
Study on the resolution of multi-aircraft flight conflicts based on an IDQN
2022-03-08 03:26DongSUIWeipingXUKaiZHANG
Chinese Journal of Aeronautics 2022年2期
Dong SUI,Weiping XU,Kai ZHANG
College of Civil Aviation,Nanjing University of Aeronautics and Astronautics,Nanjing 211106,China
KEYWORDS Air traffic control;Conflict resolution;Multi-agent system;Multi-aircraft flight conflict;Reinforcement learning
Abstract With the rapid growth of flight flow,the workload of controllers is increasing daily,and handling flight conflicts is the main workload.Therefore,it is necessary to provide more efficient conflict resolution decision-making support for controllers.Due to the limitations of existing methods,they have not been widely used.In this paper,a Deep Reinforcement Learning (DRL) algorithm is proposed to resolve multi-aircraft flight conflict with high solving efficiency.First,the characteristics of multi-aircraft flight conflict problem are analyzed and the problem is modeled based on Markov decision process.Thus,the Independent Deep Q Network (IDQN) algorithm is used to solve the model.Simultaneously,a ‘downward-compatible’ framework that supports dynamic expansion of the number of conflicting aircraft is designed.The model ultimately shows convergence through adequate training.Finally,the test conflict scenarios and indicators were used to verify the validity.In 700 scenarios,85.71% of conflicts were successfully resolved,and 71.51%of aircraft can reach destinations within 150 s around original arrival times.By contrast,conflict resolution algorithm based on DRL has great advantages in solution speed.The method proposed offers the possibility of decision-making support for controllers and reduce workload of controllers in future high-density airspace environment.
1.Introduction
In recent years,with the rapid development of China’s civil aviation industry,air traffic flow has continued to increase.In 2019 China Civil Aviation Industry Development Statistical Bulletin,the civil aviation industry transported 659,934,200 passengers in 2019,an increase of 7.9%over the previous year.China’s civil aviation airports handled 11,660,500 takeoffs and landings in 2019,an increase of 5.2% over the previous year.From 2015 to 2019,the numbers of passengers carried and airport takeoffs and landings in civil aviation in China both increased year by year,with the average growth rate reaching 11.6% and 8.0%,respectively.In China’s civil aviation airspace,resources are limited,and the continuous growth of flight flow will lead to airspace congestion,which will increase the possibility of conflicts occurring in the operation of aircraft.
The control sector is the basic unit of air traffic control,and the service capacity of the control sector is usually limited by the controller’s workload.When an increasing flight flow gradually saturates the sector,the traditional measure is to share the workload of controllers by dividing the sector.However,the size of the sector has a critical state.When its size is too small,the control handoff load will be greater than the control command load,so that the effectiveness of sector segmentation is lost.According to the current trend of air traffic development,the existing sector operation mode will not be sustained in the future.At present,the controller’s workload mainly comes from the identification and resolution of flight conflicts.There is much auxiliary equipment for conflict identification,while conflict resolution depends mainly on the controller’s decision.At the same time,with the rapid development of Unmanned Aircraft System (UAS),the number of aircraft in the airspace continues to increase.How to ensure the safe and efficient flight of unmanned and manned aircraft in limited airspace is also important.This virtually increases the workload of the controller.To cope with the continuous increase of flight flow and reasonably reduce the controller’s workload,intelligent conflict resolution methods should be studied to provide the controller with decision-making support in line with actual operation.In actual operation,there are both two-aircraft conflict and multi-aircraft conflict in the control sector.In the multi-aircraft flight conflict resolution problem,the aircraft in the sector are in rapid motion,which requires the time to obtain the conflict resolution strategy as quickly as possible,and the joint cooperation of multiple aircraft is required to avoid conflict.Therefore,conflict resolution strategy must be efficient and coordinated on the basis of satisfying control regulations.
By analyzing the characteristics of the multi-aircraft flight conflict problem and incorporating the actual control operational regulations,the problem is modeled as a Markov Decision Process (MDP).The Independent Deep Q Network(IDQN) algorithm combined with the Deep Q Network(DQN) algorithm and an independent learning framework allows multiple conflicting aircraft to interact with the environment at the same time and obtain feedback,and the optimal resolution strategy can be obtained through continuous learning.At the same time,a flexible ‘downward-compatible’ conflict resolution framework is proposed to support the dynamic variation in the number of conflicting aircraft.Finally,the validity and applicability of the model are verified by data,experiments and related indicators.The rest of this paper proceeds as follows:Section 2 introduces the research basis,including related works on the study of flight conflict resolution,the definition of multi-aircraft flight conflict and control regulations.Section 3 analyzes multi-aircraft flight conflicts,and the problem is modeled and described.Section 4 introduces the principle of the IDQN algorithm,the design of the resolution mechanism,the method of solving models and the result of model training.Section 5 is the result analysis of the conflict test data,including the analysis of related indicators such as successful conflict resolution rate,conflict resolution trends,the delay time after resolution,calculation time and distribution of successful conflict resolution rate.Section 6 presents the conclusions and research prospects.
2.Research basis
Research on flight conflict management has been ongoing since its existence.Many scholars have studied flight conflict detection and resolution methods.At present,the methods of flight conflict detection have been developed comprehensively,but the methods of flight conflict resolution still attract much attention.This paper summarizes works related to the existing flight conflict resolution methods,puts forward research objectives,and gives a definition of multi-aircraft flight conflict.
2.1.Related works
There are three common methods of flight conflict resolution:the swarm intelligence optimization algorithm,the optimal control theory and the hybrid system model.In recent years,a fourth method has been derived,which uses Reinforcement Learning (RL) methods to solve flight conflicts.The swarm intelligence optimization algorithm is often used in conflict resolution.The conflict process is usually divided into a series of discrete segments according to equal lengths of time or distance and then optimized by the algorithm.In 1996,Durand et al.used a Genetic Algorithm (GA) to solve the flight conflict problem for the first time by considering the velocity error of aircraft and classifying multi-aircraft conflicts.On this basis,Durandlater proposed a conflict resolution method based on a neural network which learned through GA,and this method can effectively reduce the calculation time.However,it is difficult to extend to 3D conflict scenarios,and as the scale of neural networks expands,learning will be more difficult.To solve the problem with the shortest fuel consumption and the least resolution time,Stephane and Conwayused GA for conflict resolution considering the constraint conditions.However,the algorithm ran slowly and was not suitable for real-time solving.Later,Ma et al.used GA to solve the conflict between three aircraft under the condition of free flight,and also considered the problem of aircraft flying according to air route,but the model can’t be used when the number of aircraft increases.Hereafter,Guan et al.proposed a global optimization method combining Memetic Algorithms(MA)and GA to resolve conflicts between multiple aircraft and reduce calculation time.In addition to GA,Particle Swarm Optimization(PSO) algorithm is also used to resolve flight conflicts,and these swarm intelligence optimization algorithms have similar principles in implementation.In recent studies,researchers have combined these algorithms with multi-agent concepts,such as Emami and Derakhshan.used PSO algorithm to resolve conflicts and verified that the resolution strategy can reduce the delay time and fuel consumption.Zhou et al.applied a distributed Multi-Agent System (MAS) to the flight conflict resolution problem and integrated a distributed algorithm and adaptive GA to solve the problem so that the multi-aircraft conflict problem could be solved from a global perspective.However,as the number of aircraft in the scenario increases,the resolution time increases significantly.Liu et al.proposed an improved mechanism on the basis of PSO to plan time coordinated and conflict avoidance paths for multiple Unmanned Aerial Vehicles (UAVs),taking ETA,separation maintenance and performance constraints into consideration.
The purpose of applying optimal control theory is mainly to plan the optimal path of aircraft.In 1998,Bicchi et al.studied how to apply a robotic optimal control model to flight conflict resolution.Many constraints are set in the algorithm,the calculation is complicated,and the applicability is poor.Later,Menon et al.used a discrete waypoint model and ellipsoid conflict model to study flight conflict resolution,and the problem of optimizing the flight path is transformed into that of optimizing the parameters.Ghosh and Tomlin.combined the dynamic constraint problem with game theory and used dynamic system analysis to solve the flight conflict problem.All the above attempts aimed at solving the conflict problem of flights in 2D scenarios.Narkawicz et al.proposed a 3D geometric algorithm extended from the 2D optimal set algorithm on the basis of optimization theory to calculate the set of all points whose trajectories are tangent to the aircraft protection area and then reverse this process to obtain the resolution strategy.Hu et al.used the Riemann manifold method to solve the conflict problem,and formation flight was optimized.Later,Liu et al.obtained a controllable Markov chain by discretizing the flight conflict process,and the solution of the stochastic optimal control problem was obtained by finding the optimal control discipline.Han et al.constructed the optimal conflict resolution model of aircraft on the same flight level by using optimal control theory under the condition of flying along a fixed route,and the operation instructions of the aircraft in each substage were obtained according to the optimal conflict-free track.Tang et al.proposed a dynamic optimal resolution strategy based on rolling time-domain optimization on the basis of a static single optimal resolution strategy considering the heading and low speed adjustment,including uncertain factors such as velocity disturbance that may exist during aircraft flight.Li et al.proposed a distributed conflict resolution method based on game theory and Internet of Things (IoT) technology for UAVs.Using game theory,it is possible to theoretically obtain a balanced optimal conflict-free trajectory suitable for multiple UAVs,and this method can also be applied to civil aircraft flightto obtain an optimal and balanced resolution strategy.
Conflict resolution based on a hybrid system model decentralizes the control function to each aircraft for conflict resolution.A hybrid system is a dynamic system,which is a special case of optimal control theory.Pappas et al.performed conflict resolution by switching flight states,and the motion parameters of aircraft at different flight phases were calculated to control the motion states to ensure that the flight of aircraft was within the envelope of flight safety restrictions.This is regarded as a conflict resolution strategy.Tang et al.used a hybrid system model to detect and solve flight conflicts in real time,and the changes in the distance or speed of the aircraft over time are shown in the form of a curve,and based on which,conflict detection and resolution were carried out.In 2017,Soler et al.transformed the conflict-free track planning problem into the problem of hybrid optimal control.The discrete mode of the hybrid system was used for conflict resolution,and an actual seven-aircraft conflict scenario was simulated to find the conflict-free track with the lowest fuel consumption.
The method of RL takes an aircraft as an agent with functions such as consciously receiving instructions,executing instructions and changing states.The aircraft learns by constantly interacting with the environment of a conflict scenario,and it obtains the optimal resolution strategy through the guidance of the reward function.In flight conflict resolution,the data dimension that needs to be recorded is large,so the powerful recording capability of neural networks is needed,that is,the Deep Reinforcement Learning (DRL) method.The DRL method began to be developed in approximately 2015,and it is mainly applied in robotics,strategy games and other fields.In recent years,researchers have tried to use DRL method to solve the problem of flight conflict resolution.In 2018,Wang et al.proposed-Control Actor-Critic(KCAC) algorithm to choose the random position for aircraft to avoid conflict.Considering the turning radius of the aircraft,they obtained the optimal or sub-optimal conflict-free flight trajectory by limiting the number of control times and heading changes,which proved the computational efficiency of DRL algorithm.In 2019,Pham et al.used the Deep Deterministic Policy Gradient (DDPG) algorithm of DRL to establish an automatic flight conflict resolution model,and the test showed that the method under conditions of uncertainty can effectively solve conflicts between aircraft.Under different uncertainties,the precision of the model is approximately 87%,showing that the DRL method of solving flight conflicts is a promising approach,but it is only used for twoaircraft flight conflicts and does not extend to multi-aircraft flight conflict scenarios.Then,Pham’s teamincorporated the experience of an actual controller,and the model trained through DRL could learn from the controller’s experience.The experimental results showed that the matching degree of the resolution scheme obtained by the training model and the controller’s manual solution was 65%.In 2019,Wang et al.applied DRL to flight conflict detection and resolution strategies and developed a suitable training and learning environment for aircraft conflict detection and resolution by changing 2D continuous speed actions and headings to select a strategy.The study showed the possibility of applying DRL to the flight conflict resolution problem,which has obvious advantages in terms of calculation efficiency,but the research used only 2D continuous action adjustments without considering changes in altitude or other control instructions.
Based on the analysis above,there are many methods to solve conflicts.At the same time,all kinds of more complicated and practical conditions are gradually being taken into consideration,but this problem still has research value.To compare the features and limitations of various research methods more clearly,the methods mentioned above are displayed in Table 1,which contains the method category,whether the method is based on the assumption of free flight,the number of conflicting aircraft,the types of conflict scenarios,and whether the method is based on actual control regulations.
The characteristics of the research methods in Table 1 are summarized as follows:(A) Most conflict resolution methods are based on the assumption of free flight.(B) The methods that can resolve a multi-aircraft conflict problem can be used to resolve two-aircraft conflicts,but the reverse situation is not necessarily feasible.(C) Most conflict resolution methods only consider 2D scenarios,that is,adopt speed or heading adjustments to resolve a conflict in the same plane.(D) Few conflict resolution methods consider the restrictions of control operational regulations.Although these studies can resolve the flight conflict problem to a certain extent,some methods have some shortcomings.For example,methods 1,2,3,4 and 7 have low calculate efficiency.They may have been limited by the equipment at the time and the low efficiency of the GA in decoding.Methods 10,12,16 and 22 have the problem ofscenario specialization,that is,these methods can only address smaller scenarios,and some can only resolve specific twoaircraft or three-aircraft flight conflicts.
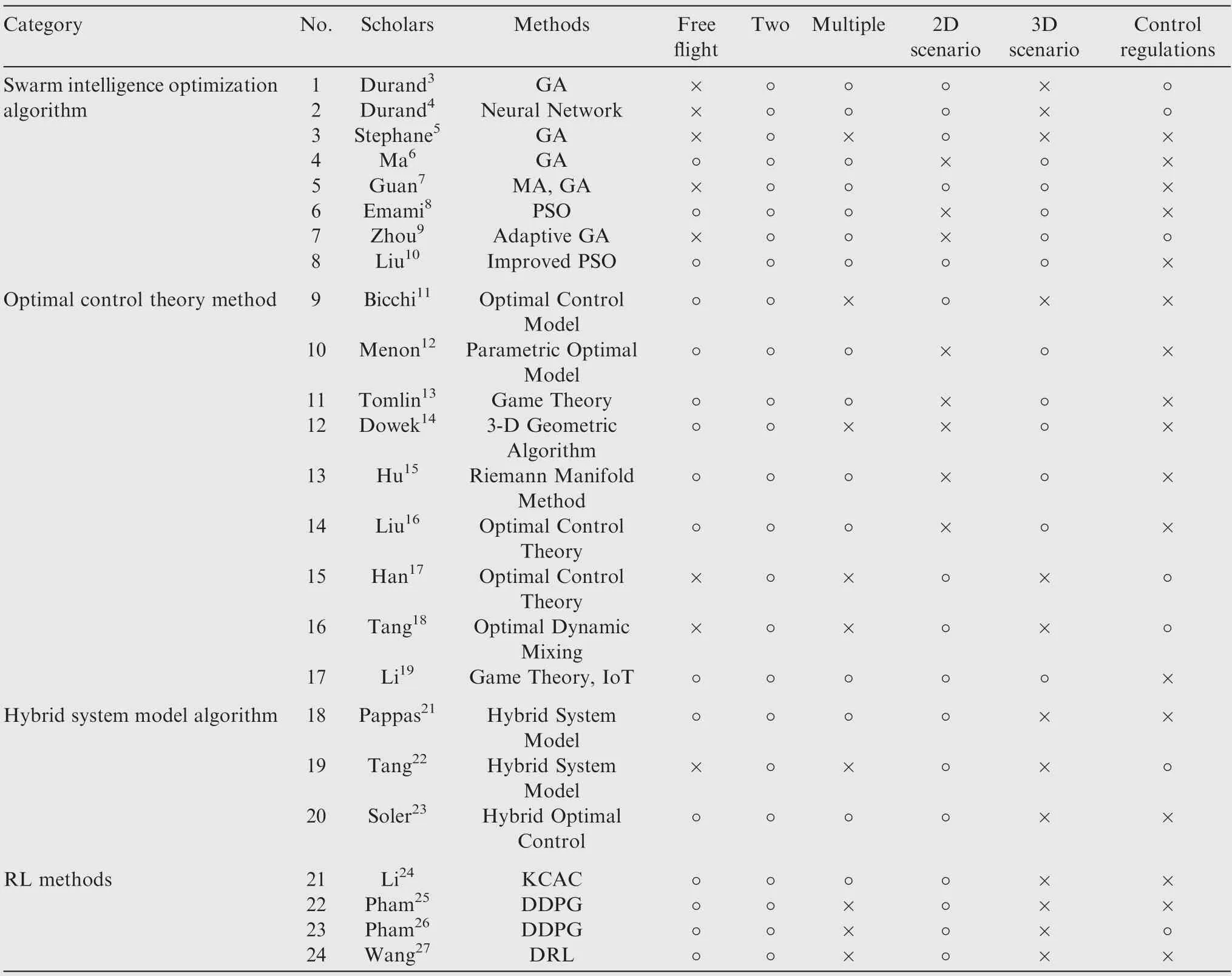
Table 1 Features of flight conflict resolution methods.
In actual operation,flight conflict resolution needs to meet the requirements of flying along the air route,solving the 3D conflict problem,and adjusting based on the control operational regulations.Among the methods above,only the method proposed by Zhou Jian (No.7) can meet these three requirements at the same time.This method improved the traditional GA,but with the increase in the number of aircraft,the algorithm programming needs to be modified accordingly,the programming will become complicated,the convergence speed will become slower,and the time needed to obtain the resolution strategy will increase.Therefore,for flight conflict resolution,on the basis of meeting three basic requirements,it is also necessary to achieve the research objectives of high efficiency,resolving multiple types of conflict scenarios and addressing dynamic changes in the number of conflicting aircraft.In this paper,combined with the basic requirements and research objectives,the IDQN algorithm of DRL is proposed to solve the multi-aircraft flight conflict problem,which can be greatly improved by offline training and online use.At the same time,an extensible framework is designed to support dynamic changes in the number of conflicting aircraft.
2.2.Multi-aircraft flight conflict
A flight conflict is a situation in which the distance between aircraft is less than the specified minimum radar separation during flight.During en-route flight,the horizontal separation should not be less than 10 km,and the vertical separation should be in accordance with the flight level.If the distance between two aircraft is less than the minimum radar separation in both horizontal and vertical directions,it is considered a flight conflict.The moment when the distance between two aircraft first reaches the minimum separation and the aircraft continue to approach each other is regarded as the moment of flight conflict.
There is no clear definition of multi-aircraft flight conflicts in the official documents of organizations such as ICAO.Conceptually,a multi-aircraft conflict is a situation in which an aircraft conflicts with two or more other aircraft in a certain time and space.However,this definition cannot cover all kinds of situations and is not precise enough,so it is necessary to supplement and clarify the definition of multi-aircraft flight conflict.
A multi-aircraft flight conflict is a situation in which multiple aircraft have flight conflicts within a certain space and a certain period of time.It is also necessary to ensure that at least one aircraft can be connected to other aircraft through their conflict relationships.To illustrate the definition of multi-aircraft flight conflicts more visually,several scenarios are shown in Fig.1.There are three constraints in the definition,and a situation cannot be defined as a multi-aircraft flight conflict if it does not satisfy all three constraints at once.In the later training and testing parts,samples of conflict scenarios used are satisfied with all constraints as shown in Fig.1(d).
Fig.1(a):The two conflict points meet the time constraints,and the three aircraft can be connected at the same time,but they exceed the space limit,so this is considered as a twoaircraft conflict rather than a multi-aircraft flight conflict.
Fig.1(b):The two conflict points meet the space limit,and three aircraft can be connected at the same time,but they exceed the time limit,so this is considered as a two-aircraft conflict rather than a multi-aircraft flight conflict.
Fig.1(c):The two conflict points meet the constraints of space and time,but they are isolated from each other and cannot be connected.Therefore,this is regarded as two twoaircraft conflicts instead of one multi-aircraft flight conflict.
Fig.1(d):The space and time constraints are satisfied,and the two independent conflicts can be connected through aircraft E,so this can be defined as a multi-aircraft flight conflict.
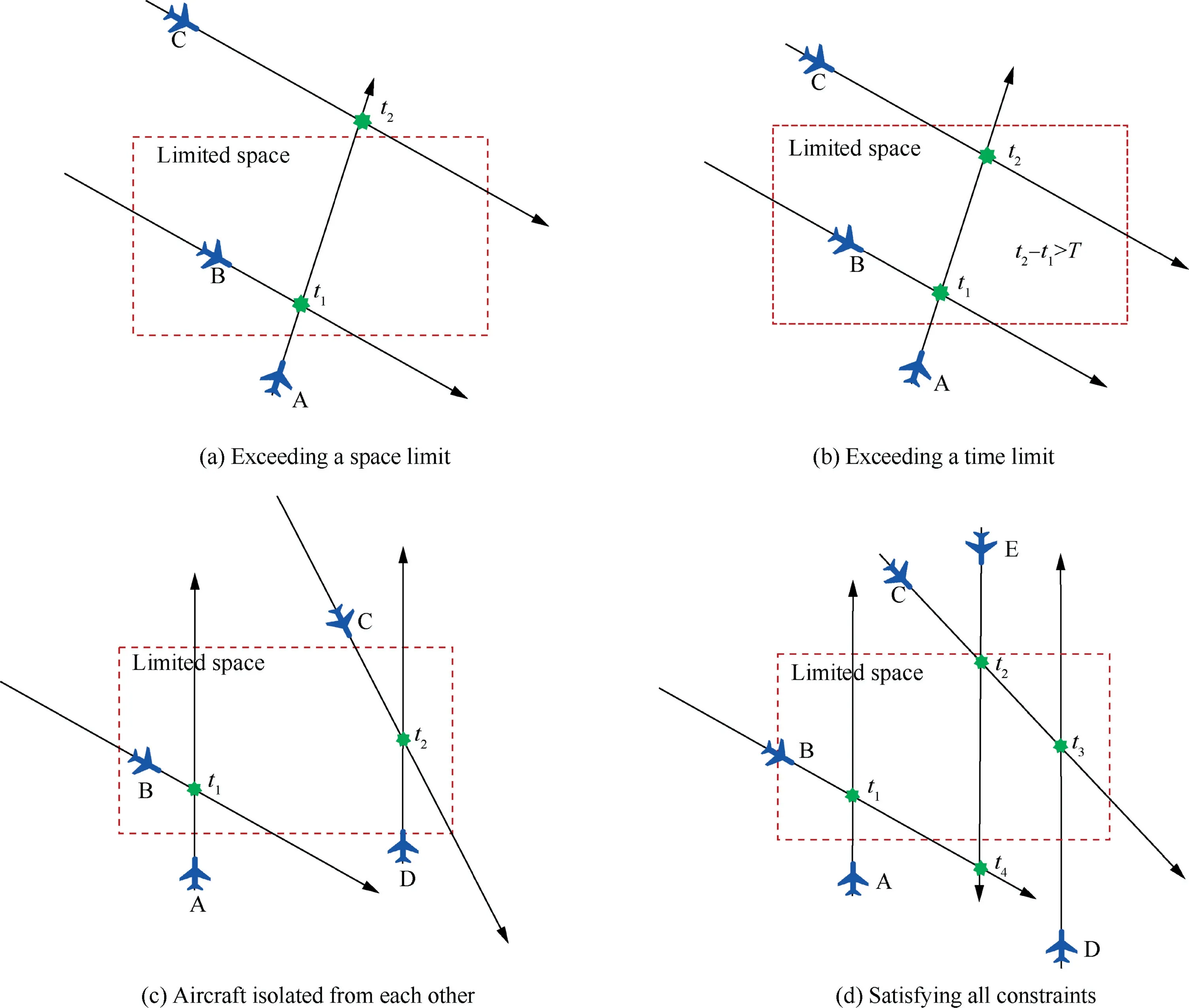
Fig.1 Schematic diagram of multi-aircraft flight conflicts.
Therefore,only when all three constraints are met can a multi-aircraft flight conflict be defined.A multi-aircraft flight conflict can be considered as a combination of multiple twoaircraft conflicts whose intervals are defined in accordance with the radar control interval above.The limited time period should not be set too long.If the time is too long,it will be more efficient to resolve the problem of the multi-aircraft flight conflict as multiple two-aircraft conflicts.Through experimental research,it is found that setting Time=4min is an appropriate value.
2.3.Air traffic control regulations
After the controller identifies the flight conflict,the controller continuously monitors the status of all aircraft in the sector in charge through the airspace dynamic information provided by the Air Traffic Control(ATC)automation system and coordinates the flight conflicts among aircraft.According to ATC regulations,controllers’experience and dynamic airspace environment,controllers usually adopt three kinds of resolution methods:altitude adjustments,speed adjustments and heading adjustments.
(1) Altitude adjustments.This is the most frequently used and most effective adjustment.The aircraft en-route fly in accordance with the flight level provided.China is currently using the latest flight level configuration standard,which was implemented at 0:00 on November 22,2007.At the same time,the RVSM is implemented in the range of 8900 m -12500 m.The altitude ranges from 900 m to 12500 m,and every 300 m is a different flight level.Above 12500 m,there is a new flight level every 600 m.When the controller uses altitude adjustments,it is necessary to abide by the flight level configuration standard.
(2) Speed adjustments.This is a common resolution adjustment.At the cruising level,generally,aircraft fly according to the economical cruising speed stipulated by the airline to which it belongs.However,in certain circumstances,it is necessary to intervene in the aircraft speed,such as in the case of an over-waypoint speed limit or a conflict on the air route.When using speed adjustments,the controller should follow the corresponding regulations:at levels at or above 7600 m,speed adjustments should be expressed in multiples of 0.01 Mach.At levels below 7600 m,speed adjustments should be expressed in multiples of 10 kt based on the Indicated Air Speed(IAS).
(3) Heading adjustments.The heading refers to the angle measured clockwise from the north end of the meridian to the extension line ahead of the aircraft’s longitudinal axis.The specific means of making heading adjustments include radar guidance and offset.The method of radar guidance requires a large airspace range,and it commonly uses the ‘dog-leg’ maneuver and direct flight to the next waypoint,which is usually used in the terminal area or to deal with severe weather such as thunderstorms during an air route flight.The offset method is widely used in air route flights.The left or right offset method is used to offset a distance to the left or right parallel to the centerline of the air route to widen the lateral space between aircraft.The offset is usually adjusted in nautical miles (nm),such as 6 nm.
3.Modeling of multi-aircraft flight conflict
From the analysis above,it can be seen that the key part of flight conflict resolution is to build the problem model and then use relevant methods to solve and calculate the model to obtain the theoretically optimal conflict resolution strategy.Therefore,it is necessary to analyze the problem of multiaircraft flight conflict and select an appropriate method to model the problem.
3.1.Problem analysis
When determining the resolution strategy,the selection of actions for multiple aircraft needs to be considered.An aircraft has autonomous functions,such as receiving instructions and changing the flight status.It can be abstracted as an agent,so an aircraft agent is established,whose internal structure is shown in Fig.2.The agent has the functions of generating an aircraft trajectory according to the flight plan and database files,receiving control instructions and status query signals,transmitting status information and so on.In a multi-aircraft flight conflict scenario,multiple aircraft agents are involved,and these aircraft agents are related to each other.Therefore,the multi-aircraft conflict scenario can be regarded as a MAS.
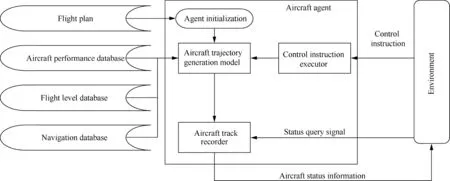
Fig.2 Internal structure of an aircraft agent.
The typical modeling method for a MAS is to model the problem as an MDP or stochastic game process.Which modeling method should be adopted depends on the characteristics of the scenario.From actual control resolution regulations,when potential conflicts are detected,the controllers send resolution instructions according to the current state of aircraft and the future airspace trends,without considering the earlier states before the aircraft executed the instructions.Therefore,after the aircraft executes the conflict resolution instruction,the next environment feedback is only related to the current state and action,which is in line with the precondition of MDP,that is,Markov property.The dynamic process of MDP is shown in Fig.3.The agent’s initial state is,an actionis selected for execution,and the agent is randomly transferred to the next stateaccording to probability.Then perform another actiontransfer to the next staterepeat the process and continue.
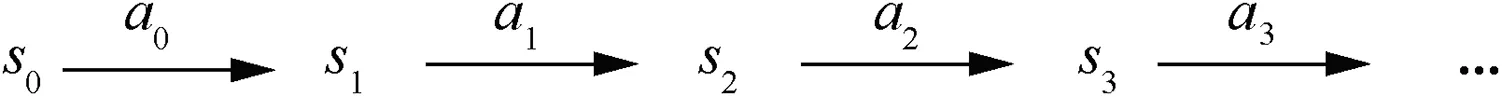
Fig.3 MDP dynamic process diagram.
A reward ris given for the transition from state sto state sthroughout the process.As the state changes,the value of the cumulative reward given can be calculated using the Fig.4,which shows the MDP process diagram with rewards.
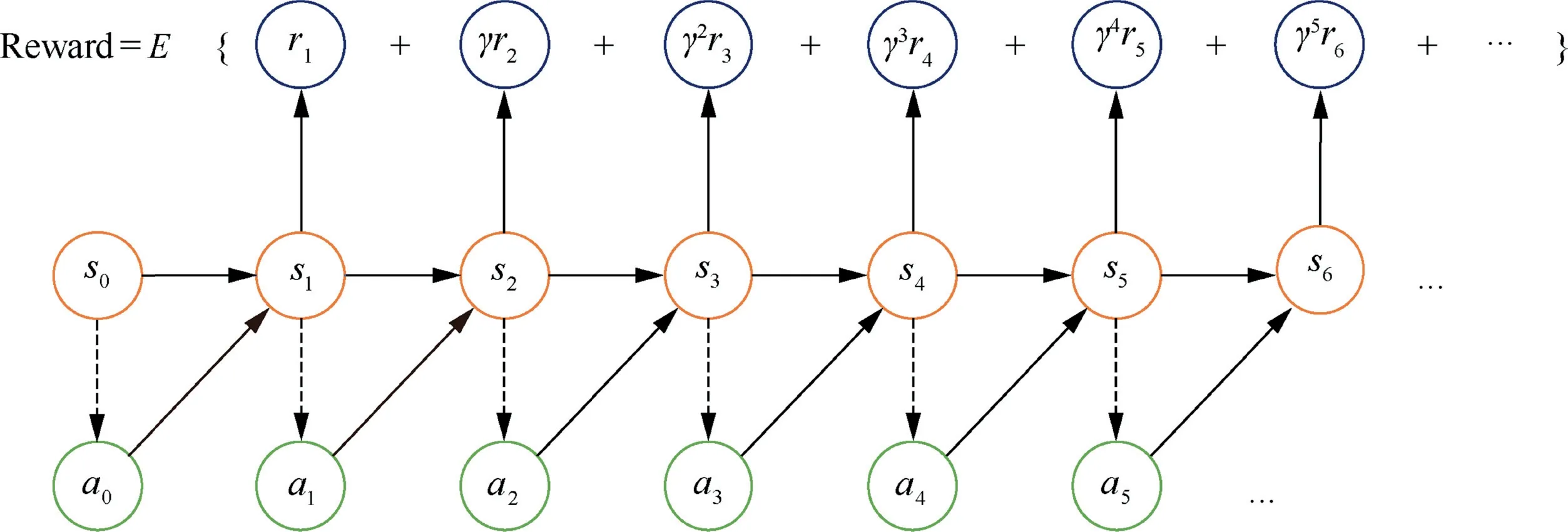
Fig.4 MDP diagram with rewards.
According to the above introduction,Temizer et al.described that when there is no information uncertainty,the optimal control problem of stochastic systems can be described as MDP.In this paper,since the research is to provide decision-making support to the controller,all aircraft information is assumed to be available through tools like ATC automation system,so there is no question of information uncertainty and communications between aircraft can be ignored,so the multi-aircraft flight conflict resolution problem can be modeled as an MDP.
3.2.Model description
Through the above analysis,the multi-aircraft flight conflict scenario is modeled as a MAS,in which each conflicting aircraft is regarded as an agent that has the ability to receive the controller’s instructions,execute the resolution instructions,and fly according to the track prediction model.These aircraft agents are independent of each other and do not have any other corresponding behaviors,such as communication.An independent learning framework is adopted for training and learning.Therefore,each aircraft in the conflict environment has an MDP model,which is specifically expressed in the following four parts:MDP=(,,,).
(1) State space
The state space is expressed as={,,...,S},andS(∈)represents the state of one small grid.The state space is the collection of the position and state information of all aircraft in the control sector at a certain time.The aircraft performs flight trajectory prediction 5 min in advance.The point where the aircraft is 10 km apart for the first time and continues to approach is considered the Minimum Safe Interval Point(MSIP),as shown in Fig.5(a).Aircraft A and aircraft B reach the MSIP at time.If the aircraft continues to fly and maintains the minimum safety interval to aircraft C at time,the positions of aircraft A and B at timeand aircraft C at timeconstitute a polygon,with the polygon’s center of gravity as the center of the state space.If there are other aircraft causing multi-aircraft flight conflicts,the expansion continues in accordance with the above method.
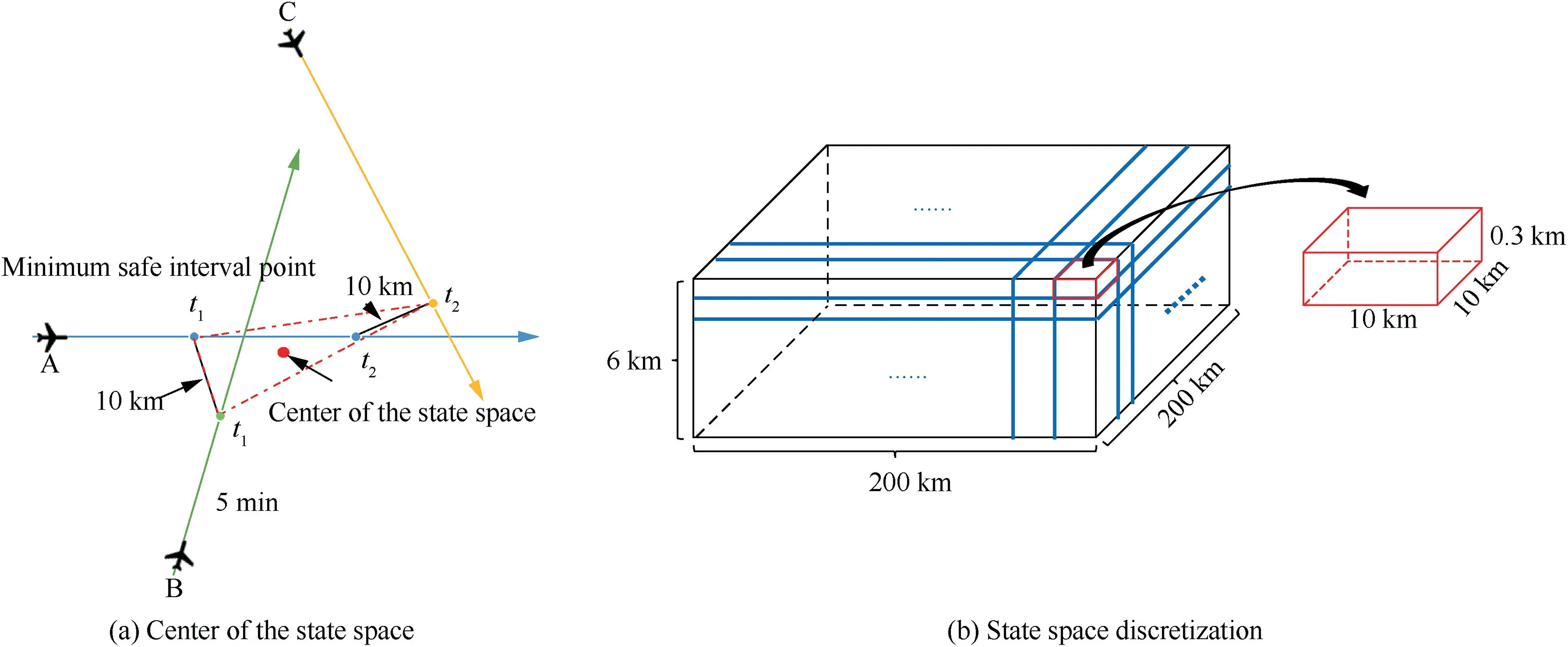
Fig.5 Schematic diagram of the state space set.
(2) Action space
The action space is expressed as.The action space consists of the conflict resolution adjustments that the controller can make at each moment.In this paper,speed adjustments,altitude adjustments and heading adjustments are mainly used.
Speed adjustments include accelerations and decelerations that are integer multiples of 10 kt with a maximum range of 30 kt,acceleration is indicated by ‘+’ and deceleration by‘-’.The speed action set is expressed as={+10,+20,+30,-10,-20,-30}.
Altitude adjustments include ascents and descents in integer multiples of 600 m with a maximum range of 1200 m,ascent is indicated by ‘+’ and descent by ‘-’.The altitude action set is expressed as={+600,+1200,-600,-1200}.
Heading adjustments include offset and direct flight to the next waypoint,where the offset is 6 nm,a right offset is indicated by ‘+’ and a left offset by ‘-’.The heading action set is expressed as={DirectToNext,+6,-6}.
(3) State transfer function
The state transfer function is expressed as P,which refers to the process by which the state of a certain aircraft is changed after the statesof all aircraft in the airspace at the current moment change to the next stateafter the instruction actionissued by the controller is taken,which is denoted as(|,)or(,|,) if the rewardis obtained.In this paper,deterministic state transfer is adopted,that is,after the actionis executed,the next state that the aircraft reach is uniquely determined according to the track prediction program.During the state transition,the track prediction program based on nominal data is used to calculate the flight path of aircraft quickly.The nominal data of commonly used aircraft types can be obtained from the Base of Aircraft Data (BADA)database.
(4) Reward function
The reward function is expressed as,it is an important tool to guide the intelligent behavior of agent trained by RL.During each state transfer process,the agent executes the selected action and moves to the next state,obtaining the corresponding reward value.Assuming the current state is,the next state isthat the agent reaches after executing action,then the environment returns a rewardfor the actionto the agent.The agent indicates the quality of the selected action through the reward function to guide the agent not to choose the action that yields a low accumulative reward.Due to the complete cooperation between multiple aircraft,the form of the reward function for each aircraft is the same.To measure the overall resolution effect and the execution effect of a single instruction,the reward function is divided into two parts:the overall reward and the individual reward.The overall reward measures the overall resolution effect after the whole conflict resolution process,and the individual reward measures a specific resolution instruction.
In the multi-aircraft flight conflict resolution model,the resolution time is stipulated to be 5 min of the complete process,and the timeline of the resolution instructions is as shown in Fig.6.In the conflict scenario,the entire resolution time is 5 min.After the resolution,5 min is added as the observation time to ensure the resolution result.The whole process lasts 10 min.Multi-aircraft conflict scenarios can be divided into multiple two-aircraft conflicts,and there areconflict pairs in total.The time interval between the first and last conflict pairs is no more than 4 min according to the definition.In the resolution phase,when the aircraft detects the first conflict,the resolution begins.The first group of action instructions is sent to each conflicting aircraft at 30 s,and the aircraft executes the action instruction within the interval 30-120 s.If the conflict is not resolved during the execution or a new conflict arises during this period,the scenario will be terminated and the next training episode will be started.If there is no new conflict until the end of execution,a certain reward will be given and the flight conflict scenario will end.If the work is carried out within 30-120 s,no new conflict is generated,but a new conflict occurs after 120 s,the second group of action instructions is assigned to each conflicting aircraft at 120 s,and then the aircraft execute the action within the interval 120-210 s.The execution is the same as in the above process.The controller has the right to issue three groups of instructions in total.
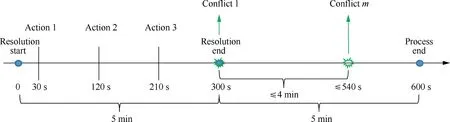
Fig.6 Timeline of the IDQN-based multi-aircraft flight conflict resolution instructions.
On the basis of the conflict resolution instruction timeline,a certain reward function should be given.As an important research object and a hyper-parameter in RL,the reward function needs to be determined before the whole training begins.At present,although there are studies on reward function learning,in most RL application cases,the reward function is still set according to the training target and modified according to many trials,so it is arbitrary.Initial attempts to use RL to resolve multi-aircraft flight conflicts have focused on the effectiveness,flexibility and practicality of strategies,and reward function set still uses artificial settings.When setting the reward function,the following basic principles should be followed:
· The distribution of the reward function should show the recognition or the disapproval of the target taken by the agent,and the reward function usually increases monotonically as the expected value of the action increases.
· The reward function can adapt to the change of environment caused by the action.
· If the reward function contains several components,the magnitude of the reward function value of each component should be uniform,so as to make the evaluation of actions more balanced.
· The reward function can be divided into the round reward,which only gets one reward at the end of the scenario,and the one-step reward,which gets one reward after each action.
· Usually in RL,the reward function is finally unified into a mathematical expression.
Following the above principles,the setting of reward function in flight conflict problem needs to meet the following objectives:(A) Complete flight conflict resolution without causing new flight conflicts.(B) The amplitude of instructions should be as small as possible.(C) The resolution time is as short as possible.In order to get better training result,the design of reward function must take into account several factors.Firstly,the reward function is divided into individual rewardand overall reward.The individual reward is the evaluation of the actions taken by a single agent,while the overall reward is the evaluation of the overall resolution effect after the actions taken in each conflict scenario.Second,the solution of the problem can be divided into infeasible solution and feasible solution.The infeasible solution refers to the solution beyond the scope of aircraft performance or in violation of actual control habits,such as the climbing action followed by the descending action.The feasible solution is the solution other than the infeasible solution.In this part,the reward function is needed to distinguish the two in order to make the aircraft more likely to take more optimal solution within the range of feasible solutions.Then,in the process of seeking for more optimal solution,the constraints such as the amplitude of adjustment instructions,the time of resolution,the success of failure of resolution and whether new conflicts will be caused need to be taken into account.Thus,through the process of ‘training-observation-modifying’,the reward function can be formed like the following.
(1) From the perspective of a single agent,the reward function can be set in the form of Eq.(1),mainly considering whether it is a feasible solution and the adjustment range of the instruction.

(A) If the action falls within the range of infeasible solutions,the reward ris given according to Eq.(2),where pis the variable parameter,usually negative.

(B) If the action falls within the range of feasible solution,the amplitude of the action is taken into account,and the greater the adjustment,the lower the reward.According to the different types of action taken,it can be divided into altitude reward r,speed reward rand heading reward r,and the rewards are given according to Eqs.(3)-(5) respectively.
(a) Altitude reward.The reward for an excessive altitude adjustment is shown like Eq.(3),where AltCmd represents a specific altitude instruction value,prepresents the maximum reward value in the altitude adjustment,qis parameter that adjusts the magnitude.

(b) Speed reward.The reward for an excessive speed adjustment is shown like Eq.(4),where SpdCmd represents a specific speed instruction value,prepresents the maximum reward value in the speed adjustment,qis a parameter that adjusts the magnitude.

(c) Heading reward.The reward for a heading adjustment is shown like Eq.(5),pand qcorrespond to the reward value of different heading actions,which can be customized according to the user’s preferences.

(2) From the perspective of the effect of the overall conflict resolution process and combined with the instruction assignment timeline in Fig.6,there may be four situations after an action is taken,and the rewards under different situations are given according to Eq.(6).

Conflict resolution is successful.Calculate the reward according to the first equation in Eq.(6).The equation takes conflict resolution time into account,and the shorter the resolution time,the higher the reward value.The nowtime represents the time when the conflict is resolved and starttime represents the time when the resolution starts,prepresents the maximum possible reward,qis a parameter that adjusts the magnitude.
Conflict resolution is failure and there are new conflicts.Calculate the reward according to the second equation in Eq.(6).In this case there is a negative reward p<0.In general,the penalty in this case is high,so the value of pis relatively high.
Conflict resolution is failure and there are no new conflicts.Calculate the reward according to the third equation in Eq.(6).In this case there is a negative reward p<0.This punishment is slightly smaller than the punishment in situation 2,that is |p|≤|p|.
The execution is not successful within a certain period of time but the resolution is not complete.Calculate the reward according to the fourth equation in Eq.(6).In this case there is a reward p>0.Usually,this is a relatively small reward.
Due to the particularity of the MAS,the overall resolution strategy should be optimized through cooperation among various aircraft.Therefore,an agent with a lower reward should be rewarded as much as possible through learning.The total reward valueis shown in Eq.(7),where∈represents aircraft.

4.Resolution scheme based on an IDQN
After the multi-aircraft flight conflict problem is modeled,an appropriate method is selected to solve the model.The multi-aircraft flight conflict resolution strategy has dynamic and real-time requirements.Conflict scenarios contain highdimensional data and require a large storage space and running memory.Therefore,the traditional RL algorithm cannot effectively address this problem.The DRL method developed in recent years makes use of the strong recording ability of neural networks,which can solve the dimensional problem well.Meanwhile,the method of offline training and online use greatly increases the solving speed.Therefore,the DRL method is adopted to solve the problem model.DRL was invented in 2013,and Google DeepMind designed the DQN algorithm.After years of development,the DQN,DDPG,Bic-Net,COMA and other algorithms have been proposed,but many aspects of the algorithm application ability in solving practical problems remain to be verified,so this paper chooses the DQN algorithm as the basic algorithm,and by using the framework of independent learning extensions in the field of multi-agent problems,the IDQN algorithm for the multiaircraft flight conflict model is derived.
4.1.Fundamentals of the algorithm
The RL process mainly consists of agent,environment,states,actions and rewards.The agent obtains the state through the environment,observes the state,uses the strategy to take an action,and gives feedback to the environment.After the environment executes the action,it transmits the new state as the new observation,and at the same time transmits the reward of the action to the agent.The agent continuously interacts with the environment through the above process and learns the best strategy by maximizing the cumulative reward.
The DQN algorithm is a mature DRL algorithm,and the IDQN is the DQN algorithm using an independent learning framework,from a single-agent problem to a MAS.Before using the IDQN algorithm to solve the multi-aircraft flight conflict problem,the relevant fundamentals of the DQN algorithm and the independent learning framework are briefly introduced.
(1) DQN algorithm
The DQN algorithm is a DRL algorithm,and it combines Q-learning algorithms and neural networks which have powerful representation ability.It uses the information of the environment as the state of RL and as the input of the neural network model.Then,the neural network model outputs the value (value) corresponding to every action,and actions are executed.Therefore,the focus of the algorithm is to train the neural network model so that it can obtain the optimal mapping relationship between the environmental information and the action.There are a series of neurons in the neural network,and the weights of the neurons are constantly updated in the process of training,so it is necessary to set an objective function for them,which is generally a loss function.The DQN algorithm constructs the network optimized loss function through the-learning algorithm.According to the literature,the update equation of the-learning algorithm is:
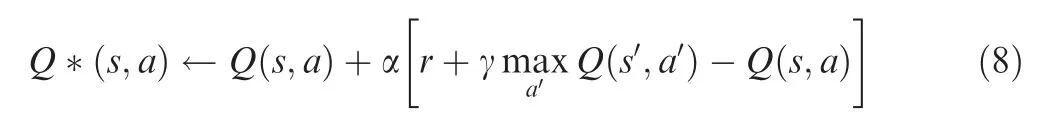
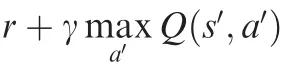
According to Eq.(8),the loss function of the DQN algorithm is defined as follows:

where θ represents the weight of the neural network model.
Since the loss function in the DQN algorithm is determined based on the update equation of thevalue in the-learning algorithm,Eqs.(8) and (9) have the same meaning,and both approach the targetvalue based on the current predictedvalue.After the loss function is obtained,the weights θ of the loss function(θ) of the neural network model can be determined by the gradient descent algorithm.
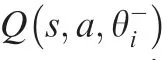
(2) Independent learning framework
The DQN algorithm itself is designed for a single-agent problem.When the number of agents in the environment is greater than one,it becomes a multi-agent problem,the relationship among the agents becomes complicated,and any changes in the agent actions may influence other agents.Therefore,the problem of a MAS is a problem that many researchers have studied in recent years,and many research directions have developed from it.For example,agent communication behavior and the mutual modeling of other agents have been studied.The independent learning framework is one of the research directions,which mainly concerns the behavior relations between agents,that is,whether agents in the MAS have cooperative relations,competitive relations or complex mixed relations,their relations are usually reflected by reward functions.
In the independent learning framework,each agent is regarded as an independent individual in the MAS,each agent has a neural network for training and studying,and there is no communication between them.This is a simple learning framework that extends the single-agent method to MAS problems.The IDQN directly extends the DQN algorithm to a MAS.Eachvalue network controls a single agent.For systems withagents,value networks are required that correspond to them.Independence is assumed,which means that there is no coupling relationship between thevalue networks and no communication behavior between the networks,and data are independently sampled from the environment to update the network.The structure of the IDQN does not explicitly express cooperation between agents but allows agents to infer how cooperation should be conducted in the course of training based on changes in the state and reward functions.The framework of the IDQN algorithm is shown in Fig.7.
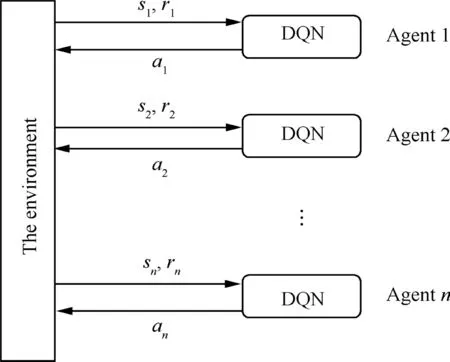
Fig.7 IDQN algorithm framework.
The independent learning framework is based on the assumption of independence while ignoring the problem of environmental instability.Although there is no guarantee of convergence in theory,many examples have shown that the algorithm can converge effectively in practice.In addition,in this algorithm,the neural networks of all agents share the same parameters.This technique of parameter sharing is widely used in RL,and it can improve the learning efficiency of agents,ensure the unity of the agent network structure,and improve the scalability of the algorithm.
4.2.Aircraft cooperation mode
Aircraft in multi-aircraft flight conflict scenarios are considered cooperative agents.Aircraft agents need to cooperate to resolve the situation.There is no possibility of sacrificing the interests of one aircraft agent to maximize the interests of other aircraft agents.The IDQN algorithm does not explicitly show the cooperative relationships among agents,and the relationships among agents are completely controlled by the reward function.The reward function in RL indicates the goal of solving the problem to a certain extent.Therefore,to balance the interests of the various aircraft agents and make the aircraft agents work together to complete the task,in the reward function,the minimum value of the individual reward and the overall reward of all aircraft agents are selected as the reward values in Eq.(7).The goal of RL is to maximize the cumulative reward,which will make the minimum value as high as possible.Only when aircraft agents tend to choose cooperative actions can they obtain a large reward.
4.3.Dynamic expansion structure
Because of the independent learning framework,each agent has a separate set of neural networks.Therefore,if the number of conflicting aircraft increases,neural networks with the same network structure need to be added for the additional aircraft and connected with each other by a reward function.If the number of conflicting aircraft is reduced,it is not necessary to change the structure or number of neural networks.In the scheme of multi-aircraft flight conflict resolution based on the IDQN algorithm,the ‘downward-compatible’ mode is adopted.The resolution framework using the RL algorithm is designed to solve the problem of a flight conflict of(∈N) aircraft,and this framework can also be used to solve the problem of a flight conflict of(1 <<,∈N) aircraft.In this way,confli ct scenarios with different numbers of conflicting aircraft can be mixed together for training.When using the trained model for testing,whenever a conflict scenario is imported,first judge the number of conflicting aircraft in the conflict scenario.When an-aircraft flight conflict scenario is selected,all neural networks are selected for training.When an-aircraft flight conflict scenario is selected,only the firstneural networks need to be selected for training.In this way,the corresponding neural network is selected to train for scenarios with different numbers of conflicting aircraft.When the training model is used for testing,flight conflict resolution is still carried out in accordance with the above selection mode.When using the RL method,it is necessary to ensure that the scenario is relatively fixed.For example,when only training the three-aircraft conflict scenario,it can usually only solve the three-aircraft conflict scenario during use.To resolve conflict scenarios with different numbers of conflicting aircraft,it needs to be trained separately for various flight conflict scenarios,and eventually several conflict resolution models need to be constructed.The advantage of using ‘downward-compatible’ mode is that conflict scenarios with different numbers of conflicting aircraft can be put together for training and integrated into one conflict resolution model.In this way,when using,only one model needs to be called to avoid the burden of constructing the relatively repeated model.
4.4.Solution process
The IDQN algorithm is used to solve the problem model established in the third section.The DQN algorithm is a combination of a Convolutional Neural Network(CNN)and a Qlearning algorithm.The CNN has obvious advantages in highdimensional image processing,but because the input data are the flight information in a designated airspace at a certain time,the CNN is not applicable.Therefore,it is replaced by a Multi-Layer Perceptron (MLP),which is more suitable for information data storage and processing.The essence of the IDQN algorithm is the DQN algorithm.It combines the MLP with Q-learning.Each agent has its own independent learning and training process.This method can effectively solve the problem of multi-aircraft flight conflict resolution.The main steps are as follows:
The multi-aircraft conflict scenario is input,and the state sis initialized.
The simulated flight platform is used to execute the joint actions uselected by each aircraft,and the reward value rand the next state sare obtained according to the observation.
It is judged whether the next state smeets the end condition.If the end condition is not satisfied,Steps 2 and 3 are continued.If the end condition is met,the current conflict scenario is reset,the new conflict scenario is input,and the algorithm starts again from Step 1.
In summary,the specific algorithm flow of the IDQN algorithm used to train and solve the MDP-based control conflict resolution model is shown in Table 2.

Table 2 IDQN algorithm flow for the conflict resolution model.Algorithm:IDQN algorithm for the conflict resolution model
4.5.Model training and learning
In this paper,the short-term conflict detection algorithm based on R-tree space query technology proposed by Liwas used to construct flight conflict scenarios needed in the study.By improving the steps of correlation search,the algorithm can be extended to multi-aircraft flight conflict detection problem.Import the flight plan into the trajectory prediction module,get the information of all aircrafts,use the R-tree for conflict detection,and record conflicting aircraft pairs.Then,according to the definition in Section 2.2,the conflict pairs are combined and filtered according to space limit,time limit,and connection limit to obtain multi-aircraft flight conflict scenarios.In the multi-aircraft flight conflict scenario obtained through this process,the flight number of the conflicting aircraft,the specific position of the conflict point,the time of the conflict,the flight plan of other aircraft in the scenario and other information are recorded.
The model was trained on a computer with a Windows 7,64-bit operating system with 32 GB of processor RAM.The training process is based on Python 3.7 in the PyCharm software.The core part of the algorithm uses the open source code of DQN published by OpenAI,and expands it into the form of IDQN,based on OpenAI Gym 0.15.4 version and TensorFlow 1.14.0 version to realize its function.Before training,multiaircraft flight conflict scenario data should be constructed.Flight conflict detection is carried out through the Air Traffic Operation Simulation System (ATOSS) developed by Intelligent Air Traffic Control Laboratory.ATOSS uses the B/S(Browser/Server) architecture as a whole,and the user interface uses the VUE architecture,which mainly uses programming languages such as TS (TypeScript) JS (JavaScript) and CSS (Cascading Style Sheets).Its main function is to perform air traffic simulation and data analysis,and generate it in the form of simulation graphs and data analysis charts.The system mainly includes technologies such as track prediction,con-flict detection,and arrival and departure sequencing.The research of this paper mainly uses the intelligent detection of conflicts technology in the system.
The flight plan data within China’s airspace on June 1,2018 are selected as the input,and random time changes are added to change the start times of the flight plans.The scenario size is set to 200 km×200 km×6 km during the detection process,as shown in Fig.8.Each scenario contains a conflict of three,four or five aircraft,as well as other aircraft,and the number of aircraft is randomly distributed between 20 and 100.During the simulation,the multi-aircraft flight conflicts within the scope of the scenario are recorded.A total of 6700 multiaircraft flight conflict scenarios are detected by using the conflict detection algorithm,among which three-aircraft conflict scenarios accounted for 70%,four-aircraft conflict scenarios accounted for 20%,and five-aircraft conflict scenarios accounted for 10%.The conflict scenarios are divided into training scenarios and test scenarios (6000 and 700,respectively),and the proportion of each type of conflict scenario is the same as above.
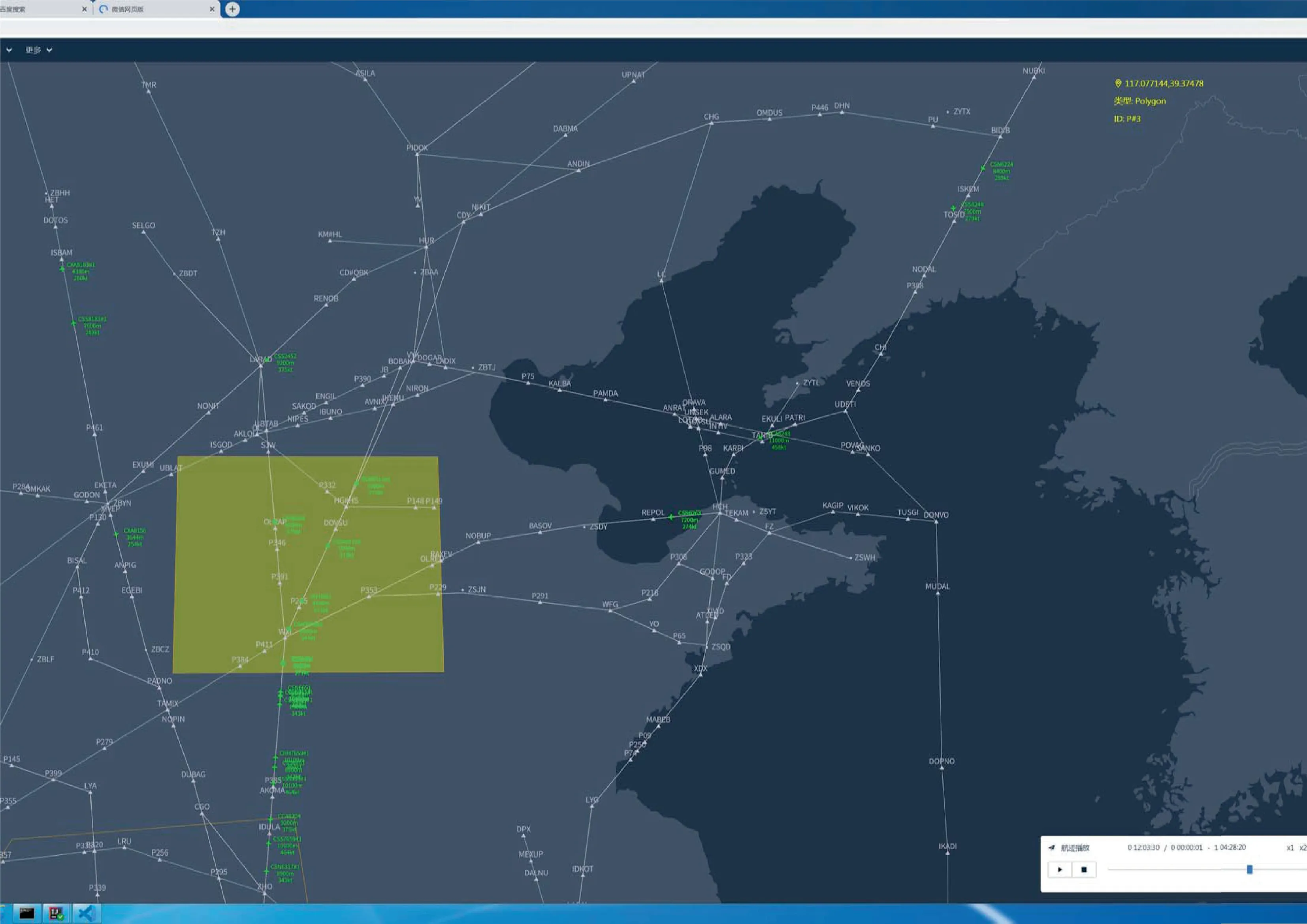
Fig.8 Schematic diagram of conflict detection simulation scenario.
Multiple hyper-parameters are involved in the process of DRL training,such as learning rate,exploration rate and total time steps,etc.,so the training parameters and their values required in the process of model training are sorted out as shown in Table 3.At the same time,set the values of the reward function parameters mentioned in Section 3.2,as shown in Table 4.
It can be seen from Table 3 and Table 4 that model training involves multiple hyper-parameters,and different parameter values have different influences on the training effect of the model.Most of the parameter values are obtained through multiple tests and modifications.When the parameter values are different,it may affect the convergence speed of the model and the reward value.By referring to the research literatureand relevant application research of DQN and combining with the test of flight conflict resolution,the values in Table 3 are finally determined.As can be seen from the analysis in Section 3.2,the first function of the reward is to distinguish the infeasible solution with feasible solution,and the second is to seek a better solution within the range of feasible solution.The setting of Eq.(2) can help the agent to avoid the action of choosing infeasible solution as soon as possible.It is a very important reward function.Since the parameter values of the reward function are set arbitrarily,the robust test was carried out here to illustrate with the parameterofin Eq.(2).Five parameter values were selected for the experiment,and the experimental results were shown in Table 5 and Fig.9.
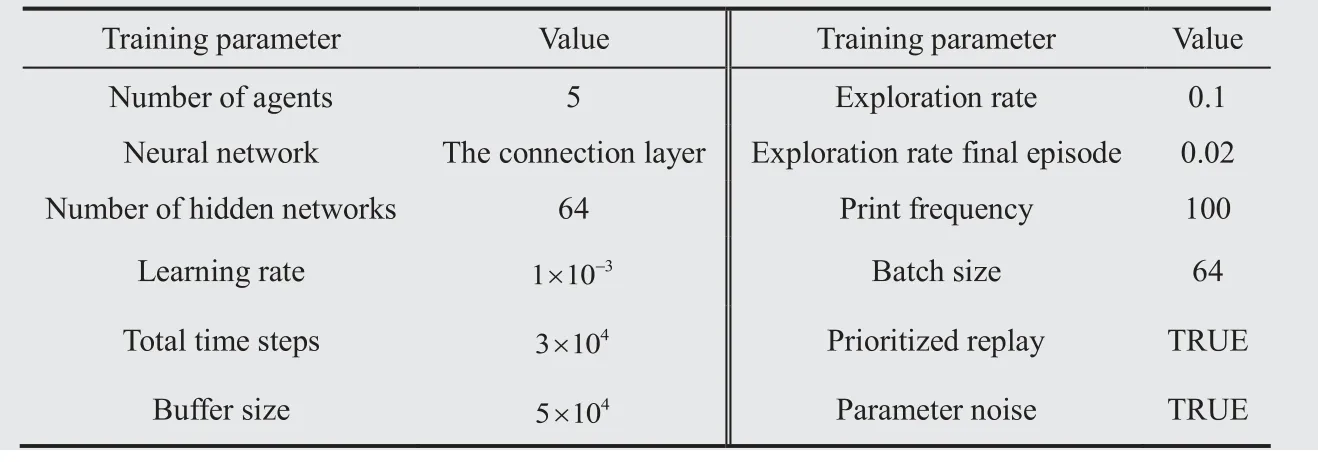
Table 3 Design values of the training parameters.
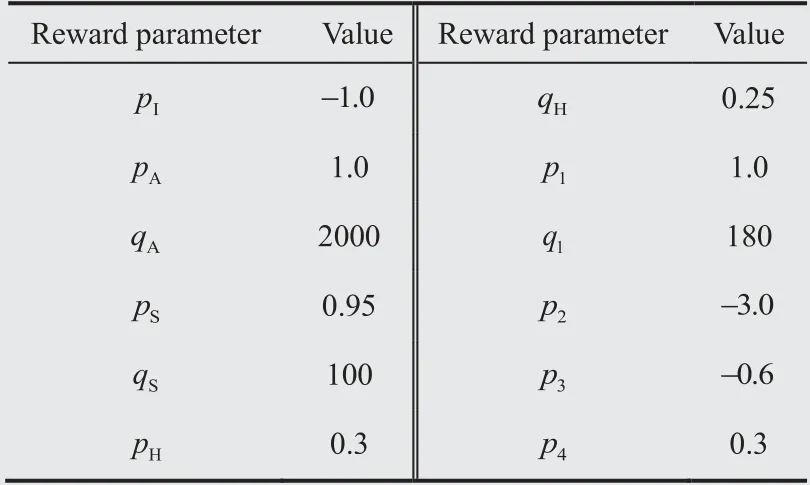
Table 4 Design values of the reward parameters.
As can be seen from the first figure in Fig.9,when the parameter value fluctuates slightly around -1.0,although the initial reward value is different and the convergence rate is slightly different,the reward value converges after the same timesteps of training,and it can be seen from Table 5 that the convergence value has little difference.When the parameter value is set to 0,it is equivalent to not having the constraint in Eq.(2).As can be seen from the second figure,the reward value is always fluctuating without a trend of convergence.When the parameter value is set to -10.0,the training effect is not good due to the great difference between the setting of this reward value and other reward values.In the training process of the same step number,the reward value does not converge,but also shows a trend of gradual decline.Meanwhile,due to the large deviation with other reward function values,it may lead to the problem of sparse reward,which is not conducive to the stability of the model.Therefore,when there is a small fluctuation between -0.5 and -1.5,the stability of the model will not be greatly affected,and the model has a certain robustness.The values of other parameters can also be analyzed by testing and comparing results to select the most appropriate value in a limited range.

Table 5 Training results of different parameter pI value.
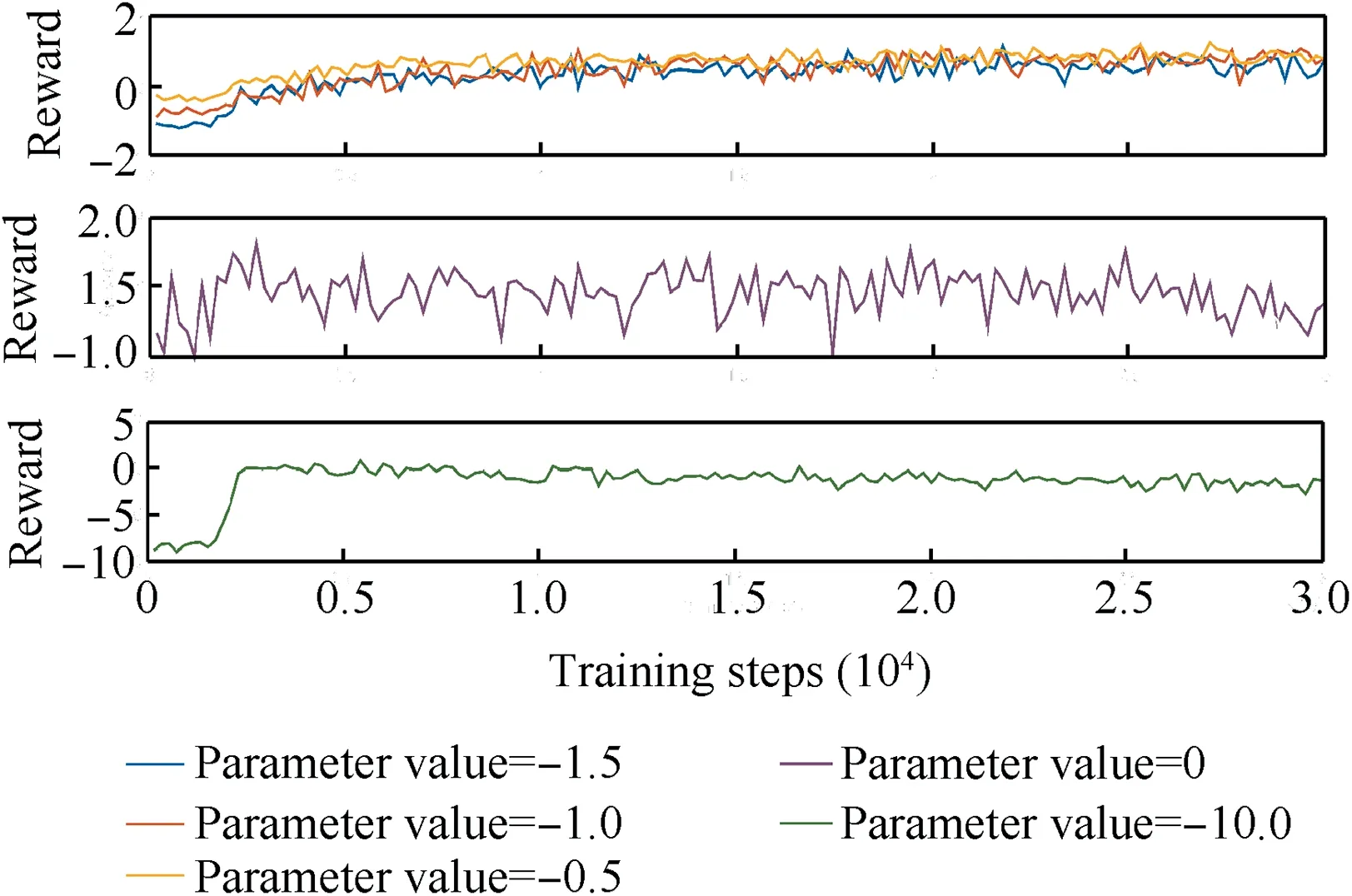
Fig.9 Reward function curve of different parameter pI value.
After the training parameters are determined,the final model training is carried out.The model is trained 30,000 steps at a time,and each training time is 50 h.The trained model shows good stability and convergence.The graphs shown in Fig.10 are its training curves,corresponding to the loss function value,the average reward value and the average maximumvalue of each agent.The loss function is used to evaluate the degree to which the predicted value of the model is different from the real value,which is usually non-negative.The smaller the loss function is,the better the model performance will be.The reward function is the evaluation of the action taken by an agent.The higher the reward,the more the action is encouraged to be taken.When the average reward is higher,it indicates that the agent can take the correct action most of thetime.Thevalue is updated according to the reward function.The agent acts according to the maximumvalue.The higher the maximumvalue,the more correct the agent can take the action.
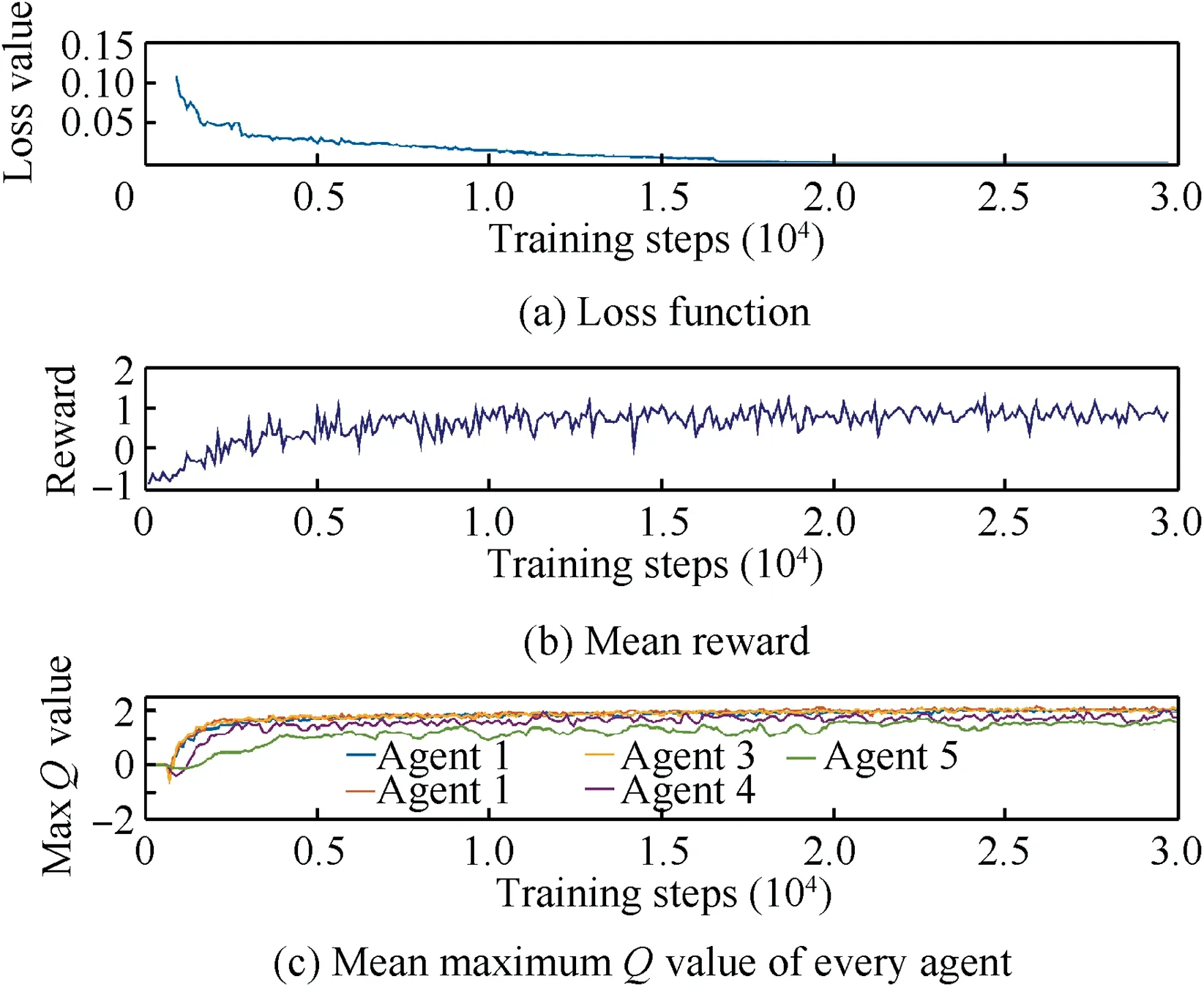
Fig.10 Chart of the model training data.
Fig.10(a)shows that the loss function of the model starts to decline rapidly when the training reaches approximately 1000 steps and then gradually stabilizes at approximately 0 at approximately 15600 steps,indicating that the agent is learning.Fig.10(b) shows that at the beginning of training,the average reward value of the model is low.With the increase in the number of training steps,the reward value gradually increases.Fig.10(c) shows that the maximumvalue of an average single agent starts to rise after approximately 1000 steps and gradually stabilizes around a higher value after approximately 2000 steps.As seen from the figure,as the number of training steps increases,the agents gradually show good learning behavior.Although these five curves are different,their convergence properties show that the model proposed in this paper is effective in resolving conflicts equal to or less than five aircraft.The learning characteristics of the‘downward-compatible’ model can also be seen in Fig.10(c).The aircraft agent will select the neural network in order,and the number of the conflict scenarios will decrease with the increase of conflicting aircraft.Therefore,the first three are fully trained,converge quickly,and have a large maximumvalue.Although the convergence of the fourth and fifth aircraft agents is slow and the maximumvalue is small,they still show convergence results.Thus,‘downward-compatible’framework is valid.
The above analysis shows that the model is stable,robust and convergent after sufficient training and learning of conflict scenario samples and training steps,which can be used for multi-aircraft flight conflict scenario tests.To further improve the training effect of the model,its performance is improved by increasing the number of training steps and adjusting the relevant hyper-parameters in Table 3 to make the model more stable.
5.Result analysis
For the trained model,a test scenario should be used to verify its validity.The data used in the test should be different from the data used in the training.Therefore,the 700 reserved conflict scenarios should be used for testing.In the analysis of the test results,the indicators like successful conflict resolution rate,conflict resolution trends,the delay time after resolution,calculation time and distribution of successful conflict resolution rate are primarily considered.
(1) Successful conflict resolution rate
The successful conflict resolution rate represents the ratio of the number of flight conflict successful resolution scenarios to all test scenarios.It is the most direct indicator to measure the effect of the model,the higher the value,the better the resolution effect of the model.Fig.11 shows a positive proportion between the successful conflict resolution rate and the number of training steps.At the same time,the training data and test data are used to test the model,indicating the generalization ability of the model.When the number of training steps is sufficient,the conflict resolution rate of the model is higher,and the reserved test data can be used to test it.
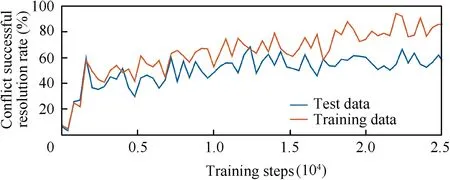
Fig.11 Change curve of the resolution rate with the number of training steps.
Among the 700 conflict scenarios,a total of 600 conflict scenarios were successfully resolved,and the successful conflict resolution rate was approximately 85.71%,including 460 three-aircraft conflicts,110 four-aircraft conflicts and 30 fiveaircraft conflicts,totaling 1970 sorties.The distribution of the reward obtained by the successful resolution scenarios is shown in Fig.12.The reward value is in the range of 1.85-2.75,and the number of scenarios in which the conflict was successfully resolved with a reward value of 2.05 is the largest.If the number of scenarios that are successfully resolved at a certain reward value is greater,it indicates that the probability that the model is stable at the reward value when conflict is successfully resolved.The test results show that the training of the model achieves some stability,but its distribution is relatively discrete.In the future,to improve the stability of the model,the number of training steps and training samples can be increased.At the same time,this can also improve the successful resolution rate of the model.
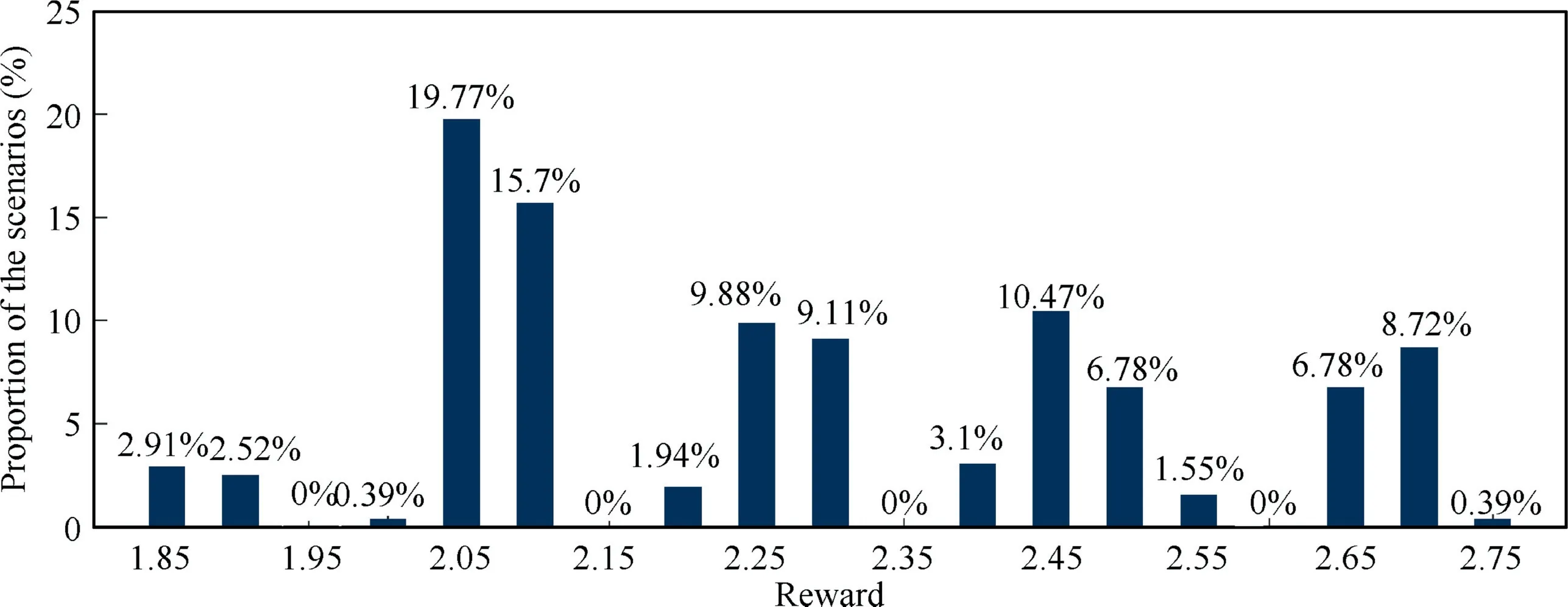
Fig.12 Reward for successfully resolved scenarios.
In the test,100 scenarios were not successfully resolved.Most were due to new conflicts with other aircraft in the environment and a small number were due to the failure of their own conflict resolution.The reasons for the failures may be analyzed as follows:(A) a model using RL training will not achieve a 100%successful resolution rate because of the difference between the training samples and the test samples,(B)the setting of the hyper-parameters and reward function in the algorithm impact the training effect of the model,and the reward function is not comprehensive enough to avoid the flights of other aircraft in the environment,(C) the training steps of the model are insufficient.Through the training of existing steps,the model obtains convergent and stable results,but the characteristics of all training scenarios have not been learned.Through the analysis above,the successful resolution rate of the model can be improved by changing the hyperparameter settings,reward function and training steps.
(2) Conflict resolution trends
In successful conflict resolution scenarios,it is necessary to verify the requirements of various aspects of the scenario.First,it is necessary to verify whether the resolution strategy adopted complies with the actual controllers’ habits.The distribution of the resolution actions taken by the 1970 aircraft is shown in Fig.13.The abscissa corresponds to the action instructions in the action space.Fig.13 shows that the action with the highest selection probability is ascending 600 m.In each category,aircraft tend to choose the action with a small-amplitude adjustment.Comprehensive statistical results showed that 12.4% of the aircraft did not change,33.33% of the aircraft chose speed adjustments,29.53% of the aircraft chose altitude adjustments,24.71%of the aircraft chose heading adjustments,and the overall order of priority selection was speed >altitude >heading,which is consistent with most of the area controllers’ habits.
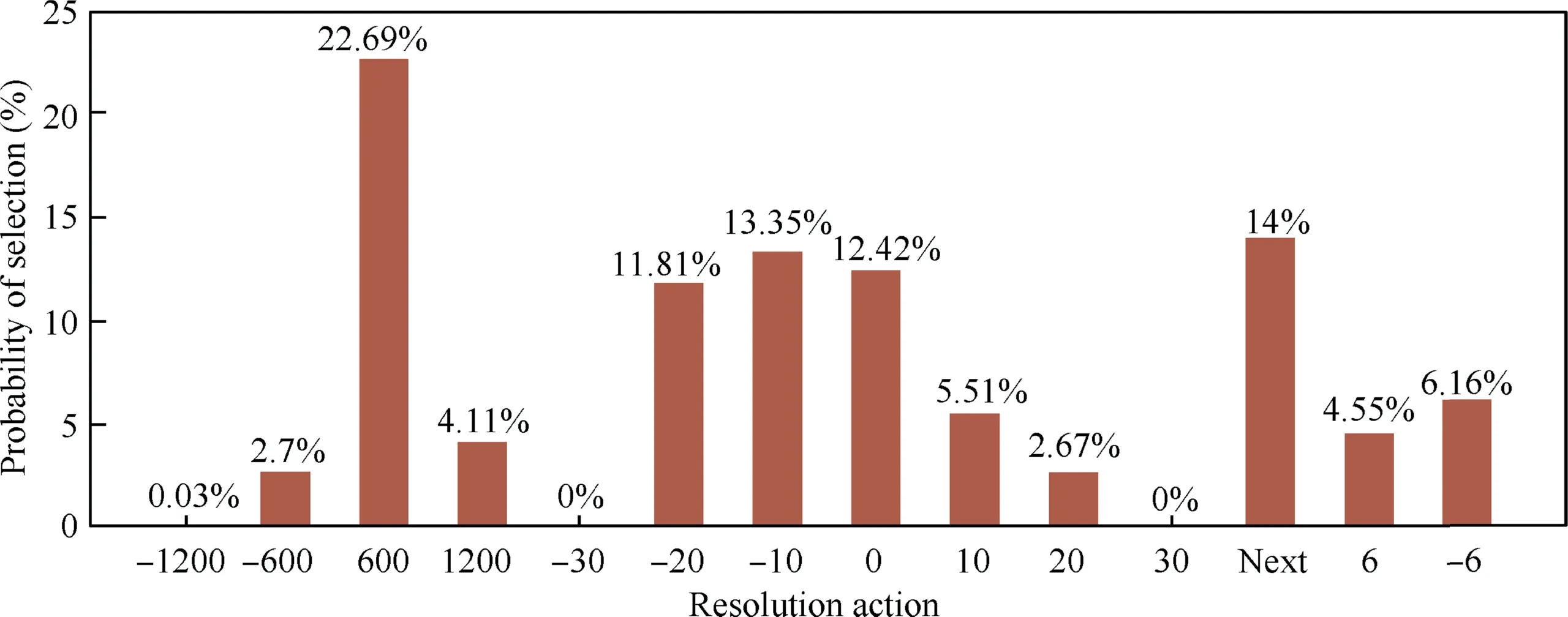
Fig.13 Statistics of conflict resolution actions.
In the test results,some actions are not selected at all because of the limitations of aircraft performance.The aircraft has minimum and maximum cruising speeds at cruising altitude,i.e.,speed adjustment range limits.Taking the A320 aircraft type as an example,as shown in Fig.14,as the flight level rises,its cruising speed adjustment range gradually decreases,eventually reaching approximately 60 kt.The standard cruise speed is usually between the maximum and minimum cruise speeds,so it can be adjusted up and down by approximately 30 kt.The selection range of the test resolution action shown in the model is 20 kt up and down,so the resolution strategy meets the performance limit.
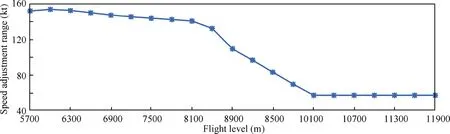
Fig.14 Cruise speed adjustment ranges of A320 aircraft at different flight altitudes.
In the resolution strategy,the aircraft tends to choose the action instruction with a smaller range.The result of this instruction resolution is more in line with actual control and resolution habits.Both controllers and pilots prefer to choose the simplest way to solve a conflict.At the same time,an action with a small adjustment range can make the aircraft arrive at the destination as close to the original planned arrival time as possible to reduce the impact of conflict resolution on its delay time.
(3) Delay time
In the process of conflict resolution,in addition to achieving the successful resolution of conflicts,the aircraft should be ensured to arrive at the destination in accordance with the planned arrival time as far as possible to reduce the impact on the flight plans of other aircraft.The delay times of the aircraft successfully resolved in the above conflicts were analyzed,and the flight time after resolution minus the original planned flight time was used as the delay time (a value greater than 0 indicates a delay,and less than 0 indicates advance arrival).The smaller the absolute value of the delay time,the smaller the impact on normal flight.To better display the distribution of the delay time,the time is divided into intervals of 1 min and expressed in the form of intervals,as shown in Fig.15.The delay time approximately follows a normal distribution.Thirty-two percent of the aircraft arrive at the destination within 30 s before or after the original planned arrival time,and 71.51% of the aircraft can reach the destination within 150 s before or after the original planned arrival time.The reason for this result is related to the selection of the resolution action.The delay time is within the acceptable range,and it will not cause great interference to the flight plans of other aircraft,reducing the workload of the air traffic controllers in handling the aircraft operating on the airport surface.Therefore,using this model to resolve multi-aircraft flight conflicts will not affect the normal operation of flights to ensure the resolution rate.
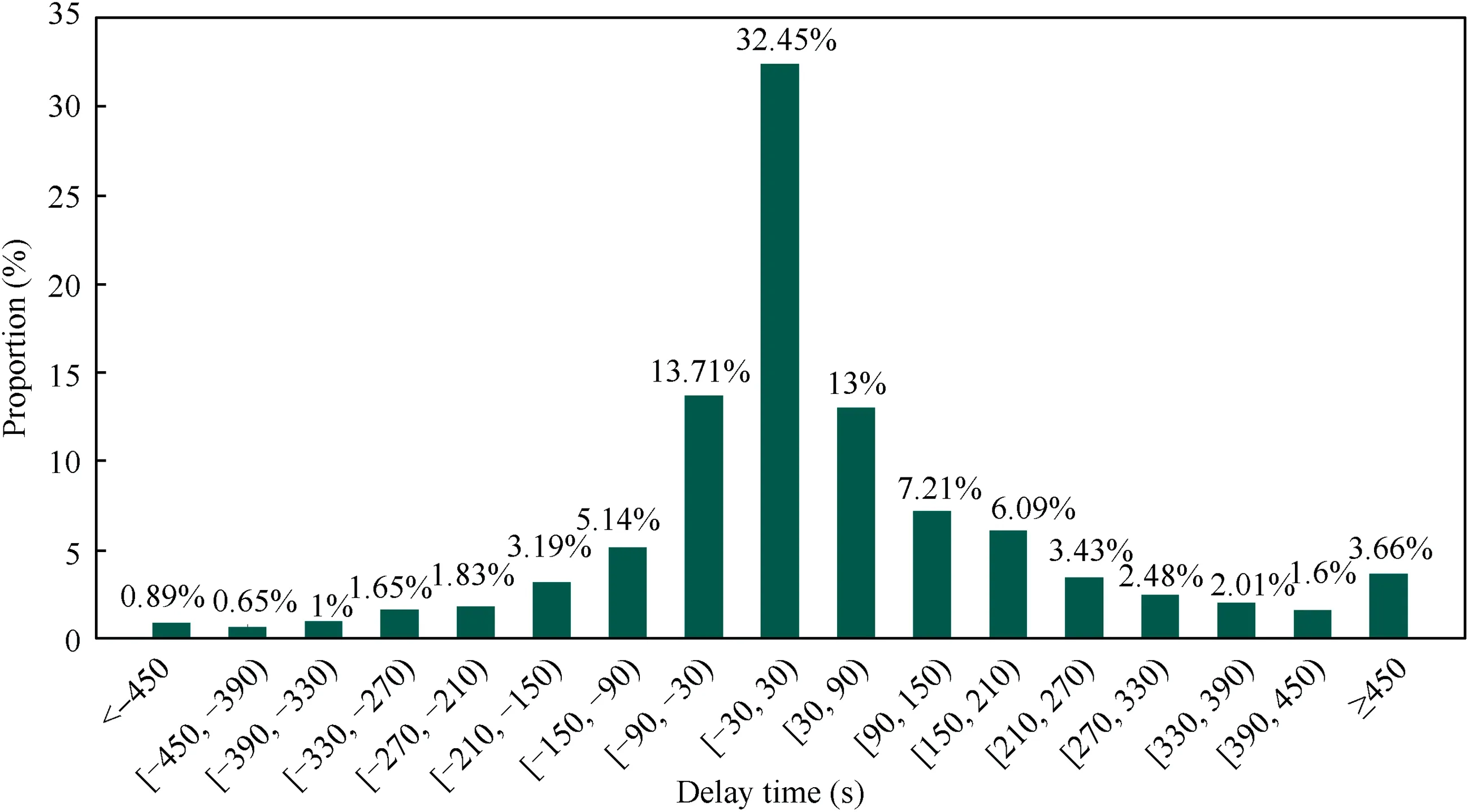
Fig.15 Statistics of the aircraft delay time.
(4) Comparative analysis of calculation time
One of the advantages of RL is that the method of offline training and online using can greatly increase the solving speed and improve the solving efficiency.In order to verify that the algorithm proposed in this paper has a high solving speed,the NO.7 method in Table 1 is selected as a comparison algorithm.Through the test of 700 conflict scenarios,the same as IDQN,the calculation time distribution of GA algorithms is shown in Fig.16.The solving time of GA is distributed between 12.6591 s and 141.5892 s,and its average solving time is 37.6003 s.The calculation time of the GA is related to the number of aircraft in the scenario and the generation.The more the number of aircraft,the more complex the airspace environment,the larger the iteration generation required,and the longer the calculation time.However,the IDQN algorithm is less affected by the number of aircraft.Due to the training of a large number of samples,it has better adaptability in actual solving.In the solution of the proposed IDQN algorithm,the calculation time distribution of the conflict resolution strategy is between 7.0004e-3 and 2.2001e-2,and the average calculation time is 1.1056e-2.The calculation time is at a different order of magnitude from that of GA.Through comparison,it can be found that DRL algorithms such as IDQN have great advantages in solving time,so it can improve the solving efficiency.
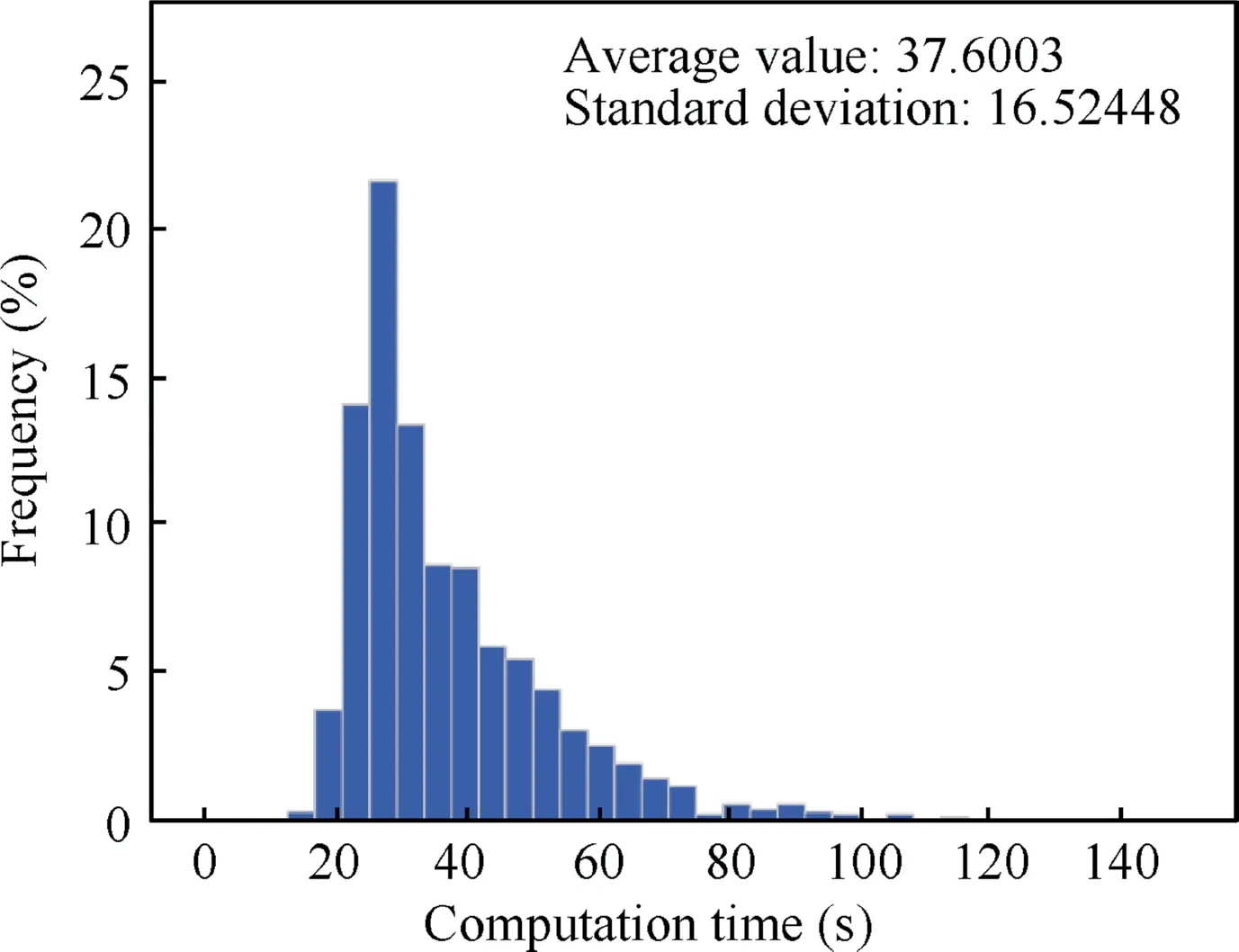
Fig.16 Distribution of GA calculation time.
(5) Distribution of successful conflict resolution rate
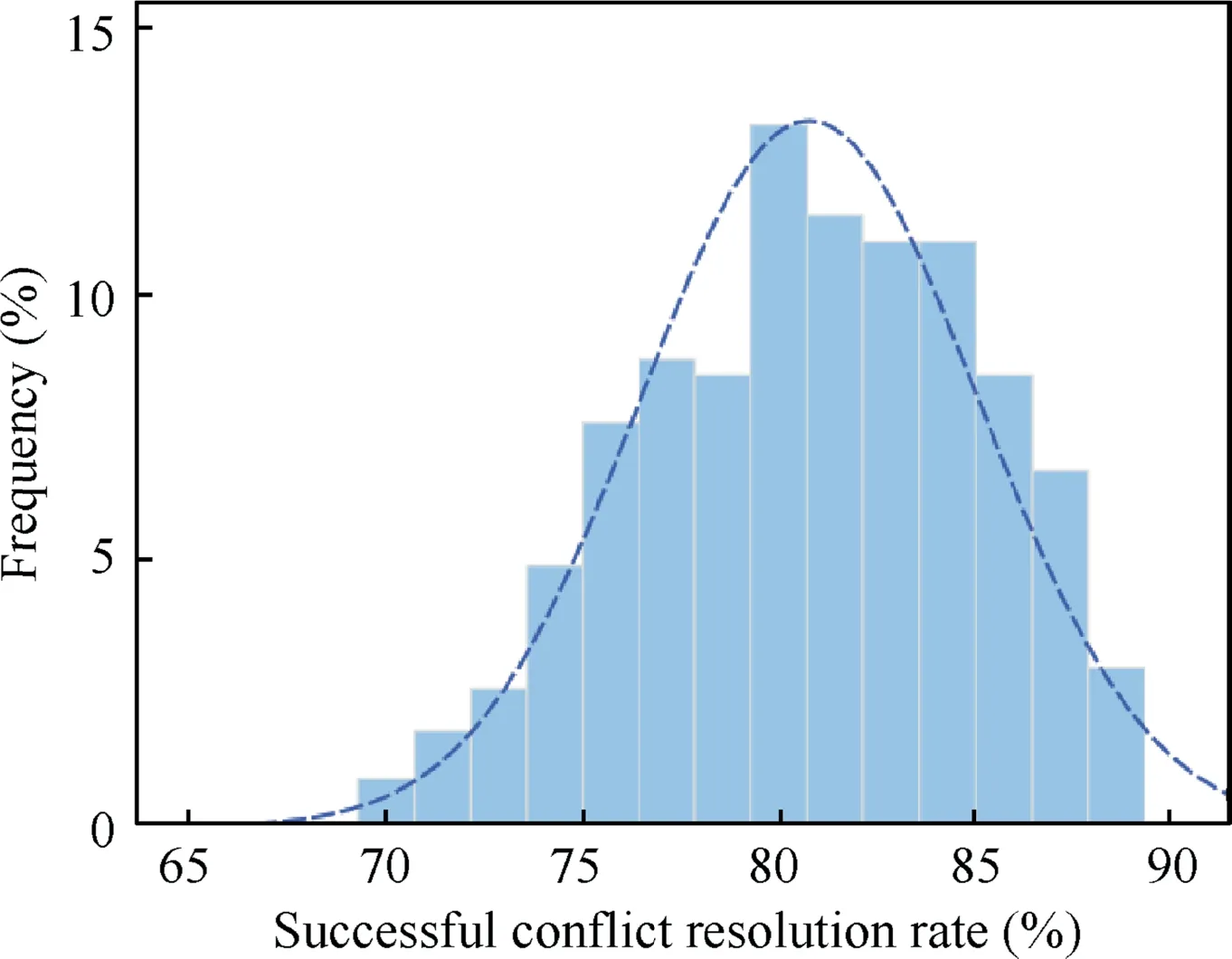
Fig.17 Distribution of test results for level of uncertainty.
6.Discussion
Through the above analysis,the flight conflict resolution model based on DRL can successfully resolve the most conflict scenarios.Under actual constrained flight conditions,flight conflicts among multiple aircraft are successfully resolved based on the control operational regulations.The overall resolution effect is measured by the delay time,and the resolution process has little impact on the normal flights of other aircraft.However,the model also has some shortcomings.In the actual control procedure,the successful resolution rate is required to be 100%.However,in the model,the rate does not meet this requirement,but the uncertainty of the algorithm is generally acceptable.So it can only be used as an assistant decision-making method for controllers.In addition,although the test results show that the action selection is more in line with control habits than previous methods,in actual area control,the priority resolution actions of controllers in different sectors are different.Conflict resolution actions often depend on the personal habits of the controller and the preferences of the aircraft crew.At the same time,the relative position,route structure and airspace situation of the aircraft should be considered.To meet the actual resolution habits of air traffic controllers,it is necessary to conduct empirical statistics for a sector or a controller and then modify the reward function to make the training results conform to their resolution habits.Generally,solving the problem of multiaircraft flight conflicts by using the framework of DRL and independent learning is successful.By comparing with the basic algorithm,it is proved that the algorithm proposed has great advantages in solving efficiency.It can ensure safe and efficient of the high-density airspace in the future.
7.Conclusions
(1) A method for multi-aircraft flight conflict resolution based on DRL is proposed in this paper,which combines the DQN algorithm in DRL and an independent learning framework to construct an IDQNalgorithm.Through verification,this method has great advantages in solving time
(2) An MDP-based multi-aircraft flight conflict resolution model is established,and IDQN based on MLP neural network is used to solve the problem,and a‘downward-compatible’ framework is proposed to support the dynamic change of the number of conflicting aircraft in conflict scenarios.
(3) By using 700 multi-aircraft flight conflict scenarios constructed in ATOSS for testing,the successful resolution rate of the model can reach 85.71%,and 71.51% of the aircraft can reach their destinations within 150 s around original arrival times.At the same time,through 1000 tests,the successful conflict resolution rate of the algorithm is distributed between 70.00% and 88.57%,and it’s generally a normal distribution.Next,the research can be carried out from the following aspects:extract the control experience from historical radar data to train the reward function to make it more in line with the actual operation,further improve the successful resolution rate of the model and reduce the probability of algorithm failure,add obstacle areas such as restricted areas and thunderstorm avoidance areas so that the aircraft can avoid obstacles.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This paper is jointly completed by the project team of the Intelligent Air Traffic Control Laboratory of NUAA and cannot be separated from the efforts of every member.And this work was supported by Safety Ability Project of Civil Aviation Administration of China (No.TM 2018-5-1/2),and the Open Foundation project of The Graduate Student Innovation Base,China (Laboratory) of Nanjing University of Aeronautics and Astronautics,China (No.kfjj20190720).At the same time,I would like to thank the other teachers of the laboratory where the project is located for their support and guidance,as well as the technical guidance of professors from the College of Computer Science and the advice of experts in air traffic control.
Supplementary data to this article can be found online at https://doi.org/10.1016/j.cja.2021.03.015.
 Chinese Journal of Aeronautics2022年2期
Chinese Journal of Aeronautics2022年2期
- Chinese Journal of Aeronautics的其它文章
- Pressure-induced instability and its coupled aeroelasticity of inflated pillow
- Adjoint boundary sensitivity method to assess the effect of nonuniform boundary conditions
- Transit time difference and equal or non-equal transit time theory for airfoils with lift
- A boundary surrogate model for micro/nano grooved surface structure applied in turbulence flow control over airfoil
- Nonlinear uncertainty quantification of the impact of geometric variability on compressor performance using an adjoint method
- High precision and efficiency robotic milling of complex parts:Challenges,approaches and trends