
基于改进Yolo v5的织物缺陷检测方法
2022-04-22 08:05王恩芝张团善
轻工机械 2022年2期
王恩芝,张团善,刘 亚
(西安工程大学 机电工程学院,陕西 西安 710613)
织物表面缺陷检测是织物质量控制过程中一项关键步骤。由于织物样式不一、种类繁多,给织物检测算法研究带来困难。长期以来,纺织厂中织物表面存在的缺陷都是通过工人手工检测。据统计人工验布速度约为12 m/min,由于各种干扰因素,验布员能专心验布时间一般只能达到20~30 min[1]。为提高工厂生产效率,降低劳动成本,自动表面缺陷检测已经变得越来越普遍。随着计算机计算力提高和软件技术的迅速发展,卷积神经网络[2]也卷起了一阵热潮,计算机视觉中的深度学习的方法在近几年也达到了非常先进的水平,成为许多难以解决问题的一个端到端的解决方案。
针对纺织行业织物表面出现缺陷的问题,大量学者提出不同的织物缺陷检测算法,主要分为基于传统的图像处理与机器学习相结合的方法、深度学习的方法。基于传统的图像处理与机器学习结合的方法又可分为:基于频谱、模型和统计等方法[3]。传统缺陷检测的方法首先对图像进行预处理提高图像质量,再通过傅里叶变换或小波变换等方法人为设计特征或提取特征,最后利用机器学习的方法对提取出的特征进行分类、识别。朱浩等[4]提出了一种多纹理分级融合的方法,通过计算缺陷区域与正常图像块特征的相似度,得到2者相似图,将初步定位的缺陷区域的经纬向特征图与相似度特征图进行融合,检测缺陷存在区域。该方法只对具有较强周期性纹理的织物有效,当算法面对纹理差异性大、缺陷形态复杂、种类多样的情况,传统的机器学习检测算法容易出现漏检或错检等情况。张团善等[5]设计了一种较多噪声干扰的情况下的防羽布疵点检测算法,通过设计基矩阵并计算其差异矩阵,与疵点因子进行比较获得缺陷二值图,但此方法只适用无色差且密度较高的纯色防羽布,具有复杂图案的织物难以检测。基于深度学习的方法通常使用卷积神经网络进行特征提取,在应用分类器或者检测头对缺陷区域进行检测。安萌等[6]基于Faster R-CNN设计了一种新的网络框架,通过在候选框提取网络(region proposal network,RPN)中引入不同尺度的特征金字塔结构,增强网络提取细节特征的能力,但Faster R-CNN是一个二阶段检测网络,速度无法达到实时检测缺陷的效果,无法满足工业检测速度。针对织物缺陷检测过程速度慢的问题,周君等[7]提出了一种基于S-YOLO v3模型的织物实时缺陷检测算法,通过利用批归一化(BN)层的缩放因子评估每个卷积核对于神经网络的权重,对神经网络进行剪枝,设计一种轻量级的模型实现织物的实时检测,但该方法精度只能达到94%,对于工厂该精度仍需提高。
针对以上算法存在的问题,课题组设计了基于改进Yolo v5的织物表面缺陷检测方法,可以在满足工厂检测精度要求的同时满足检测实时性要求,实现纺织行业检测自动化。
1 织物缺陷检测模型
目标检测算法分为2种框架:一种是一阶段检测算法(one-stage)直接设计一个端到端的提取特征、目标检测的框架,例如Yolo[8-11]系列和SSD[12]网络等;另一种是二阶段检测算法(two-stage),在进行目标识别过程中,需要首先对区域框进行检测,例如R-CNN[13-15]系列网络等。Yolo系列网络是目前最主流且效果最好的基于锚框(anchor)的目标检测算法之一。最新的Yolo v5[16]项目应用多种多样,也证明了Yolo v5算法的有效性。为提高Yolo v5网络的性能,课题组在网络的骨干网络(backbone)阶段引入卷积注意力机制(concolutional block attention module,CBAM)[17]通过对像素从语义和空间信息分别进行评分,抑制对检测不重要的特征。在金字塔注意力结构(pyramid attention network,PANet)之后引入自适应空间融合(adaptive spatial feature fusion, ASFF)[18]的方法,抑制梯度反传过程的不一致,增强网络检测精度。
1.1 Yolo v5基础结构
Yolo v5是目前YOLO系列算法的SOTA(state-of-the-art),与其他的目标检测算法一样由输入、骨干网络(backbone)、特征融合(neck)、预测(prediction)结构组成。Yolo v5包含4种不同宽度和深度的模型,分别为Yolov5s,Yolov5m,Yolov5l和Yolov5x。借鉴EfficientNet[19]的方法,通过一个常数平衡网络所有维度的宽度和深度。本研究的任务是织物缺陷检测,为满足工业上准确率的要求,在网络结构尽可能小的情况下,实现更高的精度和更快的检测速度,课题组以Yolov5l为研究对象。Yolo v5网络结构如图1所示。
Yolo v5为增强网络模型的鲁棒性和泛化性能:在输入端引入Mosaic数据增强,自适应锚框计算,自适应图像缩放和可适用于各种尺寸的图像输入;在backbone阶段引入一种新的Focus结构。Focus结构对图像进行切片,并在通道方向进行拼接,有效减少了信息丢失。Neck部分使用特征金字塔网络(feature pyramid networks,FPN)+PANet,FPN通过上采样将高层特征信息与底层特征进行融合,传递更强的语义特征,增强网络模型学习图像特征的能力,但可能丢失一些定位信息。PAN对FPN获得的图像通过自下向上传递强的定位信息,将两者同时使用达到互补效果,增强模型的特征融合能力,提高了模型的鲁棒性。
1.2 改进的Yolo v5结构
1.2.1 主干网络改进
为提高主干网络对目标的特征提取能力,课题组在backbone阶段引入软注意力机制(soft-attention)中的卷积注意力机制模板(convolution block attention module, CBAM),该模块可以在空间维和通道维分别推断出注意力的权重,使网络能够关注到图像中关于目标的重点信息。如图2所示,新的主干网络在每一个跨阶段连接网络(cross stage partial,CSP)结构之后引入一个CBAM模块。
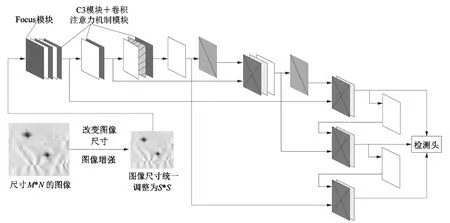
图2 改进backbone的Yolo v5结构
CBAM分为空间注意力机制(spatial attention)和通道注意力机制(channel attention),分别从空间维和通道维增强对目标的关注程度。通道注意力模块对输入特征图分别进行全局最大池化和全局平均池化聚合图像的空间信息,经过2个多层感知机结构构建模型之间的相关性,最后经过Sigmoid激活函数获得每一个通道的权重,通道注意力机制如图3所示,表示形式:

图3 通道注意力机制模块

空间注意力模块将通道注意力模块中的输出作为本模块的输入特征图。首先对输入特征图做一个基于通道的全局最大池化和全局平均池化;然后将2个单通道特征图进行通道间拼接,而后通过一个分辨率为7×7的卷积对特征图进行降维获得一个单通道特征图,便于最后特征融合;最后经过Sigmoid激活函数获得图像空间位置的每一个特征权重。空间注意力机制如图4所示,表示形式为:

图4 空间注意力机制

1.2.2 特征融合阶段改进
为了更加充分利用网络中高层特征的语义信息和底层特征的空间信息,课题组在Yolo v5的Neck阶段引入自适应空间特征融合(adaptive spatial feature fusion,ASFF),分别对PANet输出的3个水平特征图进行加权融合,通过增加可学习的参数抑制了梯度反传过程的不一致,充分利用不同尺度的特征。修改后的自适应空间特征融合的Neck如图5所示。
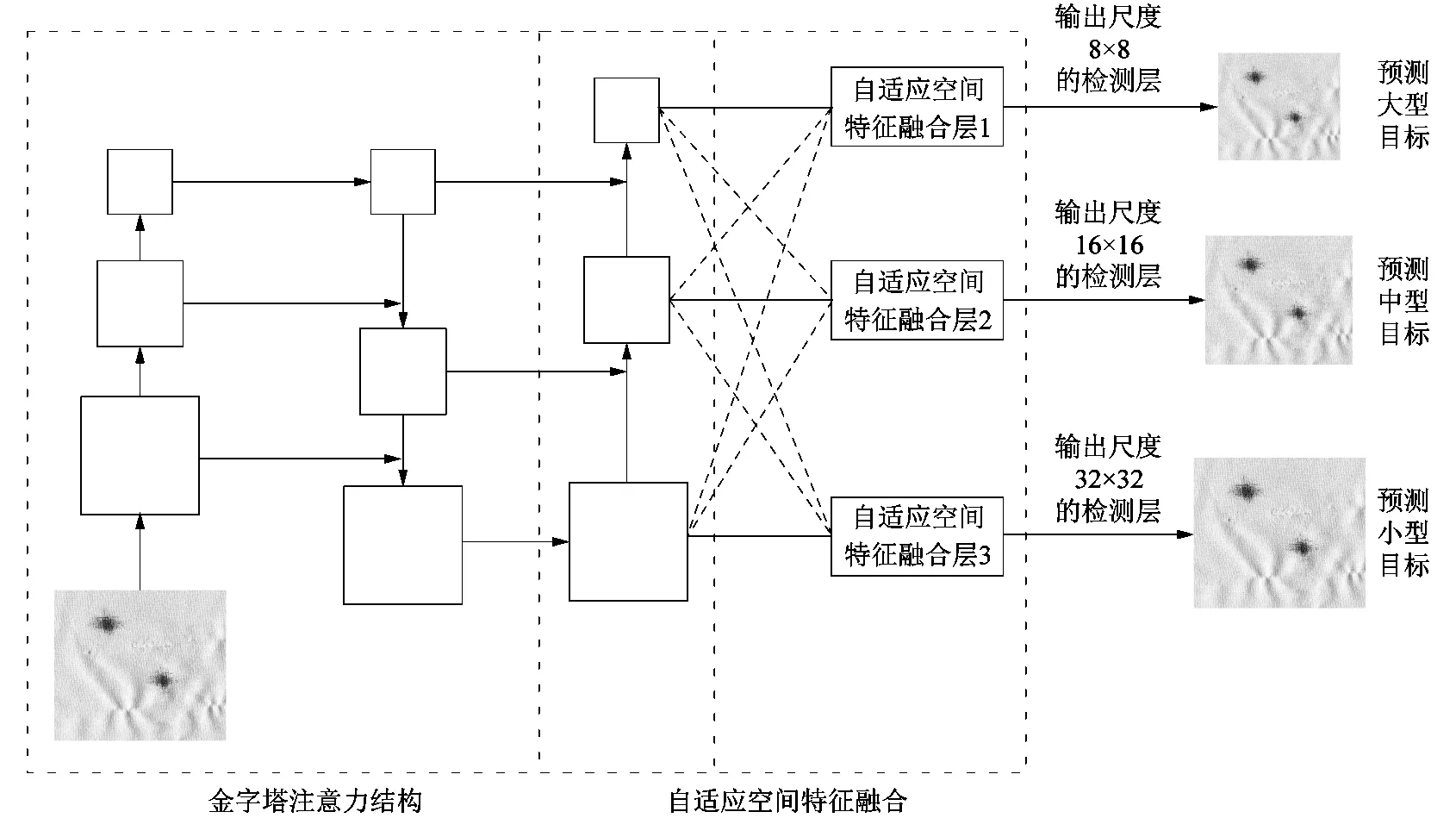
图5 自适应空间特征融合Neck
改进后的Yolo v5模型如图6所示,输入图像首先经过由CBAM增强的backbone提取特征,然后对特征图应用FPN+PANet+ASFF进行特征融合,充分利用特征图中高层语义信息和底层空间信息,最大限度获得目标信息,而后将获得的特征图送入检测头中,检测头分别输出3个尺度8×8,16×16和32×32的输出检测层,分别用于检测大、中和小3种目标。

图6 改进后的Yolo v5模型
2 实验及结果分析
2.1 软硬件环境
实验中采用的硬件配置:CPU为Intel(R)Core(TM)i9-9900K,主频为3.60 GHz,内存为32 GiB,显卡为NVIDIA;软件配置为Win10操作系统,显卡驱动为NVIDIA GeForce RTX 2080Ti和CUDA10.1,深度学习框架采用PyTorch-1.7.1,使用LableMe作为标注工具,编程语言为Python3.7。
2.2 网络训练
本算法的验证数据集使用工业CCD相机获取,手动采集3 000 张图片,图像包含复杂纹理的织物和简单纹理的织物,且样本表面至少存在一种缺陷,手动裁剪为尺寸256像素×256像素,部分具有缺陷的织物样本如图7所示。深度学习网络模型的训练数据都是基于大量数据驱动,为增强模型的鲁棒性和泛化能力,对采集到的图像随机进行旋转、缩放,及改变样本的亮度、色度和饱和度,将原来的3 000张图像扩充为10 000张图像,随机选取7 000张图像作为训练集,2 000张图像作为验证集,1 000张图像作为测试集。数据集中分别包含毛边、孔洞(包括擦洞和破洞)、黄渍、断经纬、滴墨和破损6种缺陷。

图7 部分含有缺陷的织物样本
经过多次实验,初始学习率设为0.001,迭代300代之后学习率调为0.000 1,批大小为16,权重衰减系数为0.000 5,动量为0.937,优化器使用随机梯度下降,总训练次数为1 000。
2.3 算法改进前后对比
考虑到工厂中的实际应用,课题组采用准确率(precision)和均值平均精度(mean average precision, mAP)作为模型的评价指标。Precision能够准确、合理地评价算法的定位和目标检测能力;使用PmA来衡量网络的算法性能,适用于本研究的多标签缺陷图像分类任务,并将改进后的网络与常用的SSD网络进行结果比较,公式如下:
式中:TP表示本该是正样本的样本被算法认为是正样本,预测正确;FN表示本该是正样本的样本被算法认为是负样本,预测错误;N为测试集中样本总数;P(n)是在同时识别n个样本时的大小;ΔP(n)表示召回率在检测样本的个数从n-1变为n时的变化情况;C为多分类任务中类别个数。
算法改进前后结果如表1所示。

表1 算法改进前后结果比较
图8所示为改进之后的网络模型检测结果,从效果图看,改进的算法对毛边、孔洞、黄渍、断经纬、滴墨、破损6种缺陷检测精度较高,经测算达98.8%。

图8 改进模型检测结果
3 结论
课题组针对织物表面存在缺陷,传统方法检测率低、泛化性能差且实时性低的问题提出一种基于改进Yolo v5算法的织物缺陷检测算法。实验结果表明:在Yolo v5基础网络中增加卷积注意力机制和自适应空间特征融合可以提高模型对缺陷目标的关注程度,并增强语义信息与空间信息的融合程度,在检测速度仅降低17 帧/s的情况下将疵点检测的准确率提高至98.8%。课题组设计的织物缺陷检测算法实时性高、且准确率高,能够满足实际工厂要求。该算法仍然严重依赖大量具有多样性的样本,设计一种基于小样本的织物表面缺陷检测算法是下一步的研究重点。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
纺织标准与质量(2022年3期)2022-08-10
小雪花·成长指南(2022年1期)2022-04-09
纺织科学研究(2021年7期)2021-12-02
纺织科技进展(2021年5期)2021-07-22
甘肃教育(2020年22期)2020-04-13
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
第二课堂(课外活动版)(2016年2期)2016-10-21
西南学林(2011年0期)2011-11-12
