
基于深度学习的二维人体姿态估计研究进展
2021-03-18 08:03张建林徐智勇魏宇星
计算机工程 2021年3期
刘 勇,李 杰,张建林,徐智勇,魏宇星
(1.中国科学院大学电子电气与通信工程学院,北京 100049;2.中国科学院光电技术研究所,成都 610209)
0 概述
二维人体姿态估计是计算机视觉领域的主要研究方向,在行为识别、姿态跟踪等领域有着重要研究价值和应用前景,其本质是研究如何从给定图像中精确识别目标人体并获得目标人体姿态估计的问题,是姿态估计研究领域的重要分支。
二维人体姿态估计的研究方法可划分为早期传统的基于图结构模型的方法以及目前主流的基于深度学习的方法。传统的人体姿态方法通过图模型建立人体姿态架构,参考人体运动学与人体姿态学等理论约束并优化人体姿态模型,但其需要根据样本的具体情况来选择姿态信息的特征描述子,如尺度不变特征描述子(Scale Invariant Feature Transform,SIFT)[1]以及方向梯度直方图描述子(Histogram of Oriented Gradient,HOG)[2]。这些特征提取策略难以应对视角不同、外观不同以及遮挡等情况的干扰。此外,人体可表达的姿态丰富程度使得其变化更为复杂多样,这为相关姿态特征信息的提取造成了很大挑战。传统姿态估计方法可被视为一种基于图结构优化后的代数求解问题,当人体姿态过于复杂时,针对同一样本案例的图结构优化将存在多组解,使得估计结果不再具有唯一性。
而卷积神经网络(Convolutional Neural Network,CNN)[3]对二维图像中的人体进行特征提取则可以获得更为精确和稳定的卷积特征。多层卷积叠加可以控制特征感受野的信息感知范围,从而获得不同尺度下的特征信息。深度卷积神经网络通过有策略地对样本进行学习,可以获得图像与标签信息间的复杂映射关系,提取更为丰富的关联信息,使得相关人体姿态估计结果更为精准稳定。
目前基于深度学习方法的人体姿态估计算法普遍通过卷积神经网络估计人体中各个特征关键点的种类和位置,对关键点按指定的策略进行关联,获得二维人体样本目标的姿态估计结果。基于关键点和周围局部特征间的关系、关键点间的空间约束关系和人体姿态结构关系,文献[4]提出标准的人体姿态骨架模板,后续人体关键点的标注准则基本都是在此模板的基础上进行合理的增删。
本文对近十年来有关二维人体姿态估计在深度学习领域的相关工作进行整理分类,介绍相关人体姿态数据集基准,对相关思路方法进行对比分析,描述相关测评指标,总结该领域的研究现状,并对二维人体姿态估计的发展趋势进行展望。
1 相关数据集基准
由于研究早期资源的缺乏以及对人体姿态量化描述的差异,人体姿态数据集多集中于对单人局部姿态的标注,LSP[5]和FLIC[6]即为针对人体肢体姿态标注的数据集。随着人体姿态估计课题逐步受到关注,更多研究机构陆续开始数据集基准的设计。数据集MPII[7]将人体关键点标注个数完善到16 个,作为训练和评估单人姿态估计网络的基准。该基准对人体姿态的量化描述逐步趋于统一完善,样本数量初具规模,能支持全身范围的单人姿态估计以及多人姿态估计的研究。
MSCOCO[8]是2014 年发布的用于深度学习的综合性数据集。该数据集在2016 年对专门用于多人姿态估计的数据集进行完善,于2017 年发布人体关键点的标注并在随后几年对其进行相关维护。其将人体姿态的关键点标注增至17 个,并对每个人体样本标注了分割掩膜,使得标注信息更加完备准确,无论是在单人还是多人姿态估计方面,其在当前研究领域皆被公认为是最可靠的基准指标之一。
AI Challenger[9]给出与MPII 标准相似的用于竞赛的人体姿态数据集,其包含了海量的训练测试图像。Crowd Pose[10]从现有数据集中[7-9]共筛选出约20 000 张有关人体姿态研究的图片,统一采用14 个关键点进行标注,作为拥挤场景下人体姿态数据集。
常用人体姿态数据集成分对比情况如图1 所示,一方面数据集基准的扩充与完善推动研究方法的改进优化,另一方面研究方法的改进优化又对数据集基准提出更具体的要求,从而推动人体姿态估计研究的不断发展。
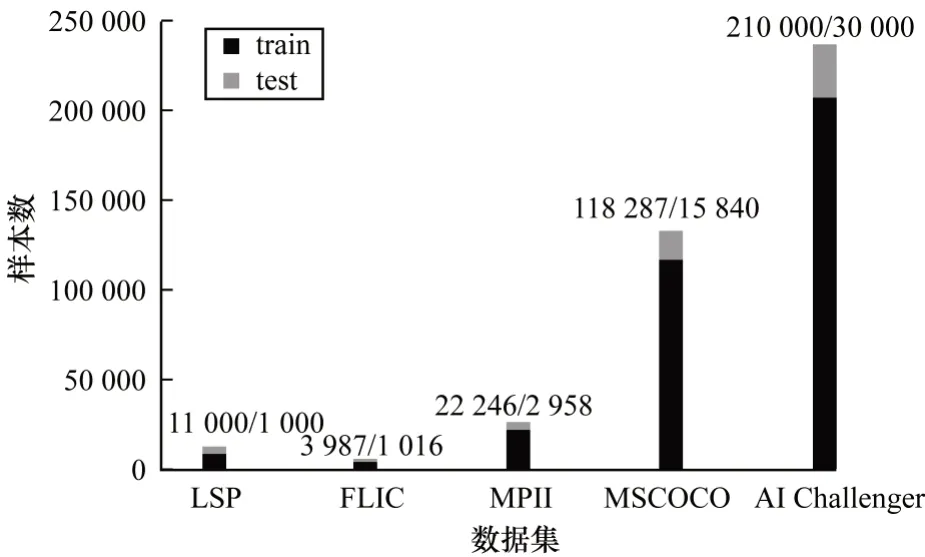
图1 常用人体姿态数据集的成分对比Fig.1 Composition comparison of commonly used human posture datasets
2 二维人体姿态估计的深度学习方法
通过深层卷积网络模型对样本图像进行特征提取,使得二维人体姿态估计方法可实现对人体的检测和关键点的定位,最终对关键点进行聚类关联,获得人体姿态估计结果。其依据所给定的标注信息对模型的预测结果进行测评,并通过反传误差信息更新人体姿态估计网络模型的参数,对人体姿态估计算法模型进行优化。基于深度学习的二维人体姿态估计方法按研究对象数目,将人体姿态估计问题划分为单人姿态估计方法和多人姿态估计方法。
在单人姿态估计问题方面,多幅图中同种类人体姿态关键点间的尺度差别通常较大,这种尺度差异性会对网络特征提取模块的设计造成一定的困难。因遮挡和不包含在图片上等情况所造成的关键点遗失,会对姿态估计网络的特征识别定位能力以及相关算法的后处理能力提出一定的要求,而且卷积神经网络规模普遍较大,所导致的反向传播梯度消失问题以及对姿态估计网络架构的改进和轻量化等问题也需要相关解决措施。
而对于多人姿态估计而言,在单人姿态估计中所遇到的诸多问题会被复杂化。在一幅图像中可以出现同种类但尺度差异悬殊的人体姿态关键点;不同人体之间的遮挡和重叠也会使相关网络模块与后处理算法对关键点的定位、所属以及分类产生歧义;而且随着图像中人体样本的增加,对卷积神经网络的特征提取能力也进一步提高,由此产生的网络参数规模扩大问题也难以避免。
针对以上问题,基于深度学习的二维人体姿态估计方法被分成单人姿态估计方法和多人姿态估计方法,如表1 与图2 所示。单人姿态估计多是对网络结构的设计和对输出结果的后处理,优化网络结构可以提高人体关键点特征的提取效率,丰富所提取到的特征内容,对输出特征信息的后处理可以提高预测结果的信噪比,并结合先验知识以及传统机器学习方法获得网络难以学到的关联信息。多人姿态估计按照对全局信息与局部信息执行顺序的不同,主要分为自底而上(Bottom-up)与自顶而下(Top-down)两种模式。自底而上的模式通过卷积网络检测并定位所有关键点,结合先验知识对关键点进行聚类和匹配,从而获得多人姿态估计结果。自顶而下的模式通过将多人目标检测和单人姿态估计方法进行结合从而实现多人姿态估计。
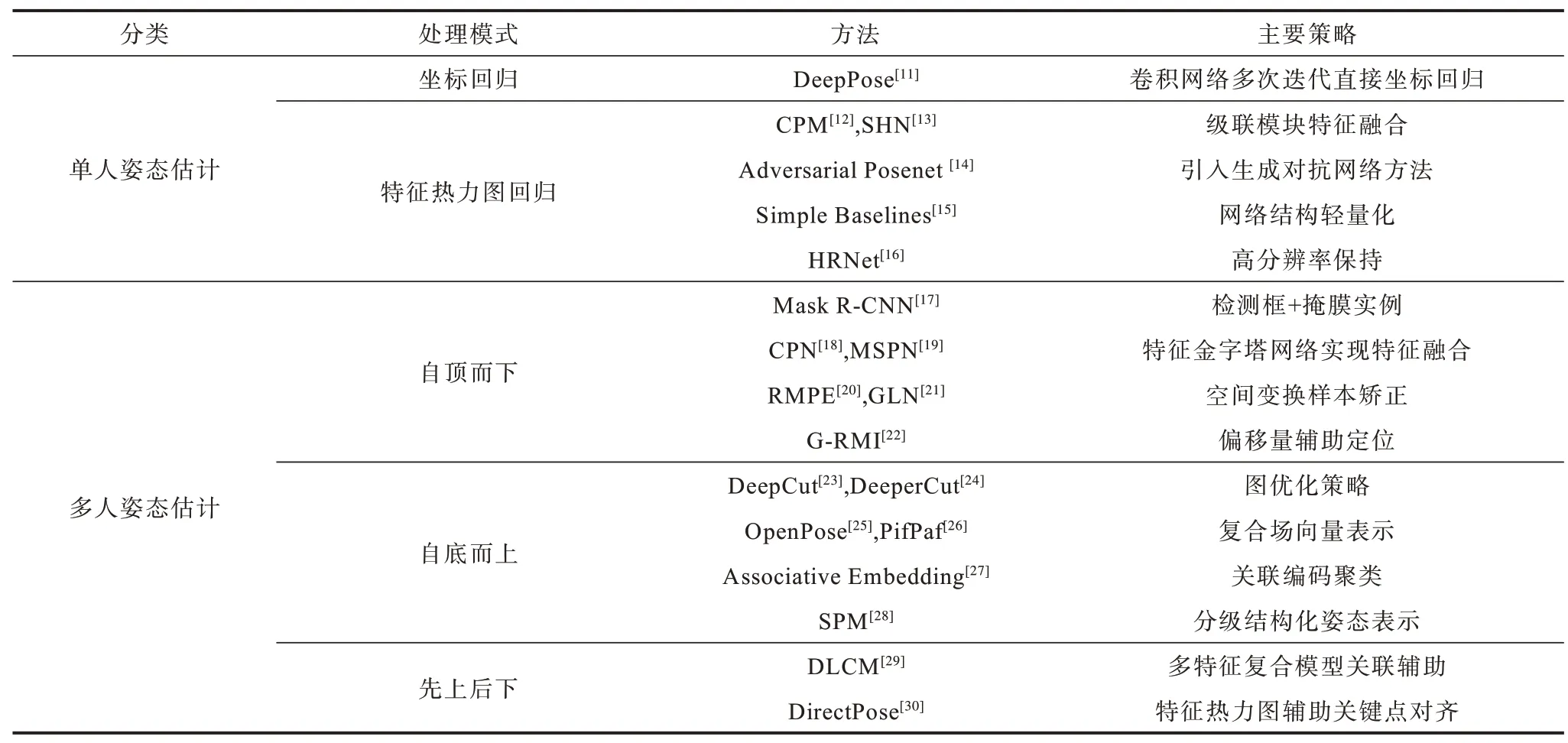
表1 二维人体姿态估计方法分类Table 1 Classification of two-dimensional human pose estimation methods
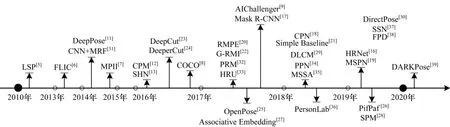
图2 近十年基于深度学习的二维人体姿态估计研究发展时间线Fig.2 Research and development timeline two-dimensional human pose estimation based on deep learning in the past ten years
此外,最近相关研究提出一种将两种模式相结合的多人姿态估计算法模式。由于该模式多数先以自底而上的模式提取所有的人体关键点获得初步的姿态估计结果,再自顶而下地对人体关键点进行精确定位,因此将其称为先上后下的多人姿态估计模式。
2.1 单人姿态估计
单人姿态估计的深度学习方法策略主要分为对网络结构的设计与对输出结果的处理。通常较深的卷积神经网络结构设计,可以提取更具体更深层的特征信息来解决同种类关键点的多尺度分布问题,有利于提高姿态估计模型的鲁棒性,单人姿态估计网络结构的设计大都采用多阶段的卷积网络级联架构;而针对如何对姿态关键点进行准确检测和定位,对输出结果的处理方法则可以分为以坐标回归为主的方法和以特征热力图回归为主的方法。其中,为了同时提高网络对人体姿态图像的局部特征和全局特征的提取,在特征热力图回归方法的基础上出现了许多有关多尺度特征的优化和多分辨率处理的方法。为避免网络估计得到现实中不存在的问题,基于生成对抗网络相关技术被应用于人体姿态估计方法。随着级联网络架构研究的不断加深,研究人员提出并改进减少人体姿态估计网络参数规模的方法。
2.1.1 坐标回归方法
坐标回归方法通过多阶段的卷积网络级联架构进行特征提取,在全连接神经网络上直接进行坐标回归,并进行多次迭代后得到姿态关键点的坐标估计结果。文献[11]将多阶段的卷积网络级联架构与人体姿态估计问题相结合,为人体姿态估计在特征提取方法上提出新的可能。文献[31]是一种多阶段卷积网络级联架构与马尔科夫随机场模型[40]相结合的单人姿态估计方法,多阶段卷积网络级联架构所输出的特征信息将被传输给马尔科夫随机场模型进行信息关联处理,最终仍由全连接网络对处理后的特征图像信息直接回归估计出坐标位置结果。
由于人体姿态信息纷繁复杂,仅靠直接坐标回归的方法很难得到精确的人体姿态关键点。虽然直接对关键点坐标进行回归求解的方法忽视了人体姿态关键点之间的特征关联信息,使得算法模型的泛化性能较差,但其多组卷积网络级联的姿态估计架构能够有效提取到丰富的人体姿态特征信息。这种以深度神经网络作为人体姿态特征提取器的方法在随后的相关研究中逐渐成为主流并衍生出多种经典的人体姿态估计网络架构。
2.1.2 特征热力图回归方法
为获得特征信息更为丰富的特征响应输出,网络需要对输入图像在更大的特征范围上进行特征提取,增大网络的特征感受野[41]是一种有效策略。通常可通过扩大池化层、卷积核尺寸和增加卷积层的策略增大网络的特征感受野。但是这些策略都有一定的缺陷:扩大池化层会导致原始特征信息损失,并对关键点定位的精度造成不可逆的影响;扩大卷积核尺寸则会使网络参数成倍增加,影响网络运行效率;而不断增加卷积层则会导致网络进行误差反向传播时的梯度消失问题。因此,在获得较大特征感受野的基础上尽量抑制其所产生的副作用是设计和改良人体姿态估计网络架构所要攻克的技术难点,目前较为经典的设计方法有:基于VGGNet[42]的多层卷积池化的下采样模块,通过多尺度特征级联的方式来弥补池化操作中的特征信息损失;基于ResNet[43]的残差模块结构,通过前馈连接策略保证反传梯度,确保网络层数持续加深。
以VGGNet为特征提取网络架构基础的卷积姿态机(Convocational Pose Machine,CPM)[12]构造了一个由多组卷积网络模块构成的级联网络架构。每组卷积模块通过采用多次卷积操作与池化处理不断扩张感受野尺度,提取获得特征感受野更大的人体姿态特征响应结果,结合之前网络模块的输出结果对特征图像进行像素级别的特征信息融合,其卷积核参数以及各层对特征感受野的扩张效果如图3 所示。
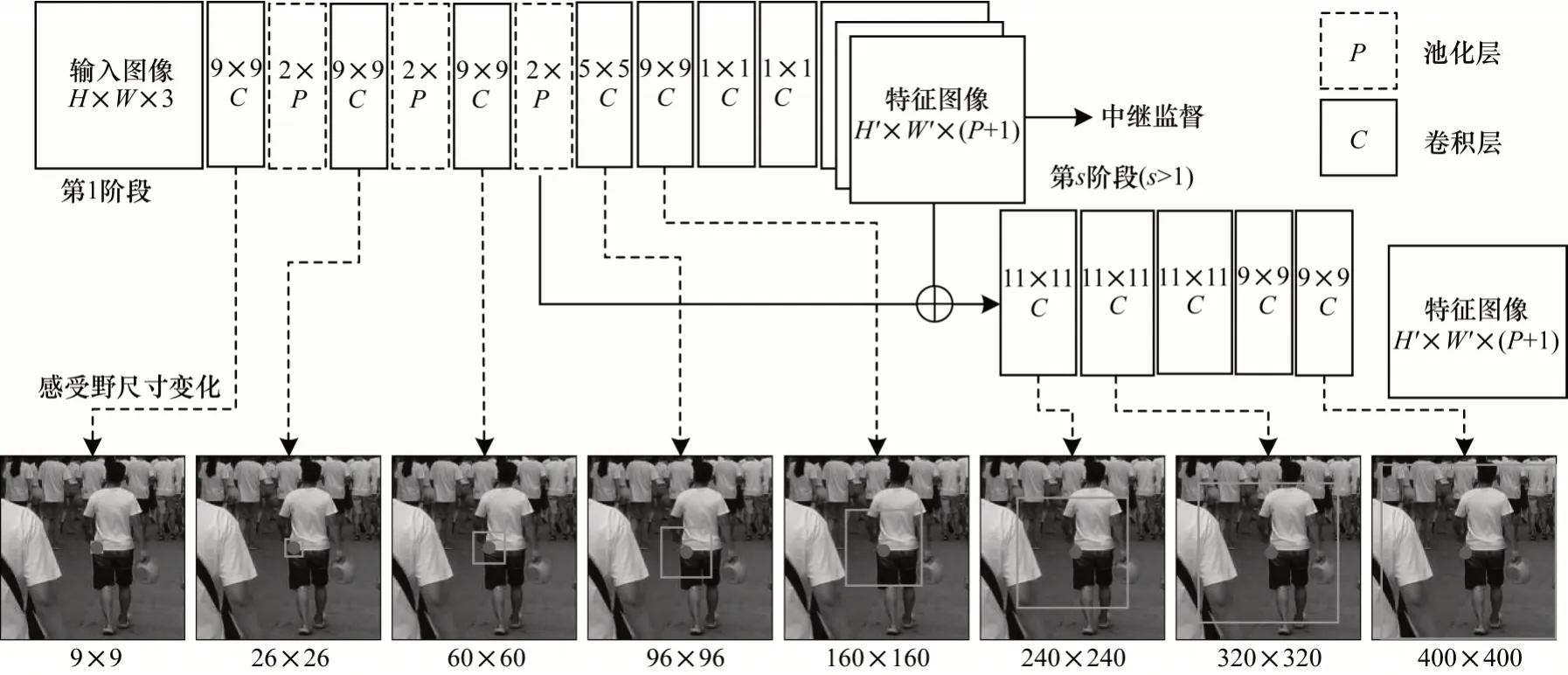
图3 CPM 网络模块中感受野尺寸变化与多尺度特征融合Fig.3 Receptive field size change and multi-scale feature fusion in the CPM network module
然而,为扩大特征感受野进行设计的多阶段级联架构使得网络过深。为防止误差反向传播时出现梯度消失,研究人员提出损失函数中继监督策略,即对每一组的输出计算损失函数,最终评判指标取决于各组累加的损失。基于空间的多尺度级联卷积神经网络架构,不再过分依赖于马尔科夫模型空间的复杂联系,一定程度上减少了算法复杂度。这种多尺度特征融合的思想被后续的相关研究所继承。
级联沙漏网络(Stacked Hourglass Network,SHN)[13]采用以残差模块为单元的多段级联式沙漏模型。其对U-Net[44]的网络拓扑结构进行改进,设计出的四阶沙漏模块用于对图像中的特征信息在各个尺度上进行充分提取。图4 所示为各个阶段的统一沙漏模块结构,通过级联多个残差模块来同时增加卷积层的深度以及卷积核的数量,不断扩大感受野。在沙漏模块的第四阶段得到最低分辨率和最大感受野的特征图像后,其仿照U-Net 的短连接(shortcut)策略,将模型前半部分的最终输出对应等尺度地传递给模型的后半部分。后半部分在分辨率较低的特征图像上采样到对应尺度,并与相应的前端输出在不改变特征通道数的前提下等尺度地进行叠加。然后再次通过相同的残差模块进行特征提取,形成与模型前半部分相对称的沙漏结构。
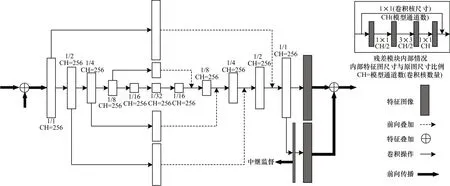
图4 SHN 架构中的四阶沙漏模块Fig.4 Fourth-order hourglass module in SHN architecture
为防止网络过深而造成的梯度消失问题,SHN同样采用了中继监督的训练策略。各阶段获得相应的特征热力图后,在训练过程中这些热力图响应结果将结合真实标注信息进一步获得其在各位置的置信度,并与本阶段网络的输入图像和最终输出图像进行融合,作为下一阶段的输入特征。而在之后各阶段的监督中也将进一步学习之前各阶段所提取到的特征信息。沙漏网络模型因其输入输出的等尺度结构极具可嵌入性,被后续诸多研究作为人体姿态特征提取器并加以优化和借鉴:其中基于沙漏模型提出的金字塔残差模型(Pyramid Residual Module,PRM)[32]通过多个分支网络下采样获取多尺度特征信息,并引入膨胀卷积替换池化过程所造成的信息丢失,使得因池化下采样所损失的原始图像特征信息能被加以利用。
简易网络架构基准(Simple Baselines)[15]对以上网络架构进行了更简易的改良。其前端采用ResNet进行特征提取,后端采用3 层尺寸为4×4 的转置卷积核来还原网络输入分辨率,最终达成端到端的人体姿态估计效果。由于其在调参、数据增强等方面使用了诸多技巧,如其对最终估计结果结合了特征热力图的最大值点朝向次大值点方向的偏移量,使得其在网络结构简易的情况下依然能够获得很好的人体姿态估计结果。
2.1.3 多尺度与多特征融合的优化策略
人体姿态估计不仅需要结合高级语境特征,还需要结合具体而细致的低级特征。由于视角的不同以及关键点类别差异,卷积网络对相同姿态关键点在不同尺度下的特征提取效果会打折扣,甚至出现错误的估计结果。文献[33]采用多语境注意力机制将沙漏模型优化为沙漏残差单元(Hourglass Residual Unit,HRU),使每个沙漏网络阶段均可输出多尺度注意力映射图像与多语义注意力的特征映射图像,将整体注意力模型得到的全局个体和局部注意力模型得到的人体局部姿态进行组合,实现多尺度端到端的人体姿态估计网络架构。多尺度结构感知(Multi-Scale Structure-Aware,MSSA)[35]网络在沙漏模型的基础上添加多尺度监督来加强语义特征学习融合多尺度的特征。此外,结构感知损失模块可以提高关键点的匹配程度并获得邻近关键点间的关联信息,对多尺度输出进行优化调整提升了姿态关键点的全局一致性。
从特征热力图到坐标的转换过程同样也会产生量化误差,因此,特征热力图到关键点坐标的解码过程至关重要。分布式感知坐标的姿态估计方法(DARKPose)[39]将输入人体姿态图像进行下采样以降低分辨率。为准确预测各关键点在原始图像中的位置,在得到特征热力图的预测结果后,需要对分辨率进行恢复后再转换回原始坐标空间。该方法能预测特征热力图的先验分布结构,并推断最大的潜在激活位置,从而获得精准的坐标预测。
采用卷积或池化操作降低图像分辨率来提高特征感受野范围的方法通常在采样过程中会产生量化误差,以致级联网络会将量化误差逐级传递,影响整体精度。高分辨率网络(High-Resolution Network,HRNet)[16]给出一种保持高分辨率的新型多层网络结构,以弥补原始图像信息因为特征感受野的扩大而造成的损失。如图5 所示,其在始终保持初始特征热力图分辨率的前提下,令不同层的级联网络在不同分辨率下对图像进行特征提取。通过不同层间特征信息的融合来获得更多的关联信息与语义信息以及精确的人体关键点定位,体现了空间分辨率的重要性。文献[45]对分辨率中高层获得的特征热力图进行特征再提取,进一步增加模型的鲁棒性和精确度。
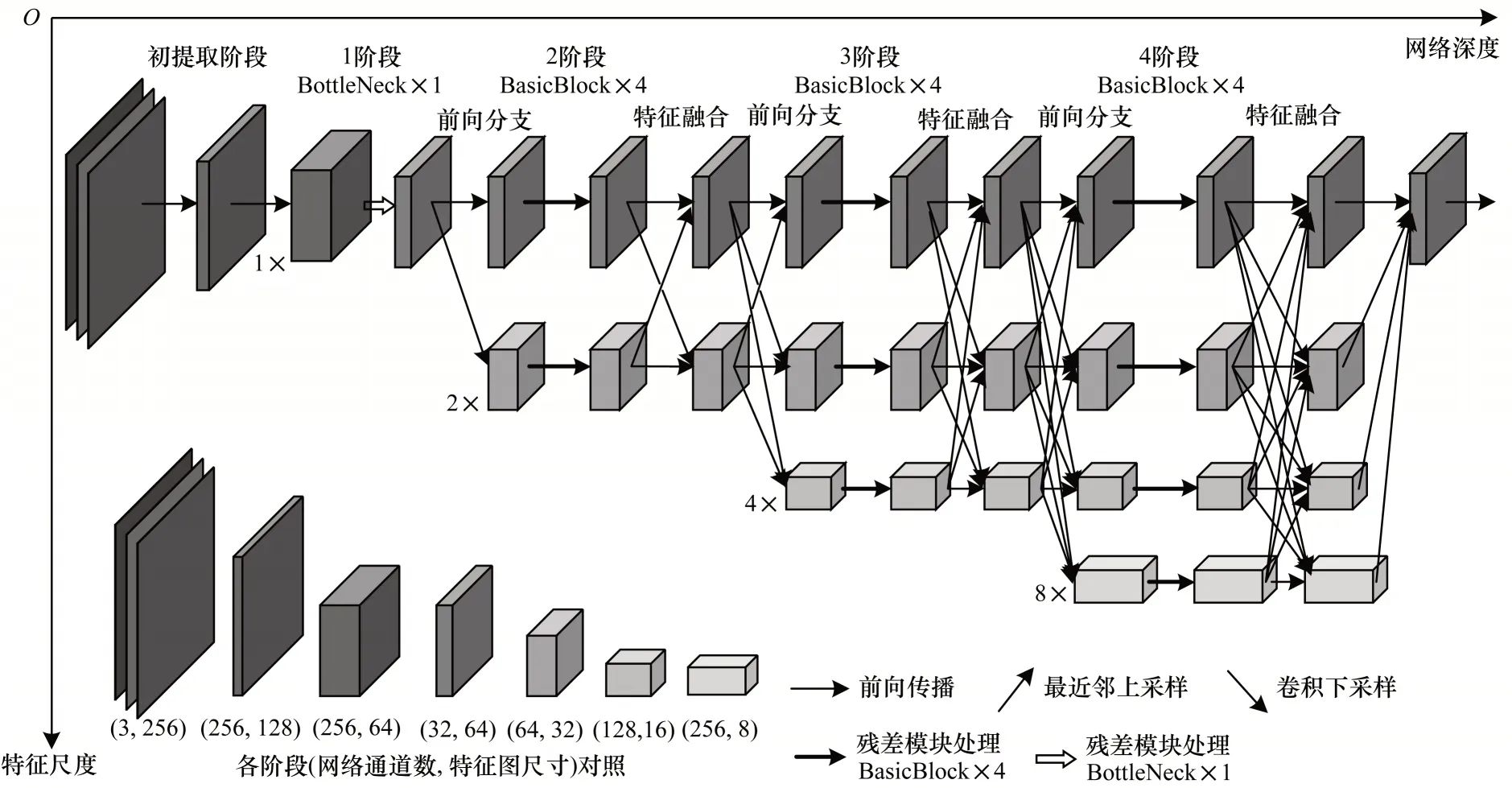
图5 HRNet 网络架构Fig.5 Architecture of HRNet network
2.1.4 生成对抗网络方法与轻量化姿态网络模型
由于人体部位的遮挡和重叠,在姿态估计中会产生许多虚假姿态结果。参考生成对抗网络的思想,通过姿态发生器产生人体姿态结果,利用关键点间的几何关系来加以约束设计鉴别器,便可判别人体的真实姿态和虚假姿态。生成姿态网络[14]即采用了这一思路,在其基础上进行改进的自对抗训练方法[28]利用沙漏模型级联网络架构分别组建人体姿态生成器和姿态判别器。前者用于人体姿态的模拟生成与估计,后者则结合人体姿态样本的真实结果对生成器的姿态估计结果进行判别,并将生成对抗误差反传回生成器,使生成器能通过学习获得二维人体姿态结果。
优先选择参数规模较小的网络模型作为特征提取网络架构是一种较为直接而有效的方法。空间短连接网络(Spatial Shortcut Network,SSN)[37]以U-Net为基础网络架构,通过建立特征信息的远程空间依赖关系提高了网络的浅层探测能力。其对特征映射信息的处理主要分为用于特征移位的主模块和预测特征间关系的特征移动模块中,实现空间信息的低成本流动。网络压缩也可以实现姿态估计网络架构的轻量化。快速人体姿态估计模型[38]将沙漏模块的规模缩小一半获得快速姿态蒸馏模型,然后采用知识蒸馏的策略使原生级联沙漏网络来引导学生网络进行训练,最终得到的轻量级模型几乎不损失精度。
2.2 多人姿态估计
多人姿态估计方法的基本策略按照对全局信息与局部信息执行策略的顺序不同被分成自顶而下和自底而上两种模式,以及对两种思想综合利用的先上后下模式。
自顶而下的多人姿态估计模式借助已有多人目标检测方法对图像多个人体区域进行检测和提取,之后再使用单人姿态估计方法对逐个人体检测区域进行关键点的识别和估计。因为事先进行多人目标检测的原因,采用自顶而下模式的多人姿态估计网络所得到的结果很大程度上避免了多人姿态估计结果的歧义性,但由于其在检测后还要进行多组单人姿态估计,且受限于多人目标检测方法的时效性,采用自顶而下策略的多人姿态方法在实时性上仍尚需改进,其改进策略多针对目标检测方法与姿态估计方法的匹配关系。
自底而上的多人姿态估计模式则是直接对图像中所有人体姿态关键点进行检测和定位,再结合姿态关键点之间的先验关系,使用相关的算法对人体姿态关键点进行筛选以及相互匹配,最终实现对多个人体的姿态估计。虽然自底而上的模式对所有关键点采取一次性提取的措施可以极大地提升多人姿态估计方法的时间效率,但是在对多组不同点中间进行特征关键点匹配时,多个相同种类的关键点间会对算法匹配造成很大的干扰。因此,如何降低相同关键点之间的干扰,并对不同种类的姿态关键点进行最优匹配是对自底而上的多人姿态估计方法进行改进与优化的难点。
与自顶而下和自底而上的模式不同,先上后下的模式结合了当前两种多人姿态估计模式的特点,先自底而上地对图像进行各关键点的特征位置提取,再采用自顶而下的方法对各个人体姿态估计进行进一步的组合与定位。这种采用人体目标检测与关键点提取对多人姿态联合进行估计的策略,可以有效提升最终的定位精确度。因此,如何对两者进行协调和结合是先上后下模式要解决的问题。
2.2.1 自顶而下方法
最初被用于多人姿态估计方法的多人目标检测模型为faster R-CNN[47]。Mask R-CNN[17]在其基础上进行检测框回归,并使用像素到像素对齐的方式对每个感兴趣区域都增加一个像素级别的实例分割预测,在逐像素地获得对应的二进制编码掩膜后,便可对已有的目标检测对象进行多人姿态估计。这种借助人体目标检测与实例化分割的姿态估计策略保证了多人场景姿态估计的准确性,但对所检测到的多个人体目标进行重复估计的方法占用了大量的空间资源,在追求高准确率与高精度的同时一定程度上牺牲了检测效率。
Mask R-CNN 的特征提取网络为增大特征感受野,而聚合空间特征信息所采用的降采样操作会影响网络输出的特征响应热力图与输入图像之间的位置对应关系并造成量化误差。同样以faster R-CNN作为人体目标检测器的G-RMI[22]人体姿态估计,则运用对关键点的坐标定位信息与坐标偏移量进行结合的人体姿态估计方法。其对特征热力图通过双线性插值方法将关键点间的坐标短程偏移量(shortrange offset)与坐标定位信息以霍夫投票的形式进行高度化的特征局部激活。这种采用关键点位置响应与偏移量的聚合方法明显改善了特征下采样操作所导致的量化误差问题。
针对多人姿态估计中因遮挡或重叠导致的实际关键点不可见等问题,级联金字塔网络(Cascaded Pyramid Network,CPN)[18]通过应对困难关键点的检测定位进行优化处理。在利用多人目标检测器获得检测边界框后,使用级联的特征金字塔网络对人体检测边界框内的信息进行关键点检测。如图6 所示,CPN 被分成对边界框中人体图像信息关键点进行粗提取的特征金字塔全局网络(GlobalNet),以及用于后续对不同层间关键点粗提取信息进行特征融合后再对关键点综合精确定位的优化网络(RefineNet)。对于特征可见的易分辨人体关键点可以通过GlobalNet 直接获得,而对于因遮挡而不可见的或是因背景复杂而难以分辨的人体关键点,则需要通过RefineNet 进一步增大感受野来对GlobalNet定位误差较大的关键点进行修正。
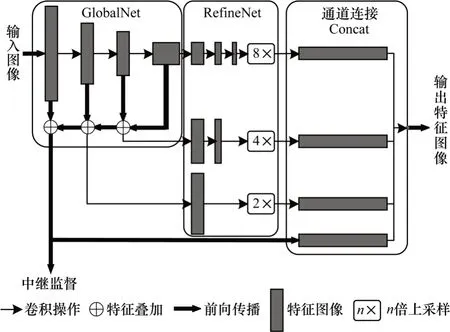
图6 级联金字塔网络模块Fig.6 Module of cascaded pyramid network
多阶金字塔网络(Multi-Stage Pyramid Networks,MSPN)[19]则是对GlobalNet 进行多级堆叠,得到的特征热力图金字塔融合了更多尺度特征,即通过加深网络深度以扩大粗提取阶段的特征感受野,并不断进行多尺度特征融合对不同层间的特征信息加以关联。层数较深的RefineNet 获得的高层特征信息的感受野较大,可用来推断不可见的困难关键点,而通过多组级联后加深的GlobalNet 所提取到的低层特征信息,不是仅对各关键点进行粗提取,而是以其较高的分辨率以及较为丰富的多特征融合信息来精确地定位关键点。
然而级联金字塔网络只考虑采用不同尺度间的特征融合来提升网络对困难关键点的检测性能,并未对通道间的信息进行关联融合。空间信息与增强通道(Enhanced Channel-Wise and Spatial Information,ECWSI)方法[48]以级联金字塔网络作为基础网络架构,为增强GlobalNet 各层之间特征图像的跨通道关联,其先用尺寸为1 的卷积核将每层提取的特征维度升至256,再对这些特征连接并使用通道随机重组的操作进一步融合这些来自不同层级的特征,之后对融合后的特征信息依次进行分组并再次映射到原始的特征维度,最终再次使用尺寸为1 的卷积核对融合各层特征的信息进行聚合,获得最终的表示结果。在学习空间位置特征的权重时,与级联金字塔网络对目标边进行边界框的特征粗提取方式不同,其利用通道特征随机重组的方式对人体目标检测结果的每个位置进行学习,最后的估计结果也较级联金字塔网络有所提高。
对于更为复杂的人群拥挤场景,由于人体之间的重叠密度过大,导致检测器所获得的定位区域内含有其他人体关键点的信息,且所检测到的人体姿态不如单人姿态估计规范,从而出现倾斜或者大范围区域不可见的情况。为此,区间多人姿态估计(Regional Multi-Person Estimation,RMPE)方法[20]选用SSD(Single Shot MultiBox Detector)[51]为检测器,级联沙漏模块为姿态估计网络架构,构成自顶而下的多人姿态估计模型AlphaPose。为解决多人关键点的匹配问题,其在获得多人检测结果后采取并行网络,并采用空间变换网络(Spatial Transform Network,STN)[50]进行正则化矫正以便获得更精确的人体姿态估计结果。
同样对人体目标检测器输出的人体检测结果进行规范化处理,全局与局部规范化(Global and Local Normalization,GLN)[21]的优化思路并非先对整个人体姿态图像进行空间信息规范化后再进行关键点检测,而是先通过简单的全卷积神经网络对检测到的各单人人体姿态图像进行初步的关键点定位,然后对人体朝向、躯干与四肢采用白化处理的方法进行空间特征规范化处理,并再次使用全卷积神经网络对各关键点进行定位上的微调,进而获得精确的姿态估计结果。
2.2.2 自底而上方法
人体姿态关键点之间的连接可以被视为加权的图模型,因此针对多人姿态估计问题,在通过特征提取网络获得所有的关键点响应之后,可以采用图优化的方法完成各关键点间的匹配连接。文献[23]构建一种DeepCut 的多人姿态估计网络架构,其采用自适应的fast R-CNN,首先对人体关键点的局部候选区域进行初步的特征提取,所有被提取检测获得的候选点都将被视为节点,对提取到的所有候选点进行全连接,然后将属于同一人的节点归为一类,对所检测的节点标记,确定其所属关键点类别,通过对其连接权重采用整数线性规划(Integer Linear Programming,ILP)进行求解,最终将对应的关键点聚类为人体姿态,但采用目标检测器提取关键点策略和线性规划的关键点连接优化策略的计算复杂度非常大,导致DeepCut 实际处理人体姿态估计问题的速度过低。文献[24]对文献[23]方法进行相应改进并提出DeeperCut 架构,其特征提取部分改用ResNet 进行关键候选点提取,采用图像成对匹配策略,通过候选点之间的欧式距离进行判断,将众多相距过于接近的候选区域内的节点进行合并压缩,减少了候选区节点的数量并有效提升了模型效率。
另外,采用目标检测器进行关键点位置信息提取的还有姿态提名网络(Pose Proposal Network,PPN)[34],其将YOLO(You Only Look Once)[51]与CPM 相结合,把姿态检测定义为目标检测问题。PPN 将一幅人体关系复杂的图像分解为多幅相对简单的多人图像,分别生成多人关键点匹配关系,实现了对视频图像的实时多人姿态估计。但通常图像中人的数量、位置和尺度大小都是未知的,人与人之间的交互遮挡会影响检测效果,且运行时间随着图像中个体数量增加,很难做到实时检测。
文献[25]借鉴CPM 模块,构建OpenPose 并联网络架构。首先运用VGG 网络对图像进行特征粗提取,以CPM 为基础组成并联网络模块,用以提取人体关键点位置特征与所定义关键点的连接特征。每组支路网络分别进行6 次网络级联,获得关键点定位信息的局部置信度图(Part Confidence Maps,PCMs)以及关键点间关联信息的局部亲和域(Part Affinity Fields,PAFs)。然后根据候选关键点响应值与对应肢体连接向量采用匈牙利算法[52]进行多组最优二分图匹配,选择最小数量的边来获得人体姿态的骨架而非使用关键点的全连接图,将匹配问题进一步分解为多组二分匹配子问题,并独立确定相邻部位节点的匹配关系,最终获得所有人体姿态估计的结果。
为防止多阶段级联所造成网络训练中梯度误差消失的情况,两组支路都采取了中继监督的策略,在各阶段的每个分支结尾,分别对所获得的关键点响应热力图和肢体连接关系响应图按类别进行加权的欧氏距离误差计算。此外,在进行下一阶段的特征提取之前,各支路前一阶段的输出结果需要与最初的粗提取特征图以及同一阶段另一支路输出的特征图进行融合,丰富特征图各尺度的信息。对于各关键点的PCMs 的标注采用高斯函数作为掩膜,遇到同时被两个相同关键点影响的情况则采用具有较大响应值一方的策略;而对PAFs 标注的设置则采用向量表示方法,距离信息用来表示关键点间的关联程度,角度信息则表示估计结果与真实结果间的匹配程度。
后续相关的研究[53]针对OpenPose 的特征提取网络模块进行调整优化,将原有的并联结构改为先进行对局部关联特征的提取,再结合原始粗提取特征进行关键点位置特征的提取。这种结构有效地减少了原始并联网络中的多次特征融合,且因为依旧采用中继监督的策略,使得网络由并联到级联的改动对于训练时的误差反向传播并未造成较大的影响。随着图像中人数的增加,OpenPose 会随着人数的增加而呈线性增长,进行级联改进后的算法运行时间则随着人数的增加基本保持不变。
为保证定位精度,文献[36]提出PresonLab 方法,基于ResNet 对所有的人体姿态关键点进行特征提取以及偏移量预测,引入中程偏移量来应对实例间的特征关联问题。文献[26]则同时借鉴了OpenPose 中的PAFs 和描述关键点偏移信息的局部响应强度(PIFs)。通过PIFs 获得类似偏移信息的全部候选点,并根据PAFs 获得各候选点间的关联信息,以高斯核函数代替G-RMI 中的双线性插值方法,匹配获得各人体的姿态估计,进一步提升关键点定位精度。
采用关键点偏移信息策略的单阶段姿态模型(Single-stage Pose Model,SPM)[28]如图7 所示。通过对级联沙漏网络进行改进,获得结构化姿态表示模型并在此基础上进行特征信息提取,输出的关键点特征仅包含一个人体基准关键点的位置信息,该基准点分别指向其余各关键点的偏移量。为避免个别关键点偏离基准点过远而造成模型难以收敛,模型输出进行以下具体优化:采用关键点分级策略,在类别位置相邻最近的关键点间通过偏移量建立位置依赖并相互牵制。最终按约束构建的多人姿态估计网络因其关键点间形成多级制约提高了人体关键点的匹配准确度。
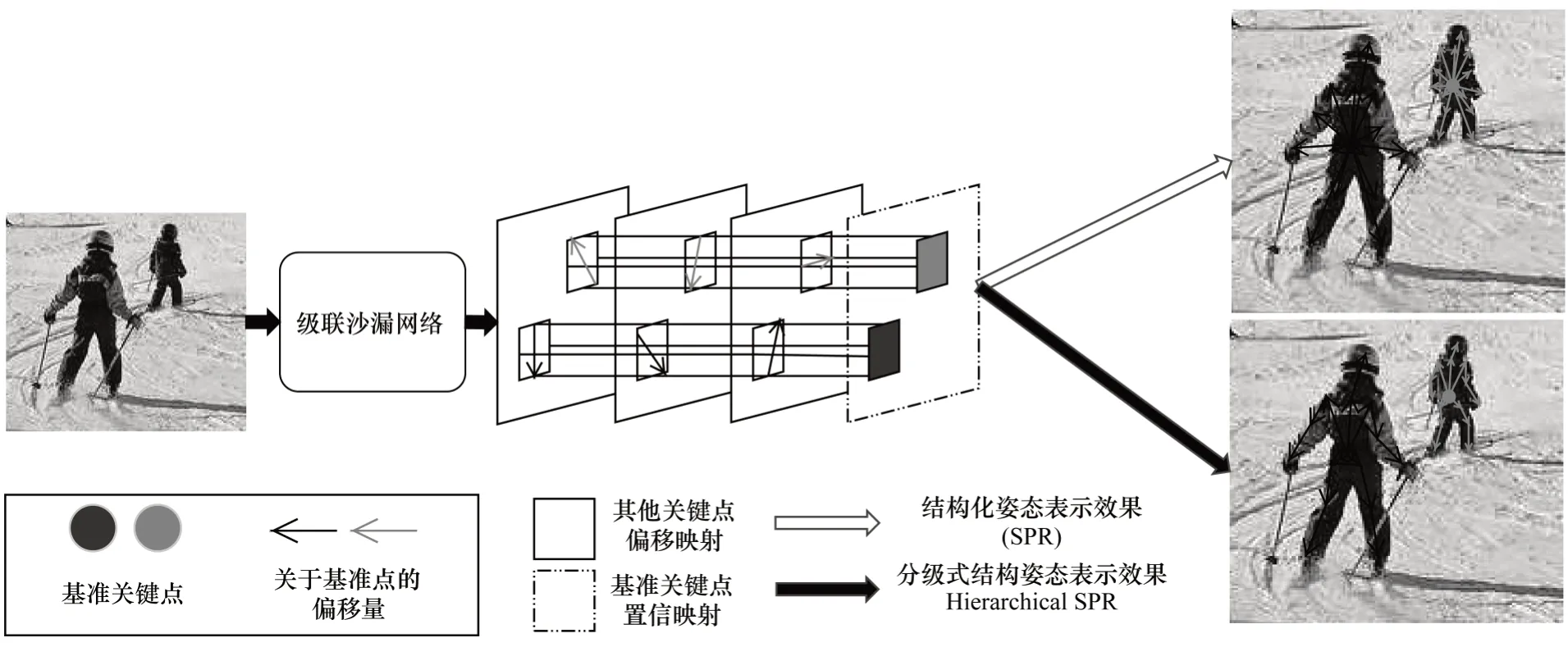
图7 SPM 网络架构Fig.7 Architecture of SPM network
除采用偏移量进行个人姿态范围的约束外,运用类似分类网络的编码方式对同属一个人体下的不同种类关键点进行聚类的方法,能够有效解决多人姿态估计中的关键点匹配问题,如图8 所示。关联编码方法[27]也是采用级联沙漏网络提取特征信息获得各个部位的关键候选点,根据关联信息嵌入方法,对各候选点都输出一个嵌入式编码标签,使同属一人的关键点的嵌入式标签数值尽可能相近,不同人的尽可能不同,并将多人姿态估计问题转化为对特定关键点的聚类问题。
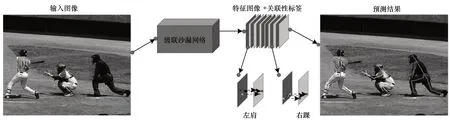
图8 Associative Embedding 网络架构Fig.8 Architecture of Associative Embedding network
2.2.3 先上后下方法
近年来,研究人员提出不依赖anchor-free 基准框的目标检测理论并得到证实。不同于faster RCNN 等依赖anchor-based 目标基准框的目标检测方法,anchor-free 利用对图像特征点的定位信息实现目标检测。对于人体姿态估计而言,人体的姿态关键点可被视为具有至少2 个边缘点的特殊边界框。因此,通过将姿态估计网络的输出附加到基于anchor-free 的目标检测网络,能够更好地解决人体关键点定位任务,即先自底而上后自顶而下的姿态估计策略,DirectPose[30]是一种端到端的关键点检测框架,如图9 所示。该框架可以直接把输入图像映射到所对应的人体实例关键点上,既不依赖先验的人体检测框,也不需将检测到的关键候选点进行分配,而是在目标检测算法FCOS(Fully Convolutional One-Stage)[54]的基础上添加关键点对齐模块,将特征热力图响应与目标关键点对齐,然后采用直接坐标回归的方法得到目标关键点的坐标,最终获得姿态估计结果。DirectPose 不依赖自顶而下中先验的人体目标检测框,且与自底而上中启发式地将检测到的关键点匹配到对应的人体实例不同。该算法无需对特征响应图进行预测而是直接对坐标进行回归,这样避免了使用特征响应图所带来的固有编解码偏差。
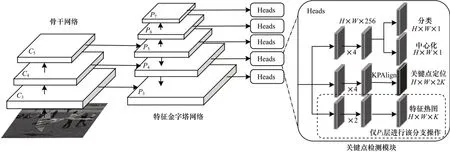
图9 DirectPose 网络架构Fig.9 Architecture of DirectPose network
为了尽量解决通用的姿态估计网络结构因遮挡、人体之间接触以及背景杂乱所导致的错误,进一步提高多人姿态估计的精度和效果,文献[29]对级联沙漏模型的姿态估计网络模块进行微调,并引入关键点组合方法,获得先上后下的组合模型(Deeply Learned Compositional Model,DLCM)。模型对自底而上的模式进行调整,定义每个关键点为最低级部件,低级部件可以组合为高级部件,最终组合为一个个完整人体。首先对图像进行低级部件的初步提取,再依次迭代估计高级部件的特征信息,在进行自顶而下过程中的低级部件的特征信息可以从高级部件信息中估计获得,最终实现以高级部件为主的人体关键点关联约束和以低级部件为主的关键点定位。
但是对低级部件组合为高级部件的行为不加以合理的约束会引发组合爆炸问题。DLCM 根据沙漏模型网络的结构提出一个五阶段的卷积网络模型,前三阶段进行自底而上的从低级部件到高级部件的特征复合,后两个阶段则是自顶而下地将获得的高级部件特征还原为低级的关键点特征,同时进行基于各级部件的中继监督。此外,在自顶而下的过程中,当前部件的特征图像将结合自底而上所生成的同级部件的特征图像后再进行下一阶段的特征还原。自底而上的改进过程有效地解决了关键点的误匹配问题,且在中继监督中采用了类似OpenPose 中包含方向、尺度等信息的特征响应热力图,其在应对因遮挡等干扰情况时使得模型的姿态估计结果鲁棒性更强。
3 相关研究方法对比与总结
纵观二维人体姿态估计在深度学习领域从单人姿态估计到多人姿态估计的发展情况,在转向多人姿态估计研究进程中,其分化成自顶而下与自底而上两大主流模式。前者推动了目标检测领域的发展,后者则推动新的匹配策略的出现,而两者结合又产生了先上后下的新姿态估计模式。
从改良人体姿态估计的方式来区分,又可分为对姿态估计网络架构的改进与对网络输出特征的处理策略的设计。前者主要针对网络拓扑结构的改进,致力于寻找最优的网络结构,不断挖掘神经网络可发挥的潜能;后者则更加关注网络的输出表示,突破固有框架寻找能进一步提升性能的经验和技巧,而损失函数的选取也会影响到网络的收敛性能。
3.1 网络架构设计
如表2 所示,二维人体姿态估计方法按姿态估计网络架构可分为以CPM 为主的多阶段级联式结构、以SHN 为主的沙漏模块级联式结构、以CPN 为主的两段式结构和以HRNet 为主的多分辨并联结构。
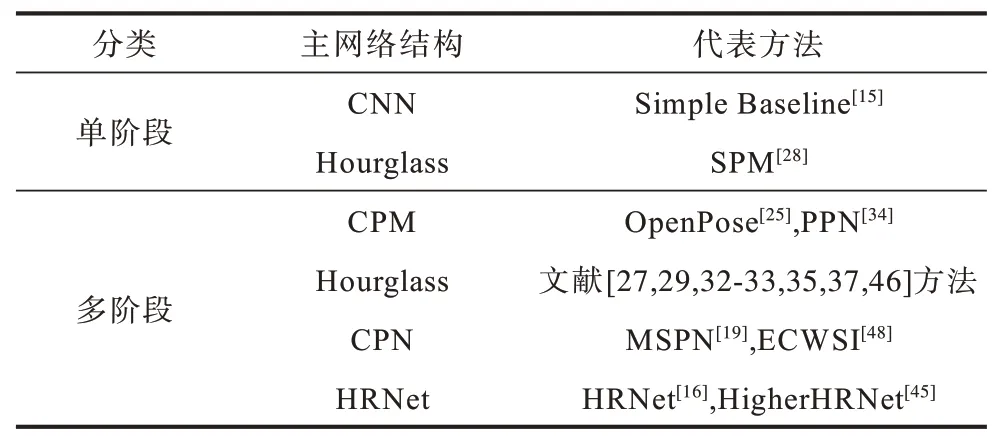
表2 经典人体姿态估计网络架构对比Table 2 Comparison of canonical human pose estimation network architectures
CPM 衍生出诸如OpenPose 多人姿态估计的经典方法,构建了多阶段级联姿态估计网络架构,PPN则将其与YOLO 相结合实现对高帧频视频的多人姿态估计。而有关沙漏模型的拓展研究则更多,无论是自顶而下模式中的单人姿态网络,还是自底而上模式中的主题网络架构,或是用于知识蒸馏中的教师网络,除性能优良外,其优美的设计结构也获得业界的承认,类似情况还有目标检测领域的YOLO 和语义分割领域的U-Net。
CPN 特征金字塔架构的两段网络结构分别对应自顶而下模式中的目标检测和姿态估计,如MSPN和ECWSI,前者是将前端的特征提取结构GlobalNet进行多阶段堆叠,提高了检测精度,后者则在CPN 上添加注意力机制模块,实现了多尺度特征融合的均衡化。而HRNet 的多分辨网络并联结构则避免了之前网络结构中频繁使用采样和池化导致尺度信息改变而造成的量化误差。
3.2 特征处理的输出表示
如表3 所示,人体姿态估计方法可按输出结果分为坐标回归输出表示、特征热力图输出表示和特征热力图及其他信息的输出表示。
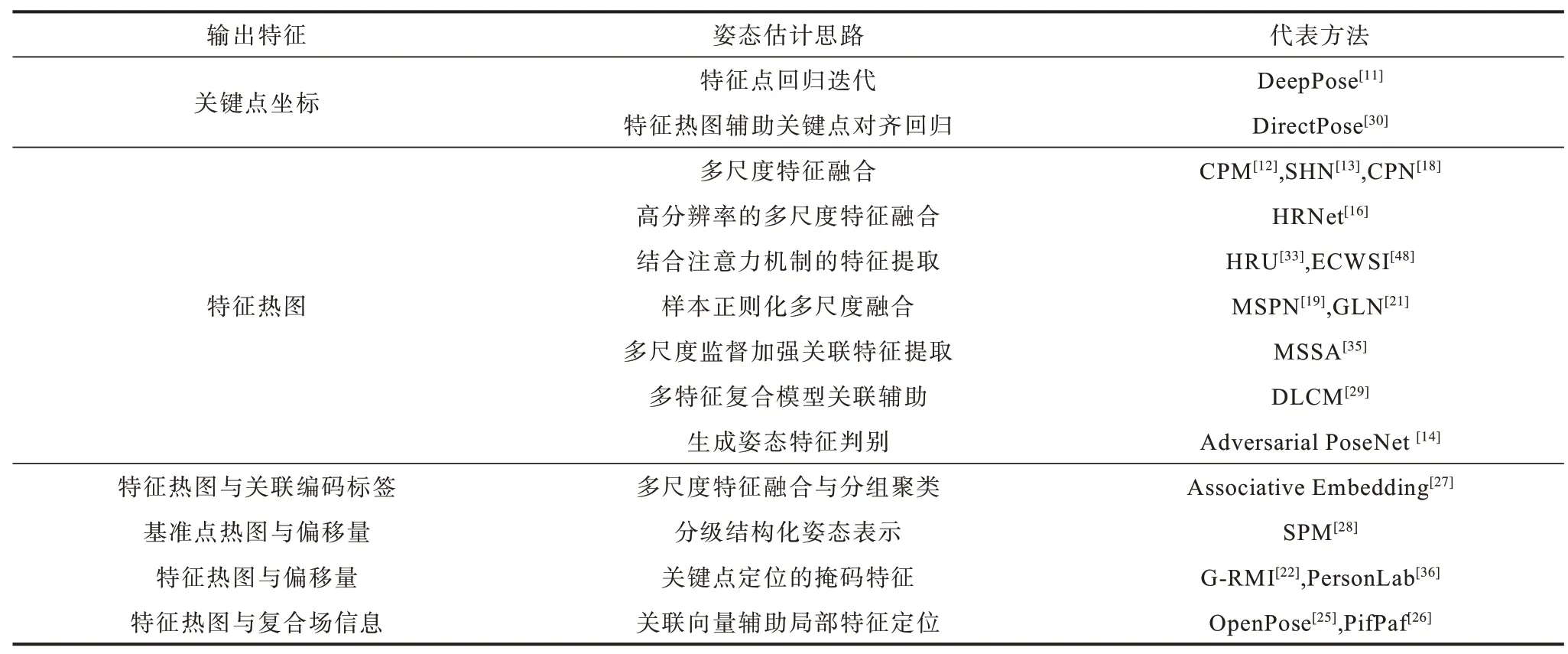
表3 人体姿态估计输出特征对比Table 3 Comparison of human pose estimation output features
直接坐标回归输出表示是最直观的一种思路,最初将深度学习方法用于人体姿态估计的DeepPose 便是使网络通过有监督的训练回归获得关键点坐标。但由于直接训练所得的关键点回归网络其泛化能力较差,直到DirectPose 在坐标回归方法中引入关键点对齐机制前,特征热力图的表示方式才逐渐占据主流。CPM 将多阶段特征热力图通过融合获得各关键点的特征热图。其后的沙漏模块、CPN 等网络结构均采取相同的方法。在评估损失时其对估计结果保证了一定柔性,使得网络的泛化性能提高。
而在特征热力图的基础上同时生成向量场嵌入信息则需要在一定程度上扩大网络结构,OpenPose和PifPaf 中的PAFs 便是通过多阶段神经网络提取出各关键点间关系向量,类似的还有生成人体关联编码标签的Associative Embedding 方法。
姿态网络基本以人体的各个关节点特征提取为主,DLCM 将姿态估计网络提取到的粗略关键点估计结果进行多次迭代提取高阶部件信息,通过部件关联辅助其所有关键点的定位。SPM 是获得各人体的基准关键点和基准点与其他关键点的偏移信息来表示人体姿态,而G-RMI 则是引入偏移信息来辅助关键点进行精确定位。
3.3 损失函数选取
损失函数用于评估预测值与真实值之间的差异,能对模型进行有效的指导。二维人体姿态估计损失函数的裁定与设计需要参考姿态估计方法所采用的网络结构和预测结果,如表4 所示。
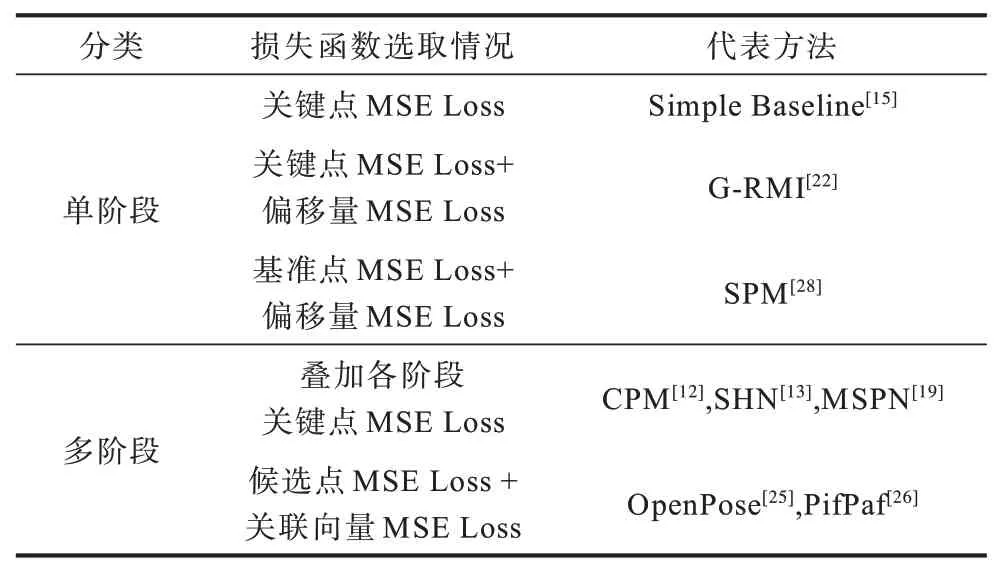
表4 不同策略中损失函数的选取Table 4 Selection of loss function in different strategies
人体姿态估计方法按网络结构大致可分为单阶段与多阶段。其中单阶段结构的损失函数仅需对网络最终输出计算一次便可评估模型,而多阶段由于网络的不断加深,若仅对网络最终结果的输出计算损失,则因网络过深导致的梯度消失问题会使网络参数更新停滞。而在各网络阶段添加合适的损失函数可有效缓解该问题,即引入损失函数对网络的中继监督策略。多阶段结构姿态估计的中继监督损失函数计算如式(1)所示:
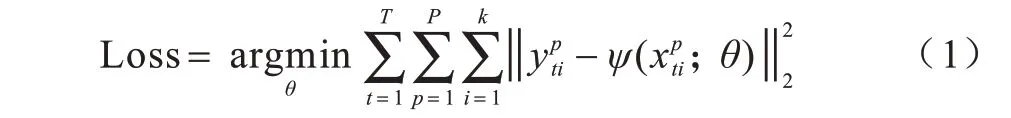
其中,k是关键点种类数,P是预测候选点数,T是网络结构阶段数,y为网络输入样本x的真实标签,ψ(·)为网络模型,θ为模型相关参数。
姿态估计方法按输出预测结果可分为回归坐标方式、回归特征热力图方式和回归特征热力图及其他信息的方式。回归模型的损失函数以均方误差函数为主,而坐标和特征热力图在本质上输出的是关键点位置信息,当正负样本信息均衡时,误差信息一般多以L2 范数的形式表示。
此外,在线困难关键点挖掘[55]是针对样本中的困难关键点进行监督而不再是所有的关键点,其在CPN 等网络的训练过程中均被采用。Focal Loss[56]则是为了解决数据集中正负样本比例严重失衡的问题,其主要是在针对拥挤人群情况下被采用。
4 评测标准
早期数据集LSP 和FLIC 主要是对部分肢体关键点进行标注,故而最早的度量评价指标PCP(Percentage of Correctly estimated body Parts)[57]是依据肢体的标注长度进行,如式(2)所示:
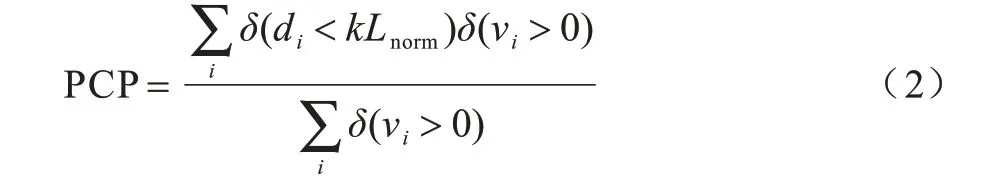
如果关键点i的预测位置与真实位置间的欧式距离di小于标准肢体长度Lnorm的一定比例k(通常为0.5),则判定预测准确(通常表示为PCP@0.5)。PCP用以划定肢体关键点检测的阈值,值越高,模型对关键点的定位效果越好。由此改进的PDJ(Percentage of Detected Joints)规定,关键点的预测位置与真实位置间的距离小于躯干对角点的长度Ldiag的一定比例,则判定预测准确。
MPII定义的PCK(Percentage of Correct Keypoints)规定,将关键点的预测位置与真实位置间的距离小于头部长度Lhead作为归一化参考,称为PCKh,如式(3)所示:
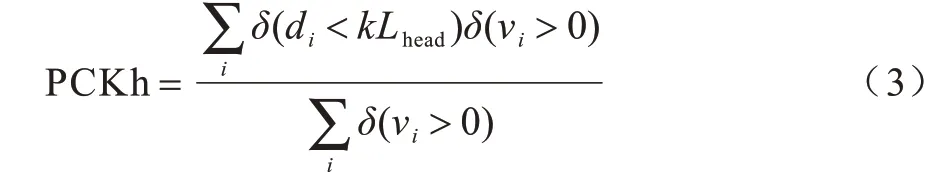
随着多人姿态数据集的普及,尤其是MSCOCO发布后,一系列以固定阈值作为判定依据的评测标准不再适用于对同一幅图中的人体尺度差异较大的情况。因此,MSCOCO 设计了测评标准目标关键点相似度(Object Keypoint Similarity,OKS),其定义如式(4)所示:
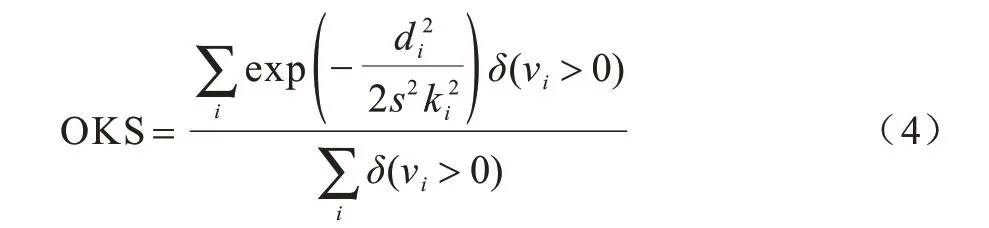
其中,di是关键点检测位置与标注位置之间的欧式距离,vi>0 代表关键点i在图上被标注,s是尺度参数,ki是控制各关键点响应衰减程度的超参数。
按照不同尺度对人体目标中各类关键点进行高斯分布,分别定义标准化的阈值评测标准并设计目标关键点相似度,使用不同的精度阈值来补偿关键点的定位信息。
上述两种有关人体姿态估计的评测标准都针对关键点的欧式距离误差,其中PCK 更注重建立固定的归一化阈值标准,而OKS 对不同尺度目标的相同关键点进行归一化处理。表5 和表6 为不同人体姿态估计方法在相关数据集上的测评结果,其中,“—”表示没有官方数据。
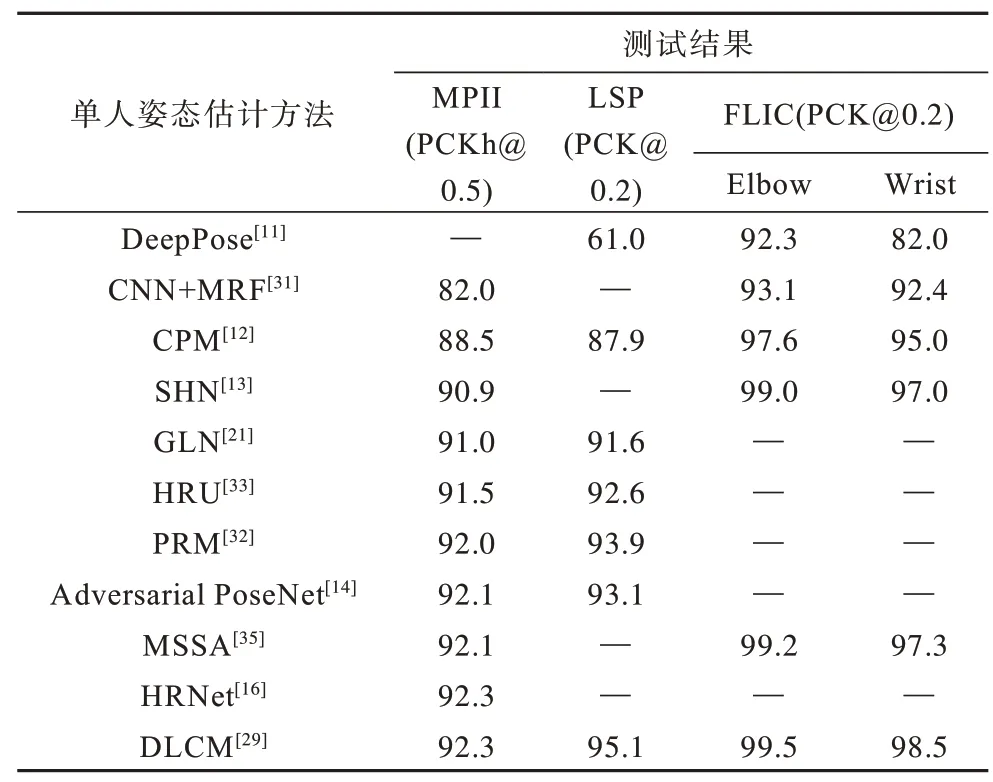
表5 单人姿态估计方法在LSP、FLIC 和MPII 数据集上的测试结果Table 5 The test result of single-human pose estimation method on LSP,FLIC and MPII dataset %
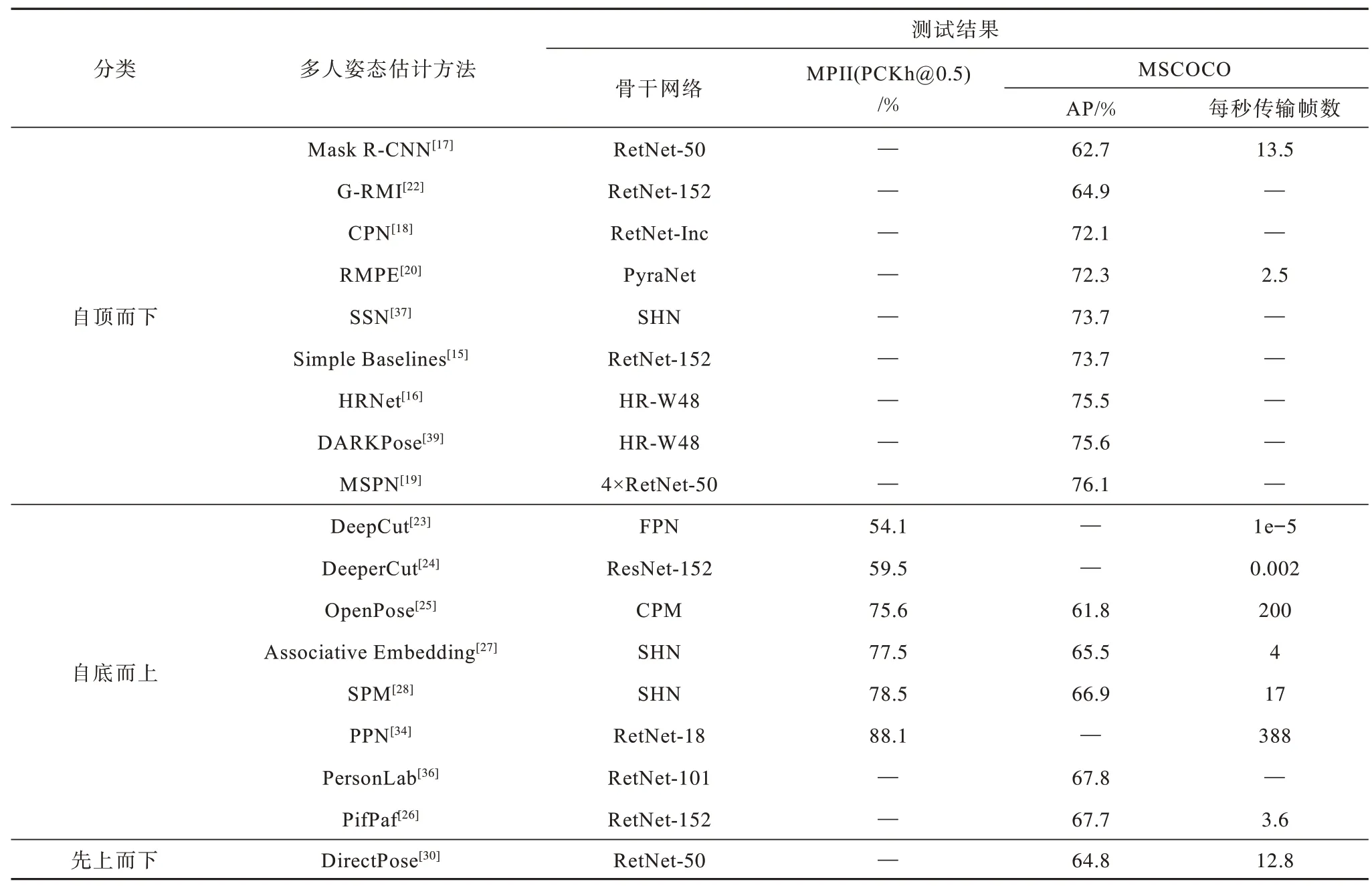
表6 多人姿态估计方法在MPII 和MSCOCO 数据集上的测试结果Table 6 The test result of multi-human pose estimation method on MPII and MSCOCO dataset
5 发展与展望
近年来随着深度学习的发展,国内外有关安防监控、医疗康复、自动驾驶等应用技术得到广泛应用,一方面推动了二维人体姿态估计在深度学习领域的创新,另一方面对算法的计算效能和结果的预测精度提出了更高的要求[58]。
1)网络模型优化
有关人体姿态估计相关算法的网络模型的优化将是未来关于该主题下实现更少模型参数的研究方向。原有的网络架构将随着模型压缩,如量化剪枝、知识蒸馏等技术的应用而得到改善[59],随着NAS(Neural Architecture Search)[60]的提出,以先验知识结合神经网络结构搜索的技术将使设计架构更加自动便利。
2)算法策略创新
遵循自顶而下模式的人体姿态估计方法由于过于依赖人体目标检测器的性能和效率,其时效性略逊于自底而上模式下的人体姿态估计方法。而诸如OpenPose 和PifPaf 引入复合场概念,其设计思路更具可解释性,故而更符合与卷积神经网络相结合。在高维向量基础上预测人体姿态,设计保持期望一致性的关联得分公式,再加之有效的匹配策略,将能够弥补自底而上模式中人体姿态估计精度较低的不足,进而提升实时的高精度人体姿态估计效果。
3)三维姿态估计
基于深度学习的二维人体姿态估计的研究是许多三维人体姿态估计研究的铺垫,其中的人体关键点定位技术也是三维人体重建的必备技术。而且目前部分三维人体姿态估计依然借鉴了二维人体姿态估计的网络架构及研究思想,如文献[61]中的网络架构就是基于级联沙漏网络进行的改进。
4)无监督训练
近年来采用无监督的方式处理二维人体姿态问题[62]的方法随着相关技术的发展成为一种新趋势。因为人体姿态可以看成图像中的特征簇,其视觉连通性具备高维空间独立性。若加上光流等辅助信息,则可以通过大量无标签的图像构建人体部件的特征、部件到整体的特征以及人体运动的时序特征,这将是一种解决人体姿态估计任务的新方案。
5)刚体姿态估计
基于深度神经网络的二维图像人体姿态估计,要求网络所学到的人体姿态应满足模型的几何约束,其本质上是一个对高维特征空间的非线性流形学习过程。深度神经网络是一个代数计算系统,既然可以获取诸如人体关键点的内部关联以及高阶耦合的几何特征等人体复杂信息,那么对于一些特定刚体部件的关键点定位与姿态估计也将在相应网络与算法中实现。而海量的刚体姿态处理需求则能够推动姿态估计相关研究的发展与革新。
6 结束语
基于深度学习的二维人体姿态估计通过深度卷积神经网络获得姿态关键点局部特征信息,并根据具体情况选择合适的关键点特征处理策略进行相应的特征聚合与特征匹配,实现对人体特征关键点的定位与姿态估计。本文对基于深度学习的二维人体姿态估计研究进展进行综述,分类与评估相关姿态估计方法,并从网络架构设计、输出特征处理以及损失函数选取方面进行比较与分析。分析结果表明,卷积神经网络提取到的人体姿态特征对于局部定位具有很高的预测精度,结合多尺度特征融合方法并在训练过程中引入中继监督策略能够增加对人体姿态估计结果的整体预测精度,进一步提升模型的鲁棒性。多人姿态估计通过构建合适的特征提取模型与相应的特征分配方法,对定位精度与估计效率进行权衡,而在对多尺度姿态特征的提取保持高精准度的同时,稳步提升姿态估计的检测效率成为基于深度学习的二维人体姿态估计在后续研究中的主要发展方向,而网络模型优化、无监督学习的研究发展也将对二维人体姿态估计从实验研究到应用实现起到重要的推动作用。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
电子制作(2016年15期)2017-01-15
系统工程与电子技术(2016年2期)2016-04-16
中国卫生(2014年2期)2014-11-12
电测与仪表(2014年1期)2014-04-04
电测与仪表(2014年1期)2014-04-04
