
基于深度强化学习的智能灯个性化调节方法
2022-03-22 03:37:24张瀚铎王昱林
计算机工程与应用 2022年6期
邓 心,那 俊,张瀚铎,王昱林,张 斌
1.东北大学 计算机科学与工程学院,沈阳 110819
2.东北大学 软件学院,沈阳 110819
随着万物互联和智能计算的趋势不断加深,各类智能信息物理系统(cyber-physical systems,CPS)和物联网(Internet of things,IoT)[1]应用不仅已经实现了物理世界和信息世界的无缝连接,更让物理设备具有了计算、通信、精确控制等能力,催生了机器人、无人机和自动驾驶汽车等自主设备。通过无处不在的环境感知、设备本身的计算能力以及网络通信和远程控制,这些自主设备将实现与周围环境和人类更自然地交互,被Gartner列为2019年十大战略技术趋势之一,已经成为研究界和产业界普遍关注的焦点。
智能家居是家庭信息化的一种重要实现方式。随着物联网技术的发展和成熟,智能家居已经成为了社会信息化发展的重要组成部分。智能照明是智能家居的重要组成部分,良好的室内光照可以提高人的视觉舒适程度和健康状况[2]。随着物联网的蓬勃发展,新一代的LED照明系统应运而生,即基于LED的智能照明系统。通过集成传感器和执行器,各类LED智能灯能够与其他智能设备一起使用,以改善人们的生活方式,提高便利性和可定制性,同时达到节能的目的[3]。例如,Philips Hue是一种无线照明产品,可以与一系列智能设备(例如Amazon Echo,Apple HomeKit,Google Home等)配合使用,以为居住者提供方便舒适的方式来控制和体验照明。
照明控制策略是智能照明系统的核心,它描述了如何在给定目标下修改照明。例如,开关、调光器和场景设置器是通过手动控制满足个人偏好并实现节省能源的基本策略[4]。为了提高用户体验的质量,灯光控制策略需要更加灵活,以便能够调节灯光以自动提供舒适的照明,同时自动将能源成本降至最低。特别是考虑到日光的自然变化和用户需求的多样性,自主学习用户偏好并适应环境亮度变化已经成为了智能照明系统的关键功能[5-6]。通过提供接近个人各自偏好的亮度在情绪、亮度满意度和环境满意度上具有重要提升作用。如果可以最大限度地利用自然光,智能地调节每个人所在位置的光照设备,让综合光照强度一直保持在一个让人舒适的范围内,可以节约能源、降低光污染、增加办公效率等[6]。
考虑到每个人对光照的舒适程度和自身习惯不同,要在满足舒适度的同时,还要精确地控制光照设备,很难使用一个确定的策略来满足所有人需求。文献[5]提出一个基于ANN的方法满足每个办公室人员桌子上的亮度偏好,通过最小化具有分布式照明的照明系统总体能量消耗,构建表示每个桌子上的照明强度和实际亮度之间相互影响的模型。然而,作者并没有考虑自然光的影响,且假设所有桌子期望亮度相同,并未考虑用户的个性化亮度偏好。文献[7-8]以使用者为中心,强调自适应亮度控制模型的重要性,主要关注开/关操作,而不是亮度调节。文献[9]提出了办公区域内的个性化照明,提出了优化照明的控制算法,并使用具有生成调光信号的亮度生成器模型。文献[10]引入了一种改进的强化学习控制器,可获得最佳的百叶窗和灯光控制策略来提供灯光控制的个性化服务。文献[11]基于居民的行为模式采用人工神经网络进行在线学习和自适应,使用基于相似度阈值的数据替换算法对历史数据进行替换,取得了很好的效果,但自然光的影响并没有考虑。
针对现有方法存在的上述问题,本文提出一种基于深度强化学习的智能灯亮度个性化调节方法。一方面,通过考虑自然光强和用户位置动态调整灯光亮度起到节能的作用,另一方面则通过采集用户对灯光亮度的手动调节情况形成强化学习的正负反馈,逐渐学习并拟合用户的使用偏好。由于强化学习是一种典型的在线学习算法,相较于传统用户行为模式挖掘、人工神经网络等方法具有更好的动态适应能力。
1 理论基础
1.1 强化学习基本原理
强化学习是机器学习的一个重要分支,它避免了对复杂的环境和用户行为进行建模,在很多需要实现个性化的问题中发挥了积极作用[11]。强化学习的本质是通过学习模型与环境不断地进行交互,通过获取的反馈信息优化其自身的决策行为,不断地进行学习和决策,最终获得最优的决策方案。
强化学习可以使用马尔可夫决策过程(Markov decision process,MDP)进行建模。马尔科夫决策过程被定义为一个五元组S,A,P,R,γ,其中,S为状态集,A为动作集,P为转移的概率,R为回报函数,γ为折扣因子。
强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略[12]。其中,策略是指状态到动作的映射,如式(1)所示:

其中,π为策略,代表给定一个状态s,在动作集上的一个分布。式(1)表示策略π在状态s给出一个动作概率,如果给出的策略是确定的,那么策略π就会在状态s上指定一个确定的动作。当策略π确定后,就可以计算累计回报,如式(2)所示:
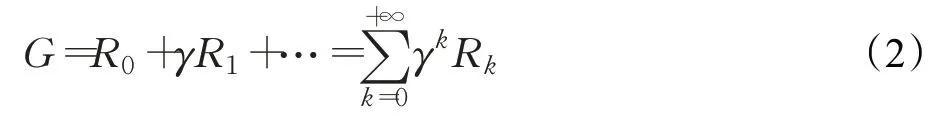
Q-learning[13]是强化学习的基础算法,属于强化学习算法中基于价值(value-based)的算法。状态-行为值函数Q(s,a)就是在某一时刻的状态s(s∈S)下,采取动作a(a∈A)能够获得收益的期望。环境会根据算法的动作反馈相应的回报R。通过回报R可求得状态行为值函数Q(s,a)的值,如式(3)所示:
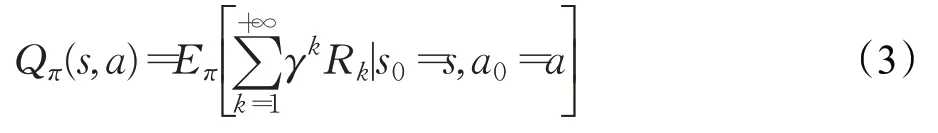
其中,k为迭代步数s0为当前状态,a0为在s0状态下执行的动作,π未执行策略,Eπ(·)为求策略π的期望。
通过Q(s,a)可以看出,每个状态的选择策略都与它下一步获取的回报有关,即随着迭代次数的增加算法会在每一个状态选择能获取到最大回报的策略,最终得到最优方案。根据所获得的状态-行为值函数Q(s,a),采用贪婪策略π*进行选择每一步的动作,如式(4)所示:

其中,π*为策略,s为当前状态a为要执行的动作。在训练过程前期,通常在策略π上增加一定的随机策略来对状态进行探索,常见的使用策略为ε-greedy。
通过贪婪策略π进行状态转移后得到奖励r和新的状态s′,可以采用时间差分法的方法对Q-learning进行更新,如式(5)所示:
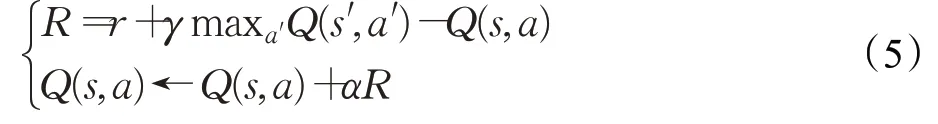
其中,α为学习率,s′为下一个状态,a′为下一个状态要选择的动作,r为Q(s,a)转义过程中的奖励值,γ为奖励折扣率。
使用强化学习算法只需根据每次与环境交互而获得的s,a,r,s′进行训练,让算法在每个初始状态s0下能够在短时间内获取最高的奖励值,无需对复杂的场景进行建模,因此在解决智能灯的个性化适应问题上,能够有很好的表现。
1.2 深度强化学习算法:DQN、DDQN和A3C
Q-learning所解决的问题的状态空间和动作空间必须是离散的,并且问题的状态空间和动作空间不能太大。当面对高维度的状态空间、行为空间,以及连续的行为空间时,Q-learning的状态-行为值函数往往无法进行表示。
谷歌DeepMind提出了将深度神经网络和Q-learning相结合,即deepQ-learning(DQN),来处理高维度状态空间和行为空间的问题[14]。与Q-learning相比,DQN[15]使用了卷积神经网络来逼近状态-行为值函数,允许更高维度、更多数量的状态作为强化学习算法的输入;DQN还提供一个经验回放(experience replay)[16]功能用来弥补训练时数据不足的问题。
Double DQN(DDQN)[17]和DQN的不同之处在于策略选择,使用贪婪策略虽然可以让Q(s,a)值快速地向可能优化的目标靠拢,但很容易出现过估计(over estimation)现象,最终得到的算法模型会有很大偏差。DDQN使用两个神经网络,通过对目标Q(s,a)值动作的选择和目标Q(s,a)值的计算来消除DQN的过估计问题。在一个网络中选择出最大Q(s,a)值的对应动作,如式(6)所示:
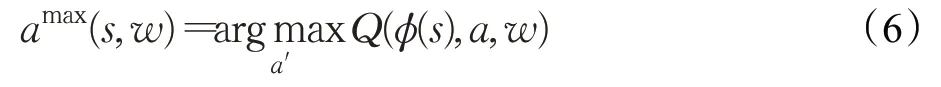
其中w为网络参数。
在另一个网络中利用选择出的动作来计算目标Q(s,a)值,如式(7)所示:
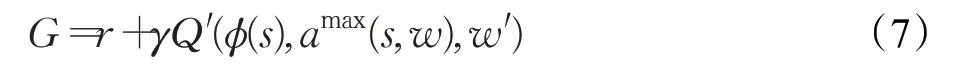
其中w′为网络参数。
Actor-Critic算法是策略(policy based)和价值(value based)相结合的方法,算法使用Actor网络负责生成动作策略π与环境进行交互;使用Critic神经网络负责对Actor的表现进行评估并指导下一步Actor的动作,相当于Q-learning中的状态-行为值函数,Actor和Critic网络都有相同结构的目标网络负责使两个神经网络收敛。由于Actor-Critic算法缺少经验回放部分,这会在训练的过程中消耗更多时间。asynchronous advantage actor-Critic(A3C)[18]算法采用异步训练框架,利用多个线程和环境进行交互,避免了对经验库的过度依赖的同时,还做到了异步并发学习能够帮助模型更好更快的收敛。
2 基于深度强化学习的智能灯亮度个性化调节方法
2.1 方法框架
论文提出的基于深度强化学习的智能灯亮度个性化调节方法主要由三部分构成,即(1)数据采集;(2)数据存储和强化学习算法的决策推理;(3)智能灯的控制。方法流程如图1所示。
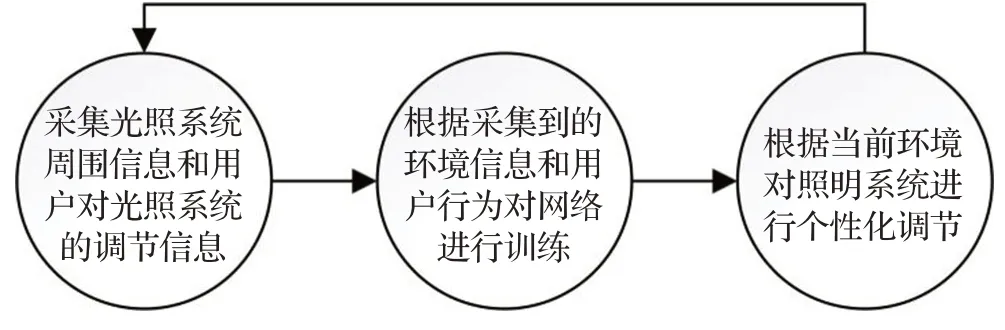
图1 方法流程Fig.1 Process design
系统开启后将实时采集环境信息,本文使用用户位置、自然光强、照明光强和用户位置处的实际光强。将采集到的上述环境信息作为环境状态输入深度强化学习模型,形成对智能灯亮度的调节动作,并基于智能灯接口对其实施亮度调节。
使用算法动态调节亮度后,系统将重新获得当前的环境状态,并采集是否发生用户手动调节。如果在给定时间阈值范围内,发生人工手动调节,则视为算法输出未满足用户偏好,形成负反馈;否则,则认为算法输出满足用户偏好,形成正反馈。在每次收到反馈后,通过不断更新模型逐步拟合在各种环境状态下的用户偏好亮度,提升智能灯亮度控制的精准度。
2.2 模型构建
使用强化学习解决问题首先要按照马尔可夫决策过程建立强化学习模型[19]。将基于深度强化学习的智能灯个性化调节模型定义为一个五元组,M=S,A,P,R,γ,其中,S代表环境状态空间,A代表动作空间,P代表状态转移概率,R代表奖励值,γ代表奖励折扣。构建基于深度强化学习的智能灯个性化调节模型,则需要按照上述定义对系统进行抽象建模。
(1)环境状态S的选择
对于环境状态的选择,需要选取能够对决策起决定性作用的因素,本文中的环境状态来自于照明系统周围的信息,包括智能灯与采集点的距离distance、采集点的自然光强sunbright、系统光强lightbright和综合光强combright,所构建的状态如式(8)所示:
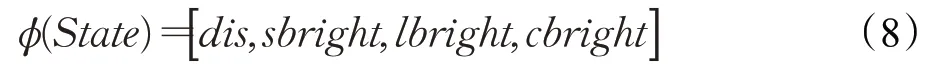
(2)动作空间A的选择及转移概率P
动作空间定义为对智能灯的调节动作。对智能灯进行调整主要分为两种方法,第一种模型的输出为连续动作,即模型直接输出智能灯的光强,智能灯根据模型的输出进行直接调整亮度;第二种模型的输出为离散动作,即模型的输出是基于当前的设备光强,对当前光强进行调高、调低或者不变。考虑到实验数据的离散性特征和强化学习算法本身的缺陷,本文采用第二种调整方法。动作空间A分为up,hold,down即up、hold、down代表对当前光强进行调高、不变或调低。
(3)环境反馈奖励R及奖励折扣γ
强化学习需要构造相应的奖励函数来进行模型训练。智能灯的优化目标是让当前用户不再对其进行调整。设置的奖励值如下,如果用户在给定时间范围内未对智能灯进行调整,则可以认为用户所在位置的综合光强符合用户偏好,环境应该返回一个正反馈1,同时若用户一直都没有对智能灯进行调整,则环境每次都要在当前的奖励值上乘以一个衰减率γ来获取新的奖励值,直到用户对智能灯进行调节才将奖励值重新设为1。如果用户调节系统,则可以认为用户所在位置的综合光强和用户偏好不符,则返回一个负反馈-1。达到算法和环境进行交互的效果,进而对模型进行训练。

其中,Icontrol为用户调整智能灯的次数,α为每次迭代中人未调整智能灯的单次交互次数,γ为奖励衰减率,i为每次迭代中人未调整智能灯的连续次数(γ=0.9,Rpositive=1,Rnegative=-1)。
3 实验设置
3.1 数据采集
本文采用DIALux软件模拟照明环境。DIALux是一个灯光照明设计软件,可根据实际需要向场景内部添加日光,能满足目前所有照明设计及计算要求。
考虑到不同照明环境或复杂的光源映射到算法中均为环境光强,本文使用亮度传感器对环境光进行采集则不需要考虑照明环境的光照复杂程度。
如图2所示,将模拟环境设置为一个5.4 m×3.6 m的房间,房间内设置一个窗户。在房间中央的桌子上放置一个功率可变的智能灯设备。通过调整智能灯的功率,可控制智能灯的光照强度。智能灯距窗1.8 m,距地面0.85 m,取距离地面0.85 m高为人们日常工作平面,可获取不同功率下工作平面上每个点在当前环境光影响下的光照强度。收集该房间内的光强数据缩略图如图3所示,图中红点为智能灯的位置,光强单位lx。

图2 环境场景布置Fig.2 Environment scene design
从图3可以看出智能灯附近的光照强度为300 lx左右,此刻窗边的光照强度为1 367 lx左右,通过调节智能灯的功率和环境光可以获得不同情况下房间内的光照强度。本文取智能灯和窗户之间的数据作为实验数据,分别在具有环境光和没有环境光两种情况下,调整智能灯功率取这段距离内的所有光照强度数据和此刻的日光数据。部分数据如表1所示。
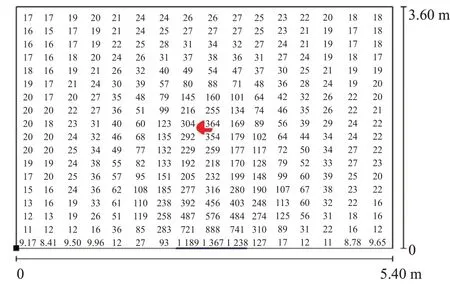
图3 房间内光强信息Fig.3 Illumination information in room

表1 模拟环境光强数据Table 1 Simulation illumination data
智能灯功率设置范围为250 W到450 W,步长为10 W,分析不同功率下获得的光照数据与距离的关系可得不同功率下光强与距离的关系呈同分布且距离智能灯越远,设备光强越弱,综合光强也越来越弱,但与智能灯距离超过0.42 m后由于自然光逐渐变强,综合光强也随之变强,考虑设备光强和自然光强的平衡性,实验取(0,0.42)m内的数据作为实验数据集。其中智能灯功率设置为250 W时,光强与距离的关系如图4所示。图4中,蓝色数据代表有环境光影响下的综合光照强度;红色数据为去除环境光时,设备光照强度。
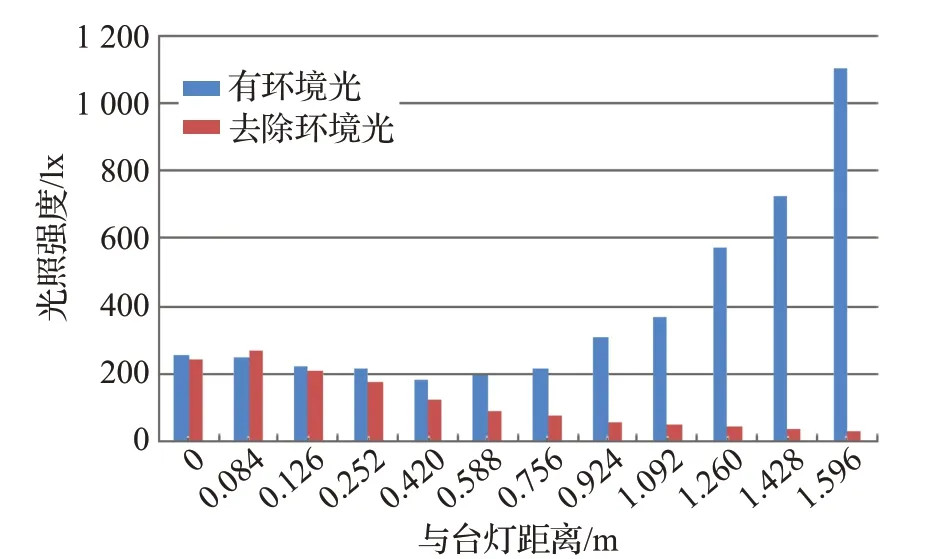
图4 光照强度与距离的关系图Fig.4 Relationship between illumination and distance
3.2 实验输入序列设置
使用上述所设置的智能灯功率和步长,以智能灯为原点对每个功率每隔0.056 m取一组综合光强、智能灯光强和环境光强数据,每个功率下共取7组。使用所采集数据根据2.2节规定的环境状态S对算法的输入序列进行构建。
根据《建筑照明设计标准》规定,学习时光照强度标准值为300 lx,考虑智能灯的使用场景,模型需要调整智能灯功率将当前距离下的综合光照强度保持在300 lx到320 lx之间,根据2.2节构建算法反馈奖励。在不同距离下对模型进行训练,实现用户无论与智能灯距离多远都能让光照强度保持在舒适范围内。
3.3 算法参数设置
实验中涉及到的三种算法输入状态、动作空间都相同,算法参数设置如表2所示。
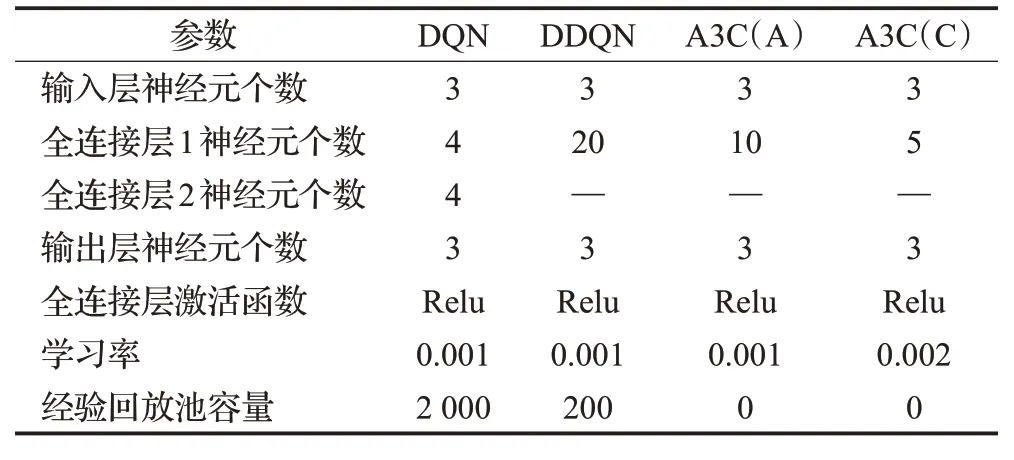
表2 算法参数设置Table 2 Algorithm parameter setting
本文使用表2中的参数采用Python语言中的Tensor-Flow框架进行实现,计算机硬件参数为Corei7-7700HQ,2.80 GHz。
3.4 实验结果
在模型训练过程中因为每次迭代与环境交互600次,所以每次迭代获得的奖励值最多不超过600。在模型训练过程中,每经过3个训练周期进行统计所获奖励的平均值,得出算法的奖励曲线,如图5~7所示。
从算法奖励曲线可以看出,DDQN算法(图6)在本实验中训练速度最快,同时泛化能力也很强,能够在很短的迭代次数内对没有遇到过的环境状态做出正确的决策,进而获得很高的奖励值。相比之下DQN算法(图5)泛化能力较弱,在没有遇到的环境状态下需要做出一定次数的学习才能很好地适应当前状态,但随着迭代次数的增加模型的泛化能力逐渐增强,奖励的总趋势也逐渐上升。
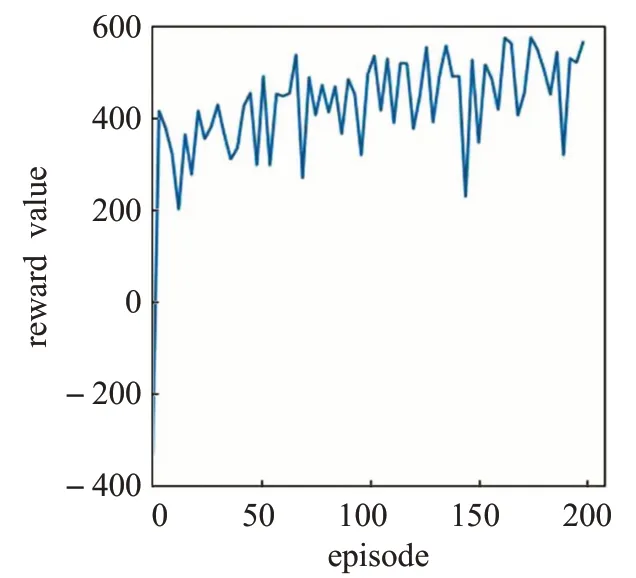
图5 DQN算法奖励曲线Fig.5 DQN algorithm reward
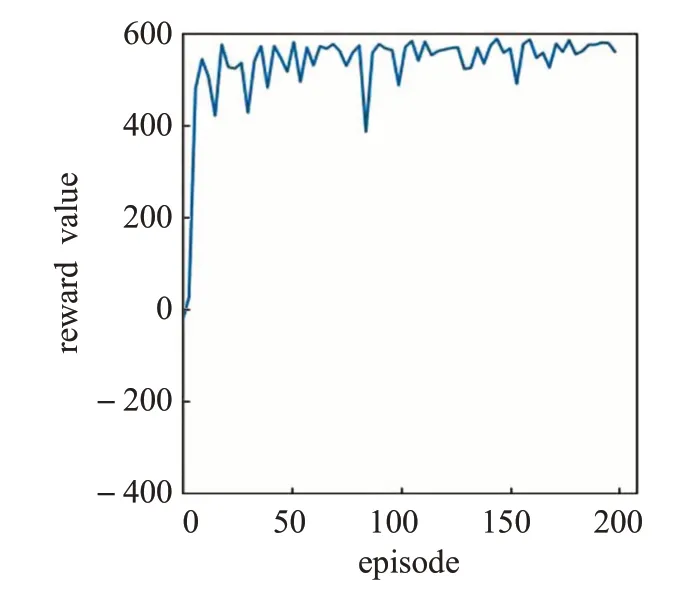
图6 DDQN算法奖励曲线Fig.6 DDQN algorithm reward
A3C(图7)模型训练速度相对DQN和DDQN更慢,因为A3C需要训练Actor网络和Critic网络,两个网络都收敛后才能获得稳定的模型决策,从A3C的奖励曲线可以看出该算法泛化能力很强,能够很快适应陌生的环境状态,决策准确率要高于DQN和DDQN,而且奖励曲线还在稳步上升。从模拟实验结果图中也可以看出DQN和DDQN在未经过预训练的情况下能够在很短的迭代周期内获取较高的奖励值,能够满足用户需求,而A3C算法则需要进行多次交互才能适应用户习惯,根据实际场景的应用情况,可以在应用前先对模型进行预训练,让模型达到一个普适的范围,然后在实际场景中对模型进行反馈调整,能够在应用中获取更好的用户体验。
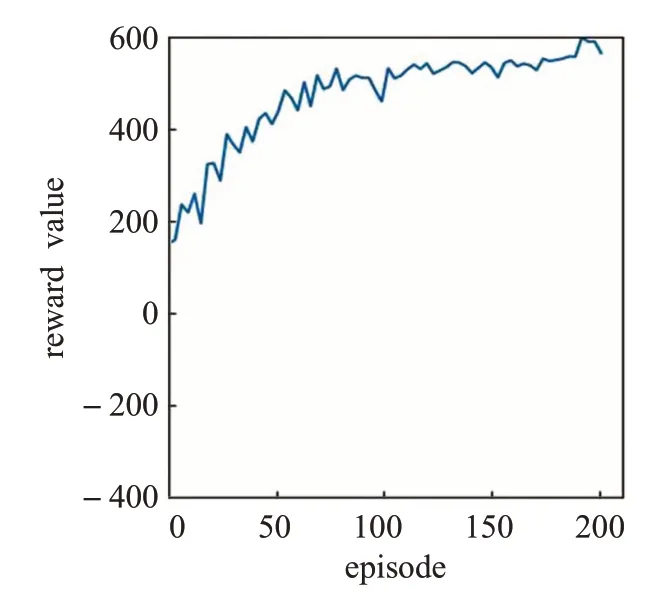
图7 A3C算法奖励曲线Fig.7 A3C algorithm reward
由于强化学习算法自身的性质,所有强化学习算法在与环境交互的过程中需要在执行的动作中加入噪声进行随机探索,因此奖励曲线存在一定的震荡现象是合理的。基于以上分析,DDQN模型和A3C模型随着迭代次数的增加平均奖励波动越来越小,从泛化能力上来看这两种算法都很适合应用在智能灯个性化亮度调节上。考虑到智能灯不是专用的计算设备,还需要从内存占用、训练时间等方面对算法进行对比分析,找出合适搭载到智能灯设备上的算法。表3统计了三种算法训练所需资源。

表3 算法训练过程中所需资源Table 3 Resources required in algorithm training
从训练时占用内存来看,三种算法训练所需内存差距不大,但从迭代次数和训练时间上来看DQN算法达到收敛所需的平均迭代次数和训练时间都很高,A3C算法需要的迭代次数较多是因为多个线程同时与环境进行交互,本实验设置4个Critic网络进行探索环境,每个线程在训练时间内与环境交互约30次,无论是训练时间还是收敛时所需迭代次数A3C算法和DDQN算法相差不大,但A3C算法需要使用多个线程与环境进行交互,当线程增多时训练时占用内存会高于DDQN算法。
综合以上分析,本文所提出的基于深度强化学习的智能灯亮度个性化调节方法完成了以下目标。
(1)在面对环境因素复杂的办公场所,不必对其进行建模,用户只需与智能灯进行交互便能让系统适应用户偏好。
(2)使用三种强化学习算法进行了模拟实验,对实验结果进行分析,对比算法间的差异,选出适用于智能灯设备的算法。
4 原型系统开发
为验证方案有效性,本文在实际环境中使用亮度传感器、距离传感器、nodemcu芯片、树莓派和小米Yeelight对本实验方案进行了验证。
4.1 数据采集模块部署
本文将亮度传感器和距离传感器通过GPIO引脚搭载到nodemcu芯片上,如图8、图9所示。

图8 亮度传感器连接nodemcuFig.8 Brightness sensor connect nodemcu

图9 距离传感器连接nodemcuFig.9 Distance sensor connect nodemcu
将芯片部署到智能灯周围。芯片启动后会和决策推理模块所在的树莓派建立socket连接,通过socket连接与树莓派进行通信,同时芯片向传感器所在的引脚发送信号,每隔一定的时间从传感器读取数据,将数据发送给树莓派。智能灯也通过Wifi模块与树莓派相连,将用户对智能灯的调节信息实时传输给树莓派,作为智能灯实现个性化的依据。
4.2 决策推理模块部署
树莓派启动后会对算法模型进行初始化,初始化方法与模拟实验中的方法相同,初始化完成后利用数据库中来自数据采集模块所收集到综合光强、环境光强、智能灯光强和用户控制信息对所部署模型进行个性化训练。
4.3 智能灯控制模块部署
树莓派根据算法模型推理结果,通过Wifi和智能灯建立socket通信,对智能灯进行亮度调节。再根据调节的结果获取用户反馈,对算法不断修正,直到当前模型符合用户偏好。实验结果与模拟实验大致相同,验证了本文提出方法的有效性。
5 结束语
论文针对智能灯亮度个性化调节问题所面临的挑战,提出基于强化学习的智能灯亮度个性化调节方法。通过使用传感器采集智能灯周围自然光强、综合光强等信息对当前环境和用户行为使用数据进行描述,利用强化学习算法的特性,无需对复杂的环境进行建模,就能对用户所在环境和用户偏好进行自适应,让用户无论在什么时间,距离智能灯多远的情况下都能获得最舒适的光强,并有效减少不必要的照明消耗。下一步将引入对多用户环境中不同用户亮度偏好冲突的解决策略,并考虑多个可变光源共同存在的复杂场景,以便更好地应用到实际工作生活中。
猜你喜欢
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
摄影之友(影像视觉)(2019年3期)2019-03-30 01:36:56
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
小天使·六年级语数英综合(2017年5期)2017-05-27 20:14:50
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
现代工业经济和信息化(2016年19期)2016-05-17 05:38:10
公民与法治(2016年23期)2016-05-17 04:21:08
家庭百事通(2016年3期)2016-03-14 08:07:17
