
数据挖掘在国内护理领域应用的文献计量学分析
2021-06-01 12:27杨健健马小琴
护理与康复 2021年5期
杨健健,马小琴,郭 冉
浙江中医药大学护理学院,浙江杭州 310053
随着新一代信息技术的发展及大数据时代的到来,医疗相关领域的数据正在飞速增长。在医疗护理领域,对数据的初步处理(录入、查询及统计等)已经通过护理信息系统得到了较好的解决,但对于数据的深入处理即数据挖掘目前还处于萌芽阶段[1]。数据挖掘是指应用数据挖掘技术对存在噪音和缺失的海量数据进行有效分析以获得潜在有用信息的过程[2]。数据挖掘可以解决目前护理领域中未得到有效利用的护理数据问题。虽然当前数据挖掘在护理学研究中的应用有一定进展,但相对于国外发展仍滞后[3]。为此,本文对已发表的有关数据挖掘在护理领域应用的文献进行文献计量学分析,为今后护理人员开展护理学相关研究提供参考。
1 资料与方法
1.1 文献检索策略
纳入标准:汉语类的一次文献,包括期刊论文、学位论文。排除标准:会议论文、综述或理论探讨类文献、专利、报纸;重复发表的文献。检索中国期刊全文数据库(CNKI)和万方数据库建库至2019年12月31日发表的有关数据挖掘在护理领域应用的文献,分别以“数据挖掘/决策树/遗传算法/关联规则/神经网络/贝叶斯/粗糙集/聚类分析/主成分分析”“护理”为检索式进行检索。
1.2 资料分析方法
纳入的文献均采用Excel 2013进行资料提取,内容包括文献的题目、发表年份、地域分布、第一作者单位机构类别、期刊分布情况、作者人数、科研基金资助情况、数据挖掘技术种类及其在护理领域应用情况等,进行描述性统计分析。
2 结果
2.1 文献检索结果及年度分布
初步检索获得相关文献共1 187篇。采用Note Express软件进行查重后剩余933篇文献,根据纳入标准与排除标准再一次筛选,最终纳入文献351篇,其中期刊论文252篇、学位论文99篇。纳入文献年度分布情况见图1,相关文献最早出现于1996年,1996-2019年发文量总体呈上升态势,自2011年开始发文量呈快速上升趋势,2019年发文量达89篇。
2.2 发文地区及机构分布
文献第一作者分布于26个省、自治区、直辖市。发文数量排名前5的省市为北京(36篇)、江苏(35篇)、上海(29篇)、山东(26篇)、湖北(24篇),共计150篇(42.74%),见图2。第一作者所在机构以医学院校和医院居多,分别为165篇(47.01%)、 128篇(36.47%),非医学院校46篇(13.11%),其他机构12篇(3.42%)。
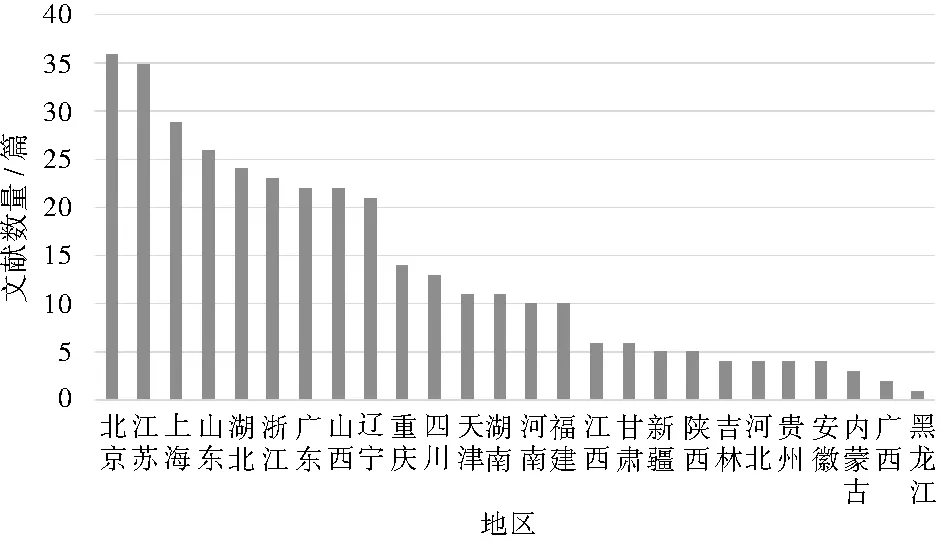
图2 纳入文献地区分布情况
2.3 文献期刊分布
纳入的252篇期刊论文分布于103种期刊,刊均载文量2.45篇,其中刊载文量超过2.45篇的期刊有10种,共刊载论文100篇,占期刊论文总量的39.68%;其中3种期刊为中国科学引文数据库(2017-2018年度)收录期刊,该3种期刊发表的文献占总文献量的8.55%。刊载文量超过2.45篇的期刊分布情况见表1。
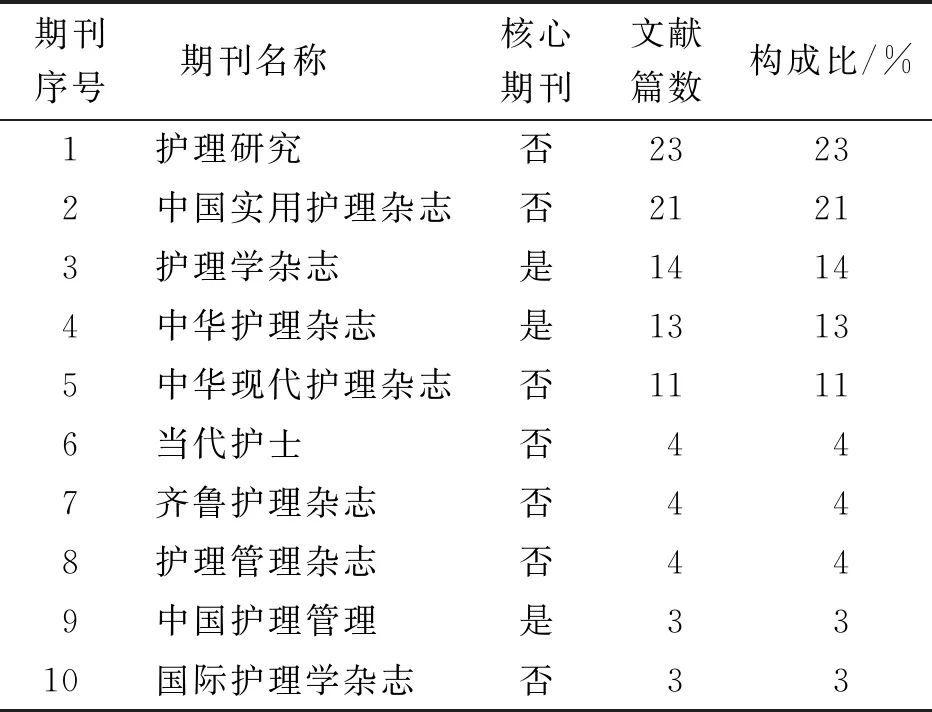
表1 刊载文量超过2.45篇的期刊分布情况(n=100)
2.4 文献合著及被引与基金资助情况
收录的351篇文献中2人及以上合著132篇,作者人数最多达9人,作者总人数811人,合作撰文率37.61%(132/351),文献合作度2.31 (811/351)。351篇文献中被引频次≥1次的文献有196篇,其中被引1~10次的文献有154篇(78.57%),被引频次>10次有42篇(21.43%)。351篇文献中基金论文105篇(29.91%),其中国家级课题22篇,省级(含自治区)课题46篇,厅局级及市级课题26篇,院校级课题9篇,医院级课题2篇。
2.5 数据挖掘技术分布情况
对纳入的351篇文献进行文献计量学分析后,得到护理领域使用率排名前5的数据挖掘技术为:聚类分析142篇(40.46%),主成分分析131篇(37.32%),决策树36篇(10.26%),关联规则20篇(5.70%),遗传算法17篇(4.84%)。经研究分析显示,有关聚类分析的文献中用于揭示护理领域研究热点的文献有81篇,用于提升护理管理效率(包括绩效及人力资源管理)的文献32篇,此外根据患者健康相关数据提取聚类信息,用于提高临床护理质量的文献29篇;应用主成分分析作为数据挖掘技术的文献均是在量表制定过程中被用于检验量表的结构效度;36篇应用决策树挖掘事物影响因素的文献中,有20篇文献基于影响因素的挖掘用于构建评价护理质量的体系,有16篇用于构建护理不良事件的预测模型;关联规则多用于分析事物的影响因素(15篇)及临床护理的规律(5篇),其中15篇事物影响因素挖掘的文献中分别是用于分析影响患者满意度因素、延缓疾病恢复因素及促进不良反应发生因素(各5篇);遗传算法则均用于解决护士排班问题,以优化护理资源配置,提升护理管理效率。
3 讨论
3.1 文献年度发文的分析
从图1可见,数据挖掘应用于护理领域的研究发展可分为两个阶段:起始阶段(1996-2010年),发文数54篇,占文献总量的15.38%,与数据挖掘在护理领域的应用尚处于探索阶段,存在资源信息共享不完善及专业人才资源短缺等问题有关[4];快速发展阶段(2011-2019年),随着数据挖掘理论的成熟,应用范围的扩大,数据挖掘应用于护理领域的成果明显增多,这可能与2011年护理学成为一级学科,为护理事业与护理信息化发展提供了广阔的空间有关[5]。
3.2 文献发文地区及机构分布分析
文献第一作者地区分布广泛,但发文量存在明显差异,北京、江苏、上海、山东、湖北5个发文量最多的省市发文占文献总量的42.74%。王佳宁等[6]发现一个地区科技的进步和经济的增长是相辅相成的,科学技术推动着该地区经济的增长,反过来增长的经济可通过加大科研经费的投入来促进该地区科技的发展。这也就解释了为什么北京、江苏及上海等经济发达省市发表的有关数据挖掘在护理领域中应用的文献量较多。医学院校相比于其他机构在护理领域的科研实力相对较强,其研究成果也相对较多。究其原因可能与高校的职能是培养出临床和科研能力并重的高水平医学人才有关。因学科交互已成为不可逆转的国际趋势[7],非医学院校的研究成果也占有一定的比例。
3.3 文献期刊分布分析
纳入的351篇文献中,学术期刊载文252篇,硕士博士论文99篇。该研究中超过平均载文量2.45篇的10种期刊中仅有3种期刊被收录中国科学引文数据库(2017-2018年度)[8],且在该 3种期刊中发表的文献仅占总文献量的8.55%,可见数据挖掘应用于护理领域的相关文献在核心期刊上发表较少,表明该领域相关研究的深度和广度不够,这可能与护理人员对数据挖掘技术掌握度不够、未能充分运用该技术对临床护理数据进行全面挖掘有关。
3.4 文献合著被引及基金资助分析
研究结果显示,本研究的文献合作度为2.31,远未达到中国科技期刊引证报告统计的指标[9]。科研人员间的相互合作可以发挥不同作者间的专长,实现优势互补,在促进科研项目的发展同时还保证了该领域的研究水平和质量。故为了提升文献质量,护理人员还应重视团队成员间或与其他相关学科人员间的合作。论文被引频次的多少表明了该篇论文的质量及学术水平的高低,已经成为论文评价的重要指标之一[10]。本次研究纳入的351篇文献中,44.2%的文献无被引记录,被引频次>10次的论文仅42篇,占被引文献的21.43%,从被引频次角度说明目前数据挖掘在国内护理领域文献的利用率不高,论文质量及学术影响力也尚处在较低水平,故需加强护理人员关于数据挖掘技术的培训,以提升该研究领域护理论文的质量及学术影响力。相比于2016年统计的中国科技核心期刊基金论文比的平均值(0.59)[9],该领域的基金论文数量相对较少,这可能是数据挖掘在我国护理领域起步较晚,护理人员对数据挖掘技术的熟悉度和掌握度相对较低,还未达到开展这方面研究的能力,最终导致这方面课题的申报数量相对较少。
3.5 数据挖掘技术分析
3.5.1聚类分析
本研究结果显示,聚类分析在护理研究中的应用最频繁(占总文献数量的40.46%),究其原因可能是聚类分析可用于揭示护理领域的研究热点,而对热点的准确把握对于一门学科今后的发展至关重要[11]。戴红等[12]将聚类分析应用于中医护理领域,揭示了中医护理技术在临床应用的研究热点,为促进中医护理技术的发展提供了科学依据和理论参考。对护理人力资源及患者健康相关数据等进行聚类,为优化护理方案提供依据,提升护理质量。李建[13]应用聚类分析对护理人员进行分类,实现护理岗位最优人员配置,提升护理管理质量。黄玉梅[14]对社区护士所需的知识与技能进行聚类,为规划社区护士岗前培训内容提供了参考依据。
3.5.2主成分分析
当前医疗护理数据中存在许多“软数据”,这是一些不可直接测量的指标或抽象的概念,而这些指标或抽象的概念如疼痛评价指标及患者满意度等若能得到客观的评价可有助于提高患者的治疗效果、节约医疗成本以及提升护理质量[15],故如何正确利用医疗护理“软数据”是当前护理人员关注焦点之一。而护理评价量表作为一款测量“软数据”的工具,也被护理研究者所青睐[16]。在量表制定的过程中,主成分分析因良好的量表结构效度检验而被广泛使用[17]。涂姝婷等[18]应用主成分分析检测量表的结构效度,经检测的量表在测量社区护理人员工作环境方面有较好的信效度。这也解释了本研究结果中主成分分析在护理学研究中较为常用的原因。
3.5.3其他数据挖掘技术
本研究显示,除聚类分析及主成分分析以外,其他数据挖掘技术在护理学研究中的应用率不到25%,这表明目前对于医疗护理数据的挖掘存在数据挖掘方法单一以及较为特殊和复杂的数据挖掘技术使用率低等问题,这可能与护理人员的整体信息处理能力及数据挖掘知识存在不足有关[19]。这些较为特殊和复杂的数据挖掘技术,如决策树、关联规则等可发现更多的护理新规律,不但可优化护理资源配置及护理质量管理等,还可提升护理人员护理患者的水平[20]。故今后应增加护理人员信息处理技术的培训,加大护理信息专科人才的培养,以促进数据挖掘技术在护理领域中的有效应用。
猜你喜欢
军事运筹与系统工程(2022年1期)2022-11-15
质量安全与检验检测(2022年2期)2022-11-13
九江学院学报(自然科学版)(2022年2期)2022-07-02
现代仪器与医疗(2021年2期)2021-07-21
智慧健康(2021年8期)2021-05-17
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
环球时报(2020-04-07)2020-04-07
地理教育(2018年6期)2018-07-12
特别健康·下半月(2017年10期)2017-10-26
