
数据流安全查询技术综述
2019-03-20 14:37李军于灵凡田斌李犇李晔康海燕
网络空间安全 2019年10期
李军 于灵凡 田斌 李犇 李晔 康海燕


摘 要:随着基于数据流安全查询(网络流监控、股票数据在线分析、物联网中的分布式数据流查询、云计算下的数据流处理等)为背景的应用越来越普遍,学术界关于数据流上的安全分析、查询、管理已经成为当前数据库领域的一个很重要的研究热点。在数据流应用中,数据流的实时到达和元组的突变性使得数据流模型同传统数据库模型有本质上的区别。因此,许多基于传统数据库模型下的查询优化技术无法适应于数据流模型。以多媒体数据流安全检测和查询的视角,讨论的核心内容是数据流上的过滤器排序、数据流之间的连接计算以及自适应优化这三个子问题。文章针对以上子问题分别介绍了国际上关于数据流上自适应查询的一些主流研究思路和研究成果,并给出了下一步的研究思路。
关鍵词:数据流;过滤器排序;自适应查询
中图分类号:TP311 文献标识码:A
Adaptive security query of streaming data: a survey
Li Jun Yu Ling fan Tian Bin Li Ben Li Ye Kang Haiyan
(1.Department of information security, Beijing Information Science and Technology University, Beijing 100192;
2.China information security evaluation center, Beijing 100185;
3.Chaoyang Branch of Beijing Municipal Public Security Bureau , Beijing 100020;
4.China Mobile Corporation Hebei Branch, HebeiShijiazhuang 050035)
Abstract: With the application of data flow security query (network flow monitoring, online analysis of stock data, distributed data stream query in the Internet of Things, data stream processing under cloud computing, etc.), the application is more and more popular. Security analysis, query and management have become a very important research hotspot in the current database field. In data flow applications, the real-time arrival of data streams and the abruptness of tuples make the data flow model essentially different from traditional database models. Therefore, many query optimization techniques based on traditional database models cannot be adapted to the data flow model. From the perspective of multimedia data stream security detection and query, the core content of the discussion is the three sub-problems of filter sorting on the data stream, connection calculation between data streams and adaptive optimization. In view of the above sub-problems, some international research ideas and research results on adaptive query on data streams are introduced.
Key words: multimedia data Stream; adaptive query processing; filter ordering
1 引言
数据流作为数据库发展的一个重要分支,在20世纪末作为一种新型的应用的模式被提出,数据流具有广泛的应用前景,包括网络流监控、股票数据流分析、异常数据流挖掘和物联网分布式数据流协同处理等。因此,数据流环境下的查询[19, 1]、管理[3, 17]、过滤[1, 2]、挖掘[5, 6, 7]是当前数据库领域的研究热点。数据流模型是区别于以往数据库模型的新型数据应用模式。主要区别为:(1)数据流模型中数据是实时到达的,查询是相对“静止”的。相反,在数据库模型中,数据是相对“静止”的,查询是不断的变化;(2)数据流模型中数据一旦被处理以后即丢弃。相反,数据库模型中,查询一旦被处理以后即丢弃。数据流模型中数据到达的速度和规模具有不可预测性。
以上是数据库模型和数据流模型的本质区别,使得数据流模型和数据库模型对查询的处理技术差别很大。主要体现在传统数据库模型中,查询是不断变化的,每次提交的查询之间互不相关。查询一旦执行完毕就可以丢弃。在数据流模型中,查询是常驻于系统,一旦注册就要求一直“在线”,而数据是在不断的变化。数据一旦处理完毕就可以丢弃。这两种数据模型下对查询处理模式的差异性导致了传统数据库模型的查询处理技术已经无法适用于数据流领域。同时,在数据流环境下,由于数据流的速率和规模的随机性和不可预测性,自适应变化的查询处理策略变得更加重要。综上,本文以一种基于数据流实时查询的视角,重点关注了近年来对数据流安全计算尤其是流查询的研究成果。
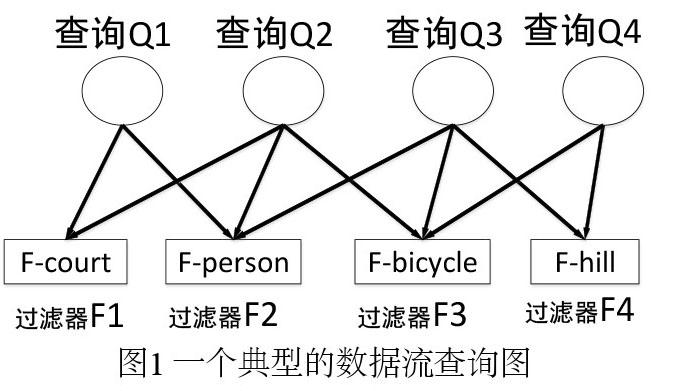
如图1所示,数据流系统通常注册大量“在线”的查询来完成数据流的实时查询处理。每个查询是多个过滤器(谓词)的“与”运算。每个过滤器的计算开销通常是比较昂贵的,特别是在日益普遍的多媒体数据流环境中。因此,数据流查询的目标就是通过计算尽可能少的过滤器来决定所有查询的结果。例如,假设在当前数据流上注册了四个查询,这些查询间共享的过滤器的数量是四个。对于当前数据流元组e,过滤器最优排序顺序A = F1;F2;F3;F4。也就是说顺序A的开销可能远远小于其他排序顺序如B = F2;F4;F1;F3。由于数据流上元组存在突变性,对于下一个数据流元组e,排序顺序B 的开销可能就优于排序顺序A。因此,在不断变化的数据流环境中,如何自适应的调整过滤器的排序顺序是关键问题。
近年來,数据流上的处理技术发展很快,主要侧重于数据流查询的处理和数据流上的深度内容挖掘技术。也出现了很多数据流管理系统,例如Tapestry[9]是构建在只支持添加模式的数据库系统上面的在线查询处理引擎,用来完成基于内容的过滤。这个系统可以说是数据流系统的雏形。
XFilter[11]将不同用户对XML 文档的“偏好”注册到系统中,将这些“偏好”作为查询以XPath[12]语言的形式来表示,进而实现了基于内容的过滤系统。Xyleme[13]是一个和XFilter[11]很类似的基于内容的过滤系统,只是使用的规则描述语言不同而已。Tribeca[14]系统是真正意义上的数据流管理系统,用来完成对网络数据流的在线查询,只不过提供查询的能力非常有限。OpenCQ[15]和NiagaraCQ[16]系统都是监视Web数据流的数据流管理系统。支持侧重点不太相同:OpenCQ[15]重点关注查询处理的算法。NiagaraCQ[16]侧重于支持的查询数量规模。Telegraph[19, 18, 20, 50]是比较有特点的数据流管理系统,具有较好的扩展性和移植性。其最大的特点是设计了一种称为Eddy[19]的机制,通过这个机制来完成对每个元组的自适应路由。Madden[20]重点讨论了在传感器网络环境中Telegraph[19]系统的查询执行策略。Madden[20]主要讨论了在Telegraph系统中如何自适应的处理多查询。Aurora[21]系统是侧重于网络管理应用的数据流管理系统,Aurora的核心是由操作符组成的触发器网络。每个触发器是由一个或者多个操作符组成的有向无环图。
对于每个使用了Aurora[21]系统的数据流管理应用中,管理员只需要创建一个或者多个触发器,并将这些触发器添加到Aurora触发器网络中。Aurora在执行计划编译时和运行时都进行了优化,Aurara在系统运行时通过检测资源负载情况结合注册服务的QoS进行“甩负荷”。STREAM[3]是一种基于关系模型的数据流管理系统。提出了一种数据流查询语言CQL[38]。所有操作算子和算子的优化都是在同一个进程中,调度算法按照时间片进行简单切割。STREAM 系统对查询的优化也非常有限,只是对单查询进行了选择下推,对多查询只是在数据共享方面做了一些优化工作。STREAM 基于关系模型进行数据流建模,给出了数据流环境下查询的较完备的形式化定义。另外还有其他一些数据流项目,例如COUGAR[22]是Cornell大学的一个传感器网络环境中的数据库项目,支持一种面向对象的查询语言,将传感器产生的数据定义为一个抽象数据类型,这样传感器输出的就是一个时间序列的数据流。StatStream[23]是纽约大学的跨多个数据流计算统计值的实时数据流统计系统。
结合上述研究成果,对提出的问题进行分析和总结。本文试图克服以上文献中的片面性,以一种全新的数据流实时处理的视角来重点介绍数据流查询领域的重点研究问题和解决办法。传统数据库模型对查询的精度、准确性有较高的要求,相反数据流模型对询计划执行的实时性和自适应调整这两个方面要求比较高。正是基于数据流模型和数据库模型在数据流查询领域的差异性,引出了三个重要子问题。
(1)在越来越多的数据流应用场景中,数据模态越来越多,例如文本、图片、音频、视频等。针对不同数据模态下的“操作算子”的属性也千差万别。将针对不同数据模态下的“操作算子”称为过滤器。这样,在数据流环境下的各种过滤器的属性(开销,选择性……)就各不相同,如果将开销较小的过滤器优先计算,那么对同一个元组的处理速度就要比其他策略要快。这就是过滤器的排序问题。过滤器排序问题是数据流处理领域最重要的问题之一。
(2)在很多数据流应用场景中,由于数据流之间的相关性越来越大,不同数据流之间通过各种属性(如网络流中四元组、时间戳、模态内容相似性)进行关联,这样就需要跨多个数据流进行融合过滤、分析、查询、管理,将这个问题称为多数据流融合计算。多数据流融合计算问题的核心是设计高效的多数据流之间的连接算子(Join operator)。多数据流的连接算子的设计是数据流领域的热点问题之一。
(3)自适应查询优化在数据流查询系统中,执行引擎通常将查询解析成执行计划,执行计划的单元是操作算子[1]。随着数据流中数据时刻变化,同一个操作算子在不同时刻所需要的资源也是时刻变化,在有限存储计算资源的情况下,如何自适应的优化执行计划以高效的处理实时数据流是数据流查询领域中一个很重要的研究热点。这个问题称为自适应查询优化[33]。
在余下的章节,按照以上列出的数据流查询领域的主要问题分别进行具体介绍:第二部分主要介绍共享过滤器排序问题;第三部分主要介绍数据流领域的主要连接算子研究进展情况;第四部分主要介绍自适应查询优化问题以及目前的进展,最后对本文工作进行总结。
2 共享过滤器排序
为了有效地过滤数据流中特定信息,人们常常在数据流上注册大量的查询,同时训练大量的过滤器。在数据流环境中,查询和过滤器常常是一种“多对多”的连接,也就是说对于单个过滤器的判断可能会同时给出多个查询的结果。在这种情况下,如何排序所有的过滤器来获得最小的过滤代价变得非常重要。对于过滤器的排序一般依赖于三个指标:过滤器本身的执行代价(c)、过滤器连接的查询数目(p)以及过滤器对于随机样本判断为真的概率(s)。针对过滤器的排序问题一般分为相关过滤器排序和独立过滤器排序两个子问题。其中,相关过滤器排序是指过滤器之间存在概率关系的情况下对过滤器进行排序。相反,独立过滤器排序问题则是相对比较理想的情况下,假设所有的过滤器都是相互独立。后者在数据流领域被广泛关注。
4 查询优化
查询优化的过程就是自适应查询处理的过程。在传统的数据库领域,查询的处理策略是:先计划,再执行。也就是,查询引擎首先决策出一个开销最小的查询执行计划,然后查询执行器来完成计划的执行。鉴于数据流查询中,数据流在速度和内容上具有不可预测性。因此,数据元组突变性可能会使得优化本次选择的执行计划在下一个数据元组的查询中会引起性能骤降[50, 37],这样就使得自适应查询处理在数据流领域被广泛关注[38]。自适应查询的主要研究动机是:
(1)由于数据流的突变,可能会导致本次的最优查询计划在下一次元组处理中的开销增加。自适应查询处理需要及时发现这种不适应并采取一些纠正措施;
(2)自适应查询处理可以及时探知数据源的未知属性并选择最优查询计划;
(3)鉴于数据流系统的资源限制条件,自适应查询处理要能够及时的根据当前系统资源和输入条件的限制做出最优计划的决策。
自适应的查询处理可以避免因为死板的查询计划带来的性能抖动,使得数据流系统的查询性能趋于稳定[45, 37]。在自适应的查询处理模型中,查询的执行被严格的划分为优化阶段和执行阶段。这两个阶段相互独立。这样可以使得查询的处理过程中可以及时的纠正因为优化策略带来的性能颠簸。自适应查询处理在过去几年中的进展情况为:
(1)所有自适应查询处理的工作集中在最近的十年内;
(2)在自适应查询处理领域的主要研究工作具有很大的差异性,这些差异性主要体现在查询语义的不同,不同的数据源,开销度量方式的差异,优化框架的差异以及不同的自适应定义;
(3)自适应查询处理的框架主要包括三个重要的组成部分。
1)优化器:选择一种开销最小的执行计划;
2)执行器:按照当前选择的执行计划来完成查询的执行操作;
3)统计跟踪器:统计在查询执行过程中的系統资源信息,查询开销信息等。以供优化器在优化过程中使用。
文献[38]第一次对数据流系统按照查询执行策略进行了分类并对系统的性能表现进行了详细的对比。对主流的数据流系统按照查询执行的策略分为三类。
(1)基于计划的系统:传统“先计划,再执行”的查询执行模式的扩展。主要的扩展体现在增加了统计跟踪器、自适应查询,如图5所示。统计跟踪器用来收集查询执行过程中的系统信息来作为优化器重新优化的重要数据参考。
(2)基于路由的系统:以Eddy[19]和River[39]作为这个分支的经典代表。核心思想是将数据流上的元组的查询过程看成一个个的数据包在操作算子间的路由。因此,所有的优化策略都是基于数据流元组级别。自适应查询处理的流程如图6所示。
(3)基于持续查询的系统:以CAPE[17]、NiagaraCQ[40]、StreaMon[49]作为这个分支的经典代表,是数据流领域查询处理的主要模型。重点考虑大量查询在线注册的情况下,将查询和数据流元组的变化常态化,重点关注优化器自适应的调整操作算子的顺序来完成查询的执行过程。自适应查询处理的流程如图 7 所示。
依据上面的分类,对近年来主流的数据查询处理系统进行简单的归类和简单说明,如表1所示。
5 结束语
本文回顾了数据流领域的国内和国际上在该领域的主要研究成果,从数据流过滤的视角重新审视自适应查询的问题,综述了在数据流模型中自适应查询出现的主要问题(过滤器排序、数据流连接、查询优化),并结合大规模数据流安全检测背景,形成了下一步的研究思路。
(1)过滤器排序:在数据流环境下的各种过滤器的属性(开销、选择性、窗口等)差异较大,以往工作均是结合自身过滤器属性构建简单的排序算法,普遍不具备自适应调整能力。下一步的工作重点是普适性的过滤器度量模型和自适应排序算法。
(2)数据流连接:随着大数据和高通量计算需求日益旺盛,跨多数据流进行融合过滤、分析、查询、管理归类为多流融合计算问题。多流融合计算问题的关键是设计高效的多数据流间的连接算法和环境感知关联模型。通过研究发现,当前工作中对连接算法普遍采用数据库连接计算方法,缺乏对数据流和大数据环境下的环境感知能力,下一步重点考虑构建具备环境感知能力的数据流关联计算模型。
基金项目:
1.国家自然科学基金联合基金(项目编号:U1936111);
2.北京信息科技大学校基金项目(项目编号:5221910933)。
参考文献
[1] S. Babu, R. Motwani, K. Munagala, I. Nishizawa, and J. Widom:Adaptive ordering of pipelined stream filters. In SIGMOD04: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 407-418 ( 2004)
[2] Chris Olston , Jing Jiang , Jennifer Widom, Adaptive filters for continuous queries over distributed data streams, Proceedings of the 2003 ACM SIGMOD international conference on Management of data, June 09-12, 2003, San Diego, California
[3] A. Arasu, B. Babcock, S. Babu, M. Datar, K. Ito, I. Nishizawa, J. Rosenstein, J. Widom. STREAM: the stanford stream data manager, in: Proceedings of the SIGMOD, 2003, p. 665.
[4] H.-H. Lee, E.-W. Yun and W.-S. Lee, Attribute-based evaluation of multiple continuous queries for filtering incoming tuples of a data stream, Information Sciences 178 (11) (2008), pp. 2416–2432
[5] Moses Charikar , Kevin Chen , Martin Farach-Colton, Finding Frequent Items in Data Streams, Pro-ceedings of the 29th International Colloquium on Automata, Languages and Programming, p.693-703, July 08-13, 2002
[6] J. Feigenbaum , S. Kannan , M. Strauss , M. Viswanathan, An Approximate L1-Di?erence Algorithm for Massive Data Streams, Proceedings of the 40th Annual Symposium on Foundations of Computer Science, p.501, October 17-18, 1999
[7] Anna C. Gilbert , Yannis Kotidis , S. Muthukrishnan , Martin Strauss, Surfing Wavelets on Streams: One-Pass Summaries for Approximate Aggregate Queries, Proceedings of the 27th International Conference on Very Large Data Bases, p.79-88, September 11-14, 2001
[8] Zhen Liu , Srinivasan Parthasarathy , Anand Ranganathan , Hao Yang, Near-optimal algorithms for shared filter evaluation in data stream systems, Proceedings of the 2008 ACM SIGMOD international conference on Management of data (2008)
[9] D. Terry, D. Goldberg, D. Nichols, and B. Oki. Continuous queries over append-only databases. In Proc. of the 1992 ACM SIGMOD Intl. Conf. on Management of Data, pages321–330, June 1992.
[10] M. Altinel and M. J. Franklin. E?cient filtering of XML documents for selective dissemination of information. In Proc. of the 2000 Intl. Conf. on Very Large Data Bases,pages 53–64, Sept. 2000.
[11] Xml path language (XPath) version 1.0, Nov. 1999.W3C Recommendation available at http://www.w3.org/TR/xpath.
[12] B. Nguyen, S. Abiteboul, G. Cobena, andM. Preda.Monitoring XML data on the web. In Proc. of the 2001 ACM SIGMOD Intl. Conf. on Management of Data, pages437–448,May 2001.
[13] M. Sullivan. Tribeca: A stream databasemanager for network tra?c analysis. In Proc. of the 1996 Intl. Conf. on Very Large Data Bases, page 594, Sept. 1996.
[14] L. Liu, C. Pu, andW. Tang. Continual queries for internet scale event-driven information delivery. IEEE Trans. on Knowledge and Data Engineering, 11(4):583–590, Aug.1999.
[15] J. Chen, D. J. DeWitt, F. Tian, and Y. Wang. NiagraCQ: A scalable continuous query system for internet databases. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 379–390,May 2000.
[16] S. Babu and J. Widom:Continuous queries over data streams. SIGMODRec., vol. 30, no. 3, pp. 109–120, 2001.
[17] J. Hellerstein, M. Franklin, et al. Adaptive query processing: Technology in evolution. IEEE Data Engineering Bulletin, 23(2):7–18, June 2000.
[18] R. Avnur and J. Hellerstein. Eddies: Continuously adaptive query processing. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 261–272,May 2000.
[19] S. Madden andM. J. Franklin. Fjording the stream: An architecture for queries over streaming sensor data. In Proc. of the 2002 Intl. Conf. on Data Engineering, Feb. 2002. (To appear).
[20] D. Carney, U. Cetinternel, M. Cherniack, C. Convey, S. Lee, G. Seidman,M. Stonebraker,N. Tatbul, and S. Zdonik. Monitoring streams –a new class of dbms applications. Technical Report CS-02-01, Department of Computer Science, Brown University, Feb. 2002.
[21] P. Bonnet, J. Gehrke, P. Seshadri. Towards Sensor Database System. In Proc. Int. Conf. On Mobile Data Management, 2001, pages 3-14.
[22] Y. Zhu, D. Shasha. StatStream: Statistical Monitoring of Thousands of Data Streams in Real Time. In Proc. Int. Conf. On Very Large Data Bases, 2002, pp. 358-369.
[23] K. Munagala, U. Srivastava, and J. Widom.Optimization of continuous queries with shared expensive filters. In PODS07: Proceedings of the 26th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, pp. 215-224 (2007)
[24] A. Kemper, G. Moerkotte, and M. Steinbrunn. Optimizing boolean expressions in object-bases. In Proc. of the 1992 Intl. Conf. on Very Large Data Bases, pages 79–90, Aug. 1992.
[25] K. Ross. Conjunctive selection conditions in main memory. In Proc. of the 2002 ACM Symp. on Prin-ciples of Database Systems, June 2002.
[26] E. Cohen, A. Fiat, and H. Kaplan. E?cient sequences of trials. In Proc. of the 2003 Annual ACM-SIAM Symp. on Discrete Algorithms, Jan. 2003.
[27] U. Feige, L. Lov′asz, and P. Tetali. Approximating min-sum set cover. In Proc. of the 5th Intl. Workshop on Approximation Algorithms for Combinatorial Optimization (APPROX), Sept. 2002.
[28] K. Munagala, S. Babu, R. Motwani, and J. Widom. The pipelined set cover problem. Technical report, Stanford University Database Group, Oct. 2003. Available at http://dbpubs.stanford.edu/pub/2003-65.
[29] L. Raschid and S. Y. W. Su, “A parallel processing strategy for evaluating recursive queries,”in VLDB 86: Proceedings of the 12th International ConReferences ference on Very Large Data Bases, pp. 412–419, Morgan Kaufmann Publishers Inc., 1986.
[30] A. N. Wilschut and P. M. G. Apers, “Dataflow query execution in a parallel main-memory environ-ment,”in PDIS 91: Proceedings of the First International Conference on Parallel and Distributed Information Systems, Fontainebleu Hilton Resort, Miami Beach, FL, pp. 68–77, IEEE Computer Soci-ety, 1991.
[31] T. Urhan and M. J. Franklin, “XJoin: a reactively-scheduled pipelined join operator,”IEEE Data Engineering Bulletin, vol. 23, no. 2, pp. 27–33, 2000.
[32] Amol Deshpande , Zachary Ives , Vijayshankar Raman, Adaptive query processing, Foundations and Trends in Databases, v.1 n.1, p.1-140, January 2007
[33] Z. G. Ives, D. Florescu, M. Friedman, A. Levy, and D. S. Weld, “An adaptive query execution system for data integration,”in SIGMOD 99: Proceedings of the 1999 ACM SIGMOD international conference on Management of data, (New York, NY, USA), pp. 299–310, ACM Press, 1999.
[34] V. Raman, A. Deshpande, and J. M. Hellerstein, “Using state modules for adaptive query process-ing.,”in ICDE 03: Proceedings of the 19th International Conference on Data Engineering, Bangalore, India, pp. 353–364, 2003.
[35] S. Viglas, J. F. Naughton, and J. Burger, “Maximizing the output rate of multi-way join queries over streaming information sources,”in VLDB 03: Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany: Morgan Kaufmann, September 9–12 2003.
[36] R. Avnur and J. M. Hellerstein, “Eddies: continuously adaptive query processing,”in SIGMOD 00: Proceedings of the 2000 ACM SIGMOD international conference on Management of data, (New York, NY, USA), pp. 261–272, ACM Press, 2000.
[37] S. Babu and P. Bizarro, ”Adaptive query processing in the looking glass,” in CIDR 05: Second Biennial Conference on Innovative Data Systems Research, pp. 238-249, Asilomar, CA, 2005.
[38] N. Kabra and D. DeWitt. E?cient mid-query reoptimization of sub-optimal query execution plans. In Proc. of the 1998 ACM SIGMOD Intl. Conf. on Management of Data, pages 106–117, June 1998.
[39] R. Arpaci-Dusseau. Run-time adaptation in river[J]. ACM Trans. on Computer Systems, 21(1):36–86, 2003.
[40] J. Chen, D. DeWitt, F. Tian, and Y. Wang. NiagaraCQ: A scalable continuous query system for internet databases. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 379–390, May 2000.
[41] Z. Ives, D. Florescu, M. Friedman, A. Levy, and D. Weld. An adaptive query execution system for data integration. In Proc. of the 1999 ACM SIGMOD Intl. Conf. on Management of Data, pages 299–310, June 1999.
[42] [45] K. Ng, Z. Wang, R. Muntz, and S. Nittel. Dynamic query re-optimization. In Proc. of the 1999 Intl. Conf. on Scientific and Statistical Database Management, pages 264–273, July 1999.
[43] B. Dageville and M. Zait. SQL memory management in Oracle9i. In Proc. of the 2002 Intl. Conf. on Very Large Data Bases, pages 962–973, Aug. 2002.
[44] E. Wong and K. Youssefi. Decomposition - a strategy for query processing[J]. ACM Trans. on Database Systems, 1(3), 1976.
[45] A. Deshpande and J. Hellerstein. Lifting the burden of history from adpative query processing. In Proc. of the 2004 Intl. Conf. on Very Large Data Bases, Aug. 2004.
[46] S. Madden, M. Shah, J. Hellerstein, and V. Raman. Continuously adaptive continuous queries over streams. In Proc. of the 2002 ACM SIGMOD Intl. Conf. on Management of Data, pages 49–60, June 2002.
[47] V. Raman, A. Deshpande, and J. Hellerstein. Using state modules for adaptive query processing. In Proc. of the 2003 Intl. Conf. on Data Engineering, Mar. 2003.
[48] S. Babu, K. Munagala, J.Widom, and R. Motwani. Adaptive caching for continuous queries. In Proc. of the 2005 Intl. Conf. on Data Engineering, 2005. (To appear).
[49] S. Babu and J. Widom. StreaMon: An adaptive engine for stream query processing. In Proc. of the 2004 ACM SIGMOD Intl. Conf. on Management of Data, June 2004. Demonstration proposal.
[50] S. Christodoulakis. Implications of certain assumptions in database performance evaluation[J]. ACM Trans. on Database Systems, 9(2):163–186, 1984.
[51] 孟小峰, 周龍骧, 王珊. 数据库技术发展趋势[J]. 软件学报, 2004(12):74-88
作者简介:
李军(1983-),男,汉族, 山东滕州人,北京邮电大学,博士, 高级工程师,北京信息科技大学,教师;主要研究方向和关注领域:网络信息安全、数据挖掘。
于灵凡(1998-),女,汉族,北京信息科技大学,本科;主要研究方向和关注领域:网络流挖掘和管理。
田斌(1983-),男,汉族,北京邮电大学,博士,中国信息安全测评中心,高级工程师;主要研究方向和关注领域:网络空间安全。
李犇(1986-),男,汉族,山东济宁人,中国科学院大学,硕士,北京市公安局朝阳分局,副科级警察;主要研究方向和关注领域:网络空间安全。
李晔(1986-),男,汉族,河北保定人,北京邮电大学,硕士,河北移动网络管理中心,工程师;主要研究方向和关注领域:网络安全和管理。
康海燕(1971-),男,汉族,河北石家庄人,北京理工大学,博士,教授,北京信息科技大学,副院长;主要研究方向和关注领域:网络空间安全。
猜你喜欢
内燃机与配件(2022年2期)2022-01-17
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
科学与技术(2018年16期)2018-05-16
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30
发明与创新·大科技(2017年5期)2017-05-16
计算机应用(2016年10期)2017-05-12
科技创新与应用(2016年34期)2016-12-23
农机使用与维修(2016年10期)2016-11-10
农机使用与维修(2016年10期)2016-11-10
