
基于压缩域新时空特征的视频动作识别
2021-04-16 01:17江凯华江小平丁昊石鸿凌李成华
中南民族大学学报(自然科学版) 2021年2期
江凯华,江小平,丁昊,石鸿凌,李成华
(中南民族大学 电子信息工程学院 & 智能无线通信湖北省重点实验室,武汉 430074)
近年来,基于压缩域的深度学习方法在视频动作识别任务中表现出优异性能[1].这类方法降低了原始视频的冗杂信息且提高了动作识别任务的识别效率,并在光流的监督下获得良好的效果.随着压缩视频动作识别算法的不断改进,这类方法已从直接使用粗糙的运动矢量和残差,发展至以运动矢量模拟光流或以残差逼近原始图像.在基于压缩域的视频动作识别算法研究中,文献[1]率先提出基于压缩域的视频动作识别方法并取得良好的实验结果.该方法以像素域动作识别双流模型为基础,主要思路是利用压缩域特征替换像素域特征来完成模型的训练.该文以I帧、运动矢量和残差为独立特征的“三流”方法解释运动的思路启发了后续动作识别算法研究.受生成对抗性网络(GAN)和光流[2]的启发,文献[3]设计了一个小型生成对抗性网络来完成动作识别任务.该方法的主要思想是联合运动矢量和像素残差对光流进行模拟,借此达到以假乱真的效果.该方法虽然增强了压缩域视频动作识别网络的稳健性、差异性,但生成器和判别器的训练与光流的提取无意间增加了计算开销,且未能大幅提升动作的识别精度.尽管在外部光流的监督学习下压缩特征能提高动作识别的精度,但大幅增加的计算开销也不容小觑.在近期的研究中,文献[4]又提出了一种利用原始图像精炼运动矢量的方法,意在通过原始图像的监督删除不可靠的运动信息.实验结果显示,该方法并未有效地处理运动矢量的噪声,且其增大了网络的计算开销,对最终动作识别结果的改善并不明显.
为了更好地利用压缩域特征的基本特性——信息密度大、计算开销小,基于压缩域新时空特征的视频动作识别提出了一种融合运动特征(运动矢量)和颜色特征(残差)的新时空特征视频动作识别新方法.该方法首先过滤运动矢量与残差的干扰噪声(如背景、孤立值等)并充分提取其时间和空间信息;其次利用这两种高信息密度特征,生成压缩域背景下的新特征;最后分别将相关特征输入到2D卷积神经网络中完成视频中人物动作的识别.压缩域新时空特征去除了运动矢量和残差的噪声干扰,提高了运动目标的精度,使网络更专注于运动本身,因而对运动的对象表征更加明确.对比主流像素域视频动作识别方法,压缩域新时空特征方法在动作识别精度相当甚至略好的情况下,计算开销却远低于对方;对比其他基于深度学习的压缩域视频动作识别方法,压缩域新时空特征算法的动作识别精度有较为可观的提升,其网络训练却并不复杂.其优势在于:其一、将运动矢量和残差联合建模,更有效地利用编码后的运动和颜色信息[2];运动矢量具有信息密度大、运动目的表征明确等特点;其二、而残差通常与运动物体的边界很好地对齐,这比其他位置的运动更重要;其三、对运动矢量和残差进行传统的压缩域预处理,去除无关背景噪声、偶然时间噪声,进一步增加其信息密度;其四、运动特征从时间维度上解释运动,颜色特征从空间维度上解释运动.具体细节将在下文详细展开.基于新时空特征的压缩域视频动作识别创新之处在于:在基于压缩视频的动作识别背景下,提出利用压缩域运动矢量和残差生成新时空特征的方法.该特征融合运动矢量和像素残差的特点,有利于完成动作识别任务,并抵抗外部环境的干扰攻击.该特征辨识度高、噪声低,既包含了运动矢量表征运动明确和残差目标轮廓清晰的优势,又减少了两者的不利之处.
1 相关工作
1.1 压缩编码
在视频编码中,当前图像的每个像素块在之前已编码图像中寻找一个最佳匹配块的过程称为运动估计,它是减少视频序列冗余信息的有效方法[5].其中用于预测的图像称之为参考图像,参考块到当前像素块的位移称为运动矢量(motion vector, MV),其表示当前编码块与其参考图像中的最佳匹配块之间的相对位移,当前像素块与参考块的差值称为残差(Residual).在压缩视频的过程中, 运动矢量是以一个16×16像素的区域宏块为单位,是MPEG-4编解码的基本单位.大多数现代编解码器将视频分为I帧(参考帧)、P帧(预测帧).I帧是常规RGB图像,P帧是残差帧且仅对运动矢量和残差进行编码.
1.2 压缩域视频动作识别
在以往的视频动作识别任务中,绝大多数基于RGB图像方法既有优势也有其劣势.首先,视频的信息密度非常低.一个分辨率为720p、时长为1 h的视频可以从222 GB压缩到1 GB.这些冗余信息使得CNNs很难提取有意义的信息,从而使其训练速度降低.其次,仅针对RGB图像的学习时间结构比较困难[1].在文献[1]中,作者提出一种减少使用原始帧的动作识别办法,其主要思路是使用压缩视频中I帧、运动矢量和残差将识别网络单独训练.但是该方法无法达到与双流方法接近的识别精度,主要原因在于运动矢量的分辨率较低;其次,运动矢量和残差虽然高度相关,但都是由独立的网络来处理的.文献[3]提出一种模拟光流的方法,虽然提高了识别精度,但是也增加了独立网络的分支数(从文献[1]的3-stream到4-stream).
2 新时空特征图像的生成
基于新时空特征的压缩域视频动作识别框架如图1所示.该框架主要包括3个模块: 基于2D卷积神经网络的新时空特征视频人物动作识别、基于2D卷积神经网络的I帧视频人物动作识别和基于2D卷积神经网络的运动矢量视频人物动作识别.首先,提取压缩视频特征——I帧信息、P帧信息;其次,利用P帧信息提取出运动矢量和残差且生成新时空特征;最后,通过2D卷积神经网络模型完成视频人物动作的识别.

图1 主体流程图
生成新时空特征的过程如图2所示.首先提取P帧中的运动矢量和残差信息,参考文献[1]分别对其进行累积操作;再对运动矢量进行时间和空间滤波处理,进一步提取其时间和空间信息;同时对残差进行灰度化处理,以减少无关噪声并提高其空间信息密度.

图2 新时空特征生成流程图
关于生成的更多细节参考下文2.5节.由于压缩域新时空特征具有高动作辨识度的运动表征,本方法合理地利用了压缩视频的特征,从而使得其更容易被捕获.
2.1 新时空特征的结构
对于传入的P帧流,首先利用FFmpeg分离运动矢量和残差,再对二者进行预处理,然后将处理后的运动矢量和灰度残差以通道组合的方式合并成新时空特征.其中预处理过程包含有对运动矢量的累积、空间和时间滤波等步骤,残差的预处理过程包含有残差累积、灰度化等步骤.其中运动矢量和残差累积的过程参考于文献[1].对运动矢量和残差进行预处理可以降低其不可靠部分[6],使动作部分的特征更具辨识度,进一步增加其信息密度.
2.2 运动矢量空间滤波
运动矢量流充满噪声和干扰,如孤立干扰块、背景干扰块等[7],利用运动矢量的空间一致性可以减少这些干扰噪声.对于运动目标,通常有一块连接的非零运动矢量区域和一个相对较大的运动矢量数值,因此:
(1)如果运动矢量具有孤立的非零块或者小型运动矢量块,则将其定义为噪声块;
(2)当前运动矢量等于(0,0)或(1,1)等微小模值时,则将其定义为背景块;
(3)当前运动矢量的空间相邻运动矢量超过半数等于(0,0)或(1,1)等微小模值时,也将当前运动矢量定义为孤立块;
(4)最后,将这一步骤所产生的噪声块、背景块和孤立块所相关的运动矢量都设定为干扰噪声.
对于噪声块、背景块和孤立块,将其对应的运动矢量清零;对于其他的运动矢量,先给予保留.
2.3 运动矢量时间滤波
在压缩域中前后帧中的运动物体相对于当前帧具有位移,因而相邻帧的相同位置块可能导致与运动物体边界相邻的少量运动矢量噪声残留[8],使原始的运动矢量变得嘈杂.如果原始运动矢量和其大部分相邻块的运动矢量模值为零,那么当前运动矢量是空间背景的概率极高.基于运动矢量的空间紧凑性和时间连续性,则有:
(1)如果NumNonMV(NumNonMV表示为当前运动矢量的空间邻域内非零运动矢量的数量)小于阈值ε,估计该运动矢量的空间紧凑性状态难以满足并将其标记为噪声块;
(2)检查在前两帧中对应位置中的运动矢量是否为零矢量;如果其中一个运动矢量是零矢量,假设时间连续性条件不满足.一旦运动矢量不满足空间紧凑型条件或时间连续性条件,则这些运动矢量将被标记为噪声块.
对于噪声块,将其对应的运动矢量清零;对于非噪声块,先给予保留.
将压缩域运动矢量预处理加入到深度学习网络模型中的目的,在于增加运动矢量的时间一致性、空间紧凑性,减少运动矢量无关噪声,使运动矢量更能有序地表征运动目标.毋庸置疑,这些预处理方法的有效性已经在实际应用中得到充分地证明.
2.4 累积残差的灰度化
像素残差的信息量并不完全低于I帧图像,且相对于处理复杂的RGB图像,网络处理灰度图更加简洁.因此图像的灰度化处理有利于减少网络的计算量.灰度化后的图像将由三通道信息变为单通道信息.残差累积的过程去除了部分干扰噪声,但是保留了运动目标的边缘轮廓信息,如图3所示,残差图像被最大值灰度化后有利于模型对于该“Hammer Throw”(单目标运动)动作的判断.

图3 单目标运动“Hammer Throw”对比图
类似于人体骨骼处理方法[9-10]可应用于运动捕获以及动作识别与分析等领域,灰度化图像因为运动目标的本质特征没有发生变化,其轮廓信息没有改变,也可用于视频动作识别且不会增加其难度.正如电视机产业发展初期,人们只能通过黑白电视机获取感兴趣的信息,虽然灰度图像没有色彩,却并没有阻碍电视媒体信息的传播,且其传递的信息也并非不准确.
2.5 新时空特征的生成
残差灰度化的目的在于降低残差的维度,即尽可能地保存残差的有效信息且去除对于动作本身影响不是特别大的颜色信息.但对于计算视觉任务而言,灰度化图像只能适用于物体与背景有较强对比的情况,或者说背景或物体的灰度比较单一.对于复杂的前景目标,单纯的灰度图像则不能完全驾驭,这也是灰度图像没有完全应用于视频动作识别任务的原因之一.
从时间关系上来看,残差由于在累积的过程中层层叠加,导致残差原本微弱表示的动作轮廓逐渐明朗、运动特征愈发突出.在运动矢量时间滤波中,既强调了它的时间连续一致性,又根据前两帧中运动矢量有效地去除了当前帧中的部分时间干扰噪声.
从空间关系上来看,运动矢量空间滤波则是减去了运动矢量的大量空间干扰噪声,突出了运动前景,弱化了背景,使得运动矢量更有效地表述了运动目标的本体.
尽管有一些文章阐明图像灰度化后可以进行计算机视觉任务[11],但在动作识别方向上,并没有找到直接融合灰度残差和运动矢量两种特征的方法.于是提出新时空特征融合方法,将单通道的灰度残差图与双通道的运动矢量图融合叠加成新的三通道时空特征图像,如公式(1)所示:
NewF∈RH×W×3=MV∈RH×W×2⊕GR∈RH×W×1.
(1)
在公式(1)中,NewF表示为新时空特征,其大小为H×W×3;MV表示为处理后的运动矢量流,其大小为H×W×2;GR表示为灰度化后的累积残差流,其大小为H×W×1;其中H表示高度,W表示宽度,1表示其为单通道,2表示其为双通道,3表示其为三通道.
新时空特征图像既融合运动矢量的时间关系,又兼顾残差和运动矢量的空间关系,满足动作识别所需要的时空性要求,且其具有原始像素无法表达的效果.这是因为首先预处理减少了大量的无关背景噪声,保护了网络对于新时空特征的有效识别;其次,新时空特征减少了颜色信息的干扰,回归了动作发生的本质——矢量位移;最后,在没有花费较大计算代价的情况下,新时空特征获得压缩域特征的良好时空关系,如图4所示.

图4 多目标运动“Horse Race”对比图
在上述图中,运动矢量特征图表示运动的大概区域和剧烈程度,灰度残差图清晰地表示出运动边缘轮廓,而结合两者优势的新时空特征则充分表达运动的显著性区域和动作的清晰轮廓,极大地有利于网络对动作的识别和判断.
3 实验过程及结果
实验使用的数据集来源于经典视频动作识别数据集:UCF-101与 HMDB51.UCF-101包含来自101个动作类别的13320个视频;HMDB-51包含来自51个动作类别的6766个视频.这两个数据集都被分成3个split(每个split有其对应的训练集、测试集)进行实验,本实验通过计算同一数据集 3 次实验准确率的平均值作为最终的实验结果.
3.1 实验设计
使用MPEG-4视频编解码标准,每一个视频被分为若干个GOP(Group of Picture),每一组GOP中包含有1个I-frame和11个P-frames,且所有的视频都被重新定义为340×256大小.网络模型运行在基于Ubuntu16.04 desktop的普通机柜式服务器,其包含的显卡为英伟达RTX 2080Ti.在训练的过程中,参考了CoViAR1的模型,对I-frame使用Resnet152网络,对新时空特征和运动矢量使用Resnet18网络.首先,预处理过程的加入对运动矢量在时间和空间关系上进行改善——弱化背景、突出前景;其次运动矢量和残差累积操作——去除孤立、边缘噪声;在预处理结束后,生成新时空特征;最后将处理后的运动矢量和新时空特征送入2D卷积神经网络训练.其中,压缩视频及其数据的处理基于FFmpeg平台.根据文献[1]中的结论,将丢失率设置为0.85,初始的学习率设置为0.01,batch-size设置为40,在迭代510次后停止训练.
大部分视频动作识别文献[1,2,4,12]均将视频级预测作为25帧图像预测的平均值(在视频中均匀采样25帧).每一测试帧图像中均有5次裁剪和1次翻转,即在网络模型一测试帧图像都有10种预测结果,这是底层网络[13,14]设计的结果.最后使用后端融合方法得出最终预测结果.
3.2 实验结果
在融合新时空特征、运动矢量和I帧的结果后与文献[1]提出的CoViAR(Compressed Video Action Recognition)方法、文献[3]提出的DMC-Net(Discriminative Motion Cues Net)、文献[4]提出的Refined MV(Refined Motion Vector)、文献[8]提出的TSN(Two-stream + Flow)、文献[15]提出的C3D(3D convolutional neural networks)、文献[16]提出的Res3D等多种方法进行对比.表1给出了不同方法计算的复杂度和数据集HMDB-51精度对比,其中GFLOPs越大则网络的计算复杂度越大,Our则是指融合I-frame、MV和New Spatiotemporal Feature的结果.因为DMC-Net用到了光流和GAN网络,所以其在实际训练网络过程中的GFLOPs将会远远大于其他方法.表2给出了不同方法在数据集HMDB-51和UCF-101精度对比.从表1和表2看出在网络模型相同的情况下,本方法的精度高于CoViAR的精度;虽然精度略低于DMC generator,但其模型的计算复杂度仅是DMC generator的0.1362倍.与主流的3D卷积神经网络算法模型C3D[15]、R3D[16]相比,本文的算法模型计算开销远远小于它们,更有效,如图5所示.

图5 部分视频中动作识别正确案例
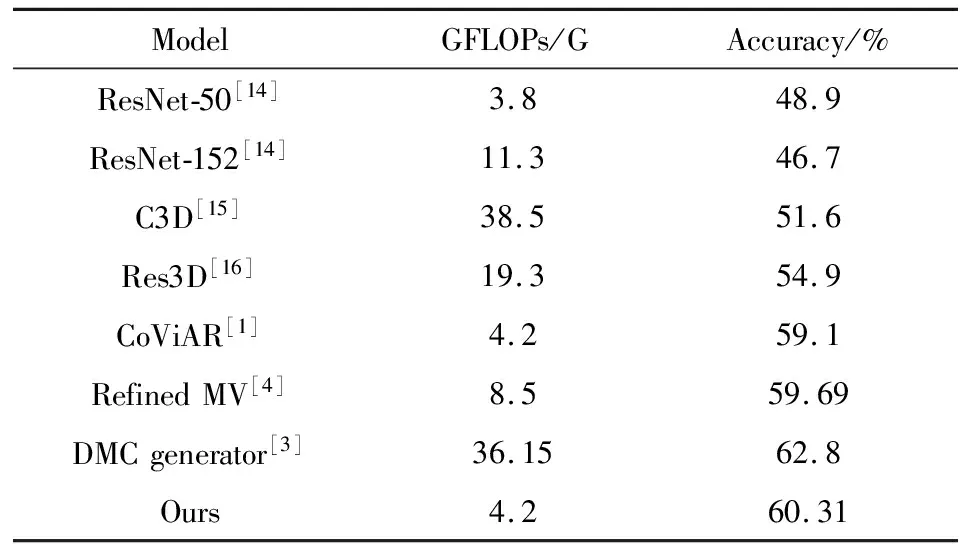
表1 不同方法计算的复杂度和HMDB-51的精度对比
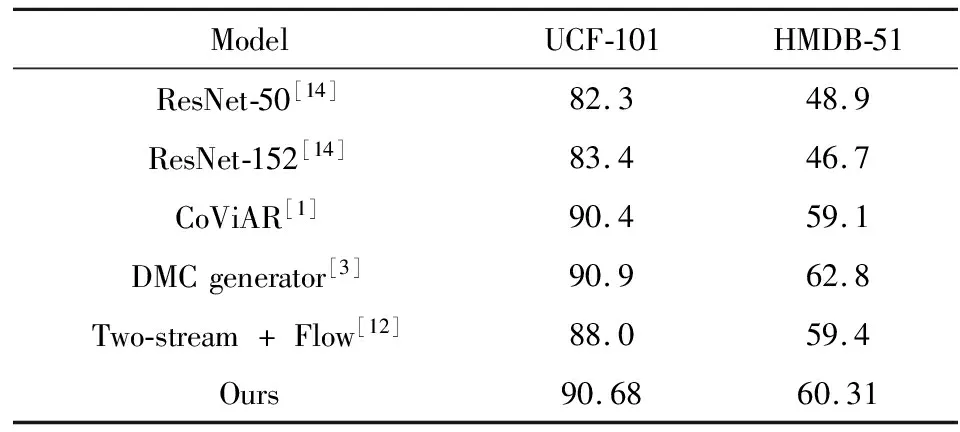
表2 数据集UCF-101和HMDB-51的精度对比
表3和表4为不同的特征方法在数据集HMDB-51和UCF-101上的识别效果.在表3和表4中,COVIAR MV 和COVIAR Residual 是文献[1]的特征在Resnet18网络模型的实验结果,Refined MV 是文献[4]在Resnet152网络模型的实验结果,Our MV指的是预处理后的运动矢量在Resnet18网络模型的实验结果,Our Feature指的是新时空特征的测试结果.如表3、4所示本方法比其他方法更优.

表3 数据集HMDB-51的精度

表4 数据集UCF-101的精度
4 结语
文中提出了一种基于新时空特征的压缩域视频动作识别方法来完成动作识别任务.该方法利用预处理好的压缩域特征来生成更有效的新时空特征,并利用2D卷积神经网络完成视频人物动作的识别.实验表明新时空特征能够有效继承运动矢量和残差的时间与空间相关性,更有利于识别视频中人物的动作.本文的方法也存在不足之处,如使用MPEG4并非是最先进的新一代编解码标准;在后端融合时,依旧采用绝大多数同类文章的方法——固定比例值融合,这对于所有的测试视频来说不一定是完美比例.接下来的改进中,笔者将采用新一代视频编解码标准并考虑更妥善地后端融合方法.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
天津医科大学学报(2021年1期)2021-01-26
北京航空航天大学学报(2020年10期)2020-11-14
中国信息技术教育(2020年2期)2020-02-02
北京航空航天大学学报(2019年9期)2019-10-26
航空世界(2018年12期)2018-07-16
