
汉语反语认知加工机制的ERP研究*
2020-12-09 07:59杨波卞京张辉
语言科学 2020年5期
杨 波 卞 京 张 辉
1东南大学外国语学院 江苏 南京 2111892南京师范大学外国语学院 江苏 南京 210097
提要 日常会话中包含大量的反语,对于字面义和反语义的理解和加工,心理语言学家Gibbs在上世纪90年代大胆提出,人类认知从根本上讲包含比喻性的加工过程,理解反语并非一定需要理解字面话语所需的认知加工之外的特别加工。Gibbs的这一观点被称为直接通达观,其在神经语用学领域,特别是关于比喻义与字面义的加工问题上颇受争议。包括反语在内的比喻语言理解加工的时间进程的模式或假说除了Gibbs的直接通达观,主要还有标准语用模式和分级突显假说,且相关的实证研究结果存在分歧。我们把问题和争议概括为:1)反语的理解和加工机制是什么样的?是不同于字面语言加工的特殊过程吗?2)就反语而言,上述三大加工模式或假说中哪种更具适用性?本研究以较熟悉的汉语反语为例,在神经语用学的框架下使用事件相关电位技术(ERP)来记录和分析所得到的N400和P600成分。实验发现:1)较熟悉的反语义较之对应的字面义诱发了更大的N400和P600波幅,提示反语义的加工过程经历了不符预期(或语境)的语义整合以及后期语用整合推理,因此是不同于字面语言加工的特殊过程;2)实验结果说明,汉语反语的加工最可能采取的是标准语用模式,而非直接通达观的加工模式。
1 引言
我们的日常生活中不乏“想得美”“你真坏”和“看看你干的好事”这样看似寻常而实际上“似是而非”的语言。说话人真正要表达的意思跟字面意思相反,而听话人往往能理解其传递的真正含意,这就是“反话”或者“反语”(verbal irony)。本研究将反语定义为:用肯定的语言形式来表达否定的意思、态度或评价,或者相反。直到20世纪70年代,反语的研究随着语用学、心理语言学和认知语言学的兴起逐渐开辟了修辞之外的新视角(Garmendia 2018)。特别是心理语言学家Gibbs(1994)指出,人类认知从根本上讲包含比喻性的加工过程,反语跟隐喻、转喻以及其他比喻性语言一样,并不是异常的或修饰性的,而是普遍存在于日常语言中。这就是说,“理解反语并非一定需要理解字面话语所需的认知加工之外的特别加工”(同上:437)。Gibbs对于比喻语言理解加工的观点引发了学界的广泛争议,特别是在神经语用学的研究中,比喻义是其主要研究对象之一,而且从理论到实证都存在分歧。首先,反语的字面义和比喻义的区分:反语义的理解和加工是一个不同于其字面义的特殊过程吗?反语义能否直接通达?其次,反语加工的时间进程:在比喻语言的三种加工模式或假说(详见下文)中,反语加工更可能采取何种加工模式?
1.1 相关的反语加工时间进程研究
关于反语加工的时间进程问题,主要存在三大加工模式或假说,即标准语用模式(Standard Pragmatic Model,SPM)、直接通达观(Direct Access View,DAV)和分级突显假说(Graded Salience Hypothesis,GSH)。(1)根据杨波和庞超伟(2015)的介绍,SPM认为加工比喻性语言较之字面语言需要更大的认知努力,必须首先计算话语的字面义;DAV提出理解比喻性语言可以毫不费力,不需要有意识的思考;GSH假定模块的、词汇的通达机制是有顺序的:较为突显的意义因为规约性(conventionality)、频率(frequency)、熟悉度(familiarity)或原型性(prototypicality)更高,是处于大脑的首要位置的编码义,要比不突显的意义的通达更快。GSH在某种程度上说是前两种模式或假说的融合,基于语言意义的突显程度而假定相应的加工模式。SPM(Grice 1975;Searle 1978)提出,理解反语需要首先构建字面的、独立于语境的解读,当发现字面解读明显跟语境不一致时,字面解读就会被压制,反语解读随即被计算,因此假定反语较之字面语言需要额外的加工努力。DAV(Gibbs 1989)对SPM提出了挑战,认为如果语境支持反语解读,那么反语义被直接激活,无需首先通达字面义,因此假定反语解读较之字面解读不需要更多的努力。GSH(Giora 1997,2003)在某种程度上融合了前两种模式,提出突显义和基于突显义的解读首先被激活,而熟悉反语的字面义和反语义都是突显的,二者被平行加工,反语义也应该被直接通达而无需重新分析;不熟悉反语通常是其字面义先被加工,然后发现其跟语境的不一致,需要重新加工将其分析为反语。
我们重点关注与本研究相关的ERP研究。Ivanko和Pexman(2003)考察了语境在反语理解中的作用以及在字面和反语陈述中的影响模式。为此,研究者控制了情境的否定性程度(使用强否定、弱否定和中性语境),并通过直接改变目标句中的关键词(通常是成对的反义词,详见Ivank和Pexman 2003:276-279)来生成反语义和字面义,结果发现在强否定情景中,反语陈述的阅读时较之字面陈述更长,而在弱否定情景中,反语陈述的阅读时较之字面陈述更短或者等同。因此,恰当的语境条件有助于反语义的加工,支持比喻语言加工的直接通达模式,即DAV。此外,DAV对适当语境下反语义被直接加工的预期也得到了Gibbs(1986)研究的证据支持,即在一定的语境下反语句的阅读时间短于或者等同于字面句的阅读时间。
Cornejol等(2007)发现了关于反语解读策略的脑电成分。整体策略(关注整个交际情景)中的反语诱发了类似N400的成分和明显的晚期正波(根据波形图判断应为P600,参见Cornejol等 2007:420),而解析策略(关注句子各个成分)主要诱发了较之整体策略明显减少的N400相关成分,并认为这跟解读策略和语境信息提示量以及对更高级的认知资源的要求有关。这样的结果显然支持SPM而不支持DAV。
Regel等(2011)考察了反语和字面句理解中包含的认知过程的类型及其时间进程,该实验的ERPs结果一致显示,不管呈现通道如何,反语相比对应的字面句子而言出现较大的晚期正波(即P600成分)而没有N400成分。反语N400的缺失,暗示在支持性的语境下反语义的加工不涉及语义整合困难。因此,在反语的理解过程中,语义不一致的识别对于整合字面句义和前面的语境信息来说不是必要的。相反,观察到的反语诱发的P600为晚期加工中包含推理过程提供了一些支持,这跟SPM和GSH一致;同时也提供了不支持DAV的证据,因为结果显示了字面语言和反语理解中的明显差异。该文还提出,观察到的左前负波(Left Anterior Negativity,LAN)效应,以及未观察到N400效应,要求对SPM和GSH进行修正,因为它们都认为,适合语境的字面义首先被激活(至少对于不熟悉的反语而言是这样)。
Filik等(2014)针对GSH关于熟悉和不熟悉反语加工之间不同的预期进行了实验研究。N400时间窗结果显示,不熟悉反语较之非反语控制语料表现出更大的负走向的波形,而熟悉反语及其控制语料无差异。加工熟悉反语(较之非反语控制语料)则没有经历这样的加工困难。在600-1000ms时程中,反语较之控制语料出现更正走向的波形,该文认为这反映了类似P600的效应。这一语境效应跟熟悉度无关,暗示在此晚期时程内,熟悉和不熟悉反语较之相应的非反语控制语料进行着相似的认知加工。文章认为这样的结果跟SPM不一致,因为该观点预期所有反语语料较之非反语控制语料存在加工困难;与DAV也不太一致,因为该观点认为只要有充足的语境支持,反语和字面语的加工方式相同。所以,其实验结果跟GSH最为一致,较符合该假说对熟悉和不熟悉反语加工差异的预期。
1.2 本实验的研究目的和方案
从上述梳理中我们发现,首先,已有实验结果对反语加工时间进程的三大模式或假说的验证存在分歧:Ivanko和Pexman(2003)的研究显然支持DAV;Cornejol等(2007)的结果支持SPM而不支持DAV;Regel等(2011)的结果跟SPM和GSH一致,同时也提供了不支持DAV的证据;Filik等(2014)的结果跟SPM和DAV不完全一致,总的说来跟GSH最为一致。其次,就关键成分N400和P600而言,目前的ERP研究一致地报告了P600或者类似P600的晚期正成分,但Regel等(2011)的研究和Spotorno等(2013)考察反语理解中信息整合的关键阶段的研究都报告未发现N400成分。这一成分的缺失值得继续验证和探究。最后,上述各实验虽都涉及对反语加工的考察,但在语料设计编排和实验范式上却因为各自的视角和目的而存在差异。下文将说明本实验的语料设计编排方案和实验范式。
本研究以较熟悉的汉语反语(2)汉语反语有多种分类,可根据熟悉度、“正/反”(褒词贬用和贬词褒用反语)、推理反语义主要依赖的知识类型(基于词汇语义知识和世界知识的反语)等。本研究挑选的反语实际上是依赖词汇语义知识来理解的、较熟悉的、褒词贬用类反语,是大多数研究认为更具典型性的一类反语。为例,针对上述分歧和问题有针对性地设计ERP实验方案,以考察这类反语加工的神经机制,探究反语义的通达是否是特殊的加工过程,并借此探讨上述关于反语加工时间进程的模式或假说。
首先,创造尽量自然的实验语料和条件,排除Ivanko和Pexman(2003)控制的语料的强否定和弱否定语境,以及Cornejol等(2007)对被试进行解读策略训练等因素对实验结果的影响,因此我们的实验记录的是被试自然地在线阅读同类型语料的ERPs。
其次,采用视觉通道呈现语料,排除听觉通道呈现语料时人为控制的韵律特征等跟声音有关的因素可能给被试的加工带来的影响。控制语料目标句的音长、音高和音调等韵律特征极可能造成被试对目标句的韵律期待及相应的加工偏向,从而干扰目标句的语境因素本身对加工的影响。如何控制听觉通道呈现语料的韵律特征以及韵律特征会对反语的加工产生怎样的影响(参见 Regel 等 2011;Filik 等 2014),我们将另做研究。
再次,通过评分(ratings)的方式控制语料的熟悉度,排除熟悉度差异对反语加工造成的影响。专门控制熟悉度是因为熟悉度跟分级突显假说的核心概念“突显”密切相关,因为熟悉度在很大程度上可以作为突显度的指标。本研究实验语料的目标句大致为“评价对象+副词+关键词”结构,并非不需结合语境就可以解读的词汇化的反语。因此,我们首先需要对反语语料的熟悉度进行区分。尽管目前只有Giora(2003)、Pexman等(2010)和Filik等(2014)等少量研究控制了熟悉度,却无法提出严格统一的区分标准,但确实存在非常熟悉甚至词汇化的反语(如本文开篇列举的“想得美”和“你真坏”)和非常不熟悉的新颖反语(Regel等 2011),因此其加工势必受到熟悉度的影响。本研究对语料目标句的熟悉度的区分采用评分的方法,一方面是因为评分更易操作和量化,另一方面是因为这是大多数关于包括反语在内的比喻语言的实验中区分熟悉度的常用方法,可使本研究的实验跟其他研究的实验在此方面具有更高的可比性。因此,我们选取较熟悉的这样一类更具代表性的反语作为考察对象,旨在为反语的认知加工得出初步结论,并成为下一步深入研究的参考和比较基础。
最后,控制语境提示信息的丰富程度,保持语境部分人物和事件框架基本一致,只改动个别关键信息,使得原本相同的目标句产生偏向字面或者反语的解读。这是几个主要参考研究和本研究编制和筛选语料的共同标准。事实上,这同时也是实验语料的设计编排问题。反语理解加工的语料主要有“语境(不同)+目标句(相同)”(如Giora等 1998;Regel等 2011;奉先武 2011;Spotorno等 2013;Filik等 2014)和“语境(相同)+ 目标句(不同)”(如Gibbs 1986;Ivanko和Pexman 2003;Pexman等 2010)两种设计编排。本研究采用的是第一种,这是因为相同目标句的不同解读诱发的ERPs的差异就更加单纯地被看作是不同类型的解读造成的,而不是目标句关键词本身的不同造成的。而且,这样的实验语料设计编排也是为了和其他研究有更高的可比性。
此外,设计实验时还控制了实验语料的可接受度、填充概率(cloze probability,参见 Taylor 1953)、反语性(即某句话被判断为反语的可能性)(Pexman等 2010;Filik等 2014)等因素,在最大程度上保证实验结果的可靠性。
2 汉语反语的ERP实验
本实验关于较熟悉反语加工时间进程的基本预期如下。首先,根据Gibbs(1994)关于比喻语言理解加工的观点,我们预期较熟悉反语这类相对典型和易理解的反语义的加工应该跟普通字面语言的理解一样,而不是特殊的加工过程。其次,根据SPM,反语的字面义应先被通达,这会给目标句句尾关键词与前面的语境信息之间的语义整合带来困难,预期反映语义整合困难的N400成分出现;同时,该模式假定的字面义在后期被重新分析为反语则预期作为持续分析或者解决冲突指标的类似P600的晚期正波的出现。DAV假定当反语被置于信息足够丰富的语境中时,反语义被直接通达,因此预期不会出现任何ERP效应(N400和P600)。GSH假定突显度高(在本研究中对应熟悉度较高)的语义先被加工,因此预期只有不熟悉的反语存在语义整合或者提取的困难以及之后的重新分析,从而诱发N400和P600效应。而本实验语料熟悉度是“较熟悉”,字面义和反语义平行加工,因此预期可能诱发的N400和P600波幅无显著差异。总的来说,因为语料是较熟悉的反语,但又没达到“想得美”和“你真坏”这样非常熟悉甚至是词汇化的程度,所以预期上本实验中的反语加工采取SPM,以及GSH关于不熟悉反语加工的部分,而不采取DAV。
2.1 被试
本实验选择不同专业的23名母语为汉语的在校大学生(含本科生和硕士研究生)被试,男11名,女12名,平均年龄23.6岁(SD=1.45)。被试经爱丁堡利手量表(Oldfield 1971)测试均为右利手。被试视力或矫正视力正常,家族中无神经或精神疾病史。被试自愿参与本实验,且实验前签署知情同意书,实验后获得适当报酬。
2.2 实验设计和刺激材料
本实验采用ERP技术,通过比较被试对反语和字面目标句关键词的加工,考察较熟悉汉语反语的在线认知加工机制。首先,本实验中的语料都经过预选,在可接受度、填充概率、反语性和熟悉度上均有所控制,(3)根据反语加工ERP实验的既定程序和规范,我们结合相关参考文献对语料进行了必要的预先筛选,筛选的标准包括可接受度、填充概率、反语性和熟悉度。实验语料的可接受度和熟悉度经5点量表测试,结果经t检验分析显示,字面、反语目标句可接受度(3.68±0.7)和熟悉度(3.90±0.7)对比均无显著性差异(ps>0.43);反语目标句的反语性平均得分高于4.76,字面目标句的反语性平均得分低于1.32;两种目标句填充词的填充概率均高于87.6%。以保证获取的ERPs成分最大程度的有效性。最终的语料为30条反语句(对应30条字面句),形式为“语境(偏向字面和偏向反语)+目标句(相同)”。目标句的结构和字数基本一致:评论对象+副词+关键词。关键词应作字面还是反语解读取决于前面的语境(如表1所示)。(4)作为语境的语篇长度大致相当,语境内容相似。此外,为了避免标点符号可能给被试带来的不必要干扰,语料在呈现时均省去了标点符号。语料逐词或词组分屏呈现,而且正式实验前还有练习实验,避免被试在阅读语料时出现断句方面的问题。另外,为了避免被试对语料出现形式的猜测和预期,制作了30条填充语料(fillers)。因此,实验语料共计90条试次(trial),被伪随机后分成三个实验组块(block),每个组块中两类目标语料和填充语料在种类和数量上平衡。最后,为了让被试集中注意力阅读和理解语料,在约1/3的语料(包括填充语料)后面加一个是/非型理解问题,要求被试按键进行判断。(5)问题分两类,一类只涉及语境部分的某个细节,另一类涉及对整个语篇的理解,正确答案为是/非各一半。两类问题经过伪随机均匀地嵌入语料中,目的是让被试集中注意力阅读和理解语篇,而且对语境和目标句都同样关注。这也是数据是否被统计的依据(回答正确率低于80%的被试的脑电将被剔除)。被试在实验中的按键反应还进行了左右手平衡。

表1 实验语料示例
2.3 实验程序
本实验采用视觉通道呈现语料。实验在暗光的屏蔽室内进行,被试双眼水平注视显示器中央,视距为80cm,水平视角为4°。刺激系统STIM2(Neurosoft,Inc. Sterling,USA)控制刺激在屏幕上的呈现,所有语料都被随机排序。每个试次首先呈现一个提示符“+”,呈现时间为300ms,提醒被试刺激语料即将出现,提示符消失后500ms语料开始呈现。所有语料(除了理解问题句)逐词(组)呈现。汉字为48号宋体、白色,显示器背景为深灰色。语料文字每屏刺激的呈现时间为600ms,屏与屏时间间隔为800ms,目标句关键词呈现3000ms后再继续呈现下一屏。在约1/3的语料后还跟随一个理解问题,以屏幕中央“####”符号300ms的呈现作为提示,整句呈现2000ms。问题句呈现后被试需在第一时间通过按键做出“是/非”判断。如未及时按键,3000ms后下一条语料自动呈现。刺激语料呈现流程如图1所示。实验分3个组块进行,实验时组块呈现顺序亦随机。每个组块大约耗时8~9分钟,组块间让被试短暂休息和调整2~3分钟。被试加工的所有语料,包括填充语料,均为同一种形式呈现。
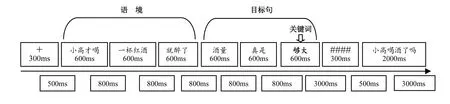
图1 实验刺激流程示意图
2.4 脑电记录及处理
使用NeuroScan 64导电极帽(10/20系统),通过Neuroscan Synamps 2同步记录脑电。左侧乳突(M1)记录值为参考,离线分析时重新转换成双侧乳突连线为参考。前额接地,使皮肤与电极间的阻抗保持在5kΩ以下。同时在双眼外侧安置电极记录水平眼电(HEOG),在左眼上下眶安置电极记录垂直眼电(VEOG)。脑电信号由放大器放大,对各类刺激总平均的ERP波形进行40Hz的低通滤波,采样频率为1000Hz,离线分析处理ERP数据。
本研究主要参考了Regel等(2011:283)的兴趣区(Region of Interest,ROI)划分。(6)Regel等(2011)的兴趣区划分不仅兼顾左右半球和中线,还区分了前部和后部脑区,有利于我们对反语加工脑区分布的考察以及对实验结果的分析讨论。我们的电极帽没有AF7和AF8这两个点,因此就近换成了FP1和FP2,而且这样跟P2和P6兴趣区中的O1和O2两个点在分布上更对称。

图2 统计兴趣区划分示意图(改自Regel等 2011:283)
如图2所示,大脑被分成了前(Anterior,A)、后(Posterior,P)部脑区,再分别划分了前、后部脑区的兴趣区A1-A7和P1-P7。
我们使用Neuroscan 4.3离线处理ERP数据。使用DC矫正去除脑电采集中慢电位漂移造成的伪迹,利用回归的方法去除眼电伪迹。每个兴趣区上字面和反语解读的关键词诱发的ERPs被分别叠加,叠加的时间区段为1100ms,自刺激呈现前100ms至刺激呈现后1000ms,取刺激呈现前100ms作基线。在这些分析时段里,波幅大于±80μV的伪迹信号被剔除。
数据统计时,本实验关注反语解读的关键词可能诱发的N400和P600成分,因此在可能出现N400成分的300-350ms、350-400ms和400-450ms三个时窗,以及可能出现P600成分的700-750ms、750-800ms和800-850ms三个时窗对字面和反语解读的关键词诱发的ERP平均幅值进行统计分析。统计采用SPSS11.5软件进行3因素28水平,即类型(2)× 前/后部(2)× 兴趣区(7)的重复测量方差分析。(7)类型因素2水平,即字面和反语解读两类目标句关键词;前/后部脑区因素2水平;兴趣区因素7水平,包括了前、后部脑区对应的7个兴趣区(A1-A7和P1-P7)。在进行方差分析之前,首先计算每个兴趣区内3个电极点波幅的平均值。对统计结果采用Greenhouse-Geisser算法对得到的p值进行校正,统计检验采用0.05的α水平,同时关注边缘显著差异。(8)本研究对边缘显著差异的认定主要参考了Regel等(2011)和Spotorno等(2013)等对数据处理结果的相关分析,认定如果0.05< p < 0.10,则存在边缘显著差异。
3 实验结果
在23名被试中,有7名被试的脑电被剔除:有5名被试(4男1女)因为某段脑电严重污染无法读取而被剔除,另有2名被试(男)的数据在处理步骤的“取平均值”后可接受度低于80%而被剔除。最后,有16名被试的脑电数据用于统计分析。下面报告这16名被试的ERP数据结果。(9)本研究关注的行为数据是被试对实验中出现的所有理解问题的反应的统计,结果表明被试都对问题作出了按键反应,且正确率都在80%以上。
3.1 N400成分
从总平均波形图(图3)(10)本研究关注的是反语加工的时间进程而非脑区分布问题,且限于篇幅,故略去了N400和P600成分的脑电地形图。上观察,目标句关键词诱发的ERPs出现了在300-400ms时窗中的负波,汉语反语解读的关键词较之字面解读诱发了更大的负成分N400。现以350-400ms时窗为例作简要报告。该时窗内,3因素28水平的重复测量统计分析发现:类型主效应非常显著,F (1, 15)=9.15,p=0.009,说明反语解读诱发的成分非常显著地大于字面解读诱发的成分;类型和前/后部交互效应不显著,F (1, 15)=0.65,p=0.434,说明前后部脑区反语和字面解读的脑区激活无显著差异;类型和兴趣区交互效应非常显著,F (6, 90)=6.93,p=0.002,说明在不同的兴趣区反语和字面解读的脑区激活存在显著差异。类型、前/后部和兴趣区交互效应不显著,F (6, 90)=0.87,p=0.449。因为类型和兴趣区交互效应显著,我们重新对每一个兴趣区(A1+P1,A2+P2,……,A7+P7)的类型主效应进行单因素方差分析,发现兴趣区A5+P5类型效应边缘显著,F (1,62)=3.148,p=0.081;兴趣区A6+P6和A7+P7类型效应显著[A6+P6: F (1,62)=4.028 ,p=0.049; A7+P7: F (1,62)=4.624 ,p=0.035],说明反语加工主要在右侧脑区的激活差异明显。
3.2 P600成分
从总平均波形图(图3)上观察,目标句关键词诱发的ERPs出现约始于700ms直至900ms时窗内类似P600的晚期正波,而且汉语反语解读的关键词较之字面诱发较为明显的更大的正成分,我们将其认定为P600。以750-800ms时窗为例,该时窗内3因素28水平的重复测量统计分析发现:类型主效应边缘显著,F (1, 15)=3.703,p=0.074,说明反语解读诱发的成分较显著地大于字面解读诱发的成分;类型和前/后部交互效应边缘显著,F (1, 15)=4.070,p=0.062,说明反语和字面解读的脑区激活存在前后部的较显著的差异;类型和兴趣区交互效应不显著,F (6, 90)=1.085,p=0.377;类型、前/后部和兴趣区交互效应不显著,F (6, 90)=0.815,p=0.561。因为类型和前/后部存在边缘显著的交互效应,我们对这一交互效应进行事后检验,发现类型主效应在前部脑区无显著差异,F (1, 15)=0.354,p=0.561;类型主效应在后部脑区差异显著,F (1, 15)=8.325,p=0.011,说明反语加工在后部脑区有明显的激活。
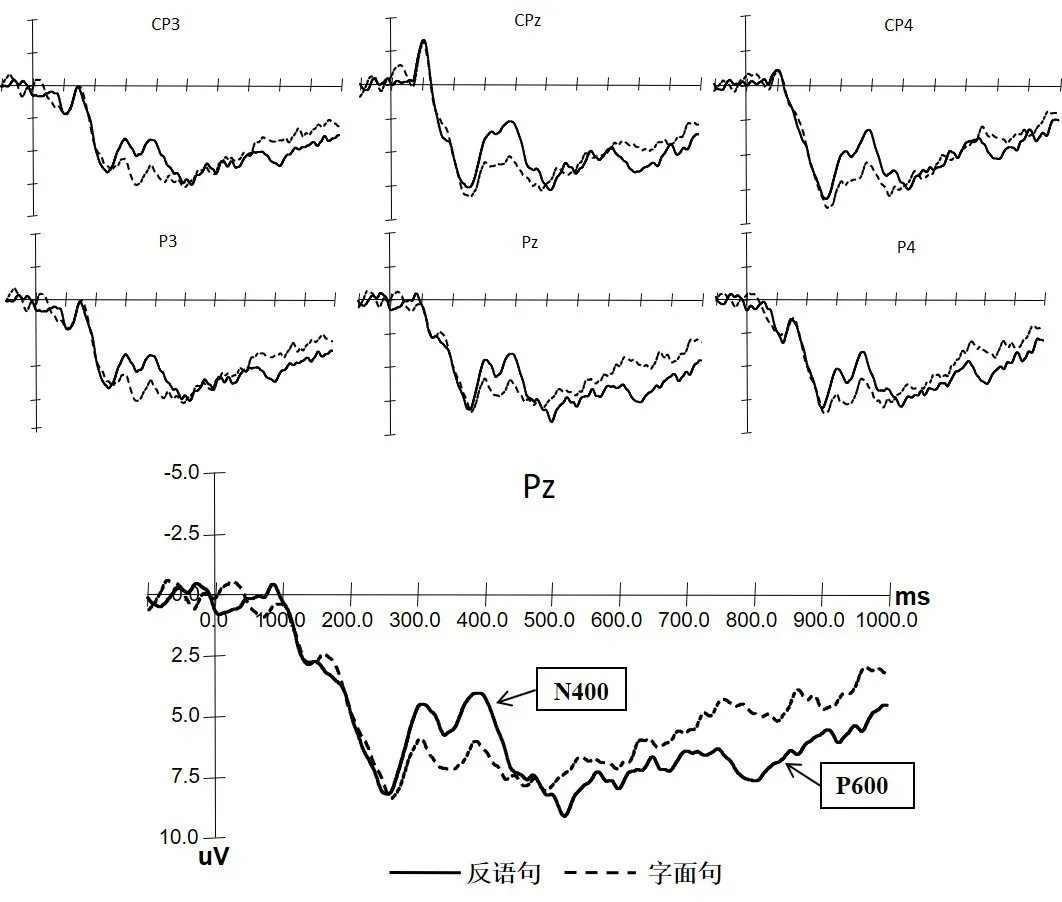
图3 反语和字面关键词的N400和P600的ERP波形图
4 分析与讨论
本实验考察较熟悉的汉语反语理解加工的神经机制,通过对比分析反语和字面关键词诱发的N400和P600,探究反语义的通达是否为不同于字面语言加工的特殊过程,探讨反语加工的时间进程与三大加工模式或假说预期之间的关系。下面我们结合观察和统计得出的N400和P600成分进行分析和讨论。
4.1 汉语反语的加工经历了早期语义整合
就N400而言,其波幅在300-400ms时间窗内差异最为显著,而且分布广泛,汉语反语解读相比于字面解读诱发了更大的脑电负波,提示反语义的理解需要额外的认知加工。这样的结果跟Cornejo等(2007)、奉先武(2011)和Filik等(2014)等的相关ERP研究结果一致,而跟Regel等(2011)和Spotorno等(2013)的实验结果相反,因为这两个研究也关注了N400成分可能的潜伏期时窗,但并没有观察到预期的N400效应。
对此,Spotorno等(2013)只是提到了N400可能对语用推理高度敏感,或者反映了基于语义记忆系统,新输入词的词汇信息和已经存储在语义记忆中的信息的比较。Cornejo等(2007:423)的实验发现了N400,在讨论N400的诱发因素时提到N400与语境提示多少的关系,认为其实验语料的语境描写较少,而当语境提示信息较少时,反语诱发了N400成分,是预期被打破的典型特征。Regel等(2011)就其研究没有发现N400专门进行解释,认为反语N400效应的缺失暗示在支持性的语境下比喻义的加工不涉及语义整合困难。因此,在反语的理解过程中,语义不一致的识别对于整合字面义和前面的语境信息来说不是必要的,如果语用上可行(即通达比喻意义)便不会诱发N400。Regel等(2011:280)的实验语料的语境信息比较丰富,因而没有观察到N400,这跟上述Cornejo等(2007)的解释是一致的。后来,Filik等(2014:817)在其研究的讨论部分也提出,未发现N400的Regel等(2011)的研究值得深究,一种可能的解释是,如果跟经典的N400有相似的脑区分布的P600在N400的时窗内已经出现了,那么它可能使任何N400效应都不明显。
回到我们的实验结果,上述可能的解释都不适用。首先,关于语境提示信息丰富与否,我们的语料(见本文2.2节)跟Regel等(2011)在编排形式和语境提示信息的丰富程度上大致相同,有着支持性的丰富的语境信息,但我们观察到了N400效应。其次,关于Cornejo等(2007)提到的预期打破与否的说法,我们的实验经过预测试与筛选,排除语料本身的语境提示信息不够丰富的可能性后,预期打破与否还跟反语解读语料的出现频次有关。但是,我们的语料中偏向字面解读和偏向反语解读的数量是相同的,而且跟Regel等(2011)的实验二一样还加入了填充语料,目的就是要消除被试对反语出现的预期。因此,我们的实验中反语义的加工诱发的N400就不是预期被打破造成的,而应该是反映了反语的语义整合加工。最后,关于P600可能出现在N400的时窗进而使N400效应不明显的说法,我们的实验不仅观察到了N400效应,也观察到了类似P600的效应(见图3和下一小节的专门讨论),二者的波形总体上是清晰可辨的,因此这种说法也不成立。
因此,如果上述导致N400缺失的可能原因和解释成立,我们的实验也将无法观察到N400。那么,本实验中观察到的N400效应怎么解释呢? N400作为语言加工指标的功能意义大致是反映语义、语用或世界知识出现异常,语义的不可预期性,语言编码与语境之间的不一致,或者是将新出现的词整合到句子语境中的加工等,而且其波幅大小反映语义记忆提取的难易程度(参见Kutas和Hillyard 1980;Niewland和Van Berkum 2006;Kutas和Federmeier 2011;Filik等 2014)。结合其功能意义,我们认为本实验的N400波幅反映反语义的加工更费力,是汉语反语的字面形式的语言编码跟语境不一致,或者超出被试预期,从而造成了将不合理的字面义整合到反语语境之中的语义整合困难。
4.2 汉语反语的加工经历了后期语用推理
本实验观察到具有边缘显著差异的P600效应,这与之前的相关ERP实验发现(如Cornejo等 2007;Regel等 2011;Spotorno等 2013;Filik等 2014;奉先武 2011)基本一致,反语和字面解读的关键词诱发的脑电在P600成分潜伏期内的750-850ms时窗内存在边缘显著的类型主效应差异以及类型与前/后部脑区的交互效应。反语解读诱发了更大的晚期正成分,说明其加工有更大程度的激活,提示反语义的晚期加工推理更费力。P600作为语言加工指标的功能意义大致是反映词语出现语法异常,与结构的重新分析、修补相关联的句法加工和整合过程,各类信息的晚期整合加工,比喻语言加工过程中的隐含义的语用解读等(参见Coulson和Lovett 2010;Regel等 2011;Spotorno等 2013;Filik等 2014),结合其功能意义,我们认为这一P600效应反映了反语义的后期各类信息整合加工更费力,其中包含了语用推理过程:将不符合预期的字面义和非语言信息(语境、语用)重新整合,解决字面义和传递真实语用意图的非字面义之间的冲突,最终得到符合语境的语用含意,即反语义。
需要注意的是,关于N400和P600作为语言加工指标的功能意义并非那么泾渭分明,甚至可能存在重合之处。比如,Kutas和Federmeier(2000)的研究发现N400是语义-语用异常引发的,无独有偶,Ericsson等(2008)的研究发现P600也受语义-语用异常的影响。因此,如果N400和P600都是反映语义-语用异常的指标,那么Regel等(2011)和Spotorno等(2013)的实验未发现N400的原因可能是其语料加工的语义-语用异常的整合集中反映在了P600指标上;或者如Filik等(2014)指出的,跟N400有相似脑区分布的P600出现在N400的时窗内,导致N400效应不明显。这或许能解释为什么我们梳理的所有相关研究都一致地报告了P600效应,而N400效应的报告却存在不一致。当然,这还需要更多的实验研究来进一步验证。
4.3 汉语反语的加工最可能采取标准语用模式
现在我们就本文一开始提出的研究问题,结合本实验的预期和结果进行分析讨论。首先,汉语反语的加工是一个不同于字面语言加工的特殊过程吗?我们对较熟悉的汉语反语的ERP研究发现,反语义较之对应的字面义诱发的N400存在显著差异,前者的负波幅明显大于后者,说明反语义的加工存在语义整合的困难,需要额外的加工努力。同样,反语义较之对应的字面义诱发的P600存在边缘显著差异,前者的正波幅大于后者,说明反语义的加工还需要后期语用推理等整合加工努力。这说明汉语反语的加工是一个不同于字面语言加工的特殊过程,经历了早期的语义整合(N400效应)和后期的语用推理(P600效应)。同时,这样的结果也就否定了“理解反语并非一定需要理解字面话语所需要的认知加工之外的特别加工”(Gibbs 1994:437)的观点。
其次,本研究中汉语反语的加工时间进程跟三大模式或假说的预期是什么关系呢?或者说哪种模式或假说更具适用性?1)根据SPM,反语的字面义应先被加工,预期反映早期语义整合困难的N400成分的出现;同时,该模式假定字面义在后期被重新分析为反语则预期作为语用整合推理指标的类似P600的晚期成分的出现。反语义的N400效应和P600效应这样的实验结果反映汉语反语加工体现出难于一般语言加工,经历了早期语义整合和后期语用推理的特点,其加工可能采取了类似SPM的方式。2)根据DAV,当反语被置于信息足够丰富的语境中时,反语义被直接通达而不会出现任何ERP效应。本实验发现的N400效应和P600效应说明汉语反语加工不可能采取这样的加工方式。3)根据GSH,突显度高(在本研究中对应熟悉度高)的语义先被加工,因此只有不熟悉的反语存在语义整合困难以及之后的重新分析,从而诱发N400和P600效应;熟悉反语的字面义和反语义则被平行加工,二者诱发的N400或P600波幅无显著差异。本实验发现的N400和P600效应似乎说明汉语反语加工可能采取了GSH关于不熟悉反语的加工方式。这是否说明我们的实验结果符合GSH的部分预期呢?
这个问题值得进一步探讨。首先,对熟悉度的区分源自GSH的核心概念“突显”,因为该假说正是基于不同的突显度而做出了区别性的比喻义加工预期。其次,突显性被定义为跟规约性、频率、熟悉度或原型性密切相关(Giora 1997,1999),而Giora(2003)进一步提出在语用学实验中,往往采用主观的熟悉度评分(ratings)作为突显的代理指标,因为这似乎是相关文献中最为常用的考量。接下来的问题就是熟悉度的区分标准和具体考量方法。比如Filik等(2014)的研究让被试对目标语料的熟悉度进行8点评分测量的方法(1表示语料很少或者没有听说被用作反语,8表示非常熟悉的反语),最终入选的“熟悉反语”平均得分6.50,“不熟悉反语”平均得分2.69(Filik等 2014:815),而且实验结果跟GSH的预期最为一致。我们的实验虽然没有进行不同熟悉度反语加工的比较,不能全面地验证GSH,但较之没有控制语料熟悉度的Cornejo等(2007)、Regel等(2011)和Spotorno等(2013)的研究,我们的研究跟Filik等(2014)有可比之处:本实验语料经过筛选,熟悉度控制在“较熟悉”(在5点测量中均值约为3.90),较之我们在开篇提到的“想得美”和“你真坏”这种“非常熟悉的反语”,大致相当于Filik等(2014)实验中的“熟悉反语”(在8点评分测量中均值约为6.52)。我们的实验发现了“较熟悉反语”加工的N400和P600效应,跟Filik等(2014)关于“不熟悉反语”实验的结果类似,因此也符合GSH关于突显度较低的反语加工的预期。同时我们发现,需要进行更多不同熟悉度的反语加工实验来进一步全面验证GSH的预期以及突显度的细分:比如三种甚至更多的熟悉度(非常熟悉、较熟悉、较不熟悉、不熟悉)的语料的实验结果会怎样,跟GSH的两种预期会是什么关系,区分几种熟悉度才能兼顾GSH理论的经济性和有效性,在实操中如何把控熟悉度,等等。这些问题为我们今后的研究提供了方向。
5 结语
本实验使用ERP技术考察了较熟悉的汉语反语和对应字面控制语料的认知加工过程。根据我们对实验结果的分析和讨论,结论如下:
1)反语义较之字面义诱发了更大的N400和P600波幅,提示反语义的加工过程经历了不符预期(或语境)的语义整合以及后期语用整合推理,其理解是不同于字面语言、需要额外的加工努力的特殊过程;这样的结果否定了Gibbs(1994)关于字面义和比喻义的加工不存在原则上的区分的观点。
2)本实验结果反映汉语反语加工体现出区别于字面语言加工、需要语义整合和语用推理过程的特点,说明其加工最可能采取了标准语用模式,而非直接通达观的加工模式。
最后,本研究的改进之处和下一步研究方向可考虑:
1)实验技术手段的加强和多样化,比如实验语料的图片加文字呈现方式(Wakusawa等 2007),采用跟ERP技术互补的高空间分辨率的fMRI(功能性磁共振成像)技术,以及TFA(时频分析)技术(Spotorno等 2013)等。
2)关于分级突显理论和熟悉度问题,在理论上需要进一步探究突显的定义及突显度跟熟悉度的关系,在实践中需要使突显度和熟悉度的考量和区分方法更客观和可操作,比如参考使用词频词典(刘源等 1990)。
3)对其他类别反语的考察,比如考察并比较分析褒词贬用和贬词褒用反语,以及依赖语义知识理解和依赖世界知识理解的反语等。
猜你喜欢
通信技术(2021年12期)2022-01-25
商丘师范学院学报(2021年4期)2021-02-01
浙江大学学报(人文社会科学版)预印本(2020年6期)2020-11-16
文化创新比较研究(2020年3期)2020-04-14
学生导报·高中版(2019年4期)2019-09-10
阅读与作文(英语高中版)(2018年8期)2018-12-28
新高考·英语基础(高一)(2016年7期)2017-07-06
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
