
动作分类卷积神经网络特征的时域属性校正方法
2021-04-01 07:04陈思宇杨大伟张汝波
大连民族大学学报 2021年1期
毛 琳,陈思宇,杨大伟,张汝波
(大连民族大学 机电工程学院,辽宁 大连 116605)
动作分类是行为识别研究方向中一项重要的基础任务,对动作时序提名[1]、动作时序定位[2]、视频密集事件描述[3]等技术都有一定的贡献,大部分基于视频数据的学习任务都需要以动作分类技术[4]为基础进一步研究。当前动作分类方法主要有三种:运用视频信息与对应光流信息作为输入数据的双流网络;仅运用视频信息作为输入数据的3D卷积神经网络[5-6];运用视频中人体骨骼关键点信息作为输入数据的卷积神经网络。本文提出的时域属性校正法针对仅运用视频信息作为输入数据的3D卷积神经网络展开。
动作视频中包含着多种属性:时域动作属性、静态空间属性、行人与背景的关联性、运动者自身的特点(衣着、身高、被遮挡与否)等。诸多学者发现,卷积神经网络(Convolutional Neural Networks,CNNs)中的卷积运算结构拥有的平移不变性特点为其带来优异的空间属性学习能力,却降低了网络模型对其他属性的注意力,限制模型对时域属性的学习能力[7]并影响动作特征中的时域稳健性。文献[8]指出训练完成的CNNs在对动作视频分类时,约半数的分类没有依据真实的运动轨迹,仅运用了视频中的空间信息来完成分类判决,该实验反映出CNNs在训练时对时域属性的注意力存在不足。文献[9]为了使网络模型不受限于视频中局部的空间外貌特征,针对视频数据设计了非局部网络结构,使模型对局部与非局部信息进行区分,学习到全局的动作信息,但网络结构的复杂性使得其模型参数量大幅度增加,不利于应用。文献[10]设计了4D卷积结构对长距离时空表示进行建模,并利用残差结构保存三维时空特征,作为视频级网络,其性能较为优异,但该结构的参数量与计算成本都较为庞大,在后续应用中还需优化。
为了突破CNNs的局限性,改进该网络在动作分类中的表现,本文针对CNNs所捕获的特征中时域属性信息的稳健性不足问题,提出一种时域属性校正法提升模型对该属性信息的学习能力。基于3D卷积神经网络结构,抽象模型所学特征的属性信息,对比各动作特征间的时域属性偏差,校正偏差过大的特征,强化网络模型对时域动作规律的学习,提升CNNs的性能。本文基于文献[11]对各种热门卷积网络的实验结果,选取其中表现最好的ResNext-101模型作为仿真对象,经本方法改进后,该网络模型的Top-1与Top-5准确率在两个常用的动作分类数据集中都有一定的提升,其预训练模型的仿真结果也能够得到优化。
1 时域属性校正法
时域属性校正法主要分为属性抽象与校正反馈两个部分。
1.1 属性抽象
样本数据空间关系如图1。基于词类比等自然语言处理领域相关应用的研究成果[12-13],当不同词汇样本间具备某种一致属性时,它们的特征将拥有一致的属性空间映射关系,如图1a。本文由此创新性地推论,具备时间维度的各视频样本虽包含多种属性,但其拥有的时域属性能使它们保持一定的时域空间关联特性,由于三维卷积神经网络模型在训练时所学到的特征信息x也具备时间维度[14],上述推论能够应用于拥有时域属性的特征信息x,不同的特征信息存在如图1b所示的空间关系。
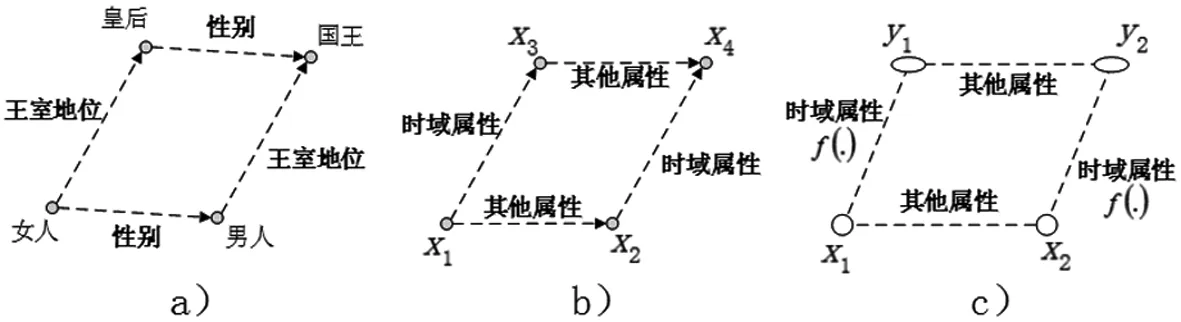
图1 样本数据空间关系
在动作分类任务中,神经网络能否准确分辨动作信息,主要依据该网络模型能否辨别不同环境、不同行人的一致动作轨迹规律。真实视频图像与其对应的差值信息如图2,上行为原始视频的连续帧图像,下行为上行图像运用帧差法获取的差值图像。图中可以看出差值图像能够包含非常完整的动作轨迹信息,且图中与动作轨迹无关的噪点信息也较少,由此将动态差值图像定义为视频数据的时域动作属性信息。
属性映射法假设原始信息与属性信息之间的映射关系能够代表该属性本身,设定任意拥有时间维度的数据X与对应时域动态信息Y之间存在稳健的时域映射f(·),本设定存在公式表达:
f(X)=Y。
(1)
当时域属性由时域映射关系f(·)代表时,具备一致时域属性且拥有时间维度的各个网络特征信息组x也应具备一致的时域映射关系f(·)。由图1b可推论,不同的特征信息x具备一定的时域空间关联特性,那么任意两组特征数据x与其对应的时域动态信息y之间应存在如图1c所示的空间关系。属性映射法的核心逻辑是透过对映射关系的求解,完成时域属性的抽象。
属性抽象的计算环节分为两步:第一步,指定时域映射f的函数形式;第二步,利用已知的特征数据x与对应时域动态信息y,根据指定时域映射f的函数形式设计对应的算法,得出f的未知系数。透过对未知系数的求解,完整的f即为特征数据时域属性的抽象结果。
不同的函数形式会对抽象结果拥有不同的影响,在应用时可以根据实际需求指定不同的函数作为时域映射f的具体形式。在此以一元一次函数作为计算示例,指定的时域映射f存在函数形式:
f(x)=ax+b=y。
(2)
式中,a、b为当前指定形式中的未知系数。

图2 视频图像与帧差法获取的差值图像
通过已知的x与y,可得出一种估计结果:将x与y的商与余数作为a、b的解,存在算式:
(3)
(4)
由于上述方法只能得出当a为最大值时的解,得出的未知系数解集并不完整,在实际应用时可添加额外的计算(如收束a值的倍率并得出对应的b值),得到更完整的解集,将解集的期望值作为最终的系数解,完善抽象结果f。
1.2 校正反馈
根据图1展示出的样本数据空间关系,可以得出约束条件:具备一致时域属性的不同特征间应具备一致的时域映射关系f(·)。当分类模型对各场景动作视频中时域属性的学习成效不佳,导致同一中间层内特征的时域稳健性不足时,可以通过对映射关系的一致化校正来改善特征数据中所包含的时域属性。本方法利用上述约束条件并基于三维网络中拥有时间维度的特征数据,对比模型内各特征组的时域映射关系f(·),将对比得出的属性偏差值作为约束,反馈到模型的再训练过程。当属性偏差值较大时,反馈再训练的过程可以通过该偏差校正模型所学特征的时域属性,提升对应属性信息的稳健性;当属性偏差值较小时,即认为该组特征具备稳健的时域一致性,不用加以校正。
继续以一元一次函数作为示例,利用从模型训练过程中选取的特征数据x,得出对应的时域动态信息y。通过x与y计算出时域映射f(·)中的未知系数a、b,由于特征数据x为包含时间维度的三维数据,得出的未知系数解将构成参数集合A与参数集合B,可表示为:
A={a1,a2,a3,…,au};B={b1,b2,b3,…,bu}。
(5)
式中,u的大小取决于被计算特征数据中图像帧的数量。在此基础上,将不同特征组的参数集合A与参数集合B的线性差值整合为分歧集合A与B,以分歧集合的标准差作为时域属性映射的分歧参数Dt,存在计算公式:
(6)
用不同参数集合的差值代表不同特征之间时域映射f(·)的偏差,以该偏差作为各组特征间时域属性的分歧,将分歧参数Dt与原始的损失函数l′[15]整合,使分歧参与到模型的反向传播中。模型的损失函数直接影响网络模型的反向传播过程[16],添加分歧参数Dt后的损失函数:
L=l′+φDt。
(7)
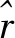
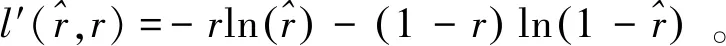
(8)
本方法以增强3D CNNs的时域属性学习成效为目的,解决卷积运算容易忽略视频数据中时域信息的问题,改进卷积神经网络在视频动作分类任务中的局限性。
1.3 时域属性校正法框架
运用网络模型在训练过程中捕获到的特征信息,通过独创的属性映射法抽象出时域属性,对比各特征信息中的时域属性偏差,将偏差反馈到模型的训练中,使时域属性的偏差作为一项训练约束,直接影响神经网络模型的反向传播。在优化训练约束的同时,逐渐降低时域属性偏差,提升3D CNNs所学特征的时域属性一致性。使用时域属性校正法的网络模型训练逻辑图如图3。
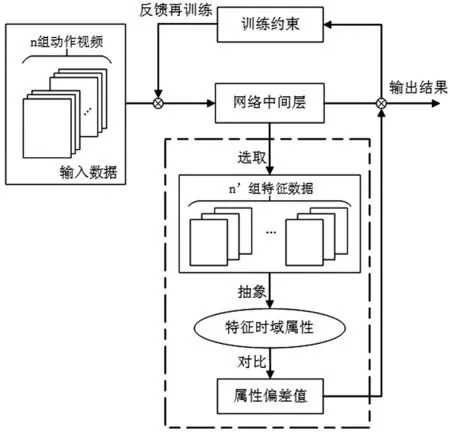
图3 改进后网络模型的训练逻辑图
图3虚线框选部分为方法的运算流程,结合反馈部分后本方法共计四个步骤。
步骤1:在模型训练过程中,选取指定网络中间层的特征数据。中间层的指定可以完全随机,或默认优先指定较浅中间层(以10层网络为例,1~3层为较浅层)或较深中间层(7~10层为较深层),可根据不同网络模型、训练结果对指定层进行调整,以达到更好的校正效果。
步骤2:运用属性映射法抽象所选取特征数据的时域属性。通过帧差法计算选取特征数据x的时域动态信息y,具体计算过程可表示为
yi=xi+2-xi,1≤i≤n-2 。
(9)
式中:i代表帧数;n代表一个特征数据集合X的总帧数;x为特征数据X的单帧二维图像,计算时逐两帧作差。x的图像大小受到网络模型训练时既定输入数据大小与指定中间层位置的影响,特征数据集合X与时域动态信息集合Y存在公式表达:
X=[x1,x2,x3,…,xn] ;
(10)
Y=[y1,y2,y3,…,yn-2] 。
(11)
剩余步骤如本文1.1章节所示,后续仿真对时域映射f(·)的指定形式为一元一次函数。运算过程中,集合X为复数,根据网络模型训练时既定的批量尺寸数s存在对应数量的集合X所构成的集合组X,出于对算法实时性的考虑,直接采用向量化(逐帧逐像素对应)计算得出f(·)的未知系数解。假设x的大小为(28,28),得出的一组集合的未知系数解A与B的大小为(n-2,28,28),完整未知系数解A与B的大小为(s,n-2,28,28)。
步骤3:对比各组特征数据的时域属性,得出量化的属性偏差值。从s组参数集合中随机选取一组参数集合A'、B'为对照组,其他所有组为被对照组,计算时需得出所有对照组与被对照组的差值,将得出的s-1组差值求和并取期望值,以此作为属性偏差值Dt,其中的公式化表达详见本文1.2章节。
步骤4:将属性偏差值反馈添加到损失函数中,成为一项训练约束,使模型的再训练过程受到特征数据时域属性偏差的影响,具体公式细节详见本文1.2章节。
2 仿真验证
为了验证有效性,本文在两个常用的动作分类数据集UCF-101[17]与HMDB-51[18]上进行仿真验证,根据文献[11]的实验结果,选择了其中准确率最高的ResNext-101网络作为仿真模型,运用时域属性校正法对该模型进行改进。
仿真使用4张英伟达1080ti显卡对分类模型训练,基于python3.6构建仿真程序,运用了pytorch深度学习框架(版本为0.4.0)。网络模型未经任何预训练,各中间层均为3D结构,训练时使用批量归一化与随机角点裁剪处理输入数据,并结合基于验证集的自适应学习率调整模块,其他详细参数见表1。
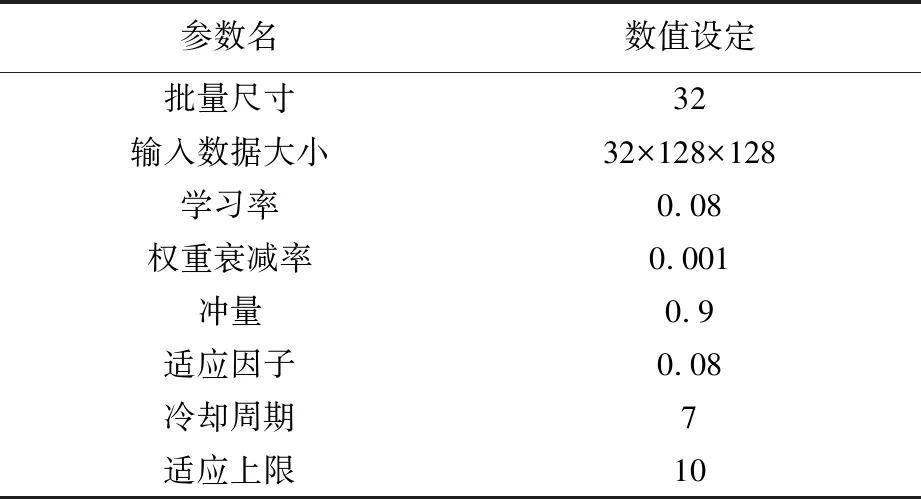
表1 仿真相关参数设置
属性偏差值Dt在网络模型训练过程中的变化曲线如图4。根据图像结果可知,网络模型在对两个数据集进行训练时,经校正后的特征数据时域属性偏差值都基本低于模型校正前,表明本方法有效校正了分类模型所学动作特征的时域属性偏差,优化了特征的时域属性稳健性。曲线优化前后的波动较为一致,说明本方法作为一个辅助部分,不会使网络模型的训练进程产生本质上的偏移,结合方法无需更改模型结构的特点,时域属性校正法拥有较强的可适用性,在不多加调试的情况下也能够直接与动作分类卷积神经网络模型相结合。
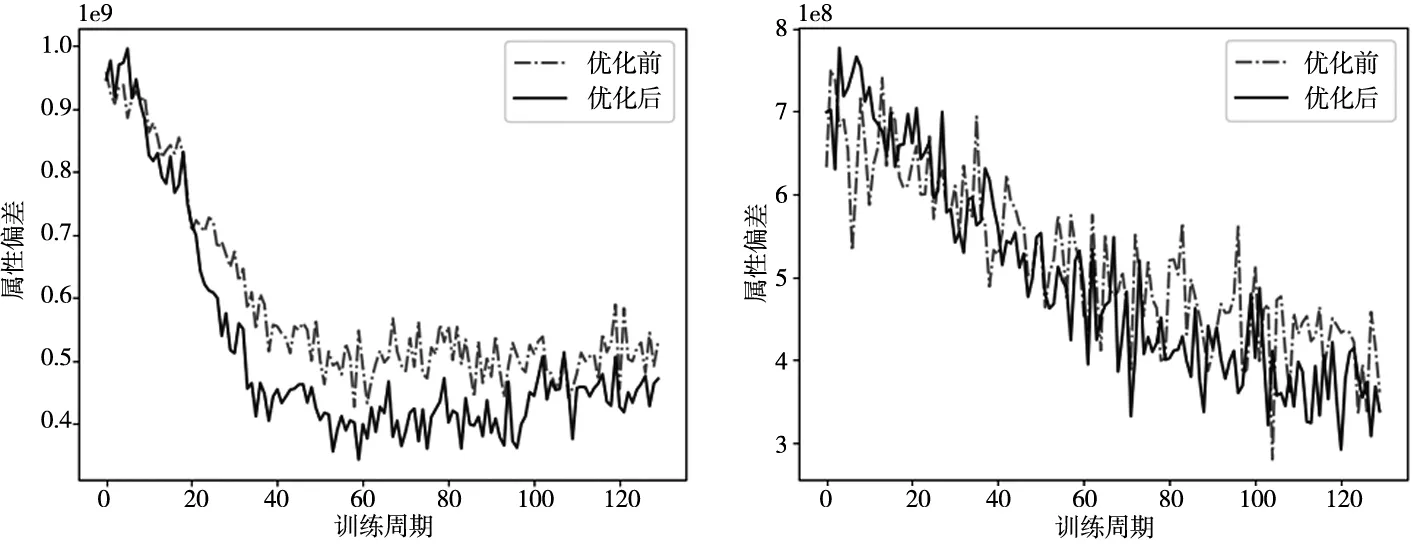
a)UCF-101 b)HMDB-51
校正前后的ResNeXt-101网络在两个数据集上的测试准确率见表2,最终结果从三组测试数据中取均值后得出。可以发现经改进后的ResNeXt-101-R模型在两个数据集上均有不同程度的提升。其中,在UCF-101数据集上的性能改善较为明显,分别在Top-1和Top-5准确率上提升3.5%与2.3%,在HMDB-51数据集上的测试结果仅提升了1%的Top-1准确率与0.9%的Top-5准确率。同时,两组测试结果都是Top-1准确率的提升大于Top-5准确率的提升,可以得出推论:在未经其他预训练的情况下,改进后的网络模型提升了对动作样本的精确度。
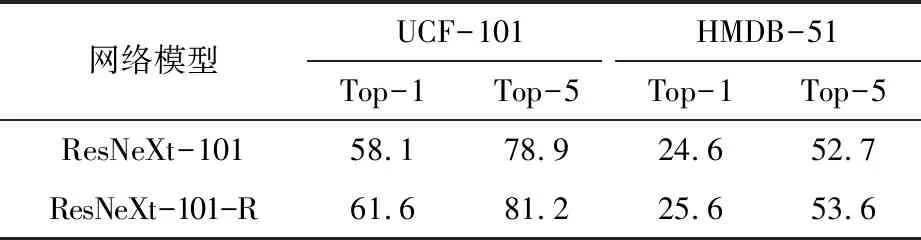
表2 对不同数据集的测试准确率/%
选取两个数据集中的样本进行实例演示,模型独立判别视频内每5帧数据内容的动作分类结果如图5,一个样本的上下两行图像别为ResNeXt-101与ResNeXt-101-R网络训练后所得模型的分类结果,每张图片的左上角显示了模型的分类结果,右上角注明了分类结果的正确与否,“×”代表分类错误,“〇”代表分类正确。经本方法校正后的模型能够有效对错误的实时分类情况进行修正。

图5 分类实例演示
在验证了方法的有效性后,通过使用预训练模型的仿真实验检验先进性。预训练模型在仿真时的相关参数与表1不完全相同,批量尺寸为64,学习率0.001,权重衰减率0.000 01,未使用自适应学习率调整模块。使用预训练模型后所得出的测试结果见表3。
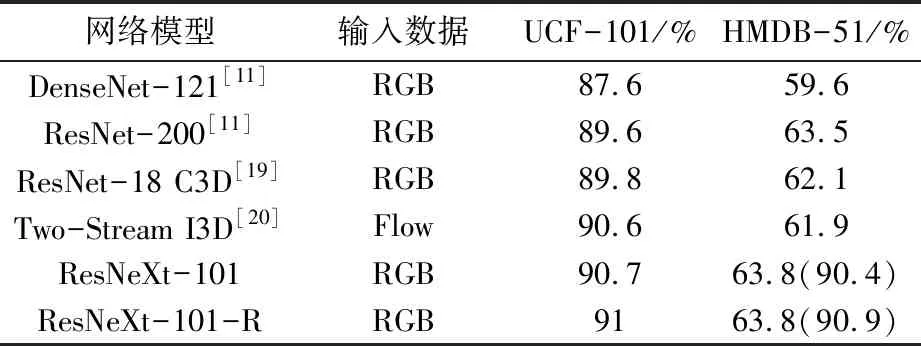
表3 预训练模型在不同数据集上的测试准确率
表中动作分类网络模型的预训练都在Kinetics数据集[20]上进行,该数据集拥有400个动作类,共计300 000个动作实例样本,是当前常用于动作分类模型预训练的数据集之一。表3中引用网络模型的输入数据都为仅包含RGB原始图像或光流数据的单类数据,多类输入数据组的仿真结果不在对比范围内。通过准确率结果的对比可以发现,本方法所带来的校正优化效果在预训练模型中也具有成效,括号内为Top-5准确率,虽然优化后模型在HMDB-51数据集上的top-1准确率没有变化,但top-5准确率有一定的提升,体现出本方法对模型泛化能力的加强。相较于其他经过Kinetics数据集预训练、仅单类输入数据的动作分类模型结构,本方法的优化结果拥有更佳的性能表现。
3 结 语
本文提出利用时域属性校正法改进3D卷积神经网络模型对时域属性学习成效不足的问题,直接对模型所学特征的属性信息进行抽象并校正,增强特征的时域一致性。本方法在应用时无需修改模型结构,耗费的时间成本较低,拥有较高的实用性,改进后的ResNeXt-101在不同动作分类数据集上的性能都有所提升。后续工作将对不同网络模型、数据集进行尝试,验证本方法是否拥有更广泛的应用空间。
猜你喜欢
电声技术(2022年7期)2022-09-23
科技视界(2020年26期)2020-09-24
科技视界(2020年24期)2020-08-26
科技视界(2020年22期)2020-08-14
国学(2020年1期)2020-06-29
宇航计测技术(2019年1期)2019-03-25
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
佛山陶瓷(2017年8期)2017-09-06
少儿科学周刊·儿童版(2017年3期)2017-06-29
