
结合数据库结构及内容的问句理解方法研究
2021-03-18 08:03袁志祥任冬冬洪旭东孙国华
计算机工程 2021年3期
袁志祥,任冬冬,洪旭东,孙国华
(安徽工业大学计算机科学与技术学院,安徽马鞍山 243000)
0 概述
互联网上的许多重要数据都存储在结构化数据库中,其具有存储简单、数据质量高等特点。但是对于缺少相关SQL 专业知识的用户而言,很难快速准确地写出他们所需求的SQL 查询语句。为解决该问题,研究人员提出NL2SQL(Natural Language to SQL)任务,该任务要求模型根据自然语言问句和数据库表生成相应的SQL 查询,而解决该任务的关键是充分地理解自然语言问句的语义,并将其映射到SQL 表达式相应的部分(如在表中找到对应的列名,在表内容找到对应的条件值,在SQL 关键字中找到对应的聚合函数等)。
由于缺少人工标注的SQL 数据集,使得该任务未被重视。2017 年,ZHOU 等人[1]发布人工标注的大型SQL 数据集——WikiSQL,该数据集含有大量英文问句以及对应的SQL 语句和数据库表。2019年,追一科技公司在阿里云平台举办的首届中文NL2SQL 挑战赛,提供了大型中文SQL 数据集。上述数据集为训练NL2SQL 神经网络及解决语义解析提供了训练条件。
早期将自然语言转换为SQL 语句的研究是利用中间表达式的方法,结合自定义语法和规则将自然语言问句转换成SQL 语句。文献[2]使用斯坦福依存树解析器[3]解析问句,根据启发式规则生成SQL候选集,利用语法树核函数的SVM[4]对候选SQL 进行排序。文献[5]使用无监督学习的方法生成SQL,利用数据库模式限制模型的输出空间以弥补标注数据的不足,同时引入扩展状态空间的语义依存树解决语义和语法不匹配的问题。文献[6]通过与用户交互来确定问句的词语与表相应内容的关系,同时自定义规则调整查询树的结构,最终将其转换成SQL。文献[7]通过自定义一种形式化意义语言实现了中文GIS 自然语言接口。上述方法都是依赖高质量的语法来解析问句,不能处理用户语法多变的问句,因此具有局限性。
随着深度学习的发展,人们开始将NL2SQL 的研究转向训练神经网络模型。早期的深度学习模型将NL2SQL 看成序列生成问题,利用sequence-tosequence 模型[8]生成SQL 查询。文献[9]运用注意力机制,通过sequence-to-sequence 的解码层自动生成SQL 序列。为提升SQL 查询的准确率,结合SQL 语法限制输出空间的模型被提出。文献[1]提出Seq2SQL 模型,该模型将SQL 生成分为聚合函数分类、select column 以及where 子句生成三部分,同时利用强化学习解决序列生成引发的“order matters”问题。文献[10]利用SQL 语句的格式和语法提出sequence-to-set 模型,将SQL 语句任务分成多个子任务,并结合column attention 提升SQL 生成的准确率。文献[11]结合知识图谱识别问句中的实体。文献[12]利用sequence-to-sequence 以及sequence-toset 模型各自的优势,提出sequence-to-action 模型。该模型使用预定义的action 来填充SQL 查询草图的插槽。文献[13]通过SQL 执行结果修复错误的SQL查询。
近年来,大规模预训练模型在许多自然语言处理的下游任务中取得优秀的成绩,许多基于预训练的Nl2SQL 模型被提出。研究人员使用Bert[14-15]预训练模型替代glove[16]作为模型的编码器,基于Bert 编码器提出3 种不同的输出层,超过了人类手动标注。文献[17]基于MT-DNN 模型[18]提出X_SQL 模型,通过强化上下文信息得到数据库模式新的表达式,更好地表征其结构信息以用于下游任务。
现有许多深度学习模型都仅局限于数据库结构对模型的影响,忽略了表内容对NL2SQL 任务的重要性。问句的词语与表内容不匹配,导致生成的SQL 查询在数据库执行错误。而结合表内容不仅可以帮助模型更好地识别问句中对应的SQL 语句实体,还可以缓解问句与表内容不一致的问题。本文在SQLova[13]的框架下,提出一个同时结合表结构和内容的NL2SQL 模型。使用字符串匹配的方法筛选出与问句相关的表内容,利用Bert 编码器对问句、表列名以及相关表内容进行字编码,value attention 和column attention 将表结构和内容的表示特征加到问句表达式中,帮助模型更好地理解用户问句的语义,识别问句中的表列名和条件值,并根据多个子模型的分类方法填充SQL 草图完成SQL 查询。
1 任务描述
本文使用追一公司在阿里云发布的中文数据集作为整篇文章的示例。该中文数据集的任务是在给定问句和数据库表的情况下生成相应的SQL 查询。其数据格式如图1 所示,每条数据对应一个数据库表和1 条问句以及SQL 查询。

图1 中文数据集数据格式Fig.1 Chinese dataset data format
对于问句的词语与表内容不完全匹配的问题,如图1 中的“死侍2”与表内容的“死侍2:我爱我家”不一致的情况,会导致SQL 查询结果为空。模型结合表内容通过字符串匹配的方法来替换模型从问句中生成的词语,即将“死侍2:我爱我家”替换成“死侍2”,缓解表内容与问句词语不一致的问题。在WikiSQL 测试集上比SQLova 准确率高出1.4%,实验结果表明,结合数据库结构和内容特征可以帮助模型更好地理解问句语义,提升SQL 查询的准确率。
本文将序列生成任务转化为多个分类任务,通过填充SQL 草图生成SQL 查询。该中文数据集的SQL 查询对应的SQL 草图如图2 所示,草图的每个槽对应不同子任务。以$开头的标记表示槽标记,$后面的名称表示需要预测的类型。其中:$AGG 表示模型预测SQL 查询的聚合函数,取值集合包括{‘ ’,‘MAX’,‘MIN’,‘COUNT’,‘SUM’,‘AVG’};$SELECT_COL 和$WHERE_COL 表示模型需要预测的数据库表列名;$WHERE_RELA 表示where 子句的关系,包括{‘ ’,‘and’,‘or’};$WHERE_OP 表示SQL 查询的操作符,包括{‘=’,‘>’,‘<’};$WHERE_VAL 表示从问句中生成的SQL 查询条件值;(…)*表示子句的数量是零个或多个。

图2 SQL 草图Fig.2 SQL sketch
2 相关表内容获取方法和模型整体架构
在SQLova 框架下,将模型分成Encoder 层、Attention 层以及Ouput 层三部分,具体结构如图3 所示。在Encoder 层,SQLova 将问句和表列名作为Bert 预训练模型的输入,在SQLova 模型的基础上将相关表内容作为Bert 的输入;在Attention 层,SQLova 通过Column Attention 得到问句表达式,利用Value Attention 将表内容的信息融入问句的表达式中;在Output 层,为了更好地预测Where Column和Where Value 子任务,将基于表内容的问句表达式作为额外输入。

图3 模型整体结构Fig.3 Model overall structure
2.1 表内容筛选
在解析问句语义时,相对于结合数据库结构,表内容对于生成SQL 查询有着重要作用。结合表内容可以帮助模型更好地找到SQL 查询的条件值,如图1中的示例,模型根据表内容“大黄蜂”更好地找到问句中的“大黄蜂”。同时结合表内容还可以帮助模型预测问句中表列名,比如“北京”这个条件值使模型更倾向于预测“城市”列名。但将表内容所有的信息作为Bert 编码器的输入,给模型带来过多的干扰因素,同时会使得模型的输入过长,所以本文筛选出与问句有关的表内容作为模型的输入。
为得到与问句相关的表内容,模型将问句进行分词处理,枚举长度为1~4 的所有n-garms,使用Jaccrad公式计算组合的词语与表内容的相似度。若问句中出现单引号或者双引号以及书名号时,直接使用该词语与表内容进行相似度计算。计算公式如下:

如果相似度超过一定的阈值,则将表内容加到模型的输入中。本文利用得到的相关表内容、问句和表列名共同构成Bert 编码器的输入。
2.2 基于表的Bert 编码器
基于语境的动态词表达式ELMO[19-20]和Bert[14]预训练模型,在处理许多自然语言处理任务方面表现突出。SQLova[13]的实验结果也表明利用Bert 模型得出的基于上下文和表的词表达式,可以有效提高NL2SQL 任务的准确率。模型使用Bert 模型对其进行字编码,同时将问句、数据库列名以及相关表内容作为Bert 的整体输入。Bert 中的self-attention 机制使得模型更注重问句中列名和条件值,获得更准确的表达式。具体如图3 所示,其中[CLS]和[SEP]是用于分类和上下文分离的特殊标记。本文使用[SEP]来分隔问句、列名以及表内容,与位置向量共同构成bert 编码器的输入,得到对应的问句、列名以及表内容的特征表达式Hq、Hcol和Hval。
2.3 注意力层
将Hq、Hcol、Hval通过3 个Bi-LSTM,选择最后的隐藏状态得到对应的表达式Eq、Ecol、Eval。在预测Select Column 与Where Column 子任务时,为表示不同列名在自然语言问句的重要程度,本文引用SQLNet 的Column Attention[9]表示问句的表达式,具体如下:
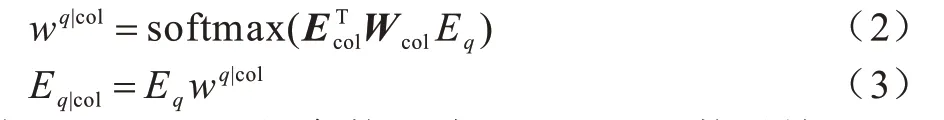
其中,Wcol是d×d的参数矩阵,softmax 函数对输入矩阵的每行做归一操作,wq|col表示列名对问句的注意力权重,Eq|col是结合表内容的问句表达式。
为更好地理解问句中的条件值,本文提出Value Attention,使问句的表达式可以在预测SQL 查询的条件值时更好地反映出表内容在问句的重要信息。本文首先利用问句和表内容的表达式计算问句对应表内容的权重,其中,Wval是参数矩阵。根据得到的每个问句的权重wq|val,然后与问句的特征表达式Eq进行加权乘积求和得到基于表内容问句的新表达式,具体公式如下:
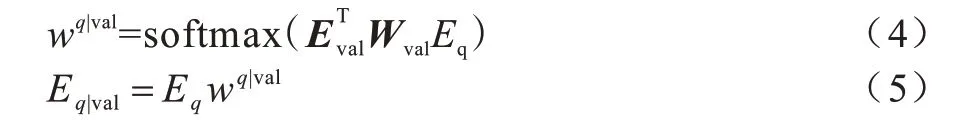
2.4 输出层
模型利用Attention 层得到的输出来预测SQL 草图不同的槽,其中槽分别对应8 个子任务,分别是Select Number、Select Column、Select Agg、Where Relation、Where Number、Where Column、Where Operator、Where Value。Output 层的子任务以及之间详细的依存关系如图4 所示。由于Select Number 子任务与Where Number 以及Where Relation 模型结构相同,在图中只显示出Select Number 子模型的结构。

图4 输出层子模型之间的关系Fig.4 Relationship between output layer submodels
子任务分别介绍如下:
1)Select Number。该任务是确定Select 子句中表列名的数量,模型把该任务当成一个4 分类任务,具体公式如下:
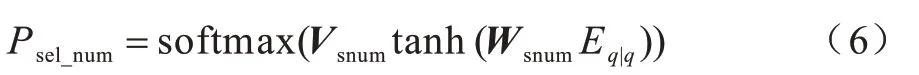
其中,Eq|q表示基于self-attention 的问句表达式,Vsnum和Wsnum分别对应4×d、d×d的参数矩阵。
2)Select Column。该任务根据概率的大小从表中k个列名作为SQL 语句的Select 查询字段,其中,k是Select Number 预测的个数,具体公式如下:
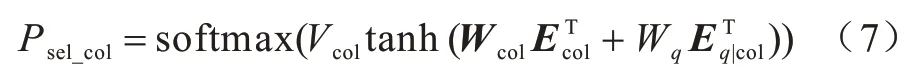
3)Select Agg。该任务是预测SQL 查询的聚合函数,利用Select 子句的列名和问句进行分类任务,具体公式如下:

4)Where Number:该任务是利用问句的表达式预测Where 子句的个数,具体公式如下:
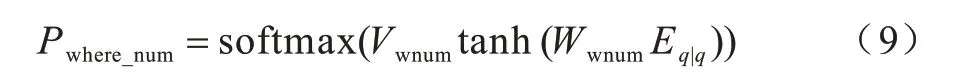
5)Where Relation。该子模型是预测Where 子句之间的关系。若Where 子句的数量为1 时,默认Where Relation 为空;当Where 子句的数量大于1 时,将问句表达式作为输入对Where 子句的关系进行二分类(and,or),具体公式如下:
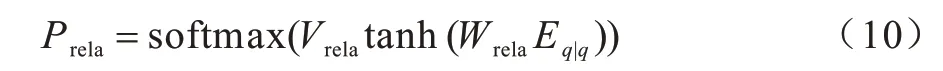
6)Where Column。该任务是确定Where 子句的表列名,利用列名、基于表结构和表内容的问句表达式进行分类任务。根据SQL 语法,Select Column 与Where Column 不能同时对应数据库表的同一个列名,因此把Select 子句生成的列名也作为该任务的输入,公式具体如下:

7)Where op。该子任务是确定Where 子句的操作符,需要根据Where 子句的表列名与问句表达式来进行分类,具体公式如下:
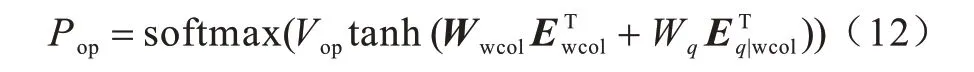
8)Where Value。该任务通过序列标注从问句中找到每一个Where Column 对应的条件值。除了基于列名问句表达式与Where Column 预测的Column表达式作为Where Value 任务的输入外,基于Value attention 的问句表达式也可以帮助模型预测Where Column,具体公式如下:
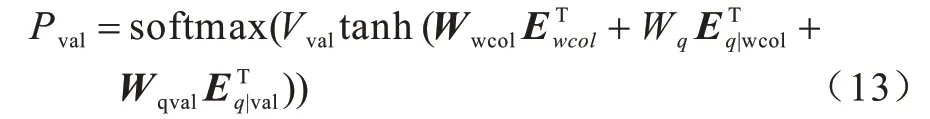
若该任务生成的条件值与表内容存在不匹配的问题,模型结合表内容利用字符串匹配的方法替换生成的条件值。
2.5 训练阶段
在训练阶段,由于模型被分成多个分类子任务,因此目标函数可以被看成多个子模型的交叉熵损失函数的和。针对表列名的预测,模型通过交叉熵损失函数计算标注数据出现的表列名与预测列名概率的损失;针对Where Value 子任务的预测,通过预测问句中的条件值的开始位置和结束位置与真值的损失。交叉熵损失函数的具体公式如下:
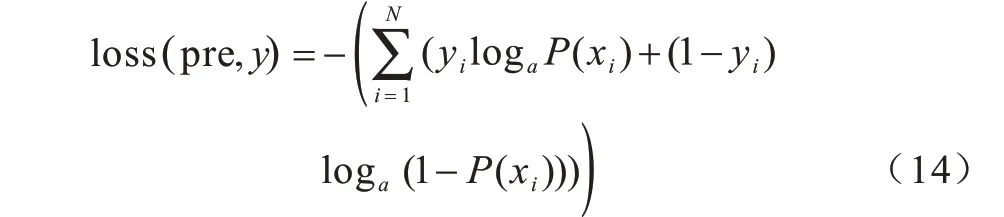
其中,x表示训练数据,y表示真值,N表示样本的数量。本文通过最小化目标函数的方式来更新模型参数。
3 实验结果与分析
3.1 数据集和评估方法
本文分别在追一公司发布的中文数据集和WikiSQL 数据集进行测试。WikiSQL 数据集是ZHONG 等人[1]发布的手工数据集,被广泛应用于NL2SQL 深度学习模型,该数据集拥有80 000 多条训练数据以及对应的20 000 多张数据库表。中文数据集共有50 000 多条数据,与WikiSQL 不同的是,中文数据集的SQL 查询中Select 子句的表列名可以是多个,另外,Where 子句之间的关系不是默认的“and”关系,其条件数量以多个为主。本文使用Logic Form Accuracy(Logic)和Execution Accuracy(Exe)两个指标评估模型性能,其中,Logic Form Accuracy 是指生成的SQL 查询与数据集的SQL 真值比对的准确率,Execution Accuracy 是指生成的SQL 语句与数据库的SQL 语句在数据库执行完查询结果后进行比对的准确率。
3.2 实验设置
在实验中,本文使用768 维的Bert 作为模型的编码器,其最大长度设置为222,在训练阶段微调Bert 预训练模型的参数;设置模型使用的Bi-LSTM隐藏层的维度是100,丢失率为0.3,不同子任务之间的Bi-LSTM 的参数不共享;设置迭代次数为100,批训练次数为8,每次迭代打乱训练数据的顺序,学习率设置为0.003,使用Adam 方法优化参数模型。
3.3 实验结果
表1 给出本文模型和不使用表内容的模型在中文数据验证集上的实验结果,其中,“-表内容”表示不使用表内容的模型。可以观察到在S_col 任务上,原模型比不使用表内容的模型准确率高出0.021,在W_col 任务上,比不使用表内容的模型高出0.007,结果表明,结合表内容可以在一定程度上帮助模型预测与表内容相关的表列名;原模型在W_val 上高出0.01,这是因为原模型可以通过表内容更好地理解问句中的SQL 查询条件值。例如问句“爱情的呼唤这部电影是哪家单位引进的”,对应正确的Where 子句是“Where 剧名=爱情呼叫转移and 类别=电影”,结合表内容可以帮助模型预测“电影”应该作为SQL查询的条件值,而不是表列名。不使用表内容的模型比原模型在Execution 低0.19,在Logic Form 低1.8%,说明模型利用Attention 层的Value Attention 注意力机制,获得更加准确的问句表达式,可以更好地帮助下游任务分类。

表1 不同模型在中文数据集上的实验结果Table 1 Experimental results of different models on the Chinese dataset
表2 给出不同模型在WikiSQL 验证集和测试集上的实验结果。从表2 可以看出,本文模型的准确率明显高于表中前5 个模型。针对SQLova 的模型,本文获取到SQLova 源码得到的模型由于不知道SQLova 具体的参数,实验结果比原文给出的准确率低。本文模型在验证集上的Logic Form 比SQLova高出0.18,在测试集高出0.15;在验证集上的Execution Accuracy 比SQLova 模型高出0.14,在测试集高出0.14。该结果表明结合表内容和表结构可以有效地提高SQL 生成的准确率。
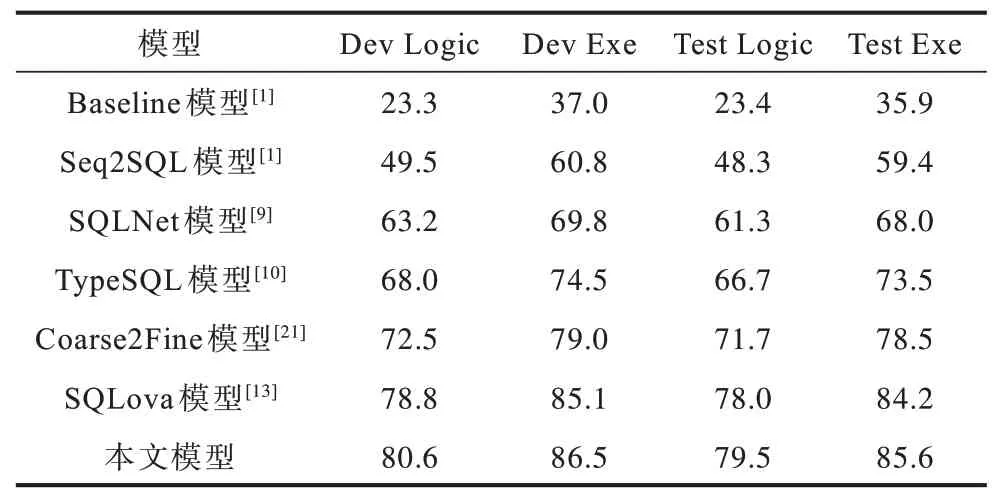
表2 不同模型在WikiSQL 数据集上的实验结果Table 2 Experimental results of different models on the WikiSQL dataset%
4 结束语
本文在SQLova 框架下,提出一个基于表结构及其表内容的NL2SQL 模型,利用Column Attention和Value Attention 来更好地理解用户问句的语义。将序列生成任务转变成多个分类任务,通过填充SQL 草图生成SQL 查询。实验结果表明,结合表结构和内容可以提升模型生成单表的SQL 语句的准确率。但该模型暂不能处理结合生活常识解决的问题,同时在实际情况中,用户提出的问题往往需要多张数据库表来解决,而多表对应的SQL 查询会涉及表名、多张表的连接方式、嵌套查询以及增加Group、Order 等SQL 关键字的情况。下一步研究方向是处理涉及多表查询的Spider 数据集,利用人们的生活常识生成SQL 查询,以更符合实际应用场景。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机集成制造系统(2020年8期)2020-09-11
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
现代计算机(2019年6期)2019-04-08
中国交通信息化(2018年5期)2018-08-21
西夏学(2018年2期)2018-05-15
