
基于百度百科多特征信息的词汇相似度计算∗
2020-10-09 02:47黄树成
计算机与数字工程 2020年7期
仲 远 王 芳 黄树成
(江苏科技大学计算机学院 镇江 212003)
1 引言
词汇相似度计算在现实生活中使用非常广泛,如在机器翻译、词义消歧、信息检索等诸多领域就发挥着极为重要的作用。例如在信息检索领域中,词汇相似度计算可以用来衡量用户查询内容和返回结果内容信息的匹配度,从而实现改进检索效果,提高检索结果内容准确率。
国内外的学者们对词汇相似度已经有了大量的研究。在国内,田久乐等提出了基于同义词词林的词汇相似度计算方法[1]。张小川等提出以词语间第一基本义原相似度最高的概念组合为计算对象,并引入动态加权因子实现了对词语语义相似度算法的改进[2]。金博提出基于语义理解的文本相似度算法[3]。李海林提出基于分类词典的文本相似性度量方法[4]。
在国外,Aminul Islam 提出基于语料库的语义相似度计算方法[5]。Junji Tomita 等提出利用基于图形的文本表示模型来计算文本相似度[6]。
通过分析上述国内外学者的研究方法,可以将这些方法分为以下两种[7]:一种是基于统计的方法,另一种是基于知识体系的方法。基于统计的方法,相对客观、全面地反映了词汇所处的上下文,缺点是此方法以综合训练所使用的语料库为依靠,且存在数据稀疏的问题。基于知识体系的方法是通过本体计算语义相似度,此方法简单有效,但是准确性受语义词典的规模和完备性影响较大。
针对上文中提到的不足,本文提出一种基于百度百科的多特征信息词汇相似度计算方法。该方法经由百科名片、词条正文,开放分类和相关词条四个部分的内容,分别计算出它们之间的相似性值,以此来获得一对词汇间的整体相似性。
2 相关工作
2.1 词汇相似度概念介绍
文中的词汇相似度的概念并非完全指的是词汇的意思相似度,在这里可以把它看作是一种近似于语义相关度的概念。假如衡量词汇之间相似度的取值范围在0 和1 之间,如果是0,表示两个词汇毫无关系,相似度很低;如果是1,则表示两个词汇间关系紧密,相似度很高。互为同义词的两个词汇,如“旧金山”和“圣弗朗西斯科”,它们的词汇相似度可以是1;而互为反义词的两个词汇,如“严寒”和“酷暑”,它们之间的词汇相似度也可以是1。但如果是两个风马牛不相及的词汇,如“专家”和“沙发”,就可以认为它们之间的相似度很低,甚至可以将它们的相似度设为0。综上,只要两个词汇之间存在很强的关联性,由词汇A很容易联想到词汇B,那么就可以认为词汇A 和B 之间的相似度很高,否则相似度很低。
2.2 百度百科词条介绍
百度百科中的内容五花八门、包罗万象。截止到2018 年10 月,百度百科已经含有15,598,605 个词条,多达6,618,846 人参与了编写词条内容。可以说百度百科是目前为止规模最大、内容最全面的语料库。百科词条有四个部分在本文研究中发挥了重大作用,分别为名片、正文、开放分类、相关词条。通过对词条各部分内容的分析,可以得到许多有用的信息。
2.3 Words-240测试集介绍
为了验证本文提出方法的有效性,实验中将本文方法与刘群等提出的基于《知网》的相似度计算方法SSCH 进行比较,所以在实验中同样采用了Words-240作为测试集。该测试集一共有240对中文词汇,并且提供了词对之间的语义相关度的参考值,用它来作为依据,来衡量本文提出的中文词汇相似度方法的有效性。词汇之间相关性的考量值在0 和1 之间(如果值是1,则这两个词具有极强的关联性;0则表示毫无联系)。
3 基于百度百科的相似度计算
3.1 词条名片相似度计算
词条的百科是一段短文本,由它来对词条进行简略的描述。实验中对这段短文本建立向量空间模型,然后使用余弦相似度的方法来计算这两段短文本之间的文本相似度。
该方法的主要思想就是:通过衡量向量间夹角的大小的余弦值,来判断两个文本间的相似度。余弦值越大,相似度越高。其中两边之间的夹角的余弦计算公式为

当a 的向量坐标是(x1,y2),b 的向量坐标是(x1,y2),两向量的夹角为θ,如果夹角为锐角时,向量a 和向量b 之间的关系如图1所示。

图1 向量a 和b
向量a 和向量b 的夹角的余弦计算如下:

当对式(2)进行扩展,即向量a 是(t1,t2,t3,…,tn),b 是(t1,t2,t3,…,tn) 的形式,式(2)依然可行。扩展后的公式可以写为
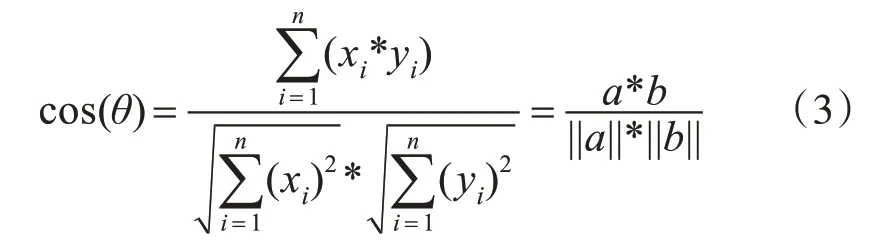
式(3)中cos(θ)值的范围是-1~1,为了便于比较,方法中将cos(θ)转换为0~1:

余弦相似度主要由向量方向决定,向量数值对其影响很小。由于这一特点,所以在使用中会存在一些问题,需要进行修正。
观众对电影《碟中谍》进行评价,打分是10 分值,小明和小王对电影的评分分别为(2,4)和(8,10),直接使用式(3)和式(4)得到的结果是0.989,两者对这部电影的喜好程度似乎相同。但实际情况是小明不喜欢《碟中谍》这个电影,小王很喜欢这个电影。余弦相似度对数值的不敏感的特性对结果产生很大的误差,因此有时不能够直接使用式(3)、式(4)对向量数值进行计算,必须对向量数值进行预处理后再进行计算,以实现对余弦相似度的修正。预处理方法是所有的向量数值都减去一个它们的平均值,比如小明和小王的评分均值是6,那么经预处理后为向量变为(-4,-2)和(2,4),使用式(3)和式(4)后得到Sim1为0.1,显然在对向量数值进行预处理后,再计算得到余弦值更符合实际情况。
计算过程中,将词条名片的短文本当作是一组词的集合。
Step1:对词条A和B的百科名片短文本进行分词等预处理,创建分词向量Ta(t1,t2,…,tm),Tb(t1,t2,…,tn)。
Step2:统计每个词在文本中出现的次数。写出词频向量,并通过TF-IDF求权值。
Step3:使用式(3)和式(4)计算得到基于向量空间的百科名片相似度。
3.2 百度词条正文相似度计算
经研究发现,余弦相似度算法在短文本中效果良好,但在长文本中存在一些不足,而SimHash 算法在长文本中有着出色的表现。基于词条正文的文本内容多,篇幅大,因此实验中在对词条正文部分的计算中使用了SimHash算法。
SimHash 算法有五步:分词、Hash、加权、合并、降维。具体过程如下所述。
Step1:对词条正文进行预处理,建立分词向量,并且需要为特征向量设置权重(权重可以是这个词在正文中出现的频数)。例如给定一段语句:“慷慨就义重如泰山,或长流于世自甘堕落”,分词后为:“慷慨就义,重如,泰山,或,长流,于世,自甘堕落”,然后为每个特征向量赋予权值:慷慨就义(5)、重如(3)、泰山(4)、或(1)、长流(2)、于世(2)、自甘堕落(5)。
Step2:Hash 计算,可以得到每个特征向量的Hash 值。假设Hash 值为二进制数0-1 组成的字符串。比如“慷慨就义”的Hash值为001001,“自甘堕落”的Hash值为“100100”。
Step3:得到特征向量的哈希值后,对特征向量设置权重,即W=Hash*Weight。遇到1,则1 直接和权值做乘法,遇到0,那么Hash 值和权值负相乘。例如给“慷慨就义”的Hash 值“001001”加权得到:W(慷慨就义)= 001001 5=-5-5 5-5-5 5,给“自甘堕落”的Hash 值“100100”加权得到:W(自甘堕落)=100100 3=3-3-3 3-3-3。
Step4:将Step3 得到的W 全部加起来,得到一个0-1 字符串。拿Step3 中两个特征向量举例,W(慷慨就义)+W(自甘堕落)=-2,-8,2,-2,-8,2。
Step5:对于Step4 得到的0-1 字符串进行降维处理,是正数则将值置1,否则为0,经过上述五步的处理,就获得了正文部分的SimHash值。
在得到文本的SimHash 签名值后,就可以计算它们的海明距离d。海明距离的求法:当对Sim-Hash 签名值进行XOR 计算时,仅当相同位置值不同时值置为1,否则值置为0。XOR 计算之后得到的1 的数量即是汉明距离的大小。词条正文部分的相似度如以下公式:

其中d为海明距离,maxL为最长关键词数组长度。
3.3 百度词条开放分类相似度计算
开放分类是一个词条的重要组成部分。是词条的一种不同于传统目录式的新的分类方式。具有相同开放分类的词条具有很强的相关性。
因此,开放分类对两个词汇之间的相似度的计算具有很大价值。如果词条B 是词条A 的开放分类,则Exist(A,B)=1,否则Exist(A,B)=0 。统计在词条A 与B 开放分类中相同的个数,用Common(A,B)表示。Percent(A,B)为Common(A,B)占词条A和B总的开放分类个数的比例。
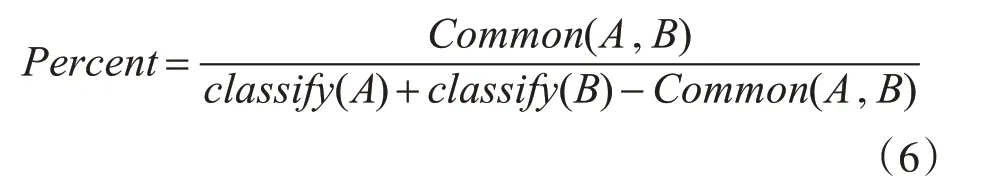
其中classify(A)是词条A 中的开放分类个数。词条开放分类相似度计算公式为
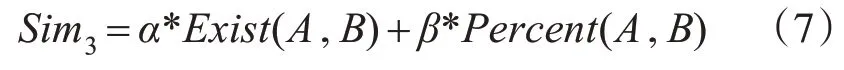
其中,α+β=1。
3.4 相关词条相似度计算
近年来,SimRank 在信息检索领域引起了广泛关注,并在网页排名,协同过滤,孤立点检测和近似查询处理等领域取得了巨大成功。
SimRank 模型根据递归的概念定义两个对象之间的相似性:如果节点a 的相邻节点和节点b 的相邻节点相似,则a 和b 也是相似的。这个递归定义的初始条件是:每个结点与它自身最相似。如果τ(a)用于表示节点a 的所有相邻节点,用Sim4(a,b)表示两个节点a 和b 之间的相似性,则相关词条相似度可表示如下:

其 中,当a=b 时,Sim4(a,b)=1;当τ(a)=φ 或τ(b)=φ 时,Sim4(a,b)=0。
文献[8]对式(8)进行了扩展,扩展后的Sim-Rank算法为
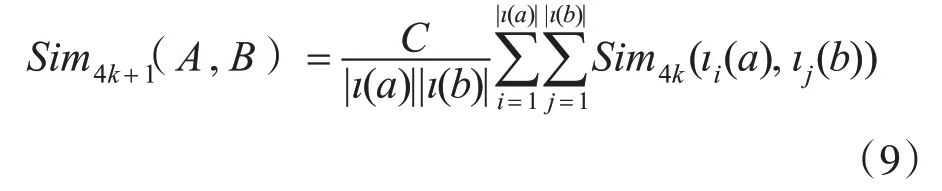
其中k 不等于0,当k 趋于无穷大,能够准确得到图中两个节点之间的相似度。
对相关词条的相似度计算步骤有以下三步。
Step1:在本研究中,百度百科被看作一个图,图中节点表示词条,用M=<VN,EN>来描述该图,N 是节点的个数,PN={p}是所有节点的集合,EN={e}是所有边的集合,e={v→w}表示节点v是w 相邻节点。
Step2:如果A是B的相关词条,则在图中,存在这样的两条边e={A→B}。例如,“特朗普”的相关词条有“曼哈顿”、“房地产”等,所以在图中,存在节点“特朗普”、“曼哈顿”、“房地产”,并存在边e={“特朗普”→“曼哈顿”}、e={“特朗普”→“房地产”}等。
Step3:使用式(9)计算相关词条相似度。
曹海等给出了迭代过程中SimRank 算法的精确度分析,提出了牺牲较小精度来获得较大性能提升的方法,并定义了如下公式:

其中,Sim4(a,b) 为节点a 和b 的相似度表示,Sim4k(a,b)为节点a 和b 在第k 次迭代时的Sim-Rank,值,C 为衰减因子常量,Ck+1是在第k 次迭代时SimRank 算法的最大误差。所以如果设C=0.8,最大误差为0.001,经过29 次计算就可以获得相对确切的结果。
3.5 词条相似度计算公式
由上文得到的Sim1、Sim2、Sim3、Sim4,将它们加权相加得到词汇之间的综合相似度,得到词条的整体相似度:

其中,k 是可调节的参数,且有k1+k2+k3+k4=1,k1≥k2≥k3≥k4,后者表明Sim1到Sim4对于总体相似度的重要程度逐渐变小。这是考虑到百科名片和百科词条正文反映了一个词条最核心的内容,因此他们的权值应大一些。经过多次实验比较,选取的参数为α=0.5,β=0.5,k1=0.35,k2=0.35,k3=0.15,k4=0.15 结果最佳。
3.6 评价指标
将本文计算出的综合相似度Similary(A,B)与Words-240 给出的参考标准值作比较,计算它们的之间的差值Value,Value的绝对值越接近于0,则本文方法计算得出的相似度越准确。
4 实验及结果分析
本文做了两个实验,实验一使用刘群等提出的基于《知网》的相似度计算方法SSCH计算一对词汇之间的相似度,实验二使用本文方法来计算相同词汇对之间的相似度。分别计算他们和Words-240测试集给定的标准值之间的差值,取绝对值比较。实验结果如表1所示。

表1 词汇相似度计
从实验结果可以看到:
1)在表1 中,一共选取了13 对词汇,其中有10对词汇使用本文方法计算出的相似度更接近于标准值,其Value 的绝对值相比较SSCH 方法的Value的绝对值更小。这说明本文方法在词汇相似度计算中更加准确,本文中方法在多数情况下优于基于《知网》的相似度计算方法SSCH,且在使用中切实有效。
2)在图2 相似度结果的折线图中,可以看出使用本文方法计算出的相似度折线走势更贴合于标准值,且比较稳定。
3)SSCH 方法在医生-责任,员工-公司,学校-教学这三个词汇对的相似度的计算上表现的非常差,这说明该方法在通用性上不如本文提出的方法。

图2 相似度结果比较
5 结语
本文提出一种基于百度百科的多特征信息词汇相似度计算方法。该方法经由百科名片、词条正文,开放分类和相关词条四个部分的内容,分别计算出它们之间的相似性值,以此来获得一对词汇间的整体相似性。
从实验结果来看,这种新方法比现有方法更加可靠有效。但本文的方法也存在一些不足,一是对词汇的同名异义缺乏研究,没有进行分歧处理。二是有些词条并不完整,缺少计算所需的相关内容。因此仍需在后续的研究中对该方法进行相对应的改进。
猜你喜欢
电脑知识与技术·经验技巧(2020年3期)2020-05-07
创新作文(5-6年级)(2019年3期)2019-09-03
计算机辅助工程(2018年2期)2018-06-03
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
智能制造(2015年7期)2015-11-20
小溪流(故事作文)(2014年6期)2014-07-31
智慧与创想(2013年10期)2013-11-28
