
齐夫定律在古汉语文本中的适用性研究
——以《梦溪笔谈杂志一》的文献计量为例
2020-10-14 02:01秦克霄
晋图学刊 2020年4期
秦克霄
(山西大学 图书馆,太原 030006)
19世纪以来,随着语言学的发展以及文学风格和速记研究的需要,人们开始对语言的成分进行统计分析。德国语言学家F·W·凯丁(F.W.Kaeding)历时七年,编纂了世界上第一部频率词典——《德语频率词典》(《Häufigkeits wörter buch der Deutschen Sprache》)被认为是第一次现代意义上以统计调查方法完成的词汇研究工作;20世纪初,美国教育学家兼心理学家E·L·桑迪克(E.L.Thorndike)先后编写了《教师二万词词书》(《Teacher’s Word Book of 20 000 Words》)和《教师三万词词书》(《Teacher’s World Book of 30 000 Words》),对英语的词汇作了大量的频率统计工作。伴随着不同语言中有关词频资料的大量积累,词语频次的特征也不断被揭示,人们开始从理论上思考词频差异的现象。由于频率词典实际上就是一种词表,而其中字词的出现频次与字词序排列的序号等级是最基本的两个数据指标,反映了字词的地位和性质,因此,人们首先着重研究的就是这两个基本数据之间的相互关系,试图在一定的篇章范围内总结出语言成分出现频次所满足的严格的数学原理。哈佛大学语言学教授齐夫(G.K.Zipf)在前人研究的基础上,对英语文献中单词出现的频次进行大量统计以检验前人的定量化公式,在此基础上,进行系统的分析并提出了齐夫定律[1]:若把一篇较长的文章中每个字词出现的频次从高到低进行递减排列,字词出现的频次f与它的位序r的乘积为一个常数c,即:
f·r=c。
该公式可以理解为:在自然语言的语料库里,一个单词出现的频次与它在频率表里的排名成反比(又称省力法则)。后又提出更加普适的公式:
将上式两边取自然对数可得:lnf+alnr=lnc,绘制lnf与lnr的关系曲线并作线性回归,即可得到斜率a与截距lnc。齐夫定律表明,在英语单词语料库中,只有极少数的词被经常使用,而绝大多数词很少被使用。
近些年来,在文献计量学和其它学科领域,针对齐夫定律或与其相关的领域有许多补充和深化的研究,国内也有很多学者展开了对齐夫定律本身[2]及其应用[3-6]的研究。近年来,江南大学的研究者以诺贝尔文学奖得主莫言的《红高粱》《蛙》和《透明的红萝卜》为主要研究对象,统计莫言作品中字频、词频,发现都能满足齐夫定律[7]。所得结果与包括英语、西班牙语、法语等在内的多种语言研究结果一致。此研究结果从统计学角度阐明了莫言成为中国大陆首位诺贝尔文学奖得主的可能原因之一。
本文以中国古代具有代表性的百科全书《梦溪笔谈》为例,考察齐夫定律对中国古代汉语语料的适用性。在统计词语频次时,确定词语等级多采用以下两种方法:
(1)并列法。并列法是指遇到同频词时,将这些同频词并列为一个词级,并延承上一个词级。比如词序为第5至第8的词是同频词,同时,第5个词的词级为5,那么这些第5至第8的词的词级都是5;若词序第9至第12的词也是同频词,那么这些词的词级则延承上一词级,为6。在许文霞的《齐夫定律与中文词频分布机理》一文中采用的词级确定方法就是并列法[8]。
(2)随机法。齐夫第一定律在确立时,最先使用的方法是随机法。所谓随机法,就是指在确立词级的过程中,遇到同频词时,按照词语在统计文本的词表中的自然词序或随机排列确定词语的等级,这样每个词的自然或随机词序就是这个词的词级。比如词序为第5至第8的词是同频词,那么这些词的词级随机排列为5、6、7、8。
1 分词原则
(1)根据汉语自身的语言特点,采用计算机自动分词统计,以齐夫定律理论为基础,再参照《现代汉语词典》条目所列出的词语形态,以保留词语语义的完整性为前提。
(2)人名、地名等专有名词均作为独立的词来划分。
(3)统计时,标点符号等非汉字书写符号不计入内。
根据文献中出现的词频(字频)与等级序号的统计数据,建立横坐标表示词的位序r,纵坐标表示相应的频次f的直角坐标系,得到一条双曲线,即:齐夫分布曲线。再将位序r与频次f都取对数坐标,则上图中的图像就变成一条直线,即:齐夫分布对数曲线。若满足这种类型的词频(字频)分布,就叫做齐夫分布。《梦溪笔谈》作为我国古代的科学技术百科全书,在科学史和文学史上都具有重要的地位和代表性,故此,我们选择《梦溪笔谈杂志一》作为研究对象,考证齐夫定律对我国古汉语文本的适用性。
2 文本分析
2.1 字频的统计数据(并列法)
通过对文本《梦溪笔谈杂志一》的统计分析,此段语料共有4 740个书写符,其中,汉字共有4 739个,累计总字数为3 903个,不同字数为1 905个,不同频次数为39次(见表1)。
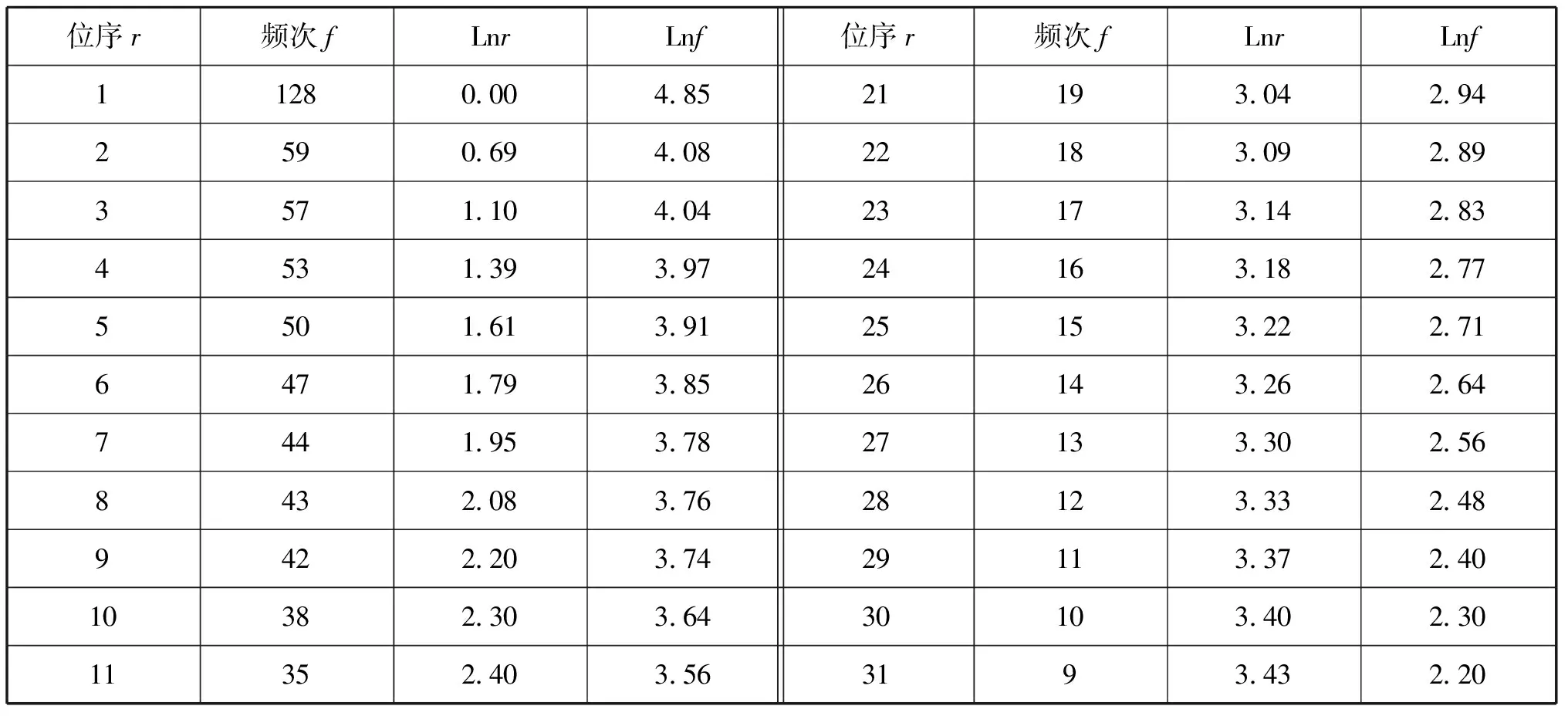
表1 以递增顺序排列的位序r和以递减顺序排列的频率f
2.2 字频的统计分析(并列法)
(1)图1为频次与词级图:
由图1齐夫分布曲线的反比例函数分布特性和齐夫对数分布的线性特性可以看出,采用并列法,该文的字频与位序大致满足齐夫定律。
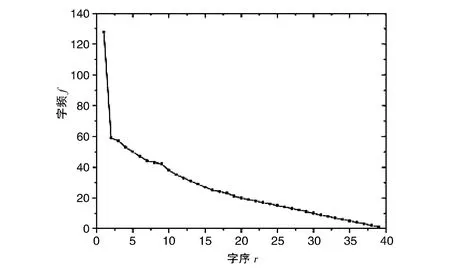
图1 词频f-词序r分布图
(2)由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率a与lnc,如图2所示。

图2 lnf-lnr图以及线性拟合
(3)求a和lnc以及c,如表2所示。
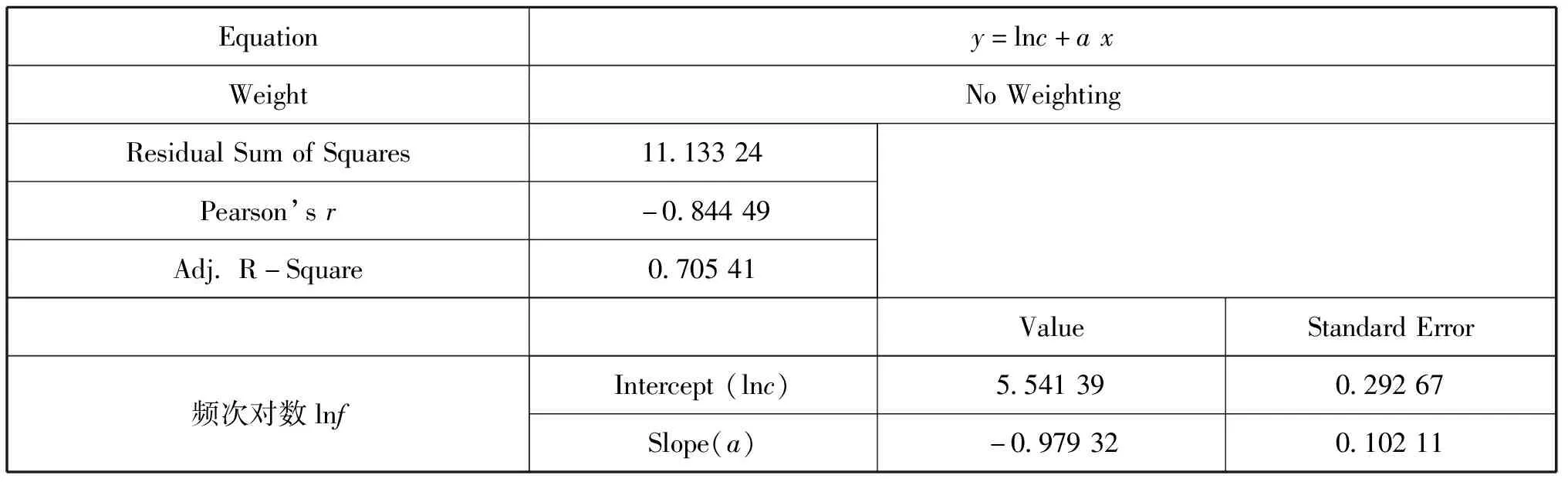
表2 图2的线性拟合分析
由表2可知,修正决定系数Adj.R-Square=0.705 41,反应了线性回归的良好;a=-0.979 32,标准误差为0.102 11。由结果可知,采用并列法得到的统计结果比较符合齐夫定律[7]。
2.3 字频的统计数据(随机法)(见表3)

表3 以递增顺序排列的位序r和以递减顺序排列的频率f
2.4 字频的统计分析(随机法)
(1)图3为频次与词级图。由图3可以看出,采用随机法时字频与词级很好地满足齐夫定律。

图3 词频f-词序r分布图
(2)由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率a与lnc,如图4。
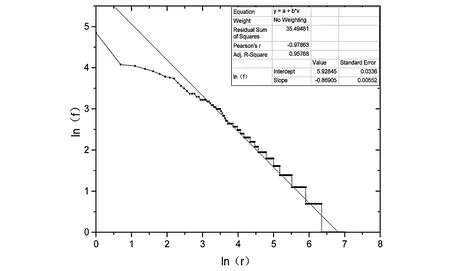
图4 lnf-lnr图以及线性拟合
(3)求a和lnc以及c,如表4所示。由表4可知,修正决定系数Adj.R-Square=0.957 68,反应了线性回归良好;斜率a=-0.869 05接近值-1,标准误差为0.005 52。由此可知,采用随机法得到的结果非常符合齐夫定律。

表4 图4的线性拟合分析
2.5 词频的统计数据(并列法)
此段语料共有4 740个书写符,其中汉字共有4 739个,累计总词数为3 120个,不同词数为1 439个,不同频次数为30次(见表5)。

表5 以递增顺序排列的位序r和以递减顺序排列的频率f
2.6 词频的统计分析(并列法)
(1)图5为频次与词级图。由图5可以看出,采用并列法古汉语《梦溪笔谈杂志一》文本的词频与词级也基本满足齐夫定律。

图5 词频f-词序r分布图
(2)由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率a与lnc,如图6所示。

图6 lnf-lnr图以及线性拟合
(3)求斜率a和lnc以及c,如表6所示。

表6 图6的线性拟合分析
由表6可知,修正决定系数Adj.R-Square=0.731 27,说明线性回归良好;斜率a=-0.992 51接近标准值-1,标准误差为0.109 18。从结果可知,采用并列法得到的结果也比较符合齐夫定律,但不如随机法符合效果好。
2.7 词频的统计数据(随机法)(见表7)

表7 以递增顺序排列的位序r和以递减顺序排列的频率f
2.8 词频的统计分析(随机法)
(1)图7为频次与词级图。由图7可以看出,用随机法时词频与词级符合齐夫分布定律非常好。

图7 词频f-词序r分布图
(2)由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率a与lnc,如图8所示。
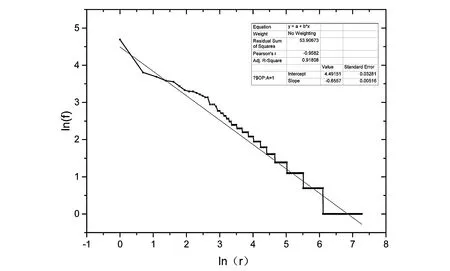
图8 lnf-lnr图以及线性拟合
(3)求a和lnc以及c,如表8所示。
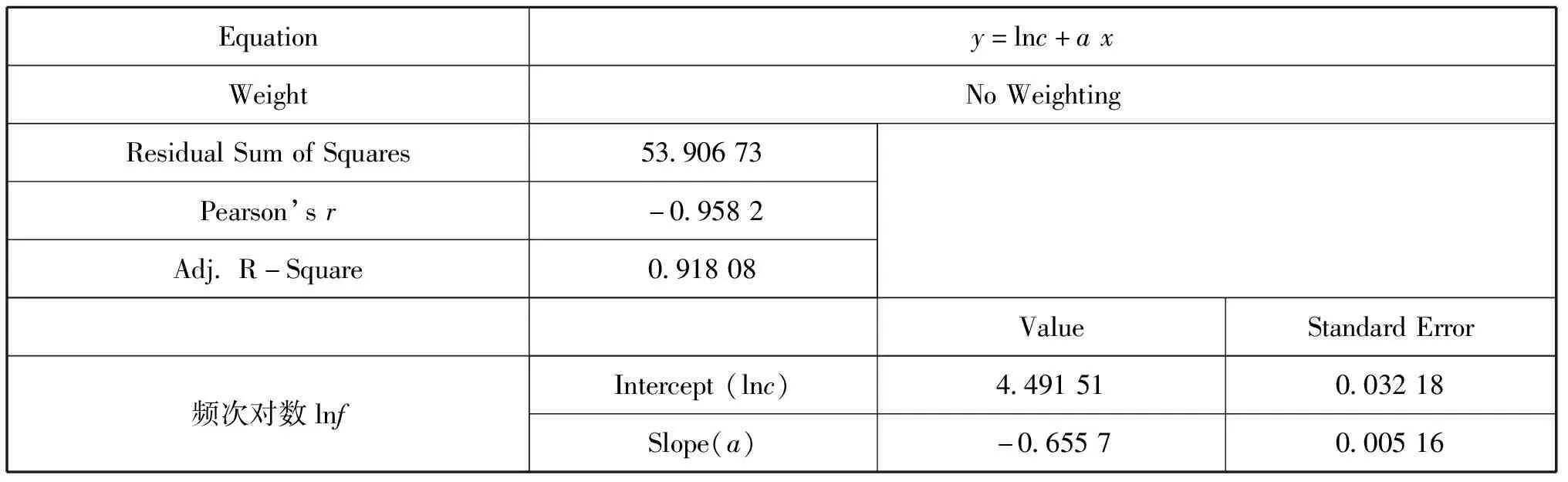
表8 图8的线性拟合分析
由表8可知,修正决定系数Adj.R-Square=0.918 08,反映了线性回归优良;斜率a=-0.655 7接近标准值-1,标准误差=0.005 16,说明词频的统计分析采用随机法得到的结果非常好地符合齐夫定律。
2.9 总结
本文同时采用并列法和随机法对我国古代极具代表性的古汉语文本《梦溪笔谈杂志一》语料的字频(词频)和字序(词序)数据进行了统计和分析,绘制出字频(词频)和字序(词序)的分布图及对数化后的散点分布图。研究结果表明:古汉语文本的字频(词频)和字序(词序)分布曲线呈现出较为明显的双曲线特征;利用专业Origin软件对字频(词频)和字序(词序)的对数化后的散点图作线性回归处理,其分布曲线呈现出线性关系,斜率在-1左右,符合齐夫第一定律的设定,验证了齐夫定律对古汉语文本的适用性。从频次与位序的数据统计分析结果可以看出,无论字频还是词频,采用随机法拟合的结果修正决定系数大,标准误差小,与齐夫定律符合得更好。从词频统计结果我们知道,频次最高的十一个词为“之、有、为、以、其、也、中、而、谓、皆、者”;字频统计结果中频次最高的十个为字“之、有、人、为、其、中、以、不、大、山”。由此可知,俗语云古人只懂“之乎者也”是有一定科学依据的,如同英文中的定冠词“the”、介词“of”和连词“and”。
不同时代以及同时代不同作者具有不同的语言风格特征。如果进行大规模文本统计,通过对语言的字频词频等的分析,有助于甄别作品的作者和写作年代。比如:关于古典名著《红楼梦》的前八十回与后四十回的作者素有争议,齐夫定律可以成为文献考证的一个工具。事实上,齐夫定律除了在语言学、情报学领域运用较多外。在非语言学领域如:地理学、经济学、信息科学等领域也有广泛的应用,例如:社会学领域中城市人口数量分析[9]、公司规模大小分析[10]等。研究表明,无论英语、汉语以及许多国家的语言,只有极少数的词被经常使用,而绝大多数词很少被使用——人类的语言具有经济省力性原则(或曰“惰性”)。莫言在一次访谈中说到,他就上了小学五年级,认识大概五百多个汉字就开始写作,后来可能又增加了五百多个汉字,现在大概是一千多个字。诚如此言,纪录片《摇摇晃晃的人间》的拍摄对象、2018年湖北文学奖获得者、央视《朗读者》节目特邀嘉宾、湖北农村脑瘫女诗人余秀华创作诗歌二千多首,其语言使用的局限性和地域性也同样值得研究和关注。
齐夫定律是描述词频分布规律的强大数学工具,作为经验定律,它仍然有待进一步完善[11]。比如:对高频词汇和低频词汇引入不同的权重因子或参数,结果会更好地符合齐夫定律。这需要分析和研究大规模的文本语料库,如今在大数据和高性能计算机的时代将变为可能。我们相信齐夫定律的运用将会取得更丰硕的成果。
猜你喜欢
孩子(2019年12期)2019-12-27
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
儿童故事画报·智力大王(2019年5期)2019-07-14
中国修辞(2017年0期)2017-01-31
心理与行为研究(2016年4期)2016-12-16
北方文学·中旬(2016年6期)2016-08-01
江西教育C(2015年4期)2015-05-25
读者·校园版(2015年7期)2015-05-14
读者·校园版(2014年7期)2014-05-14
图书馆论坛(2014年8期)2014-03-11
