
基于编解码器结构从图像生成文本的研究进展
2021-05-28 06:04吴越
现代计算机 2021年11期
吴越
(四川大学计算机学院,成都610065)
0 引言
随着日常生活的数字化程度的逐步加深,数字图像的数量也在飞速增长,而人们利用图像的能力与图像的增长速度却不匹配,从图像生成文本即图像标注旨在为计算机赋能,使其具备“看图说话”的能力,能够自动地从图像获得描述性的文本,可以帮助人们从海量的图像数据中获取所需要的信息,在视觉问答系统、以图搜图、视频内容理解等任务场景都有着重要的应用,在商业、军事、教育、生物医学、数字图书馆等领域都有良好的发展前景。
近年来,随着人工智能浪潮的翻涌,越来越多的专家和学者投入到神经网络的研究中来,其中以文本方向的自然语言处理(NLP)和图像方向的计算机视觉(CV)最为火热,而从图像生成文本即图像标注作为这两个方向的结合,得益于两者的快速发展也取得了坚实而长足的进步。从图像生成文本的方法大致可以分为基于模板、基于检索和自动生成三种,目前效果最好的模型几乎都是采用自动生成的方法,本文的主要关注点在自动生成中基于神经网络的编码器和解码器结构的算法,这也是目前主流的方法,以下分别从三个方面进行阐述:基于编解码器从图像生成文本的神经网络模型、生成过程中的重要研究点以及网络模型的性能评价。
1 基于编解码器从图像生成文本的神经网络模型
基于编解码器[1]从图像生成文本的神经网络模型包括三个主要部分:骨架网络、编码器和解码器。其中骨架网络采用卷积神经网络(CNN),用来提取图像的视觉特征表示,生成高维的视觉特征图;编码器利用骨架网络产生的视觉特征图编码成一个上下文向量;解码器根据上下文向量来生成最终的描述性文本。
主流的神经网络模型大致可以分为三类:CNN +RNN、CNN+CNN、CNN+Transformer。
1.1 CNN+RNN
CNN+RNN 模型使用卷积神经网络(CNN)作为骨架网络,循环神经网络(RNN)作为编码器和解码器,如图1 所示。
CNN 模型以AlexNet[2]、VGG[3]、GoogLeNet[4]、ResNet[5]等为主要代表,这些模型已经在大规模的图像数据集如ImageNet[6]、COCO[7]等中表现出了极其优越的性能,通过卷积、池化、激活函数、归一化等操作能够从图像数据中提取出有效的特征信息,这些特征信息可以直接作为编码器的输入,而不再需要机器翻译的做法(将输入的语句序列通过词嵌入变成向量空间中的高维向量,然后再送入编码器进行上下文向量的编码),不过需要额外对特征信息进行位置编码,因为图像特征可以看作一个二维向量,通用做法是按行或者按列展开成一个序列,所以需要对序列中加入行或者列的信息。
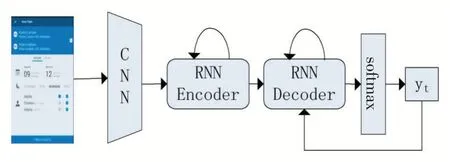
图1 CNN+RNN模型结构
现有研究不仅仅是使用CNN 模型来提取视觉特征图,更多的是采用目标检测网络(以R-CNN[8]、Faster R-CNN[9]为代表,已经在计算机视觉领域下的目标检测中证明了其优越性)提取出感兴趣的区域,然后将这些区域作为编码器的输入信息。
RNN 主要采用长短期记忆神经网络(LSTM)[10]及其变种双向LSTM(BiLSTM)[11]和门控循环单元(GRU)[12],这些模型也已经在语言模型上表现出了极其优秀的性能,采用自回归的方式逐字的生成描述性文本。模型按照时间片一步一步的向前推进,每一个时间片的输入包括上一个时间片的隐状态和生成的单词,然后经过运算产生当前时间片的隐状态和单词,循环往复的执行下去,直到输出结束标记停止,每一步得到的单词串起来就是完整的输出序列。模型将
由于RNN 模型在机器翻译领域表现良好,故而在图像生成文本中也较常采用RNN 类的模型,且基于自回归特性,能够生成不定长的描述性文本,恰好满足任务需求。但是因为它的逐字的训练方式,导致模型并行运算程度低,不能较好地发挥GPU 的并行计算能力,故而另有一部分研究着重关注并行计算。
1.2 CNN+CNN
由于RNN 模型的特性,每一步都是将上一步的输出当作输入,从而按时间片展开进行训练,虽说模型生成文本的效果较好,但是训练时间比较长,并不能较好地发挥GPU 并行计算的能力,而在计算机视觉领域广泛采用的CNN 却能很好地并行计算,如果能够将CNN用来做不定长文本生成的话,恰好能解决这一问题,基于此,有一些研究专门针对CNN 网络来模拟RNN效果。

图2 CNN编解码器
这种CNN 不同于图像中采用的2D 的CNN,被称作因果卷积[14],实质上是堆叠而成的一维卷积,如图2所示,将提取出的图像特征与文本的词嵌入向量一起送入CNN 编码器提取上下文向量,再采用解码器进行解码,实际构建中可能不进行编解码器的区分,直接堆叠卷积层[15],然后进行计算得出描述性文本,需要注意的是,采用的卷积层为了避免“看到”未来的单词向量,加入了mask 来进行遮蔽,达到选择性计算的目的[16]。
利用CNN + CNN 模型进行图像到文本的生成任务,基本上可以达到3 倍于CNN+RNN 模型的训练速度,并且可以取得相当的生成效果。
1.3 CNN+Transformer
CNN+Transformer 模型[17]使用CNN 提取图像特征或者目标检测器提取感兴趣区域,然后送入Transformer encoder 进行上下文向量编码,之后送入Transformer decoder 进行解码生成描述性文本,其中encoder 和decoder 都是多层堆叠的[18],层内结构如图3 所示。其中CNN 模块的使用和组成同1.1 小节中的描述,但是将编解码器的RNN 模块使用Transformer[19]进行替代,这种做法基于以下几个原因。
(1)RNN 的step by step 的训练方式导致它的训练速度过于缓慢,对于具有强大并行计算能力的GPU 来说,这种算法并不高效,需要花费大量的时间。而Transformer 模块的self-attention 完全可以并行计算,能够充分发挥GPU 的性能,加快模型的训练速度。
(2)RNN 天生具有长依赖问题,即对于当前的预测来说,它的输出虽说是依赖于之前时间片所有的输出得出来的,但是距离过长的时间片的输出对于当前时间片的影响可以说是微乎其微,虽然引入了LSTM 可以部分解决长依赖,但是对于过长的序列,依然普遍存在这个问题。而图片本身又是一个2D 空间,将其从2D 空间展开成1D 空间向量所得到的序列往往都特别长,即使一个200×300 的小图片展开之后都可以达到60000 的序列长度,这时如果图片头和图片尾存在强依赖的话,LSTM 也会导致错误的预测结果。Transformer由于其每一个V 都是采用Q 和所有K 计算得出,即每一个值都是“看过”所有的值计算出来的,所以能够从根本上解决长依赖问题,就算是图片头的输出,也是可以“看到”图片尾的。

图3 Transformer编解码器层
Transformer 的解码器依然是一步一步的进行解码的,每一步都是基于之前生成的单词进行后面的预测,但是在训练的时候采用teacher-forcing mode 进行训练,这里是可以并行计算的,即一次性输入target 的嵌入向量矩阵,然后生成一个mask 向量矩阵,该矩阵特定编码成按target 单词长度的mask,从而保证每一次预测都是基于之前的预测的,而不需要一步一步的进行训练。
2 生成过程中的重要研究点
从图像生成文本最主要的研究点基本上可以概括为两个方面:一个是如何从图像提取特征表示,另一个是生成的文本和图像中哪些区域相关联。
2.1 如何从图像提取特征表示
得益于计算机视觉的高速发展,现在一般采用两种方法来进行图像特征提取:
(1)使用CNN 对图像进行卷积操作,不采用一般CNN 网络最后的连接层,而提取前面的图像特征图,然后将特征图按行或按列展开,使其成为一个1D 的向量,后续可以采用机器翻译类的模型,直接作为编码器的输入而不需要依照传统机器翻译的做法,将输入文本进行嵌入式操作。
(2)使用R-CNN、Faster R-CNN 等目标检测头来进行图像特征提取,不同于之前的CNN 卷积操作提取,先将目标检测头在目标检测数据集上做预训练,然后将目标检测头用来提取出一个感兴趣区域的集合,将这些区域的集合作为编码器的输入。
由于检测头提取的感兴趣图像区域更利于后续编码器提出上下文向量,现有state-of-the-art 的方法几乎都是采用的第二种特征提取方式。
2.2 生成的文本和图像中哪些区域相关联
由于网络的输出包括两个部分:图像和文本。它们之间有一个显而易见的区别,即图像具有2D 空间排列且宽高比例多变,而文本是1D 空间排列,那么如何将抽取出的图像特征和文本特征进行对齐呢?[20]针对这个难点问题,研究者提出了注意力机制,即对不同的向量有不同的得分,从而能够针对性的关注得分高的区域,从而将文本和目标区域关联起来[21]。
注意力最早在机器翻译里面提出来,主要源自于人类观察事物的时候总是只关注某一个局部,换句话说,一句话的主要意思只和某一些部分相关联,而和其他部分关联不大。前面所述的Transformer 模型采用了self-attention 的注意力机制,基于dot-product attention进行的改进,可以完全进行矩阵运算,并行效率高,并且每一个V 的计算都是在所有向量数据的基础上得出的,是一个优秀的注意力方法。
3 图像模型的性能评价
3.1 主流评测数据集
主要用来做图像生成文本任务的数据集包括:Flickr8k、Flickr30k 以及MS COCO。在对目标检测头做预训练的时候常用到的数据集包括:ImageNet、MS COCO 和Visual Genome。Flickr8k 是一个图像标注数据集,一共有8000 张图片,每一张图片都带有5 个不同的描述性文本;Flickr30k 增大了图片数量,每张图片依然是带有5 个不同的描述性文本,统一放在token 标注文件中,一共有30000 多张图片;MS COCO 数据集比较庞大,有多个分支,包括目标检测,分割以及图像描述等,常用2014 和2017 的版本,有超过16 万张图片,每个图片依然有5 个描述性文本,并且分了80 个类别,且同时包含目标检测的标注,所以可以同时作为目标检测头的预训练数据集。Visual Genome 有超过10 万张图片,对图片中出现的所有类别都进行了标注,且一张图片可能有多个描述性文本,主要针对场景和关系。
3.2 主流评价指标
主要用来评估图像生成文本任务的指标包括:BLEU、METEOR、ROUGE、CIDEr、和SPICE。BLEU 常用在机器翻译的任务中,用来评价翻译文本和参考文本的差异性,基于精度来进行相似性度量;METEOR 不仅仅考虑精度,还考虑了召回率,加入了同义词的考量,基于chunk 来进行得分计算;ROUGE 不同于BLEU,它是基于召回率来进行计算的,只要没有出现漏掉的词,得分就会比较高;CIDEr 是专门针对图像标注任务的指标,通过评价生成文本与其他大部分的参考文本之间的差异性计算得分,通过计算TF-IDF 向量的余弦距离进行度量;SPICE 也是针对图像标注任务的,与CIDEr 不同的是它是基于图的语义表示进行计算的,主要考量词的相似度。
4 结语
本文梳理了近年来在图像生成文本的任务上提出来的主要的编解码器模型。提出了3 种主要的编解码器类型,同时讨论了各种类型的主要特点;除此之外,也总结了2 个在图像生成文本任务中的主要研究点,便于后续深入研究;同时也描述了在图像生成文本任务中常用到的5 种数据集以及5 种评价指标,讨论了各个数据集特点和各种评价指标的特性。未来的研究者可以针对特定场景下的任务选取适用的评价指标,参考前面提出的神经网络框架进行深入研究,使其更好地适应任务场景。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
科技与创新(2017年5期)2017-03-28
新教育时代·教师版(2016年45期)2017-03-02
考试周刊(2016年90期)2016-12-01
人间(2016年27期)2016-11-11
电子设计应用(2004年6期)2004-07-27
