
基于新型注意力机制的LSTM 光伏发电预测方法
2021-05-28 06:03陈晨王小杨梁建盈马武兴
现代计算机 2021年11期
陈晨,王小杨,梁建盈,马武兴
(1.电子科技大学中山学院,中山528402;2.湖南安华源电力科技有限公司,湘潭411100;3.水发兴业能源(珠海)有限公司,珠海519000)
0 引言
全球经济持续快速发展增加了电力需求,同时化石燃料的大量使用造成温室气体排放问题,进一步导致全球变暖和全球气候变化。光伏发电日益成为我国能源生产当中不可或缺的一部分,到2020 年底,太阳能发电装机将达到1.1 亿千瓦以上,其中光伏发电装机达1.05 亿千瓦以上。由于其受气象因素影响较大,光伏产能曲线波动较大,光伏电能并网时会对电网造成安全问题,光伏发电准确预测可以有效解决并网安全问题。许多学者针对该问题提出了解决方法,目前光伏发电预测方法概括起来有以下四大类[1](如图1 所示):
(1)物理模型:主要依据太阳能发电原理,结合太阳能电板的材料性能、太阳辐射量、辐射角度、温度等参数整理出一套公式进行计算。该方法在气象环境稳定时可以获得较好的预测精度,异常环境下的预测结果较差,文献[2-3]中提出了几种常用的物理模型方法。
(2)统计模型:使用统计学方法从大量历史数据中,分析出发电量与气象数据之间的关系,搭建统计学模型,实现对未来光伏发电量的预测。常见的统计学方法有多元回归方法[4-5]、主成分分析法[6]、自回归移动平均法[7]等。该类方法直接从大数据中分析发电量与气象数据直接的关系,忽略了光伏系统本身的参数对发电量的影响。
(3)机器学习模型:通过算法分析数据,从结果中进行学习,将“学习后的算法”用来做出决策或进行预测。文献[8]提出了新型前馈神经网络进行预测,文献[9]使用人工神经网络进行预测,文献[10]使用支持向量机的方法进行发电量预测等,该类方法需要大量历史数据对模型进行训练,再使用训练好的模型进行预测。
(4)混合模型:该类方法是将多种模型结合起来进行预测,发挥不同模型的优势,提高预测的精度。对于n 个预测模型m1,m2,…,mn组成的混合预测模型,可以表示为:

其中yt是t 时刻预测的结果,wit是t 时刻各个模型的权重,bt是t 时刻的偏移量。混合模型常见的方法有SARIMA+LSTM[11],文献[12]提出了时序数据预测方法ARIMA+LSTM,文献[13]提出了GAN+CNN 方法。
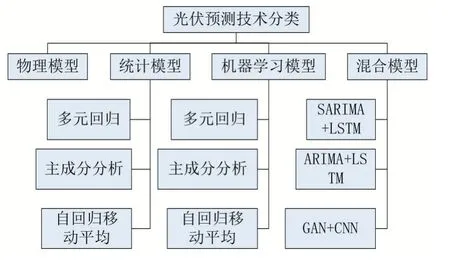
图1 光伏预测技术分类
后三类方法均需要在大量高质量的历史数据集中训练才能得到较好的模型,实际情况下我们很难获得较好的训练数据集,特别是对于光伏发电影响最大的气象因素——太阳辐射量历史数据难以获取,通常情况下较容易获取的气象数据只有温度、湿度、风速等。本文提出一种方法改善实际气象数据缺乏情况下的预测准确度,由于温度、湿度、风速与光伏发电量之间并不是简单的线性关系,不同时刻它们对于光伏发电量的影响因子是变化的,因此我们尝试使用注意力机制在不同时刻选择不同的气象因素的组合进行发电量预测,同时气象数据和发电量均是时序数据,一定时间段内的发电量具有连续性,使用循环神经网络进行训练可以获得较好的效果,LSTM 是一种时间循环神经网络,可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
1 理论基础
1.1 长短期记忆网络(LSTM)
LSTM 是一种常用的门控循环神经网络,可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。LSTM 引入了三个门,输入门、遗忘门、输出门以及隐藏状态形状的记忆细胞,遗忘门控制上一时间步的记忆细胞Ct-1的信息是否传递到当前时间步,输入门控制当前时间步的输入通过候选记忆细胞如何流入当前时间步的记忆细胞,输出门控制记忆细胞如何流入当前隐藏状态Ht,计算关系结构如图2 所示。
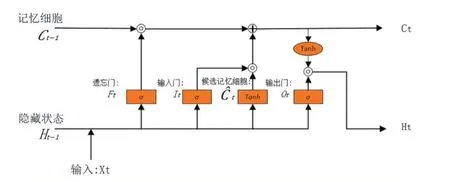
图2 LSTM计算关系结构图
假设隐藏单元有h 个,给定时间步t 的小批量输入Xt和上一时间步隐藏状态Ht-1,则:
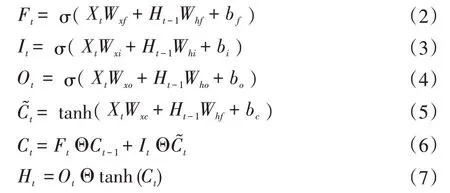
其中Wxf、Wxi、Wxo、Wxc、Whf、Whi、Who、Whf是权重参数,bf、bi、bo、bc是偏差参数,σ是激活函数,这里选择sigmoid 函数,Ht为隐藏状态矩阵。
1.2 传统注意力机制
注意力机制在很多任务中都已经成为序列建模和变换模型的不可或缺的一部分,也因此我们的序列依赖关系建模也就突破了输入和输出序列中距离的限制,在大部分任务中,注意力机制通常和递归神经网络联合起来使用。深度学习中的注意力机制从本质上讲是模拟人类大脑的选择性视觉注意力机制,目的是从众多信息中选择出对当前任务目标更关键的信息,注意力机制思想如图3 所示,它更多地关注输入序列中的关键部分,即可以从中更好地学习有用信息去影响输出结果,此外不会增加模型的计算与存储。注意力机制是一种通用加权池方法,其中输入由两部分组成:keys-values、query,attention 层可获取输出尺寸,针对每一个query,attention 层会计算每个key 的注意力比重并且归一化这些比重,输出结果是每个value 乘上其加权值的总和。
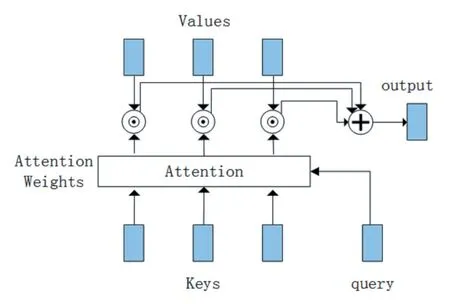
图3 注意力机制思想
注意力机制主要应用在LSTM 框架中的隐藏状态矩阵Hi={h1,h2,…,ht}生成过程中,重要计算公式如下:
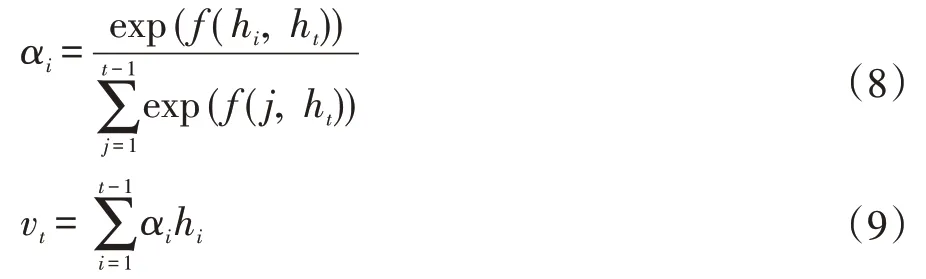
其中hi是第i 时间步的隐藏状态信息,vt上下文信息向量,最终可由vt、ht得到预测结果。
2 MVWM设计
由上述传统注意力机制的介绍可知,基于传统注意力机制的LSTM 方法对时序数据的预测是选择当前时间步的前一段时间步进行加权,这种设计方式存在一定的缺陷,特别是多变量时序数据的预测,因为每个时间步上都存在多个变量,上述加权方式下同一个时间步上的变量权重是相同的,但实际情况下,每个变量对后续时间步的预测影响程度并不同,而光伏发电量预测问题也具有这种特性,气象因素与发电量之间的关系如图4,从图中结果可知气温、湿度与发电量有较明显的正关系趋势、负关系趋势,下面使用皮尔逊相关性分析法对温度、湿度、风速与发电量的相关性进行分析。
Pearson 相关性系数(Pearson Correlation)是衡量向量相似度的一种方法。输出范围为-1 到+1,0 代表无相关性,负值为负相关,正值为正相关,计算公式如下:
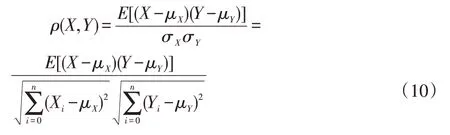
结果如图5,可以发现这些变量与发电量之间并无明显线性关系,不同时刻不同气象因素与发电量之间的相关性是动态变化的。

图4 温度、湿度、风速与发电量的关系图
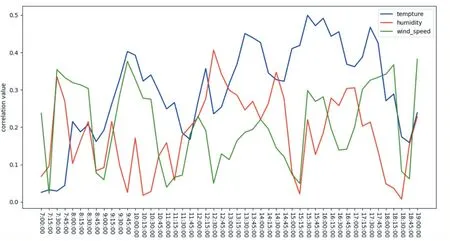
图5 不同时刻温度、湿度、风速与发电量的皮尔逊相关性
因此我们将使用新型注意力机制应用到LSTM中,其计算框架如图6,主要特点是同一时间步上不同变量使用不同加权系数做为网络输入,这里的不同变量实际上是指隐藏状态矩阵中的不同行向量,注意力加权系数计算公式如下:

其中是隐藏状态矩阵的第i 行向量,包含了第i 个变量的信息,w 是滑动窗口的宽度,αi是第i 个变量的加权系数。得到隐藏状态每行的权重αi之后,我们可以得到一个上下文向量vt,它包括多个时间步的信息,获取了时间维度信息。最后连接vt和ht生成,使用生成最终预测值。相关计算公式如下:

其中Wh、Wv、wh'为矩阵变换参数,通过样本训练确定其值,αi的计算方法显然不同于传统注意力机制中的方法,也最终影响我们的预测结果。
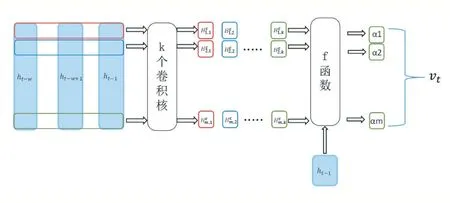
图6 新型注意力机制计算框架
3 实验与结果分析
3.1 实验数据
为了验证该方法的效果,提取了阳江地区光伏电站2019 年2 月1 日至2020 年3 月30 日的单个光伏阵列的气象数据与发电量数据,每条记录每隔15 分钟采集一次,采集时间段为7:00-19:00,共20774 条数据。列举简单的示例样本如表1。
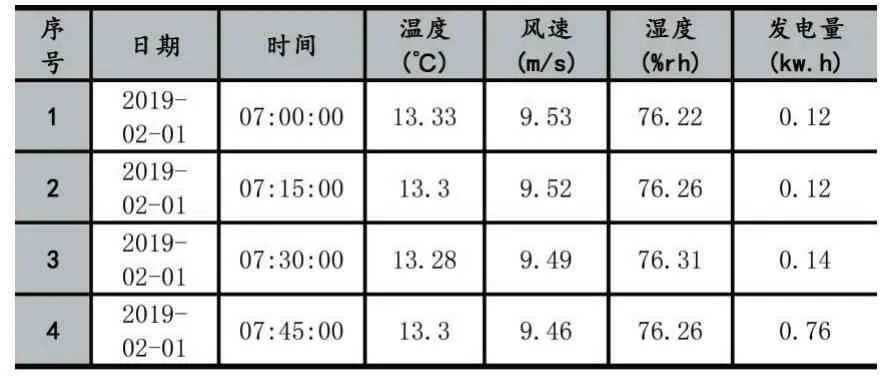
表1 实验示例样本
MVWM 网络参数设置如表2。
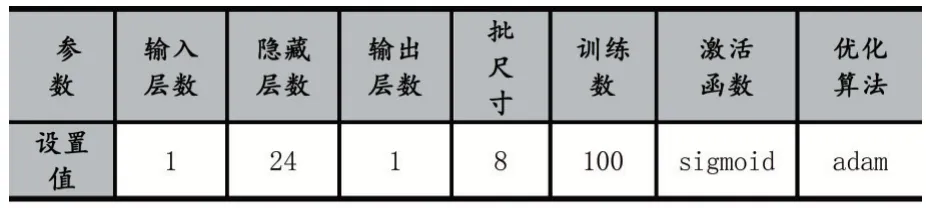
表2 网络模型参数
模型损失函数采用均方根误差函数(MSE),定义如下:

3.2 实验步骤
Step 1:训练集、测试集按照80%、20%的比例划分后分别是16620、4154 条数据。
Step 2:将训练集、测试集进行归一化处理,提高模型收敛速度。
Step 3:使用训练集训练我们的网络模型MVWM,得到模型的最终学习后的参数。
Step 4:利用学习后的模型进行预测,将测试集作为输入,得到预测值。
Step 5:将测试集的预测值与真实值对比,进行实验结果分析。
3.3 实验结果与分析
为验证MVWM 模型的有效性,我们在Ubuntu 深度学习平台搭建环境,使用Pytorch 深度学习框架,硬件为Intel Core i7-8750H CPU+2×NVIDIA 1080ti GPU,经过训练集学习后,在测试集进行预测,光伏发电实际值与预测结果对比如图7 所示,横坐标是连续的时间步,纵坐标是发电量值,紫色线条表示MVWM 模型的预测值,红色线条表示实际值,预测值与实际值平均误差5.362。
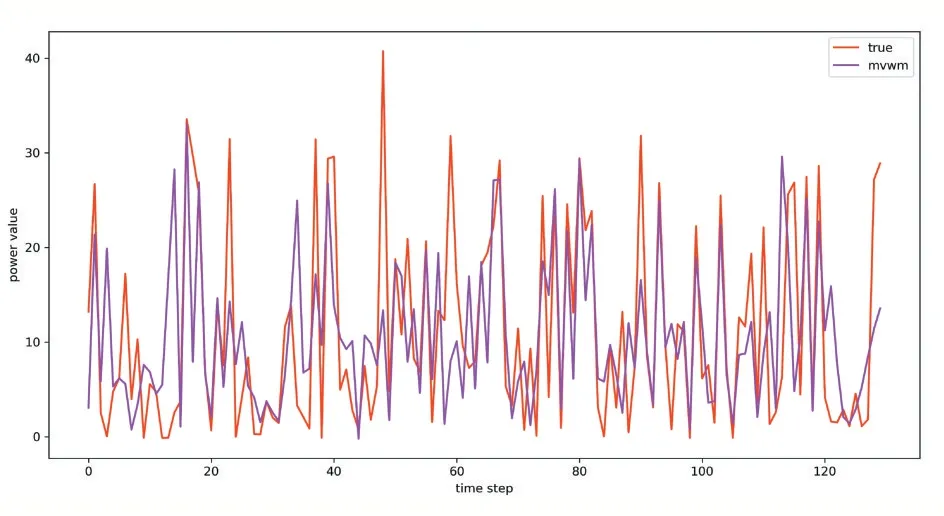
图7 MVWM模型预测结果
同时我们也将MVWM 模型预测结果与LSTM、SVM 线性回归模型进行对比,由于每种模型训练参数不同都会得到不同的预测果,这里我们选择每种模型最好的结果进行对比,结果如表3 多模型预测结果对比表示,列举了每种模型的误差值,误差值计算方法使用的是均方根误差、平均绝对误差,由表结果知,对于一般气象参数的太阳能发电预测,循环神经网络对于时序周期性的数据具有较好的预测结果,实际结果也验证了LSTM、MVWM 模型优于SVM 线性回归模型;添加新型注意力机制的MVWM 模型对比传统的LSTM模型,其性能有一定的提高。
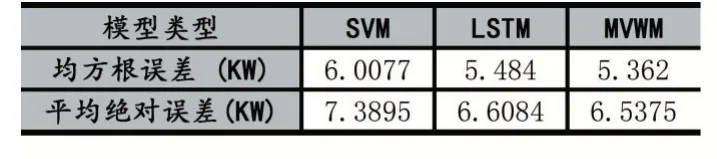
表3 多模型预测结果对比
4 结语
本文针对常规气象数据情况下的光伏发电短期预测问题,提出了一种基于注意力机制的多气象因素加权预测模型,模型的网络以LSTM 网络为基础,同时采用不同时间步对气象变量进行加权的方式实现注意力机制,最后我们在数据集上验证了该模型的效果,对比SVM 线性回归、LSTM 等方法有了进一步的提高。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
作文周刊·小学一年级版(2022年24期)2022-06-18
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
能源研究与信息(2021年1期)2021-11-15
金桥(2021年7期)2021-07-22
美文(2017年23期)2017-12-13
软件(2017年6期)2017-09-23
