
基于IOWA 算子的中国人口总量组合预测
2020-12-28 07:38王叶WANGYe
价值工程 2020年34期
王叶WANG Ye
(安徽财经大学统计与应用数学学院,蚌埠233000)
0 引言
新中国成立以来,我国人口总量持续增长,近年来虽然人口增速放缓,但人口问题始终是中国的一个大问题,人口基数多,人均耕地面积少,人均占有资源不足是我国的基本国情。从本质上来说,人口问题是发展问题,会制约我国的发展。要有效控制人口增长,前提是要了解人口数量的变化规律,需要建立合适的人口预测模型,进行较为准确的预测。
国内目前有很多学者采用不同的方法来预测中国的人口总量。涂雄苓(2009)分别利用指数平滑法和ARIMA 时间序列模型对中国人口数量进行预测, 并将二者的预测结果进行比较,得出最优预测模型是ARIMA(2,2,1)模型[1];韩绍庭(2014)运用了多元线性回归预测和ARIMA 预测,发现多元线性回归模型的预测精度更高[2];李利利(2014)在综合考虑了自然资源、环境条件等因素的情况下,建立了Logistic 模型对中国人口进行预测[3]。经过学者不断研究发现,单一的预测方法存在着很多的缺陷和不足。Bates和Granger 在1969 年提出了组合预测方法,它是将各个单一预测方法看成一个个包含着不同信息的片段,通过将各项信息集成后分散单项预测的不确定性和减少总体不确定性,从而提高预测精度[4];陈华友和刘春林通过引进诱导有序加权算术平均(IOWA)算子,这是一种以误差平方和最小为准则的组合预测模型,并给出了IOWA 权向量的确定的数学规划方法[5]。该模型提出了一种新的赋权思想,根据各单项预测方法在各时点上的拟合精度的高低进行有序赋权,优先给予预测精度最高的单项预测方法最高的赋权系数。
因此,为了更准确的预测中国人口总量,本文采用基于IOWA 算子的组合预测模型对我国人口总量进行预测。首先分别采用多元线性回归模型、ARIMA 模型和二次指数平滑预测法这三种预测方法对中国的人口进行单项预测,然后建立基于IOWA 算子的组合预测模型来分析所建立的组合预测模型的优越性。在此基础上,使用IOWA 算子组合预测模型对我国未来五年的人口总量进行预测,以此来分析我国的人口总量及其增长情况。
1 模型简介
1.1 IOWA 算子

则称函数fw是由v1,v2,…,vm所产生的m 维诱导有序加权平均算子,即IOWA 算子。其中v-index(i)是v1,v2,…,vm中按照从大到小的顺序排序后第i 个大的数的下标,其中是加权向量,满足。从上述概念中可以看出IOWA算子是对诱导值v1,v2,…,vm按从大到小的顺序排序后所对应的a1,a2,…,am中的数进行有序加权平均,ωi与ai的大小和位置无关,而是与其诱导值所在的位置有关。
1.2 模型建立
选择不同预测方法在各个时点上的预测精度作为该方法的诱导值,其中预测精度为:

其中,i=1,2,…,m;t=1,2,…,N,vit表示第i 种预测方法在第t 时刻的预测精度,xt为第t 时刻的实际值,xit表示第i 种预测方法在第t 时刻的预测值。此时,m 种预测方法在t 时刻的预测精度与其预测值构成了m 个二维数组:

于是,N 期总的组合预测误差平方和S2为:


IOWA 算子组合预测法通过各单项预测法在各个时点上预测精度的高低按顺序赋权,并以误差平方和最小为准则建立组合预测模型,符合实际需要,所以本文采用IOWA 算子的组合预测模型。
2 我国人口总量的实证研究
2.1 多元线性回归模型
笔者选取2000~2018 年之间24 年的全国总人口(y)作为被解释变量,人均GDP(x1),城镇化率(x2),初中毕业生人数(x3),城乡收入差距(x4),人均受教育年限(x5)以及时间t 作为解释变量。在导入数据后,利用R 软件进行多元线性回归模型,逐步回归后,剔除一些不显著变量,最终得到如下回归模型:
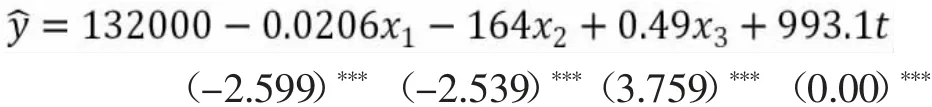
各个自变量的系数均通过显著性检验,R2=0.9969,F统计量的值为32020,p 值为0,说明在0.05 水平下回归方程整体显著。模型的预测值和预测精度见表1。(注:***表示在0.05 水平下显著)
2.2 ARIMA 模型
ARIMA 模型是以平稳随机序列为前提建模的,经过对原序列以及各阶差分数据进行ADF 检验后,发现二阶差分序列平稳,并通过观察其自相关图和偏自相关图以及比较模型的R2,统计量t 和AIC 准则,最后确定建立ARIMA(0,2,0)模型,模型的预测值及预测精度见表1。
2.3 二次指数平滑
指数平滑法是在时间序列统计模型的基础上进行预测的方法。指数平滑法分为一次指数平滑法和多次指数平滑法。一般情况下,运用最多的是二次指数平滑法,其公式为:
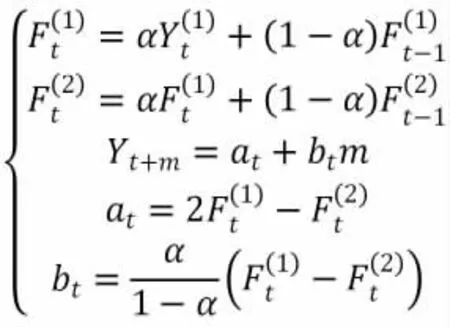
2.4 IOWA 组合模型
对于以上三种模型的预测结果,选取2000~2018 年的预测数据建立组合预测模型。其中三种预测方法的各项预测结果如表1 所示。
由于要建立诱导(以预测精度作为诱导值)有序加权算术平均(IOWA)组合预测模型,将三种预测模型在样本期(2000-2018 年)各时点按照预测精度由大到小的顺序重新排列,得到预测精度最高、预测精度次高和预测精度最差的诱导预测模型对应的预测值和预测精度,见表2。
根据各单项预测精度值和误差,建立基于误差平方和最小的组合预测模型,三种单项预测的误差信息矩阵为:

使预测误差平方和最小的诱导有序加权算术平均组合预测模型:


表2 按照精度从大到小排序的预测值与精度

表1 三种单项预测预测值与精度

利用LINGO11 解得最优权重系数为:ω1=0.684,ω2=0.283,ω3=0.033。根据最优权重系数及IOWA 算子组合预测模型,得出各年组合预测值见表1,以及各年组合预测值的预测精度见表2。
2.5 我国人口总数预测
结合各单项外推预测计算出2019-2023 年的各单项预测值,再乘以各单项预测方法的最优权重系数求和,即可计算出我国人口总量的后五年预测值,见表3。
由表3 可知,未来几年我国人口仍在持续不断地增长,到2023 年人口总数会达到142854 万人,从预测结果可以看出我国由于人口基数过大,短期一段时间内人口仍呈增长趋势,人口发展问题仍是未来几年的工作的重点。

表3 2019-2023 年全国人口预测值
3 结论
本文在回顾诱导有序加权平均(IOWA)算子的组合预测模型的理论基础上,首先分别采用了多选线性回归模型、ARIMA 模型及二次指数平滑三种单项预测模型对我国2000-2018 年期间的人口总量,然后建立以单项预测法预测精度为诱导值,以误差平方和最小为准则的IOWA 算子的组合预测模型。预测结果显示,由于我国人口基数较大,在未来的几年中,人口依然处于持续增长阶段,中国在发展过程中的人口问题依然是一个重点问题。
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
数学物理学报(2021年2期)2021-06-09
应用数学(2020年2期)2020-06-24
国外核新闻(2020年8期)2020-03-14
中等数学(2019年1期)2019-05-20
数学年刊A辑(中文版)(2018年2期)2019-01-08
中等数学(2018年7期)2018-11-10
中学数学研究(广东)(2017年2期)2017-03-28
数学物理学报(2016年3期)2016-12-01
