
基于YOLO-v5的双块式轨枕裂缝智能识别
2022-05-10 11:45崔晓宁王起才代金鹏梁柯鑫李隆甫
铁道学报 2022年4期
崔晓宁,王起才,2 ,李 盛,代金鹏,2,梁柯鑫,李隆甫
(1.兰州交通大学 土木工程学院,甘肃 兰州 730070;2.道桥工程灾害防治技术国家地方联合工程实验室,甘肃 兰州 730070;3.中铁上海设计院集团有限公司, 上海 200070; 4.中建三局集团有限公司,甘肃 兰州 730000)
截至2020年底,我国高速铁路运营里程达到3.79万km,居世界第一,高速铁路在服务经济建设和社会发展的过程中扮演着不可或缺的角色[1]。在高速铁路的运营过程中,由于列车的动荷载、地基不均匀沉降、外界温度荷载等因素的影响,无砟轨道道床板及轨枕等构件容易出现松动、开裂,严重影响高速铁路的安全运营[2-3]。因此,开展轨枕裂缝相关研究具有较高的科研价值与现实意义。
鉴于轨枕裂缝研究的重大意义,国内外学者针对轨枕的裂缝进行相关研究,也产出丰硕成果。曾志平等[4]基于太阳能辐射及表面换热理论,建立轨枕的温度场数值模型,通过研究不同工况下的温度场变换得到了最不利工况,研究成果为双块式轨枕的设计及养护提供了理论支撑。徐凌雁[5]分析双块式轨枕成段开裂机制,结合实际工程背景,提出针对双块式轨枕成段开裂的病害整治方案。郭润平等[6]利用三维光学应变测量仪和裂缝检测仪观察研究多孔火山岩骨料混凝土轨枕的疲劳裂缝发展规律,结果表明轨枕疲劳裂缝的扩展速率与加载次数呈现明显的非线性关系。文献[7]基于断裂力学研究B70预应力混凝土轨枕的裂纹扩展,研究结果表明:在确定裂纹扩展参数KIC、裂纹长度及CMOD情况下,预应力混凝土轨枕的断裂行为是可预测的。张景伟[8]基于西北地区的恶劣环境因素,分析了西北地区轨枕裂缝的形成原因,并总结了轨枕开裂宽度对裂缝内部碳化程度的影响规律。以往的研究成果一般基于轨枕裂缝的产生机制和扩展规律展开,然而由于外界荷载、温度场、不均匀沉降的不间断性与不可避免性,轨枕的裂缝也随之不断产生和发展,为保证高速铁路的安全运营,需要对轨枕裂缝进行损伤识别以便及时更换不能继续正常工作的轨枕。因此,开展轨枕的裂缝目标检测对高速铁路的安全运营具有很高的科研价值。
基于深度学习的结构损伤智能识别是目前结构健康监测领域的重要研究课题。对于铁路建筑而言,国内外学者纷纷开展基于深度学习的铁路损伤识别研究。扣件的定期安全检测对铁路安全运营意义重大,为实现轨道扣件的智能安全检测,文献[9]建立多尺度深度检测网络(MSF-DDN)与区域多分类网络,实现了铁路扣件的智能异常检测。文献[10]基于Faster R-CNN目标检测模型实现了扣件的缺陷检测。文献[11]以日本高速铁路线(东海道新干线)钢筋混凝土铁路高架桥的局部损伤为研究对象,建立全卷积神经网路进行结构表面剥落的像素级语义分割,进而实现高速铁路建筑健康状态的自动化评估。钢轨表面缺陷的严重程度关系铁路安全运营,文献[12]基于SqueezeNet和MobileNetV2的融合模型实现了对钢轨表面缺陷的高精度智能检测。文献[13]为实现铁路接触网异常检测,建立基于深度学习的改进视网膜模型,提高了接触网故障诊断的精度和效率。文献[14]基于YOLO-v3和RetinaNet的迁移学习模型实现了轨道裂缝的损伤智能检测。为解决裂缝图像正负样本不均衡的难点,文献[15-16]在Unet语义分割模型上引入注意力机制进行模型改良,并基于改良后的Unet模型进行裂缝语义分割,得到较高的裂缝识别精度。
对于高速铁路的发展,实现智能化是大势所趋,人工智能技术在铁路相关研究中也纷纷开展[10,13,17-18]。由于人工智能在土木工程领域的应用尚处于发展阶段,因此,深度学习技术对许多土木工程领域还未涉足,针对轨枕裂缝的目标检测,目前研究较少。本文采用先进计算机视觉智能识别方法进行轨枕裂缝的目标检测,将目前先进的目标检测算法——YOLO-v5[19]应用于研究较少的轨枕裂缝识别,并基于优化后的YOLO-v5模型进行高精度的轨枕裂缝检测,在实现轨枕裂缝智能识别的同时也为计算机视觉技术在铁路行业的应用与发展提供一定参考。 目前目标检测算法的图像边界框多是目标整体框选[10,17,20-21],而裂缝图像具有极强的正负样本不均衡性,即需要关注的裂缝本身在图像中占的像素点极少,不需要关注的图像背景却占整个图像的绝大部分。如果裂缝图像的标注框太大,深度学习模型对于轨枕裂缝的识别结果欠佳;标注框太小,则深度学习模型容易学习到裂缝图像中的噪点和干扰。因此,本文通过试算采用适度密集标注法制作轨枕裂缝数据集标签并取得较高的模型预测精度。
1 轨枕裂缝数据集
1.1 数据集简介
本文所用的双块式轨枕裂缝数据集来自“智创工程AI挑战赛”。轨枕裂缝数据集总量为2 532张图片,每张裂缝图片的分辨率为1 400×1 200,裂缝数据集在不同光照、不同干扰条件下采集而得,可有效地提高目标检测模型的鲁棒性。数据集按照6∶2∶2划分为训练集、验证集和测试集。训练集用来训练拟合模型权重参数,验证集用来调整模型参数以便得到最优模型,测试集则利用得到的最优模型进行最终输出预测和评价。图1呈现的是部分具有代表性的轨枕裂缝照片。

图1 不同条件下轨枕裂缝展示
1.2 数据集标注
本文所做的轨枕裂缝智能识别属于有监督学习的范畴。有监督学习是将具有标签的数据集输入深度学习模型,进而使深度学习模型学习到数据集输入与标签之间的映射,最后将得到的映射关系应用到测试数据集上,以达到分类或回归的目的。因此在利用深度学习算法对轨枕裂缝进行智能识别之前,需要对数据集中的每一张轨枕裂缝进行裂缝标签制作,本文采用的裂缝标签制作软件为LabelImg,其标注过程如图2所示。通过大量试算发现,轨枕裂缝标注框不能过大或过小:标注框太大,深度学习模型对于轨枕裂缝的识别结果欠佳;标注框太小,深度学习模型则容易学习到裂缝图像中的噪点和干扰。因此,本文通过试算采用适度密集标注法进行轨枕裂缝的标签制作,为目标检测算法提供数据基础。
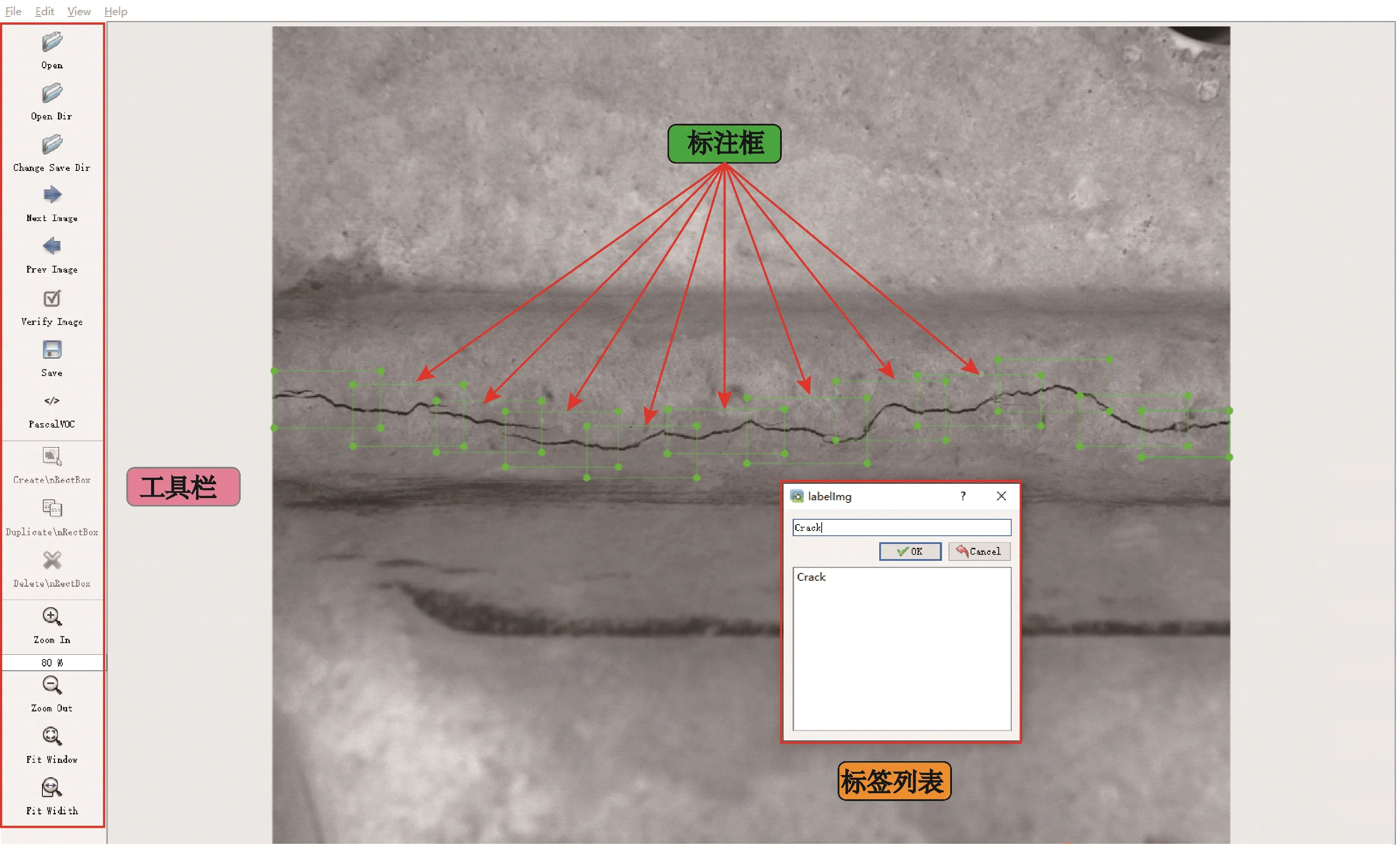
图2 LabelImg裂缝标注过程
2 算法理论
2.1 目标检测算法
目标检测算法可分为两大类:
(1)一阶段目标检测。一阶段目标检测算法可以一次性预测出目标的类别和位置,这类算法具有识别速度快的特点,但是比两阶段目标检测算法的识别精度低,一阶段目标检测代表算法有YOLO-v3[22]、SSD[23]等。
(2)两阶段目标检测。这类目标检测算法原理如下:首先,通过对输入模型的图像进行选择性搜索,进而得到候选区域;其次,将生成的候选区域输入卷积神经网络模型进行特征学习与提取;再次,通过全连接神经网络进行图像分类;最后,得到图像的预测边界框与置信度。两阶段目标检测具有精度高的特点,但识别速度较慢,两阶段目标检测代表算法有Faster-RCNN[24]、Spp-Net[25]等。YOLO系列算法经过不断的迭代更新,目前已经更新出最新的YOLO-v5算法,YOLO-v5算法结合了目前目标检测算法领域的众多先进技术,如Mosaic数据增强技术、自适应锚定框、空间金字塔池化、Head-YOLO等。通过结合以上先进技术,YOLO-v5已成为目标检测领域性能最好的模型之一,尤其对于小目标的检测,YOLO-v5体现出了较高的适用性与精确度[26-27],而轨枕裂缝也属于小目标的范畴,因此,本文基于YOLO-v5进行轨枕裂缝的智能检测。
2.2 YOLO目标检测算法原理
YOLO目标检测算法是将目标检测任务转化为回归与分类的综合任务,其算法原理为:将输入的整张图片分割成S×S网格,对于每一个网格,模型都预测B个预测框,每个预测框包含了预测物的类别和置信度,进而预测得到S×S×B个目标检测窗口,根据模型预先设定好的阈值,神经网络模型会先清除置信度比较低的目标窗口,最后根据非极大值抑制算法筛除冗余窗口,即可得到最终的目标检测结果,该预测结果包含目标物的类别与置信度,YOLO目标检测算法的原理示意如图3所示。

图3 YOLO算法目标检测原理示意
2.3 YOLO-v5算法结构
轨枕裂缝目标检测任务的最终目的是用先进的计算机视觉技术来代替传统的人工检测,因此,裂缝的检测算法最终要部署在移动端进行裂缝智能识别[21],这就要求裂缝识别的模型满足实时识别与检测精度的要求,YOLO系列算法识别速度快,实时性强,目标检测识别精度高。这与轨枕裂缝的智能识别任务契合度较高,因此,本文采取YOLO-v5[13]算法作为轨枕的裂缝识别模型,YOLO-v5算法总体结构如图4所示。
从图4可以看出:YOLO-v5算法结构由四部分组成,分别为输入端、主干网络、瓶颈块、预测。输入端主要完成Mosaic数据增强和自适应锚框计算;主干网络结构主要对图片进行特征提取,需要特别指出的是,Focus算法块首次出现在v5版本中,该算法块用于对608×608×3的输入图片进行切片和卷积,进而得到304×304×32的特征图;瓶颈块结构采用FPN+PAN网络,实现对不同等级特征的融合;预测部分完成对输入图像的预测。YOLO-v5用到的算法块运算原理如图5所示。
图4中所示的YOLO-v5算法整体由图5中的细部算法基本块堆叠而成,图5中的算法基本块由以下单元组成:
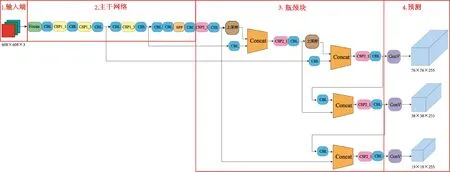
图4 YOLO-v5算法结构
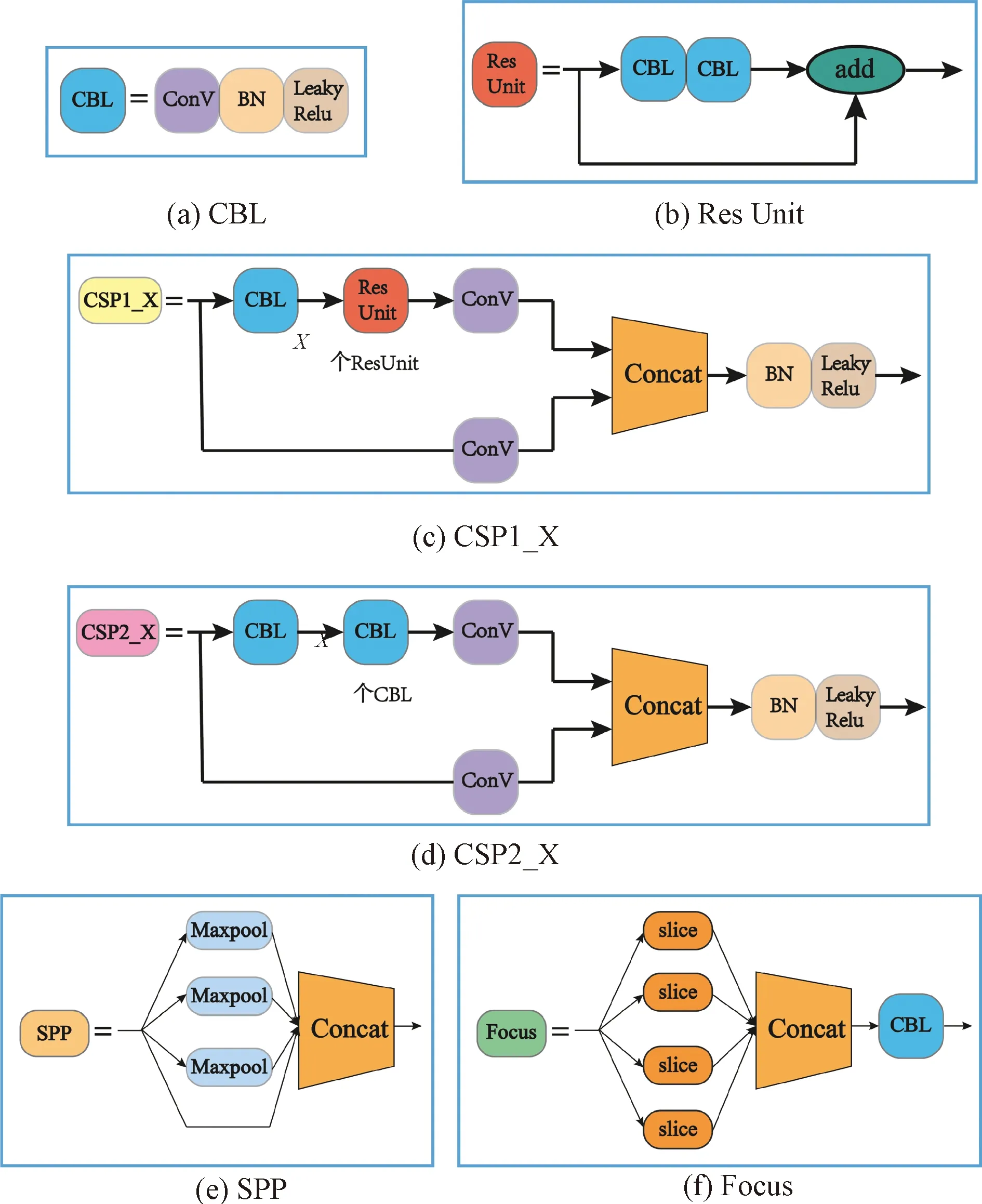
图5 YOLO-v5细部算法块
(1)ConV层,又称卷积层,其作用是提取输入图像的特征信息。
(2)BN层,又称批标准化层,其作用是对输入进行标准化处理,从而极大地抑制神经网络模型出现的过拟合与梯度弥散问题。
(3)LeakyRelu激活函数,其作用主要为在神经网络模型中引入非线性因素,使神经网络模型可以执行非线性任务。
(4)Concat层,又称拼接层,其作用主要是将两个及两个以上的特征图在通道维度进行拼接,以实现不同层次的特征信息融合。
(5)Slice运算,对输入图像进行切片操作,使Focus模块能在信息不丢失的情况下实现二倍下采样。
(6)Maxpool层,又称池化层,其作用是提高神经网络训练速度且有效防止过拟合现象发生。
2.4 损失函数
根据YOLO-v5目标检测原理与算法结构分析,YOLO-v5目标检测模型在得到最终的预测结果前,需要完成三个任务:目标物的分类、目标物预测框位置回归、目标物的置信度回归预测。因此,基于以上三个任务,YOLO-v5目标检测任务用到三种损失函数,最终的损失函数为三者之和。
2.4.1 目标分类损失函数
轨枕裂缝的目标检测模型的分类任务就是区分输入图片中的裂缝和背景,属于二分类任务,因此,本文的目标分类损失函数为BinaryCrossEntropy损失函数,其计算公式为[17]
L(f(x),y)=-[yln(f(x))+(1-y)ln(1-f(x))]
(1)
式中:f(x)为预测结果类别y的概率;y为预测的类别。
2.4.2 IoU、GIoU及CIoU原理
根据IoU、GIoU、CIoU三者的特点,同时结合轨枕裂缝目标检测的任务需要,对于预测框位置的回归任务选用CIoU为损失函数,对于预测目标置信度的回归任务选用GIoU为损失函数。GIoU、CIoU均由IoU改良而来,三者的原理及特点如表1所示。
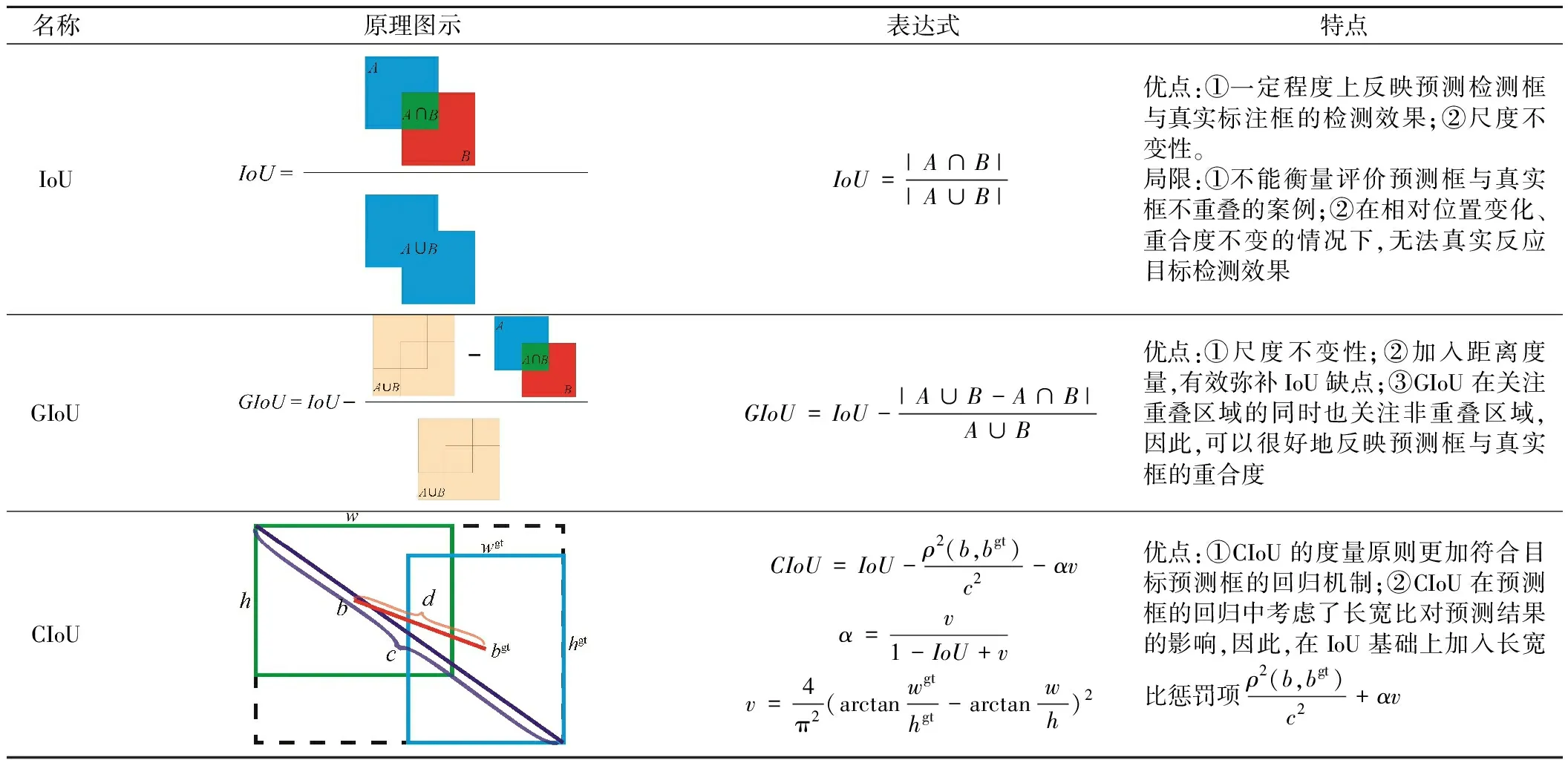
表1 IoU、GIoU及CIoU原理汇总
3 试验结果与讨论
3.1 试验环境及超参数
轨枕裂缝的目标检测数据量较大,且数据格式为RGB图像,因此,为加速YOLO-v5神经网络模型的训练与收敛,使用GPU对模型计算进行加速,YOLO-v5目标检测模型搭建与训练所需的操作环境和依赖库如表2所示。
表2 计算机参数
轨枕裂缝目标检测超参数设置如下:本文YOLO-v5模型的初始学习率为0.001,学习率调整策略选取余弦退火算法[28],优化器选用Adam优化器,图像输入批大小为16,通过Mosaic数据增强技术[29]对输入的每一批次数据进行数据增强处理,以便生成更多的训练样本,提升模型的鲁棒性和准确率。
3.2 试验结果
图6、图7为模型的运算过程曲线,由图6可得:训练集正确率最终收敛于98.75%,验证集正确率收敛于98.36%,两者的最终收敛值都较高且两者非常接近,说明轨枕裂缝目标检测模型没有发生过拟合或欠拟合现象,模型的目标预测结果准确可靠。由图7可得:训练集的损失收敛速度较快,训练集的损失值提前收敛于0.12,验证集的损失收敛速度较慢,其损失值最终也收敛于0.12附近,两者的损失最终收敛值基本一致,这也说明了本文的目标检测模型参数设置合理,预测结果准确。
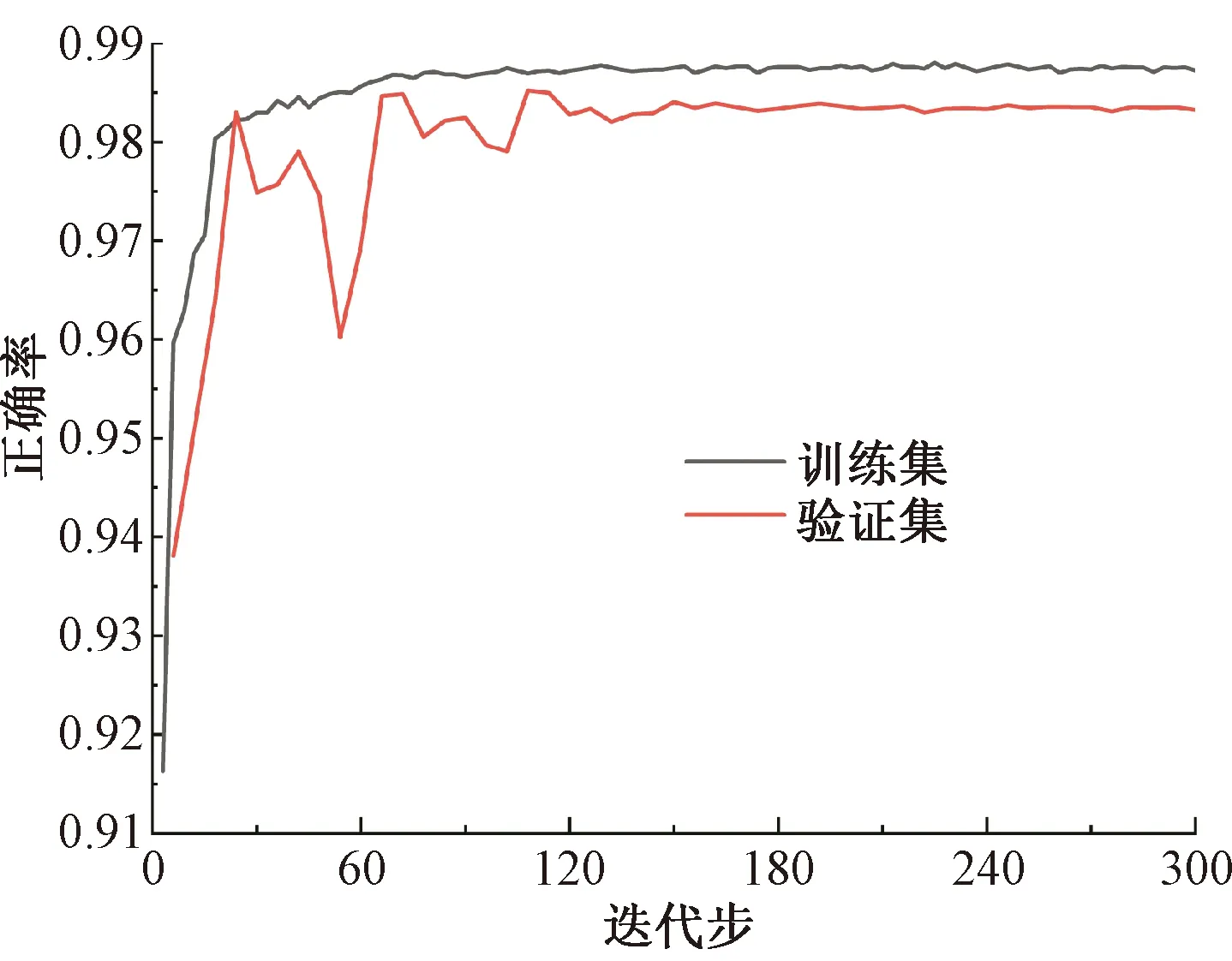
图6 模型正确率曲线
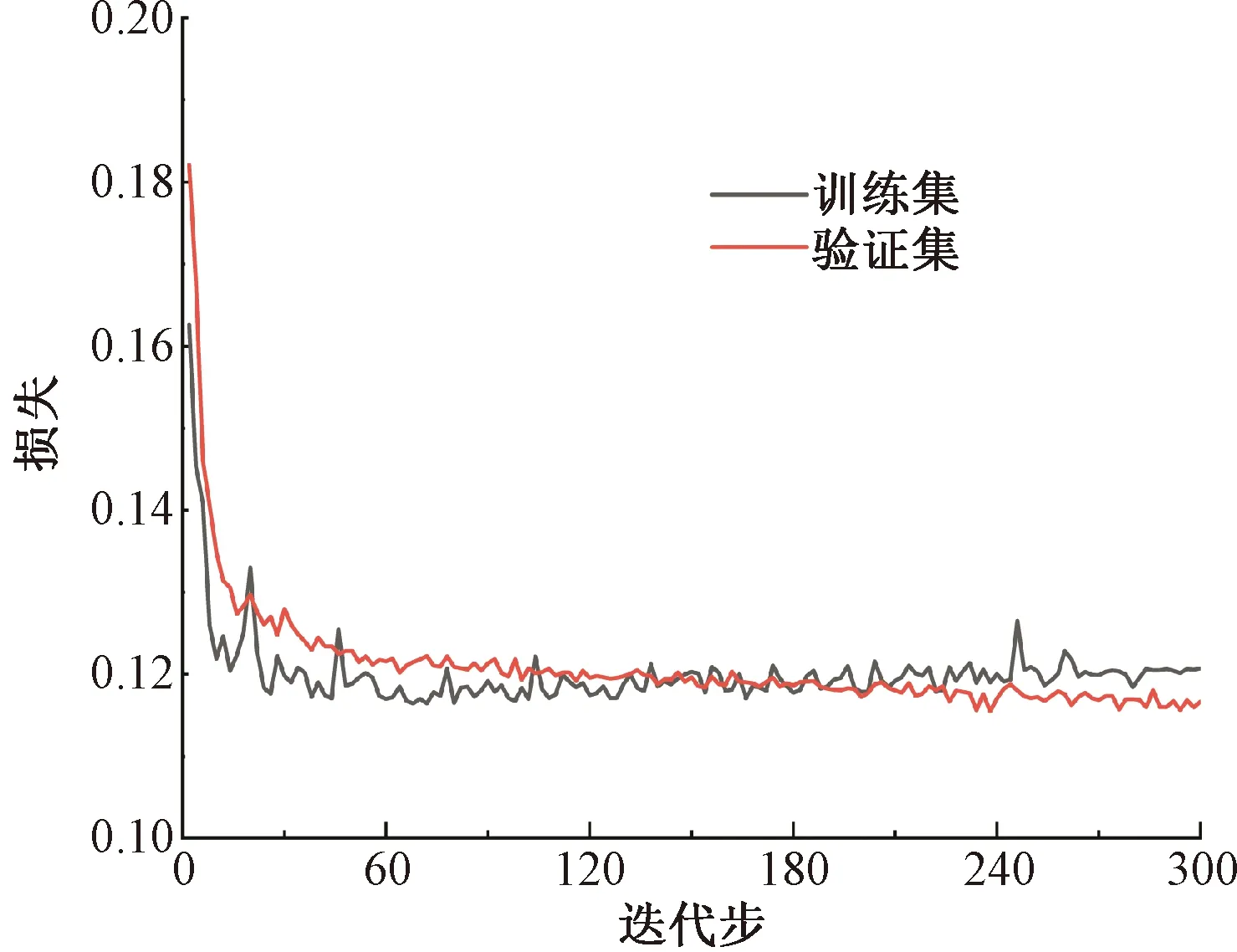
图7 模型损失函数曲线
3.3 目标检测评价
根据目标真实标注框和模型预测框的相对关系,目标检测模型的预测结果分为四种:真阳性(TP)、假阳性(FP)、真阴性(TN)、假阴性(FN)。为了评价模型裂缝检测能力的优劣,引入了模型的评价指标:PA(目标检测正确率)、mAP(平均精度)和Recall(回调),在训练YOLO-v5目标检测模型的同时,YOLO-v2、YOLO-v3、Faster R-CNN等目标检测模型也在同一数据集上进行训练,以便横向比较采用YOLO-v5的目标检测效果。
(2)
(3)
(4)
(5)
式中:p为查总率;C为目标检测任务中的类别数量;k为图片数目;N为图片总数。
YOLO-v2、YOLO-v3、Faster R-CNN及YOLO-v5在轨枕裂缝数据集上的模型性能评价结果如表3所示。由表3可得:在轨枕裂缝的目标检测任务中YOLO-v5模型表现出良好的裂缝检测能力,各项评价指标都是最优,其中PA为98.35%,mAP为48.72%,Recall为90.32%;在单张图片平均识别时间方面,由于YOLO-v5算法模型较为复杂,模型参数较多,使得YOLO-v5模型的单张图片处理时间为0.01 s,考虑YOLO-v5模型的裂缝监测结果更准确,运算时间略长在可接受范围内。
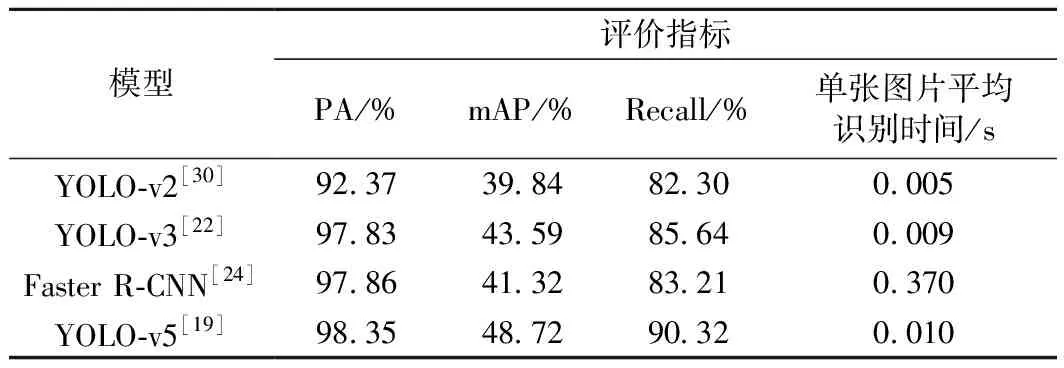
表3 目标检测模型评价分析
3.4 裂缝目标检测结果可视化
前文从模型训练过程的正确率与损失函数变化规律的角度分析,得出了模型参数设置合理、预测结果准确的结论,本节将对轨枕裂缝目标检测模型的预测结果可视化,以更加直观的方式展现YOLO-v5的裂缝目标检测结果。为体现模型的泛化能力和强鲁棒性,选取不同条件下轨枕裂缝的智能识别结果进行展示。轨枕裂缝可视化结果如图8所示。
由图8可得:对于正常光照、暗光线、微裂纹等不同条件下的原始裂缝图片,YOLO-v5轨枕裂缝目标检测模型都预测出了准确的目标检测框,这体现了YOLO-v5模型良好的泛化能力和鲁棒性,同时模型的准确预测结果可为实际铁路工程的轨枕裂缝检测与智能识别提供理论参考和算法支撑。在此需要特别说明的是:轨枕裂缝的目标检测置信度普遍不高,置信度最大为0.92,置信度最小为0.26,这一结果相较文献[22,24,30]低。事实上出现这样的结果是合理的,原因在于:本文YOLO-v5模型执行的目标检测任务为轨枕裂缝识别,而裂缝本身狭长,在整张图片中所占像素点极少,图片中模型不关注的背景反而占据绝大部分的像素点,造成裂缝图像正负样本极不均衡,裂缝检测较为困难;本文所用的裂缝数据集存在光照差、裂缝不明显、环境干扰较多等诸多问题,这些因素也会降低裂缝置信度的预测值。因此,本文的裂缝目标检测置信度较低。
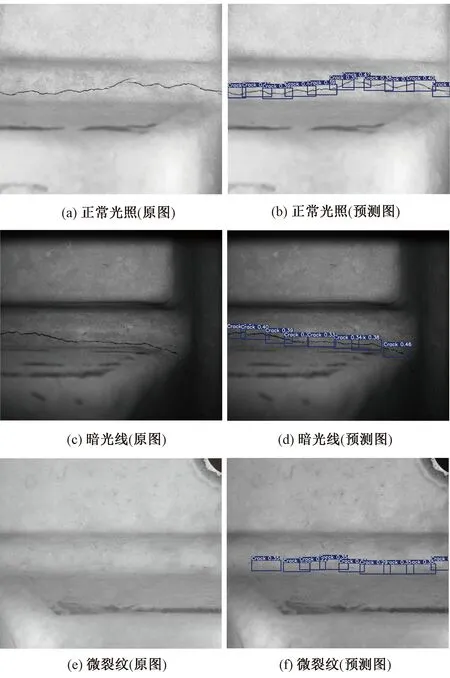
图8 轨枕裂缝智能识别结果
4 结论
基于YOLO-v5目标检测算法,建立了轨枕裂缝的目标检测模型,完成了轨枕裂缝的智能识别。主要结论如下:
(1) 将YOLO-v5目标检测模型应用到双块式轨枕裂缝的智能识别中,通过数据集标注、模型构建、参数调整、模型训练和结果预测等步骤,实现了轨枕裂缝的高精度智能识别。
(2) 通过合理的参数选取与调试,YOLO-v5轨枕裂缝目标检测的训练集与验证集准确率接近并各自收敛,模型没有发生过拟合或欠拟合现象,模型目标检测正确率为98.35%,mAP值为48.72%,Recall值为90.32%,单张图片识别速度为0.01 s,模型预测结果精确度高且裂缝实时识别性能良好。
(3) 对YOLO-v5轨枕裂缝目标检测模型在测试集上的预测结果进行可视化,结果表明:针对正常光照、暗光线及微裂纹等不同条件下的裂缝图像,YOLO-v5都能实现高精度的智能识别,YOLO-v5轨枕裂缝目标检测模型可满足实际工程中复杂工况的要求。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
铁道勘察(2022年5期)2022-09-21
铁道勘察(2022年3期)2022-08-01
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
建材发展导向(2021年15期)2021-11-05
铁道标准设计(2020年8期)2020-07-28
铁道标准设计(2020年7期)2020-07-13
意林·全彩Color(2018年7期)2018-08-13
计算机应用(2018年5期)2018-07-25
