
基于GLSTM和Attention的中文事件要素提取
2022-03-22 03:36:10曹渝昆
计算机工程与应用 2022年6期
曹渝昆,孙 涛
上海电力大学 计算机科学与技术学院,上海 200090
事件抽取是信息抽取中的一项分支任务,旨在从文本中提取出可以描述事件的触发词和要素[1]。例如,给定一句话,则其指示词与事件要素如图1所示。

图1 事件抽取示例Fig.1 Example of event extraction
事件信息抽取任务一般分为事件触发词的抽取和事件要素的抽取。相比触发词而言,事件要素更难识别和提取,主要的分析方法是通过神经网络来进行多元分类,主要分为两个部分,特征选择和分类模型。事件要素类似命名实体,而事件要素抽取类似命名实体识别,而且针对人名、地名和时间的识别技术已经相对成熟。事件要素的定义会根据事件类型的不同而不同,要求和数量都有更高的要求。对中文事件要素抽取的研究,有利于扩大实体识别的范围,同时也有利于相关方向如知识图谱的研究。
特征选择方面,主要分为词法特征和句法特征。通常采用词嵌入、位置信息作为词法特征,从上下文中采集信息作为句法信息。现有的研究中选用了不同的方法来抽取特征,在特征的表示方式和不同特征的结合方式上也有不同。分类模型方面,通常采用Softmax、条件随机场(conditional random fields,CRF)[2]和支持向量机(support vector machine,SVM)等方式对候选示例进行标记。现有的研究表明,词法特征与句法特征的嵌入,能明显提升事件要素抽取的效果。但是也存在一些问题,比如如何选择词法特征与句法特征,位置信息、距离特征等需要预训练,实体信息和事件类型特征等需要人工标注,且并不同适用于中文事件抽取环境。
中文在句法和词法的表达上与英文所有不同,在抽取词法与句法特征上所用的方式也不同。英文事件抽取任务中,可以通过位置信息,相对距离特征来帮助事件要素的确定和抽取,但是在中文事件抽取任务中,这些特征的所取得的效果并不明显。由于中文事件要素的抽取更类似于命名实体识别,在中文事件抽取任务中,往往依靠Bi-LSTM来捕获语法特征,进而抽取事件要素,而Bi-LSTM与CRF结合的模型在实体识别上取得了非常好的效果。近年来,随着transformer的兴盛,Self-attention也被应用于中文事件抽取,从而提升了事件要素抽取的效果。但是Self-attention仅仅能捕获词与词之间的相互关系,无法捕获词在整个句子中所表现出的特征。
本文采用Word2vec预训练的词向量作为词法特征,并以数据集本身为语料训练出句向量作为句法特征,通过Multi-head Attention[3]将每个词都注意到句子上,得到一种兼具词法特征和句法特征的融合特征,在获得多样性特征的同时,保证了特征的完整性。融合特征以词嵌入的形式输入到序列标注模块中,本文采用双向GLSTM来计算每个词对应每个标签的分数,并通过Softmax转换成置信度,最后通过CRF得到合理的标注结果。
本文的主要贡献在于:
(1)采用Word2vec训练的词向量作为词法特征,并以数据集本身为语料计算的句向量作为句法特征,以满足中文文本的特征要求。
(2)采用Multi-head Attention将普适性词法特征聚焦于具有事件特色的句法特征上,以满足事件要素提取的特征要求。
(3)采用GLSTM捕获上下文信息,从向量维度出发,横向分组提取要素特征,强化特征的效果,以提升事件要素抽取的准确率。
1 相关工作
事件要素抽取技术的研究中,主要可以分为特征选择和分类方式两个方面。
在特征的表示方式上,2015年Chen等[4]提出的DMCNN模型中,句法特征的输入由三部分组成,表示上下文的词向量特征、用于表示与候选词相对位置的位置特征和用于表示事件类型的事件特征,将这三部分拼接并通过动态多池化卷积构成最终的句法特征,词法特征则由预训练的词向量表示;2018年Björne等[5]在TEES系统上进行的事件抽取研究中,采用了多种特征,包括Word2vec预训练的词向量、BLLIP解析器生成的词性表示、实体特征、距离特征、相对位置特征、路径嵌入和最短路径嵌入等;2018年Liu等[6]提出的JMEE模型中,将Word2vec预训练的词向量、词性表示、实体类型标签和相对位置表示拼接到一起作为嵌入;2020年Shafieibavani等[7]提出的全方位事件抽取方法中采用Word2vec预训练的词向量为主体,拼接相对位置表示以及距离特征,作为词嵌入表示。
可以看到,现有的研究中,特征选择上主要采用位置特征、实体类型和词性表示等,并且将这些特征拼接到词向量上作为模型的输入。这些特征或依赖大量的人工标注,如实体类型、词性;或不适用于中文文本,如相对位置、距离特征。而在结合方式上,大多数模型采用简单的拼接,以将特征体现在输入向量表示中,然而简单的拼接并不能让特征足够明显,除非像DMCNN模型中那样对每个部分单独聚焦。
在分类标记方式方面,2017年Kusa等[8]总结了几种经典的分类模型,并进行了全面的对比,其中包括support vector machines(SVM)、decision tree(DT)、decision tree(RF)、multinomial Naive Bayes(MNNB)、multi-layer perceptron(MLP);DMCNN模型中采用了Softmax分类器进行最后的标记;Elaheh等采用了一层卷积加最大池化进行特征提取。
在分类标记方式上,现有的模型大多采用机器学习方法,而对于序列分析,本文提出的模型采用深度学习和机器学习相结合的方式,实验证明,其效果比单纯的机器学习方法要好。
在2018年Yang等[9]提出的DCFEE中,Bi-LSTMCRF模型来进行句子级事件要素的抽取,并将识别出的结果作为特征进行文档级的事件抽取。在2019年Zheng等[10]提出的Doc2EDAG中,作者也赞同该模型在实体识别和句子级事件要素抽取方面的有效性。可以看出,神经网络可以有效提取中文句子中的语法信息。但是,仅仅靠Bi-LSTM提取出的信息显然是不够准确的,因此2018年Cao等[11]提出通过Self-attention来捕获词与词之间的长期依赖关系,并与Bi-LSTM相结合来提高中文实体识别的效果。相应地,在事件要素抽取任务中,本文除了需要考虑词与词之间的相互关系,还考虑了解词在句子中所表现的特征,才能更准确地识别词所代表的角色。
2 模型介绍
2.1 模型框架
本文模型分为两个部分,基于Attention机制的词嵌入,将预训练的词向量和句向量相融合,保证了特征的多样性和完整性;基于分组长短期记忆网络(grouped long-short term memory,GLSTM)[12]和CRF的序列标注,将深度学习与机器学习相结合以提升序列标注的效果。模型框架如图2所示。

图2 模型框架图Fig.2 Framework of model
词嵌入部分采用Word2vec来训练词向量,取维基百科语料作为预训练的语料库,使词向量本身具有普适性,并且词与词之间保持紧密的联系;采用实验数据集本身作为句向量的训练语料,使句向量带有上下文的信息之外,还包含更明显的突发事件特征;采用Multihead attention将每个元素注意到其所处的句子上,使词嵌入包含两者的特征。
序列标注部分采用GLSTM来计算一个词对应每个标签的概率,通过Softmax函数转化为得分并输出;CRF接收GLSTM算得的概率,计算不同条件下序列组合的得分,将得分最高的一组序列作为最后的输出。
模型中每一层的具体功能将在2.2~2.4节中详细说明。
2.2 基于Attention机制的特征融合
特征融合部分采用Multi-head attention将句法特征融合到词法特征中。
首先,采用N-gram模型来训练词向量,训练语料为维基百科,训练结果为包含普适性词特征的输入向量,则词向量为:

式中,n为词向量的维度。
文本可表示为:

式中,W表示词向量构成的矩阵;m表示批次大小;i表示句子的长度。
然后,句向量的训练采用文本本身为训练语料,使句向量带有上下文的信息之外,还包含更明显的事件特征,句向量可表示为:

式中,S表示句向量构成的矩阵;m表示批次大小;i表示句子的长度。
最后,采用Multi-headed attention的方式融合词向量与句向量。由于词本身包含了普适性的词特征,当其注意到带有事件性质的句子上时,两种特征不会互相抵消或覆盖,而会使词向量的特征向突发事件聚焦,从而更符合事件提取的要求。
Multi-headed attention模型是由放缩点积注意力机制(Scaled dot-product attention)[13]模型演变而来,Scaled dot-product attention在相似度计算上表现非常出色,其表达式为:

其中,Q表示由查询向量组成的矩阵,K表示键向量组成的矩阵,V表示值向量组成的矩阵,dk为矩阵K的维度。将查询向量乘上键向量,可以得到该查询向量对每一个键向量的得分,将每个score经Softmax处理成概率再乘上值向量,可以得到查询向量对每一个键向量的相似度。
Multi-headed attention可以将整个句子分为多个部分,并允许模型在不同的句子部分中学习到相关的信息,对应于事件抽取任务中,可以让词关注到句子的不同部分,从而使不同的事件要素关注到其所处的句法位置。
将词向量设置为查询向量,句向量设置为键向量,为了使维度对应,将句向量复制,使句矩阵和词矩阵大小相同。使用多个head以及不同的权重组合得到和相同数量但值不同的Query、Key和Value。其中,向量的维度为300,每个head的维度为100,相当于将词分别对句子的三个部分进行注意,通过训练权重来得到最合理的特征表示。
由得到的多个Query、Key和Value分别计算出对应词做多次Attention的新特征矩阵Zi,则:

式中,W0为整个Multi-headed Attention的外部权重矩阵,ci表示经过融合之后的词向量表示,其维度为n;m表示批次大小;i表示句子长度。
2.3基于GLSTM的置信度评价
LSTM(long short term memory,长短期记忆网络)可以有效处理序列信息。将词向量的序列(c1,c2,…,ci)作为输入,并得到一个输出序列(h1,h2,…,hn),输出序列捕获的是输入序列在当前时间的信息。一个GLSTM(Group-LSTM)单元每组由一个LSTM子单元组成,其中每个子单元在输入的均匀大小的子向量上操作,并产生输出的均匀大小的子向量,其作用在于减少训练参数同时可以加快训练速度。
GLSTM单元可表示为:

采用双向GLSTM计算得出句子中第t个词左侧的信息hlt,以及它右侧信息hrt,将左右侧的输出拼接起来得到最终的输出结果。
通过多头注意力机制融合了句子特征的词嵌入依旧无法满足事件要素抽取的需求,因此,考虑加入上下文信息来提高事件要素的识别效果。
将词嵌入输入到双向GLSTM中得到每个词对应每个标签的分数,将分数输入Softmax层中可以得到词获得每个标签的置信度,即当前的词获得每个标签的概率。

式中,j表示标签的数量;m表示批次大小;i表示句子的长度。
GLSTM部分输出的是一个得分,用于表示每个元素被标记为各种角色的可能性,CRF部分重新将词构成不同的序列,通过确认标签之间的关系来重新评分,最后输出得分最高的标签序列进而确认元素对应的角色。
2.4 标签体系定义
在标签体系方面,由于BIO(B-begin,I-inside,O-outside)标签体系的精度能达到要求,而且训练复杂度相对较低,因此选择该体系来序列标注。在中文中,每个元素是由一个词组来表示的,BIO标签体系将一个元素中的字标记为“B-X”“I-X”或“O-X”。其中,“B-X”表示当前的字所在的词组属于X类型并且这个字在当前词组的开头,“I-X”表示当前的字所在的词组属于X类型并且这个字在当前词组的中间位置,O表示这个字不属于任何类型的元素。
在本模型的标签定义中,数据集内凡是带有Event、Denoter、Time、Location、Participant和Object标记的词,词中第一个字重新标记为B-Event、B-Denoter、B-Time、B-Location、B-Participant和B-Object,词中剩余的字重新标记为I-Event、I-Denoter、I-Time、I-Location、I-Participant和I-Object,两位以上连续的数字合并到一起标记,其他没有标记的词一律标记为O,包括标点符号。
3 实验与结果分析
3.1 数据集及实验环境
中文突发事件语料库是由上海大学(语义智能实验室)所构建[14]。该语料库根据《国家突发公共事件总体应急预案》所提出的分类体系,通过网上广泛搜索,收集了5类突发事件,事件以新闻报道的方式表达,分别为地震、火灾、交通事故、恐怖袭击和食物中毒。通过对生语料文本进行处理、分析、标注等,最后形成标准的标注语料存入语料库中,共计332篇。该语料库包含了六种标记:Event、Denoter、Time、Location、Participant和Object。其中,Event表示事件的开始;Denoter为事件的触发词;Time、Location、Participant和Object为事件的4个要素,并且每个要素也有更细致的分类。语料库以XML文件构建,形式类似ACE2005数据集,但是更针对中文的语法习惯和结构,也更详细。
本文在Tensorflow平台上构建了模型,将数据进行预处理,共整理出2 027句话,共91 221个标记字符(包括标点符号),其中90%作为训练集,10%作为测试集,批次大小设定为16,并采用Adam优化器,最终的结果取F1分最高时的测试结果。
实验共分为两组,分别为采用不同LSTM单元的实验效果比较和与基线模型的比较。比较分为两个方面,评估标准上的比较用以说明模型的事件抽取能力,训练过程的对比图用以说明模型的性能。
3.2 采用不同的LSTM单元效果比较
如表1所示,在嵌入层相同的情况下,比较不同LSTM单元的实验效果。

表1 采用不同LSTM单元对比分析结果Table 1 Comparison of different LSTM units
独立循环神经网络(independently RNN,Ind-RNN)[15]和独立循环长短记忆网络(independently recurrent LSTMs,Indy-LSTM)[16]是LSTM的两种最新的改进算法,其作用都是通过降低过拟合以获得更好的效果。传统LSTM单元的抽取效果仅次于本模型采用的GLSTM,由此可以看出,事件要素之间的相互关联很紧密,独立性质的算法不适合用于事件抽取任务。从实验结果可以看出,AGCEE采用的GLSTM取得的效果最好。
实验记录了每个模型在四个评估指标上的训练过程,并按四个评估标准分开制图,以对比模型性能,对比结果如图3~图5所示。

图3 不同LSTM单元的准确率训练结果Fig.3 Precision training results of different LSTM units

图4 不同LSTM单元的召回率训练结果Fig.4 Recall training results of different LSTM units

图5 不同LSTM单元的F1分训练结果Fig.5 F1 score training results of different LSTM units
如图6所示,神经网络单元在准确率上的训练效果差不多,但是在召回率上的差异比较大,特别是Ind-RNN单元,整个过程震荡较大,说明该单元对数据特征的把握不够精确,虽然在准确率上与其他几种单元相差不多,但是在覆盖程度上的表现来看,容易顾此失彼。相比较而言,传统的LSTM和Indy-LSTM的训练过程都比较平缓,各项指标都在稳步上升。AGCEE采用的GLSTM,在各项指标上都优于另外三种单元,训练过程平稳且规律。

图6 不同LSTM单元的正确率训练结果Fig.6 Accuracy training results of different LSTM units
3.3 与基线模型比较
如表2所示,基线模型采用预训练的词向量为输入,通过Bi-LSTM和CRF结合的方式进行标注[17],后面三种模型都采用了Bi-GLSTM和CRF结合的方式进行分类标注,不同的是,第二种模型将句向量与词向量拼接作为输入,第三种模型在词句拼接之后通过Selfattention对词嵌入进行特征的优化,最后一种模型是本文提出的AGCEE。

表2 与基线模型对比分析结果Table 2 Comparison result with baseline model
从实验可以看出,仅将句向量作为句法特征拼接到词向量后面,模型的整体评估结果有所提升,但提升非常有限,在精确度方面甚至有所下降。
Self-attention可以有效捕获词与词之间的依赖关系,对事件抽取而言,除了可以提高词语的完整性,可以捕获事件要素之间的依赖关系,实验表明在词句向量拼接的基础上,增加Self-attention可以有效提升事件抽取的效果,特别是在召回率上提升明显,说明Attention机制可以有效提升事件要素抽取的覆盖率。
AGCEE基于Multi-head attention构建了包含词法和句法的融合特征,并采用Bi-GLSTM和CRF向结合的方式进行分类标注,从实验结果中可以看出,本模型取得了最好的事件要素抽取效果,准确率、召回率、F1分和精确度都有提升。
实验记录了每个模型在四个评估标准上的训练过程,并按四个评估标准分开制图,以对比模型性能,对比结果如图7~图9所示。
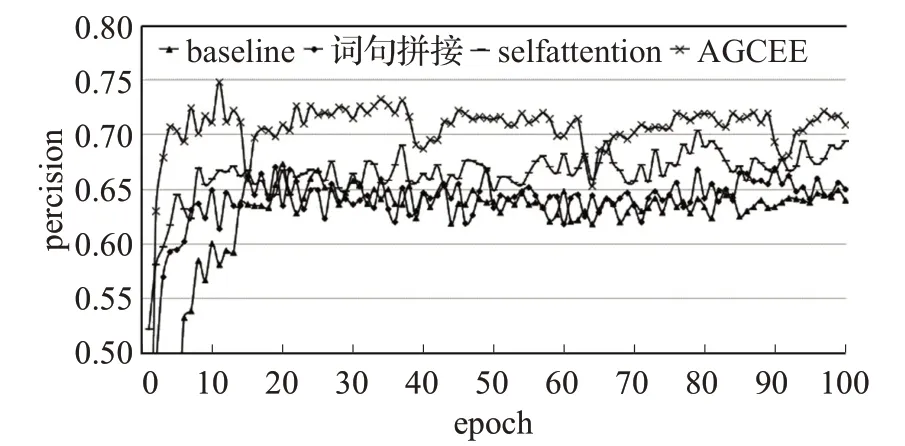
图7 不同模型的准确率训练结果对比Fig.7 Precision training results of different models

图8 不同模型的召回率训练结果对比Fig.8 Recall training results of different models

图9 不同模型的F1分训练结果对比Fig.9 F1 score training results of different models
如图10所示,将整个训练过程分为上升阶段与平稳阶段,可以明显区分两个阶段的点称为转折点。可以看到,基线模型在第20个epoch时出现转折点,之后的测试结果围绕这个值上下浮动,并趋于平稳。在增加了句法特征之后,模型在第15个epoch出现转折点,并且在第80个epoch后有一段小幅提升。增加self-attention之后,模型在第10个epoch出现转折点,在第50个epoch后有一段幅度较大的提升,然后趋于平稳。AGCEE在第15个epoch时出现转折点,此外,从图中还可以明显看出15~40、40~65、65~90三段提升过程。
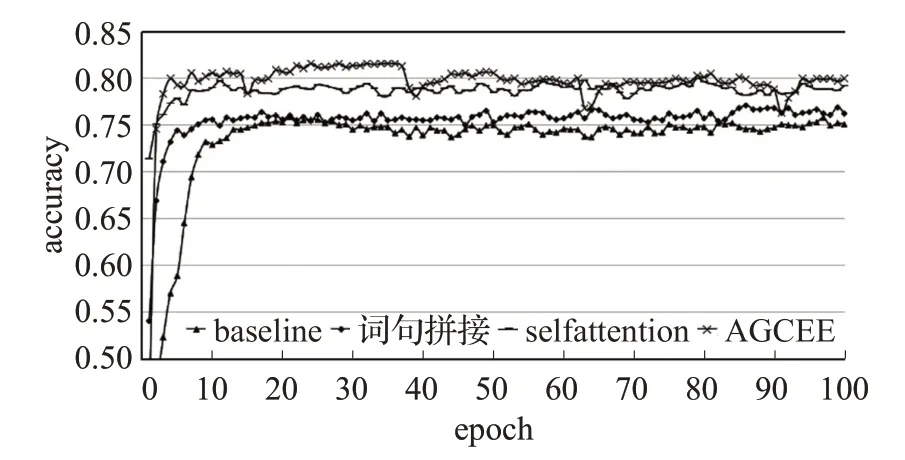
图10 不同模型的正确率训练结果对比Fig.10 Accuracy training results of different models
通过对比可以看出:
(1)词法特征与句法特征的结合可以有效提升模型的准确率,并且使模型更快地得到一个较好的结果。
(2)训练的过程是一个螺旋上升的过程,测试结果按一定的规律波动,Attention机制在提升训练效果的同时,还可以缩短波动的周期。
(3)AGCEE通过Multi-head attention将词法特征与句法特征融合,得到了最好的效果,并且大幅缩短了波动的周期。
3.4 与现有模型比较
表3中模型采用相同的训练方式,即数据集90%作为训练集,数据集10%作为测试集,批次大小设定为16,并采用Adam优化器,最终的结果取F1分最高时的测试结果。可以看出,DMCNN在正例准确率以及全要素识别正确率上具有一定优势,验证了在中文事件要素抽取任务中,对句子不同部分进行聚焦是有效的;JMEE采用了多种特征表达,弥补了DMCNN在一句多事件情况下事件要素抽取的效果,有效提升了召回率;AGCEE针对中文文本设计特征组合,并通过分组的方式对句子不同部分进行特征的进一步聚焦,在准确率、召回率和F1分数三个方面都有提升。在训练时间方面,AGCEE采用Attention机制提取特征,所需要的时间成本相对多一些。
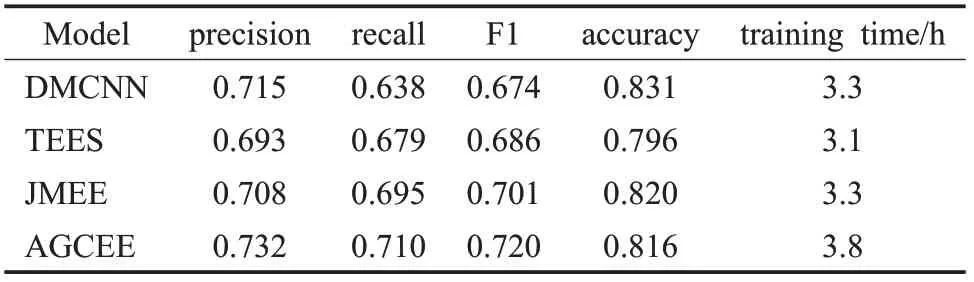
表3 与现有模型比较Table 3 Compared with existing models
4 结语
中文事件要素抽取的难点在于构建特征工程,由于中文的词法与句法难以通过一个或几个表达来定义,而词向量和句向量包含了大量的词法和句法信息,通过处理词向量和句向量是捕获中文语法的有效途径。
本文提出了一种新的事件要素抽取模型AGCEE,针对中文表达的特点,通过Attention机制构造包含词法特征与句法特征的融合特征,并采用GLSTM与CRF结合的方式进行分类标记,在加快训练速度的同时提高标注的精度。实验表明,相比基线模型,该模型在准确率上提升了6%,在召回率上提升了6.2%,在F1分上提升了6.1%,在正确率上提升了3.3%。
在未来的工作中,会将研究重点放在改善Attention机制所带来的运算时间成本问题。此外,AGCEE可应用于继续提升整个事件抽取系统的效果,会继续探究该模型在知识图谱中的应用。
猜你喜欢
时代英语·高三(2024年3期)2024-09-03 00:00:00
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中华诗词(2021年3期)2021-12-31 08:07:22
大连民族大学学报(2021年2期)2021-07-16 05:41:42
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中华诗词(2018年3期)2018-08-01 06:40:40
中华诗词(2018年11期)2018-03-26 06:41:32
科技经济市场(2017年5期)2017-09-16 19:20:11
海外华文教育(2016年3期)2017-01-20 08:22:19
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
