
分类矩阵对象数据的BC-k-modes聚类算法
2020-11-21 07:45李顺勇王改变
河南科学 2020年10期
李顺勇, 余 曼, 王改变
(山西大学数学科学学院,太原 030006)
聚类分析[1-3]是常见的多元统计分析方法的一个分支,被广泛应用于多个领域,如电信、保险、银行和医疗数据库中. 聚类的主要目的之一是对数据进行分类,使得在同一个簇中对象间的距离尽可能小,在不同簇中对象间的距离尽可能大. 因此,数据聚类可以帮助我们深入了解数据的分布.
数据一般可以分为数值型、分类型以及混合型,根据数据类型不同,提出了各种各样的聚类算法. k-means算法[4-5]是对数值型数据进行聚类的算法之一,该算法是对数据计算均值然后将其聚类. 与数值型数据不同,由于分类数据的无序性和离散性,若还是计算它的均值,就会显得牵强,因而k-means聚类过程不能直接用于分类数据. 基于此,诸多研究人员发展了分类型数据聚类的几种算法. Huang[6]在1998 年提出了k-modes 算法,对分类对象采用简单匹配不相似度测量,用modes 代替means 来代表聚类的中心,并且提出了一种基于频率的更新模式的方法. 这样的处理使得聚类过程能够对分类数据进行聚类,消除了对于数值的限制.Cao[7]提出了一类时变数据的广义聚类框架. Bai[8]提出了一种对于分类数据能同时找到初始聚类中心和聚类数的初始化方法. Liang[9]提出了一种用于高维分类数据聚类的属性加权算法. Liang[10-14]基于多项度量对分类数据提出了多种聚类算法. Cao[15]对分类矩阵对象数据提出了一种新的算法:k-mw-modes算法.
本文利用簇间信息建立新的目标函数;结合目标函数提出了一种新的聚类算法;导出了隶属度矩阵以及聚类原型的更新公式;在真实数据集上进行了实验,验证了该算法的有效性.
1 回顾k-modes算法

2 分类矩阵对象数据聚类算法(between-cluster k-modes,BC-k-modes)
2.1 簇间信息

2.2 对象间的相异性度量


2.3 BC-k-modes聚类算法


Algorithm:BC-k-modes算法
Input:
1:-n:每个集群中对象的数量;
2:-k:聚类个数;
3:-ε:阈值;
4:-X:由m个属性描述的n个矩阵对象数据;
5:-idcenters:k个初始类中心的标签;
6:Output:
7:-cid:聚类后对象标签;
8:-num:迭代次数;
9:Method:
10:Z按照索引在idcenters中存储k个初始中心,value=0,num=0;
11:while num ≤100 do
12: newvalue=0;
13: for i=1 to n do
14: for l=1 to k do
15: 通过式(7)计算第l个簇与其他簇之间的相似性度量;
16: 通过式(11)计算第i个对象到第l个聚类中心的距离;
17: 通过式(18)计算第i个对象到第l个聚类中心的隶属度;
18: end for
19: end for
21: if |newvalue-value |≤ε,break;else value=newvalue 且num=num+1;
22: for l=1 to k do
23: 启发式算法更新类中心;
24: end for
25:end while.
3 实验分析
在本节中,我们主要在Market Basket data(Data website下载),Market Basket data数据包括1001个用户的交易记录,Microsoft web data(UCI数据集下载),Microsoft web data记录了1998年2月的一个星期内随机选择的32 711个匿名用户在访问这些网站的情况,Musk data(UCI数据集下载),Musk data记录由167个属性描述的92个对象,MovieLens data(MovieLens website 下载),记录了6040 个用户对3900 部电影的1 000 209 条评分情况,Alibaba data(competition website 下载)记录了793名用户的165 655条的访问记录,在五个数据集上进行了实验,来评估所提算法的有效性. 首先对五组数据进行了数据预处理,接着使用文献[15]中的五个评价指标,将该算法与其他算法进行比较. 五个真实数据集的预处理结果见表1.

表1 预处理后的数据集Tab.1 Preprocessed data sets
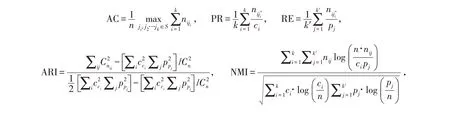
3.1 评价指标

3.2 BC-k-modes算法与其他算法的比较

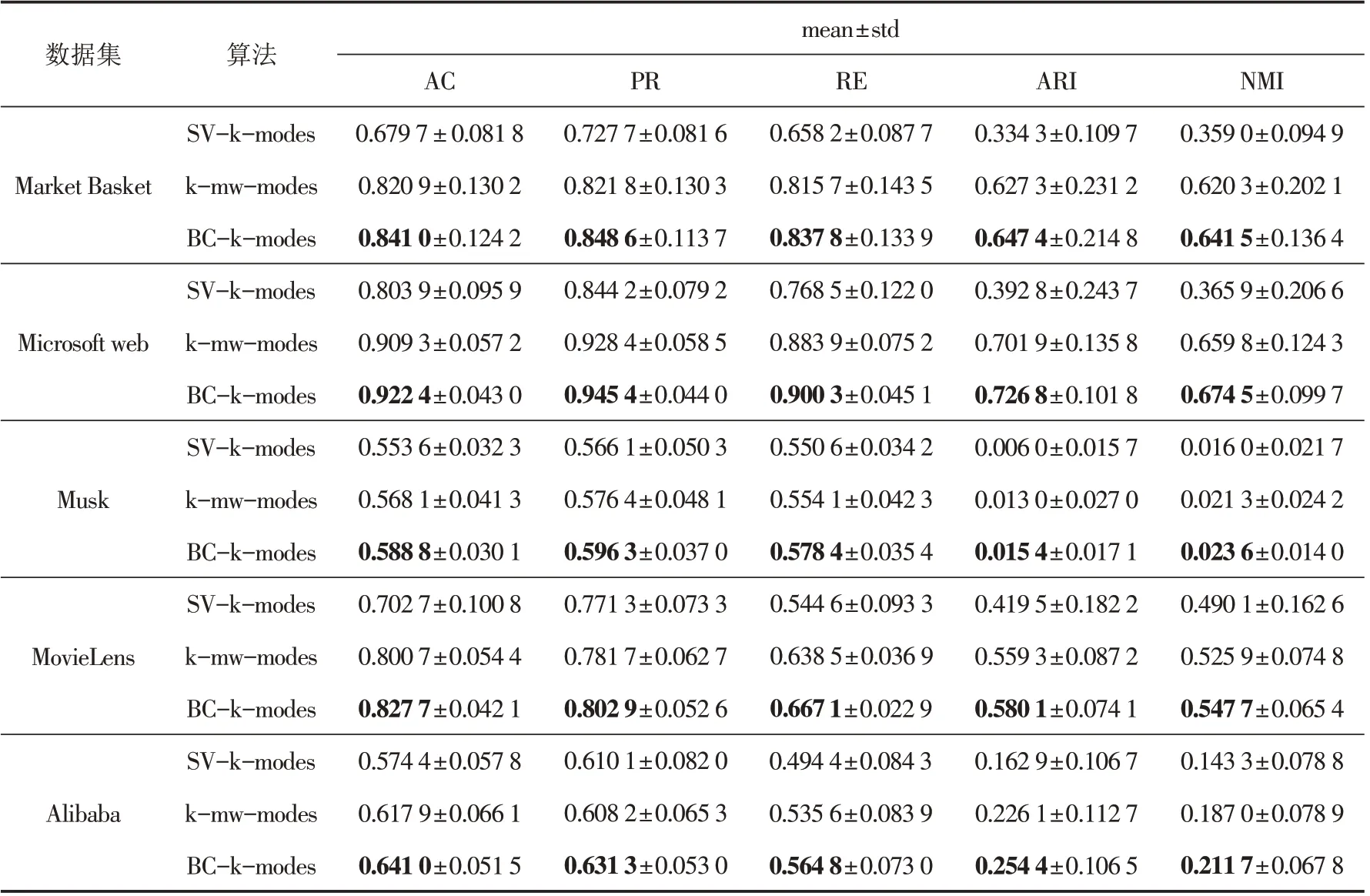
表2 在五个实验数据集上三种算法比较Tab.2 Three algorithms compared on five experimental data sets
表2 表明BC-k-modes 算法比SV-k-modes 算法相比在Market Basket data,Microsoft web data 两个数据集AC,PR,RE 的值提高了15%,在ARI,NMI 上的值提高了30%,在Musk data 数据集上AC,PR,RE 的值提高了3%,ARI,NMI 上的值也有所提高,在MovieLens data 上AC,RE,ARI 的值提高了12%,最高提高了16%,在PR,NMI 的值提高了3%~5%,与Alibaba data 相比,AC,RE,ARI,NMI 提高了5%~9%,在PR 上也有所提高. 与k-mw-modes 算法相比,BC-k-modes 算法在AC,PR,RE,ARI,NMI 的值提高了2%~3%,说明聚类效果更好.
图1~图5分析了五组数据在五个评价指标的箱线图. 其中中间的黑线表示均值,上下值波动的幅度表示标准差.
从图1~图5可以看出,BC-k-modes算法的均值明显高于SV-k-modes,k-mw-modes算法,且BC-k-modes算法是在k-mw-modes算法的基础上增加簇间信息,还可以看出BC-k-modes算法比k-mw-modes算法的波动浮动更小,聚类的效果更稳定.

图1 五组数据在AC上的箱线图Fig.1 Boxplots of five sets of data on AC

图2 五组数据在PR上的箱线图Fig.2 Boxplots of five sets of data on PR
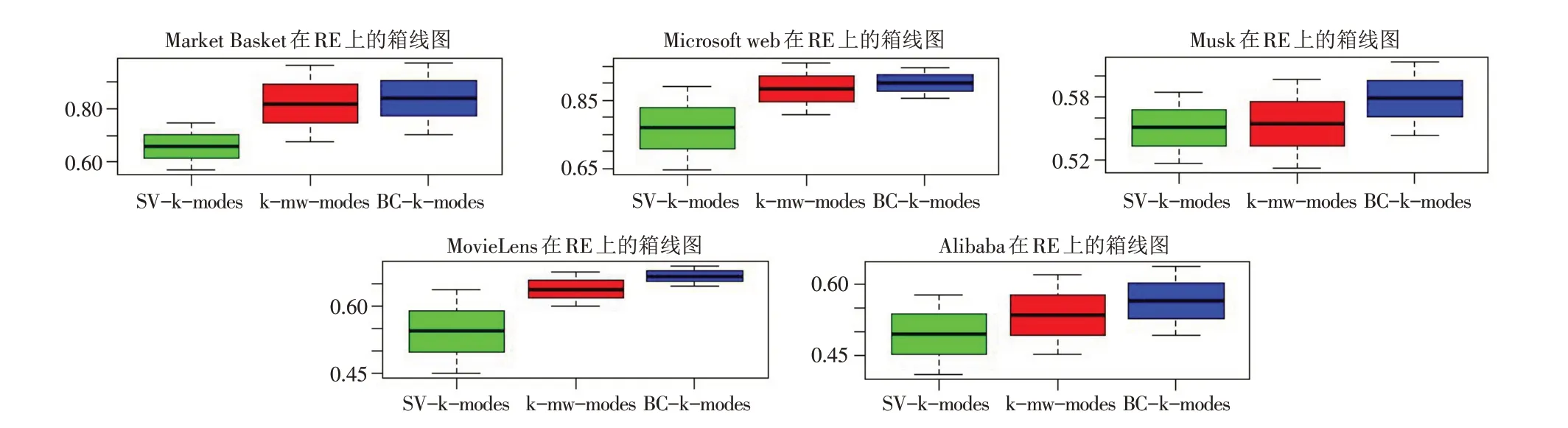
图3 五组数据在RE上的箱线图Fig.3 Boxplots of five sets of data on RE

图4 五组数据在ARI上的箱线图Fig.4 Boxplots of five sets of data on ARI

图5 五组数据在NMI上的箱线图Fig.5 Boxplots of five sets of data on NMI
4 结论
本文对于矩阵对象数据提出了一种新的聚类算法:BC-k-modes. 在BC-k-modes算法中,首先给出矩阵对象之间的相异性度量,其次引入了簇间信息,提出了新的目标函数,通过目标函数解决了矩阵对象数据的聚类问题. 最后在五个真实数据集上验证了BC-k-modes算法的有效性.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
四川大学学报(自然科学版)(2021年6期)2021-12-27
新疆大学学报(自然科学版)(中英文)(2021年5期)2021-10-10
现代临床医学(2021年1期)2021-01-26
计算机应用(2020年12期)2020-12-31
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
文苑(2015年9期)2015-09-10
湖南师范大学学报·自然科学版(2014年1期)2014-03-13
