
基于分层词袋模型的室外环境增量式场景发现
2020-08-14 08:33陈昊天孙凤池黄亚楼
控制理论与应用 2020年7期
陈昊天 ,张 彪 ,孙凤池 ,黄亚楼 ,苑 晶
(1.南开大学计算机学院,天津 300350;2.南开大学软件学院,天津 300350;3.南开大学人工智能学院,天津 300350)
1 引言
能够对所处环境进行感知、建模,是移动机器人自主导航和完成各种操作任务的重要前提[1–2],随着移动机器人应用领域的持续扩展,场景认知与理解问题备受关注[3–4].对机器人来说,一个场景是其在一定时间、空间范围内感知到的外部环境整体.而对于最常见的视觉传感器而言,机器人获取的场景信息取决于当前的环境成分外观以及光照等外部条件,当这些因素发生变化时,意味着场景已经改变.为使机器人能够主动适应不同场景的变化,并做出适当的反应,需要机器人能够自主识别当前所处场景类型,即场景识别.而对于行驶中的移动机器人来说,从来自视觉传感器的实时图像序列中自动发现新类型的场景,即场景发现,是实现自主场景识别的先决条件.本文中场景发现的作用类似于机器视觉领域里的场景分割,都是对连续视频按照场景属性进行分段.但是机器人运行时获取的场景数据是持续增长的,考虑机器人在线运动的特点,实时性也是一个重要指标.
在机器人领域,当前和场景理解相关的研究大多集中于场景识别问题.文[5]针对室内环境家庭机器人提出视频识别技术,结合了视觉注意模型中的特征图和空间信息形成图像特征并进行分类,在保留空间信息的情况下避免了过于复杂的细节.文[6]通过自主发育神经网络模拟人的思维方式来实现移动机器人对室内场景的识别.文[7]利用卷积神经网络来减少图像的维度并提取特征,然后通过训练多层感知网络来完成场景识别.但上述场景识别流程均是有监督的,通过人工标注的方式获得训练数据,这不仅增加了耗时,而且使机器人不具备对超出标注数据考虑的场景变化的适应能力[8],对移动机器人来说,如能自动地将视频(外部环境的连续图像)划分为多个场景,进而对旧场景类别进行无监督的识别并实现对新场景的自主发现至关重要.
在机器视觉领域,场景理解也是一个重要的研究热点,研究人员通过将视频自动分割成不同镜头并提取关键帧完成场景理解.文[9]利用视觉相似度和聚类来完成视频分割,然后使用序列对比算法进行场景识别.文[10]使用Nystr¨om近似下的多相似谱聚类方法实现快速的影片场景划分,并增加时间约束,以确保场景划分在时域上的完整性.上述方法对于固定长度的视频能够自主划分并发现新的场景类别,但移动机器人采集到的数据随时间不断增加,并不适合直接采用上述方法.
词袋模型(bag of words,BoW)[11]利用基于内容的特征来度量图像之间的相似度,相对于使用低层特征的方法,词袋模型更容易形成类人的场景类别.文[12]将改进的词袋模型和改进的双线性深度信念网络(bilinear deep belief network,BDBN)模型进行融合,形成最终的场景判别结果,该文仍采用了有监督方式进行学习.
本文所研究的场景发现是指,移动机器人在自主划分外部环境图像流的同时,实现对旧场景类别的识别和新场景类别的发现,这里旧场景是指在此之前发现的场景类别而非人工标注类别.通过分析室外场景的特性,做出如下合理假定:机器人持续运动时,在某一段时间内,所经历的场景属于同种类型,例如从小树林到草地,两段时间内经历两种场景.在此基础上,本文提出基于分层词袋模型的室外环境增量式场景发现算法,使机器人能够在无监督条件下区分不同场景,对于某一特定场景,如果它是以前经历过的场景,则直接归入已有类别;如果它是未知类型的新场景,则赋予其新的场景标签;同时,根据场景识别结果划分图像流.
本文在不需要先验知识(人工标注数据)的无监督框架下,一方面,通过分层词袋模型建立图像和场景的联系,使得场景发现过程更加类似人类认知模式;另一方面,通过增量式聚类方法—–流化亲和力传播算法(streaming affinity propagation,StrAP)[13–15]动态构造分层词袋模型,使得场景类别设定摆脱先验知识的约束,从零先验知识起步,逐渐发现新场景.本文在前期工作[16]基础上,进一步完善了场景发现算法,并且增加了在公开数据集和整段视频上的实验.实验结果表明,本文算法发现的场景类别和场景划分结果能够符合人的判断,并且具有一定的实时性.
2 分层词袋模型
设I为图像空间,I1,I2,···,It,···∈I,t ∈N为摄像头获取的图像序列,采集到的图像随时间的增长而不断增加,场景发现就是要构造映射Ft和场景集合序列St:
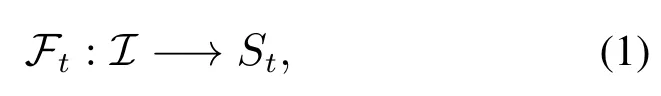
其中St{s1,s2,···,sNt}为t时刻的场景集合,si为特定的场景种类或标签,Nt为场景数量.由于没有先验知识,场景的数量也从0开始不断增加,其具体类别应由模型自动生成. t 时刻的Ft和St取决于当前图像It与之前的Ft−1和St−1.该图像所对应的场景为Ft(It),它可以是旧场景,也可以是新发现的新场景.
本文结合词袋模型和动态无监督学习算法,提出一种基于分层词袋模型的增量式场景发现方法,它能够在没有场景先验知识的情况下,通过视觉特征对场景进行建模,增量式地构造Ft和St,使机器人能够完全自主地对环境进行切分.单层词袋模型中的词典由聚类算法生成和更新,其聚类中心称作关键块,它是全部图像块中最具代表性的分块.本文算法的分层词袋模型除了生成和更新低层关键块外,还包括高层的关键帧,它们是最具代表性的图像,用以表示场景类别.模型的两层分别由两个StrAP算法实现.随着机器人的运动,所获得的关键块和关键帧连续集成到模型更新过程,这种算法机制实现了通过持续观测场景来更新、完善模型,从而识别旧场景、发现新场景并进行场景划分.分层词袋模型如图1所示.
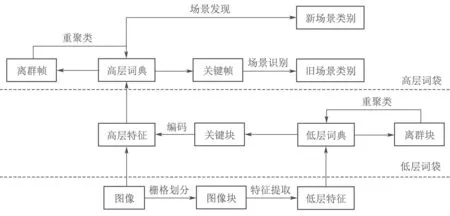
图1 分层词袋模型Fig.1 Hierarchical BoW model
首先按照如下步骤对摄像头获取的图像进行特征提取:
1)将图像以等大栅格进行划分.
2)对每个图像块,计算它们的低层特征.
在得到了每一个图像块的特征之后,在低层词袋模型中,根据它们之间的相似度和StrAP算法生成和更新低层词典中的关键块:
3)利用已有的关键块和最近邻分类器对图像块进行分类.
4)如果图像块与已有关键块的距离小于一定阈值,则将其并入该类;否则将其分类为离群块.
5)当离群块数目大于一定阈值时,对所有关键块和离群块进行重聚类,得到新的低层词典和相应的新关键块.
接下来,利用高层词袋模型对图像所属的场景类别进行判断和划分,同时生成和更新高层词典中的关键帧:
6)按照低层词典对图像块进行编码.
7)对图像整体提取高层词袋模型的特征.
8)使用StrAP算法将当前图像添加到高层词典中,此时,要么将新图像识别为已知场景,要么将其作为离群帧,当离群帧数量大于一定阈值时,对关键帧和离群帧重新进行聚类,得到新的高层词典,形成相应新关键帧,发现新场景.
分层词袋模型通过增量式地生成和更新低层和高层词典,实现了连续识别旧场景,同时发现新场景,并根据场景类别完成图像流的自主划分.整个过程都是无监督的,不需要任何先验知识的参与.
下面对上述3个阶段的内容进行详细阐述.
2.1 低层特征的选择
为了丰富对图像属性的刻画能力,保证分类正确率,本文综合利用颜色、纹理两种特征,使用色相–饱和度–亮度(hue-saturation-value,HSV)颜色直方图[17]计算图像块的颜色特征,结合局部二进制模式(local binary patterns,LBP)纹理直方图[18]作为完整的低层特征.
由于直接进行统计的直方图矢量维数非常多,导致图像的颜色信息分散,并且特征矢量包含许多零值,从而降低特征的分辨能力,因此先参照人类颜色感知规律对HSV的3个分量做等间隔量化,然后再进行统计.具体做法是按照人眼的分辨能力,将色调空间H分为8个部分,将饱和度空间S和亮度空间V 各分成3部分[17],如式(2)所示:

上述统计直方图的特征维数是72维.最后对于每个图像块,将其和最常见的LBP纹理直方图拼接起来,形成一个完整的81维低层特征向量.
定义两个图像块特征向量之间的相似度为它们的颜色和纹理直方图之间的巴氏距离[19]:

其中H1和H2是两个图像块的特征向量.
2.2 低层词袋模型
考虑到实验数据中图像尺寸是320×240,选择40×40的图像块进行划分:

其中:a为图像块边长,Bt为分割后的图像块集合.对每个图像块提取前述低层特征得到bit∈Bt,i1,2,···,48,然后将每幅图像上所有分块的特征向量顺序加入低层词袋模型,利用StrAP算法增量式地生成和更新低层词典:
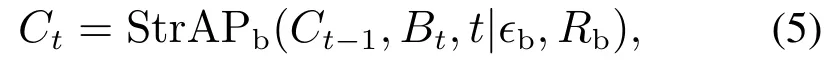
其中: Ct{c1t,c2t,···,cMtt}为t时刻的低层词典,ϵb和Rb为参数.StrAP算法用四元组模型实现聚类,在t时刻,每个四元组中的代表点即为低层词典中的关键块cit,i1,2,···,Mt,新数据与代表点通过相似度进行关联,相似度定义为−d(H1,H2).
低层词袋模型的流程如图2所示,初始时,低层词袋模型中没有任何四元组,即低层词典中没有任何关键块,机器人对场景内可能出现的图像块没有任何先验知识.在一段时间内,新加入的图像块均不能与任何关键块相关联,因此将其放入离群块集合R中.当离群块集合中的图像块个数超过一定阈值Rb时,模型使用StrAP算法对离群块聚类,得到初始的四元组模型,即低层词典中产生了初始的关键块.由于场景在一段时间内不发生变化,虽然低层词袋模型的参数不断更新,但是关键块不会变化,低层词典也不会变化,即CtCt−1.
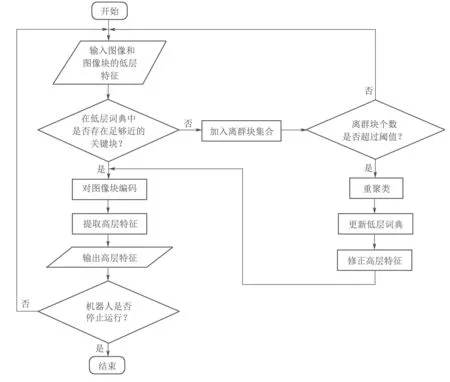
图2 低层词袋模型流程图Fig.2 Flowchart of the low-level BoW model
当场景发生变化或出现视觉噪声,新图像块不能与当前低层词典中的关键块进行关联,则将它加入到离群块集合中.考虑到这些图像块可能源于视觉噪声,所以只有当包含相似未知物体的图像块数量足够多时,才在低层词典中建立对应图像块类别的关键块,即当离群块数量大于一定阈值ϵb时,模型用StrAP算法将当前关键块和离群块进行重聚类,得到新的四元组模型,即形成新词典和新关键块.此时,原本不能与词典中关键块关联的图像块将与新词典中的某个关键块进行关联,从而使得新词典适应新场景的变化.上述过程实现了在零先验知识的情况下对低层词典的生成和更新.
生成和更新低层词典的过程也是对图像块编码和特征提取的过程.对每个图像块,使用最近邻分类器得到低层词典中最近的关键块,当它与该关键块的距离小于一定阈值ϵb时,用StrAP算法的融合公式将它融合到该四元组中,并把该图像块按照这个关键块的编号进行编码;否则,不对它进行编码.
根据图像块的编码提取整帧图像的高层词袋模型特征:

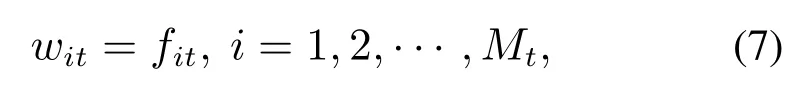
其中:fit为关键块cit在图像It中出现的频数,Mt是词典Ct的大小.
StrAP算法的实现方式保证了低层词典内关键块的有序性,这使得重聚类前后,图像块编码以及对整帧图像提取的高层词袋模型特征保持了一定的稳定性,但是仍需要对基于旧词典提取的特征进行修正,否则会造成特征向量维数不齐.词典在重新聚类后有两类变化:一是增加新的关键块类别,二是合并若干原有关键块类别.前者是因为机器人遇到了新关键块而产生的,由于新关键块在以前的图像块没有出现,因此将其频数置为0;后者是因为同一物体被过度细分造成,这使得以前图像内的不同关键块在后续图像中合并为一个关键块,此时将其频数合并.经过上述修正后,即使低层词典发生变化,低层词袋模型也能正确地提取整帧图像的特征.
2.3 高层词袋模型
虽然低层词袋模型能够适应场景变化,但具有一定滞后性,即当场景发生变化时,整帧图像将含有许多未编码的图像块.此外,视觉噪声也会在图像上产生未编码图像块.为降低未编码图像块对场景发现的影响,高层词袋模型仅处理已编码图像块数量超过一定阈值的图像,根据其特征向量生成和更新高层词典.该词典仍由StrAP算法实现,模型内每个四元组中的代表点即为高层词典中的关键帧.
高层词袋模型的流程如图3所示.与低层词袋模型类似,初始时,高层词袋模型中没有任何四元组,即高层词典St中没有任何关键帧,机器人对可能遇到的场景种类没有任何先验知识.在一段时间内,新加入的图像均不能与任何关键帧相关联,没有旧场景被识别,因此将其放入离群帧集合R′中.当离群帧集合中的图像个数超过一定阈值Rf时,模型使用StrAP算法对离群帧聚类,得到初始的四元组模型,即高层词典中产生了初始的关键帧,新的场景类型被发现.由于场景在一段时间内不发生变化,虽然高层词袋模型的参数不断更新,但是关键帧不会变化,高层词典也不会变化.
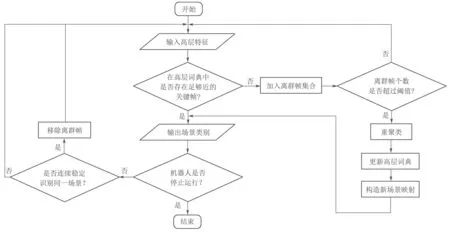
图3 高层词袋模型流程图Fig.3 Flowchart of the high-level BoW model
当场景发生变化,新图像不能与当前高层词典中的关键帧进行关联,则将它加入到离群帧集合中.当离群帧数量大于一定阈值ϵf时,模型用StrAP算法将当前关键帧和离群帧进行重聚类,得到新的四元组模型,即形成新词典和新关键帧,新的场景类型被发现.此时,原本不能与词典中关键帧关联的图像将与新词典中的某个关键帧进行关联,从而使得新词典适应新场景的变化.上述过程实现了在零先验知识的情况下对高层词典的生成和更新,完成新场景的发现.
生成和更新高层词典的同时,也完成了对旧场景的识别.对每幅图像,使用最近邻分类器得到高层词典中最近的关键帧,当它与该关键帧的距离小于一定阈值ϵf时,用StrAP算法的融合公式将它融合到该四元组中,并且把该图像识别为旧场景:

其中:St为t时刻的高层词典,也是场景集合;为图像It的场景标签,it∈N且1itNt,即找到了映射Ft使得
由于场景内物体的多样性以及采集过程中存在视觉噪声,图像有时会被错分为离群帧,而它们会在下一次重聚类时生成错误的关键帧,形成错误的场景类别,进而影响场景发现的准确度,因此要对离群帧进行特殊处理.基于场景在时间和空间上的连续性,即机器人持续运动时,在一段时间内所经历的场景属于同种类型,当模型能够连续稳定识别同一场景时,移除离群帧集合中的离群帧,使它们不会参与到下次重聚类中.
由于StrAP算法的特点和词袋模型的误差,一个场景可能对应模型中多个关键帧,此时基于场景的时空连续性,将同时生成的关键帧映射为同一个新场景类别,一旦关键帧发生变化,映射关系也随之改变.
3 实验结果及分析
本文使用MATLAB实现了上述场景发现算法,操作系统为Ubuntu 16.04 LTS,CPU 为i7−6700HQ,在3个室外视频上进行了实验,其中:实验1的数据来自公开数据集中的多段视频;实验2的数据由相机采集的多段视频拼接而成;实验3的数据是相机直接采集的一段完整视频,也是最贴近实际应用的数据.不同实验的阈值选择不同,同一实验中的阈值选择相同.
3.1 公开数据集实验
第1个实验的数据来源于手工标记的国防高级研究项目机构“学习应用于地面车辆”数据集[20],是科罗拉多大学从国防高级研究计划局(defense advanced research projects agency,DARPA)的野外运行日志中提取和整理出来的几组公开的视频片段.
选择特点鲜明的3组视频片段进行实验,图像的分辨率为320×240.3组片段的图像样本如图4所示,每个片段100帧,将3个视频片段重新剪辑拼接成300帧的视频,其中:1−75帧和276−300帧为片段1的图像,76−150帧和226−250帧为片段2的图像,151−225帧和251−275帧为片段3的图像.

图4 实验1数据集中3组片段的图像样本Fig.4 Samples from the three parts in the dataset of the 1st experiment
由本文模型自主发现的场景有4个,图5中每一行对应一个场景类别,第1列是每个场景在高层词典中对应的关键帧,而后4幅图像为与该关键帧相关联的图像样本.可以看出,不同场景之间存在显著差异,而在同一场景内,图像所包含的内容相似,即使它们的拍摄角度不同.

图5 实验1的场景发现结果样本Fig.5 Samples from the scene detection results in the 1st experiment
3.2 在拼接视频上进行的实验
第2个实验的数据是由PowerShot A630数码相机在假山公园采集的多个视频片段拼接而成,共19951帧,图像分辨率为320×240,采集频率为30 帧/s.
图6是本文模型中低层词典所生成的关键块,可以看出这些关键块之间差异明显,不同的物体或者相同物体的不同视觉特征都被划分不同的关键块.从图中可以分辨出树叶、天空以及不同光照条件下不同类型的地面.图7展示了与部分关键块相关联的图像块样本,包括草地、天空、土地、有一定光照的土地、阴影下地面、光照下的草地.每一行对应一个图像块类别,第1列是每个类别在低层词典中对应的关键块,而后4个图像块为与该关键块相关联的图像块样本.分层词袋模型不存储每个图像块,StrAP算法将其余图像块的信息归纳在四元组的其他3个参数中,从而降低了算法的时间和空间复杂度.图7中同一行内的图像块具有一定的相似性,即具有相似视觉观感的图像块将以同一关键块进行编码,从而验证了图像编码和高层词袋模型特征的正确性.

图6 实验2中低层词典内的关键块Fig.6 Key blocks from the low-level dictionary in the 2nd experiment

图7 实验2中关键块和图像块样本Fig.7 Samples from key blocks and image blocks in the 2nd experiment
本文模型中高层词典内的部分关键帧和与之相关联的图像样本如图8所示,包括不同密度的草地、光秃的土地、道路与松树、布满光斑的土地以及光暗相间的草地.每行对应一个场景,第1列是关键帧.可以看出,本文算法所发现的场景特点显著,不同视觉感观的图像被区分开来.
需要指出的是,场景发现过程是一个动态过程,分层词袋模型内的参数随着场景的变化而不断自主调整,这与其他静态的场景划分和场景识别方法不同.图9展示了模型中关键块个数和场景个数随时间变化的关系.初始时,场景数量很少,这是由于场景相对稳定.但是随着场景愈发复杂和变化愈发剧烈,新的场景也随之被发现.

图9 实验2中关键块、场景的个数随时间变化曲线Fig.9 The number of key blocks and scenes the system generated in the 2nd experiment
3.3 在连续视频上进行的实验
第3个实验所用视频是由PowerShot A630数码相机在沿河公园里采集的一整段视频,时长7分29秒,共13486帧,图像的分辨率为320×240,采集频率为30 帧/s.
图10是本文模型中高层词典内的关键帧和与之相关联的图像,它们对应了机器人发现的场景类别.可以看出,在面对各种复杂的场景时,算法仍然能做出正确的场景发现与识别.图10中的8类场景分别包含了阴影中的路面、光照下的草和树叶、落叶覆盖的地面、光照强烈区域、阴影中的草和树叶、光照下的路面、灌木和路面、房屋.从实验结果看出,由于模型采用直方图特征,新场景的发现不仅与场景包含的成分有关,而且和它们所占比例也密切相关.此外,外部条件(如光照强弱)也将影响场景发现结果.

图10 实验3的场景发现结果样本Fig.10 Samples from the scene detection results in the 3rd experiment
3.4 算法的定量评价
图11是3次实验中处理每帧图像所用时间,横坐标为帧数,纵坐标为时间,单位为s.图中高峰值对应低层词典的重聚类过程,需要90∼160 ms;低峰值对应高层词典的重聚类过程,耗时在60∼80 ms之间;关键块和关键帧的关联与编码等过程耗时最低,都在40 ms以下.可以看出,实验数据量的增加并未提高处理每帧的时间,实际应用中,用C++语言实现本文算法程序,可以进一步提高计算效率,这保证了本文模型的实时性.

图11 3个实验中每帧的耗时Fig.11 Time cost per frame in the three experiments
对实验2的数据进行人工标注,采用外部评价指标调整兰德系数(adjusted rand index,ARI)[21]定量评价场景发现的结果,并与静态词袋模型结果进行对比(见表1),ARI指标值越大则算法的场景划分结果越贴近人工标注结果.可以看出,在关键块个数和场景个数相同时,分层词袋模型的ARI指标优于传统的静态词袋模型,而且静态词袋模型无法适用于移动机器人在室外的场景发现任务.
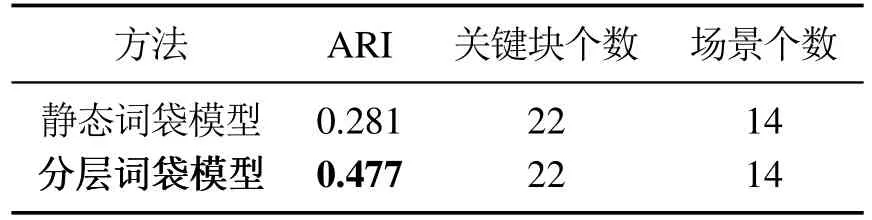
表1 分层词袋模型与静态词袋模型的定量比较Table 1 Quantitative comparison between hierarchical and static BoW models
3.5 阈值分析
以ARI、关键块个数、场景个数为指标,对算法中的5个阈值(a,ϵb,Rb,ϵf和Rf)进行分析.
表2为不同图像块边长a下的实验结果.随着边长的增大,关键块个数逐渐下降,这是由于该边长决定了图像块的尺度,尺度越大关键块的种类越少.在a40时,ARI指标达到最大值.
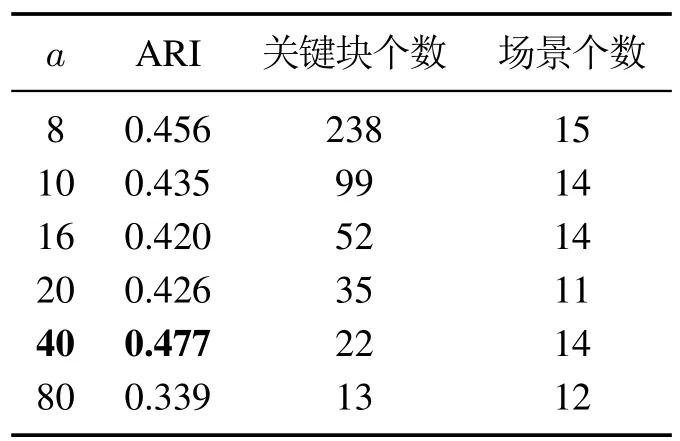
表2 不同图像块边长a下的实验结果Table 2 Experimental results from different side lengths a of image blocks
表3为不同关键块间距离阈值ϵb下的实验结果.随着ϵb的增大,关键块个数和场景个数逐渐下降,这是由于ϵb决定了哪些分块属于离群块集合,取值越大,离群块集合产生的关键块越少,从而间接导致场景个数的下降.在ϵb0.5时,ARI指标达到最大值.
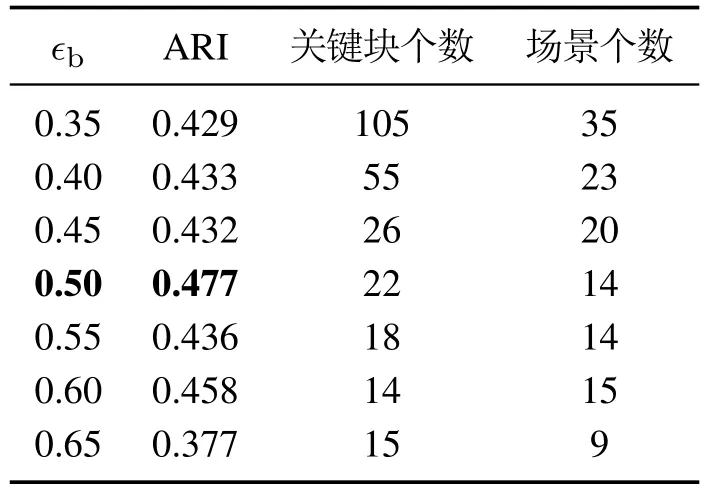
表3 不同关键块间距离阈值ϵb下的实验结果Table 3 Experimental results from different thresholds ϵb of the distance between different keyblocks
表4为不同离群块集合大小阈值Rb下的实验结果.随着Rb的增大,关键块个数和场景个数有一定波动,这是由于Rb决定了何时产生新关键块,并不会对关键块的数量有太大影响,但由于每个场景产生的图像块数量是固定的,关键块的产生时间影响了场景发现的个数.在Rb80时,ARI指标达到最大值.

表4 不同离群块集合大小阈值Rb下的实验结果Table 4 Experimental results from different thresholds Rb of the size of the keyblock outlier set
表5为不同帧间距离阈值ϵf下的实验结果.随着ϵf的增大,关键块个数保持不变而场景个数逐渐下降,这是由于ϵf并不影响低层词袋模型,只决定哪些帧属于离群帧集合,取值越大,离群帧集合产生的新场景类别越少.在ϵf0.6时,ARI指标达到最大值.
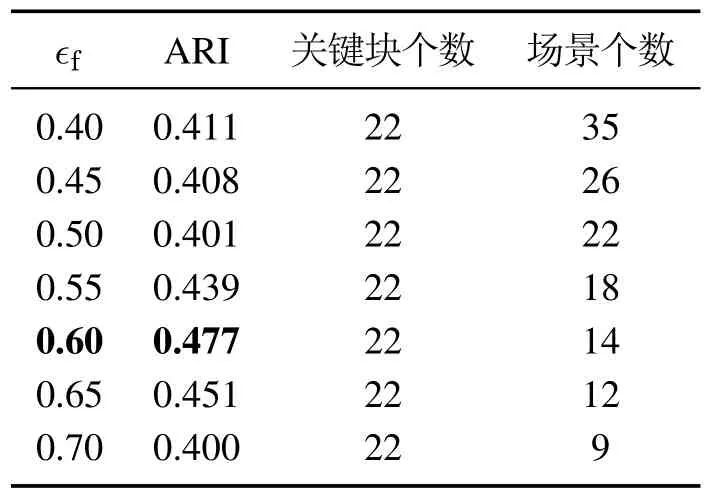
表5 不同帧间距离阈值ϵf下的实验结果Table 5 Experimental results from different thresholds ϵf of the distance between frames
表6为不同离群帧集合大小阈值Rf下的实验结果.随着Rf的增大,关键块个数保持不变,场景个数略有下降,这是由于Rf并不影响低层词袋模型,但会影响场景发现的个数.在Rf50时,ARI指标达到最大值.

表6 不同离群帧集合大小阈值Rf下的实验结果Table 6 Experimental results from different thresholds Rf of the size of the frame outlier set
4 结论
本文提出了基于分层词袋模型的室外环境增量式场景发现方法,基于图像块,用低层特征动态生成和更新低层词典,在高层词袋模型中,增量式地对图像进行聚类,并完成场景发现.该算法基于无监督学习框架,涉及选择低层特征、建立低层词袋模型、编码图像、建立高层词袋模型以及完成场景发现等步骤.最后,分别在3个实验数据集上对算法进行了验证,实验结果表明,本文算法在不需要专家提供先验知识的前提下,能够自主获得可以合理解释的场景发现和划分结果,且算法具有较好的实时性.
下一步将在场景发现研究的基础上,研究对场景内在关系和总体属性的理解,为在室外环境工作的移动机器人进行任务规划、导航和操作提供知识支持.
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
热带气象学报(2022年2期)2022-08-24
现代计算机(2022年4期)2022-04-24
微型电脑应用(2020年12期)2020-12-25
扬州大学学报(自然科学版)(2019年2期)2019-08-12
小型微型计算机系统(2018年8期)2018-09-07
软件导刊(2018年4期)2018-05-15
报刊荟萃(上)(2018年3期)2018-04-24
环球市场信息导报(2017年36期)2017-12-24
阅读(中年级)(2016年4期)2016-11-19
