
UAV navigation in high dynamic environments:A deep reinforcement learning approach
2021-04-06 10:25TongGUONnJIANGBiyueLIXiZHUWANGWenboDU
CHINESE JOURNAL OF AERONAUTICS 2021年2期
Tong GUO,Nn JIANG,Biyue LI,Xi ZHU,Y WANG,Wenbo DU
a School of Electronic and Information Engineering, Beihang University, Beijing 100083, China
b Key Laboratory of Advanced Technology of Near Space Information System (Beihang University), Ministry of Industry and Information Technology of China, Beijing 100083, China
c Research Institute of Frontier Science, Beihang University, Beijing 100083, China
d College of Software, Beihang University, Beijing 100083, China
e State Key Laboratory of Software Development Environment, Beihang University, Beijing 100083, China
KEYWORDS Autonomous vehicles;Deep learning;Motion planning;Navigation;Reinforcement learning;Unmanned Aerial Vehicle(UAV)
Abstract Unmanned Aerial Vehicle (UAV) navigation is aimed at guiding a UAV to the desired destinations along a collision-free and efficient path without human interventions, and it plays a crucial role in autonomous missions in harsh environments.The recently emerging Deep Reinforcement Learning (DRL) methods have shown promise for addressing the UAV navigation problem,but most of these methods cannot converge due to the massive amounts of interactive data when a UAV is navigating in high dynamic environments,where there are numerous obstacles moving fast.In this work,we propose an improved DRL-based method to tackle these fundamental limitations.To be specific, we develop a distributed DRL framework to decompose the UAV navigation task into two simpler sub-tasks,each of which is solved through the designed Long Short-Term Memory(LSTM) based DRL network by using only part of the interactive data. Furthermore, a clipped DRL loss function is proposed to closely stack the two sub-solutions into one integral for the UAV navigation problem.Extensive simulation results are provided to corroborate the superiority of the proposed method in terms of the convergence and effectiveness compared with those of the state-of-the-art DRL methods.
1. Introduction
Over the past few years, Unmanned Aerial Vehicles (UAVs)have shown promise for a wide range of practical applications1–9, such as disaster rescue3, wildlife protection4and remote surveillance. In most of the practical application scenarios,to ensure the completion of different tasks,UAV must safely navigate among various locations to perform specific tasks.Therefore,a reliable and efficient navigation system is of great importance to UAV applications, which has attracted wide interest in the research of UAV navigation in various scenarios.
Many studies10–15concentrate on UAV navigation in completely known and static environments. For example, Duchonˇ et al.13extracted a grid map for a static indoor room and applied an improved A* algorithm to plan the path. Lindemann and LaValle14constructed a Voronoi diagram for a large-scale airspace and implemented the rapid-exploration random tree to search for an available path for the UAV.Hu and Yang15formulated a precise mathematical formula for obstacles and many specific constraints, and UAV navigation was addressed using the genetic algorithm. Regardless of the promising speeds of the above methods,these methods are restricted in practice since we can hardly acquire specific complete information about the UAV environment to formulate a rigorous graph or model.
Some methods16–20resort to Simultaneously Localization and Mapping(SLAM)to realize UAV navigation in unknown and static environments. For instance, Wen et al.16used an RGB-D (Red, Green and Blue-Depth) camera to construct a map of an indoor scenario, and a greedy-search algorithm is implemented to find a path. Mu et al.17applied laser radars to construct a point cloud graph for a cluttered room and navigated robots by using the probabilistic roadmap. However,SLAM fails when there are dynamic obstacles in real-world scenarios because those mobile obstacles require a continuous mapping process, which leads to unaffordable computation costs.
Some other studies21–24utilized Reinforcement Learning(RL) to navigate UAVs in unknown and dynamic environments. However, when we consider navigating UAVs in practical environments, there is a commonly known ‘dimension curse’ for RL, which prevents it from being further applied.With the recent emergence of deep learning techniques, some approaches25–30combining RL with deep neural networks have been proven to be efficient for navigation problems. Tai and Liu27first developed a model-free Deep Reinforcement Learning (DRL) algorithm based on the convolutional neural network that allows a car to navigate in a static indoor room.Loquercio et al.28trained an artificial neural network using human demonstrations to navigate UAVs in urban areas at higher altitudes, which contains sparse dynamic obstacles.Zhu et al.29input both the first-person view and image of a target object to the Asynchronous Advantage Actor-Critic(A3C)model to formulate a target-driven navigation problem in a low dynamic and relatively simple indoor room.Most of these approaches have not considered high dynamic environments where numerous obstacles are randomly drifting with a high speed.However,this scenario is commonly existing in practice,for example, many dynamic obstacles, such as humans and cars, will disturb UAVs when they are flying at low altitudes.
Challenges arise when we consider navigation problems in high dynamic environments. Numerous drifting obstacles will lead to massive amounts of interactive data, making it extremely difficult to train an integral (end-to-end) neural network using DRL.31–34To be specific, firstly, the frequent collision with the high dynamic obstacles causes lots of unsuccessful episodes and negative rewards in the initial training process,which will offer only few of positive episodes for DRL to learn the desired policy. This sparse rewards problem burdens the convergence of the neural network and prevents the agent from exploring the environment to accumulate rewards.31Secondly, to achieve the collision avoidance objective in the high dynamic environments,it is essential for the agent to predict the movement and position of the drifting obstacles which is a spatial–temporal prediction task.Linearly stacking several obstacles states into one for predicting their position35–37may be oversimplified for this task, and some researches38,39have extended DRL approaches by leveraging the Recurrent Neural Network (RNN). In spite of the improvements from RNN,these approaches are offline learning algorithm, which only update their parameters at the end of an episode,contributing to insufficient exploration of the environment and lower computational efficiency. Last but not least, UAVs navigation is a multi-objective problem that is composed of obstacle avoidance and target acquirement which has been proved non-trivial for DRL approaches32. Despite some of the inspirations from hierarchical learning methods34that divide the multi-objective problem into several simpler sub-objective problems and fuse them based on a prior regulation,they cannot be appliable directly since the fusion regulation may be varying in the dynamic uncertain environment.
To mitigate these challenges,we propose an improved DRL approach named Layered-RQN to enable UAVs to implement autonomous and robust navigation in high dynamic environments. The main contributions are as follows:
(1) We propose a distributed DRL framework containing two sub-networks, namely the Avoid Network and the Acquire Network,which are trained to address collision avoidance and target acquirement respectively by rewarding the UAV to steer away from obstacles and approach the target. We learn from the prior works39to design the sub-networks structure but extend it to an online manner, which is proven more efficient for learning from the dynamic environment to update the parameters in real time. Compared to an end-to-end neural network, each of the sub-networks has better convergence due to the availability of denser positive rewards. Moreover, it can capture more information from the movement of the drifting obstacles to enhance the security of UAV by leveraging the power of Long Short-Term Memory (LSTM).
(2) We develop a clipped DRL loss function to stack the sub-networks into one integral, whose objective is to choose a specific action from the Avoid Network and the Acquire Network to accumulate the positive rewards.Instead of a fixed fusion regulation that is prior to the mission, it is derived from UAV’s exploration in the environment, and thus it is more adapted to the uncertain and dynamic environment.
(3) We construct a UAV mission platform to simulate the high dynamic airspace for training and validating the effectiveness and robustness of the proposed approach.Simulations demonstrate that Layered-RQN has good convergence properties and outperforms some of the state-of-the-art DRL methods. Extensive experiment also indicates that Layered-RQN can be generalized into higher dynamic situations.
The remainder of this manuscript is structured as follows.Section 2 formulates the UAV navigation problem. Section 3 demonstrates the proposed method.The simulation results and discussion are presented in Section 4 and Section 5, respectively. Section 6 concludes this paper and envisages some future work.
2. Problem formulation
In this section,we construct a mathematical description for the UAV navigation problem and show how to establish this problem as a Markov Decision Process (MDP), which can be efficiently solved by DRL methods.
2.1. Scenario description
We consider the heterogeneous scenario containing obstacles with various velocity levels, where the UAV is planning its path at a fixed altitude.As illustrated in Fig.1,the red,orange and yellow circles are the dynamic obstacles with the highest,the moderate and the lowest velocities,respectively,which represent different entities in practical environment such as birds,human and the other UAVs.The dynamic obstacles randomly drift in the airspace at a prescribed velocity,and the goal of the UAV navigation problem is to find a feasible path from the origin to the target through the cluttered obstacles, which should be collision-free and as short as possible. During this process,dtargetand dminare expected to be minimized and maximized respectively.


2.2. Kinematics of UAV

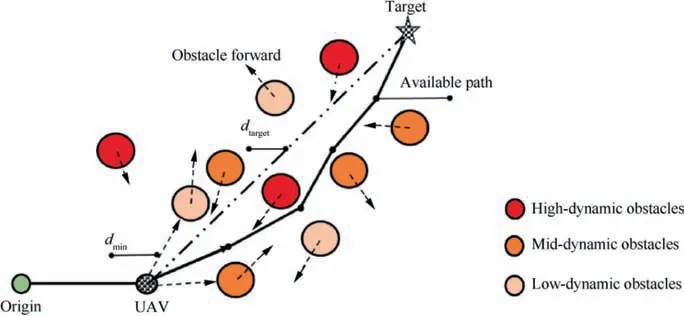
Fig. 1 Scenario description: Many dynamic obstacles with various velocities that randomly drift in heterogeneous airspace.
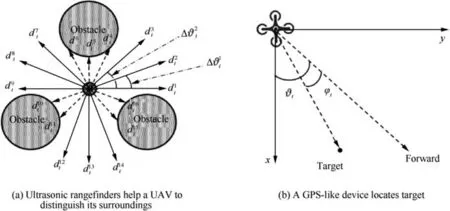
Fig. 2 Sensor data and kinematics of UAV.

In addition,the decision-making process can be easily realized by implementing a greedy-policy at=argmaxatQ
3. Methodology
In this section,we develop a novel DRL framework to address the UAV navigation problem. An overview of the proposed Layered-RQN is demonstrated in Fig. 3 and Fig. 4, where the UAV navigation problem is decomposed into two simper problems,and each of subproblem is addressed by feeding historical trajectories into the designed DRL network and updating the parameters to minimize the Temporal-Difference(TD)-error.
3.1. Distributed structure and designed DRL network
In the navigation task, DRL guides the UAV to avoid a collision or acquire a target based on the collected sensor data,such as the distances to obstacles, the direction to the target,etc. The UAV navigation task is considered to be a complex behavior that can be divided into three simpler behaviors:avoid obstacles, acquire targets and choose a specific action.The first prevents the UAV from experiencing a collision, the second drives the UAV to the target and the last chooses an action from avoid or acquire. In this regard, solving the UAV navigation problem can be transformed into solving avoid, acquire and choose problems, and then combing the solutions. Each of the problems can be addressed by a DRL network.Here,we present the designed DRL network to solve the avoid and acquire problems, and the choose problems is addressed in the Section 3.2.
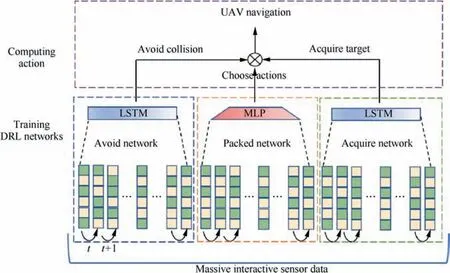
Fig. 3 Distributed structure of proposed Layered-RQN.
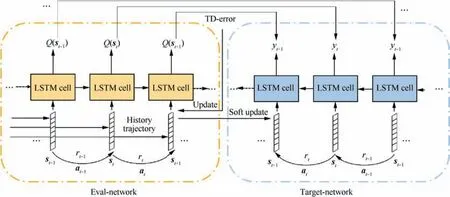
Fig. 4 Illustration of designed DRL network.


3.2. Clipped DRL loss function in packed network
To solve the choose problem, a clipped DRL loss function is used to stack the three DRL networks into one model to guide the UAV to efficiently and safely explore the environment.Additionally, the reward of Avoid Network and Acquire Network need to be shaped.
The Avoid Network is formulated to instruct the UAV to avoid obstacles in the navigation task. Rewards should be informative to prevent the UAV from colliding. The closer the UAV is to obstacles, the smaller the rewards are:

where α, β are constants,and dmincan be acquired by comparing the rangefinder readings in various directions.
The Acquire Network is established to instruct the UAV to acquire the target in the navigation task. When approaching the target from the right direction,the farther the UAV is from target, the smaller rewards are:

The Packed Network is formulated to select an action from the Avoid Network or Acquire Network for the UAV to take.Concentrating on avoiding collisions instead of approaching the target in cluttered surroundings will reduce the probability of failure. Thus, the UAV hopes to avoid obstacles when they are densely packed and quickly approach the target if it is navigating in open airspace. In this way, we justify the UAV’s‘choose behavior’by observing its state after choosing a specific action(acquire or avoid).If a collision happens,the choose action will be punished. The lagging rewards are:

The proposed algorithm is demonstrated in Table 1, where a target-network, eval-network and an experience replay buffer are used to stabilize the training process.
4. Experiments
In this section, we first present the experimental settings, and then,we show the effectiveness and robustness of the proposed model.Some presented comparisons demonstrate that the proposed model outperforms the state-of-the-art method in addressing the UAV navigation problem.

Table 1 Algorithm: Layered-RQN.
4.1. Experimental settings
To simulate a scenario with dense and high dynamic obstacles,we set up a visualized canvas with a total size of 500×500 pixels, where each pixel represents 1 m, and it varies with the frames. The UAV covers 5 pixels per frame and a dynamic obstacle with a radius of 1 pixel(probably represents a person or another UAV) covers several times more pixels than the UAV in one frame.
The hyper-parameters in the model are tuned through a series of repetitive experiments and we deploy the model with the optimal hyper-parameters.
As for the LSTM settings,the UAV sensor data are vectors with 18 dimensions.LSTM has 2 layers where the size is 8100,the number of LSTM cells is 120, and the output layer has 16 units that represent 16 directions of UAV actions.The learning rates for the Avoid Network, Acquire Network and Packed Network are 0.001, 0.001, and 0.0001, respectively. The soft update ratio is set to 0.95.
For rewards, we validate the hyper-parameters and set α=4,β=2;ρ=2,σ=2;ζ=0.5;τ=3.
The discount factor is γ=0.99, the selection probability is ε=0.3 and the decay is e-3ε. The longest length of the historical trajectories is limited to 40, and the Adam optimizer is employed to learn all the network parameters.
Experiments use a single Nvidia GTX 1080 Ti using CuDNN and a fully optimized version of Caffe.
4.2. Evaluation indicators for UAV navigation
To measure the quality of UAV navigation, we design some quantitative evaluation indicators, which represent the security,effectiveness and robustness of the navigation model.The details are as follows.
(1) Collision Number(CN).CN represents the total number of UAV collisions. The smaller the CN is, the safer the corresponding algorithm is.
(2) Path Length (PL). PL is the total path length from the origin to the target.The smaller the PL is,the more efficient the algorithm is.
(3) Success Rate (SR). Suppose that the experiment is repeated N times and N0of the repetitions successfully navigate the UAV from the origin to the target without a collision. SR is computed as

(4) Mutation Number (MN). MN reflects the deflection angle of the UAV between two times. The larger the MN is, the more likely it is that the UAV will crash.
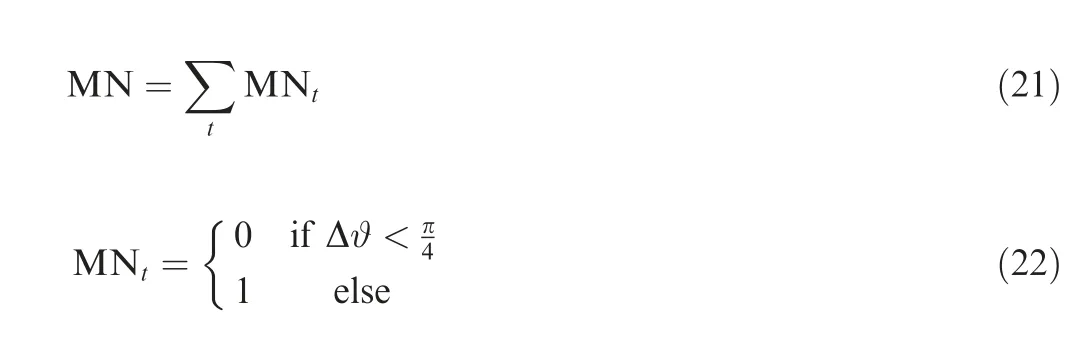
4.3. Baselines
To demonstrate the effectiveness of the proposed method,reasonable comparative experiments are necessary. Therefore, we report some of the state-of-the-art DRL-based controller as baselines.
(1) DQN35. DQN first extends RL to DRL and performs excellent at playing Atari games.
(2) Prioritized DQN(DPQN)36.An improved version of the DQN,which selects samples using priority sampling and has been proved to be more efficient than the DQN.
(3) DDQN37.An improved version of the DQN, which has a more stable training process.
(4) DRQN38.An LSTM version of the DQN,which is more capable of capturing dynamic features.
4.4. Experiment I: Convergence of Layered-RQN
To validate that Layered-RQN has better convergence than the other DRL-based controllers,we re-implement those baselines with hyper-parameters equal to those of Layered-RQN in the same simulated scenario where there are 12 dynamic obstacles with a higher velocity of 15 pixels per frame. The convergence can be evaluated from two aspects, the final accumulative rewards and computation speed. The convergence of one method is better if it achieves the higher final accumulative rewards with less training duration.
The varying curve of the accumulative rewards of various methods with the episodes are recorded. As illustrated in Fig. 5, Layered-RQN uses around 4500 episodes to reach its convergence point and acquires much higher accumulative rewards. DRQN converges faster, and it takes around 4000 episodes to achieve the convergent situation,while for DDQN,DPQN and DQN, they take around 4500–5000 episodes to acquire the relatively low accumulative rewards.
Additionally, we record the required training duration for convergence of the three best performing models. The maximum length of an episode is set to 100 and the convergence point is set to 4500,4000 and 5000 for Layered-RQN,DRQN and DDQN, respectively. As illustrated in Table 2, although Layered-RQN needs more episodes to reach the convergence point, it takes shorter duration than DRQN, owing to its online and incremental computation structure.
It can be concluded that DRQN is sample-efficient but has a poor convergence,while Layered-RQN has a relatively better convergence than the other baselines since it explores the environment more effectively and accumulates the highest rewards with a lower cost of training duration.
4.5. Experiment II: Effectiveness of Layered-RQN
In this scenario,to test the adaptability of different models to a high dynamic environment,we design a scenario with dynamic obstacles that move at different velocities.As shown in Fig.6,we set 12 dynamic obstacles.The yellow,orange and red circles represent obstacles with relatively low speed of 5 pixels/frame,moderate speed of 15 pixels/frame and high speed of 25 pixels/frame. To demonstrate the robustness of the proposed model,the target is covered starting at the 100th frame, which means that the position of the target is missing.This situation is common in practical UAV navigation scenarios,for example,when the GPS signal is interrupted because of interference(magnetic disturbance,etc.).In the training process,the episode is ended if the UAV touches the boundary, collides with obstacles or acquires the target,while in the validating process,the episode will never end until the UAV touches the boundary or acquires the target. The converged DRL methods are deployed in the mixed scenario, and one of the successful navigation results is shown in Fig. 6.
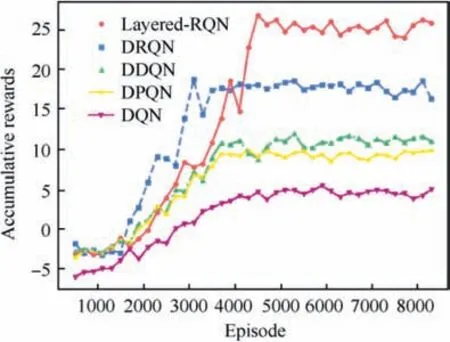
Fig. 5 Convergence curves of Layered-RQN, DRQN, DDQN,DPQN and DQN.

Table 2 Training duration of Layered-RQN, DRQN and DDQN.
From the overview of the simulation results,Layered-RQN allowed the UAV to autonomously and safely navigate in the high dynamic environment.As depicted in Fig.7(a),the cumulative number of collisions slowly increases for Layered-RQN,and it is successfully finished with only 4 collisions out of 50 episodes. However, for the other methods, more collisions happened.As illustrated in Fig.7(b),as for the trajectories that are generated by the DDQN, DPQN and DQN, there are many sudden changes when the UAV encounters high dynamic obstacles(red circles),which is not beneficial for UAV control because in most actual UAV control systems, changing the steering of a UAV abruptly is not permitted. However, the DRQN and Layered-RQN are smoother in this aspect. Additionally, it seems that Layered-RQN and DRQN keep good tracks of the target when the target is covered since the 100th frame. On the contrast, the DDQN and DPQN stray from target and navigate out of the airspace.
In order to eliminate the impacts of accidental factors, we further carry out some statistical tests of the methods. The comparative experiment is repeated for 150 times and the total amount of collision and mutation,path length and success rate are reported in the Table 3.
We conclude from the table that the proposed Layered-RQN is more robust to this moving mixed-dynamic environment with a success rate of 88%, and only 0.1 collision occurred on average. In those successful navigation tasks,the DRQN has the shortest average path length, and it is followed by Layered-RQN.
4.6. Experiment III: generalization of layered-RQN
To validate that Layered-RQN can be generalized into a more dynamic environment, we develop a comparative experiment where the DRL methods are trained in a fixed environment that contains 12 dynamic obstacles with velocity of 25 pixels/frame, and the trained DRL methods are deployed in more dynamic and denser environments.
For one comparative experiment, the total number of obstacles is fixed. We increase the velocity of obstacles and observe the changes of the 3 metrics of each DRL model.Each experiment is repeated 50 times.As illustrated in Fig.8,as the velocity of the obstacles increases, Layered-RQN’s number of collisions slowly increases while the DRQN’s and DDQN’s numbers increase more quickly. Layered-RQN’s path length is also the shortest when the environment becomes more dynamic (greater than 20 pixels/frame). In a real-highdynamic environment (the velocity of obstacles is 8 times that of the UAV), Layered-RQN still has nearly an 80% probability of successful navigation while the DRQN and DDQN have only 60% and 20% probabilities of successful navigation,respectively.
The same trend of the 3 metrics appears when we increase the density of obstacles in the environment while the velocity is fixed.
5. Discussions
For comprehensively evaluating the proposed method,we conduct experiments to demonstrate its convergence,effectiveness and generalization ability, by comparing it to DQN, DRQN,DDQN and DPQN.
For the convergence evaluation, Layered-RQN takes 4500 episodes to converge to a stable situation while DRQN and DDQN take 4000 and 5000 episodes. As shown in Fig. 5,Layered-RQN eventually acquires the highest accumulative rewards if the episodes are sufficient. It indicates that the proposed method has a good convergence property in the high dynamic environment, which is contributed by the designed distributed structure. The distributed structure mitigates the spare rewards problem by offering more positive rewards to the sub-networks and encourages UAV to explore further in the environment. Compared to DRQN, Layered-RQN is not sample-efficient, which can be ascribed to more parameters needed to be trained. However, from the results shown in Table 2, its training duration is shorter than DRQN in spite of more episodes needed. This computational efficiency comes from the online training manner, where Layered-RQN executes update incrementally by utilizing the current state and the action-value of the last moment. On the contrast, DRQN is much slower because it updates its parameters only when an entire episode is ended while DDQN is the fastest since it only uses some transitions between two states as samples.
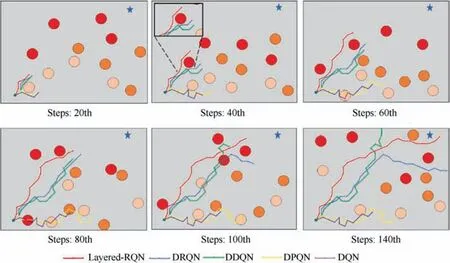
Fig. 6 An overview of experiment results.
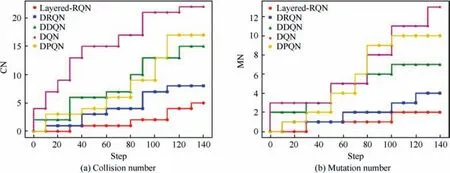
Fig. 7 Episode is repeated for 50 times and statistical evaluation indicators of CN and MN.
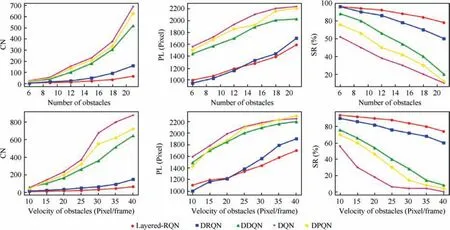
Fig. 8 Changing curves of various evaluation indicators under different numbers and velocities of obstacles.

Table 3 Statistical results for 4 evaluation indicators.
For the effectiveness evaluation, qualitative and quantitative experiments are conducted. As depicted in Fig. 6,Layered-RQN can plan a smoother path for UAV and keeps a good track of the target when the target is covered. Some numerical experiments based on the defined indicators also verify the effectiveness of the proposed method. As shown in Table 3, Layered-RQN has the highest success rate 88% out of 150 repetitive experiments. Moreover, it has the lowest collision number and the mutation number with a relatively short path length. The improvement in controlling comes from the utilization of LSTM. The spatial–temporal data in the history is helpful to predict the next behaviors of dynamic obstacles because their spatial location cannot change abruptly. Thus,the correlations that are extracted by LSTM help the UAV to capture more information about the dynamic scenario than the linear estimation in DDQN. Noting that the DRQN has the shortest path length among the DRL methods, the reason for the longer length of Layered-RQN is that it needs to choose to acquire or avoid action based on sensor data, while the DRQN directly generates an action for the UAV to take.
For the generalization ability,we train the DRL methods in a simulated scenario and validate them in the new scenarios with different numbers and velocities of obstacles.Fig.7 illustrates that Layered-RQN can be generalized into higher dynamic environment with denser and faster obstacles. This feature is mainly contributed by the work of the clipped DRL loss function. Instead of a fixed fusion regulation that is determined prior to the missions,the clipped DRL loss function derives the fusion regulation directly from the interactions with the environment;therefore, it evolves as the environment changes and can be adopted to a new environment without a priori.
From the experimental results, we conclude that Layered-RQN outperforms the baselines in navigating UAVs in high dynamic and uncertain environment.However,it is noted that deploying the proposed method in real UAV platform may still be challenging due to a commonly known reality gap problem.This problem is also discussed in another similar work41.Firstly,the sensory data in realistic platform are full of various noise and error,but the simulated sensory data are commonly precise or have a previously known noise distribution.Furthermore, the numerous training episodes are always available in the simulated scenarios. However, the high cost in both time and expenditure of UAV’s random exploration in practice restricts the available samples.To apply this technique in a real UAV platform, it is essential to pre-train the DRL model in more advanced simulated environments,such as AirSim42that are closer to the realistic world, to mitigate the reality gap.Then,it is further fine-tuned by using few realistic samples that are collected during UAV flight.
6. Conclusions
In this work,we develop a DRL framework for UAV autonomous navigation in a high dynamic and complex environment.The UAV problem is formulated as an MDP, and a novel DRL method is proposed to address it. To cope with the convergence challenges that are brought by the massive amounts of interactive data, we decompose the UAV navigation problem into three simpler subproblems and efficiently address them via the developed Layered-RQN.Without prior information of the environment, our method enables the UAV to safely and efficiently fly from the origin to the target in a changing and cluttered environment. Various simulation results demonstrate the effectiveness and robustness of the proposed method.Furthermore,this method can be generalized to a more dynamic and complex environment. In the future, we are going to develop a neural network that can be used to control multiple UAVs to carry out cooperative path planning.The sharing of sensing information among different UAVs improves the perception range of each UAV. Therefore, this kind of research will be of great significance to further improving overall navigation capabilities.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (Nos. 61671031, 61722102, and 91738301).
 CHINESE JOURNAL OF AERONAUTICS2021年2期
CHINESE JOURNAL OF AERONAUTICS2021年2期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Recent active thermal management technologies for the development of energy-optimized aerospace vehicles in China
- Electrochemical machining of complex components of aero-engines: Developments, trends, and technological advances
- Recent progress of residual stress measurement methods: A review
- Micromanufacturing technologies of compact heat exchangers for hypersonic precooled airbreathing propulsion: A review
- Towards intelligent design optimization: Progress and challenge of design optimization theories and technologies for plastic forming
- A combined technique of Kalman filter, artificial neural network and fuzzy logic for gas turbines and signal fault isolation