型没有考虑到一个用户的兴趣变化可以通过其他用户的兴趣变化来预测,更具体地说,相似的用户会朝着相似的方向改变他们的兴趣。
7 注意力机制之间的详细比较
简单来说,注意力机制就是对每个输入项分配一个权重。其主要目标是让神经网络在执行预测任务时可以多关注输入中相关部分,少关注不相关部分。表1对文中所述注意力机制在逻辑思路、优势、局限性和适用场景这四个方面进行了详细比较。
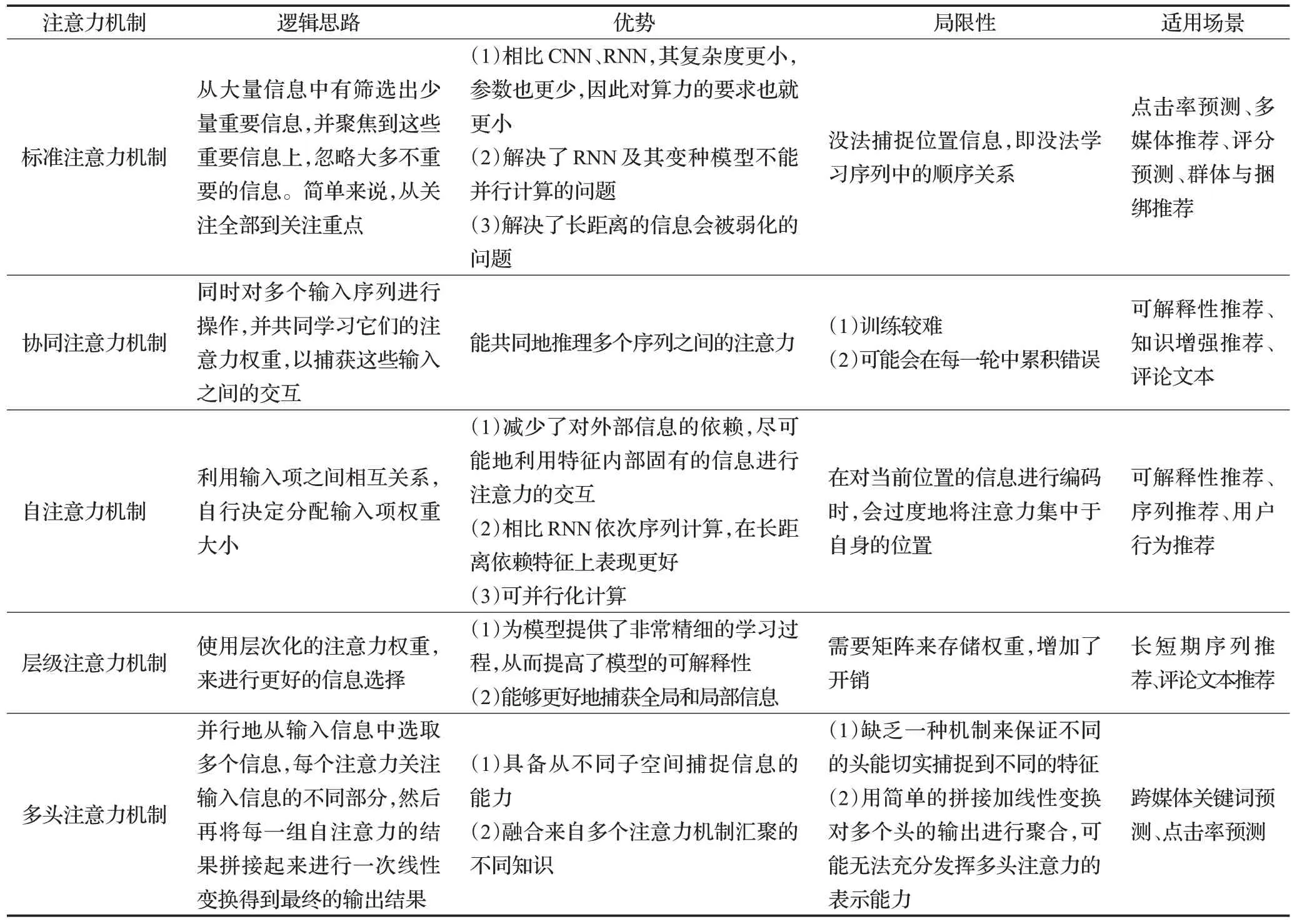
表1 注意力机制详细比较Table 1 Detailed comparison of attention mechanism
8 总结与展望
深度学习推荐系统是深度学习技术在商业社会的一项成功应用,它通过从海量数据中筛选出对用户最有价值的数据,从而让用户更高效地接触对自己有意义的内容,进而提高整个商业流程的效率[43-44]。而注意力机制能帮助推荐模型快速抓住最具信息量的特征,推荐最具代表性的物品,同时一定程度上增强模型的可解释性等。鉴于此,本文针对一些有代表性的推荐场景,探讨研究了深度学习推荐模型如何利用注意力机制及其变种来对不同的项目或特征施加不同的权重以提升推荐效率,为下一步的深入研究打下良好基础。注意力机制或许是未来深度学习的核心要素,但目前融合注意力机制的深度学习推荐模型在推荐系统上的应用还处于比较初级的阶段,尤其是技术上的发展较慢于计算机视觉和自然语言处理领域等。展望未来,为进一步激励将融合注意力机制的深度学习用于推荐系统,本文认为注意力机制技术在推荐多样性、推荐可解释性和多种辅助信息(side information)融合等方面仍存在一些开放性问题值得探讨。
(1)有效实现推荐多样性
推荐结果多样性是指推荐模型为每个目标用户推荐类别多样化的物品。推荐结果多样性可以被视为双目标优化问题,即最大化推荐列表的整体相关性,并尽量减少列表中物品之间的相似性。现实应用中,推荐结果多样性不仅能向用户推荐彼此相似度低的物品,还能开阔用户认知视野、激发用户潜在兴趣等,甚至能使用户更好地发现具有“新颖性”的物品,进而增加冷门物品被推荐的机会(避免长尾现象)。总结来说,推荐结果多样性对优化点击转化效率、用户体验、浏览深度、停留时长、回访、留存等目标至关重要。现有研究中,提升推荐结果多样性的思路主要有三种:①召回阶段策略。可以融合不同推荐召回算法的推荐结果,即多路召回。②精排阶段策略。精排模型中加入用户、物品和环境特征,实现在不同的维度的多样性。通常来说,特征越丰富个性化越强,同时多样性越强。③重排序阶段策略。在推荐流程前面的召回、过滤、粗排和精排阶段的基础上,进一步找到商品集中相关性和多样性最大的子集,从而作为推荐给用户的商品集,工业界的代表性方法有:最大边界相关算法(maximal marginal relevance,MMR)[45];行列式点过程(determinantal point process,DPP)[46]、个性化重排序模型(personalized re-ranking model,PRM)等,这类方法都是基于贪心的策略,容易陷入局部最优解,且都需要额外的参数来平衡多样性与准确率。尽管现有的推荐结果多样性方法已取得不错的效果,但其仍然存在固有的局限性:①没有考虑领域级别和用户级别的多样性分布差异[47]。首先,即使用户的兴趣比较固定(多样性较低),这些方法仍然会给用户推荐一个多样化的结果。其次,现有方法的推荐策略不会随着领域的不同而做出改变。②假设用户意图是静态的,并且需要预先告知具体的用户意图[48]。因此,在保证推荐准确率的前提下,如何从用户多样性偏好角度,利用注意力机制来挖掘反映在用户行为序列中的多个潜在用户意图,然后为用户意图生成一个准确且多样性的推荐列表,将是推荐模型未来研究的热点和新的发展方向。
(2)帮助促进推荐可解释性
推荐可解释性指的是推荐模型在为用户提供推荐的同时,也提供直接的推荐理由。现实应用中,给用户提供有价值的推荐解释往往是很重要的,这不仅能够加深用户对产品的理解和信赖,提升用户体验和用户选择推荐物品的概率,还能提升模型透明度(模型为什么会做出如此决策等)和用户对模型的信任和接受程度等[49]。尽管现在的推荐模型具备一定程度的可解释性,但仍存在以下两个问题:①给出的解释通常是以相关历史交互物品的形式来产生,其中的相似性是通过在系统内定义每个物品的潜在权重来获得,这让报告为相似的两个物品可能被终端用户认为不是这样的,并且与提供解释的最初动机相矛盾;②通常仅能捕获部分用户偏好和物品属性信息,无法识别出与被推荐物品密切相关的用户特征,这将导致推理和准确性有限。事实上,缺乏合理的解释已成为模型在现实推荐任务中进一步发展和应用的主要障碍之一[28]。因此,如何利用注意力机制从生成策略,密度控制和维度优化等方面来动态识别最能代表不同用户的特征,以便在产生相关的推荐物品的同时,提供被证明是合理的解释,将是一个值得探索的方向之一。
(3)快速融合多种辅助信息
辅助信息中所包含的信息量可以有效弥补用户历史交互信息的稀疏或缺失,因此同时利用这些信息将能更好地发现用户的个性化偏好,从而给推荐效率带来显著提升[50]。在实际应用中,除了大量的用户与物品的交互历史数据之外,还有丰富的用户画像(例如年龄、性别、兴趣偏好等)、物品属性(例如物品类别、描述、价格等)、上下文信息(例如当前会话信息、位置信息等)和知识图谱[51]等辅助信息,它们往往具有多模态、数据异构、大规模、数据稀疏和分布不均匀等复杂特征。很显然,要想提高推荐的精准度或增强推荐算法的挖掘能力,就必须要求推荐模型应尽可能多地融合辅助信息,并具有很强的扩展性。然而现有大多数推荐模型对辅助信息缺乏深入理解,主要体现在以下三个方面:①辅助信息本身存在较为复杂的多源异构特征;②没有考虑任何不同类型和任何数量的属性的组合;③没有计算属性间的高阶交叉特征。因此,如何利用注意力机制实现早期融合各部分信息,使各部分相互补充、相互启发,从而将辅助信息统一嵌入到物品的潜在语义空间中,进而形成语义丰富的更精确的物品表示,最终增强模型的扩展性并提高推荐性能,将是未来学术界的探索方向和研究重点。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·初中天地(2021年11期)2021-02-16
甘肃教育(2020年22期)2020-04-13
少年漫画(艺术创想)(2019年2期)2019-06-06
文苑(2018年21期)2018-11-09
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年9期)2015-11-10
小天使·一年级语数英综合(2015年8期)2015-07-06
中国卫生(2014年3期)2014-11-12
