
基于深层连接注意力机制的田间杂草识别方法
2022-03-22 03:37:28疏雅丽张国伟徐晓康
计算机工程与应用 2022年6期
疏雅丽,张国伟,王 博,徐晓康
上海电力大学 自动化工程学院,上海 200082
我国杂草众多、分类广泛,与作物争夺光肥水的营养,造成作物产量的降低和品质的下降。据统计,我国因杂草危害造成的损失达到粮食总量的10%左右,因此如何高效地除草一直是人们的研究重点[1-3]。除草主要分为两种:机械除草和化学除草。机械除草泛化性低,不具备处理各种作物伴生杂草的合适机具,容易在移动过程中损害作物,化学除草是农业除草的主要方式,采用传统的全淋式喷洒,造成大量农药的浪费以及土地和水源的污染。随着国家对智慧农业的推动,精确喷洒农药是农业除草技术发展的必然趋势,对农作物的产量和环境的保护有着十分重要的意义。
近年来,深度学习网络在许多领域都有着较好的表现,经典的CNN网络从LetNet(5层)和AlexNet(8层)发展到VGGNet(16~19层),再到后来GoogleNet(22层),广大学者探索深度学习的深度与模型性能之间的关系,发现传统的CNN网络结构通过层数的加深可以增加非线性的表达能力,但到达一定的深度后,添加层数反而会缓慢网络收敛速度和降低分类的准确率[4-6]。针对此类现象,He等[7]于2015年提出了一种残差网络,通过shortcut(捷径分支)避免网络的退化,从而可以加深网络的深度,提高模型的准确率。由于其优异的性能,研究者提出多种方式来提高残差网络的性能,左羽等[8]融合植物的宏观上整体轮廓和微观上局部纹理特征,采用密集型残差网络提取植物全面的植物特征,增加了模型提取特征的能力,但是训练过程需要花费大量的时间;陈加敏等[9]利用金字塔卷积改进残差网络提取图片的全局特征信息,并融入空间注意力机制和通道注意力机制聚焦局部特征,取得较好的实验效果,但是增加了模型的参数量和复杂度;曾伟辉等[10]通过级联残差网络的输出丰富病害的特征表达,并利用参数共享反馈机制优化模型,具有很好的鲁棒性,但计算资源消耗较大。目前,注意力机制成为现在的一大热点,如SE、SK、CBAM等注意力机制,广泛应用到各种深度模型中,聚焦于图像中的局部信息从而提高模型的性能,但是这些注意力机制[11]仅从当前的特征图中提取信息,额外信息的缺乏反而影响其辨别能力。
针对田间杂草识别问题,本文提出了一种改进残差块结构和注意力机制的杂草识别模型,以残差网络为基础,改进残差块结构,采用迁移学习[12-14]策略,载入部分ImageNet权重参数,仅训练高层特征提取层,并引入轻量级的注意力机制(efficient channel attention,ECA)和连接注意力机制模块(deep connected attention,DCA),在复杂环境下高效准确的识别杂草种类,对于小样本的田间杂草识别提供很好的理论支持。
1 残差网络
1.1 基本的网络结构
杂草图像的识别相比于一般物体更具有挑战性,由于光照、角度等条件的影响,同一种植物呈现不同的姿态,而且同科的植物形态特征存在着一定的相似性,给图像识别带来了更大的挑战。此时低维浅层特征不能提供足够的特征的信息识别杂草,深层的网络可以提取图片的高维抽象的特征,Resnet网络的残差结构在加深网络的同时有效解决梯度爆炸或者梯度消失问题,在图像分类、目标识别领域都有着突出的成就,很多研究都是建立在Resnet50或者Resnet101的基础上完成的。基于现有的数据集和设备,实验对比不同深度的残差网络,选取了Resnet50的网络模型进行杂草的识别。
Resnet50网络共有50层,包括49个卷积层和1个全连接层。输入尺寸为224×224×3的彩色图像,首先经过一个大小为7×7的卷积核和最大池化层,然后通过多层残差块的堆积,提取图片的特征信息,最后紧跟平均池化层和全连接层,使用Softmax计算测试集图片属于各个类别的概率,完成杂草的分类。
1.2 残差块原理
浅层的传统神经网络已经具有比较理想的输出结果后,额外增加层数后反而可能导致网络退化。因为对于传统的神经网络,直接去拟合一个潜在的恒等映射函数H(x)=x是很困难的,而残差网络提出残差的概念,将拟合的目标转换成将残差逼近为零,不再是学习一个完整的输出,而是目标值H(x)和x的差值,来达到恒等映射的训练目标[15]。残差结构可用下式表示:
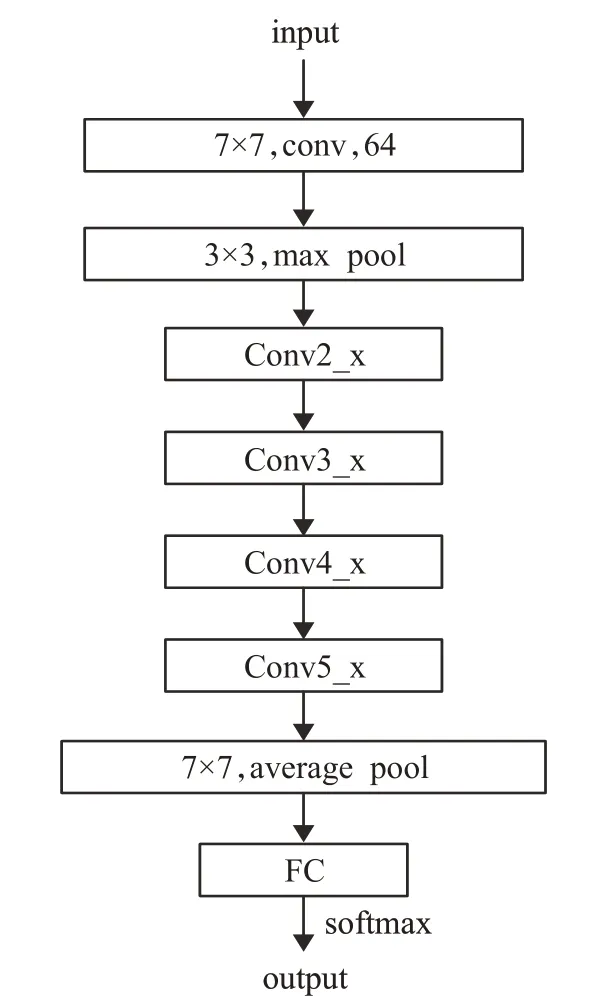
图1 Resnet50结构图Fig.1 Resnet50 structure diagram

2 改进的Resnet50网络
2.1 残差块的改进
当残差单元的输入和输出维度不一致时,不能将捷径分支直接与主干分支直接相加,一般采用步长为2的1×1卷积核或者采用池化层降低特征的维度并保留有效信息[16]。
标准Resnet50网络残差块如图2中(a)所示,在捷径分支和主干分支上分别采用步长为2的1×1卷积核进行降维完成下采样功能。如图3(a)所示,由于卷积核宽度小于步长(stride=2),无法遍历特征图中的所有特征信息,图中只有框选部分的信息才能传递到下一层,非框选部分的信息均不参与卷积计算,造成了3/4信息的缺失,对于杂草中特征差异较小的杂草而言,信息的缺失使得模型无法提取更深层次的空间像素信息,从会导致识别精度的降低。
为此本文重新布局残差块中下采样的位置,如图2(b)所示,将主干分支的下采样过程移动到3×3的卷积核处,在捷径分支的1×1卷积核前另加入一层步长stride=2的3×3的平均池化层。如图3(b)所示,卷积核在移动过程中能够遍历特征图上的所有信息,并且有一部分的信息重叠。平均池化层在不同的通道上进行的,且不需要参数控制,避免了冗余的信息,对输入的图像特征信息进行压缩,使输出图像的长和宽变为原来的一半,从而减少了模型计算量和内存消耗,减低了过拟合的可能性。
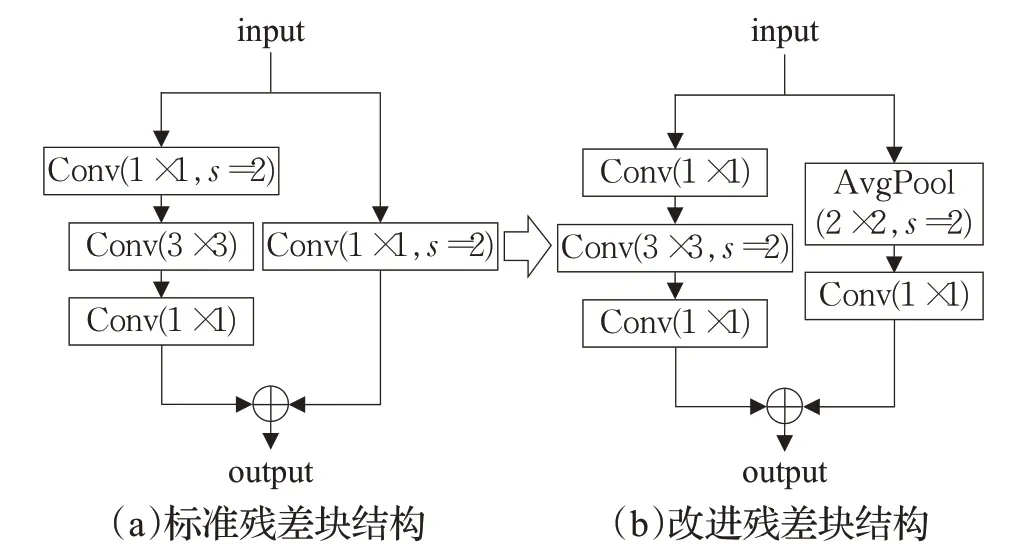
图2 残差块结构Fig.2 Residual block structure
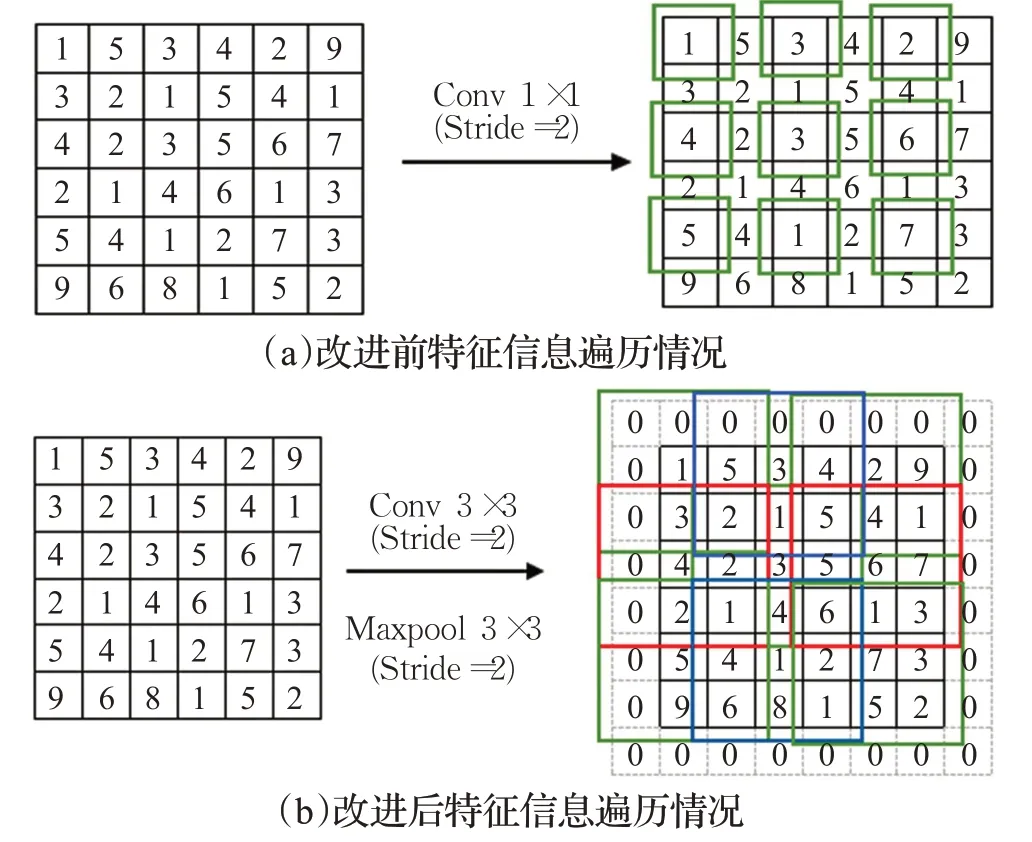
图3 改进前后特征信息遍历情况Fig.3 Feature information traversal before and after improvement
2.2 引入注意力机制
杂草图片在不同的光照、背景拍摄条件下存在着颜色、大小和形状的差异,且有效特征信息分布在图片中的局部区域,为提高模型的识别精度和提取速度,本文将注意力机制ECA(efficient channel attention)模块[17]引入残差模型中,通过网络自主学习一组权重参数,并以“动态加权”的方式来强调杂草的区域同时抑制不相关背景区域。ECA模块结构如图4所示,将ECA模块嵌入到残差块主干分支之后,经过不降低维度的通道级全局平均池化(GAP)后,利用一维稀疏卷积操作来捕获当前通道与它的k个领域通道信息的交互,大幅度降低了参数量的同时又保持了相当的性能。
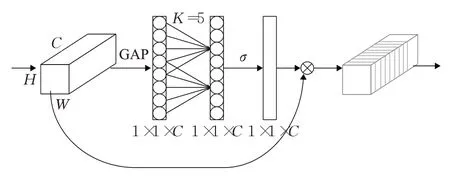
图4 高效通道注意力(ECA)模块结构图Fig.4 Efficient channel attention(ECA)module structure diagram
假设网络模块输入的特征图为F∈RC×H×W,然后通过平均池化层,将每个二维的特征通道(H×W)变成一个实数,得到一个1×1×C的全局描述特征。随后,利用卷积核大小为k的一维卷积捕捉局部的跨通道交互信息,接着通过一个Sigmoid的门获得一个0~1之间归一化的权重,作用到之前的特征图中。为了减少模型的复杂度,ECA模块简化了SE模块[18]密集型的连接方式,仅考虑相邻通道信息的交互,权重计算公式如下:
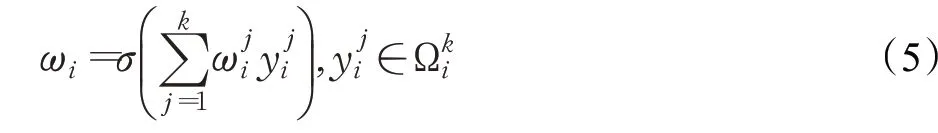
其中,σ为Sigmoid激活函数,yi代表通道,ωi为通道yi的权重,为yi的k个相邻通道的集合,k的值是随着学习自适应变化的。有效通道注意力模块可以通过核大小为k的一维卷积实现,如式(6)所示:

其中,C1Dk表示核为k的一维卷积操作,y表示通道。
2.3 深层连接注意力机制
尽管注意力机制在很多视觉任务中都显示出良好的效果,但是它一次只考虑当前的特征,没有充分利用到注意力机制。受到文献的启发,通过DCA(deep connected attention)模块[19],将相邻的注意力块相互连接,使信息在注意块之间流动,提高注意力的学习能力,DCA模块不限定特定的注意模块或基本的网络框架,在不改变CNN模型内部结构的情况下提升注意力模块的性能。
DCANET(deep connected attention network)研究目前先进的注意力块,通过分析总结它们的组成部分和处理过程,将其分成三部分,分别为extraction(特征提取)、transformation(转换)和fusion(融合),DCA网络结构图如图5所示。首先ECA模块通过GAP(global average pooling)从给定的特征图中进行特征提取,再利用一维卷积核和激励函数将提取的特征转换到一个新的非线性注意空间,最后将注意与原始特征进行融合,而DCA模块在注意力块之间引入一条连接链,将先前注意块的转换输出和当前注意块的特征提取输出合并在一起,以前馈的方式保证各注意块之间的信息流,防止每一步的注意信息变化太多。
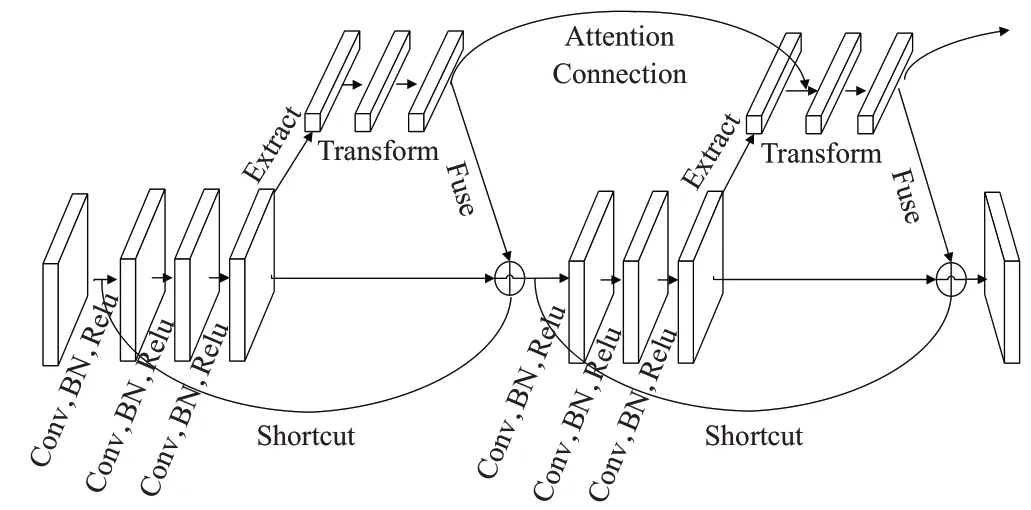
图5 深层连接注意力(DCA)网络结构图Fig.5 Deep connected attention(DCA)network structure dia-gram DCANET(Deep connected attention network)
3 实验及结果分析
3.1 实验环境和实验数据
实验平台采用免费提供GPU的Google colab开发平台,colab的使用界面类似jupyter notebook,运行于虚拟机(VM)上。虚拟机配置NVIDIA Tesla K80 GPU,12 GB内存,39 GB硬盘空间。软件框架采用Tensorflow的Keras的深度学习框架,使用Python3.6在线编译。
模型训练参数设置如下:迭代次数均设置为80次,批处理BatchSize参数为32,预热后的初始学习速率为0.001,动量因子设置为0.9,选择优化器为SGD。
实验图像数据采集于江苏省苏州市巴城农田处,分别在晴天、阴天不同光照条件下,使用分辨率为10 MP的照相机垂直向下拍摄作物和杂草,选取农田中数量较多的杂草进行拍摄,共采集到3 670幅图像作为豌豆杂草小样本数据库,包含豌豆和4种不同杂草,分别为银叶菊742幅、小蓬草718幅、马唐722幅和猪殃殃740幅,如图6所示。为了评价模型性能,本文采用80%的图像数据作为训练集,另外20%的图像数据作为测试集。

图6 豌豆田间的杂草图像Fig.6 Images of weeds in pea field
由于采集的图片分辨率较大,需要对图片进行预处理,本文采用大数据ImageNet中学习的知识迁移学习到杂草识别中,选用resnet50训练大数据集ImageNet时所用的预处理方式,发现可以得到较好的训练结果。将采集的图片随机缩放到224×224的尺寸,进行随机水平旋转后,采用归一化处理,将数据归一化到[-1,1]。
3.2 引入迁移学习的有效性分析
为了验证迁移学习对小样本数据的促进作用,以DCECA-Resnet50-a模型为基础模型,采用不同的迁移学习策略在相同的实验条件下进行对比实验。实验分为以下四种类型:(1)不加载ImageNet预训练权重,采用随机生成的初始权重训练网络模型;(2)载入部分ImageNet权重,冻结全部卷积层的全部参数,仅训练最后全连接层以输出杂草的种类;(3)载入部分ImageNet权重,冻结Conv5_x卷积层前面的全部参数,仅训练Conv5_x卷积层和全连接层以输出杂草的种类;(4)加载全部的ImageNet权重后训练所有参数。
表1和图7表明,采用迁移学习策略明显提高了模型的性能,实验1不采用迁移学习策略,模型在小样本数据集情况下无法提取足够的特征信息,收敛速度慢,平均消耗时间最长,且准确率也远低于其他3个实验,实验2冻结了全部卷积层,仅训练最后的全连接层来输出杂草种类,将其他领域的知识迁移到杂草领域,缓解了杂草数据不足的缺点,准确率达到92.21%,实验3冻结了部分的卷积层,由于浅层特征信息中存在着共性,例如角点信息、纹理信息等特征信息可以直接迁移到预训练模型中,避免从头训练浪费大量时间,直接学习新数据集中的高维特征,获得比较理想的实验效果,相比实验2而言,能很好地提取杂草的特征信息,实验4准确率最高,但是需要花费大量的时间从头开始训练,时长高出实验3约2.6倍。
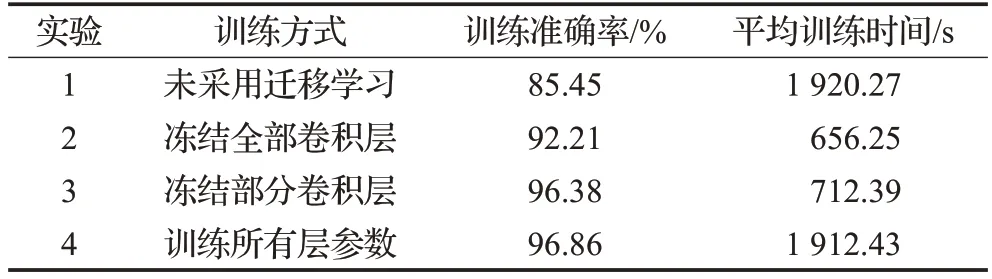
表1 不同训练方式对比Table 1 Comparison of different training methods

图7 不同训练方式模型准确率的对比Fig.7 Comparison of taccuracy of models with different training
3.3 不同注意力机制的模型对比实验
注意力机制在许多视觉任务上都显示出良好的效果,并广泛用于图像识别和图像分割领域。为了协调模型的识别精度与模型参数量之间的平衡,本文引入轻量级的注意力机制ECA模块和连接注意力机制DCA模块,与其他先进的注意力机制进行对比实验。实验结果如表2所示。
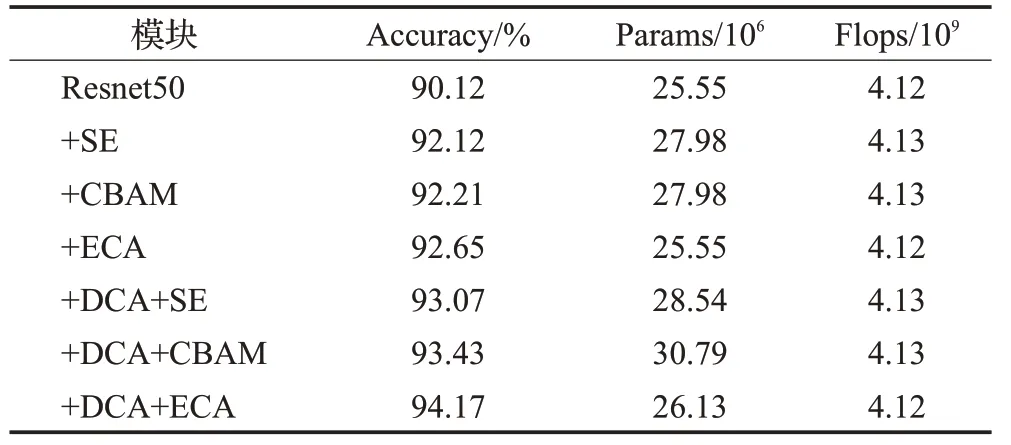
表2 不同注意力机制实验对比Table 2 Experimental comparison of different attention mechanisms
表2表明,注意力机制的引入在一定程度上可以提高Resnet50模型的识别准确度,相较与注意力机制SE、CBAM模块而言,ECA模块在提高模型精度的同时,并不额外增加模型参数和复杂程度,另外DCA模块融入到各个注意力机制后,使得加入注意力机制的模型的性能再一次得到提升,以最小的额外计算开销优于其他先进的注意力模块,说明注意力块的连接增强了注意力在通道上和空间上获取信息的能力,从而挖掘更深层次的特征。相比较而言,Resnet50+DCA+ECA模型以94.17%的识别准确率优于其他模型,并且引入的模型参数最少,其中CBAM模块增长的参数最多,由于CBAM模块[20]融合通道注意力模块和空间注意力模块,在多重注意维度的背景下,DCA模块沿着每个维度连接注意,致使模型参数大幅度增加,参数量相比于标准的Resnet50增加了5.24×106,计算资源消耗较大。
便于直观地探讨注意力机制的引入和连接后的学习能力,本文采用类激活映射(class activation mapping,CAM)进行可视化对比,如图8所示。
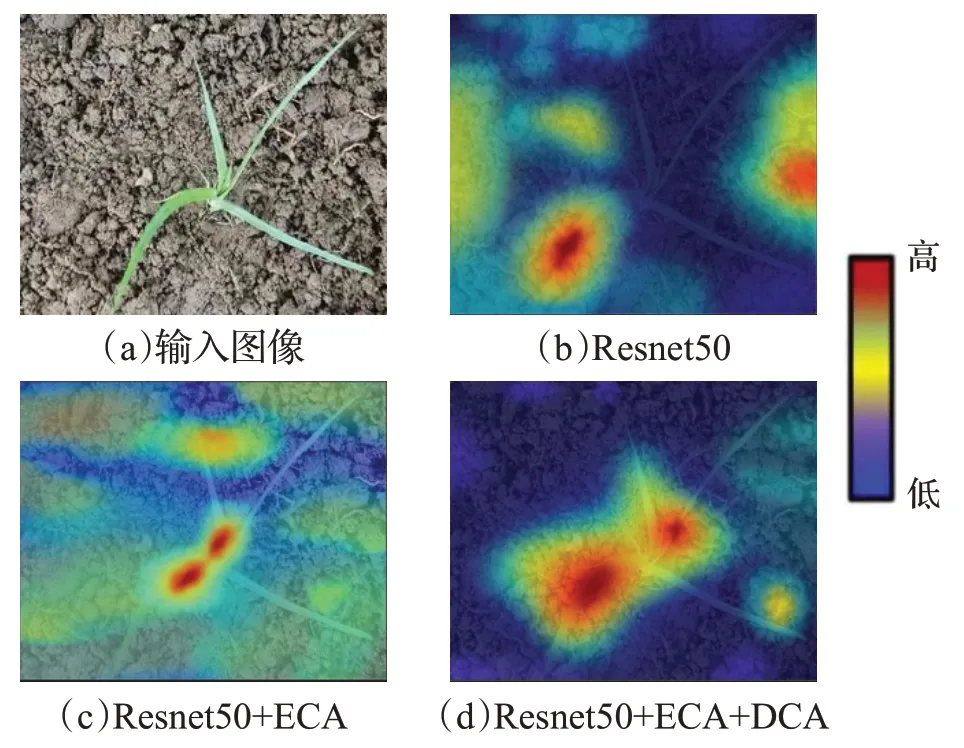
图8 特征激活图可视化Fig.8 Feature activation map visualization
根据热力图的颜色图标表示,红色到紫蓝色代表由高到低的激活值,越红的区域表示模型学习特征的能力越强。图(a)为原始输入图像,图(b)为Resnet50模型可视化结果,该模型更多地关注背景信息从而忽略对杂草区域信息的提取,导致识别准确率较低,图(c)为在Resnet50基础上加入注意力机制后的结果,发现模型的关注区域重心逐渐转移到杂草目标上,但仍然受到受到部分背景信息的干扰,图(d)为在Resnet50基础上引入并连接注意力机制后的结果,此时模型对提取到杂草信息的通道赋予更高的权重,使得模型更关注于杂草的关键特征,在重点区域不变的情况下增加杂草区域的关注范围,并进一步抑制了背景信息的干扰,提高了模型识别杂草的准确率。
3.4 网络模型的测试结果
随机划分豌豆杂草数据的20%作为测试集,分别于标准Resnet50模型和优化后的DCECA-Resnet50-a模型上进行测试,并通过爬虫网站查找新的图片数据丰富测试集,得到杂草识别结果如表3所示。
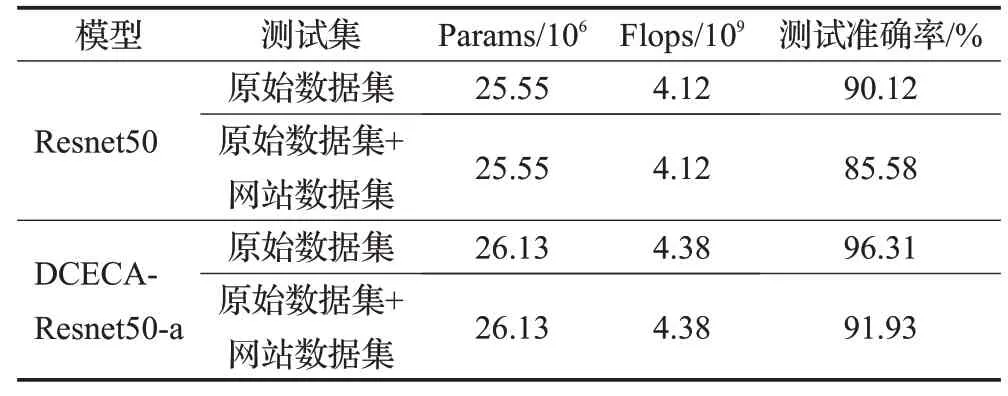
表3 豌豆苗杂草测试集识别结果Table 3 Identification results of weed test set for pea seedlings
对比两种网络模型的测试结果,改进后的网络模型增加了模型复杂度,Flops增加了约6%,但是由于计算Flops是将Resnet50的不同分支的运算量依次累加起来,Resnet网络模型由于捷径分支可以并行运算,因此,改进前后的网络模型实测速度没有太大差别。
相比于改进前的网络模型,改进后的网络模型在不同的测试集上都有一定的提高。改进后的网络模型相对于改进前的网络模型在原始数据集上正确识别率提高了6.19%,但是加入网站的数据集测试后,准确率都有所下降。在测试结束后,通过查看被错误分类的图片数据,发现识别错误的问题主要发生在以下情形:一种是拍摄的两种杂草相似度比较高;另一种是图片中的杂草背景复杂,背景图片在训练数据中出现频率较少。由于采集的数据库是在同一个豌豆田间进行采集,背景环境多为类似,所有的数据集都有一定的偏向,当在测试集中加入网站中不同背景环境且背景较为复杂的杂草图片来进行测试,会降低一定的正确识别率,深度学习网络受数据驱动,在样本数据集较少的情况下,对于图像中的变化也会相对敏感。
3.5 不同数据集下的模型对比实验
本文采用的数据集始终为杂草数据集,为进一步探究改进后的模型在其他数据集上的实验效果,使用kaggle平台上公开的花卉数据集进行比较,花卉数据集共包含4 242张图片,包括雏菊、蒲公英、玫瑰、向日葵、郁金香,分别在标准残差网络模型和改进后的Resnet50-a和DCECA-Resnet50-a模型上进行实验,如表4所示。对比于标准的Resnet50模型,Resnet50-a代表改进残差块后的网络模型,DCECA-Resnet50-a代表在改进残差块的基础上引入注意力机制和连接注意力机制后的网络模型。
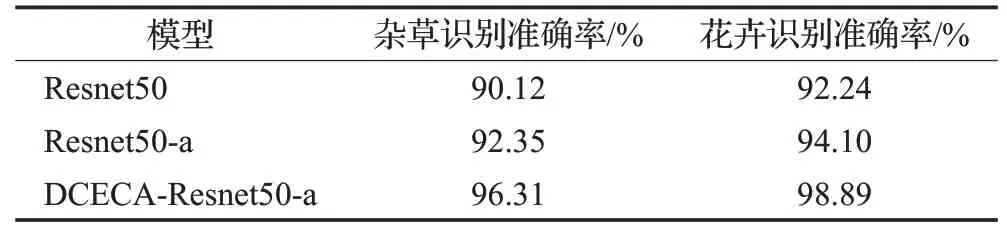
表4 不同数据集下的识别结果Table 4 Identification results under different data sets
改进前后的残差模型在花卉数据集下的识别效果均优于杂草数据集,一方面,由于花卉数据集特征更为丰富,与杂草数据集相比,颜色、边缘等基本特征更易于区分,另一方面,田间下的杂草背景较为复杂,增加了模型的识别难度。此外,残差块的改进、注意力机制的引入和深层连接使得模型的性能都得到了相应的提升,可以提取更多的有效特征。改进后的DCECA-Resnet50-a模型泛化性强,在花卉图像分类上也具有一定的可行性和有效性。
3.6 不同识别模型对比实验
为了进一步验证本文识别模型的可靠性,在相同的实验条件下选取不同的识别模型进行对比实验。根据大量文献可知,在图像识别领域中多采用VGG16、Alexnet、Resnet50、Resnet101卷积神经网络模型。为加快模型的训练时间,实验中模型均采用迁移学习策略,冻结部分特征提取层,训练高层特征提取层,并改变分类层的种类数目以输出杂草的种类。
表5表明,针对于采集的原始杂草数据集,这些识别模型都取得较好的实验结果。VGG16、Alexnet模型识别准确率都低于90%,且模型参数较大,占用更多的空间内存和浪费更多计算资源,其中Resnet50网络模型大小最小,约占VGG16模型大小的1/6,并且在性能上也更加优越,Resnet101网络通过增加网络深度提取深层有用的特征信息,相比较Resnet50而言,在识别准确度上有一定的提高,但是占用更多的空间内存。
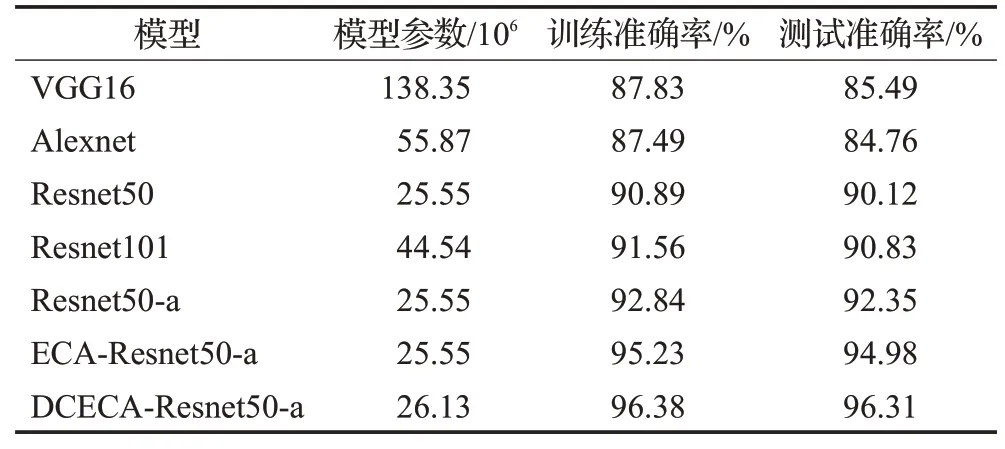
表5 不同识别模型实验对比Table 5 Experimental comparison of different recognition models
同时将Resnet50-a模型与Resnet50相比较,训练准确率和测试准确率都有明显的提升,说明下采样位置的改变可以帮助模型更好地提取特征信息,ECAResnet50-a较Resnet50-a整体性能有所提升,表明注意力机制可以改善模型的表达能力,并且ECA模块的引入可以在不增加模型参数量的同时提高模型识别杂草的准确率,DCECA-Resnet50-a模型与其他模型相比综合性能最好,训练准确率和测试准确率最高,表明注意块之间信息的流通是有必要的,在一定程度上提高了模型的性能。
4 结论
对于采集到的复杂的田间杂草图像,往往有很多因素干扰对杂草种类的识别,为了增加模型对于图片特征信息的把握,本文提出了深层连接注意力机制的残差网络模型。在传统的残差网络基础上,重新设计下采样在残差块中主干分支和捷径分支的位置,遍历特征图中的所有特征信息,同时引入轻量级注意力机制ECA模块,聚焦图片中杂草中的重要特征信息,在不增加模型参数的同时提高了模型识别杂草的准确率,并采用DCA模块连接注意块,使得各个注意块可以获得更多的额外信息,对图片中的重要特征信息有更好的辨别能力,对比于其他先进注意力机制,实验证明注意力机制(DCA+ECA)的引入以最小的计算开销进一步提高模型的综合性能,识别精度对比于传统的残差网络提升4.02%,并不额外增加模型的复杂程度。在训练过程中,本文将未使用迁移学习和其他三种迁移学习策略进行对比,发现冻结底层特征提取层,仅训练高层特征提取层可以获得理想的训练结果并大幅度地减少模型的训练时长,相较于从头训练所有层,训练准确率低了0.48%,但是平均训练时间上约占其1/3。为了验证模型的泛化性和有效性,本文采取了不同的数据集进行实验,发现改进后的模型在杂草和花卉图像数据集中均可获得较好的识别效果,但是由于杂草数据图片背景较为单一,额外增加杂草数据集进行测试时,识别准确率会相应降低。比较了不同的深度学习网络模型,在相同的实验条件下,DCECA-Resnet50-a模型在杂草特征识别上优于其他模型,识别准确率最高,且模型参数较小,节省了大量的计算资源。
猜你喜欢
科教新报(2022年22期)2022-07-02 12:34:28
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
河南科技(2015年8期)2015-03-11 16:23:52
现代农业(2015年5期)2015-02-28 18:40:49
杂草学报(2012年1期)2012-11-06 07:08:33
