
基于机器视觉的玉米头尾识别
2022-04-22 08:05朱旭阳唐正宁
轻工机械 2022年2期
朱旭阳,唐正宁
(江南大学 机械工程学院,江苏 无锡 214122)
玉米加工中的顺向工步多为人工完成,不仅劳动强度大而且效率低。为降低用工强度和提高生产率,可通过机器视觉识别玉米的头尾,实现玉米顺向自动化设备的研制。
目前,玉米果穗的头尾识别多用机械结构来进行区分。崔相德[1]利用玉米头尾的直径不同,通过一个介于头尾直径之间的孔洞来区别玉米果穗的头尾。但用机械结构的区分方式具有一定的复杂性和不稳定性。因此近年来,机器视觉和机器学习被众多学者用于果蔬的头尾特征识别。Lin等[2]利用基于颜色分割和二值化的机器视觉系统来识别草莓带有花萼的头端。Antoni等[3]利用激光投影对苹果进行三维重建,并利用卷积神经网络来判断其方向。田林[4]根据蒜种头尾纹理特征的不同,通过设定识别阈值来识别蒜种头尾。张万里等[5]通过莲子头尾灰度值的不同来区分莲子的头部和尾部。尚志军等[6]利用红绿色差法和阈值分割实现枳壳果梗端的识别。王侨[7]通过提取玉米种粒的外观特征和颜色特征,获取白色区域轮廓线上距黄色区域形心的最远点,完成了玉米种粒的尖端识别。机器视觉和机器学习在玉米方面的应用多为品种分类、果穗参数测量和品质检测等。Javanmardi等[8]利用卷积神经网络提取不同品种的玉米种子的特征,之后使用人工神经网络来对其进行分类。刘长青等[9]利用机器视觉实现对玉米果穗长度、果穗宽度和穗行数等的检测。李伟等[10]基于HSV颜色空间,利用滤波和形态学处理完成玉米果穗性状的检测。李颀等[11]通过提取并融合玉米种穗的颜色和纹理特征,利用SVM实现对4种异常玉米种穗的识别分类。高新浩等[12]通过小波分析算法获取图像纹理特征,结合最大熵函数判据和质量判据实现玉米品质的检测与分类。
机器视觉和机器学习在果蔬头尾识别的研究中已有相关应用,而在玉米头尾识别中还不多见。课题组提出了一种基于机器视觉和机器学习的玉米头尾识别方法。
1 识别方法与原理
1.1 图像采集与预处理
图像采集所用玉米采购自无锡农贸市场,选择穗皮完整未脱落且鲜绿无枯萎的玉米作为实验材料。采集图像时选用500万像素的OV5647摄像头并将摄像头用三角支架固定,玉米垂直正置于摄像头正下方进行采样。

图1 样本采样
图像采集和传输中常出现噪声干扰,为排除噪声的影响,需对图像进行降噪处理。因中值滤波既能够过滤掉噪声又能使玉米边缘轮廓不被滤波模糊,从而平滑图像,故使用3×3的模板对图像进行中值滤波处理。

图2 中值滤波后的图像
由于玉米图像在RGB颜色空间内对光照变化产生的阴影敏感,不利于玉米图像的分割。为消除光照阴影的影响,将玉米图像由RGB颜色空间转入HSV颜色空间,并提取H,S和V通道图像。由图3可知,S通道图像中,玉米和背景的灰度具有明显差异,故采用阈值分割的算法对S通道图像进行玉米和背景分割。由于OTSU算法是一种以目标和背景的类间方差最大为标准的阈值分割算法,能够自动确定出最佳的分割阈值,故采用OTSU算法完成图像的二值化分割。二值化图像如图4所示。
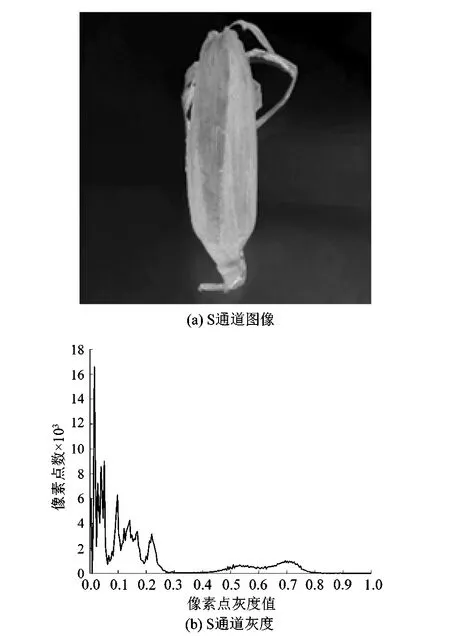
图3 S通道图像及其灰度分布直方图

图4 二值图像
初步得到的二值图像虽然较好地将玉米目标与背景分割开来,但玉米目标的边缘有些毛糙且连通域内存在大小不一的空洞噪声。为更好地对玉米目标进行分割,对初得二值图像进行3×3的十字形结构闭运算,以消除玉米目标连通域内小型空洞,平滑玉米目标的边缘。可以看出,最终的二值图像较好地对玉米图像进行了分割,如图5所示。最后,依据最终的二值图对玉米图像的灰度图进行分割,如图6所示。

图5 闭运算后的二值图像

图6 分割后的灰度图像
1.2 HOG特征提取
HOG特征是一种基于像素点的梯度大小和梯度方向的特征。该算法将图像划分为局部区域,通过计算其方向梯度直方图,并以此为基础作为图像的特征。因其具有描述目标轮廓结构的能力,又对梯度变换敏感,因此能很好地检测目标轮廓的差异,常被用于目标检测与目标识别。
为减少提取图像HOG特征时的计算量,将分割后的玉米图像压缩至100×100像素,并将图像水平平均分割为上下两部分,以玉米头端图像作为正样本,将玉米尾端图像旋转180°作为负样本,分别提取HOG特征。
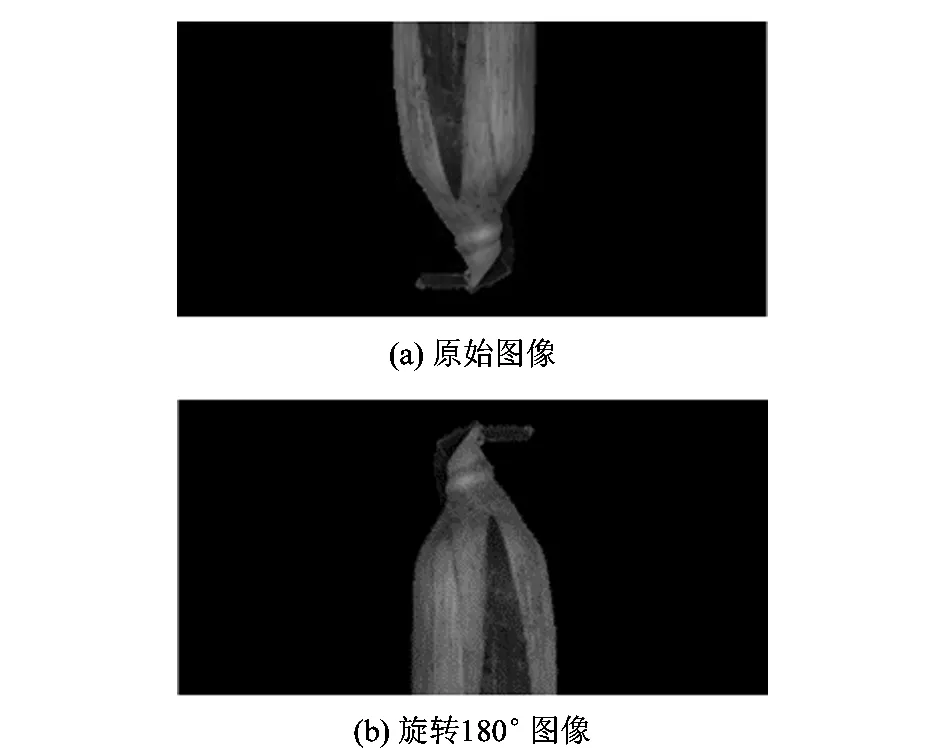
图8 玉米尾端
HOG特征提取流程如下:
1)Gamma矫正。对提取的玉米图像进行Gamma矫正能够减少光照和阴影的影响,提升图像的对比度。
2)计算梯度。对图像使用梯度算子[-1,0,1]和[-1,0,1]T分别进行卷积运算,得到水平方向和垂直方向的梯度,计算公式为:
Gx(m,n)=I(m+1,n)-I(m-1,n);
(1)
Gy(m,n)=I(m,n+1)-I(m,n-1)。
(2)
式中:Gx(m,n)为像素点(m,n)水平方向的梯度;Gy(m,n)为像素点(m,n)垂直方向的梯度;I(m,n)为像素点(m,n)的灰度值。
图像中某一像素(m,n)的梯度公式为:
(3)
(4)
式中:G(m,n)为像素点(m,n)的梯度幅值;θ(m,n)为像素点(m,n)的梯度方向。
3)构建细胞单元,计算梯度方向直方图。根据提取的玉米图像的大小,选择构建10×10像素的细胞单元。计算细胞单元内所有像素点的梯度幅值和梯度方向,并将梯度方向以20°为一个区间长度进行划分,得到bins数为9,再将细胞单元内所有像素点的梯度幅值根据梯度方向大小投到相应的bins中,即得到梯度方向直方图。由此,一个细胞单元可得到一个9维的特征向量。
4)构建块,并进行归一化。选择构建20×20像素的块,一个块中包含4个细胞单元,即包含4个梯度方向直方图。由此,一个块可得到一个36维的特征向量。为了更好地消除光照和阴影的影响,对这个36维的特征向量进行归一化处理。
5)获取HOG特征。将20×20像素的块以10像素为步长历遍整个100×50像素的玉米图像,则块水平移动9次,垂直移动4次,再将每次得到的36维的特征向量串联起来。由此,一个样本可得到一个1 296维的特征向量,并以此作为该图像的HOG特征。
1.3 PCA降维
由于提取的HOG特征是1 296维的特征向量,当特征向量的维数较多时,往往存在着数据冗余和一些噪声,同时影响着分类器的复杂程度、分类效率和分类准确性。因此需要在保留有效数据信息的前提下,对特征向量进行降维。
主成分分析(PCA)是一种常用的降维方法,其通过线性变换将高维特征运算变为低维特征,从而达到特征向量降维的目的。其过程如下:
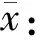
(5)
式中:P为特征样本个数;xi为特征样本。
2)由式(6)求协方差矩阵Σ:
(6)
3)求出协方差矩阵Σ的前M个特征值后按从大到小排序,并求出特征值对应的特征向量集A={a1,a2,…,aM},并按式(7)归一化所有特征向量:
(7)
式中:M为要降至的维数;ai为协方差矩阵Σ的特征向量。
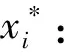
(8)
(9)
7)最终得到降维后的特征样本集Y={y1,y2,…,yp}。
某个主成分的方差与所有主成分的方差的比值称为贡献率,前M个主成分贡献率的累积称为累积贡献率。为保留数据信息的完整性,后续以累积贡献率为参照选取主成分数目。
1.4 SVM分类识别
支持向量机(SVM)是一种多用于二分类问题的分类器。它通过在高维空间里寻找一个超平面,使得2类支持向量之间的距离最大化,继而使用该超平面划分这2类,从而解决二分类问题。
设有样本集(ui,vi),i=1,2,…,N;其中ui为样本的特征向量,vi为样本标签,正样本标签为1,负样本标签为-1。设超平面方程为:
wTu+b=0。
(10)
式中:w和b为超平面参数。
则某一样本点的ui到超平面的距离d为:
(11)
通过放缩超平面方程的参数,使得支持向量到超平面的距离d*为:
(12)
于是可得出SVM的目标函数和限制条件为:
(13)
由此转为一个二次规划问题,可以求得超平面参数解w*和b*,从而得出超平面方程:
w*Tu+b*=0。
(14)
继而得出分类器f(u):
f(u)=sgn(w*Tu+b*)。
(15)
为使用SVM处理非线性问题,可引入惩罚因子C和松弛变量ξ,并通过映射函数φ(u)把样本映射到高维空间,则SVM的目标函数和限制条件变为:
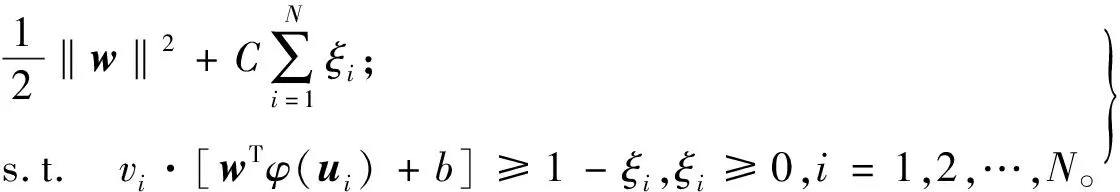
(16)
引入拉格朗日乘子α和β,并将ξi取其相反数而形成新的ξi,即可得到拉格朗日函数L:
(17)
对w,b,ξ求偏微分可得到对偶问题:
(18)
式中k(ui,uj)为核函数。
由此,可求出解α*,从而得出超平面方程:
(19)
继而得出分类器f(u):
(20)
2 试验过程与结果分析
试验在Corei5CPU、8 GiB内存的环境下进行测试。选取800幅采集的玉米图片构成数据集进行试验,其中80%作为训练集,20%用作测试集。
对数据集进行预处理,得到处理后的玉米图像,然后将图像水平分割为上下2部分,并对分割后的图像进行标记:玉米头部图像为正样本,记为+1;玉米尾部旋转图像为负样本,记为-1。由此,数据集共1 600个样本,正样本和负样本各占比50%。
对得到的分割图像提取其HOG特征,并对特征进行PCA降维。当主成分数目为150时,累积贡献率达到90%;当主成分数目为230时,累积贡献率达到95%。95%累积贡献率保留了大部分的原始数据信息,因此选取前230个主成分作为降维后的HOG特征。
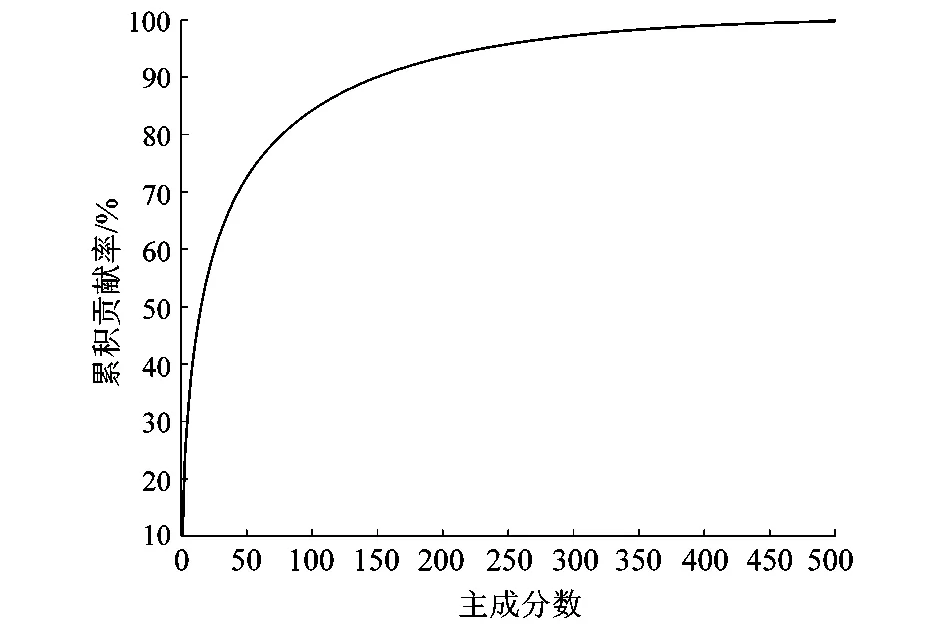
图9 主成分数目对累积贡献率的影响
为了试验核函数的选取对支持向量机分类准确性的影响,试验选取了线性核函数、多项式核函数、高斯核函数和sigmoid核函数。选取一对一的分类方式,并对支持向量机的参数进行寻优。
以高斯核函数为例,其表达式如下:
k(ui,uj)=exp(-g‖ui-uj‖2)。
(21)
式中g为高斯核参数。
对惩罚因子C和高斯核参数g设定一些选择范围,并将其两两组合,每次选取一组参数作为支持向量机的参数;再将训练集平均分为10份,选取1份作为验证集,剩余9份作为训练集;使用训练集对支持向量机进行训练,使用训练的支持向量机对验证集进行分类,得到验证集分类结果的正确率。再选取另外1份作为验证集,剩余9份作为训练集,重复上面的验证,直到10份都作过验证集,将验证集分类的准确率进行平均来作为该组参数的性能参考。历遍所有参数组合后,比较验证集分类的平均准确率以得到支持向量机的参数。
试验使用训练集降维后的HOG特征对支持向量机进行训练,然后使用训练的支持向量机对测试集降维后的HOG特征进行预测,最终得到的分类准确率如表1所示。

表1 不同核函数的支持向量机的分类准确率
为测试不同分类器对本试验的分类性能,在相同的试验环境和数据集下,选取最近邻(KNN)和随机森林(RF)对训练集进行十折交叉验证,以十折交叉验证得到的分类器对测试集进行分类的准确率作为该分类器的分类准确率,试验结果如表2所示。

表2 不同分类器的分类准确率
3 结语
课题组提出一种基于机器视觉和机器学习玉米头尾识别方法进行玉米头尾识别。试验结果表明:相比于最近邻、随机森林和其他核函数的支持向量机,使用高斯核函数的支持向量机对降维的HOG特征进行分类能够得到更高的准确率,分类准确率达到97.2%,实现了玉米头尾的有效识别。
课题组提出的方法为玉米头尾识别提供了思路和依据。试验存在样本量较小和分类器参数优化的问题,后续可增大样本量并通过其他寻优算法来优化分类器参数,从而进一步提高分类器的鲁棒性。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
计算机应用与软件(2022年4期)2022-06-24
电子产品世界(2022年4期)2022-04-21
保定学院学报(2022年2期)2022-04-07
计算机应用与软件(2022年2期)2022-02-19
中北大学学报(自然科学版)(2021年5期)2021-11-15
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
数学学习与研究(2018年15期)2018-11-12
时尚北京(2017年1期)2017-02-21
