
基于随机森林算法检出hs-cTnT项目小偏移的实时质控方法*
2021-02-10 06:22梁玉芳程华丽王清涛王哲冯祥韩泽文宋彪周睿首都医科大学附属北京朝阳医院检验科北京00020航空总医院检验科北京0002北京市临床检验中心北京00020内蒙古卫数数据科技有限公司大数据研究院呼和浩特00000内蒙古财经大学呼和浩特0005
临床检验杂志 2021年12期
梁玉芳,程华丽,2,王清涛,3,王哲,冯祥,韩泽文,宋彪,5,周睿,3(.首都医科大学附属北京朝阳医院检验科,北京00020;2.航空总医院检验科,北京0002;3.北京市临床检验中心,北京00020;.内蒙古卫数数据科技有限公司大数据研究院,呼和浩特00000;5.内蒙古财经大学,呼和浩特 0005)
传统室内质量控制(internal quality control,IQC)通过按照预先规定的频次检测稳定的质控物对分析系统性能进行监控,是目前实验室主要采用的质量管理工具。该质控方式在质控物本身互换性及浓度水平、质控频次、质控成本等方面存在不足之处。在当前实验室规模扩大且实验室检测量陡增的场景下,基于患者的实时质量控制(patient based real time quality control,PBRTQC),作为传统IQC的补充方案,被越来越多的实验室用于室内质量控制及室间质量评价[1-2]。2017年,Liu等[3]使用一种浮动异常值之和的方法(moving sum of outlier,MovSO)监测前列腺特异性抗原(PSA)项目0.03 μg/L偏移改变。MovSO方法属于PBRTQC方法,该法虽可检出有临床决定意义0.03 μg/L大小的误差,然而尚不能满足2014年欧洲临床化学和检验医学联合会(European Federation of Clinical Chemistry and Laboratory Medicine,EFLM)提出的用于设定分析性能规范的要求[4],该规范涉及的检测项目有高敏肌钙蛋白(hs-cTnT)[5]、PSA[6]等,由于是基于对医学决定影响而设定的分析性能规范,所以被测量值的准确度对医疗决策起关键作用,直接影响患者管理[5]。
随着人工智能的出现,机器学习已经逐渐发展出一些各有特点的算法,可以在一定程度上帮助人们完成数据预测、自动化、自动决策、最优化等任务。其中,随机森林(random forest,RF)能够处理超高维度的数据,并且特征选择不受约束,对缺失值不敏感,在特征遗失的情况下仍可维持准确度的优势,适合类似质控的项目数据。本研究探索利用患者数据,基于RF算法,以hs-cTnT项目为例,尝试建立识别小偏移的质控方法,并与MovSO方法比较,验证该方法的临床效能。
1 资料与方法
1.1数据收集 通过航空总医院的实验室信息系统导出2016年1月至2021年8月在罗氏化学发光E601设备检测的hs-cTnT项目,选择质控在控(质控判定规则设置为13s、22s)时段、标本类型为血清或血浆样本的患者检测数据,数据清洗规则:(1)排除来自于儿科、ICU、血液科、肿瘤科、肾病科、透析科的患者样本数据;(2)剔除含有离群值、荒谬值的样本数据,其中离群值通过统计学下的3σ准则,将分布在(μ-3σ,μ+3σ)之外的数值定为异常值,荒谬值表示非数字格式或者为负值的数据。最终确定患者检测结果54 243份,用于机器学习模型训练、模型测试及临床PBRTQC中的MovSO方法的比对验证。
1.2有偏数据模拟 为研究不同算法对质控失控的识别能力,由于收集到的数据默认为全部在控无偏数据,需要人为生成不同偏移大小的有偏数据作为无偏数据的对照组,以尽可能涵盖临床中各种大小的偏移。根据公式x′=x+e,其中,x表示原始在控数据,x′表示引入偏移后的数据,e是偏移大小。设置10个不同大小的偏移:±1 ng/L、±2 ng/L、±3 ng/L、±4 ng/L、±5 ng/L。按公式在所有无偏数据上加入偏移,构成与无偏数据集等长的有偏数据集。由此,每个实验条件下,均有2组数量为54 243的数据集,用于后续实验。
1.3RF算法
1.3.1数据预处理 对于hs-cTnT项目,根据临床质量规范要求,临床需准确识别出5 ng/L以内的小偏移。采用机器学习中孤立森林算法过滤数据,以有效去除数据噪音对实验结果的干扰。滤过比例需根据实验合理设置,孤立森林会综合样本的距离与密度筛选有效数据。如果滤过比例设置过小,则无法有效减少噪声数据;如果比例设置过大,则在实际检测环节会导致延迟,从而扩大受影响的患者样本数。针对无偏数据和有偏数据的操作步骤相同,将处理后的新样本按照预设浮动窗口大小(block size)[2](即在PBRTQC质控方法中每次计算浮动均值所包含的患者结果数量)分批,将每批内的所有数据作为机器学习的一个新样本,并标注标签,将来自无偏数据集与有偏数据集的样本分别标记为“0类”、“1类”。
1.3.2模型构建及调优 RF算法是常用分类算法之一,其原理是通过集成多个决策树的结果进行分类[7]。决策树的数目和最大深度是RF算法需要调节的核心参数。RF模型通过对样本以及对其属性的随机抽取,实现横向与纵向的并列划分,使模型的泛化能力更强。为了保证集成分类器的多样性,理论上树的数目越大越好。但是随着树的数目的增大,会抵消随机性的引入,模型发生过拟合的可能性增大,其泛化性能也会降低。此外,噪音较大时,模型也会学习到更多噪音相关的信息,发生过拟合,降低泛化性能。选取偏移大小为1 ng/L的有偏数据,以10为浮动窗口大小,数据处理后,在上述参数的经验范围内进行遍历,评估每个实验条件下的性能。选取最优模型参数,对10个偏移进行测试。测试时,按虚拟天进行统计,每天设置2 000个数据,根据总数据源数量划分为28个实验日。2 000个样本中前1 000个为无偏数据,后1 000个为有偏数据。无偏数据是为了模拟实际场景中质控在控状态,有偏数据是为了模拟实际场景中质控失控状态。
1.4MovSO方法
1.4.1算法原理 参考文献[3]中方法,依据预设阈值将患者结果判定为正常或异常,如果结果超过设定阈值,被认定为异常值。在指定浮动窗口大小的浮动窗口中,理论认为异常值个数在均值附近稳定波动且近似符合正态分布,故可将此变量用于质控监控,计算公式为:
MovSOt=Count(xt-N,xt-N+1,…,xt|xi∉RI),
其中t为浮动窗口序号,N为浮动窗口大小。
1.4.2实验流程 (1)阈值参数选定:选取3个临床水平决定限作为划分异常值的阈值——12、14、52 ng/L,超出阈值的数据按异常值计数。(2)浮动窗口大小参数选定:依次尝试不同大小的浮动窗口大小——20、100、200、500、1 000。(3)对样本队列以当前实验的浮动窗口大小利用1.4.1中公式计算浮动的异常点个数形成MovSO队列。(4)按照控制限计算:3种不同的控制限计算方法[8]分别是:(a)对称法(symmetric),控制限=m±3×sd,其中m、sd为无偏样本下所有块的MovSO均值与标准差;(b)所有日统计法(all PBRTQC),所有的实验日下MovSO队列的0.5和99.5分位数;(c)日极值统计法(daily extremes),统计每个实验日的最小值中取5位数,每个实验日的最大值中取95分位数。(5)测试结果:通过两类数据统计评估结果,将所有步骤的排列组合下,在所有偏移下进行实验。(6)结果寻优:综合观察各偏移下的性能评价指标与所有偏移的累计评价指标,对所有实验进行筛选,挑出最佳浮动窗口大小与控制限。
1.5统计学分析 利用Python3.7.3通过“sklearn”、“tensordlow”框架执行。采用曲线下面积(AUC)、准确度(ACC)、真阳性率(TPR)、假阳性率(FPR)、真阴性率(TNR)、假阴性率(FNR)指标评价RF模型训练和模型测试分析性能。在FPR小于5%的情况下,将受影响的患者样本数 (number of the patient sample until error detection,NPed)定义为每个实验日,从引入偏移开始到误差被检出时止,受影响的患者样本数。当经过1 000个有偏数据仍未检出时,将NPed以1 000的110%替代,用来表示算法检测失败。基于28 d的NPed,统计其均值ANPed、中位数MNPed、95分位数95NPed,用于RF算法与MovSO算法比对验证。
2 结果
2.1RF实验结果 根据对原始样本的数值分布分析,可发现数值在1~7.6 ng/L之间的数量占31%,数值在7.6~21 ng/L之间的数量占33%,这两部分的分布比较集中,数值在大于21 ng/L之后分布开始出现离散,最大可达135 ng/L,这一部分数量占36%。离散数据并非无效数据,不能全部去除。根据数据分布情况,孤立森林的滤过比例设置为30%,以此降低离群值对实验的影响。
在实验10个偏移之前,选取1 ng/L的偏移为例进行分析,树的数目的遍历范围定为3个候选值:100、200、300,树的深度的遍历范围定为10~500,间隔为50。经过了30次预实验,综合比较模型的训练准确度与测试准确度,选择最佳树的数目为200,树的深度为350。树的数目在200的情况下,改变树深度后的实验情况见表1。

表1 1 ng/L的偏移下RF在不同树的深度下模型的训练准确度与测试准确度
固定RF内参之后,为提高实验效率,只选择5个正向偏移进行训练。经过28 d测试数据的检验,挑选FPR<5%的情况下,统计不同浓度偏移下的评价指数见表2,测试集数据ROC曲线与AUC结果见图1,其中图1中A~E分别对应1、2、3、4、5 ng/L大小的偏移。RF对hs-cTnT的微小偏移具有较强的识别能力,除了在±1 ng/L下准确度为85%左右,其余的8个偏移下均能达到90%以上的准确度。10个偏移下的FPR均在4.7%以下,MNPed在12以下。

表2 RF在10个偏移下的测试结果
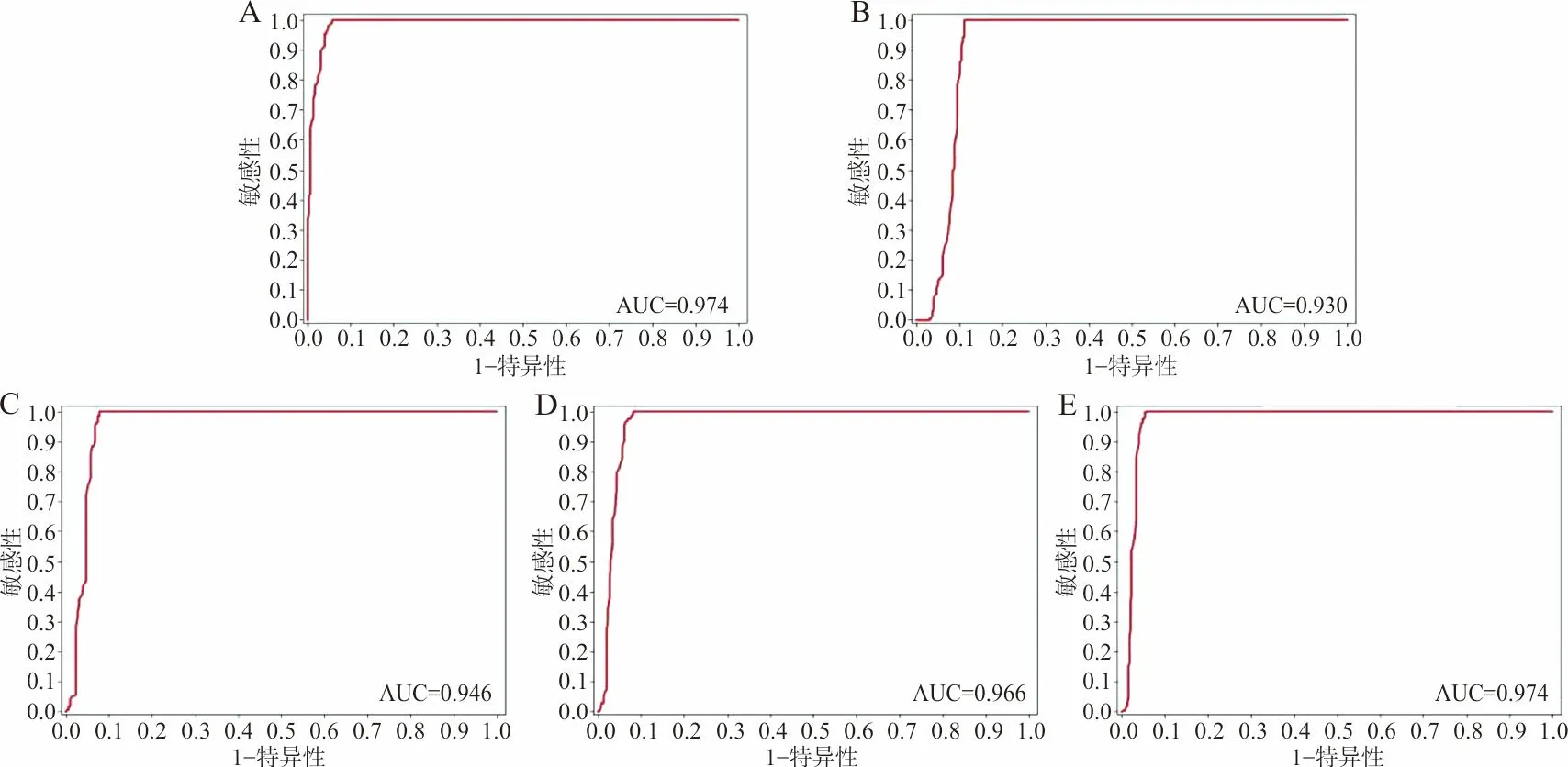
注:A、B、C、D、E依次对应1、2、3、4、5 ng/L的偏移。
2.2RF与MovSO比对结果 当FPR<5%时,固定浮动窗口大小为1 000,在3种阈值时(5、14、52 ng/L)进行不同控制限方法实验,统计MNPed结果,见表3。

表3 固定浮动窗口大小为1 000时不同阈值下的MNPed实验结果
当FPR<5%时,固定阈值为5 ng/L,采取5种不同的浮动窗口大小:20、100、200、500、1 000,统计最佳MNPed的实验结果见表4。由此可得阈值改变对于实验结果的影响程度大于浮动窗口大小的改变。

表4 固定阈值为5 ng/L时不同浮动窗口大小时MNPed实验结果
在3种阈值与5种浮动窗口大小的遍历下,临床要求FPR<5%,误差检出率>90%,误差检出率可等效于评价指标中的TPR。最终选出的最佳阈值为14 ng/L,浮动窗口大小为200,控制限方法为all PBRTQC,控制上下限为95和62。表5为MovSO的实验结果。

表5 MovSO在10个偏移下的实验结果
通过图2比较MovSO算法与RF算法的MNPed,在被引入的10种大小的偏移下,MovSO算法的MNPed变化明显,整体均在150以上,只有在±5 ng/L的偏移下能在150~200之间,随着偏移绝对值的减小,MNPed呈现指数式增长,但是RF的MNPed均在20以下,且趋势平稳。图3为增加辨识度单独显示RF在不同偏移下的MNPed,可以看出MNPed最小为10,即使在±1 ng/L的偏移下MNPed仅为12。由此可得各情况下RF表现均优于MovSO。

图2 MovSO与RF的MNPed整体对比
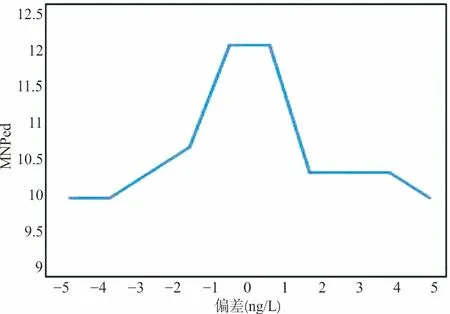
图3 RF在不同误差因子下MNPed的改变
3 讨论
对于hs-cTnT标准测定法,欧洲心脏病学会(European Society of Cardiology,ESC)在《非持续性ST段抬高型急性冠脉综合征患者的管理指南(2020)》中指出,临床在急性冠脉综合征患者诊疗中,要采用检验方法特异的诊断临界值[9]。实验室应确保hs-cTnT测试结果精确可控,低浓度水平结果准确可靠极其重要,调查发现,目前室内质控现状对低浓度质控覆盖率并不高,并不能有效监测这类有临床意义的小偏移[10-11]。
使用hs-cTnT对就诊的心肌梗死患者进行检测,正是利用hs-cTnT的高敏感性和诊断准确性,第二次检测hs-cTnT的时间间隔可以缩短,大大减少了诊断时间,提高患者精准诊断和治疗效率,减少不必要的诊疗资源浪费[12-16]。因此,临床要求选择质控方法既要有高的误差检出概率也要有低的假失控概率。通常误差检出概率达90%以上,而假失控概率在5%以下可满足一般临床实验室的要求。针对本研究提出的方法结果,TPR达90%以上,等效于误差检出概率;而FNR在5%以下,等效于假失控概率,从受影响的患者数来看均少于50,明显低于MovSO方法。从算法原理上分析,MovSO算法的依据是在浮动块中,划分为异常结果数量被认定为在正态分布附近波动,这是一种严重依赖数值分布的计算方式。其识别成功的前提是当且仅当被研究变量存在等于或大于某临床水平决定限的持续偏移的情况下,有阳性结果的患者比例将会增加,其抗干扰能力极其有限。相比MovSO,本研究提出的方法涉及2个重要步骤:特征工程与模型建立。
特征工程中数据滤过减少了离群数据对整体实验的影响,进一步的正态标准化可以使样本更加集中,组织队列环节实现了将单维数据向多维样本的转化。在数据预处理的输出上与MovSO的共同点是将一定长度的数据块看作一个整体,区别在于MovSO隐没了原始样本的数值信息,仅通过阈值统计一个划分数量作为输出;而本文的预处理可将原始样本的所有数值信息保留,以批为单位处理为1个队列,信息量比MovSO更全,MovSO在这一环节产生了特征遗失。
在模型建立环节,RF之所以能有效区分2类样本,原因在于算法内部经过了2次采样。在不同的树之间相当于行采样,在不同的节点之间相当于引入了列采样,只选取部分特征进行基础分类器的学习,因此每个基本决策树所选择的数据列都不相同。这种“行采样+列采样”的形式,可以在每个节点随机选取所有特征的一个子集,来计算最佳分割方式[17]。因此,即使存在特征遗失,用RF算法仍然可以维持准确度,RF的强抗干扰能力。
在结果决策环节,MovSO通过控制限简单划分,本身存在极大的误诊率(FPR)和漏诊率(FNR)。而RF方法如前所述,其原理是通过集成多个决策树的结果进行分类,每棵决策树都将进行独立的学习和不剪枝生长进而作出相应预测[18]。通过集成思想将若干个弱分类器组合起来,通过投票得出最终的分类或预测结果,得到一个分类性能显著优越的强分类器。从结果观察,二者的误诊率虽然均在5%以内,单是MovSO的误诊率除了在5 ng/L下为3.2%,其余均在16.18%以上,且偏移的绝对值平均每减少1 ng/L,误诊率增加15.2%;而RF除了在±1 ng/L下的误诊率为15%外,其余各偏移下均在1%左右,从而减少了错误发生率,降低因误报停机产生的时间与人力物力成本,减少因错误决策造成的额外损失。本文提出的算法可向类似PSA、TnT等其他高敏项目扩展推广。
致谢:感谢内蒙古卫数数据科技有限公司陈超,在本研究中负责人员组织、协调,提供必要的硬件保障。
猜你喜欢
军民两用技术与产品(2022年8期)2022-10-10
科海故事博览·下旬刊(2022年4期)2022-05-07
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
中国外汇(2019年19期)2019-11-26
小资CHIC!ELEGANCE(2018年34期)2018-11-13
现代职业教育·高职高专(2017年11期)2017-10-19
价值工程(2016年32期)2016-12-20
