
定性指标单臂多中心临床试验中心效应的调整及SAS程序实现*
2022-01-19 08:40:06北京协和医学院中国医学科学院国家心血管病中心阜外医院医学统计部102300王闯世范肖雪赵延延白银晓
中国卫生统计 2021年6期
北京协和医学院,中国医学科学院,国家心血管病中心,阜外医院,医学统计部(102300)王闯世 范肖雪 赵延延 白银晓 王 杨
【提 要】 目的 探讨定性指标单臂多中心临床试验中调整中心效应的策略及其应用。方法 介绍使用倒方差和D-L法计算中心加权效应值在定性指标单臂多中心临床试验中调整中心效应的基本原理和相关考虑,如权重的计算,率的转换等,编写SAS程序,并以“人工心脏瓣膜”试验为实例说明。结果 计算中心加权效应值处理单臂多中心临床试验中心效应时,若各中心效应同质,各中心权重等于其效应值方差的倒数;可根据Q值判断是否需要对各中心权重进行调整。当分中心结局发生率趋近0或1时,建议对原始率进行数据转换。实例中,使用双反正弦转换法的结果显示,中心加权复合终点事件率的95%置信区间上限低于目标值,拒绝原假设,提示研究产品的疗效优于设定的目标疗效。结论 定性指标单臂多中心临床试验调整中心效应可通过计算中心加权效应值,若分中心结局发生率接近0或1,建议先对原始效应值进行数据转换。
在多中心临床试验(multicenter clinical trial)中,因各中心在受试者基线特征、临床实践等方面可能存在差异而产生的中心效应(center effects)[1]是统计分析阶段不可忽视的问题,《药物临床试验的生物统计学指导原则》和《ICH E9临床试验的统计学指导原则》中均指出需考虑中心效应,选择恰当的中心效应调整策略是准确评价药物或医疗器械有效性和安全性的前提。多中心随机对照试验(randomized controlled trial,RCT)中,根据主要结局指标的类型(定性或定量),可采用相应中心效应调整的方法,如协方差分析、Cochran-Mantel-Haenszel(CMH)检验和多水平模型(multilevel model)等[2-3],其中CMH检验的本质是计算加权效应值,各中心权重与其样本量或效应值方差相关。但在单臂多中心临床试验中,目前缺少相关方法介绍。本文借鉴RCT中CMH方法调整中心效应的思路,在定性指标的单臂临床试验中通过“加权”的方法以调整中心效应,并编写SAS程序。
材料与方法
1.基本原理
(1)中心加权效应值
CMH方法是主要结局指标为二分类定性变量(如手术是否成功)的多中心RCT中调整中心效应的常用策略之一,其基本原理是把各中心作为“层”,基于各层的四格表数据分别计算效应值并通过一定的算法合并,达到调整中心效应的目的。根据所采用的算法,SAS中提供两个效应估计值:Mantel-Haenszel(MH)估计值和logit估计值,均为“中心水平”的加权,MH法把各中心样本量的倒数作为权重[4],logit法把各中心效应值自然对数的方差取倒数作为权重[5]。类似地,在定性指标的单臂临床试验中,可借鉴上述中心加权的策略,通过使用倒方差等算法计算中心加权效应值调整中心效应。
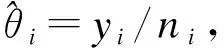
(1)
θi~N(θ,τ2)
(2)
各中心间效应估计值的差异包括随机抽样误差(si)和中心间变异(τ2);若各中心的效应同质,即各个中心的效应相同或一致,不同中心来自同一总体,则各中心效应估计值的差异为随机抽样误差(si),没有中心间变异(τ2=0)。根据倒方差法[6]和D-L法[7],两种情形下,中心加权效应值θw及其标准误Se(θw)的计算分别如公式(4)、(5)和公式(11)、(12)所示。
若各中心效应同质,各中心权重wi取其效应估计值方差的倒数,计算如下:
(3)
(4)
(5)
相应的95%置信区间为:
θw±1.96Se(θw)
(6)
在单臂临床试验中,通常会基于主要结局指标预先设定有临床意义的目标值Δ(objective performance criteria),在单侧0.025的置信水平下,根据公式(6)计算其95%CI是否包含Δ判定是否拒绝原假设:对于高优指标(如手术成功),若95%CI下限大于Δ,则拒绝原假设;对于低优指标(如死亡),若95%CI上限小于Δ,则拒绝原假设。亦可通过标准化变换(或z变换)[8]:
(7)
若z>1.96,则在单侧0.025的置信水平下拒绝原假设。
各中心效应是否不同(即是否有中心效应)可使用下面公式判断[7]:
Q=∑wi(θi-θw)2
(8)
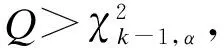
(9)
其中,
(10)
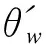
(11)
(12)
类似地,把根据公式(11)和(12)得到的加权效应值95%CI与目标值Δ比较,判断是否拒绝原假设。
(2)效应值(率)的转换
对于二分类定性结局指标,结局发生数服从二项分布B(n,π),π为结局发生概率,可以证明当n足够大,且nπ和nπ(1-π)都大于5时,二项分布B(n,π)近似正态分布N[nπ,nπ(1-π)][8],前文中心加权效应值的区间估计也是在该前提下完成。但当结局发生率趋近0或1时,可能会出现:(1)按照近似正态估计得到的置信区间下限小于0或者上限大于1;(2)结局发生率趋近于0或者1的中心因方差趋于0而被赋予过大的权重[6]。为解决上述问题,可考虑对各中心效应值(即率)进行数据转换,计算转换后的中心加权效应值,再反算。本文主要介绍两种转换:logit转换和双反正弦转换(double arcsine transformation)。
logit转换是医学研究中常用的一种数据转换,转换后的变量θt及其方差var(θt)计算如下:
(13)
(14)
其中,n表示总人数。通过公式(4)~(6)或公式(8)~(12)得到θt的中心加权估计值θtw后,反算未转换的效应估计值θw:
(15)
需要特别注意的是,当θ等于0或者1时,无法直接进行logit转换,可以先进行“连续校正”[9],如对该中心的结局和非结局发生数各加0.5。
双反正弦转换[10-11],又称为Freeman-Tukey转换,转换后的变量θt及其方差var(θt)计算公式如下:
(16)
(17)
其中,y表示结局发生数,n表示总人数。类似地,计算得到θtw后,反算θw的公式如下:
(18)
或使用下面简易公式反算:
(19)
2.实例资料来源
本文以一项评价置入人工主动脉瓣膜安全性和有效性的多中心、单组目标值临床试验为例。该临床试验共有5个中心参与,其主要终点指标是术后12个月内的全因死亡或严重卒中的发生,评价术后12个月复合事件发生率是否低于目标值(35%),全分析集FAS(full analysis set)和符合方案集PPS(per protocol set)分别有101例和97例受试者,各中心入组情况见表1。结果将分别展示不考虑中心效应与使用上述权重法调整中心效应的总事件发生率及其95%CI,并提供调整中心效应的SAS程序;同时将展示使用原始率与转换率计算的加权率及95%CI,以比较上述数据转换方法。
结 果
1.不考虑中心效应
若不考虑中心效应,对各中心数据进行直接累加估计总体事件发生率及其95%CI,无论是渐进正态法或者精确概率法,FAS和PPS对应的事件发生率的95%CI上限均远低于目标值35%(表1),拒绝原假设,可以认为研究产品的疗效优于设定的目标疗效。
2.加权法调整中心效应
FAS集中,使用原始率,双反正弦转换率或logit转换率均未提示异质性(P>0.1),使用各中心率的方差倒数作为其相应权重,得到率的加权均值95%CI上限低于目标值,拒绝原假设;考虑中心间变异调整中心权重后结果仍稳定。PPS集中,未调整中心权重计算的加权率95%CI上限也均低于目标值,但双反正弦转换和logit转换法提示存在异质性,调整中心权重后,logit法加权率的95%置信区间上限为35.3%,略高于目标值,但考虑到01中心事件发生数为0,使用logit转换时进行了“连续校正”,其结果解读应慎重。
本实例中各中心事件发生数均较少(<5,见表1),当使用渐进正态估计各中心事件发生率时,95%CI下限“截断”为0,这种情况下使用原始率方差的倒数作为各中心权重的处理不太合理,提示应对率进行数据转换。双反正弦转换法中各中心权重与中心样本量成正比,而logit转换法中权重与中心样本量和事件发生率均相关,但考虑到存在中心事件发生数为0的情况,logit法需要进行“连续校正”,本实例中更推荐使用双反正弦转换法对率转换后计算加权效应值。
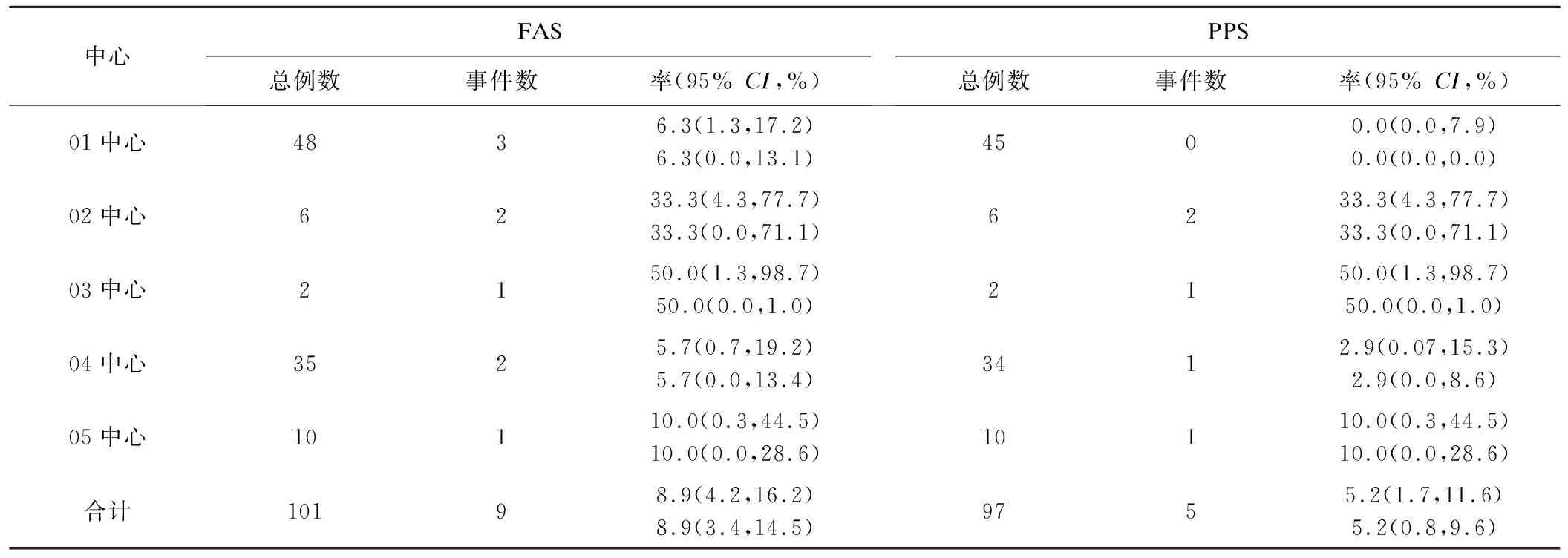
表1 各中心术后12个月复合终点事件发生率
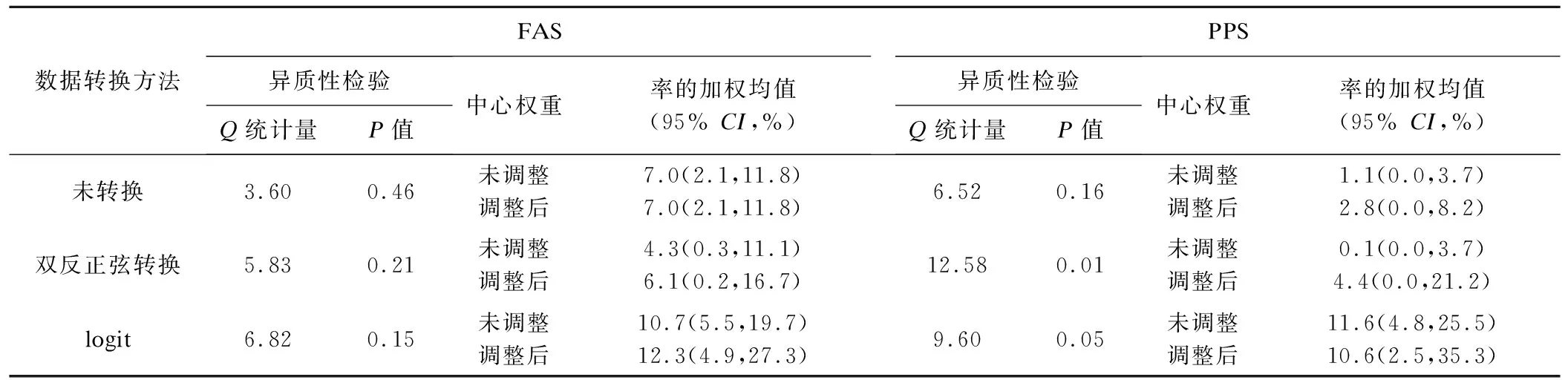
表2 术后12个月复合终点事件率的加权均值(调整中心效应)
3.程序实现
基于第一部分介绍的中心效应调整的策略,我们编写了相应的SAS宏程序(%S_CG_CenAdj)以便读者参考。并以上述试验为例,提供调用该宏程序的代码,详见文后附录。
讨 论
以单组目标值设计为代表的单臂临床试验在创新医疗器械产品评价中比较常见,在该研究设计下准确评估器械产品的有效性和安全性非常重要,但目前尚缺少单臂临床试验中心效应调整策略的研究。借鉴RCT中CMH法调整中心效应的思路,本文介绍了定性指标单臂多中心临床试验中调整中心效应的策略及考虑,并以某“人工心脏瓣膜”的多中心单臂试验为例介绍其应用。
根据ICH E9及中国食品药品监督管理局发布的《药物临床试验的生物统计学指导原则》,在试验数据库锁定前,统计师需要制定统计分析计划书并预先指明计划使用的统计分析方法,尤其是针对主要终点指标的分析;对于多中心临床试验,还需明确中心效应调整的策略。目前在单臂多中心临床试验中,往往没有考虑中心效应问题,仅对各中心的结局发生数和总例数进行简单地累加来计算总体结局发生率。而实践中各中心受试者招募能力、结局发生率等可能存在较大差异,如本研究实例中,02和04中心结局发生率分别是33.3%(2/6)和5.7%(2/35),忽视中心效应可能会得到有偏性的效应估计值。本文提出通过计算中心加权效应值以调整中心效应,其思路与多中心RCT中CMH法调整中心效应类似;该策略的倒方差加权法和D-L法与单组率的荟萃分析算法一致,如把各中心看作荟萃分析中每个纳入的原始研究,既往亦有研究介绍荟萃分析在二分类定性指标的多中心RCT中处理中心效应的应用[12-13]。
若分中心结局发生(低优指标)或未发生(高优指标)例数较少(如≤5),建议对效应值(即率)转换后计算加权效应值;使用logit转换时,当分中心结局发生率为0或1时,需进行“连续校正”,其结果解读应慎重。目前关于转换方法的优劣仍存在争议,有研究显示双反正弦转换优于logit转换[6],但其他研究发现双反正弦转换可能会产生令人误导的结果[14],主要因为该法在反算率时仅需要一个样本量[10],并建议可通过开展一系列敏感性分析(如使用一定范围的多个样本量)来检查结果的稳定性。关于不同转换方法的比较有待通过模拟研究进一步探讨。实际研究中,可开展系列分析(如权重调整前后,率的转换与否及不同转换方法等),提供多种场景下的分析结果以综合判断结果的稳定性。
本研究也有其局限性,主要考虑了结局指标为二分类定性指标的单臂试验,未涉及多分类定性指标或定量指标。实际研究中,二分类定性指标在单臂试验中更常见,而多分类定性指标和定量指标可根据临床专业知识转化为二分类定性指标后开展相关分析。
附 录
宏程序%S_CG_CenAdj:
/*宏参数使用说明:*/
/*dataset:原始数据集,包含各中心结局事件发生例数及总受试者例数;*/
/*type:取值p,darcsin或logit,表示使用原始率,双反正弦转换率或logit转换率;*/
/*event:各中心结局事件例数;*/
/*total:各中心受试者例数;*/
/*siteno:中心号;*/
/*name:标识率的转换方法,取值“原始率”、“双反正弦转换率”或“logit转换率”,与type取值相对应,如type取值为p,name取值为“原始率”;*/
/*output:生成新数据集,用于输出结果*/
%macro S_CG_CenAdj(dataset,type,event,total,siteno,name,output);
/*数据预处理:包括原始率的转换及各中心权重(未调整前)计算*/
data weight_&type.;
set &dataset.;
noevent=&total.-&event.;/*未发生事件例数=总例数-事件发生例数*/
total_in=1/&total.;/* 各中心受试者例数的倒数 */
/*原始率*/
%if &type.=p %then%do;
if &event.=0 or &event.=&total.then do;/*当事件发生率为0或1时,*/
event1=&event.+0.5;/*事件数+0.5*/
noevent1=noevent+0.5;/*非事件数+0.5*/
total1=event1+noevent1;/*总例数+1*/
end;
else do;
event1=&event.;
noevent1=noevent;
total1=&total.;
end;
&type._p=&event./&total.;/*各中心事件率,无需上述+0.5校正*/
var=((event1/total1)*(noevent1/total1))/total1;/*各中心事件率的方差*/
%end;
/*率的logit转换*/
%if &type.=logit %then%do;
if &event.=0 or &event.=&total.then do;/*当事件发生率为0或1时,*/
&event.=&event.+0.5;/*事件数+0.5*/
&total.=&total.+1;/*总例数+1*/
end;
&type._p=log((&event./&total.)/(noevent/&total.));/*logit转换:logit(p)=log(p/(1-p))*/
var=(1/(&event.))+(1/(noevent));/*各中心logit转换率的方差*/
%end;
/*率的双反正弦转换,即Freeman-Tukey转换*/
%if &type.=darcsin %then%do;
&type._p=arsin(sqrt(&event./(&total.+1)))+arsin(sqrt((&event.+1)/(&total.+1)));/*FT转换*/
var=1/(&total.+0.5);/*各中心FT转换率的方差*/
%end;
weight=1/var;/*各中心权重*/
p_w=weight*&type._p;/* 权重×事件发生率 */
weight2=weight*weight;/* 权重×权重 */
run;
/*生成宏变量:计算Q统计量、加权率(未调整权重)等*/
proc sql noprint;
select sum(p_w),/*各中心权重×事件发生率之和*/
sum(weight),/*各中心权重之和*/
sum(p_w)/sum(weight),/*率的加权平均(未调整权重)即:加权率*/
1/sqrt(sum(weight)),/*加权率的标准误*/
sum(weight2),/*各中心权重×权重之和*/
sum(&total.),/*总样本量*/
count(distinct &siteno.),/*中心数量*/
count(distinct &siteno.)/sum(total_in)/*谐波均数harmonic mean*/
into:p_w_sum,:weight_sum,:effect_p0,:se,:weight2_sum,:total_sum,:C,:h_mean
from weight_&type.;
select sum(weight*(&effect_p0.-&type._p)**2)into:Q /*Q值*/
from weight_&type.;
quit;
/*异质性检验,并计算中心间变异(D值)*/
data Q_&type.;
p_Q=1-probchi(&Q.,&C.-1);/*异质性检验*/
if p_Q<0.0001 then pvalue_Q='<0.0001';else pvalue_Q=put(p_Q,6.4);
D=max(0,(&Q.-(&C.-1))/(&weight_sum.-(&weight2_sum./&weight_sum.)));
call symput(′D′,D);
run;
/*生成宏变量:用于计算加权率(调整权重后)及其95%置信区间的相关指标*/
proc sql noprint;
create table weight_&type.
as select *,1/(&D.+1/weight)as adjust_weight,/*调整后的各中心权重*/
&type._p*calculated adjust_weight as p_adw /*调整后权重×事件发生率*/
from weight_&type.;
select sum(p_adw),/*各中心调整后权重×事件发生率之和*/
sum(adjust_weight),/*各中心调整后权重之和*/
sum(p_adw)/sum(adjust_weight),/*率的加权平均(调整权重后)即:加权率*/
1/sqrt(sum(adjust_weight))/*加权率的标准误*/
into:p_adw_sum,:adw_sum,:ad_effect_p0,:ad_se
from weight_&type.;
quit;
/*计算事件率及其95%置信区间:原始率,logit转换率和双反正弦转换率;率的反算;调整权重与否*/
data effect_&type.;
set Q_&type.;
Q=put(&Q.,6.2);
/*原始率*/
% if &type.=p %then%do;
effect_p=&effect_p0.;/*不调整权重effect size*/
lower=max(effect_p-probit(0.975)*&se.,0);/*95%置信区间下限*/
upper=min(effect_p+probit(0.975)*&se.,1);/*95%置信区间上限*/
ad_effect_p=&ad_effect_p0.;/*调整权重effect size*/
ad_lower=max(ad_effect_p-probit(0.975)*&ad_se.,0);/*95%置信区间下限*/
ad_upper=min(ad_effect_p+probit(0.975)*&ad_se.,1);/*95%置信区间上限*/
%end;
/*logit转换*/
% if &type.=logit %then%do;
effect_p=exp(&effect_p0.)/(1+exp(&effect_p0.));/*不调整权重effect size*/
lower=exp(&effect_p0.-probit(0.975)*&se.)/(1+exp(&effect_p0.-probit(0.975)*&se.));/*95%置信区间下限*/
upper=exp(&effect_p0.+probit(0.975)*&se.)/(1+exp(&effect_p0.+probit(0.975)*&se.));/*95%置信区间上限*/
ad_effect_p=exp(&ad_effect_p0.)/(1+exp(&ad_effect_p0.));/*调整权重effect size*/
ad_lower=exp(&ad_effect_p0.-probit(0.975)*&ad_se.)/(1+exp(&ad_effect_p0.-probit(0.975)*&ad_se.));/*95%置信区间下限*/
ad_upper=exp(&ad_effect_p0.+probit(0.975)*&ad_se.)/(1+exp(&ad_effect_p0.+probit(0.975)*&ad_se.));/*95%置信区间上限*/
%end;
/*双重反正弦转换*/
%if &type.=darcsin %then%do;
effect_p=0.5*(1-sign(cos(&effect_p0.))*sqrt((1-(sin(&effect_p0.)+(sin(&effect_p0.)-1/sin(&effect_p0.))/(&h_mean.))**2)));/*不调整权重effect size*/
lower0=&effect_p0.-probit(0.975)*&se.;
upper0=&effect_p0.+probit(0.975)*&se.;
lower=0.5*(1-sign(cos(lower0))*sqrt((1-(sin(lower0)+(sin(lower0)-1/sin(lower0))/(&h_mean.))**2)));/*95%置信区间下限*/
upper=0.5*(1-sign(cos(upper0))*sqrt((1-(sin(upper0)+(sin(upper0)-1/sin(upper0))/(&h_mean.))**2)));/*95%置信区间上限*/
ad_effect_p=0.5*(1-sign(cos(&ad_effect_p0.))*sqrt((1-(sin(&ad_effect_p0.)+(sin(&ad_effect_p0.)-1/sin(&ad_effect_p0.))/(&h_mean.))**2)));/*调整权重effect size*/
ad_lower0=&ad_effect_p0.-probit(0.975)*&ad_se.;
ad_upper0=&ad_effect_p0.+probit(0.975)*&ad_se.;
ad_lower=0.5*(1-sign(cos(ad_lower0))*sqrt((1-(sin(ad_lower0)+(sin(ad_lower0)-1/sin(ad_lower0))/(&h_mean.))**2)));/*95%置信区间下限*/
ad_upper=0.5*(1-sign(cos(ad_upper0))*sqrt((1-(sin(ad_upper0)+(sin(ad_upper0)-1/sin(ad_upper0))/(&h_mean.))**2)));/*95%置信区间上限*/
/*如果95%置信区间下限或上限小于minimum,则“截断”为0;如果95%置信区间下限或上限大于maximum,则“截断”为1*/
minimum=(arsin(sqrt(0/(&h_mean.+1)))+arsin(sqrt((0+1)/(&h_mean.+1))));
maximum=(arsin(sqrt(&h_mean./(&h_mean.+1)))+arsin(sqrt((&h_mean.+1)/(&h_mean.+1))));
if lower0 if &effect_p0. if upper0 if lower0>maximum then lower=1; if &effect_p0.>maximum then effect_p=1; if upper0>maximum then upper=1; if ad_lower0 if &ad_effect_p0. if ad_upper0 if ad_lower0>maximum then ad_lower=1; if &ad_effect_p0.>maximum then ad_effect_p=1; if ad_upper0>maximum then ad_upper=1; %end; run; /*生成输出数据集,保留关键指标*/ data &output.; length label $50; retain label effect CI ad_effect ad_CI Q pvalue_Q; set effect_&type.; label=“&name.”; effect=compress(put(effect_p*100,6.2)||'%'); lower=put(lower*100,6.2); upper=put(upper*100,6.2); CI=compress(′(′||lower||′%′||′,′||upper||′%′||′)′); ad_effect=compress(put(ad_effect_p*100,6.2)||′%′); ad_lower=put(ad_lower*100,6.2); ad_upper=put(ad_upper*100,6.2); ad_CI=compress(′(′||ad_lower||′%′||′,′||ad_upper||′%′||′)′); label label=“数据转换方法” effect=“中心权重法:事件发生率” CI=“中心权重法:95%置信区间” ad_effect=“调整中心权重:事件发生率” ad_CI=“调整中心权重:95%置信区间” Q=“Q统计量” pvalue_Q=“Q检验P值”; keep label effect CI ad_effect ad_CI Q pvalue_Q; run; %mend S_CG_CenAdj; 宏程序调用示例: %S_CG_CenAdj(example,p,event,total,siteno,原始率,p1); %S_CG_CenAdj(example,logit,event,total,siteno,logit转换率,p2); %S_CG_CenAdj(example,darcsin,event,total,siteno,双反正弦转换率,p3);
猜你喜欢
内江师范学院学报(2022年4期)2022-04-27 02:22:32湖北师范大学学报(自然科学版)(2021年3期)2021-09-08 01:00:48数学物理学报(2021年1期)2021-03-29 03:14:30基层中医药(2020年5期)2020-09-11 06:32:04诗潮(2019年8期)2019-08-23 05:39:48铁道通信信号(2018年9期)2018-11-10 03:26:34意林·少年版(2018年10期)2018-05-30 16:24:42诗潮(2017年4期)2017-12-05 10:16:18诗潮(2015年3期)2015-03-20 14:40:24中国合理用药探索(2012年2期)2012-03-20 16:30:30
