
Pythagorean犹豫模糊熵及其多属性群决策方法*
2020-11-16 04:36张俊芳周礼刚薛明香
重庆工商大学学报(自然科学版) 2020年6期
张俊芳, 吴 澎, 周礼刚, 肖 箭, 薛明香
(安徽大学 数学科学学院,合肥 230601)
0 引 言
自Zadeh首次提出模糊集[1]以来,人们对其进行了广泛而深入的研究,并提出了一些新的模糊集,例如直觉模糊集[2]、区间直觉模糊集[3]、二型模糊集[3]等研究不仅丰富和发展了模糊集的理论基础,而且极大地推广了模糊集的应用范围,使之能更多地应用于解决实际问题当中。在此基础上,Yager[4-5]提出了Pythagorean模糊集,Torra[6]提出了犹豫模糊集,这两者均有着各自突出的优点和应用前景,文献[7]将两者结合给出了一种新的模糊集:Pythagorean犹豫模糊集。将此二者相结合不仅扩充了模糊集的理论基础,而且对实际问题中决策方案的选取也有非常重要的意义。
熵测度作为研究模糊集的一种重要工具,Zadeh[8]首次引入之后,Luca和Termini[9]又基于Shannon函数给出了模糊集中熵的公理化定义。Bruillo[10]提出了直觉模糊环境下熵的公理化定义,并给出了计算公式;随后,Szmidt和Kacprzyk[11]在文献[9]的基础上,将信息熵定义扩展到了直觉模糊环境当中。为解决直觉指数不稳定的问题,王和雷[12]又给出了一种新的直觉模糊熵的构造方法。在直觉模糊熵方面,文献[14]和文献[15]也做出了很多贡献。使得直觉模糊熵公理化定义更加完善。
在犹豫模糊环境中,Xu和Xia[15]为衡量犹豫模糊值与其补集的差异化程度,提出了犹豫模糊熵的公理化定义,并给出其计算公式;之后,文献[16]从犹豫模糊集中各元素与0.5的距离不同的角度出发,提出了一种新的公理化定义和计算公式;文献[17]基于得分函数和离差函数,设计了一种新的犹豫模糊熵的公理化定义。但是,目前关于Pythagorean犹豫模糊熵的研究较少。
提出一种基于Pythagorean犹豫模糊熵的多属性群决策方法。首先提出Pythagorean犹豫模糊熵的公理化定义,然后提出Pythagorean犹豫模糊上的计算公式,并提出一种基于Pythagorean犹豫模糊熵的多属性决策方法。最后,将新方法应用到精准扶贫项目决策中,验证其可行性和有效性。
1 基本概念
定义1[1]设X为论域,则A={
定义2[2]设X为论域,则
A={
vA(x)≤1,x∈X}
称为X上的一个直觉模糊集,其中
μA(x):X→[0,1],vA(x):X→[0,1]
分别表示X上元素x∈X的隶属度和非隶属度
πA(x)=1-μA(x)-vA(x)
为其犹豫度。
记β=(μβ,vβ)为直觉模糊数,且满足条件0≤μβ,vβ≤1,0≤μβ+vβ≤1。
定义3[6]设X为论域,
A={
称为X上的一个犹豫模糊集,其中hA(x)表示X上元素x∈A的所有可能隶属度组成的集合。
记hA={h1,h2,…,hl}为犹豫模糊数,且满足条件0≤hi≤1,i=1,2,…,l,hi≤hi+1。
定义4[4]设X为论域,
A={

定义5[7]设X为论域,则称三元组
A={

为x属于A所有可能的犹豫度的集合。
注1 当对任意的x∈X,MA(x)和NA(x)均只有一个元素时,Pythagorean犹豫模糊集就退化为Pythagorean模糊数。
注2 称α=
定义6[18]设
α=
<{μα1,μα2,…,μα#Mα},{vα1,vα2,…,vα#Nα}>
是一个Pythagorean犹豫模糊数,则称
(1)
为α的犹豫度,其中#Mα,#Nα分别表示隶属度元素个数和非隶属度元素个数。
2 Pythagorean犹豫模糊数的最小公倍数扩充法
由于在Pythagorean犹豫模糊决策环境下,决策者们对某些问题认知的差异,使得他们对于同一个方案可能会给予不同的Pythagorean犹豫模糊决策信息,可能会出现任意两个Pythagorean犹豫模糊数之间的隶属度集合和非隶属度集合长度不相等的情况。基于此,Liang和Xu[18]采用基于乐观—悲观准则的扩充方法对Pythagorean犹豫模糊数之间长度不等的情况进行处理。
但文献[19]指出了文献[18]提出的方法的有效性是存在争议的,因为从现实角度出发,上述方案既没有解释其决策者决策的主观性,也没有对方法的有效性和必要性进行说明。同时,文献[20]为了规范化处理犹豫模糊语言术语集中的不同元素,提出了一种最小公倍数拓展原则,文献[21]采用最小公倍数拓展法对Pythagorean犹豫模糊集的隶属度(非隶属度)进行规范化处理,但文献[21]关于最小公倍数拓展法的说法较为粗略浅显,且没有给出详细的定义过程和算法步骤,所以,将文献[20]的扩充思想运用到Pythagorean犹豫模糊数的规范化处理中。具体如下:
定义7 设
α=
则称集合
为α的r-s扩充集,且称这种对α的扩充方法为r-s扩充规则。其中,隶属度集合
中的各个元素分别被重复扩充了r次,非隶属度集合
中的各个元素分别被重复扩充了s次。显然扩充后的αr,s仍为Pythagorean犹豫模糊数。
例1 设Pythagorean犹豫模糊数
α1=<{0.1,0.2},{0.7,0.8,0.9}>
则α的2-2扩充集为
{0.7,0.7,0.8,0.8,0.9,0.9}>
定义8 设
α=
是两个Pythagorean犹豫模数,lcm(#Mα,#Mβ)为#Mα和#Mβ的最小公倍数,lcm(#Nα,#Nβ)为#Nα和#Nβ的最小公倍数,其中#Mα,#Nα分别表示α的隶属度元素个数和非隶属度元素个数,#Mβ,#Nβ分别表示β的隶属度元素个数和非隶属度元素个数。令
(2)
(3)
根据定义7和定义8,任意Pythagorean犹豫模糊数均可以通过扩充方法,变成新的Pythagorean犹豫模糊数,扩充方法被称作最小公倍数扩充法。
若采用定义8对Pythagorean犹豫模糊数的隶属度和非隶属度进行扩充,则可得到基于最小公倍数扩充法的Pythagorean犹豫模糊数规范化方法,基于扩充Pythagorean犹豫模糊数的规范化算法如下:
输入:任意两个Pythagorean犹豫模糊数α=
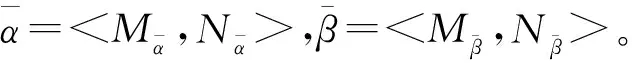
步骤1 计算Pythagorean犹豫模糊数α和β的元素个数,即:#Mα,#Mβ,#Nα,#Nβ。
步骤2 计算#Mα和#Mβ的最小公倍数lcm(#Mα,#Mβ),#Nα和#Nβ的最小公倍数lcm(#Nα,#Nβ)。

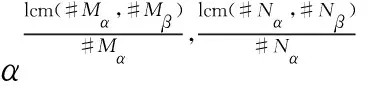
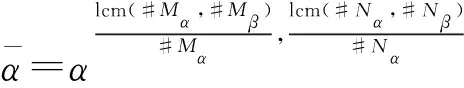
步骤6 结束。
例2 设有两个Pythagorean犹豫模糊数
α=<{0.1,0.2},{0.7,0.8,0.9}>
β=<{0.7,0.8,0.9},{0.1,0.2}>
根据算法1,则有
#Mα=2,#Mβ=3,#Nα=3,#Nβ=2;
lcm(#Mα,#Mβ)=6,lcm(#Nα,#Nβ)=6;
{0.7,0.7,0.8,0.8,0.9,0.9}>;
{0.1,0.1,0.1,0.2,0.2,0.2}>。
定义9[18]设
α=<{μ1,…,μ#Mα},{v1,…,v#Nα}>,
β=<{μ1,…,μ#Mβ},{v1,…,v#Nβ}>
是两个Pythagorean犹豫模糊数,则α和β之间的欧氏距离定义为

其中,lcm(#Mα,#Mβ)=τ,lcm(#Nα,#Nβ)=φ,πα和πβ由式(1)给出。
3 Pythagorean犹豫模糊熵
Pythagorean犹豫模糊熵可以有效度量模糊信息的模糊程度,能够将模糊程度较高的数据转化更有利于决策者精确评价的信息。对于两个Pythagorean犹豫模糊数:
α=<{μ1,μ2,…,μ#Mα},{v1,v2,…,v#Nα}>∈PHFN
β=<{μ1,μ2,…,μ#Mβ},{v1,v2,…,v#Nβ}>∈PHFN
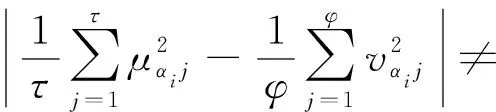
定义10 设A={α1,α2,…,αn}是一个Pythagorean犹豫模糊集,其中
αi=
{vαi1,vαi2,…,vαiφ}>
是一个Pythagorean犹豫模糊数,则A的熵可定义为

(3)
定理1 设
α=
<{μα1,μα2,…,μα#Mα},
{vα1,vα2,…,vα#Nα}>
β=
<{μβ1,μβ2,…,μβ#Mβ},
{vβ1,vβ2,…,vβ#Nβ}>
是两个Pythagorean犹豫模糊数,E:α,β→[0,1]为Pythagorean犹豫模糊熵,则E满足以下性质:
(1)E(α)=0,当且仅当
α=<{1,1,…,1},{0,0,…,0}>
或
α=<{0,0,…,0},{1,1,…,1}>

(3)E(α)=E(αc),这里αc=
(4) 当E(α′)≤E(β′)时,有两种情况:
这里
α′=<{μα′1,μα′2,…,μα′τ},{vα′1,vα′2,…,vα′φ}>
β′=<{μβ′1,μβ′2,…,μβ′τ},{vβ′1,vβ′2,…,vβ′φ}>
是α,β经最小公倍数扩充方法规范化处理后的Pythagorean犹豫模糊数。
证明
(1)~(3)显然成立,下证(4)。
(4)(⟹)显然成立;
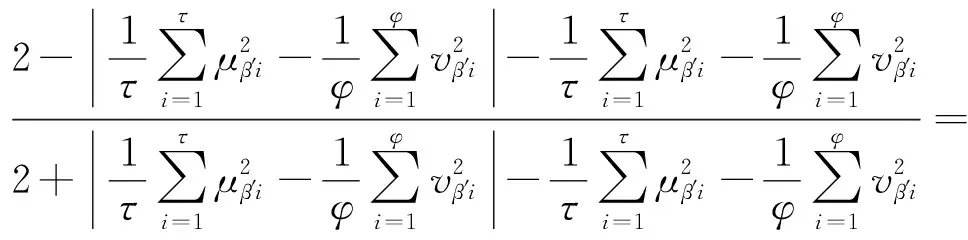
故,E(α′)≤E(β′)。
故E(α′)≤E(β′)。证毕。
4 基于Pythagorean环境下的多属性 群决策方法

(4)
根据熵理论知,如果各方案针对同一属性下的熵值越小,说明该属性的稳定性越高,则应该被赋予一个较大的权重,即Ej越小,其权重wj就越大。
若属性权重wj完全未知,可由式(4)计算属性cj的权重:
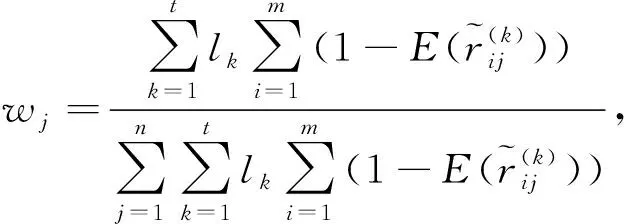
(5)
若属性权重wj部分已知,令H表示未知权重满足的条件集合,则可构建模型求解属性权重:

(6)
TOPSIS法是解决多属性问题的常用方法之一,其宗旨是找出最佳方案和最差方案,即为正理想点和负理想点。方法主要是通过计算离正理想点和负理想点的距离,之后再通过计算贴近度,对方案进行排序和择优。
在Pythagorean犹豫模糊环境下,正理想点为
负理想点为
则方案xi与正理想点的加权距离为

(7)
方案xi与负理想点的加权距离为

(8)
其中wj为属性cj的权重。
方案xi的贴近度可表示为
(9)
故基于Pythagorean犹豫模糊熵的多属性群决策步骤如下:
步骤1 矩阵的规范化处理。设
为决策矩阵,其中:
运用算法1将t个决策者给出的决策矩阵进行规范化处理,规范化后的决策矩阵为

步骤3 属性权重的确定。当属性权重完全未知时,运用式(5)计算属性权重;当属性权重部分已知时,运用式(6)中的模型计算属性权重。
步骤4 对距离进行加权集结。利用加权平均算子和式(7)—式(8)计算各方案与正负理想点的加权平均距离。
步骤5 计算贴近度。利用式(9)计算各方案的贴近度,并对其降序排列。
步骤6 排序择优。对方案进行排序,并选出最优方案。
5 案例分析
减贫和脱贫是世界各国共同面临的难题,也是全球共同关注和研究的重大课题。针对我国的具体国情,习总书记提出了“脱贫贵在精准、重在精准、成败之举在于精准”的精准扶贫战略。十八届四中全会提出引入第三方评估机制,这是深化我国政府绩效改革。提高政府效能和完善政府治理体系的重要举措。第三方评估机制主要由三股力量来承担,一是高校的专家学者,二是商业运作的专业的管理咨询机构;三是乡镇级村干部代表[22]。
现考虑一个关于精准扶贫的多属性群决策问题。某村有4户人家申请扶贫基金补贴,但目前只有一个名额,即选择上述4户村民x1,x2,x3,x4中的一个,现由第三方评估的3位代表作为决策者d1,d2,d3从下列3个准则出发对这4户村民进行评价:c1:每年家庭的人均收入;c2:家中的劳动力数量;c3:家庭的恩格尔系数。设决策者的权重向量为:L={0.3,0.5,0.2},第k个决策者给出的Pythagorean犹豫模糊矩阵为R(k)(k=1,2,3)如下:
步骤1 利用算法1,对矩阵R(k)(k=1,2,3)做规范化处理:

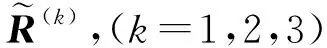
步骤3 利用式(5)计算属性权重得到:
w1=0.148 2,w2=0.406 5,w3=0.445 2
步骤4 计算方案xi与正负理想点的距离:
正负理想点分别为
(<{1,1,1,1,1,1},{0,0,0,0,0,0}>,<{1,
1,1,1},{0,0,0,0}>,<{1,1,1,1},{0,0,
0,0}>)
(<{0,0,0,0,0,0},{1,1,1,1,1,1}>,<{0,
0,0,0},{1,1,1,1}>,<{0,0,0,0},{1,1,
1,1}>)
则方案xi与正负理想点的加权距离为
步骤5 计算方案xi贴近度Pi得到:
P1=0.571 4,P2=0.576 1,
P3=0.556 8,P4=0.554 3。
步骤6 排序和择优。
贴近度排序为:P2>P1>P3>P4,故方案的排序x2>x1>x3>x4,即第二户农户符合扶贫基金补贴政策。
6 结 论
针对模糊信息下的决策问题,提出了一种基于Pythagorean犹豫模糊熵的多属性群决策方法。首先,在之前的研究基础上,构造基于Pythagorean犹豫模糊环境下熵的公理化定义及计算公式,其次,为解决任意多个Pythagorean犹豫模糊数之间隶属度集合和非隶属度集合长度不相等的问题,利用最小公倍数扩充法对Pythagorean犹豫模糊集进行规范化处理,并在之前的基础上,完善了最小公倍数扩充规则的定义及算法;之后,以Pythagorean犹豫模糊熵作为决策信息差异程度的度量,给出属性权重完全未知或部分已知情况下权重的确定方法;最后,以扶贫项目为背景,实例论证了提出的Pythagorean犹豫模糊熵的多属性群决策方法是可行且有效的。未来,Pythagorean犹豫模糊熵可被运用到模糊模式识别、医疗诊断、不确定性决策问题中。
猜你喜欢
北华大学学报(自然科学版)(2022年4期)2022-08-17
心理学报(2022年5期)2022-05-16
中央财经大学学报(2021年8期)2021-08-30
数学大世界(2021年4期)2021-03-30
当代陕西(2020年17期)2020-10-28
数学大王·趣味逻辑(2020年9期)2020-09-06
火力与指挥控制(2020年7期)2020-08-22
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
学校教育研究(2018年15期)2018-05-14
