
图像分区域多特征融合斜向车辆检测算法研究
2020-08-26 06:45李守义张洪昌
公路交通科技 2020年8期
曾 娟,李守义,张洪昌
(1.现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070; 2.交通物联网技术湖北省重点实验室,湖北 武汉 430070)
0 引言
人车混流和交通拥堵是中国道路交通路况的典型特征。在人车混流的环境下,驾驶员忽视外周视野区域障碍物是导致事故发生的重要原因。如果驾驶员能提前1~2 s 时间得到环境危险预警提示,则能避免90%的事故发生。目前基于机器视觉的车辆检测技术作为道路环境感知的核心技术[1-2],较为成熟的方法为多特征融合+分类器,包括Haar-like特征、HOG(Histogram of Oriented Gradient)特征、LBP(Local Binary Patterns)特征。分类器算法常用的有Adaboost算法、SVM(Support Vector Machine)算法、贝叶斯算法等。基于Haar-like特征与Adaboost级联分类器[3-6]组合对前向车辆具有较好的检测效果,因为前向车辆具有对称性、水平特征及垂直特征。HOG特征与SVM算法组合主要应用于行人检测[7],很少在车辆检测中使用[8-10]。刘东军等[11]提出使用主成分分析(PCA)对Haar-like特征降维,提高检测的实时性,但未在斜向车辆检测中使用。
相对前向车辆而言,在换道、十字路口、对向来车等路况下斜向车辆的检验更具普遍意义,但是针对斜向车辆的检测算法研究很少。Bin-Feng Lin等[12]通过在后视镜处安装摄像头,通过多特征融合算法检测相邻车道车辆。朱彬等[13]通过分区域检测,对斜向车辆采用多块局部二值模式(MB-LBP)特征,相对于使用Haar-like特征具有更高的准确率。晏晓娟[14]通过建立不同角度车辆前脸的训练样本库,训练Haar-like+Adaboost分类器实现侧后方车辆的检测,但没有考虑实时性的问题。
基于上述,针对斜向车辆识别问题,本研究提出阴影+边缘特征融合算法;针对车辆检测的实时性和准确率问题,提出 HG&HV算法进行二次检测,即核主成分分析+Haar-like特征+HOG特征+Adaboost级联分类器算法。在Haar-like特征提取过程中采用核主成分分析降维提高实时性,Haar-like特征+HOG特征融合提高算法准确率。
1 分区域多特征融合的斜向车辆检测算法
斜向车辆检测算法具体流程如图1所示。

图1 斜向车辆检测算法流程Fig.1 Flowchart of oblique vehicle detection algorithm
1.1斜向检测区划1.1.1斜向车辆检测区域定义
为了更清楚定义检测目标,本研究列出检测范围3种工况:工况1为相邻车道车辆变道,如图2(a)所示;工况2为对向车道车辆靠近过程,如图2(b)所示;工况3为十字路口车辆 转弯或直行过程,如图2(c)所示。车辆B均定义为斜向车辆。

图2 斜向车辆定义的3种工况Fig.2 Three conditions defined for oblique vehicles
1.1.2K-means聚类与Hough直线融合的车道线区划
本研究采用K-means聚类与Hough直线融合的方式,提高车道线检测准确率。
原始图像根据最大类间方差法(OTSU)阈值分割转化为二值图像,逐行提取二值化图像的像素点。根据式(1)、式(2)判断像素点属性,利用公式(3)筛选特征点,通过K-means聚类将特征点分为两类。利用Hough直线变换,对聚类后的像素点进行直线拟合。像素点起点、终点判断式:
R(i,j)-R(i,j-1)=255∩R(i,j)-
R(i,j+1)=0,
(1)
R(i,j)-R(i,j-1)=0∩R(i,j)-
R(i,j+1)=255,
(2)
式中,R(i,j)为二值化后图像灰度值,istart,iend分别为起点横坐标及终点横坐标。像素数与摄像头有关,本研究采用车道线宽度在5~30个像素左右[15],距离差公式:
5≤iend-istart≤30。
(3)
根据像素点的分布特点及筛选条件,确定车辆的特征点及聚类效果如图3所示。
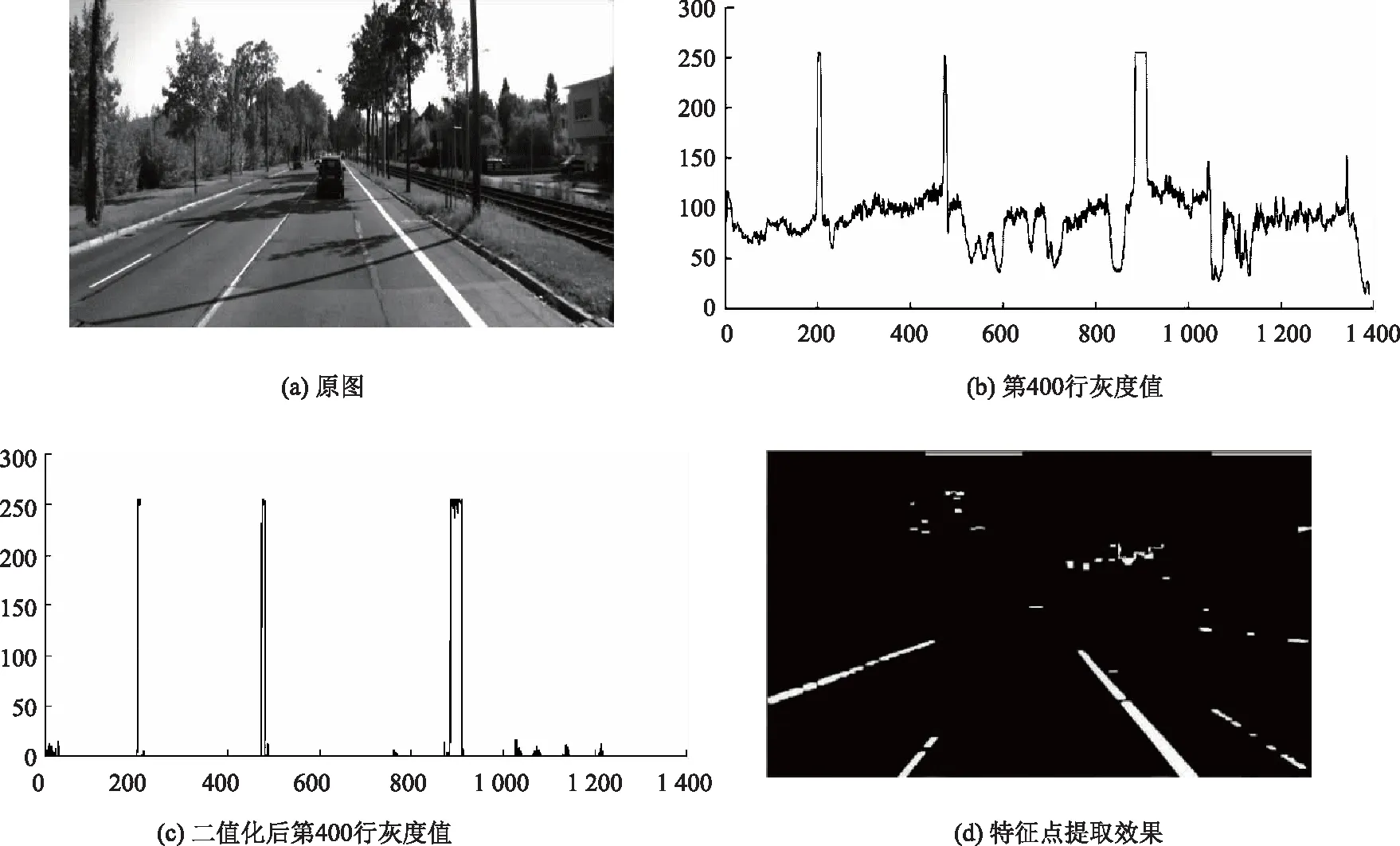
图3 特征点提取Fig.3 Feature point extraction
提取特征点后,通过K-means聚类聚成两类后,根据Hough变换实现车道线检测,见图3(a)。依据检测结果,定义在自车两侧车道线以外的区域为目标检测区域,效果见图4(b)。

图4 图像区域划分Fig.4 Image area division
1.2基于阴影特征与边缘特征融合的斜向车辆初次检测1.2.1自适应双阈值与OTSU阈值融合的斜向车辆阴影提取
OTSU与自适应双阈值分割算法应用于车辆检测会存在分割效果不佳的问题。例如OTSU算法在图像是单峰、多峰情况下无法准确分割[11];自适应双阈值法在不良天气条件下效果不佳[16]。
鉴于此,结合自适应阈值与OTSU的算法优点,提出一种融合阈值分割算法。首先利用自适应阈值Threshold1排除车辆检测区域的高亮区域及噪声,然后将满足条件的像素点进行OTSU阈值分割,从而实现车辆阴影的提取。
依据式(4)、式(5)计算图像的均值和方差;
(4)
(5)
依据式(6)和计算得到的均值与方差,计算阈值Thresholdfirst,统计低于阈值Threshold1的像素点;
(6)
将高于阈值的像素点排除后,采用OTSU阈值分割得到二次阈值分割的阈值Threshold2。灰度值小于阈值的为阴影部分,大于阈值为背景部分。根据式(7)得到二值化图像。
(7)
改进阈值算法与自适应双阈值分割算法、OTSU算法作比较,3种方法得到的阈值分割效果如图5所示。

图5 阈值分割算法对比Fig.5 Comparison of threshold segmentation algorithms
1.2.2斜向车辆边界的愈合处理
斜向车辆与正向车辆相比,垂直特征存在较大差异。通过提取垂直边缘[17]作垂直边缘直方图,并建立愈合处理规则,从而确定斜向车辆的左右边界。
通过垂直Sobel卷积算子,得图像区域的垂直边缘图,如图6(a)所示。根据垂直边缘图计算对应列垂直边缘像素点的个数。以图像宽度为横坐标、以垂直边缘像素点的个数为纵坐标作垂直边缘直方图,如图6(b)所示。定义自适应阈值Thresholdj:
(8)
式中,F为斜向检测区域;WidthF为斜向检测区域的宽度;f(i,j)为斜向检测区域垂直边缘图的灰度值;δ[]为克罗内克函数,当[]内值相等时,δ[]函数值为1,反之为0。
直线j=Thresholdj与垂直边缘直方图相交,达到固定阈值Thresholdj的峰值坐标点作为车辆左右边界的候选点,两个对应的左右边界点之间的距离为疑似车辆区域的宽度。
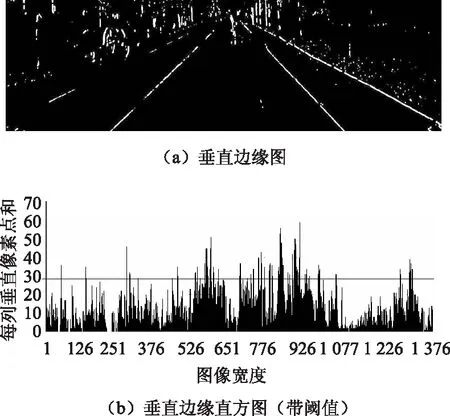
图6 斜向车辆左右边界提取Fig.6 Extracting left and right borders of oblique vehicle
通过阈值Thresholdj的边界候选点筛选匹配规则如下:
规则1:若直线j=Thresholdj与直方图的两个相交点之间所对应的列距离超过0.6limage,则两个相交点为左右边界点;
规则2:若列距离小于0.3limage,则将两个相交点合并为一个交点,合并原则为新的边界点为纵坐标不变,横坐标为两个相交点横坐标的均值,即Bnew(i,j)=(iB1+iB2,j)。
规则3:若边界候选点Bk的相邻列距离处于0.3limage与0.6limage之间,则认为边界点属于不同的车辆。
1.3 基于核主成分分析的级联分类器检测
基于HOG特征与Haar-like特征的级联分类器采取串联的方式,从而达到更优的效果。核主成分分析降维提高实时性。
1.3.1斜向车辆的HOG特征

(9)
(10)
将得到的梯度方向角θ在[0, 2π]内分为9个bin区间,每个bin区间包含梯度方向角40°。梯度方向角对应bin区间的梯度幅值函数为
(11)
式中,k=1, 2,…,9,Bk(i,j),为对应bink区间的梯度幅值。每个像素点(i,j)都能通过上述式(11)得到一个k维向量,梯度方向直方图如图7所示。

图7 梯度方向直方图Fig.7 Gradient direction histogram
1.3.2斜向车辆的Haar-like特征
特征值计算速度与特征维度大小选取相互制约。选用Haar-like特征对车辆正脸进行特征提取,如图8所示。由于Haar-like特征为矩形特征,其特征维度随区域增大而增长,可使用积分图(Viola等[19])快速计算特征值,但特征维度太大将导致计算实时性难以保证。

图8 Haar-like特征提取示例Fig.8 Example of extracting Haar-like features
1.3.3核主成分分析对Haar-like特征的降维处理
采用核主成分分析降维的方式可将高维数据流降维到低维空间,从而提高计算速度。思路如下。
提取m个图像特征,每个样本特征维度为n,将其构成特征矩阵A:
(12)
高斯径向基核函数(RBF)表达式为
(13)
计算核矩阵K的特征值λ1,λ2,…,λn及特征向量v1,v2,…,vn,并对特征值大小排序处理,而且调整相应的特征向量位置。
根据主元成分的累积贡献率Bk,当累计贡献率Bk达到最低限度值E=99.5%,提取前k个主成分向量v′1,v′2,…,v′k。累积贡献率:
(14)
计算特征集A在低维空间的投影Y,利用主成分向量v′与核矩阵K即可得到Y=v′K,投影Y即为图像特征集A的KPCA降维结果。
具体降维结果如表1所列。根据表1的结果,降维处理后,当车辆Haar-like特征维度达到86时,累积方差贡献率达99.543%,能够满足车辆检测的需要,所以选择提取车辆图片特征的前86维度特征进行车辆检测。
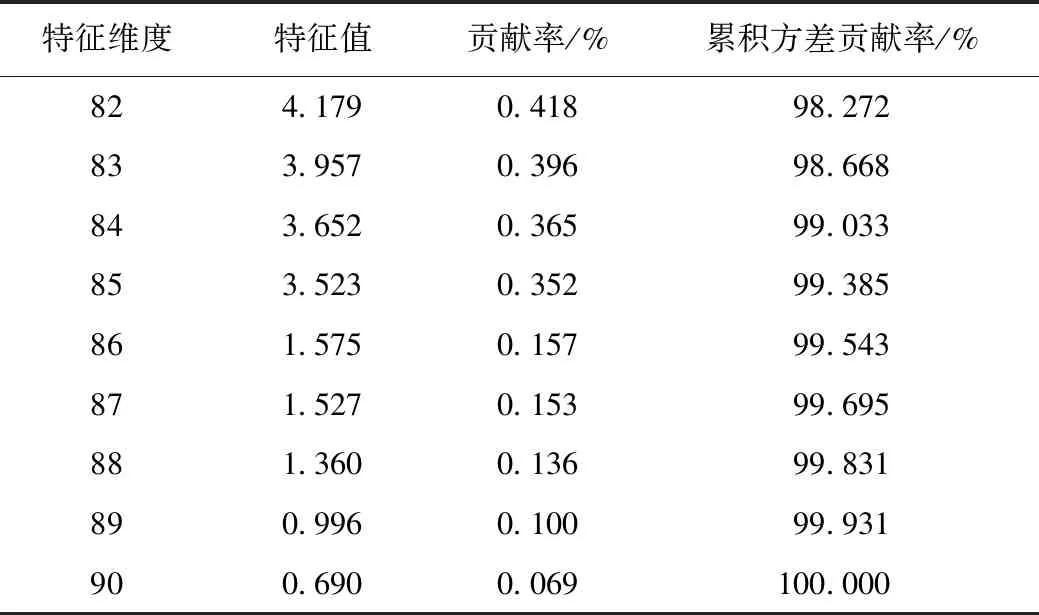
表1 车辆Haar-like特征降维Tab.1 Dimension reduction for vehicle Haar-like features
1.3.4Adaboost级联分类器
自适应增强学习算法(Adaboost)对训练样本进行训练产生若干个弱分类器(迭代n次就会产生n个分类器),且每次训练时训练样本根据上一个弱分类器结果会对训练样本集进行权值调整,增大错分样本权重,降低正确分类样本权重,提高下一次迭代的弱分类器的准确率。当错误率下降到一定要求或满足迭代次数时分类器训练结束。检测流程如图9所示。

图9 多分类器检测Fig.9 Multi-classifier detection
通过多次强分类器的训练,将其以串行方式级联成二级强分类器,作为最终分类判断的依据,提高分类器的分类精度。
2 虚拟试验结果及分析
2.1 虚拟试验设计及试验环境
试验使用两个数据集作为测试数据集:百度语义分割比赛所用视频剪辑图片,共298张; KITTI数据库的图片数据,共300张。针对检测算法改进的几个环节,设计试验如下:
虚拟试验1:阴影特征与边缘特征融合的初次检测与分类器二次检测对比试验;
虚拟试验2:增加HOG特征前后Adaboost分类器效果对比;
虚拟试验3:采用KPCA降维+多特征融合(HOG特征+Haar-like特征)+Adaboost级联分类器与HOG+支持向量机(SVM)算法对比试验;
虚拟试验4:选择3种天气条件(晴天,阴天及雨天)对比试验。
虚拟试验环境为Visual Studio2015+OpenCV3.1,使用C++语言进行编程,硬件环境为戴尔灵越N4110电脑,6G内存,i3处理器,Windows7系统。
2.2 虚拟试验评价标准
试验评价标准分别为准确率、实时性、误检率。3个定量参数定义:
(15)
(16)
(17)
式中,N为图片数量;ti为第i张图片处理所需要的时间;num为矩形框总数;numL为漏检数;numw为误检数;numr为正确数。
2.3 结果及分析
(1)虚拟试验1结果及分析
虚拟试验1为本研究算法中初次检测与二次检测的效果对比。结果如图10所示。图10(a)为阈值融合分割算法检测结果,图10(b)为分类器二次检测,矩形框表示检测结果。

图10 虚拟试验一结果对比Fig.10 Comparison of results of virtual experiment 1
从图10看出,初次检测能识别斜向车辆准确率达90.1%;表2结果显示,基于阴影特征和边缘特征的斜向车辆的识别准确率能达到94.6%。二次检测的检测准确率提升4.5%。

表2 车辆检测结果对比(虚拟试验1)Tab.2 Comparison of vehicle test results (virtual experiment 1)
(2)虚拟试验2结果及分析
虚拟试验2是3种算法效果对比。算法1,采用KPCA降维+多特征融合+Adaboost机器学习算法;算法2,多特征融合+Adaboost机器学习算法;算法3,经典的支持向量机SVM+HOG特征算法。试验结果如图11所示。矩形框为算法检测结果。

图11 虚拟试验2结果对比Fig.11 Comparison of results of virtual experiment 2
从图11看出,算法1在车辆检测中框选车辆准确;算法3存在多个车辆检测为同一辆车的情形。表3结果显示:算法2与算法3相比,误检率降低5.2%,准确性提高2.5%,说明多特征融合+Adaboost能明显提高检测准确率,但是实时性指标(检测时间)没有改善;算法1和算法2相比,准确性和误检率相差不大,检测时间减少15 ms,说明采用核主成分分析降维后,实时性指标改善明显;算法1与算法3相比,误检率降低5.1%,准确性提高1.1%,但是检测时间减少16 ms,综合检测效果最佳。
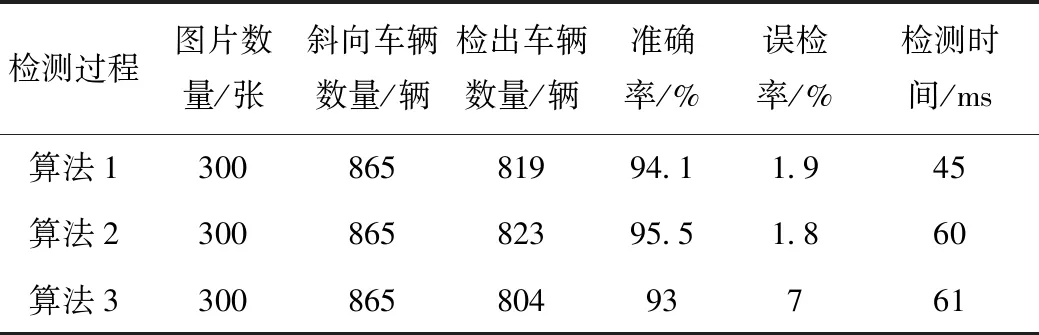
表3 三种算法的车辆检测结果对比(虚拟试验2)Tab.3 Comparison of vehicle detection results of 3 algorithms (virtual experiment 2)
(3)虚拟试验3结果及分析
虚拟试验3是增加HOG特征前后分类器效果对比。
采集Adaboost训练过程中的准确率与虚警率(被错分的几率)数据,绘制出ROC曲线。分类器2:HOG+Haar-like+Adaboost分类器;分类器1:Haar-like+Adaboost分类器。从图12可以看出,分类器2曲线位于分类器1上方,即分类器2训练效果准确率优于分类器1,虚警率低于分类器2。
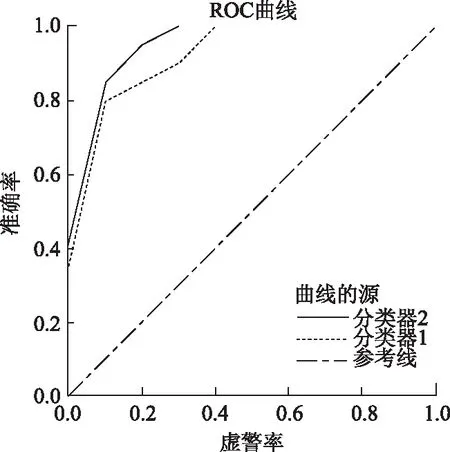
图12 ROC曲线Fig.12 ROC curves

图13 三种天气条件下车辆检测效果Fig.13 Vehicle detection effects under 3 weather conditions
(4)虚拟试验4结果及分析
从图13看出,阴天、雨天和晴天均可以检测出斜向车辆;从表4结果分析,车辆检测准确率均高于90%。
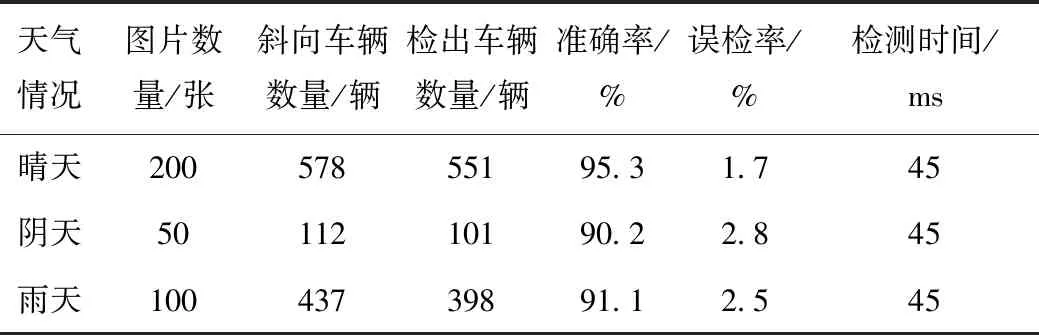
表4 三种天气条件下车辆检测结果对比Tab.4 Comparison of vehicle test results under 3 weather conditions
3 结论
针对斜向车辆识别,提出融合双自适应阈值与OTSU阈值分割算法、以及斜向车辆边界的愈合处理规则。试验结果显示可有效识别斜向车辆,准确率达90%。针对检测准确率和实时性问题,提出核主成分分析+双特征融合+Adaboost级联分类器算法。4组试验结果显示,双特征融合+Adaboost级联分类器对提高检测的准确率有明显改善;核主成分分析降维对检测的实时性效果明显;二者融合的综合效果改善明显。由于试验采取的是静态图片进行测试,在实车环境下,摄像头的安装、车体运动、空气中水分、光线均可对检测结果产生影响。所以该组图片的检测结果有局限性。实车测试是下一阶段的主要工作。实车环境下算法的有效性和稳定性、精确性是后续算法改进的关键所在。
猜你喜欢
车主之友(2022年4期)2022-08-27
军事文摘·科学少年(2020年3期)2020-03-26
海峡姐妹(2019年12期)2020-01-14
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
故事作文·低年级(2016年11期)2016-11-29
小学教学研究·新小读者(2016年7期)2016-07-15
火控雷达技术(2016年1期)2016-02-06
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
