
粗粒度可重构阵列分支指令的优化设计与实现
2021-05-28 06:03汪翔
现代计算机 2021年11期
汪翔
(上海交通大学电子信息与电气工程学院,上海200240)
0 引言
粗粒度可重构阵列(Coarse-Grained Reconfigurable Array,CGRA)[1-4]是一种由运算处理单元,访存单元,控制单元等组成的字级可重构体系结构。它具有较高的执行能效,又能满足灵活性要求,是一种具有前景的异构加速器解决方案。CGRA 在运行时通过重新配置阵列结构来执行各种应用程序,相比于现场可编程门阵列(FP⁃GA),其字级可重构粒度降低了功耗和面积。通过并行化和深流水化阵列运算[5],达到提升计算能力的效果。
然而,由于基于动态数据流驱动的CGRA 缺乏传统CPU 的程序计数器机制和分支预测机制,CGRA 针对分支语句的优化有限。而相对于ASIC 来说,CGRA 在执行分支操作时往往激活多条路径,产生了较高的功耗。
当前的CGRA 在进行设计时通过加入SIMD 特性[6-9]以提高执行效率和性能功耗比,而如何在数据级并行的CGRA 上实现分支指令的执行也成为了CGRA研究中的一个关键问题。目前CGRA 的分支指令执行技术可以分为以下三种:部分断言技术(PP)[10]、完全断言技术(FP)[11-12]以及双发射单执行技术(DISE)[13]。
针对图1(a)所示的基本分支语句,使用部分断言技术进行映射的伪代码如图1(b)所示,针对两条分支语句分别进行函数计算,最后通过sel 操作选出运算结果,并存储到对应的数据地址上。将该代码映射在CGRA 上的数据流图如图1(c)所示,该方法同时执行两条路径,最后通过多选器选出结果操作数,优点在于架构修改小,适合执行分支路径较短的语句,缺点在于需要同时执行两条路径,造成不必要的功耗和性能开销,传统的静态配置CGRA 便是基于这一技术进行分支执行。完全断言技术(FP)要求在指令字中加入额外的条件操作指令位或者引入额外的AWAKE、SLEEP状态控制PE 对于特定的指令是否进行执行,但该技术要求每个PE 内部添加一个计数器和一个状态寄存器。双发射单执行技术(DISE)要求PE 一次取来两条分支指令,但是只执行其中的一条指令,但这要求了PE 需要具有执行两条不同类型指令的能力,并且提高了指令带宽的需求。
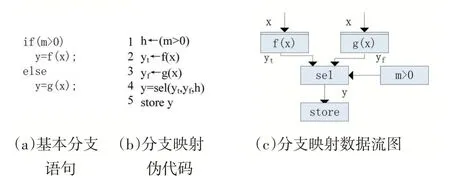
图1 CGRA部分断言分支映射方案
为实现在CGRA 上执行分支指令时功耗、性能以及资源量的优化,本文提出一种针对CGRA 的分支实现优化方法,通过控制实际运算是否执行大幅减少实际运算资源的开销,实现性能和功耗的优化,另外,该技术能有效简明地支持嵌套分支结构。
1 CGRA分支执行方案设计
为了解决当前CGRA 中的分支实现仍然存在着难以实现嵌套分支,分支实现功耗较高和分支实现性能较低的问题。本文在基于部分断言技术的基础上提出了一种优化分支实现技术,该技术绑定分支位使能或禁用运算访存操作,利用自定义的sc_if、sc_else、merge等指令修改分支位,有效简明地支持单层分支和嵌套分支结构。相比于部分断言技术,该技术禁用了未选中分支的运算操作,降低了功耗;通过消除sel 操作需要两路输入带来的紧耦合性,降低了单分支语句映射的资源量;另外,该技术禁用了未选中分支的访存操作,从而降低了片外存储器的带宽需求,有效提高了分支执行效率。
1.1 单层分支执行方案
针对图1(a)所示的基本分支语句,本文可实现两种分支映射方案,紧耦合类型的分支映射伪代码如图2(a)所示,分支映射数据流图结构如图2(b)所示,松耦合类型的分支映射伪代码如图2(c)所示,分支映射数据流图结构如图2(d)所示,为了使运算和访存的执行受到控制,在图2(b)和图2(d)数据流图的数据位上加入分支位部分,进行实际运算的PE 用空白背景标注,可能进行运算的PE 用阴影背景标注,D_C 为分支判断结果,h、hˉ分别表示if 和else 进行sc_if、sc_else 操作后的输出结果,符号“|”右边表示分支位的当前状态,T(true)表示分支位有效,F(false)表示分支位无效,图2(b)中,merge 节点进行分支汇聚操作,选出分支位有效的数据流以供后级PE 做进一步运算。
执行分支判断的PE 的输出结果由一对操作sc_if和sc_else 绑定到分支位上,sc_if、sc_else、merge 节点的行为可见表1(分支位简写为b,数据位简写为d),由于D_IF 路径和D_ELSE 路径输出数据由具体运算结果决定,因此除D_C 外,数据位不在输出信号表中作标注。在图2(b)和图2(d)的数据流图中,分支位h 和hˉ控制使能运算和访存,只有分支位有效时才会进行实际运算和访存,因此图2(a)和图2(c)中的3、4 行不会同时进行运算操作,另外,分支位通过数据流路径继续向下传输,直到遇到merge 节点时进行分支汇合,该节点内部配置为一个多选器,选择分支位有效路径的数据输出,从而完成一个分支指令。

图2 映射案例
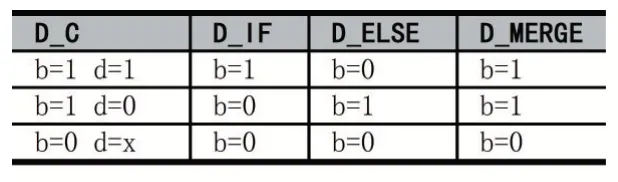
表1 路径输出信号表
为了去除采用merge 操作带来的耦合性,进一步设计了分支松耦合的映射方案,两者区别在于:在紧耦合映射方案中,存储目标操作数时使用了与部分断言技术类似的方案,利用merge 节点进行分支合并,在store 节点中存储目标操作数,在松耦合映射方案中,考虑到两路分支不会同时进行访存,因此可以两路同时进行存储操作的映射。在单分支指令下,由于松耦合方式两路运算无汇聚节点,可以直接去除另一路,从而进一步简化了映射结构,降低了资源数量,由于部分断言技术需要sel 操作进行数据匹配,只能提供紧耦合式的映射方式,仍然需要另一条伪分支路径进行sel 操作和存储操作,带来了后文所述的路径不平衡问题,大幅度提高了对带宽的需求和对节点数量的要求。
对于分支控制位无效的数据流,PE 和访存单元不进行实际的计算和访存,从而降低了ALU 运算和不必要的访存导致的功耗开销。
静态CGRA 的缺点之一在于不平衡路径会造成流水线的堵塞从而影响性能。由于两条分支数据通路延时不同,并共享一个数据来源和数据汇聚点,此时便会在长路径产生数据流气泡,导致数据吞吐率降低。本文借鉴文献[14]的做法,在短路径上加入NOP 节点进行路径平衡,从而优化了整体执行时间。
1.2 嵌套分支优化
针对代码1 所示的嵌套分支进行分支设计时,可以仅仅在图2(b)的DFG 中进行重复的单分支实现方式的扩展,如图3(a)所示,两路均需要进行嵌套分支判断的扩展,每个分支判断都需要一对sc_if 和sc_else 单元,但这种方式关键路径上存在着多个串行化的分支判断,sc_if、sc_else、merge 操作,延长了嵌套分支整体执行时间。
代码1 嵌套分支执行程序
为了解决嵌套分支执行中的性能损耗问题,本文针对嵌套分支提出了优化的执行策略,在单分支的执行基础上增加了concat、sc_sw 操作,以代码1 所示的嵌套分支程序为例,优化映射方式如图3(b)所示,使用concat 操作把两个分支判断结果绑定到数据位上。例如当左路径判断结果为false,右路径判断结果为true,concat 操作绑定的数据位为1,则只有sc_sw(1)操作将数据位转化为分支位有效的数据流,而其他路径则置分支位无效,避免了后级继续对该数据流进行运算和访存,从而降低了功耗和资源开销。
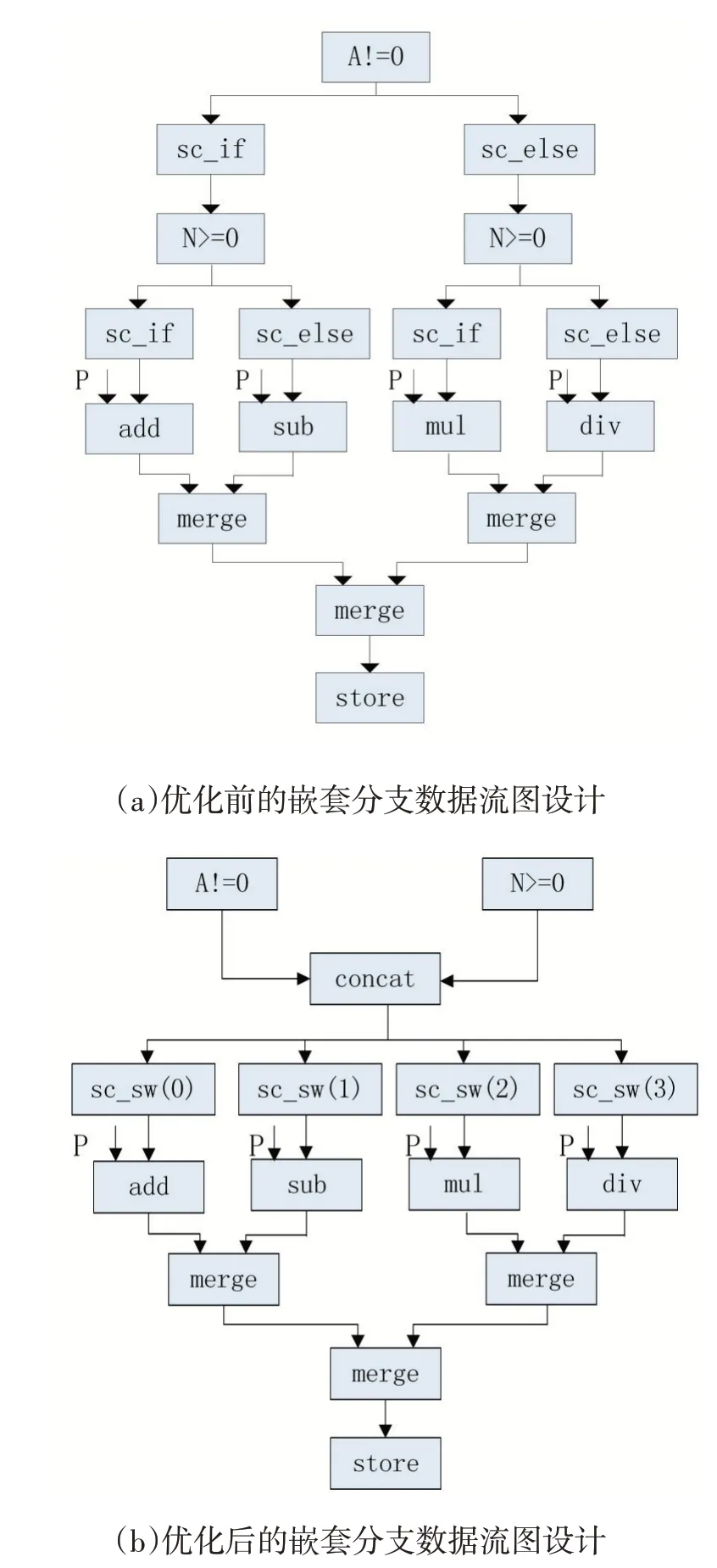
图3 嵌套分支映射对比
图3(b)的设计针对资源使用进行了优化,对于优化之前的图3(a)版本,若嵌套分支层数为n(n>1),则进行分支判断的PE 个数为2n-1,sc_if 和sc_else 的数量为2n+1-2,而对于优化之后的图3(b)版本,若PE输入端口数为m,则concat 数量为,sc_sw 数量为2n,分支判断PE 数量为n,两种设计方法merge 节点数量相等,均为2n-1,可以计算出图3(a)PE 资源数量PEs_A 与图3(b)PE 资源数量PEs_B 及差值如下所示:可以证明ΔPEs>0 ,且随n增大呈指数级增大趋势。
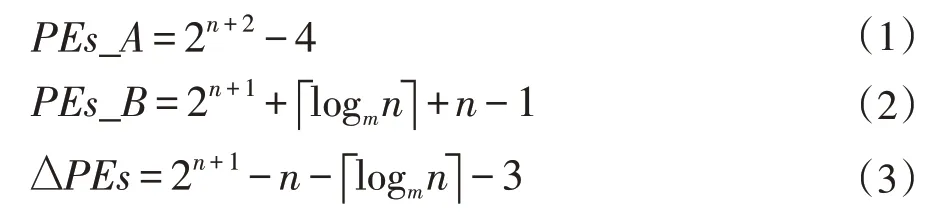
图3(b)的设计针对路径延时进行了优化,图3(a)映射方法的分支控制单元关键路径包括n层分支判断节点,n层sc_if 或者sc_else 节点,n层merge 节点,图3(b)映射方法的分支控制单元关键路径包括一层分支判断PE,层CONCAT,一层SC_SW 单元,n层MERGE 节点。可以计算出图3(a)实现方式的路径延时pd_A 与图3(b)实现方式的路径延时pd_B 数值及差值如下所示:可以证明Δdelay>0,且随n 增大而增大。
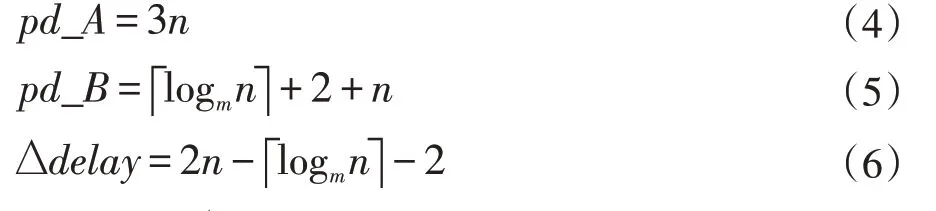
从以上公式可见,优化后的图3(b)的设计在资源使用和性能上均优于图3(a)的设计。
2 硬件实现
2.1 阵列架构
CGRA 阵列的整体架构设计如图4 所示,该阵列包括配置控制器,PE 阵列,片上缓存,执行控制器单元。配置控制器在CGRA 运行期间提供配置信息,PE阵列进行实际运算,片上缓存进行片上数据存取操作,执行控制器负责进行阵列与CPU 和DMA 的交互。
在PE 阵列中,PE 单元负责进行运算以及分支控制,LSE(Load Store Element)单元负责进行访存任务,包括为PE 提供操作数以及将数据存入存储单元。对于分支位无效的数据流,PE 不执行实际运算,LSE 不进行实际的访存,当进行取数操作时,LSE 将分支位无效的数据流直接返回给目标PE,不会占用读数所需的带宽。当进行存数操作时,LSE 不执行分支位无效数据流的访存,从而降低了功耗和带宽需求。
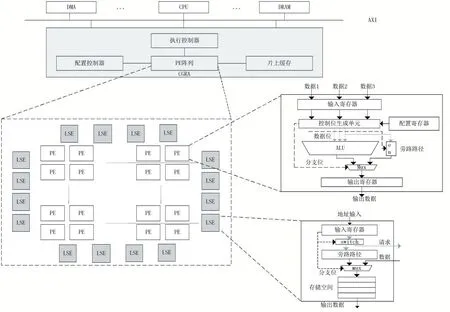
图4 CGRA整体结构图
2.2 实现细节
在如图4 所示的PE 和LSE 硬件结构中,灰实线包括数据位及有效位,黑实线包括数据位和控制位,虚线表示分支位。
在PE 内部,输入数据通过输入寄存器进入控制位生成单元中,在该单元中进行sc_if 和sc_else 指令的硬件实现,即将数据位的比较结果绑定到分支位上,若分支位无效,则通过旁路路径进入输出寄存器。在ALU内部,仅对分支位有效的数据流进行真实的运算,并在ALU 的输出端口上重新绑定输出数据位和控制位,通过输出寄存器在阵列中继续驱动下级PE,借助该分支位继续控制下级PE 和LSE 的执行动作。
本文中的LSE 负责使用地址输入进行片外存储器访存请求,对于分支位无效的数据流,通过多选器和switch 单元形成旁路通路进入存储空间,而对于分支位有效的数据流,则选通到总线上进行实际访存请求,从而实现了相对于部分断言技术的有效带宽的降低。
3 实验结果与分析
3.1 实验平台
本文基于C++搭建了一款周期精确的系统级行为模拟器,并借鉴了文献[15]的设计方法替换了基于分支执行优化的PE 和LSE 结构来进行分支执行性能与功耗的测试。该模拟器中包含周期精确建模的8×8PE 阵列,访存单元和其他控制单元,片外存储模型使用周期精确的存储器模拟器DRAMSim2[16]以确保内存仿真准确性,在仿真参数上选择DDR3 单元DDR3_micron_16M_8B_x8_sg15。片上功耗模型借鉴了哈佛大学研究小组提出的加速器模拟器Aladdin[17]的设计思路,借助其在40nm 标准库上仿真得到的功耗数据构建了功耗模型,用以评估PE 阵列运算和寄存器传输功耗。SRAM 功耗则借助挂载在系统模拟器上的CACTI 模拟器[18]进行功耗仿真,CACTI 提供了配置文件的接口,包括SRAM 的物理组数量、块大小等参数以准确地建立访存的功耗数据。
3.2 测试应用选择
本文从测试集MachSuite[19]中选择了具有分支指令的应用,以及一些具有典型分支行为的算法映射到PE阵列上进行测试。其中广度优先搜索(BFS)包括了多层分支语句。基因序列匹配(NW)的循环间具有一定依赖性,且包含嵌套分支语句。蝶形傅里叶变换(FFT)中包括一个短单分支语句,双调排序(BNCS)[20]包含多层循环,内存循环由分支语句使能,二分查找(BS)主要由嵌套分支语句构成,分支内语句较短。
3.3 实验结果分析
实验设置了使用部分断言分支技术的CGRA 作为基准组,使用了分支优化的CGRA 性能与功耗数据作为性能对照组。
本文以使用部分断言分支技术的CGRA 的性能作为资源数量,性能,功耗基准,性能和功耗对比图进行了归一化处理。资源数量实验结果如图5(a)所示,其中BFS、FFT、BNCS 主体为单分支语句,如果使用部分断言技术,则需要构造一条针对else 语句的伪分支来进行伪存取,为了进行路径平衡,需要加入更多的NOP节点,而在使用本文所述的分支实现方法时,由于在线上加入了分支位控制是否对数据流进行实际的存取,可以仅对单分支进行处理,因此在以上应用中可以使用尽量少的资源数量。另外,NW、BS 算法的各分支语句的目标操作数相对一致,对特定的目标操作数的单分支语句较少,而本文的方法则增加了SC_SW、SC_IF、SC_ELSE 等操作带来的资源开销,因此资源数量相对于部分断言分支技术相差不大。在这5 个算法上的测试结果显示本文的设计方法能达到平均12%的资源降低。
性能和功耗实验结果如图5(b)和图5(c)所示,由于基于部分断言分支技术实现的BFS、FFT、BNCS 包含更多的伪存取操作,占用了更多的DRAM 带宽,而本文所述分支实现技术则去除了这些伪存取操作,提高了性能和降低了功耗,而基于本文的分支实现技术实现的NW、BS 算法分支路径相对平衡,针对单个目标操作数的特殊运算路径较短,由于增加了sc_sw 等操作的开销,导致性能略差,而在功耗表现上,由于false 分支进行的是伪运算,因此仍然可以降低一定功耗。在采用了本文的设计方法后,性能平均提高31%,功耗平均降低21%。
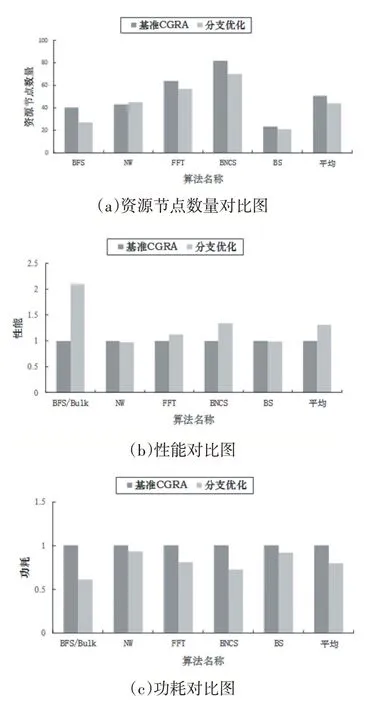
图5 结果对比图
4 结语
根据粗粒度可重构阵列的分支实现问题以及现有解决方案的不足之处,本文提出了基于分支发散汇聚的CGRA 分支实现方法。对于单层分支,使用自定义的sc_if、sc_else 进行分支发散,使用merge 操作进行分支汇聚,通过设置分支控制位控制数据流的实际运算与访存,从而实现了功耗优化。对于嵌套分支,使用自定义的sc_sw、concat 操作进行分支发散,同样地使用merge 操作进行分支汇聚,进一步优化了嵌套分支的实现效率。实验结果也证明了基于发散汇聚的分支实现方式的性能与功耗优化效果。
猜你喜欢
航空学报(2022年7期)2022-09-05
内燃机与配件(2022年2期)2022-01-17
电子技术与软件工程(2019年5期)2019-06-20
网络空间安全(2019年10期)2019-03-20
课程教育研究(2018年30期)2018-12-14
上海师范大学学报·自然科学版(2018年3期)2018-05-14
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
农机使用与维修(2016年10期)2016-11-10
大众理财顾问(2016年9期)2016-10-11
